@xlx9765
2017-06-24T14:34:27.000000Z
字数 957
阅读 350
Linux云服务器下配置Scrapy并抓取名人名言、热门标签
1. 安装配置流程
远程访问阿里云
手动创建个人文件夹

查看python版本
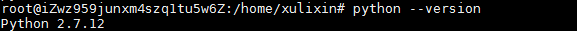
用pip安装virtualenv
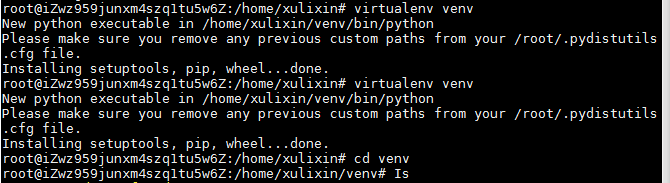
创建venv虚拟环境
pip安装twisted
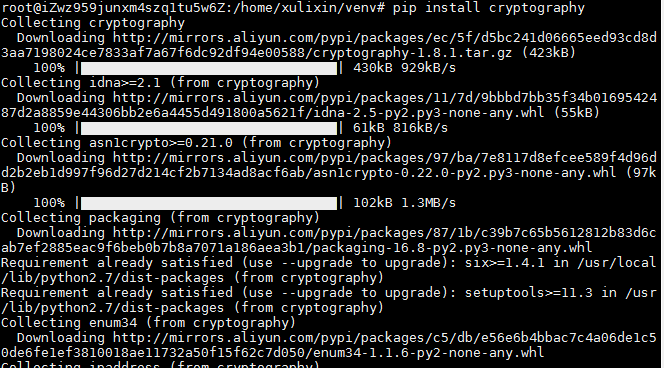
安装crypotography
安装scraphy
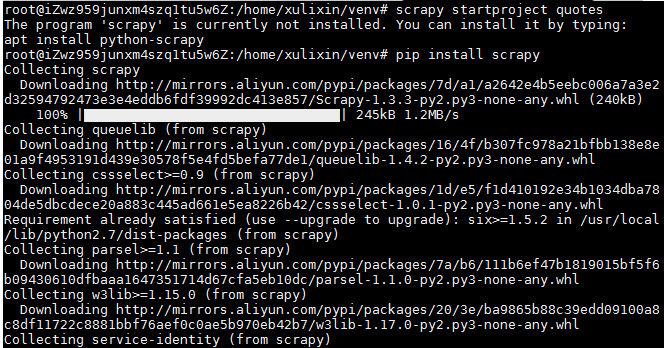
查看scrapy版本

安装成功
2. 配置过程中问题
首先是使用SSH远程登录云服务器时,输入密码无法显示,以为出错,输入检查了几次,仍旧无法输入,然后查看相关文档发现Linux下命令行就是这个样子的。然后进行下一步,创建文件夹。创建后显示成功,但是查看文件夹时显示No such file or directory。于是手动创建文件夹。创建成功。之后在安装其他安装包部分很顺利,没有遇见问题。有四个安装包由于同组有一个人首先进行了安装,组内具有sudo权限的人安装即可,所以没有进行安装,分别是
(1)build-essential: Informational list of build-essential packages;
(2)libssl-dev:是OpenSSL项目实施SSL和TLS加密协议的一部分,用于通过Internet进行安全通信。
(3)libffi-dev:外部函数接口库(开发文件)
(4)python-dev:头文件和Python的静态库(默认)
3. 爬取数据部分
(1)爬取html、激活并进入虚拟目录
本地编写spiders代码并上传
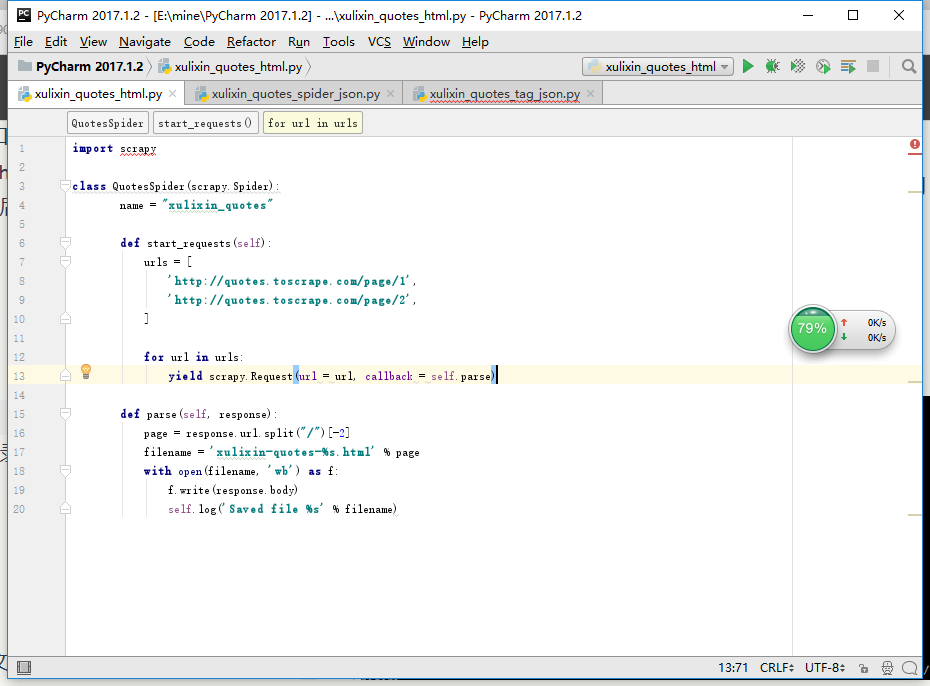
把写好的py文件拖进spiders目录下
开始执行文件
得到html文件
(2)爬取json数据
本地编写spiders代码并上传
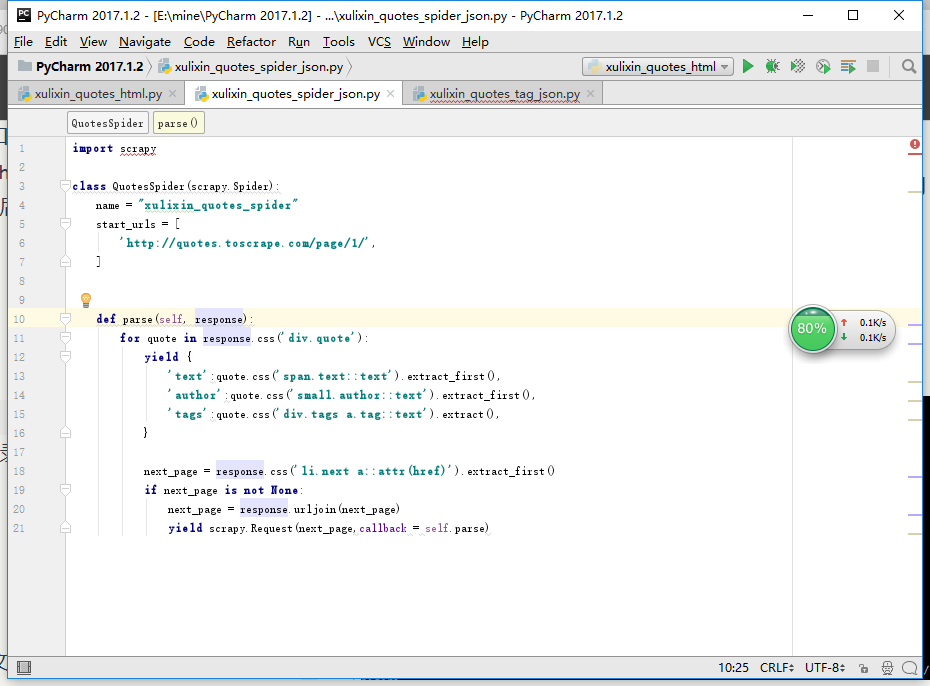
把写好的py文件拖进spiders目录下
执行、保存
(3)爬取热门标签
本地编写spiders代码并上传
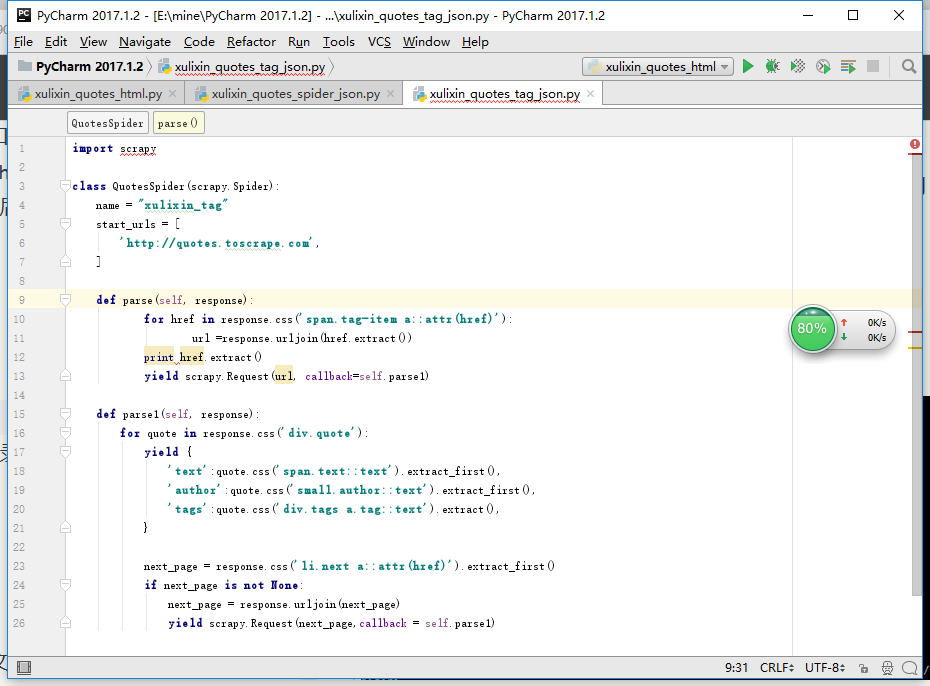
把写好的py文件拖进spiders目录下
激活进入虚拟路径
执行操作
将爬取结果存为xulixin.json文件

爬取完成
爬取成功后,目录结构
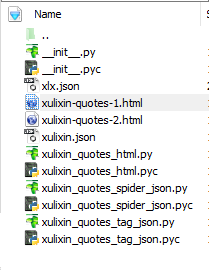
将得到的json文件转化为xml格式,得到xml文件。(xml文件在邮件附件部分)
4 爬取数据部分问题
爬取数据时在上传py文件部分遇到了问题,没有将文件传入指定位置。拖入了命令行中,导致执行失败,之后看教程将文件传入并执行成功。得到了对应的html文件和json文件。
