@lxx3061313
2018-10-09T12:59:37.000000Z
字数 4506
阅读 198
dubbo总结
dubbo
官方文档地址
http://dubbo.apache.org/zh-cn/docs/dev/implementation.html
知识点脑图
https://www.xmind.net/m/yEPV/
http://www.iocoder.cn/Dubbo/good-collection/
知识点
架构设计
1.分层设计
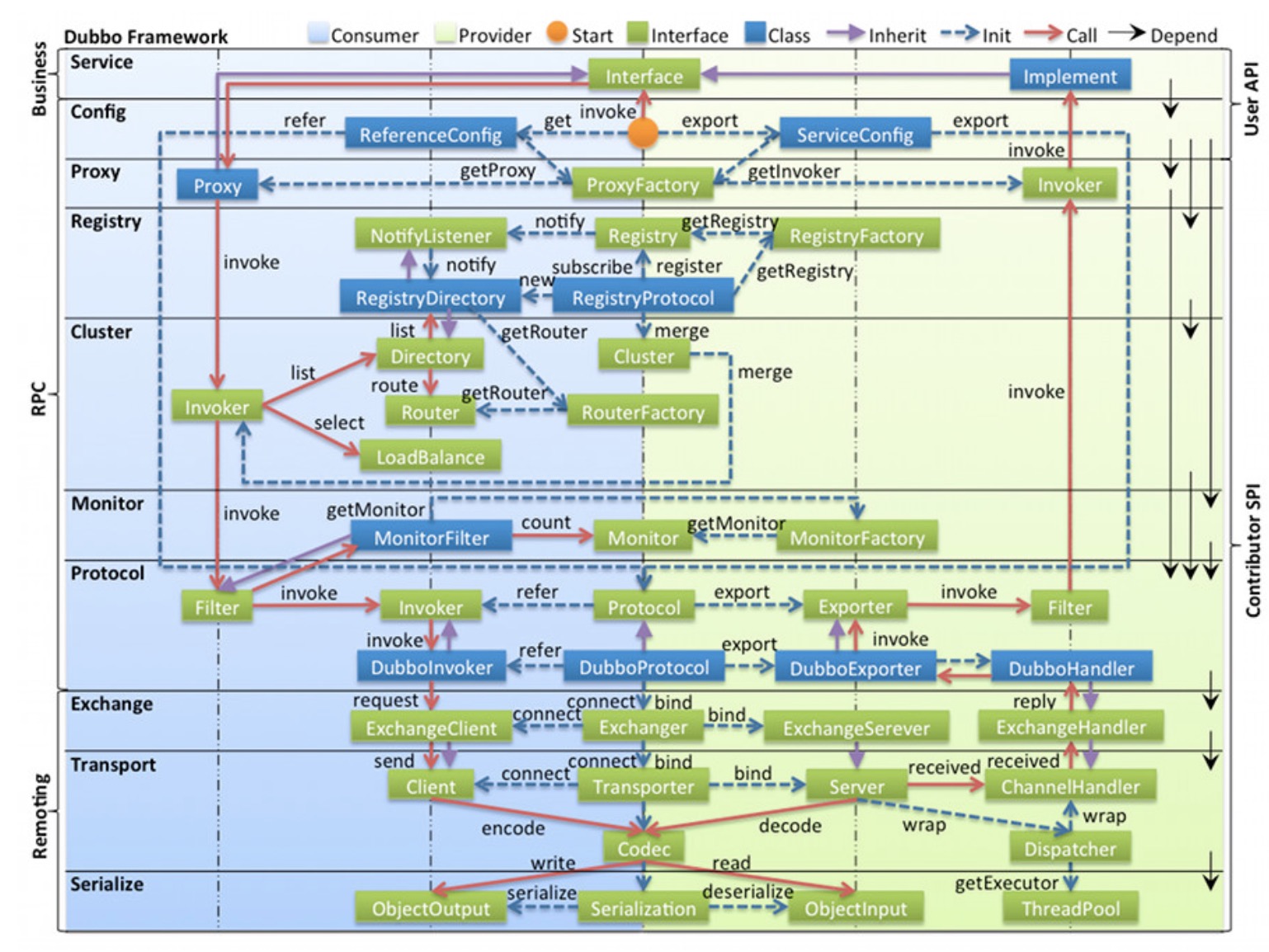
2.依赖关系
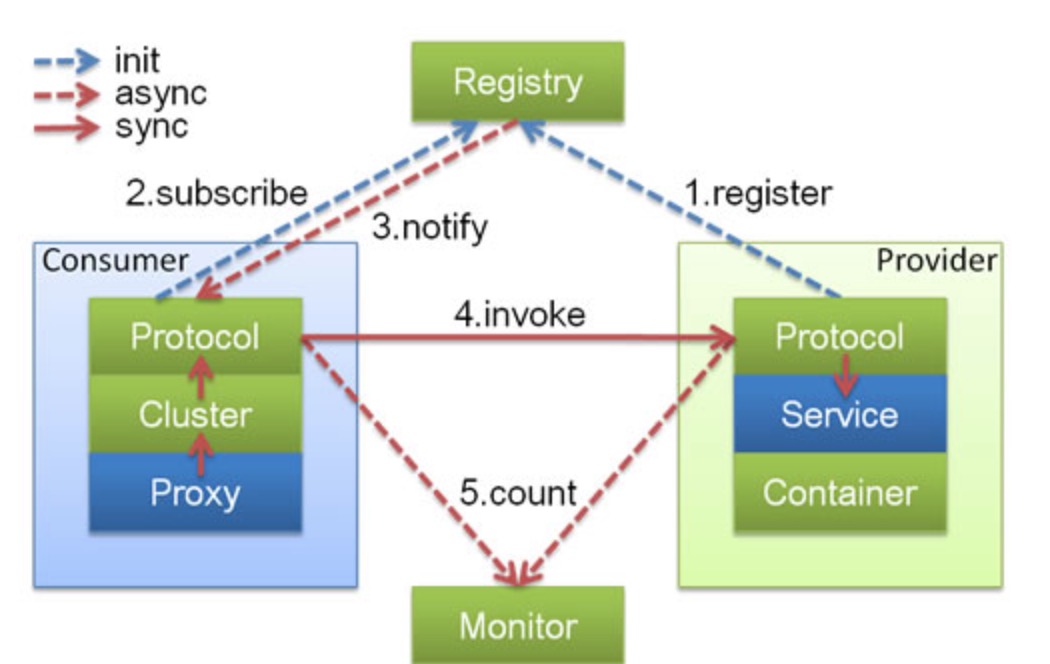
设计原则
扩展点加载
在这个分层机构中,service层和config层是接口。其余各层都是SPI。
Dubbo SPI源于JDK的标准SPI,并在其基础上进行了加强。
1. jdk需要实例化所有的实现类,并循环才能找到我们的实现,dubbo spi通过代理实现动态加载。
2. 支持loc和aop
3. 在配置文件上,JDK远程SPI只给出了实现类,而没有给他们命名,导致程序很难去引用他们。而dubbo spi给每个实现类增加了name属性。
基础概念
1.扩展点
一个接口
2.扩展
接口的实现类
3.扩展实例
实现类的实例
4.扩展自适应实例
可能把它称为扩展代理类更好一点。扩展的自适应实例就是扩展点的一个实现,只不过内部没有做逻辑的真正实现。在运行时扩展的自适应实例会根据参数来决定调用哪个扩展。自适应实例在dubbo中使用非常广泛,在dubbo中每一个扩展都会有一个适应类,如果我们没有提供,dubbo会通过字节码工具帮我们生成一个。
5.ExtentionLoader
类似于Java SPI的ServiceLoader,负责扩展的加载和生命周期维护。
总结
对Dubbo进行扩展,不需要改动Dubbo的源码
• 自定义的Dubbo的扩展点实现,是一个普通的Java类,Dubbo没有引入任何Dubbo特有的元素,对代码侵入性几乎为零。
• 将扩展注册到Dubbo中,只需要在ClassPath中添加配置文件。使用简单。而且不会对现有代码造成影响。符合开闭原则。
• Dubbo的扩展机制支持IoC,AoP等高级功能
• Dubbo的扩展机制能很好的支持第三方IoC容器,默认支持Spring Bean,可自己扩展来支持其他容器,比如Google的Guice。
• 切换扩展点的实现,只需要在配置文件中修改具体的实现,不需要改代码。使用方便。
下一篇,我们将会一起深入Dubbo的源码,更深入的了解Dubbo的可扩展机制。
服务暴露
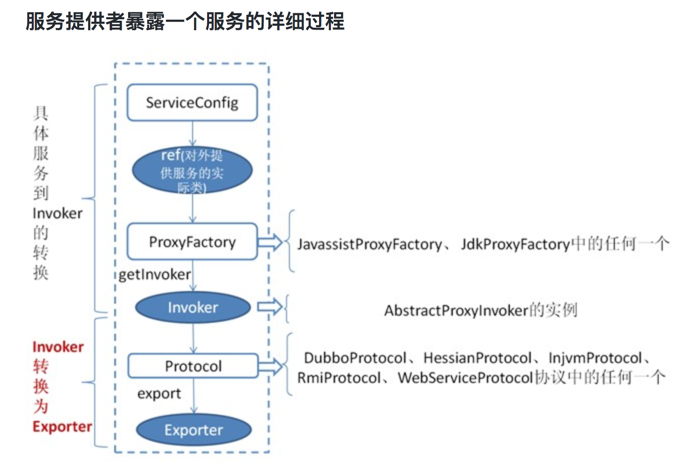
首先 ServiceConfig 类拿到对外提供服务的实际类 ref(如:HelloWorldImpl),然后通过 ProxyFactory 类的 getInvoker 方法使用 ref 生成一个 AbstractProxyInvoker 实例,到这一步就完成具体服务到 Invoker 的转化。接下来就是 Invoker 转换到 Exporter 的过程。
Dubbo 处理服务暴露的关键就在 Invoker 转换到 Exporter 的过程,上图中的红色部分。下面我们以 Dubbo 和 RMI 这两种典型协议的实现来进行说明:
Dubbo 的实现
Dubbo 协议的 Invoker 转为 Exporter 发生在 DubboProtocol 类的 export 方法,它主要是打开 socket 侦听服务,并接收客户端发来的各种请求,通讯细节由 Dubbo 自己实现。
RMI 的实现
RMI 协议的 Invoker 转为 Exporter 发生在 RmiProtocol类的 export 方法,它通过 Spring 或 Dubbo 或 JDK 来实现 RMI 服务,通讯细节这一块由 JDK 底层来实现,这就省了不少工作量
服务引用
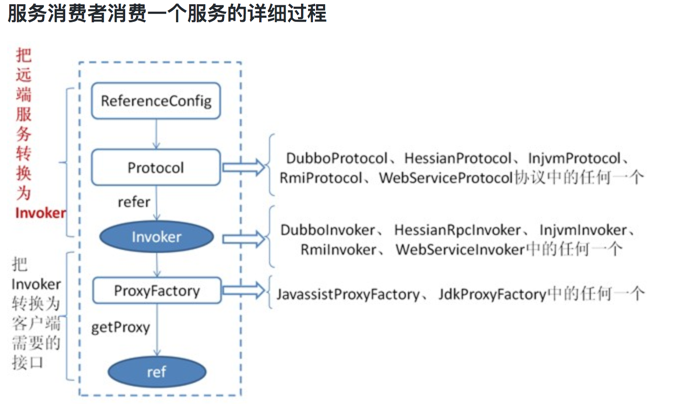
上图是服务消费的主过程:
首先 ReferenceConfig 类的 init 方法调用 Protocol 的 refer 方法生成 Invoker 实例(如上图中的红色部分),这是服务消费的关键。接下来把 Invoker 转换为客户端需要的接口(如:HelloWorld)。
关于每种协议如 RMI/Dubbo/Web service 等它们在调用 refer 方法生成 Invoker 实例的细节和上一章节所描述的类似。
invoker
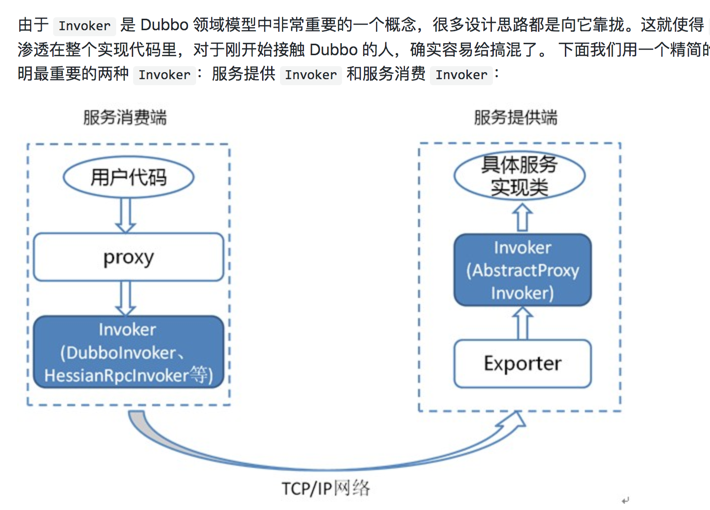
由于 Invoker 是 Dubbo 领域模型中非常重要的一个概念,很多设计思路都是向它靠拢。这就使得 Invoker 渗透在整个实现代码里,对于刚开始接触 Dubbo 的人,确实容易给搞混了。 下面我们用一个精简的图来说明最重要的两种 Invoker:服务提供 Invoker 和服务消费 Invoker:
dubbo分组怎么实现的
面试题
https://www.jianshu.com/p/9d062eceb765
https://blog.csdn.net/liyanlei5858/article/details/79236685
1.dubbo支持哪些协议
dubbo:// Dubbo缺省协议采用单一长连接和NIO异步通讯,适合小数据量大并发的服务调用,以及服务消费者数量远大于服务提供者数量的情况。
为什么要求服务消费者数量要多余提供者?
因dubbo协议采用单一长连接,假设网络为千兆网卡(1024Mbit=128MByte),
根据测试经验数据每条连接最多只能压满7MByte(不同的环境可能不一样,供参考),理论上1个服务提供者需要20个服务消费者才能压满网卡。
dubbo通信协议dubbo协议为什么不能传大包?
因dubbo协议采用单一长连接,
如果每次请求的数据包大小为500KByte,假设网络为千兆网卡(1024Mbit=128MByte),每条连接最大7MByte(不同的环境可能不一样,供参考),
单个服务提供者的TPS(每秒处理事务数)最大为:128MByte / 500KByte = 262。
单个消费者调用单个服务提供者的TPS(每秒处理事务数)最大为:7MByte / 500KByte = 14。
如果能接受,可以考虑使用,否则网络将成为瓶颈。
dubbo通信协议dubbo协议为什么采用异步单一长连接?
因为服务的现状大都是服务提供者少,通常只有几台机器,
而服务的消费者多,可能整个网站都在访问该服务,
比如Morgan的提供者只有6台提供者,却有上百台消费者,每天有1.5亿次调用,
如果采用常规的hessian服务,服务提供者很容易就被压跨,
通过单一连接,保证单一消费者不会压死提供者,
长连接,减少连接握手验证等,
并使用异步IO,复用线程池,防止C10K问题。
rmi:// RMI协议采用JDK标准的java.rmi.*实现,采用阻塞式短连接和JDK标准序列化方式,Java标准的远程调用协议。
连接个数:多连接
连接方式:短连接
传输协议:TCP
传输方式:同步传输
序列化:Java标准二进制序列化
适用范围:传入传出参数数据包大小混合,消费者与提供者个数差不多,可传文件。
适用场景:常规远程服务方法调用,与原生RMI服务互操作
hessian://
Hessian协议用于集成Hessian的服务,Hessian底层采用Http通讯,采用Servlet暴露服务,Dubbo缺省内嵌Jetty作为服务器实现
基于Hessian的远程调用协议。
连接个数:多连接
连接方式:短连接
传输协议:HTTP
传输方式:同步传输
序列化:Hessian二进制序列化
适用范围:传入传出参数数据包较大,提供者比消费者个数多,提供者压力较大,可传文件。
适用场景:页面传输,文件传输,或与原生hessian服务互操作
http://
采用Spring的HttpInvoker实现
基于http表单的远程调用协议。
连接个数:多连接
连接方式:短连接
传输协议:HTTP
传输方式:同步传输
序列化:表单序列化(JSON)
适用范围:传入传出参数数据包大小混合,提供者比消费者个数多,可用浏览器查看,可用表单或URL传入参数,暂不支持传文件。
适用场景:需同时给应用程序和浏览器JS使用的服务。
wenservice://
基于CXF的frontend-simple和transports-http实现
基于WebService的远程调用协议。
连接个数:多连接
连接方式:短连接
传输协议:HTTP
传输方式:同步传输
序列化:SOAP文本序列化
适用场景:系统集成,跨语言调用。
thift://
Thrift是Facebook捐给Apache的一个RPC框架,当前 dubbo 支持的 thrift 协议是对 thrift 原生协议的扩展,在原生协议的基础上添加了一些额外的头信息,比如service name,magic number等
memcached://
redis://
2.注册中心有哪些
https://www.cnblogs.com/duanxz/p/3772765.html
multicast
zk
redis
simple
3.默认使用什么序列化
默认使用hessian序列化,hessian是一个采用二进制传输的服务框架,轻量,快速。
4.服务提供者能实现失效踢出的原理。
长连接,临时节点等。
5.服务上线怎么不影响旧版本(多版本支持)
当一个接口实现,出现不兼容升级时,可以用版本号过渡,版本号不同的服务相互间不引用。
6.dubbo协议下的单一长连接与多线程并发如何协同工作
底层采用netty,看一下netty的线程模型。
7.集群容错怎么做
failover(默认)
失败自动切换,当出现失败,重试其它服务器。(缺省)
通常用于读操作,但重试会带来更长延迟。
可通过retries="2"来设置重试次数(不含第一次)。正是文章刚开始说的那种情况.
failfast
快速失败,只发起一次调用,失败立即报错。
通常用于非幂等性的写操作,比如新增记录。
failsave
失败安全,出现异常时,直接忽略。
通常用于写入审计日志等操作。
failback
失败自动恢复,后台记录失败请求,定时重发。
通常用于消息通知操作。
forking
并行调用多个服务器,只要一个成功即返回。
通常用于实时性要求较高的读操作,但需要浪费更多服务资源。
可通过forks="2"来设置最大并行数。
Broadcast Cluster
广播调用所有提供者,逐个调用,任意一台报错则报错。(2.1.0开始支持)
通常用于通知所有提供者更新缓存或日志等本地资源信息。
8.dubbo是如何实现负载均衡
RandomLoadBalance
随机,按权重设置随机概率。
在一个截面上碰撞的概率高,但调用量越大分布越均匀,而且按概率使用权重后也比较均匀,有利于动态调整提供者权重。
RoundRobin
轮循,按公约后的权重设置轮循比率。
存在慢的提供者累积请求问题,比如:第二台机器很慢,但没挂,当请求调到第二台时就卡在那,久而久之,所有请求都卡在调到第二台上。
LeastActive
最少活跃调用数,相同活跃数的随机,活跃数指调用前后计数差。
使慢的提供者收到更少请求,因为越慢的提供者的调用前后计数差会越大。
ConsistentHashLoadBalance
一致性Hash,相同参数的请求总是发到同一提供者。
当某一台提供者挂时,原本发往该提供者的请求,基于虚拟节点,平摊到其它提供者,不会引起剧烈变动。
Dubbo的集群容错和负载均衡同样也是Dubbo本身的高级特性.正如我们在说自定义扩展的时候一样,这两个特征同样也可以进行自定义扩展,用户可以根据自己实际的需求来扩展他们从而满足项目的实际需求.
