@lxx3061313
2018-10-09T12:59:55.000000Z
字数 2587
阅读 283
store统一订单存储系统
未分类
背景
在交易系统模型中,订单是核心概念模型之一。任何一个业务线都会针对自己的业务模型,设计自己的业务订单模型。而一个稍具规模的互联网公司,都会有两位数以上的业务线,这样推理下来,那么一个公司就会针对订单会有十几种模型,如果没有统一管理的话,意味着每个业务线需要自己做订单持久化,并根据订单的业务类型,做自己的状态机。业务量达到一定的数量级后自己做需要做分库分表和读写分离等适合高并发的场景。而且在并发控制方便需要自己踏遍无数的坑。
由此看来,不管是基于开发人力的解放,还是基于系统高可用性,高并发,高扩展性考虑,设计一套业务无关的订单存储系统势在必行。
设计
数据模型设计
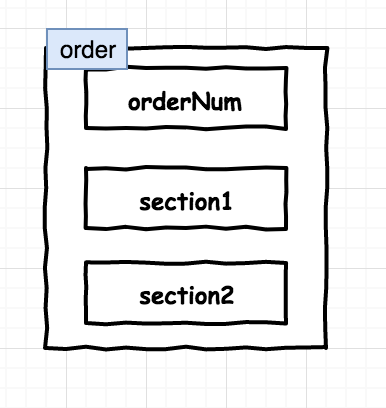
store系统在持久层采用业务段存储,每一个业务订单在持久化模型上会对应唯一对应一个订单号,和多个section。每个section是订单在业务线逻辑划分出来的一段业务数据,数据由javabean经过json序列化后生成。
这里的段是逻辑上的业务段,这样存储后,我们可以指定相应的段来完成检索,而不是每次都需要检索出整个订单信息。
分库分表设计
订单号设计
为了支持统一的分库分表,业务线的订单号需要调用统一的订单号生成系统,并且订单号是经过严格设计的,订单号位12位,分别为业务号(2位),偏移量(4位),随机数(6位),这里的偏移量是基于某一个时间点,订单生成的时间距离这个基准时间点的天数。分库分表就是的底层原理其实就是根据这个偏移量来完成的。
分库分表设计
分库分表调研
https://www.cnblogs.com/sheseido/p/8880091.html
分库分表一般有两种模式,垂直拆分和水平拆分。这两种都是结果集的描述方式,物理上的拆分。通常我们说某数据库压力很大,需要做分库分表。那么这里需要分析一下,是因为库中表非常多(所有业务都在一个库中)?还是单个表很大?
如果是表非常多,那么就需要对库进行垂直拆分,就是按业务把这么多表拆分到多个库中。而如果是单表特别大 ,就需要对表进行水平拆分,将单表按某种规则拆分成多个小表。
水平拆表的一般原则:1. range;2.hash;3.地理划分;4.时间
分库分表开源工具
目前市面上的分库分表中间件相对较多,其中基于代理方式的有MySQL Proxy和Amoeba, 基于Hibernate框架的是Hibernate Shards,基于jdbc的有当当sharding-jdbc, 基于mybatis的类似maven插件式的有蘑菇街的蘑菇街TSharding, 通过重写spring的ibatis template类的Cobar Client。
具体方案
路由实现
我们的实现方案是基于订单号上隐藏的偏移量来做的。即,针对订单号的偏移量,设计一个路由表,由路由表来决定某个订单会存储在哪个库和哪个表中。
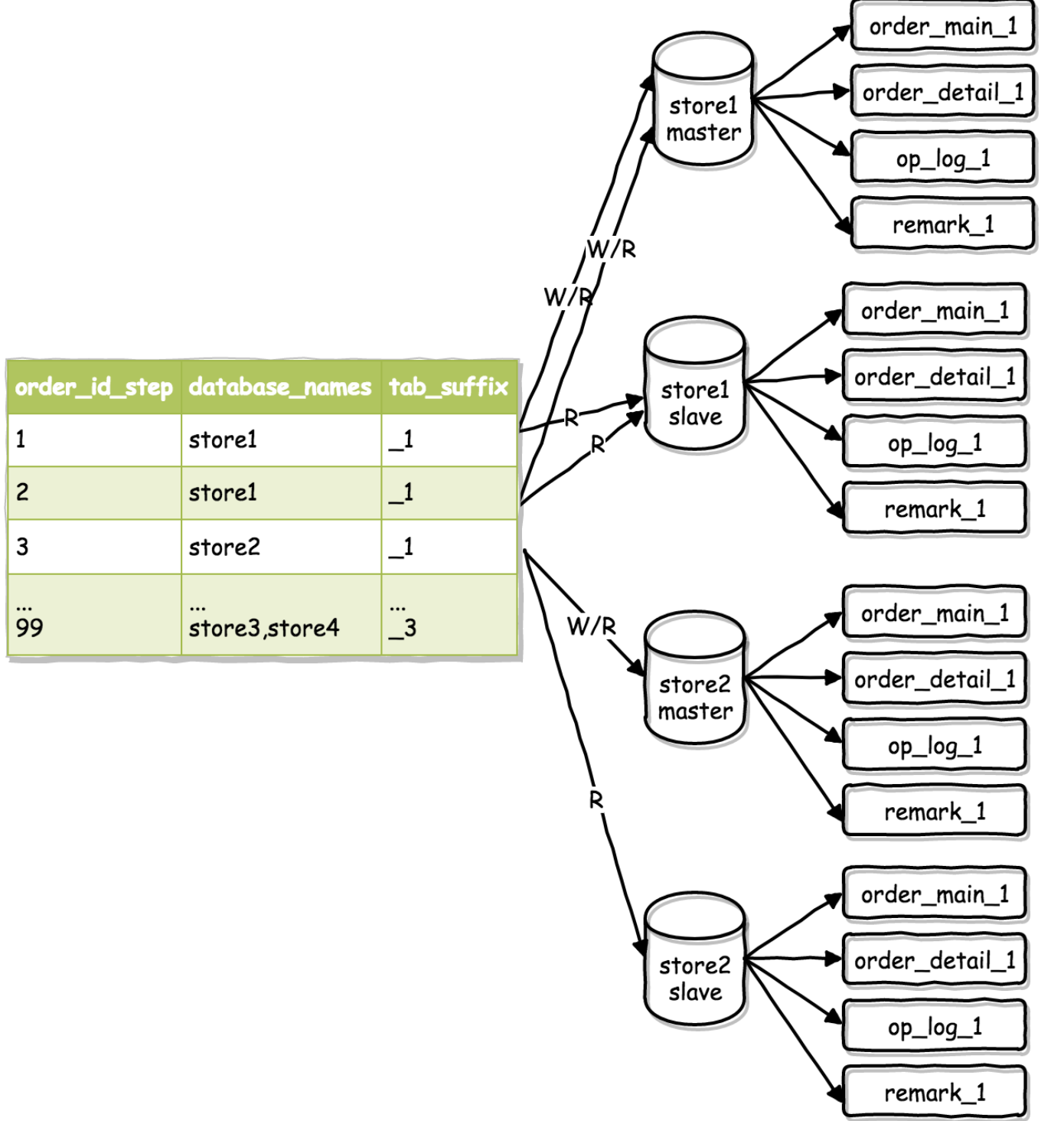
首先需要明确的是,在垂直拆分完后,已经满足不了需求的情况下,才进行的水平拆分。
水平拆分原则才由基于时间偏移量的路由表的好处是,1.水平扩展0成本,这主要是跟采用hash算法来完成分库分表的方案对比。2.业务动态适配(按需扩容),比如在业务量比较低的时候,每个表承载的时间跨度设置很大。当业务量猛增的时候,每个表承载的时间跨度可以缩小。
缺点是,一定时间段内的集火线程无法避免。假设我们有双11这样的场景,那么基于时间偏移量的方案,就是将双11当天的所有流量集中在一个库和一个表上。尽管做了读写分离,依然会问题很严峻。解决方案也很简单,在偏移量基础上加一个hash来分散负载即可,只是需要改一下路由层的协议代码。
高并发设计
统一订单存储系统采用版本控制的乐观锁方案。即在每一个订单信息上有一个版本号字段,用来表示当前的数据版本。在严格要求数据一致性的场景下,存储系统在使用订单的时候都必须根据版本号来操作。
比如在读场景,系统会先尝试使用缓存中的数据,如果对比版本号后发现数据是最新的可以直接返回,反之会尝试使用读库的场景,再反之会使用主库的场景。在实际生产环境查询qps在700-800, 缓存版本不一致导致的qps不到1,过期的大概在40,这个可能是因为缓存已经不够用了。。。想替换掉mem。
需要注意的是,在更新场景,在最底层的更细操作,用到了悲观锁。原因是,一个更新操作设计到了库表事务,版本存储在一个order_main表中,而订单数据存储在另一个order_detail表中。所以版本控制解决不了这个场景,就用到了mysql的锁空能,在更新前,先锁住order_mian相应的行信息,在执行后续的更新操作。因为粒度是行锁,所以在读多写少的场景,性能是几乎没有影响的。
流量削峰
交易系统,尤其是像store这样的通用模块,时常会面临热点时区,比如电商中的抢购,比如双11,比如我们公司的放号时间段。在这种场景下,经常会出现一段流量高峰期,如果流量瞬间超过系统的负载上线,有可能会导致非常严重的后果。
store系统是怎么应对的呢?
1.高效利用cache,让尽可能多的流量通过cache解决。少部分未命中的数据再放行到下层持久化系统。这种方式的要求是,对缓存数据更新及时性要求比较严格。
2.使用mq解耦核心模块,同步转异步。通过增加时间成本来换取稳定。试想一下,如果核心模块间采用同步模式,任何一个模块出现问题,都会影响全局。
3.做好请求有效性校验,拦截非法请求。
业务解耦
存储系统实现了订单的持久化和业务无关的解耦。而基于存储模型是业务段的json串的特点,store系实现了业务异步支持。我们这样考虑,在交易系统中,所有的业务逻辑有两种运行模式
1. 主动运行,比如保存订单,驱动者是用户。
2. 被动运行,比如提醒用户支付,驱动者是订单。
主动运行这里不考虑,因为场景非常明确,比较难做的是被动运行。因为获取订单状态变更要么主动轮询,要么被动监听。为了提高业务运行效率以及降低耦合性,store在订单信息发生变化的时候,会通过mq系统通知到业务系统。业务系统会根据具体的变更信息来确认完成相关的业务操作。
异步的实现方式为,每次update订单信息的时候,diff将要update的信息和已有的消息,将发生变更的信息通知业务系统。可能会担心diff的效率,其实diff的方式是将json串拍平成map,然后直接diff得相同key对应的value值。所以不会影响效率。
