@xlx9765
2017-07-01T11:46:09.000000Z
字数 16288
阅读 274
2014141093031 徐丽新 信息组织与信息检索作业集
期末作业集合
1、描述自己FOAF文件
1.1 FOAF文件
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:rdfs="http://www.w3.org/2000/01/rdf-schema#"
xmlns:foaf="http://xmlns.com/foaf/0.1/"
xmlns:admin="http://webns.net/mvcb/">
Lixin Xu
Miss
Lixin
Xu
xinxin
bb7be436fc925ae0b9d45a0ed2f6d021769ccc3f
Li Jiayi
ecb4a76f28b4131aa5363a896f7bc4db06dcea1a
Fan Wei
762ec4260f2e1f25685e918a2f8adf9da6712be0
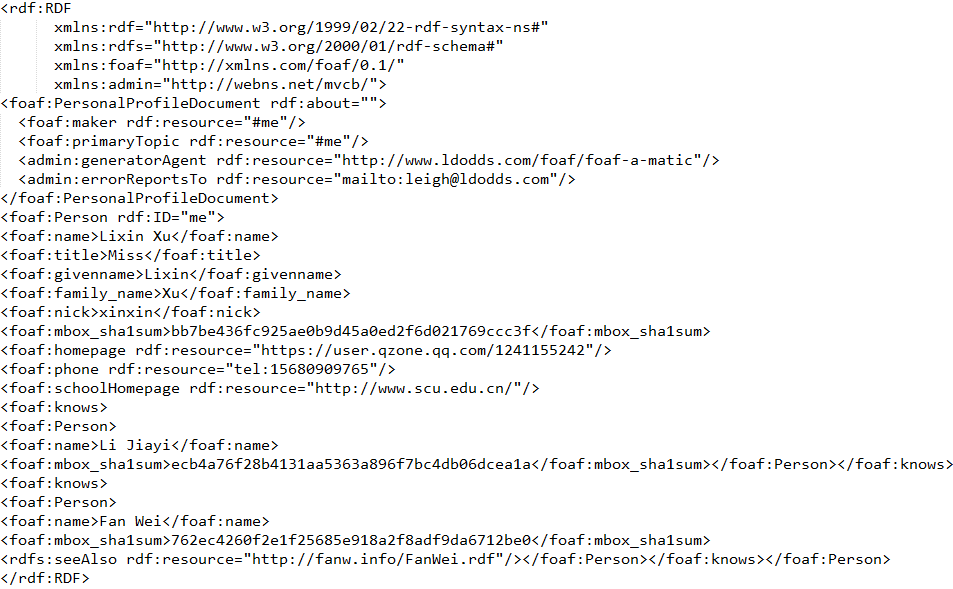
1.2 FOAF文件解读
FOAF文件是典型的rdf格式,RDF是一个用于表达关于万维网上的资源的信息的语言.
专门用于表达关于Web资源的元数据,比如Web页面的标题、作者和修改时间,Web文档的版权和许可信息,某个被共享资源的可用计划表等。现在,RDF可被用于表达关于任何可在Web上被标识的事物的信息,即使有时它们不能被直接从Web上获取。
2、信息组织读后感
2.1 当前ICT环境下信息组织新的任务和挑战
当前ICT环境下信息组织新的任务和挑战
正如《新数字秩序的革命》一书中所说,秩序共有三个层次。这本书还给我们举了个通俗有趣的例子:比尔·盖茨买下贝德曼图片资料馆后的图片保存方法。书中这样写道:
站在长长的洞穴中时,你其实正身处一个庞大的第一层秩序组织之间。而安排事物本身----将书本摆入书架,将照片插入相册则是在安排第二层秩序1。
因此我们可以通过图书馆来理解数字的秩序。图书本身就是第一层秩序,而第二层秩序是对该书本的秩序安排。
贝德曼图片资用目录卡片指示出第一层秩序照片的存储位置。第一层和第二层秩序运行良好。但是价格高昂,还受制于目录卡片的数量。即目录卡片不能庞大到无法发挥作用。书中继而引出了比特是如何完美的解决了第三层秩序障碍的内容。即引入标签,标签不是实体信息,不再受数量约束。不经可以更精准、更完备的表示信息,而且实现了个性化推荐和服务(文中的亚马逊、iTunes等)。
但是当前ICT环境对信息组织提出了更高的需求和更高的展望。ICT即信息与通信技术。在当前大数据、网络环境背景下,健康、环境、互联和智能计算等领域都等待着被发展、被突破。这也是当前ICT背景下对信息组织的新的要求。
下面就环境信息这一主题进行展开。
环境信息如何进行组织。环境信息包括地理位置信息、气候信息、植被信息等等。这些信息种类繁多,覆盖面积广、专业性较强。因此信息组织在这方面面临着挑战也充满着发展。没有看到关于环境信息组织的相关方法,选取这一主题主要是因为袁莉老师向我们说政府信息公开项目时提到了环境气候信息等因素的公开和共享。但是参考通用的信息组织管理的流程,即信息组织标准的采用----信息组织的操作----信息组织的更新和控制----信息组织的评测2,我认为可以从以上四个步骤来分别阐述信息组织当今可能面临的挑战。
首先是信息组织标准的采用,当前有很多信息组织的方法和标准,但是并没有一个一个统一的信息组织的标准。所以说当多个环境项目间进行合作或者是分阶段项目,如果项目间没有采用一致的信息组织方法,那么在信息的整合上会出现不必要又没有避免的麻烦。
其次是信息组织的实施,目前众包模式的出现可以解决基础环境数据采集阶段问题,也可以通过这种方式集思广益,获取组织最优方案并进行实施,但是如何进行信息组织,其中涉及的环境方面的专业性和信息组织本身的专业性,造成了较高的专业壁垒,仍然是一个难以解决的问题。
再次是信息组织的更新和控制,如果信息组织当初的设计对后期也完全适用,那么后期数据的更新和控制无疑只是一些和当初无异的操作,只是在数据量上有了区别。但是如果后期发现最初组织设计,不适合后期的数据组织,那么在调整上必然会出现困难,怎样进行后续处理,重新设计还是后期改造?我相信都是一个不小的工作量。然而这也是现实生活中难以避免的问题。
最后是信息组织的评测,这是指一定期和不定期地对信息组织的使用状况、投资回报等进行分析评估3。这应该是后期对价值的判定和对信息组织效果的评估。在这个阶段,难免会出现不一致、或不肯定的人,对当前的信息组织表示出不满意的态度甚至是进行抨击。每个人对同一事物都有不同的思考方式和态度,这是由人的个性本身决定,无法解决,也是不可避免的一个问题,所以面对这种情况怎样进行调节,也是一个需要面对和解决的问题。
环境信息如何实现共享。信息组织的目的无非是存储,而存储又是为了便于检索,已实现资源共享与充分利用。地理位置似乎也实现共享,但是气候信息如何能够实现共享。暂且排除专业性的问题,时效性、可靠性、用户如何利用这些问题怎么得到更好的解决,无疑又是一难题。
这些问题都面临着如何改变和突破的问题,是信息组织在当前ICT环境下面临的新的任务和挑战。
除了上文谈到的信息组织的任务与挑战,我还想谈一下当代信息人的问题。主要是从教育和个人两个方面展开。
教育方面,目前高等院校开设相关专业不够普及,而且各学校对相关专业的信息组织教育存在很大的差异。不仅导致了专业人才的缺失,也造成了人才质量参差不齐,社会公众对专业认可度存在偏差等问题。
个人方面:
ICT的迅猛发展和广泛运用改变了传统的知识媒介和人类的读写基础。新的读写环境要求我们具备新的信息素养,包括信息搜索能力、信息读取能力、信息评估能力、信息组织能力和信息再使用能力等基本能力4。
在新环境的要求下,我们要不断提升自身的信息素养,更好的满足时代的需求。同时作为一名信管人,要加强自身对专业知识的学习和把握,更好的贡献和服务于专业领域。
以上就是我对当前信息组织可能存在的问题的探讨,同时简述了当今的相关专业的教育和相关人才本身的问题。
3、爬虫报告
3.1 Linux云服务器下配置Scrapy并抓取名人名言、热门标签
3.1.1、安装配置流程
远程访问阿里云
手动创建个人文件夹

查看python版本
用pip安装virtualenv
创建venv虚拟环境
pip安装twisted
安装crypotography
安装scraphy
查看scrapy版本

安装成功
3.1.2、配置过程中问题
首先是使用SSH远程登录云服务器时,输入密码无法显示,以为出错,输入检查了几次,仍旧无法输入,然后查看相关文档发现Linux下命令行就是这个样子的。然后进行下一步,创建文件夹。创建后显示成功,但是查看文件夹时显示No such file or directory。于是手动创建文件夹。创建成功。之后在安装其他安装包部分很顺利,没有遇见问题。有四个安装包由于同组有一个人首先进行了安装,组内具有sudo权限的人安装即可,所以没有进行安装,分别是
(1)build-essential: Informational list of build-essential packages;
(2)libssl-dev:是OpenSSL项目实施SSL和TLS加密协议的一部分,用于通过Internet进行安全通信。
(3)libffi-dev:外部函数接口库(开发文件)
(4)python-dev:头文件和Python的静态库(默认)
3.1.3、爬取数据部分
(1)爬取html、激活并进入虚拟目录
本地编写spiders代码并上传
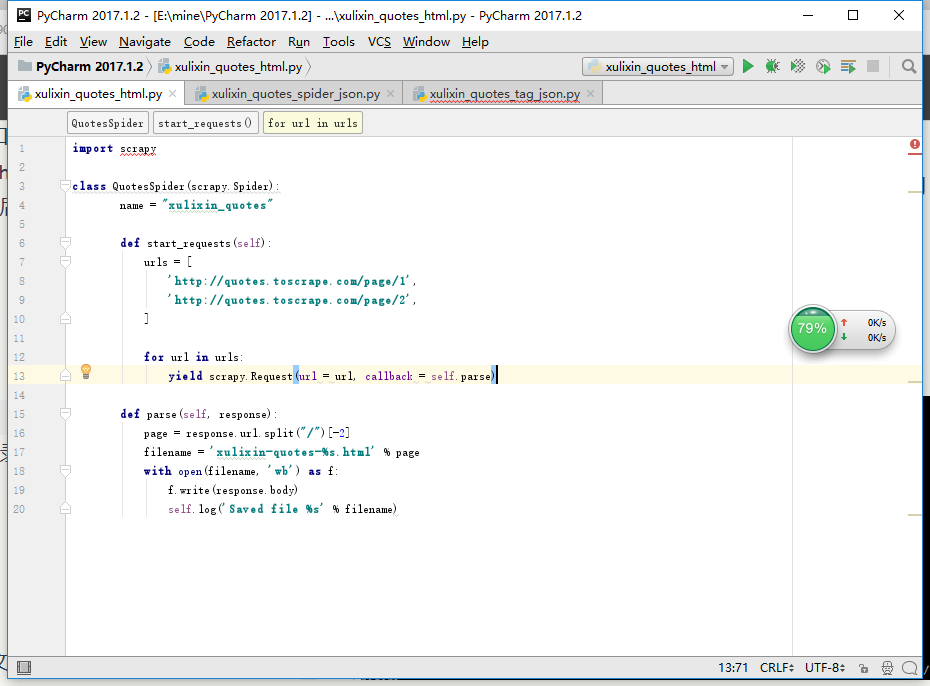
把写好的py文件拖进spiders目录下
开始执行文件
得到html文件
(2)爬取json数据
本地编写spiders代码并上传
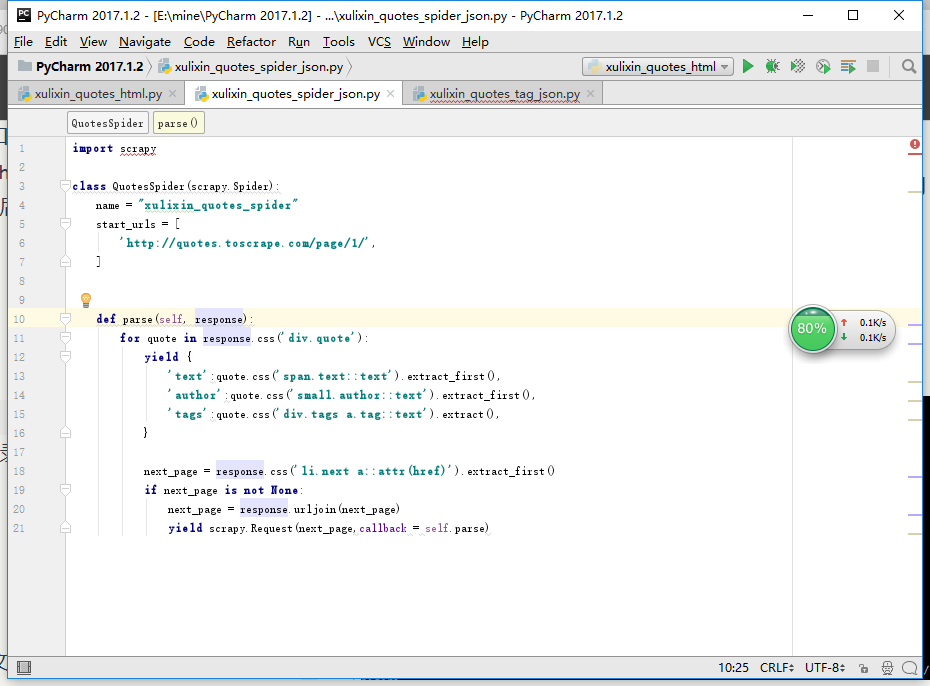
把写好的py文件拖进spiders目录下
执行、保存
(3)爬取热门标签
本地编写spiders代码并上传
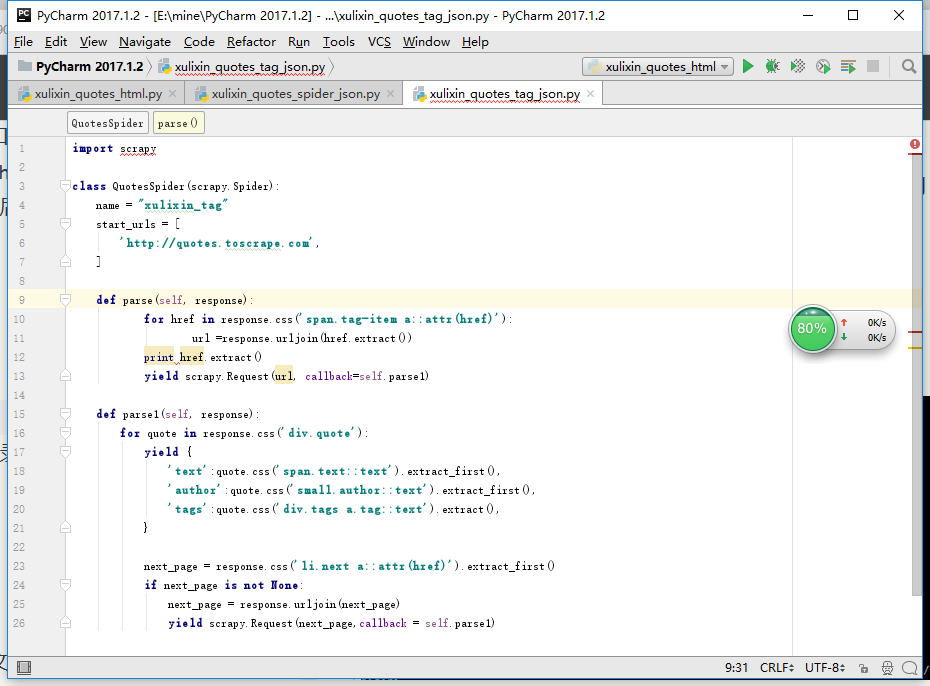
把写好的py文件拖进spiders目录下
激活进入虚拟路径
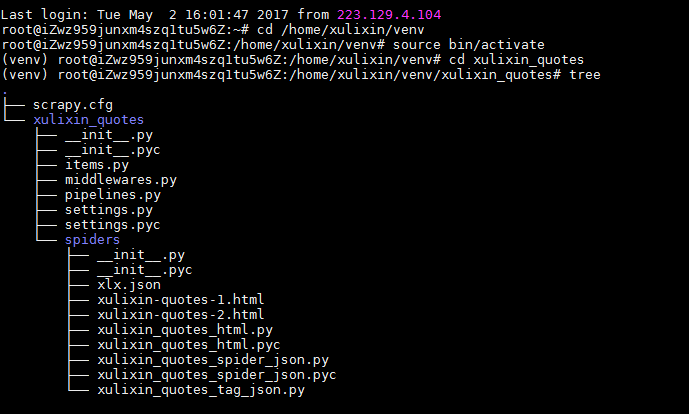
执行操作
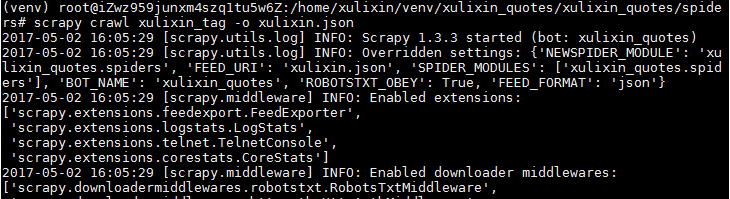
将爬取结果存为xulixin.json文件

爬取完成
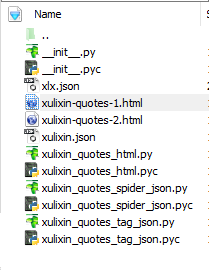
爬取成功后,目录结构
将得到的json文件转化为xml格式,得到xml文件。(xml文件在邮件附件部分)
3.1.4、爬取数据部分问题
爬取数据时在上传py文件部分遇到了问题,没有将文件传入指定位置。拖入了命令行中,导致执行失败,之后看教程将文件传入并执行成功。得到了对应的html文件和json文件。
3.2 聚美优品robots文件解读
3.2.1、全部代码展示
User-agent: *
Disallow: /i/cart/
Disallow: /i/order/list
Disallow: /i/membership
Disallow: /search=*
Allow: /i/deal/deals?filter=-0-0-0
Disallow: /?filter=*
Disallow: /i/deal/deals?filter=*
Allow: //page/?sort=popular_desc
Disallow: /?sort=
Disallow: /*track.php
Disallow: /track_cps.php
Disallow: /redirect=
Disallow: /i/Deal/list_comments
Disallow: /i/deal/list_comments
Disallow: /?site_name=
Disallow: /i/deal/deals?product_id=*
Disallow: /i/deal/mobile_subscribe/?id=*
Disallow: /ltfront.php
Disallow: /i/extconnect/
Disallow: /i/account/jump_to_referer/
Disallow: /i/account/pre_login/
Disallow: /i/account/login/
Disallow: /opt=*
Disallow: /team.php
Disallow: /k/
Disallow: /i/deal/121129.html?from=*
Disallow: /i/deal/121130.html?from=*
Disallow: /i/deal/1212.html?from=*
Disallow: /?referer
Disallow: /?referer=
Disallow:/?refer=
Disallow: /?r=
Disallow: /?utm_source
Disallow: /?utm_source
Disallow: /i/help/*
Disallow: /i/r
3.2.2、特征代码解读
| 代码 | 解读 |
|---|---|
| User-agent: * | 允许所有机器人访问 |
| Disallow: /i/cart/ | 禁止访问客户i的购物车信息 |
| Disallow: /i/order/list | 禁止访问客户i订单下的列表信息 |
| Disallow: /i/membership | 禁止访问客户i的好友列表 |
| Disallow: /search=* | 禁止访问搜索的动态页面 |
| Disallow: /i/deal/deals?filter=* | 禁止访问交易的动态页面 |
| Disallow: /*track.php | 禁止访问交易页面 |
| Disallow: /i/Deal/list_comments | 禁止访问交易的评价列表 |
| Disallow: /i/deal/deals?product_id=* | 禁止访问产品id的动态页面 |
| Disallow: /i/account/login/ | 禁止访问账户登录信息 |
| Allow: /i/deal/deals?filter=-0-0-0 | 允许爬取 |
3.2.3、浅谈商业策略与合作
聚美优品允许所有机器人进行访问,禁止的命令主要包括客户个人隐私信息部分(登陆信息、购物车信息、订单下的列表信息)和商业数据部分(动态搜索页面、交易页面、评价列表)。较好的保护了客户隐私。但是由于同类产品竞争的关系,我认为应该会有相关爬虫被禁止,例如比价相关爬虫。允许爬取部分可以给网站带来客户、增加网站流量。合理禁止相关爬虫和特定网页的爬取可以更好的保护用户信息和相关交易的隐私数据。
3.3 川大公管学院新闻爬取实验报告
3.3.1、分析过程
首先分析爬取入口,从网站结构可以看出,点击首页more进入新闻列表页,需要爬取新闻列表url。点击单个新闻标题进入新闻详情页。需要爬取新闻标题,发布日期,新闻内容,新闻相关图片。
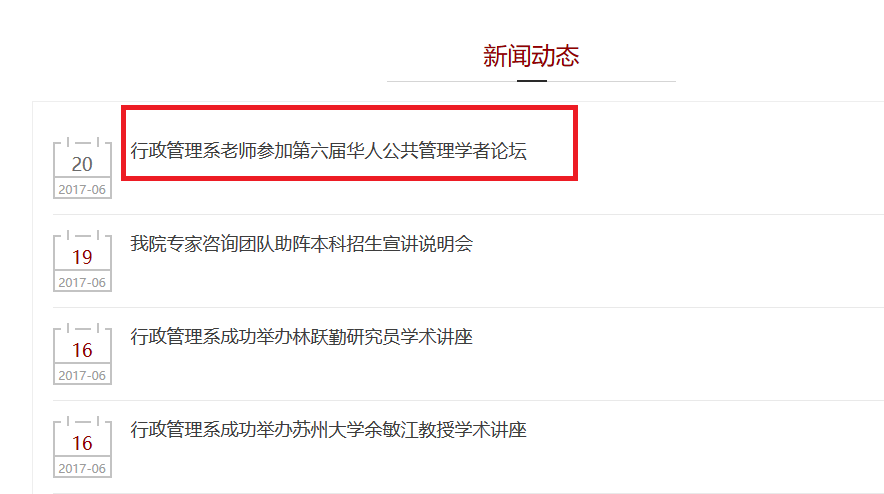
下一页定位与分析
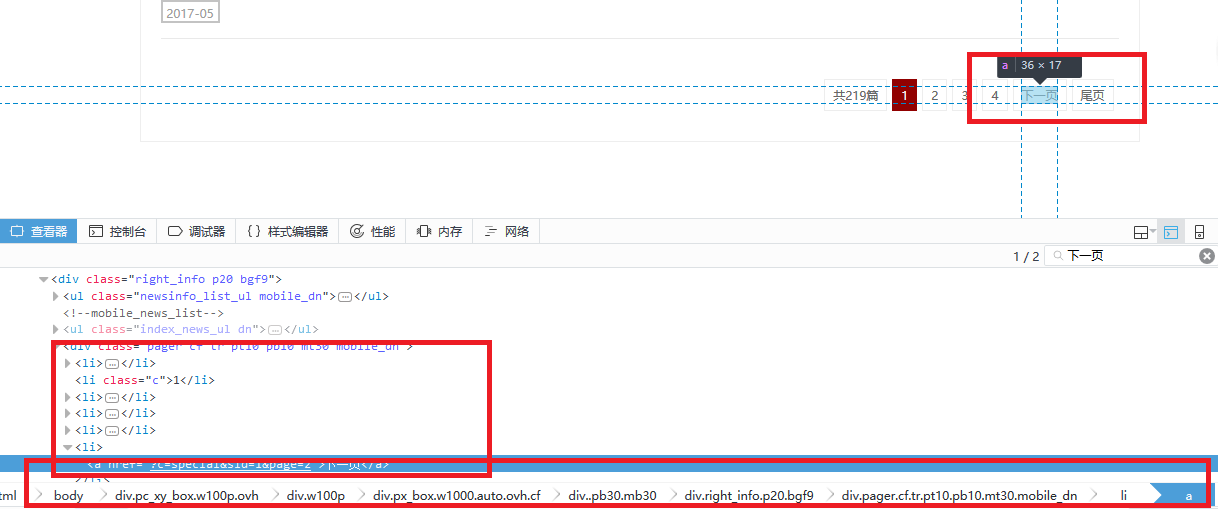
下一页规则
next_page = response.css('div.mobile_pager.dn li.c::text').extract_first()
if next_page is not None:
next_url = int(next_page) + 1
next_urls = '?c=special&sid=1&page=%s' % next_url
print next_urls
next_urls = response.urljoin(next_urls)
yield scrapy.Request(next_urls, callback=self.parse)
3.3.2、抓取内容与规则
title定位
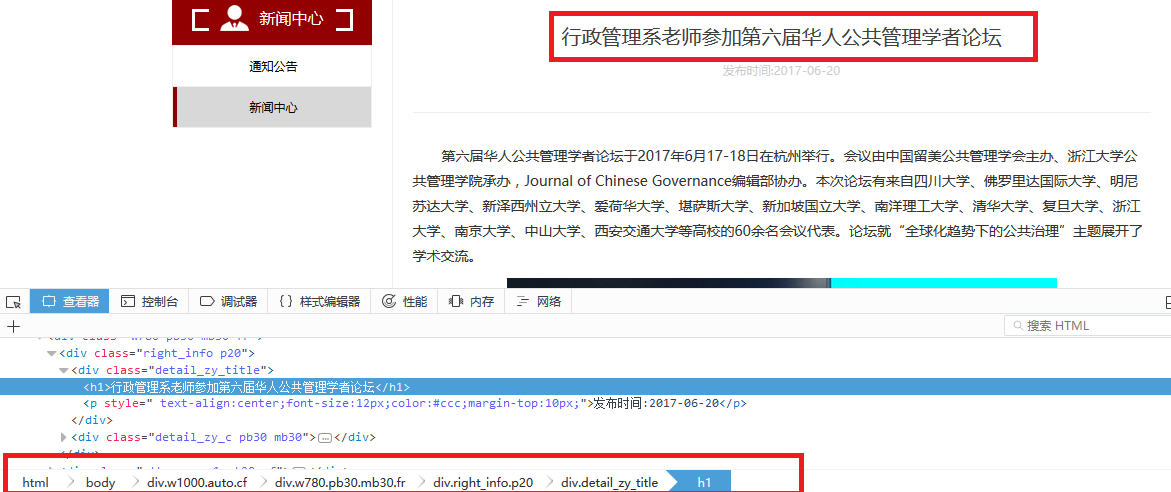
title爬取规则
div.detail_zy_title h1::text
date定位
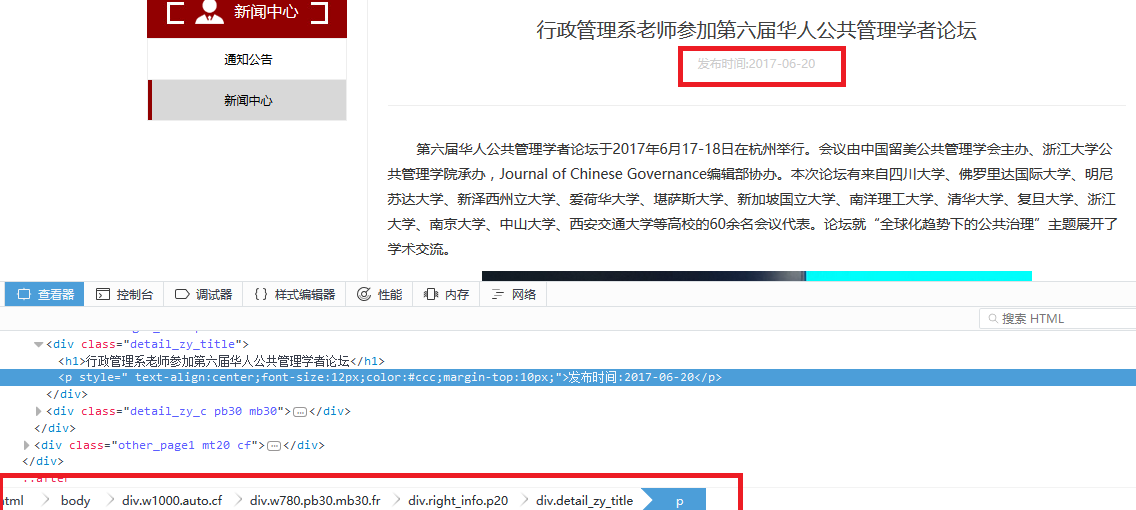
date爬取规则
div.detail_zy_title p::text
content定位
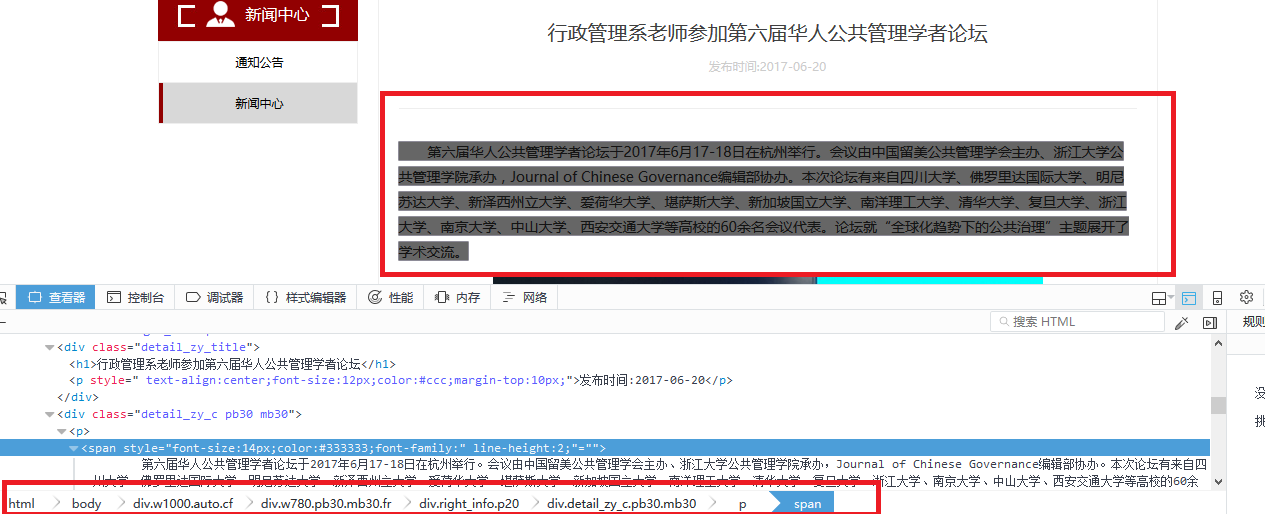
content爬取规则
div.detail_zy_c.pb30.mb30 p span::text
img定位
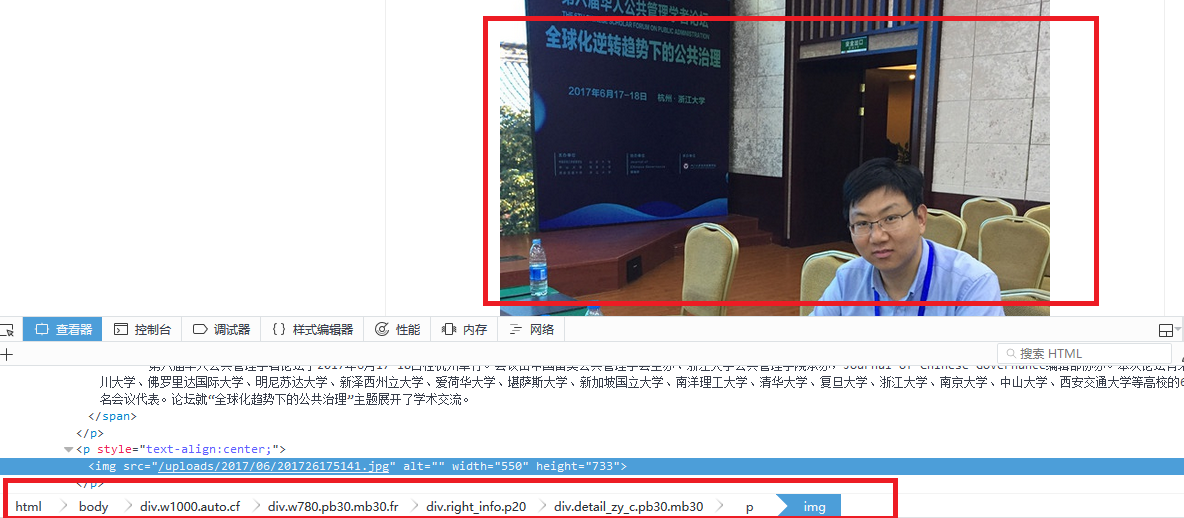
img爬取规则
div.detail_zy_c.pb30.mb30 p img::attr(src)
3.3.3、操作过程

进入虚拟环境并激活,进入工程,查看工程目录结构。最后正确的代码文件是xlx_scu_ggnews.py ,正确的结果文件是xlx_scu_ggnews.xml.其他文件都是过程中摸索的相关的文件。有多少文件就有多少次爬取过程,还不止。有些心塞吧,期间还一直断网。不过最后爬取成功,十分激动。
进入爬虫所在文件,并执行爬虫

爬虫代码
过程页1

过程页2

爬取结果页

爬取结果保存。最终得到川大公管新闻的xml文件。

3.4 八爪鱼使用实验报告(选做)
八爪鱼是一种白痴爬虫软件,任何人都可以使用,任何网站都可以采集,支持云采集和关机采集。使用简单,无需自己编写爬虫程序,采用可视化界面显示采集逻辑,协助用户的采集。
系统完全可视化流程操作,无需专业知识,轻松实现数据采集。通过对网页源码中各个数据XPath路径的精确定位,八爪鱼可以批量化精准采集出用户所需数据。
对于新手而言,可以采用向导模式,采集逻辑是已经设计好了的,只需按照流程一步步操作即可。支持SMART模式,任何表格列表数据类型的网页,爬取时使用SMART模式,只需输入网址,即可直接开始采集数据。非新人可以使用高级模式,自己设计采集流程,采集相对较复杂的网站数据。并且支持XPATH对采集数据进行精准定位。
在我的使用过程中,首先是开启向导模式,理解采集基本操作和流程。使用起来方便简单。向导模式支持采集单个网页数据采集、单个列表页数据采集、单网页表格数据采集、列表及详情采集,URL采集。将全部基本操作执行一遍过后,我对豆瓣中人民的名义的短评和剧评信息进行了采集。其中只要是列表及详情部分信息地采集。
采集流程如下:

打开网址--设计翻页--采集列表设计循环--采集详细页数据
在采集短评的过程中,由于没有登录,采集到180条数据。剧评总共2235条,共采集了442条然后手动终止执行了。短评导出到excel。导出剧评时由于字段长度超过32767字符,故导出到csv。相关结果文件见邮件附件。
除了豆瓣影评的爬取,我还爬取了中国研究生招生信息网各学校各学院各专业的研究方向。初衷是爬取开设管理科学与工程专业的学校,在这个专业上的研究方向。但是管科专业列表和总列表url一致,所以爬取了全部学校全部专业的研究方向。数据量太过庞大(19422条),导出消耗积分过多,所以没有导出数据,相关数据内容截屏如下:

采集流程

首页

尾页
其实第一次接触八爪鱼是在老师初次说思考小组数据爬取问题的时候。那个时候找到八爪鱼和火车头两种爬虫软件。当时试了试八爪鱼,觉得还挺简单实用,这次老师说学习使用一种爬虫软件和工具的时候就想到了当时自己使用八爪鱼的场景,这次也选择了使用八爪鱼软件进行爬取,完成实验报告。
3.5 scrapy爬取神奇女侠实验报告(选做)
笔者之前尝试过豆瓣影评中人民的名义的短评爬取和链家网成都房价信息爬取,由于爬虫被ban,均没有获取爬取结果。后来得知烂番茄这一影评网站,查看robots文件发现允许爬虫爬取数据,所以选择这个网站进行爬取。但是这是一个主要以影评为主的网站,没有找到电视剧人民的名义的短评信息。发现热搜榜排名第一的是刚刚看过的wonder woman 。很感兴趣,所以进行了数据爬取的尝试。
3.5.1、抓取对象分析
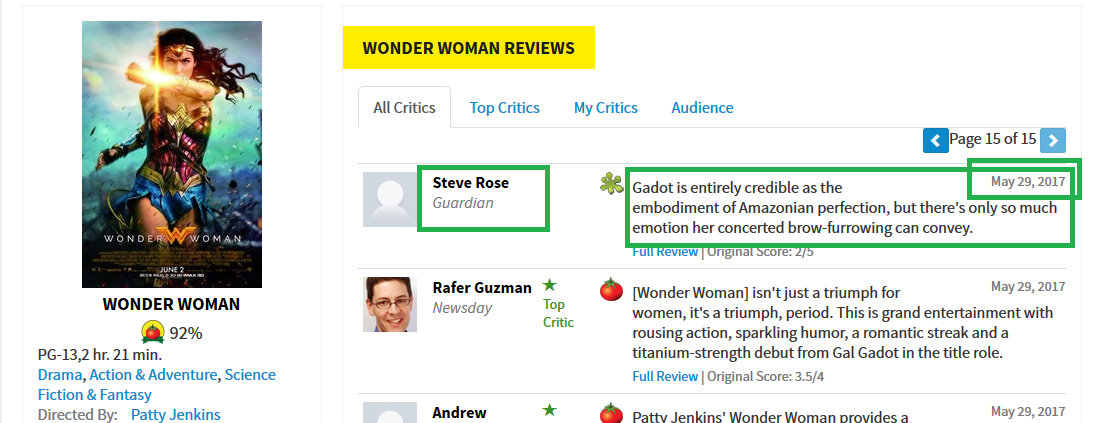
如图中所示,评论人名称name、评论时间date以及评论内容context是我们需要爬取的内容。
3.5.2、HTML定位与抓取规则
name定位
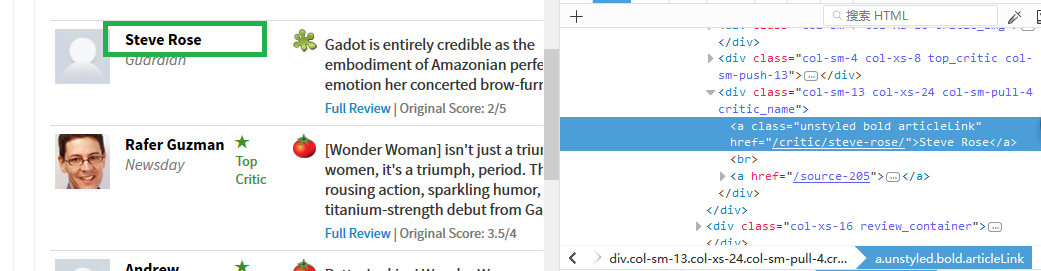
name爬取规则
div.col-xs-8 div.col-sm-13.col-xs-24.col-sm-pull-4.critic_name a.unstyled.bold.articleLink::text
review定位
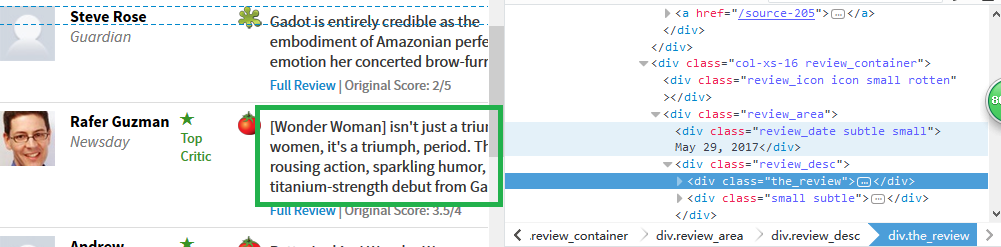
review爬取规则
div.col-xs-16.review_container div.review_area div.review_desc div.the_review::text
date定位
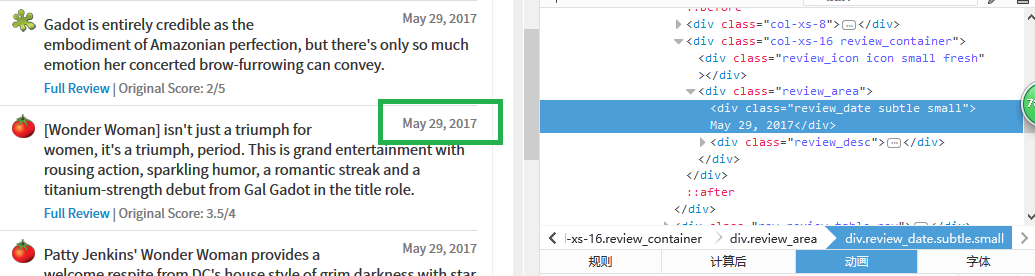
date爬取规则
div.col-xs-16.review_container div.review_area div.review_date.subtle.small::text
下一页问题
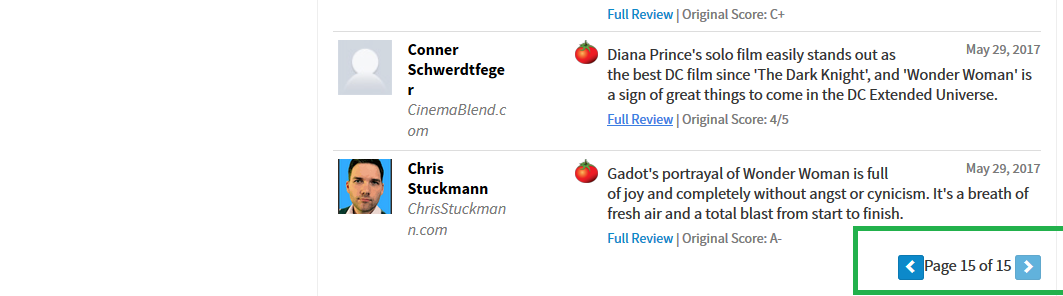
由图可知我们需要爬取的页面总共有15页,
下一页标签如下:

所以我选择的爬取所有页面数据的方式是,将url入口直接定位到第15页,然后根据下一页标签写出下一页规则,规则如下:
next_page = response.css(' div.col.col-center-right.col-full-xs section#content.panel.panel-rt.panel-box div.panel-body.content_body div#reviews div.content div a.btn.btn-xs.btn-primary-rt::attr(href)')
3.5.3、编写爬虫
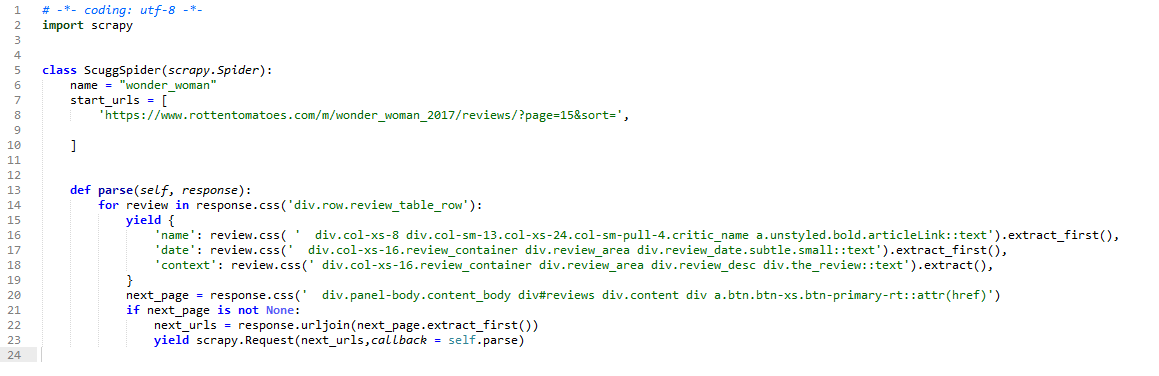
3.5.4、数据获取
爬取结果页如下:
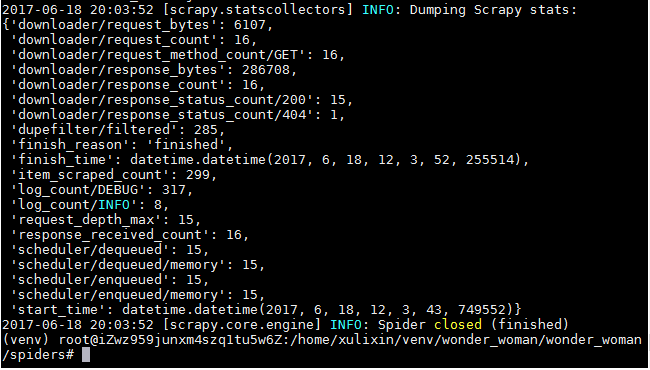
如图共爬取到299条数据,总共15页。具体结果如下:
第一页

最后一页

4、分词报告
4.1 分词工具包调研与使用报告(选做)
4.1.1、什么是分词
中文分词指的是将一个汉字序列切分成一个一个单独的词。分词就是将连续的字序列按照一定的规范重新组合成词序列的过程。中文只是字、句和段能通过明显的分界符来简单划界,但是词没有一个形式上的分界符,很难划分。
4.1.2、实现分词的技术与算法
(1)分词技术
分词技术就是搜索引擎针对用户提交查询的关键词串进行的查询处理后根据用户的关键词串用各种匹配方法进行分词的一种技术。
根据查找资料发现,目前主要有常见的分词技术。字符串匹配、词义分词和统计分词。
1、字符串匹配分词方法
作为最常见的匹配算法,又有四种分词方式。
(1)正向最大匹配法:从左到右实现分词。
(2)反向最大匹配法:从右至左实现分词。
(3)最短路径分词法:一段话里面要求切出的词数是最少的。
(4)双向最大匹配法:关键词前后组合内容被认为粘性相差不大,而搜索结果中也同时包含这两组词的话,进行正反向同时进行分词匹配。
2、词义分词法
机器进行句法、语义分析,利用句法信息和语义信息来处理歧义现象来分词。这种分词方法还不成熟,处在测试阶段。
3、统计分词法
根据词组进行统计,找出两个相邻的字出现的频率多的词,作为用户提供字符串中的分隔符。
4.1.3、现有分词工具的使用结果展示与分析
输入的文本

(一)BosonNLP
词性分析

实体识别

情感分析

新闻摘要

新闻分类

关键词提取

小结:功能齐全,分词比较准确。在该段文本的分词结果中,专有名词“一瓣科技”和动词“意愿”没有被分出来。实体识别、新闻摘要、关键词提取结果比较准确。新闻分类在现有的分类系统中的结果也是正确的,但是系统本身分类太过于宽泛。推测是正向字符匹配算法。
(二)NLPIR
分词标注

实体抽取

词频统计

文本分类

情感分析

关键词提取

摘要提取

小结:除了展示的功能外,还有敏感词提取与地图的可视化功能。由于输入文本内容的原因,这段文本没有提取到相关信息。在以上的结果中,分词时将分出来的词做了词性标注,这是和第一个不相同的地方,但是就分词总体效果而言,不如第一款分词那么准确。“想要”“打造”“旅游委”等都没有分出来。并且所属分类不太准确,摘要提取部分将文本全部提出来,没有进行分析。总体优势是呈现效果更加多元,并且可视性强,让人一目了然。另外词频统计功能第一款没有,这里给出了比较准确的词频统计结果。
4.1.4、主观比较与使用感受
两种分词工具都具有较好的分词功能,就准确程度而言,第一种BosonNLP主观感受更准确。第二种NLPIR结果呈现形式更为直观。关键词以字体大小和颜色区分重要程度和相关程度,较于第一种的列表罗列更为直观。实体抽取结果也是如此。能够很清晰的看出有哪几个实体,每个实体相关的分词结果是什么。两种分词工具功能都比较齐全,支持摘要提取、 类别提取、情感分析、关键词提取、实体抽取等。
4.1.5、典型分词工具的结果准确度比较(来源于资料)


以上是主流分词工具在爬取新闻数据、微博数据、汽车论坛、餐饮点评信息时的准确的比较。可以看出BosonNLP工具在爬取这四种类型的数据时,准确程度都是最高的。语言云次之。NLPIR更适合新闻数据、微博数据的爬取。结巴分词更适合汽车论坛、餐饮点评类数据的爬取。
新闻数据:用词规整,符合语法规则。
微博数据:用词多样、话题广泛,并常包含错别字及网络流行词。
汽车数据:针对汽车领域的专业评价数据,会出现很多的专业术语。
餐饮点评数据:顾客评论数据,更偏重口语化和很多不规范的表达,使分词更加困难。
不同的文本内容具有不同的词法、词源特点。在选择分词工具时我们应选择更适合自己项目数据本身的分词工具。就我们组所在的项目苍蝇馆子而言,就很类似于最后一种餐饮点评类数据。这次作业也给了我们小组一个启示。
4.2 中文分词实验报告--基于mmseg4j
4.2.1、认识中文分词包(mmseg4j)(下载、安装与运行)
1 简介
mmseg是蔡志浩(Chih-HaoTsai)提出的基于字符串匹配(亦称基于词典)的中文分词算法。基于单纯的最大匹配无法完美地解决歧义这一问题,MMSeg在正向最大匹配的基础上设计了四个启发式规则。
2 算法
MMSeg的字符串匹配算法分为两种:
(1)Simple,简单的正向最大匹配,即按能匹配上的最长词做切分;
(2)Complex,在正向最大匹配的基础上,考虑相邻词的词长,设计了四个去歧义规则(Ambiguity Resolution Rules)指导分词。如下:
在complex分词算法中,MMSeg将切分的相邻三个词作为词块(chunk),应用如下四个消歧义规则:
1、备选词块的长度最大(Maximum matching),即三个词的词长之和最大;
2、备选词块的平均词长最大(Largest average word length),即要求词长分布尽可能均匀;
3、备选词块的词长变化最小(Smallest variance of word lengths );
4、备选词块中(若有)单字的出现词自由度最高(Largest sum of degree of morphemic freedom of one-character words)。
3 运行
(1)下载
(2)检查java环境
输入java -version
输入javac
4 运行mmseg4j-core-1.10.0.jar
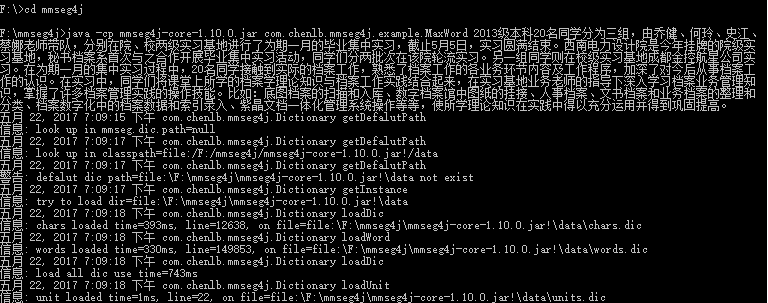
可以看到分词结果,如下:

4.2.2、分词方法与效果分析
1 分词文本
2013级本科20名同学分为三组,由乔健、何玲、史江、蔡娜老师带队,分别在院、校两级实习基地进行了为期一月的毕业集中实习,截止5月5日,实习圆满结束。西南电力设计院是今年挂牌的院级实习基地,秘书档案系首次与之合作开展毕业集中实习活动,同学们分两批次在该院轮流实习。另一组同学则在校级实习基地成都金控航星公司实习。在为期一月的集中实习过程中,20名同学接触到实际的档案工作,熟悉了档案工作的各业务环节内容及工作程序,加深了对今后从事档案工作的认识。在实习中,同学们将课堂上所学的档案学理论知识与档案工作实践结合起来,在实习基地业务老师的指导下深入学习档案业务管理知识,掌握了许多档案管理实践的操作技能。比如:底图档案的扫描和入库、数字档案馆中图纸的挂接、人事档案、文书档案和业务档案的整理和分类、档案数字化中的档案数据和索引录入、紫晶文档一体化管理系统操作等等,使所学理论知识在实践中得以充分运用并得到巩固提高。
2 分词方法结果比较
(1)complex方法
分词结果:
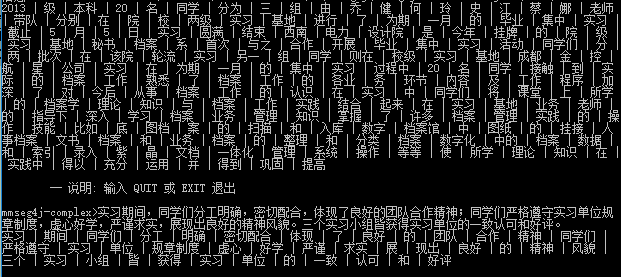
统计分析
| 文本 | 错误分词结果 | 类型 |
|---|---|---|
| 乔建 | 乔/建 | 人名 |
| 何玲 | 何/玲 | 人名 |
| 史江 | 史/江 | 人名 |
| 蔡娜 | 蔡/娜 | 人名 |
| 西南电力设计院 | 西南/电力/设计院 | 专有名词 |
| 秘书档案系 | 秘书/档案/系 | 系名 |
| 成都金控航星公司 | 成都/金/控/航/星/公司 | 公司名 |
| 各/业务/环节 | 各业/务/环节 | |
| 底图档案 | 底/图档/案 | 专有名词 |
| 紫晶文档 | 紫/晶/文档 | 专有名词 |
共10次错误,绝大多数是人名和专有名词。
(2)simple方法
分词结果:

统计分析
| 文本 | 错误分词结果 | 类型 |
|---|---|---|
| 乔建 | 乔/建 | 人名 |
| 何玲 | 何/玲 | 人名 |
| 史江 | 史/江 | 人名 |
| 蔡娜 | 蔡/娜 | 人名 |
| 西南电力设计院 | 西南/电力/设计院 | 专有名词 |
| 秘书档案系 | 秘书/档案/系 | 系名 |
| 成都金控航星公司 | 成都/金控/航星/公司 | 公司名 |
| 各/业务/环节 | 各业/务/环节 | |
| 底图档案 | 底/图档/案 | 专有名词 |
| 紫晶文档 | 紫/晶/文档 | 专有名词 |
也是10次错误,分词结果和complex大体相同。公司名称分词结果有差异。
4.2.3、分词结果提交
1 转换为纯文本类型
使用tika将上次得到的新闻xml文件转化为纯文本格式,保存在c盘
4.2.4、基于分词结果的词云分析(词频统计+可视化)
1 词云

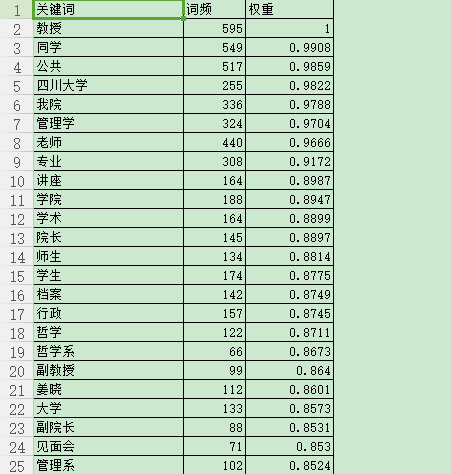
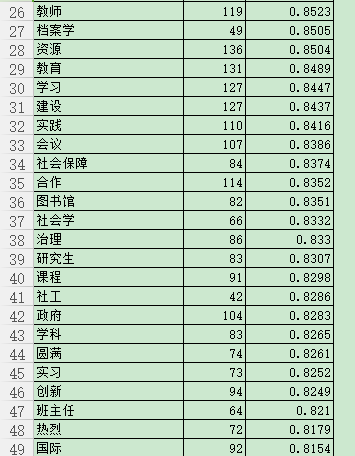
2 词频统计
在此展示结果前两页
页面1
页面2
5、文本解析报告
5.1 Apache Tika使用实验报告(选做)
5.1.1、配置Apache Tika运行环境
首先验证java环境
输入java -version

输入javac显示javac不是内部或外部命令
所以重新设置了环境变量,设置完成后,验证通过,如下:
输入javac

输入java

下载Tika的源代码和tika的jar包
在cmd中打开GUI图形界面

打开如下

5.1.2、用GUI可视化界面进行文件格式转换
编写一个二进制文件tika.txt,

放入C:根目录
显示客户端无授权,操作如下:

将该文件直接拖入gui,显示如下:

将该文件解析成Formatted Text格式

将文件解析成Plain text格式

将文件解析成json格式

5.1.3、命令行使用Tika
查看tika命令行基本参数


编写一个doc文件

使用命令将doc文件解析为text格式

5.1.4、java工程中使用Tika(eclipse)
在eclipse中新建java项目TikaTest,导入tika-app-1.14.jar

导入后如下

编写test.java文件,文件如下:


运行该程序,结果如下:


成功执行。
6、索引报告
6.1 windows下Luke索引实验报告
6.1.1、简介
Luke是一个用于Lucene搜索引擎的,方便开发和诊断的第三方工具,它可以访问现有Lucene的索引,并允许您显示和修改。
6.1.2、主要功能
浏览文件编号
查看文件/复制到剪贴板
检索条件的最常见的排名名单
执行搜索和浏览结果
搜寻结果分析
有选择地从索引中删除文件
重构原始文档,修改并重新插入到索引
优化索引
6.1.3、Luke下载
官方下载地址:https://github.com/DmitryKey/luke/releases
笔者使用的是Luke-6.3.0.
6.1.4、Luke使用
双击luke-with-deps 打开
打开后可导入索引文件,找到本地内索引文件,进行导入
导入成功后显示如下:
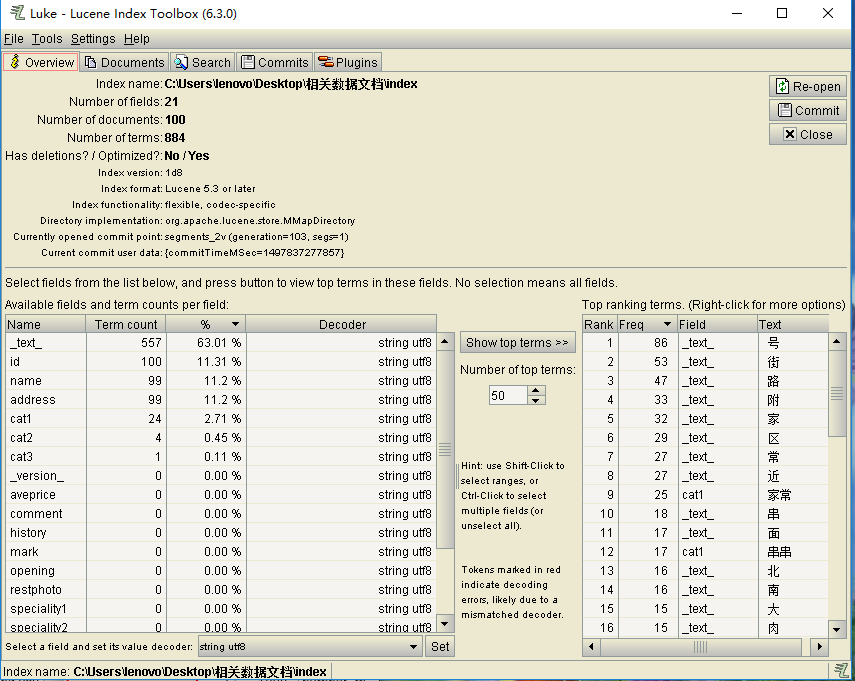
导入成功后则默认在overview选项卡,该选项卡下主要由三部分构成,上部分显示了Document,Field,Term的统计信息,上图中显示的有100个Document,21个Field,884个Term;下部分左侧显示了所有的Field,以及每个Field下的分词个数,每个Field的出现频率,每个Field的编码格式。下部分右侧显示的则是详细信息,按照出现频率进行排名,显示了每个Field的分词文本。
Documents选项卡
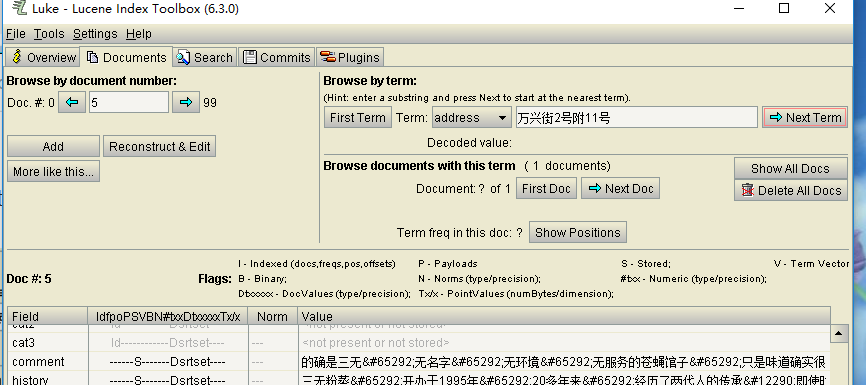
可以用来增删文档,也可以用来通过编号查找记录,并可以显示该记录的详细信息,如下查找第5条记录,显示的信息如图:
点击Recoonstruct&Edit可以查看和更改当前Document的值与属性。如下:
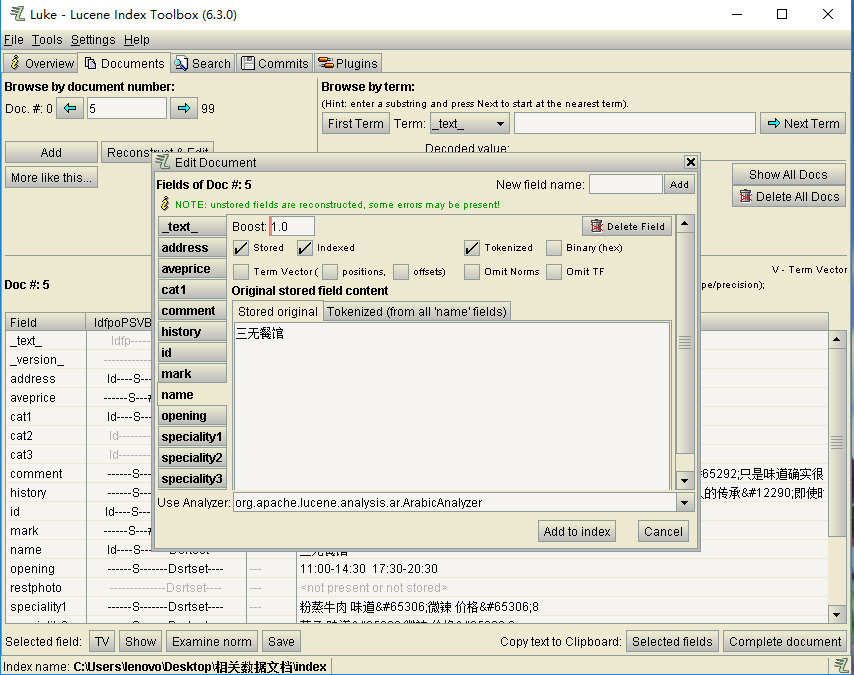
也可以查看Field的值,如下所示:
search选项卡
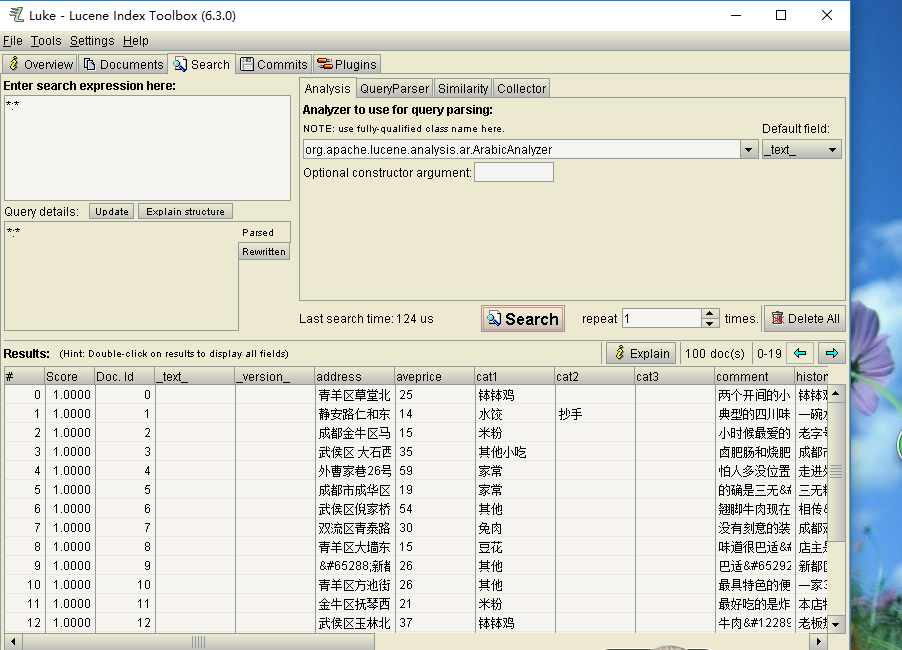
搜索选项卡,可以进行匹配查询,如下:
commits选项卡
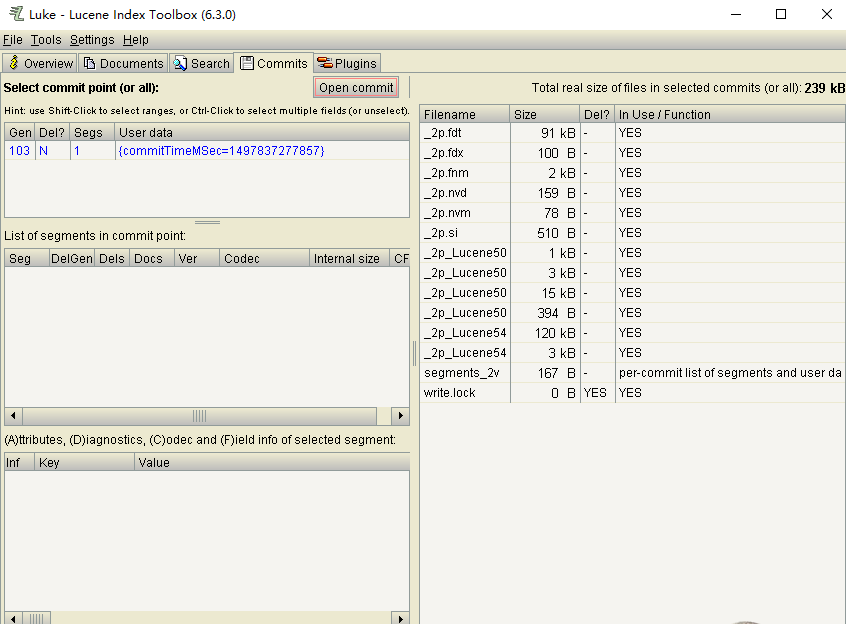
可以查看每个索引的名称,大小等信息,以供索引分析,
Plugins选项卡
可以将文本进行分词,并且有多种分词方法可以选择,如下:
Scripting Luke提供了一个JavaScript的交互式Shell,如下:
关于Vocabulary Analysisi Tool
关于Zipf distribution
将索引导出为xml格式。
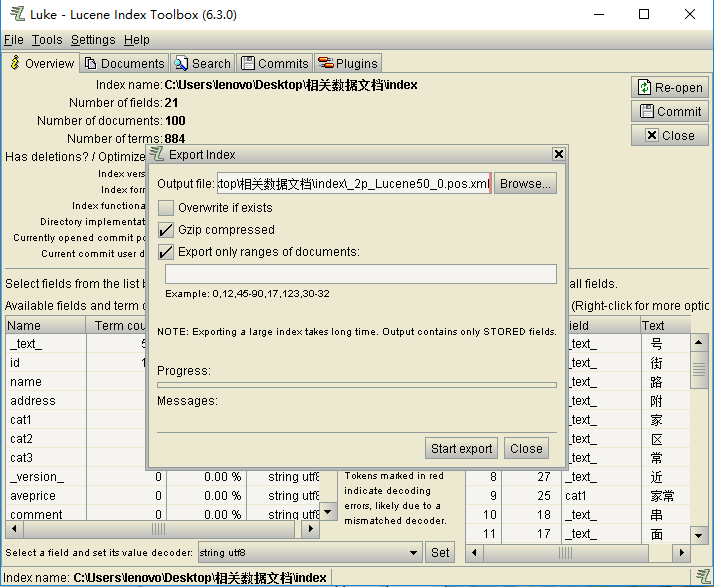
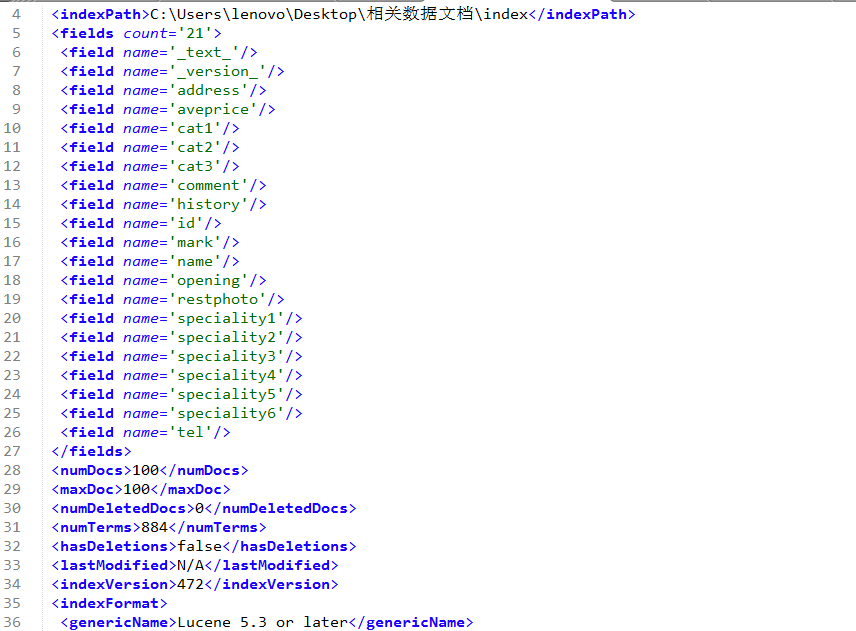
导出后内容

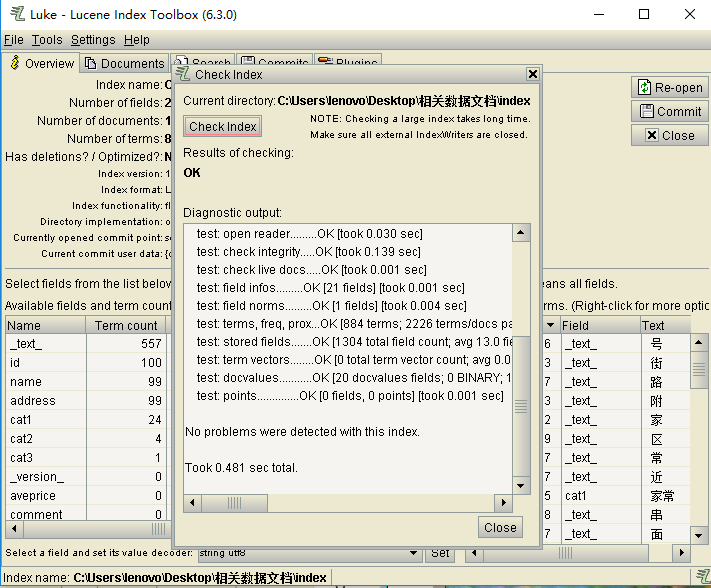
检查索引正确性
Tools->check Index Tool进行索引检查
6.1.5、总结
Luke可以实现对索引的分词,可以对分词结果进行优化,显示详细索引信息,还可通过可视化界面显示词频信息,流行度统计。
7、查询报告
7.1 Query索引实验报告
7.1.1、techproducts示例相关查询
本文的实验环境是solr搜索服务器(阿里云服务器)+本地solr-6.3.0分析环境.
首先通过命令行进入本地solr,然后启动示例techproducts
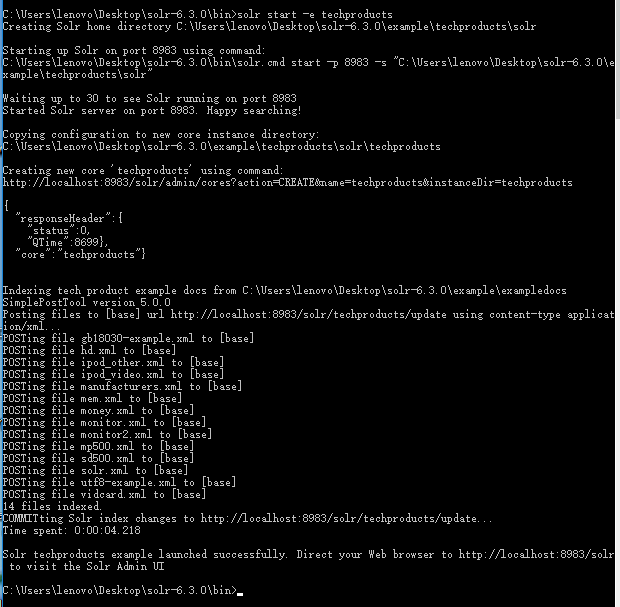
启动后如下显示
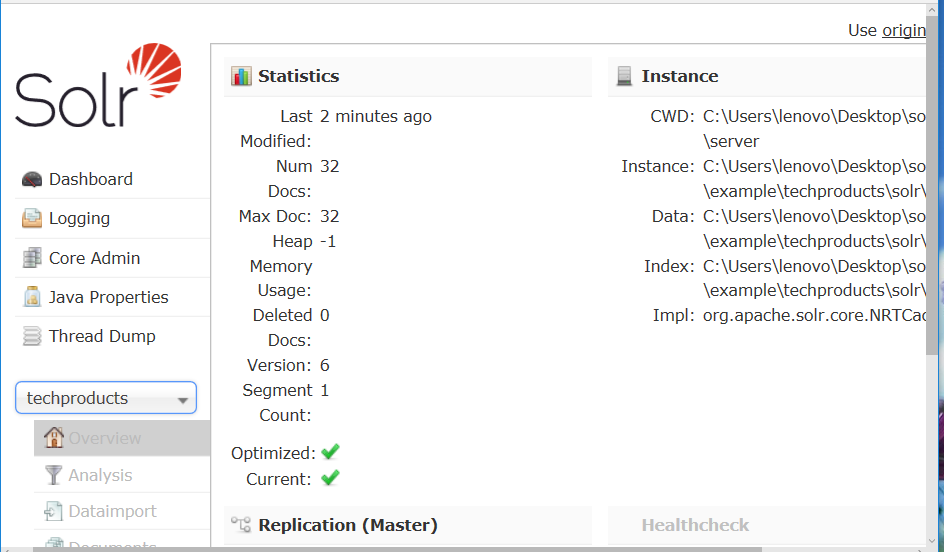
选择的core是techproducts。
然后可以进行query查询,得到查询的相应结果。
(1)
搜索流行度为5及以上的产品,结果按照inStock降序,在按照price升序,每页显示5个结果分页,结果内容包括name,price,features,popularity,结果为json格式。
流行度5及以上 popularity:[5 TO *]
升降序部分 inStock desc,price asc
分页部分 5
结果条目即fl部分 name,price,features,popularity
输出格式 json
url为:
http://localhost:8983/solr/techproducts/select?fl=name,price,features,popularity&fq=popularity:[5 TO *]&indent=on&q=iPod&rows=5&sort=inStock desc,price asc&wt=json
查询结果为

(2)
搜索价格在400以下且有库存的商品,popularity降序排列,搜索结果为name,price,features,score,json格式
价格400以下 price:[0 TO 400]
有库存 inStock:[0 TO *]
欢迎程度降序 popularity desc
url为
http://localhost:8983/solr/techproducts/select?fl=name,price,features,score&fq=inStock:[0 TO *]&fq=price:[0 TO 400]&indent=on&q=iPod&sort=popularity desc&wt=json
查询结果为
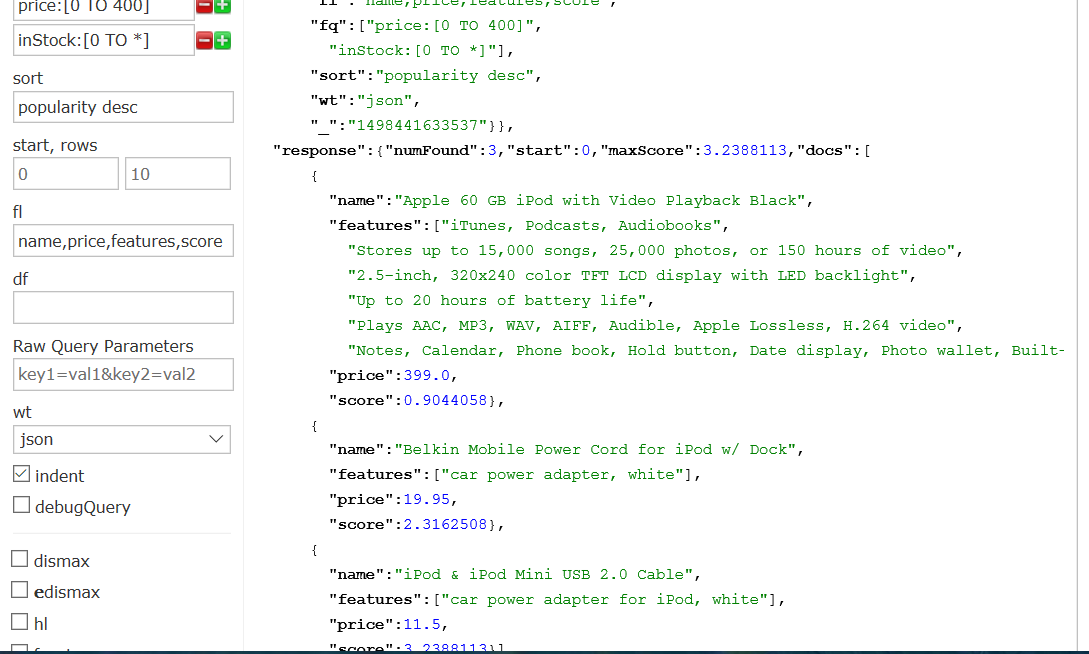
(3)
搜索制造商为Belkin的iPod部件,价格升序,返回结果为name,price,features,xml格式
manu=Belkin
price asc
url为
查询结果为
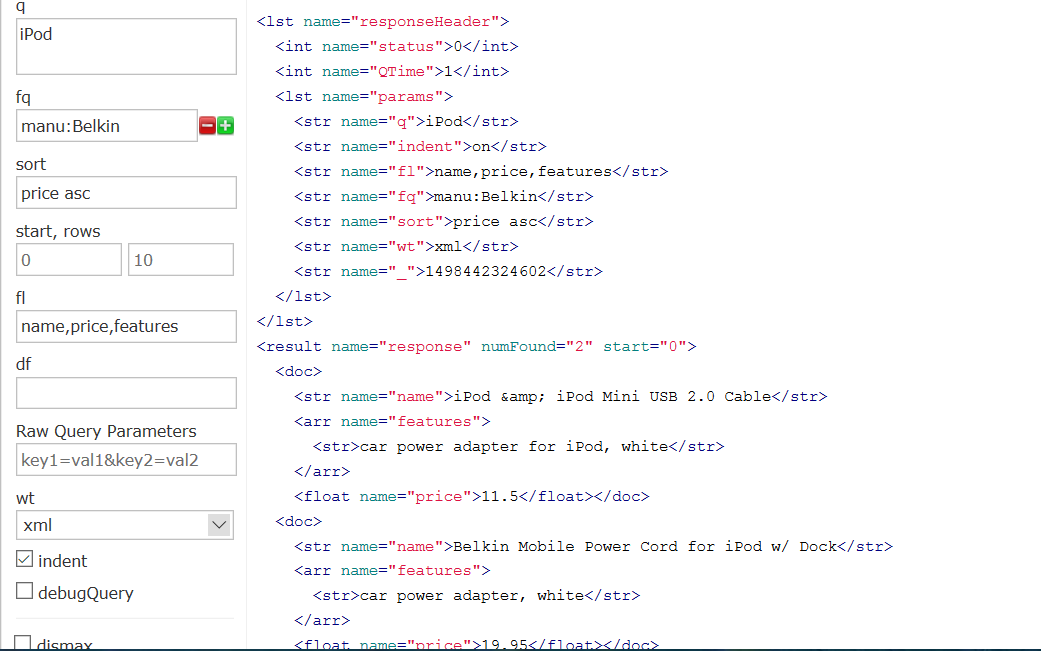
(4)
特征features字段中搜索“plays”,高亮,返回xml格式。
url为
http://localhost:8983/solr/techproducts/select?fq=features=plays&hl=on&indent=on&q=iPod&wt=xml
查询结果为
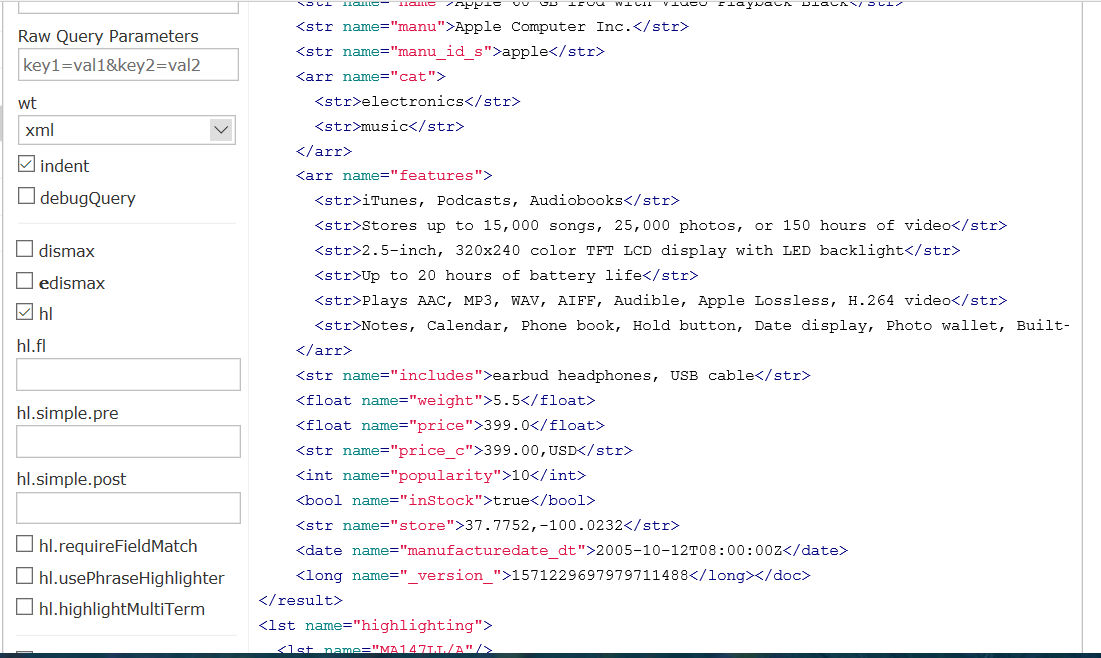
(5)
查询electronics有多少有货,多少没货。
url为
查询结果为:
如图显示每个部件名称及是否有货。
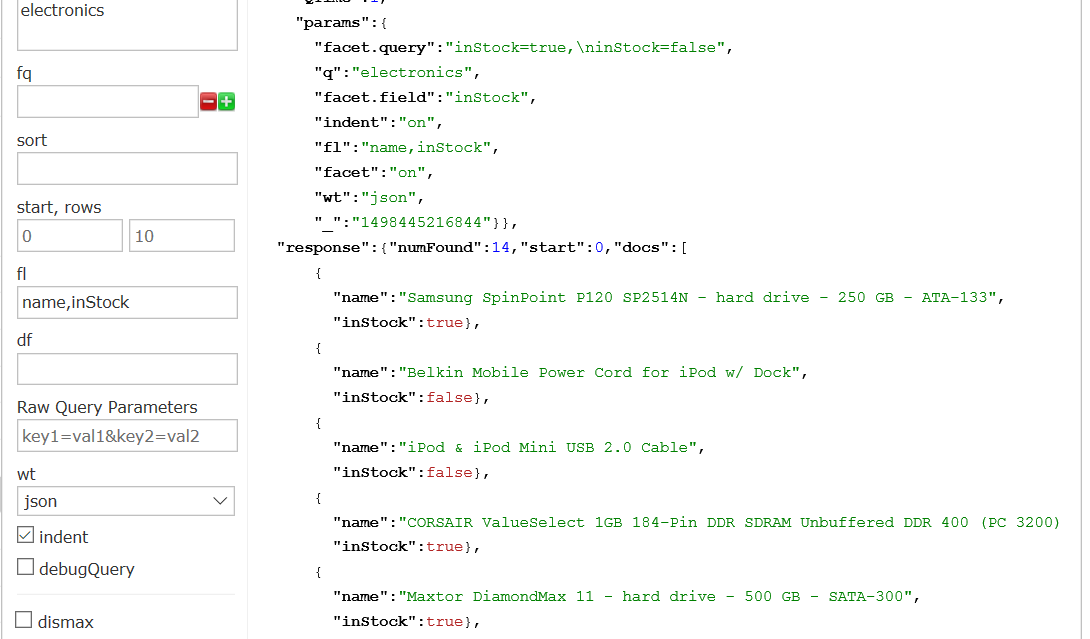
如图给出库存统计信息:
inStock true 10
inStock false 4

(6)
搜索价格为0-300,300-600,600以上的商品,按照cat进行分类,搜索结果显示name,price,manu,返回json数据。
通过Luke可视化界面我们可以看到cat记录16条,如下
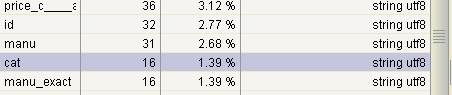
共有两个类型electronics(12条)和currency(4条),如下:


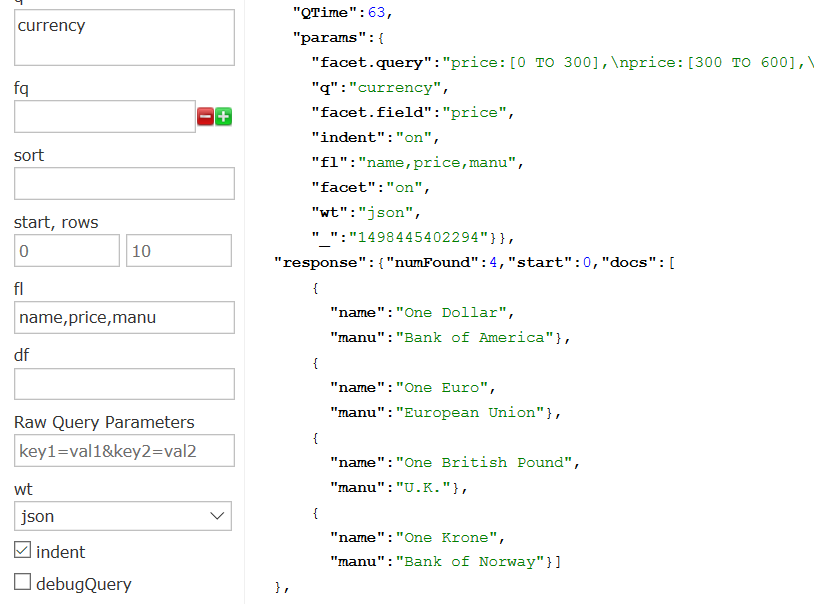
所以我构造了两个查询,第一个指定cat为currency,url为
http://localhost:8983/solr/techproducts/select?facet.field=price&facet.query=price:[0 TO 300],price:[300 TO 600],price:[600 TO *]&facet=on&fl=name,price,manu&indent=on&q=currency&wt=json
返回结果为
第二个指定cat为electronics,url为
http://localhost:8983/solr/techproducts/select?facet.field=price&facet.query=price:[0 TO 300],price:[300 TO 600],price:[600 TO *]&facet=on&fl=name,price,manu&indent=on&q=electronics&wt=json
返回结果为


如图我们可以看到每个价格出现的次数。
7.1.2、 movie与films相关查询
(1)创建内核导入索引
创建movie内核
熟悉Documents字段内容。
创建films内核
通过schema API 方式新增字段name和initial_release_date,如下方式添加:
添加成功后如下显示
导入json格式的films数据
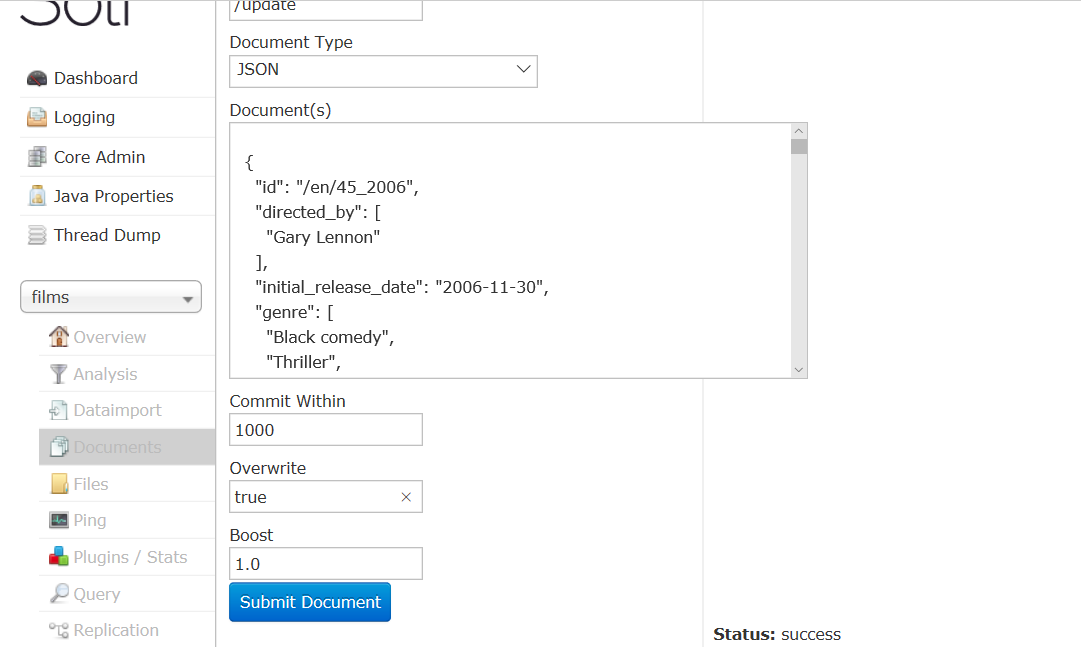
导入后生成如下索引
将索引导入luke
导入成功后显示如下
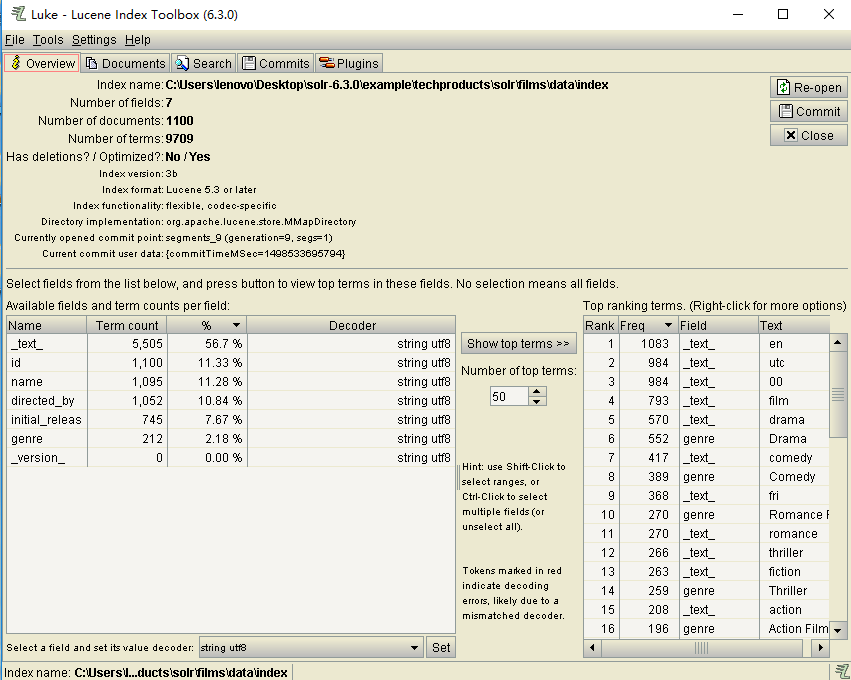
可看出每个字段的词频,百分比,编码格式。还可以看出索引中有7个fields,1100个documents,9709个terms。
(2)相关查询
查找所有Super hero的电影
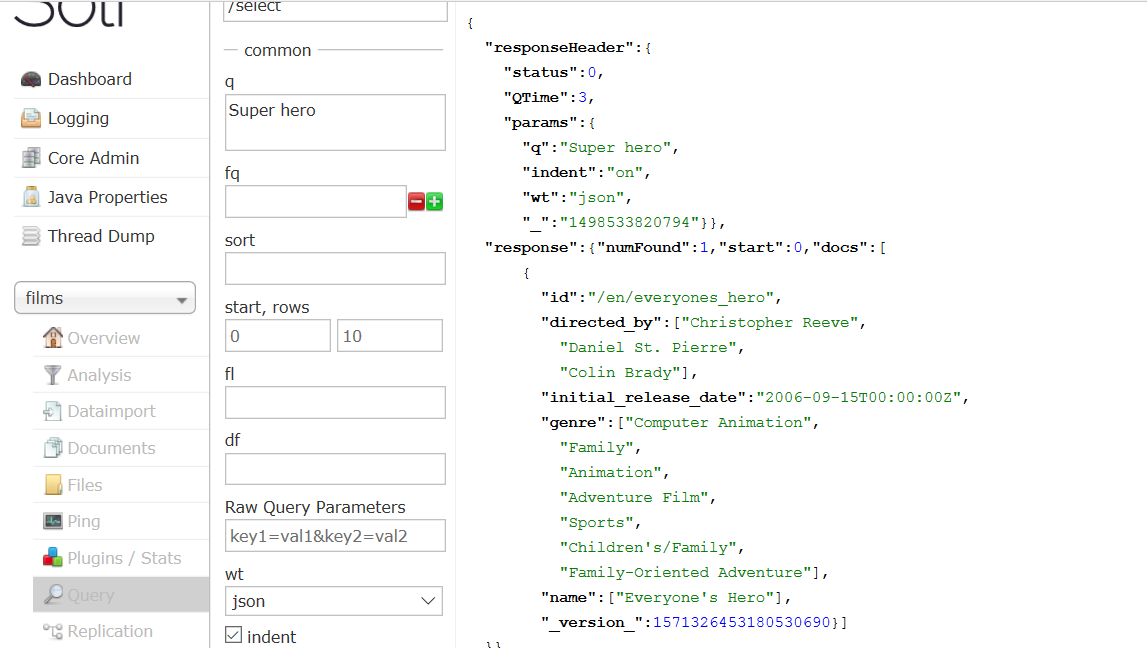
url为
http://localhost:8983/solr/films/select?indent=on&q=Super hero&wt=json
返回一条记录。
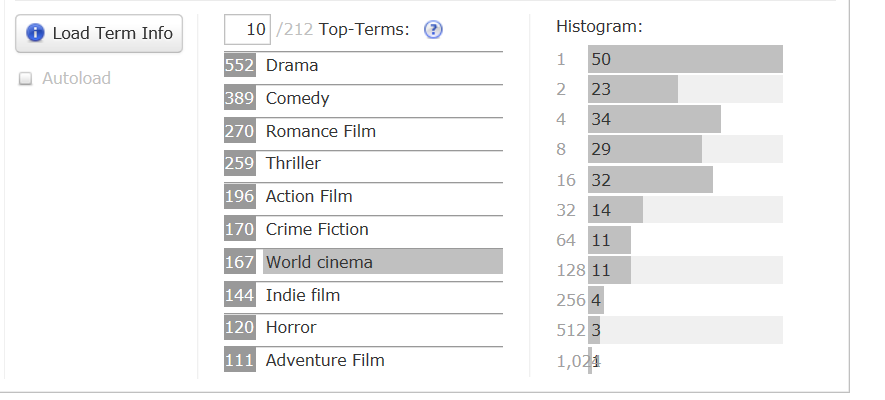
统计各流派电影的数量
如图,Field选择genre,
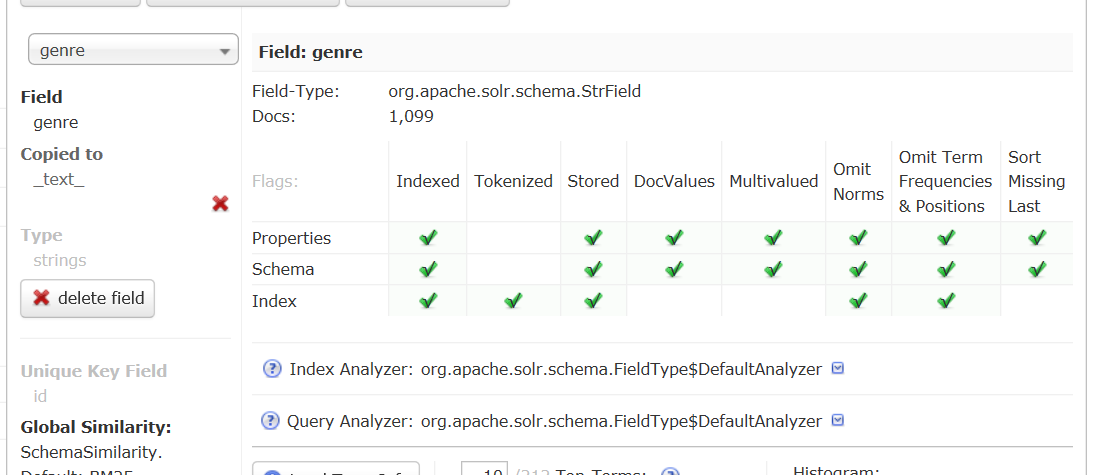
然后会显示各流派电影数量
也可以使用分类查询
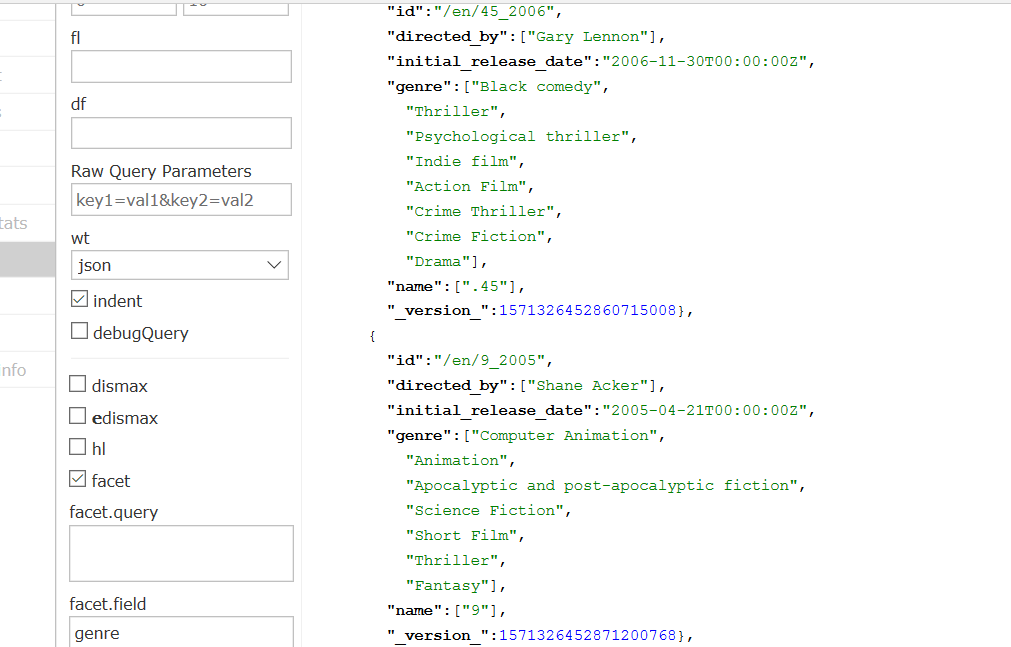
url为
http://localhost:8983/solr/#/films/query?q=%7B!term%20f%3Dgenre%7DAdventure%20Film
具体结果如下:





另外也可以单个流派进行查询,查看返回结果,如下
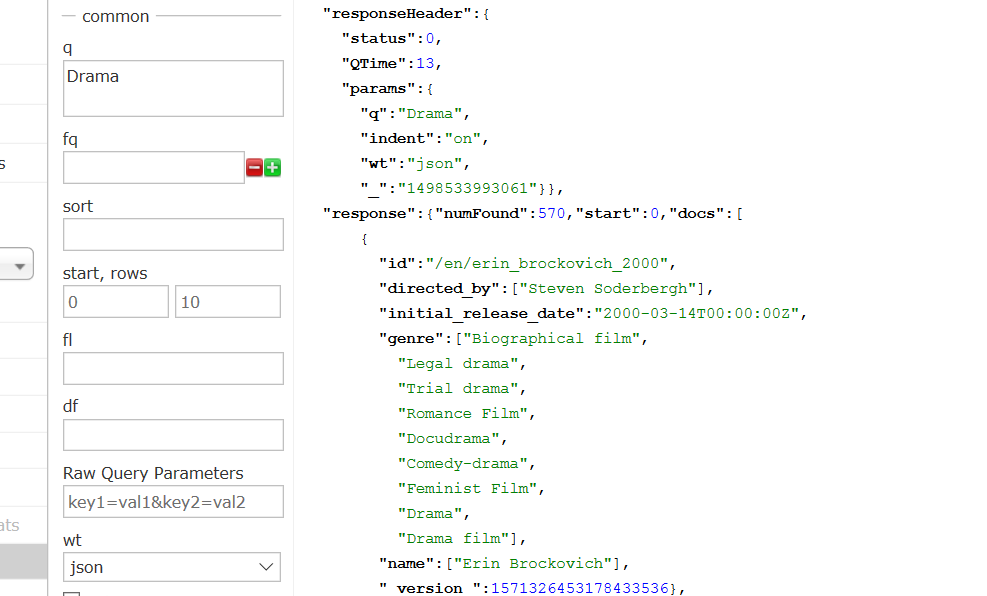
如图Drama 570条,与之前结果一致。
还可以通过Luke进行查询,如下
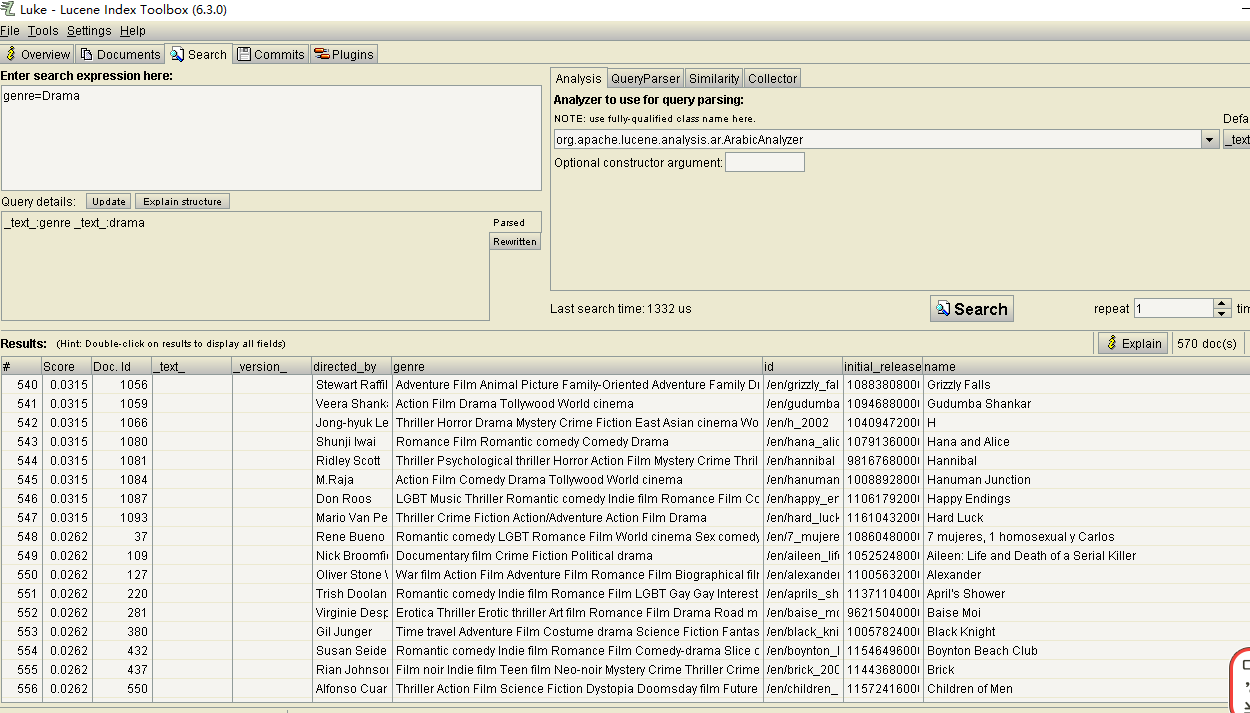
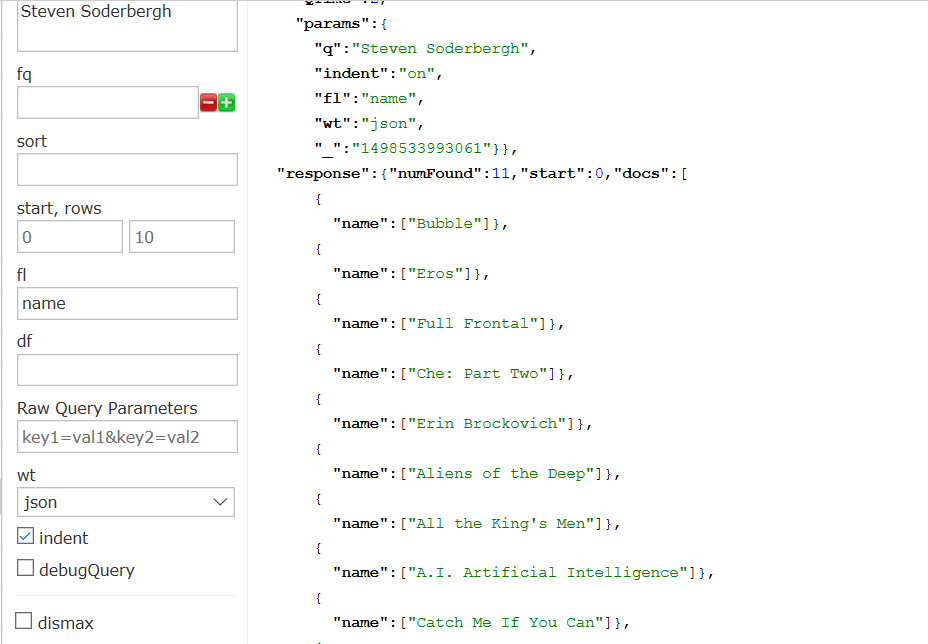
自建查询,查询Steven Soderbergh导演的电影,
url为
http://localhost:8983/solr/films/select?fl=name&indent=on&q=Steven Soderbergh&wt=json
返回结果为:
显示films简单搜索界面,如下:
7.1.3、新建内核实现中文索引
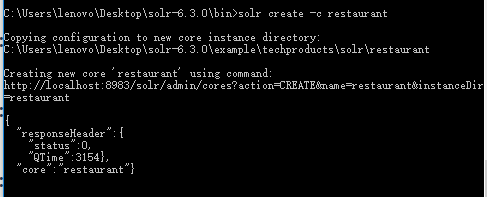
(1)新建内核restaurant,如下:
(2)配置mmseg4j
配置mmseg4j中文分词包,首先将如下两个jar包导入文件夹,jar包和文件路径如下显示:


在solr-6.3.0/server/solr下新建文件my_dic,并在managed-schema中添加如下代码:

显示如下:
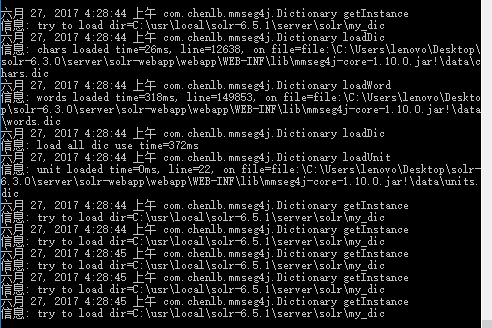

可以对中文进行分词,分词包配置成功。
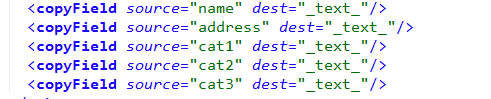
(3)设计schema
在schema中添加做如下修改,指定被索引字段为店名,地址,种类。

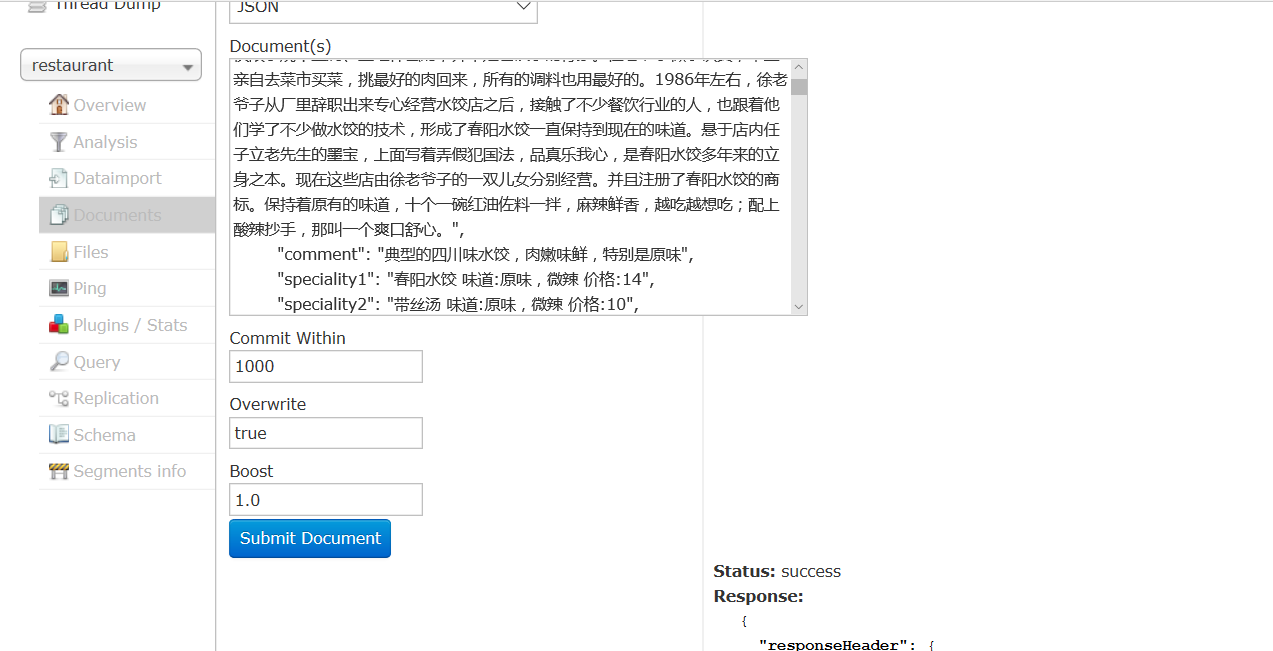
(4)导入中文文档
(5)样例搜索
查询位于金牛区的店,返回店名。
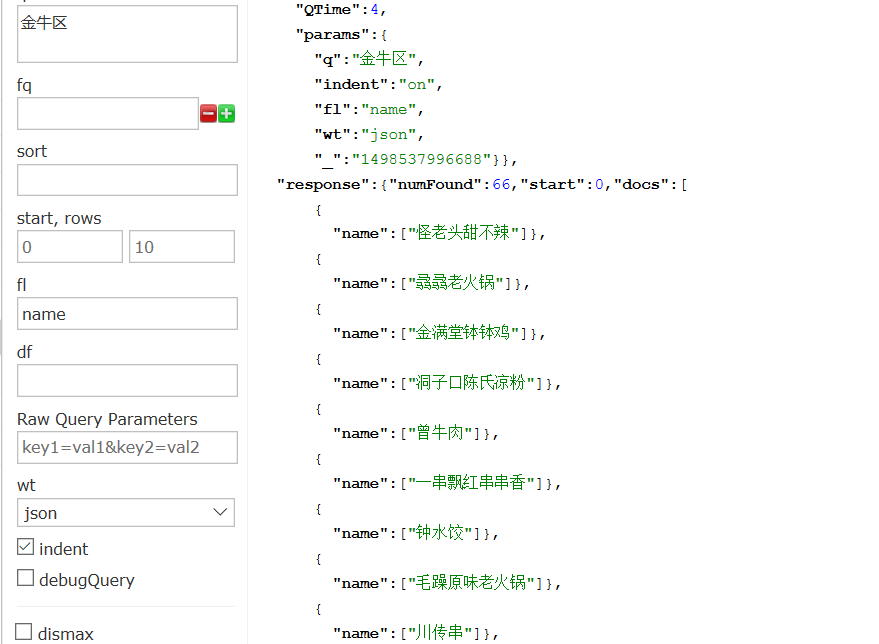
指定店名进行查询

查询卖水饺的店,返回店名,
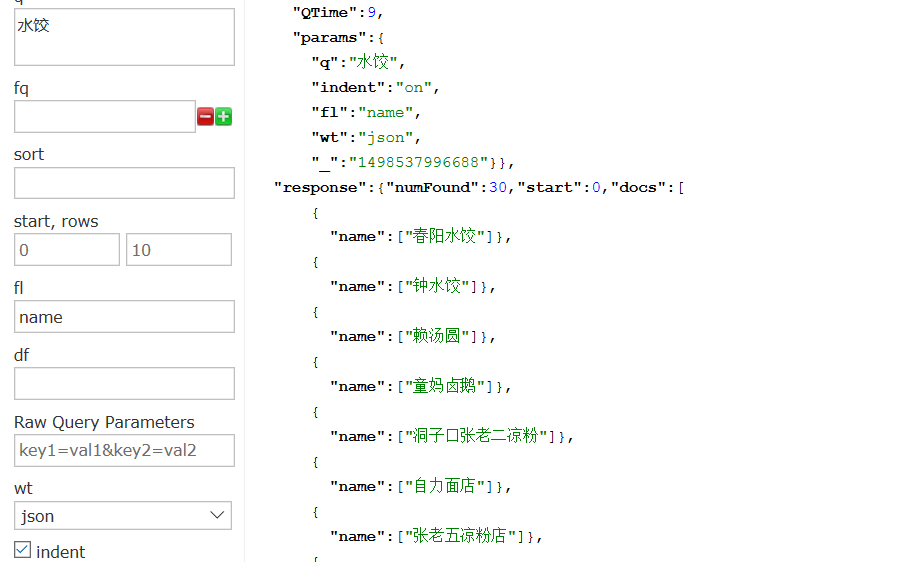
参考文献:
1戴维·温伯格.新数字秩序的革命[M].中信出版社,2008:12-14
2http://baike.baidu.com/item/%E4%BF%A1%E6%81%AF%E7%BB%8
4%E7%BB%87%E7%AE%A1%E7%90%86/12753285
4许明,探析ICT环境下的信息素养[J].现代远程教育研究,2008,5期
5 http://www.afenxi.com/post/9700
6 http://baike.baidu.com/link?url=PYSVm2ICv-TXhKxPYQ_cbvnN6Yw4hWj4zqU1FjpwAjbwIM5IZVo3iIkNTEtjDO1I8_AVOETlNjAc1GhqFC_SvmB3ea6HrPTkmER4aAW3FKSb2eWUdt4tRz0DoUyZW_wO
