@lxx3061313
2018-10-09T13:02:16.000000Z
字数 1643
阅读 466
es统一接入平台
es
背景
基于上篇介绍的统一订单存储模型的业务系统架构,在搜索上存在短板。因为store在持久化层采用了统一的业务无关的数据模式来保存订单信息,相应的订单的结构化查询则受到了很大的限制,简单来说store系统本身只能通过orderNum来查询订单。
为了支持业务本身以及运营需要,我们通过elastic-search来辅助完成查询功能。es作为一个近实时的搜索引擎,天然的支持分布式环境,支持高并发,高可用方案。(近实时的意思是,更新一个文档或者添加一个文档,在1s后才能可搜索。)
那么问题来了,为什么我们不直接使用es来代替mysql呢,况且es天生是基于json来完成文档存储的?
可以这么认为,es本质上是一个搜索引擎,我一直不认为es是一款数据库,所以,尽管他可以称作分布式文档数据库,即可以存储并索引PB级别的文档数据。es天然分布式,p2p模式,不支持事务,提供倒排索引来支持全文检索。
1. 从本质来讲es是一个搜索引擎的事实不可改变。基于这个事实,es基本上所有的特性优化都是基于搜索,比如文档不可变,使得其可以放心的将文档放在内存缓存中而不用担心多线程问题。而文档的更新在本质上都是使用替换模式,所以在写操作很多的业务中,es的场景并不适合。
2. es不支持事务,在业务场景负责的互联网环境,如果使用一个不支持事务的数据库,后果不可想象。
方案
为了尽可能通用,es是一个辅助搜索系统,简单的讲,es在大部分情况下会根据你的搜索条件,匹配出准确的订单信息,这里的订单信息其实只是一个订单号和对应的版本。如果需要具体的订单信息,需要去mysq数据库再查一次,当然如果你需要的字段信息就是只包含索引信息,那么可以直接从es获取。
所以在大部分场景下,es提供的搜索模式是QUERY_AND_FETCH。
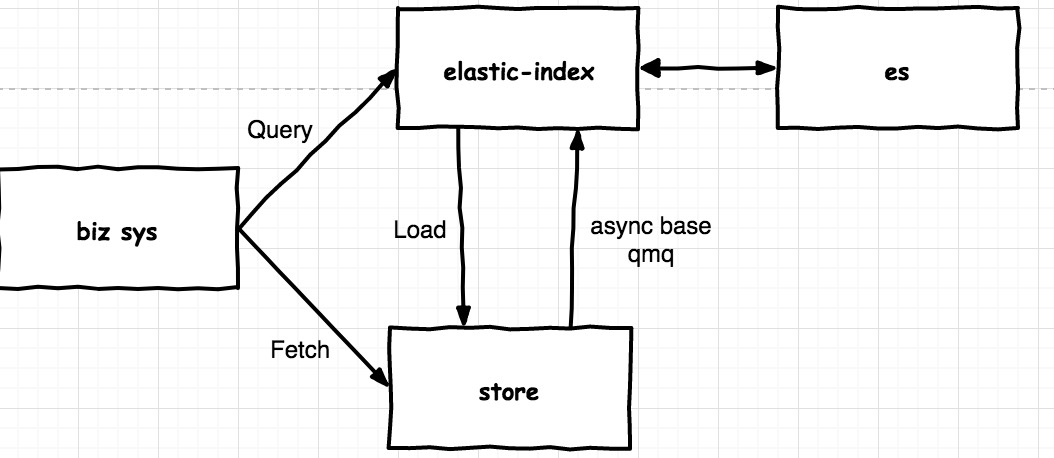
搞清楚es在整个业务系统架构中的定位后,那对es进行再包装就很简单了。es所以提供了相关的java客户端,但是客户端本身融合了es的很多查询特性,如果让一个业务线在不同es的情况下,如裸接es势必成本会很大。所以我们提供了es的统一记入平台。
我们从写和读两方面来分析
1.写,写有两种方式,同步写和异步写。同步写的好处是数据实时更新,缺点是业务系统会跟es系统进行强绑定,并且业务逻辑的处理时间会加上es的索引时间,造成业务逻辑处理时间加上。异步写,缺点是数据最终一直,但是如果采用query_and_fetch的模式,可以适用于数据实时性要求比较高的场景。优点是,业务处理跟es存储解耦,提供系统的鲁棒性。并且在系统接入时,几乎0成本。
2.读,读也有两种模式。es-index接入平台提供了两种读取模式。fetch模式和query_and_fetch模式。这两种模式在上面已经介绍清楚了。根据业务需求不同可以选择不同的接口。
经过上面分析,在系统实现上,es-index接入平台采用的是异步写,和多种方式读来作为其基础方案的。
读这里不讨论了,因为是统一的读取接口。数据模型采用业务无关的Map来实现。主要讨论写,在系统接入时,业务系统需要做几项简单的工作
1.订单索引,类型,已经对应的映射。这里需要说一下,es本身可以支持开箱即用的功能,但是考虑到系统性能,已经系统定位,es在我们的架构中是作为一个业务的辅助搜索功能,其可索引字段是有限的。所以我们这里要求自定义每个类型的映射。
2.提供回调接口,即可以根据唯一标示查询到所有的业务数据。
没了!!!!是不是很惊讶,接入es就是这么简单。
在es-index内部,我们基于store的diff消息,来动态获取业务订单数据,并根据业务线设置的mapping信息,将业务订单数据索引到es文档中。
在查询的时候,store层提供了一层查询语义层的封装,将一个查询分成了queryCondition(查询条件), limit(查询限制), order(排序信息)。es正好利用这层语义封装来统一查询请求,将其转换为es支持的query请求。
