@HaomingJiang
2016-07-22T19:25:33.000000Z
字数 7223
阅读 2910
Tweets Analysis 3
Tweets Textmining
One Last Thing About Metics
According to the research papers, ROC type metrics are hard to apply, especially in muticlass cases and online learning cases. For simplicity, we can merely use G-MEAN and accuarcy to evaluate the overall performance of the classifier, use recall to evaluate the ability of recognizing the each class.
Algorithm Setting
The feature extraction part of the following part is the same as previous work.
Basic Line
Occurrence & Naive Bayes
training set: 13485
test set: 1000
(they are selected reandomly. For each run of algorithm, the random seed is reset to a different value.)
Confusion Matrix (for one run)
| prediction | negative | neutral | positive |
|---|---|---|---|
| negative | 518 | 40 | 22 |
| neutral | 77 | 126 | 27 |
| positive | 38 | 33 | 119 |
Statistical metrics for ten runs:
Accuarcy =
G-mean =
Multiclass SMOTE
Since there is no muticlass discussion in the original paper, I extend the SMOTE in a natural way. The following disscussion is based on NaiveBayes classifier.
For each minority class, I oversample it with SMOTE at given rate.
Take the data of IRIS (class1: 20, class2: 25, class3: 50) with 2 minority class as an example.
library(unbalanced)data1=iris[c(1:20,51:75,101:150),c(1:2,5)]tablele(data1[,3])# setosa versicolor virginica# 20 25 50newdata1=ubSmoteExs(data1[(1:20),],3,200,k=5)newdata2=ubSmoteExs(data1[(21:45),],3,200,k=5)newdata<-rbind(newdata1,newdata2,data1[-c(1:45),])table(newdata[,3])# setosa versicolor virginica# 40 50 50
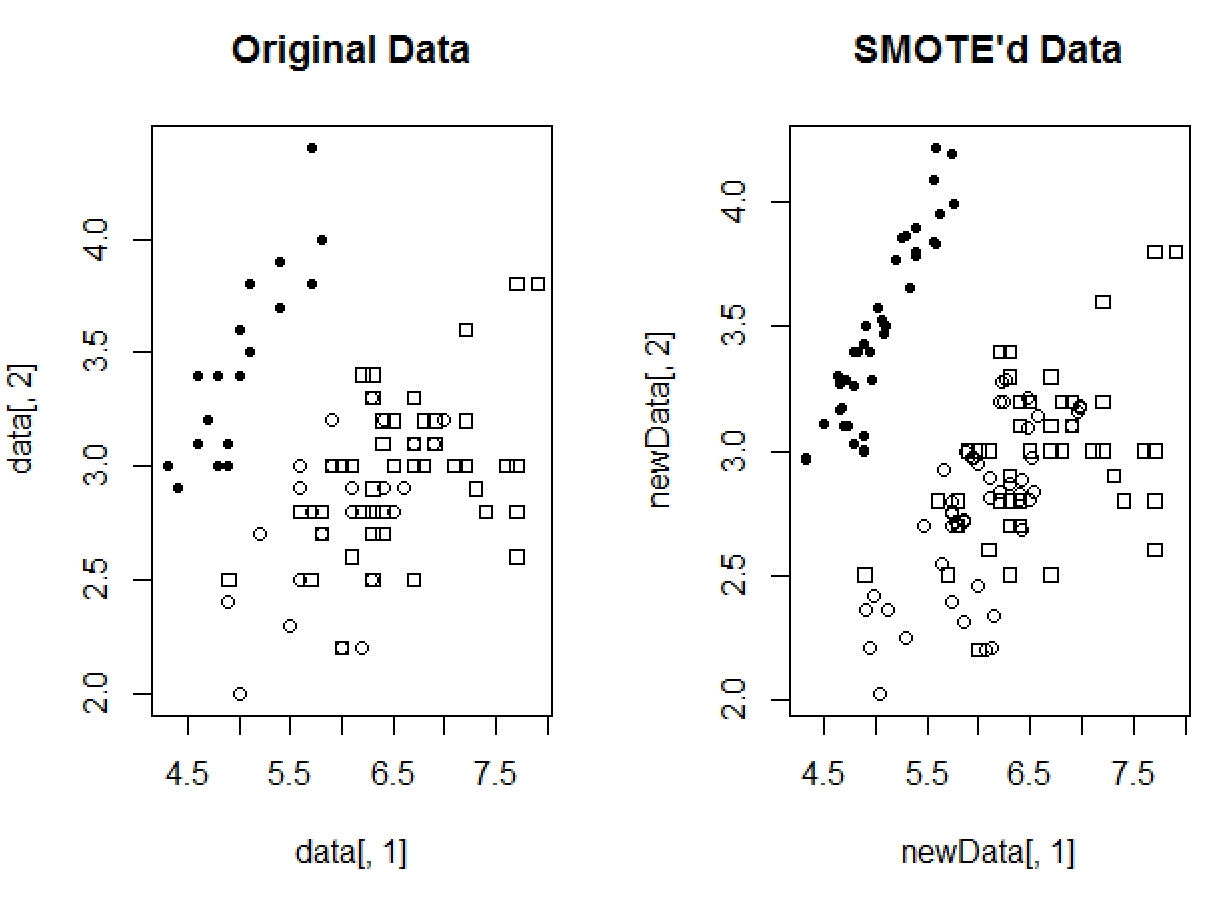
The sample misbehabiour disappear.
After SMOTE, the class capacity of training data are:
| negative | neutral | positive |
|---|---|---|
| 9082 | 8757 | 8871 |
Confusion Matrix (for one run)
| prediction | negative | neutral | positive |
|---|---|---|---|
| negative | 510 | 55 | 23 |
| neutral | 85 | 150 | 38 |
| positive | 25 | 20 | 94 |
Statistical metrics for one run:
Accuarcy =
G-mean =
Drawbacks: It really takes a long time in large data set. It spend me about three hours to run the code. The result is much better than the last report (Accuarcy: 73.8% G-Mean:0.658). However, this one run result does not outperform the base line algorithm.
IDEAS: In order to accerlate it, faster KNN searching algorithm can be introduced, like Random Projection Tree. It remind me of t-SNE, LageVis which are two dimansion reduction methods belongs to Maniford Learning Area and are able to handle large data with high demension. Some Manifold Learning techniques learn the local structure of the data. Can the similar technique also be applied in this area??? Because the idea of SMOTE is using the distacnce relation(k neigbhors) of datas, some methods learning about local data structure in Manifold Learning and Differential Geometry may have potential goodness in generating new data. Or maybe we could just use the Manifold Learning to find a better approximate low dimension coordinate of the data, use that coordinate to measure the distance of records in data. In that way, we may be able to find better neighbors and than use the method in SMOTE to generate data.
Also I think, it also related to Spectral Clustering which merely combine Laplacian Eigenmap (a maniford learning method) and K-means. Since maniford learning probably has not been applied in generating data, I think it is a good research direction. However, Manifold Learning usually utilize the information of KNN graph just as the original SMOTE, I am worried that it will not improve the quality of the generated new data.
About Manifold Learning: Find a low dimansion maniford structure of the data in the original space.
Related Material:
two Chinese blog articles
http://blog.csdn.net/chl033/article/details/6107042
http://www.cnblogs.com/wentingtu/archive/2011/12/22/2297426.html
a
http://www.iipl.fudan.edu.cn/~zhangjp/literatures/MLF/INDEX.HTM
IDEAS: Also, in terms of generating new data in text mining. Maybe we can use the synonym to do so?
AdaBoost
I tried train 100 decision tree weak classifers. However, it took me an afternoon, and finally it exceeded the memory limitation of my computer. Traning a Boosting type classifier is a hard problem. If I want to do more research on AdaBoost.NC.
Other Language Model
In terms of text mining, I think the word frequency type feature has its limitation. Complex sentiment expression will be lost in breaking the integral sentence structure into seperated word pieces.
In order to understand the fine structure of language, I study other language models.
Probabilistic Language Models
The goal of this model is to assign a probability to a sentence under certain language environment. So that we can constructure three language models (LM) under three language environment('positive','negative','neutrual'). In that way, we are able to find out which enviromentthe sentence
Goal:compute the probability of a sequence of words
The Chain Rule:
Simplifying Assumption (Markov Assumption):
or
The simplest case: Unigram model
Bigram model: use the assumption
We can extend them to trigram ... or even N-grams.
We can use Maximun Likelihood Estimate(MLE) to estimate the bigram conditional probability.
All calculation should be done in log space for computational convinence.
We can evaluate it through the classifier evaluation.
One important part of LM is that generaliztion. Because lots of new bigram or trigram will appear in the new texts, smoothing technique need to applied, such as Laplace Smoothing.
Related material : http://spark-public.s3.amazonaws.com/nlp/slides/languagemodeling.pdf
http://www.speech.sri.com/projects/srilm/
Discussion
More experiments are needed. Pan Li has found the code of unigram model, which's performance is worse than the Baseline Algorithm. But I believe bigram or trigram model can performe better. Also Pan Li proposed that there is not any online version of LM. Also some smoothing methods can be revised to online version. Or we can do class imbalance problem under the LM.
Parsing Models (Treebank)
In linguistics, a treebank is a parsed text corpus that annotates syntactic or semantic sentence structure.

This language structure can reveal the fine structure of the sentense.
A recent work combine the treebank and deep learning method to deal with the sentiment analysis (http://nlp.stanford.edu/sentiment/).
What it does is to constructure a sentiment treebank for sentence first.
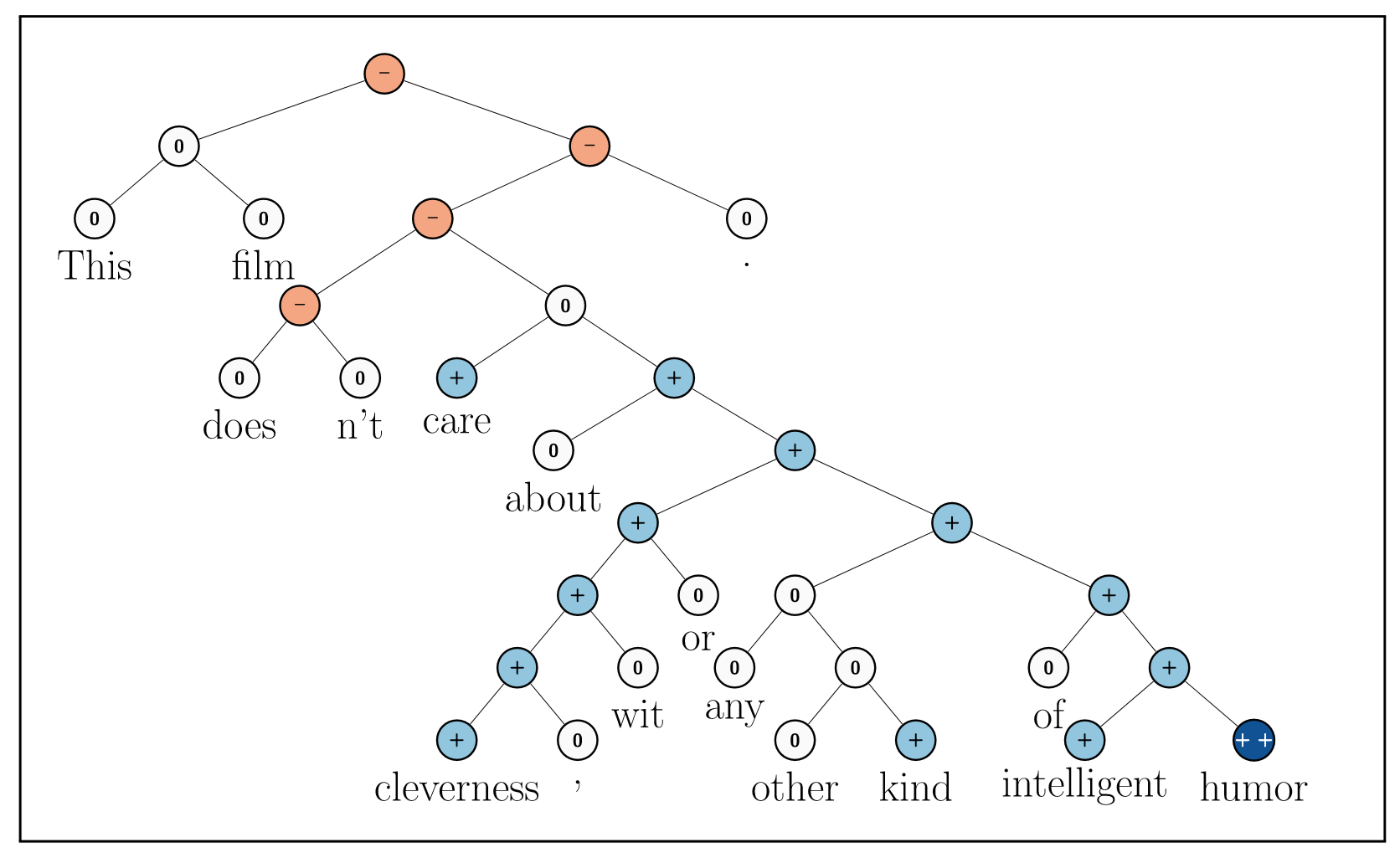
1. Each leaf node is a word.
2. Each node has a d-dimension representation.
3. Use softmax classifier to classify the vectors to labels.
4. Use RNN(Recursive Neural Network) to compute parent node's vector by using children's vectors.
5. Some more advanced RNN are purposed to improved the performance.
Because it use the gramma structure, this approach seems more reasonable. I still do not understand some details in this paper.
IDEAS & Discussion: When handling imbalanced data it may enconter problem. Maybe some algorithm can be applied here. But these ideas are hard to verified. Since the reimplement the algorithm of this paper is a big project and certainly will cost a lot of time. Also our computer may not able to train this large data just as when I trained the adaboost model.
Disscussion
I think there are a lot of interesting problems waiting me to do more experiments. But I am a little bit lost, since every experiment is time consuming and the following research work seems require a lot of coding work. If it is possible I want to disguss which way to go.
Some of the research directions are listed below.
1. To find out if Manifold Learning and Spectral Clustering can be applied in generating new data for minority class.
2. Online or Class Imbalance version of LM (maybe including smoothing methods).
3. Keep trying other methods (maybe on better language structure such as treebank) to see if we can find.
Reference
Chawla, N.V., Bowyer, K.W., Hall, L.O. and Kegelmeyer, W.P., 2002. SMOTE: synthetic minority over-sampling technique. Journal of artificial intelligence research, 16, pp.321-357.
http://spark-public.s3.amazonaws.com/nlp/slides/sentiment.pdf
http://nlp.stanford.edu/sentiment/
