@xlx9765
2017-06-23T14:48:06.000000Z
字数 960
阅读 348
scrapy抓取神奇女侠影评数据实验报告
笔者之前尝试过豆瓣影评中人民的名义的短评爬取和链家网成都房价信息爬取,由于爬虫被ban,均没有获取爬取结果。后来得知烂番茄这一影评网站,查看robots文件发现允许爬虫爬取数据,所以选择这个网站进行爬取。但是这是一个主要以影评为主的网站,没有找到电视剧人民的名义的短评信息。发现热搜榜排名第一的是刚刚看过的wonder woman 。很感兴趣,所以进行了数据爬取的尝试。
一、抓取对象分析
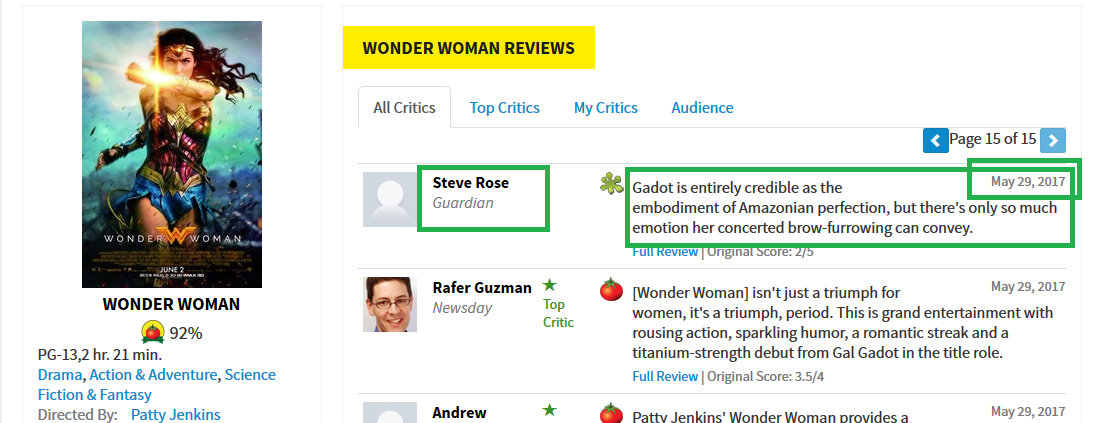
如图中所示,评论人名称name、评论时间date以及评论内容context是我们需要爬取的内容。
二、HTML定位与抓取规则
name定位
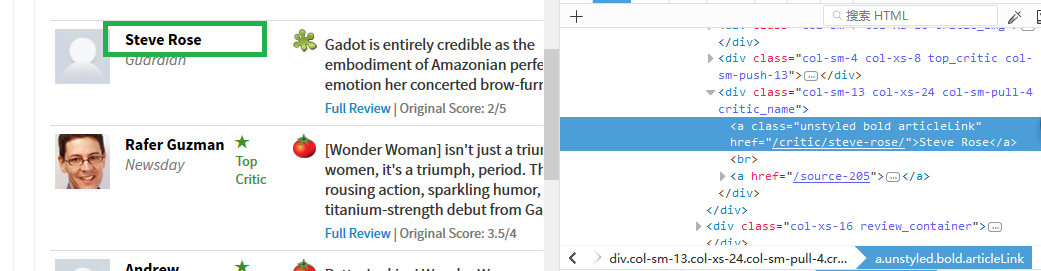
name爬取规则
div.col-xs-8 div.col-sm-13.col-xs-24.col-sm-pull-4.critic_name a.unstyled.bold.articleLink::text
review定位
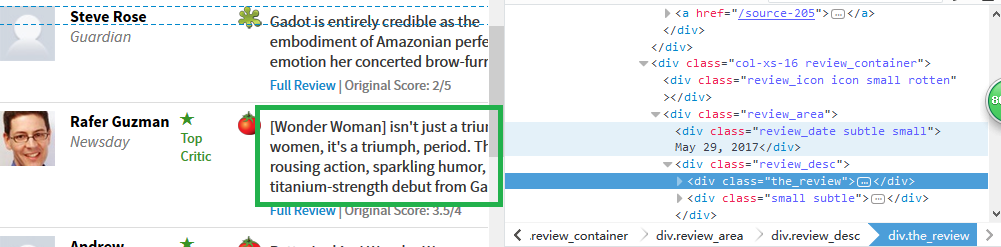
review爬取规则
div.col-xs-16.review_container div.review_area div.review_desc div.the_review::text
date定位
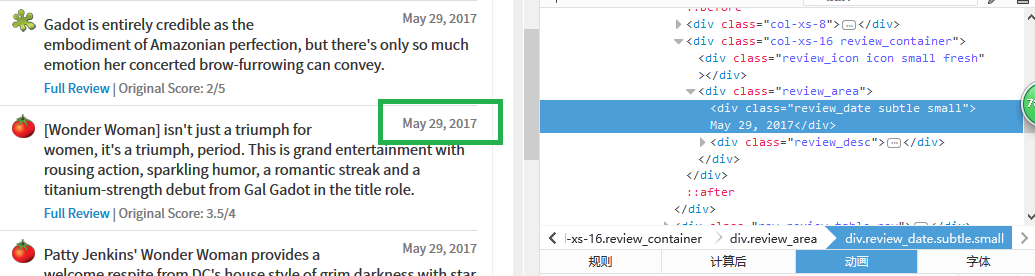
date爬取规则
div.col-xs-16.review_container div.review_area div.review_date.subtle.small::text
下一页问题
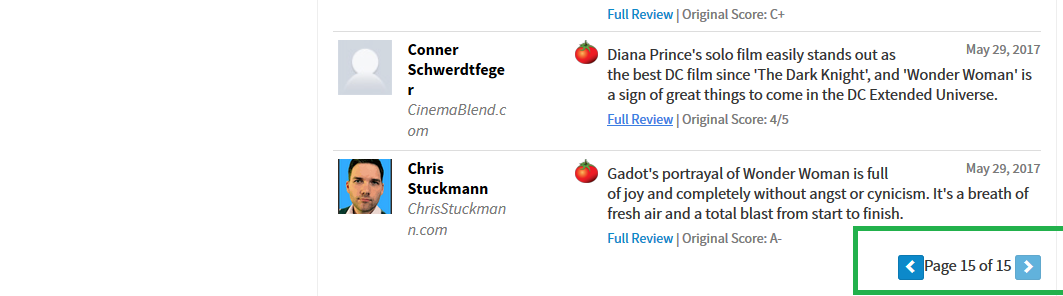
由图可知我们需要爬取的页面总共有15页,
下一页标签如下:

所以我选择的爬取所有页面数据的方式是,将url入口直接定位到第15页,然后根据下一页标签写出下一页规则,规则如下:
next_page = response.css(' div.col.col-center-right.col-full-xs section#content.panel.panel-rt.panel-box div.panel-body.content_body div#reviews div.content div a.btn.btn-xs.btn-primary-rt::attr(href)')
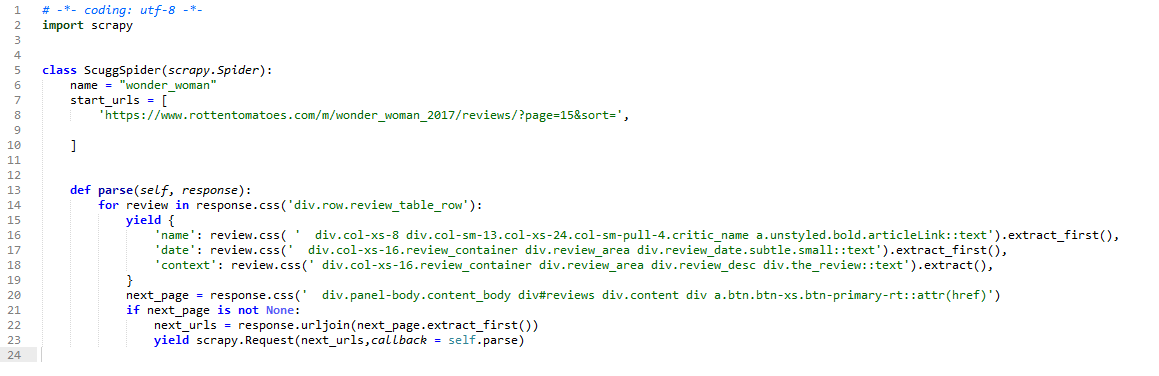
三、编写爬虫
四、数据获取
爬取结果页如下:
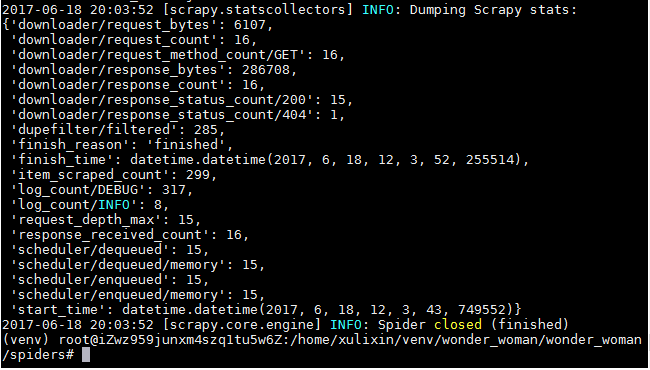
如图共爬取到299条数据,总共15页。具体结果如下:
第一页

最后一页

