@lxx3061313
2018-10-18T18:49:05.000000Z
字数 1539
阅读 334
库存扣减预算管理
作业
背景
在某种高并发场景下,某种商品的库存使用分布式存储。基于场景的需要需要对库存的扣减实施消耗率控制。为了简化分析,我们具体化场景, 某电商网站要有一个秒杀业务,商品为手机,库存1000,因为秒杀并发量很大所以将库存1000,分成10份,分别存在了10个数据库中来分担流量。另外需要的注意的是秒杀活动要进行5天,每天最多只能卖出200个,不能超卖。
方案设计
场景有两个关键点:1.分布式存储,2.消耗率控制
分布式存储
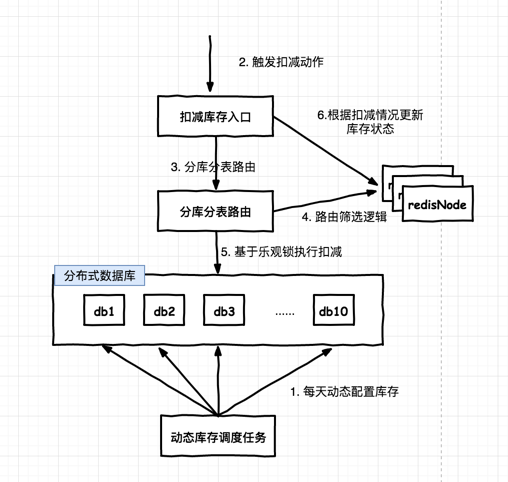
需要考虑3个问题:1.从哪个库进行扣减。2.怎么扣减。3.如果当前库存扣减失败怎么处理。
从哪个库扣减
增加路由层来完成数据库的路由,并增加过滤机制将库存为0的数据库排除以减少无畏的请求。这里需要引入分布式缓存系统(非必须,这里引入缓存是为了提高路由效率),来记录库存状态。当某一个数据的库存扣减为0后,记录该数据库状态。如果有涉及到退货的(由于时间问题,代码中未写退货相关逻辑),则恢复相关库存状态。
怎么扣减
由于库存是共享资源,必定存在资源竞争的问题。一般两种方式解决竞争,悲观锁和乐观锁。为了提升性能,这里我们采用乐观锁的方式,即CAS的方式。
update inventory set count = newOLdInventory where count = oldInventory and merchant_id=#{merchantId}
这里需要注意一个问题,即在隔离级别为RR的情况下还是会出现超卖的问题,因为RR隔离级别下事务读取不到另一个事务的提交,所以这里需要设置隔离级别为RC。
如果扣减失败怎么处理
两种模式1. 基于效率考虑,直接反给用户库存不足,保证大部分用户体验即可。2.基于用户至上考虑,做failover。本次作业使用的第一中方案,保证大部分用户体验。
消耗率控制
可以抽象出一个动态周期性库存概念,我们这里假设周期为天。
动态周期性库存
这里库存不会一下子全部初始化到数据库,而是周期性的初始化到数据库,假设消耗率周期为天。则可以理解下面的示例:
1. 第一天初始库存总量为200,每个数据库分到20个库存。如果第一天消耗完了。
2. 第二天再增加200库存,所以第二天库存还是为200,如果第一天只消耗了100,那么第二天的总体库存就是300.所以库存是动态变化的,可以兼容当天库存是否消耗完两种情况。
3. 后续依旧,直到活动结束。
这里其实还有另外一种方案,就是实现将所有的库存都初始化到数据库,然后利用分布式锁来实现周期性的信号量池,即在一个周期内向信号量池放入指定数目的信号量,每次扣减都必须首先获取信号量才能进一步操作。但是考虑到可能会严重依赖缓存,所有这个方法没有实施。
结构图
代码组织
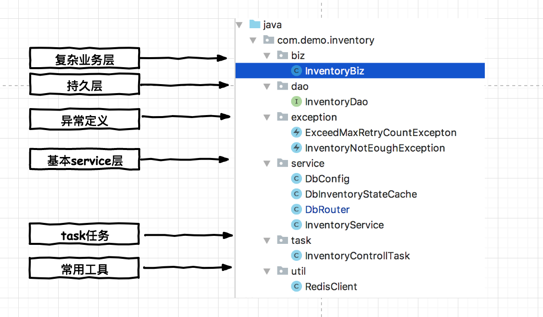
层级结构
层级说明
biz包:一般会将复杂的逻辑专门抽象出一层,来减少service的逻辑复杂度。扣减库存入口。
service包:常用service服务,其中DbConfig假设为配置中心,可以从分布式配置中心拿到数据。DbRouter是分库分表的路由器,可以根据相关逻辑筛选出需要连接的数据源。DbInventoryStateCache是用来缓存各数据中关于库存的有无状态,注意这里并没有将库存直接放在缓存中。InventoryService是轻量级的库存服务类。
dao包:持久层代码,这里假设使用的是mybatis来完成持久层的接入,所以定了一个接口。
task包:用于定义调度任务。这里只定义了一个任务,用来完成动态库存的分配工作。
util包:定义常用工具类,这里定义了redis的一个假想客户端。
exception包:定义相关异常类。
