@xlx9765
2017-07-01T13:34:02.000000Z
字数 868
阅读 220
成都房价信息爬取实验报告
一、抓取对象分析
笔者之前尝试过安居客网站放假信息爬取、链家网信息爬取,均由于爬虫被ban没有爬取到房价信息,最后找到想住网,发现允许爬虫访问,所以对该网站进行了爬取,以获取成都房价信息。
爬取网址为https://www.ixiangzhu.com/House/lists.html
首页信息如下:
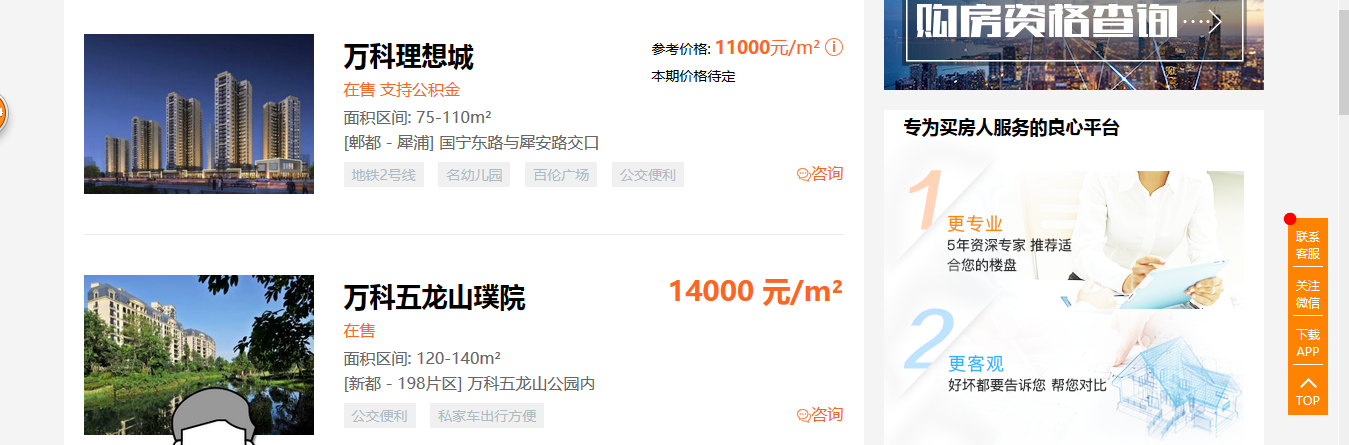
如图中显示,我们需要爬取的信息有楼盘名称,地址,房价,面积,图片。
二、HTML定位及与抓取规则
楼盘名称name定位
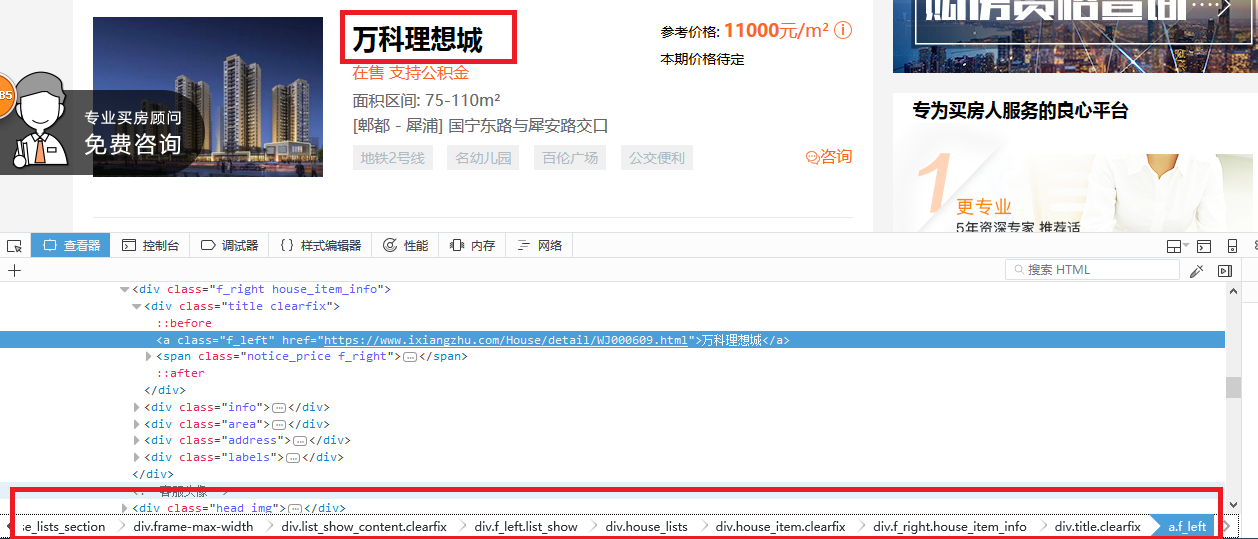
name爬取规则
div.f_right.house_item_info div.title.clearfix a.f_left::text
地址addr定位
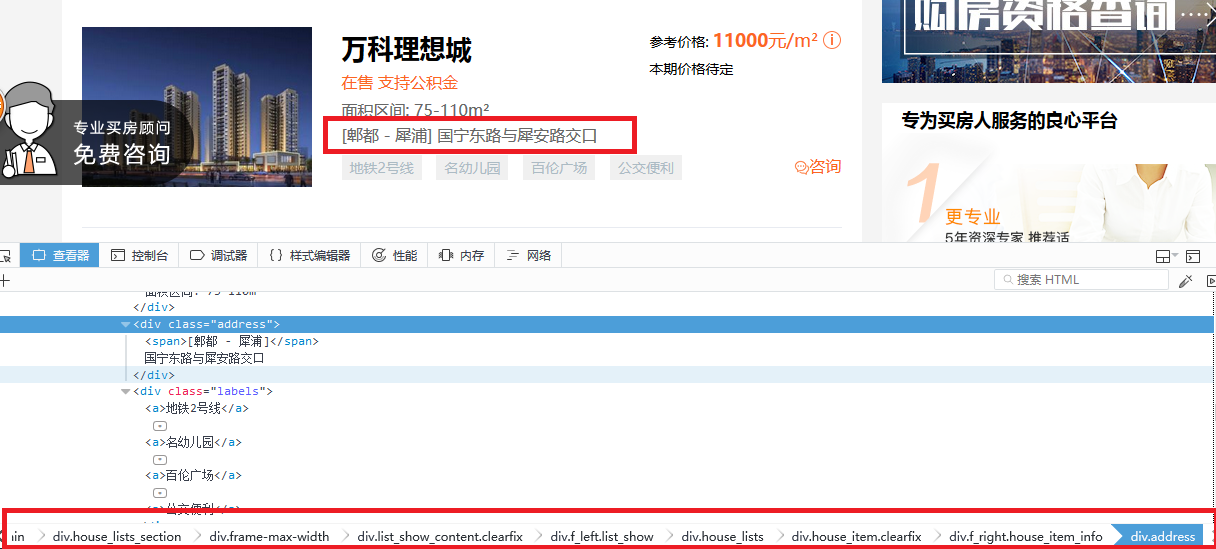
addr爬取规则
div.f_right.house_item_info div.address span::text
房价price定位
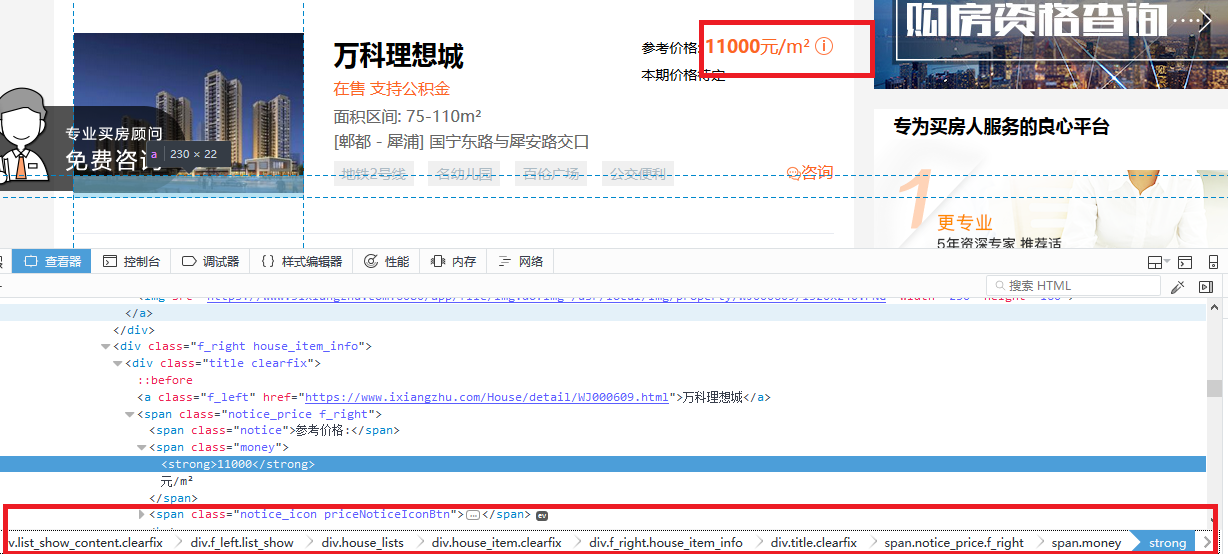
price爬取规则
div.f_right.house_item_info div.title.clearfix span.price.f_right span.money::text
面积area定位
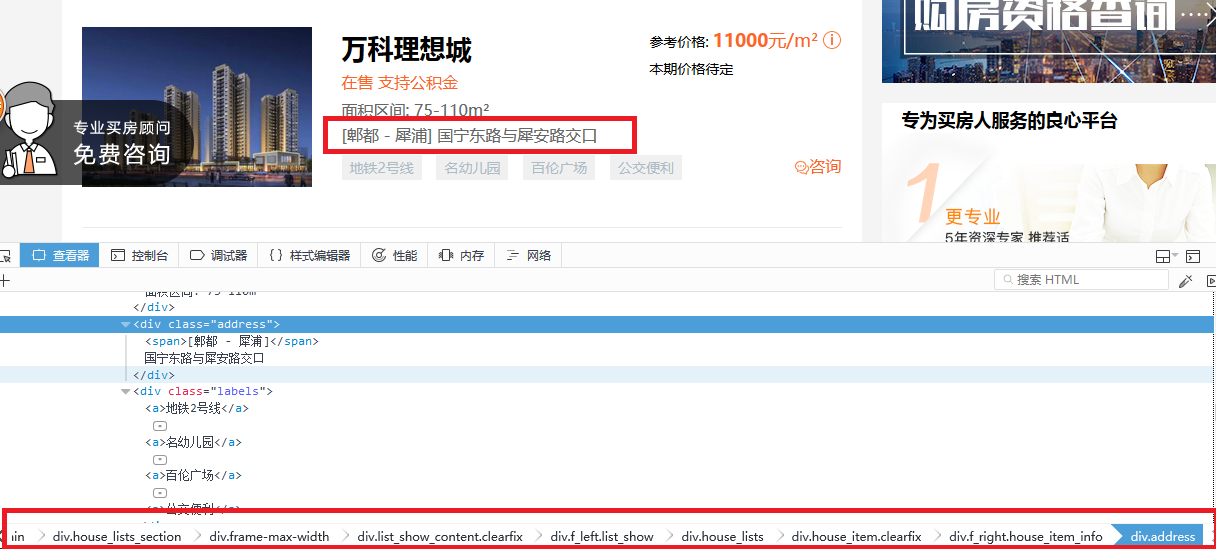
area爬取规则
div.f_right.house_item_info div.area::text
图片picture定位
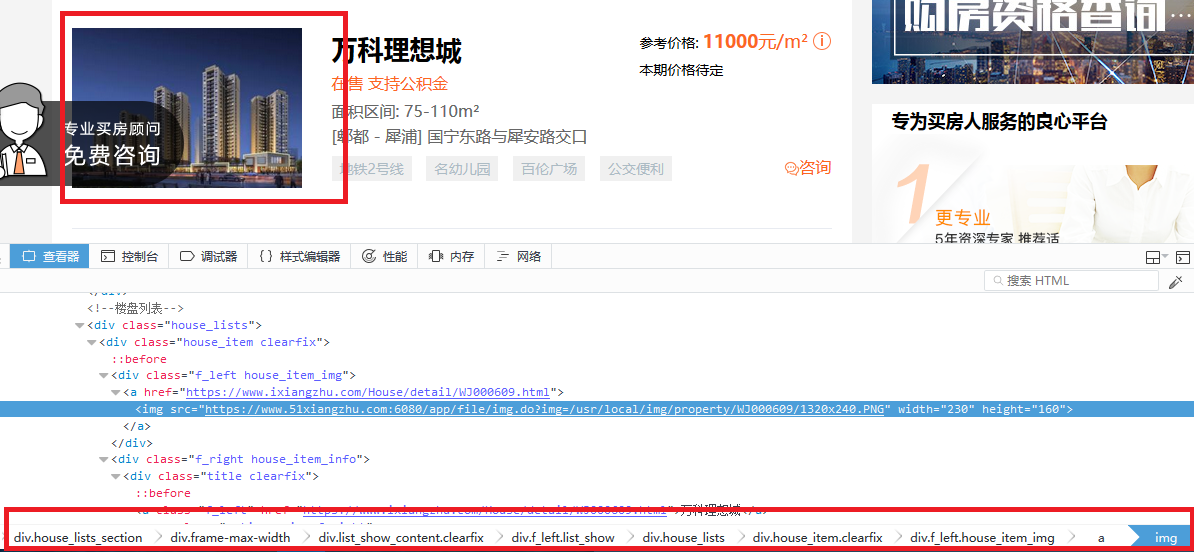
picture爬取规则
div.f_left.house_item_img a img::attr(src)
下一页定位
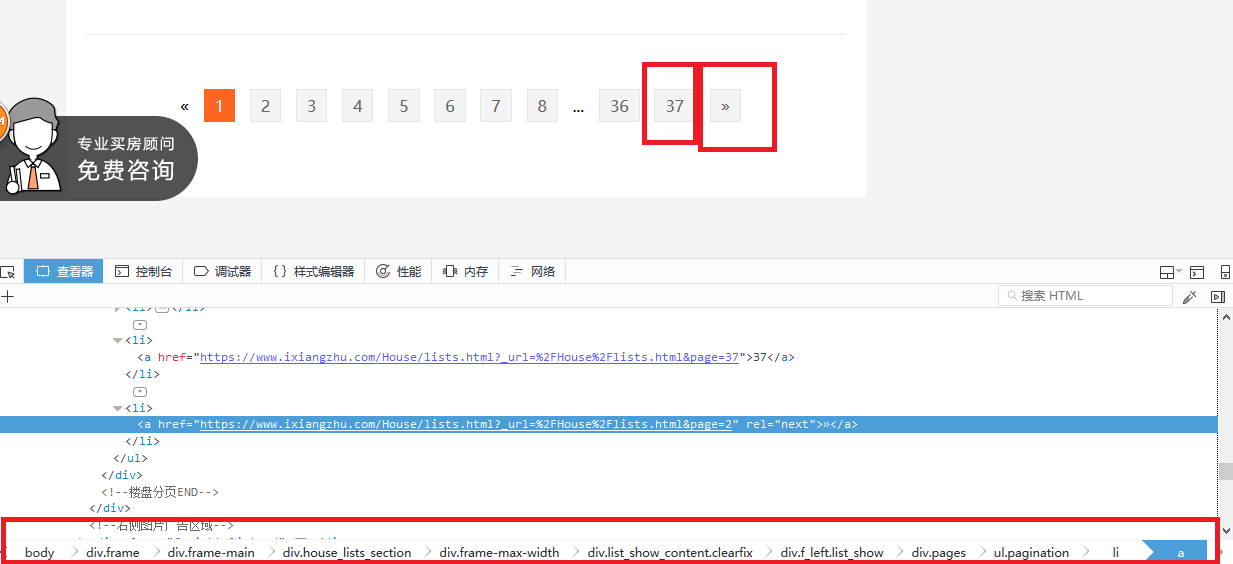
下一页规则
div.f_left.list_show div.pages ul.pagination li a::attr(href)
如图,已知该网站共有37页,所以在爬取数据时可直接将入口设为37页的网址,然后进行爬取。
三、爬虫编写
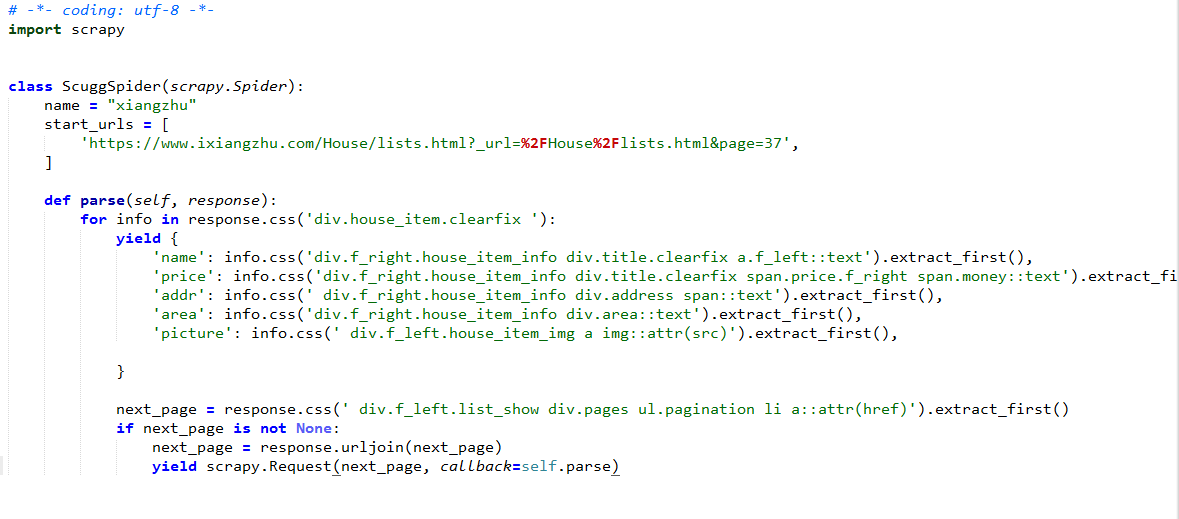
四、数据爬取
首先进入虚拟沙盒,并进行激活。然后进入cdfangjia项目,将爬虫文件拖入成都房价项目下的spiders文件夹,随后进行爬取。
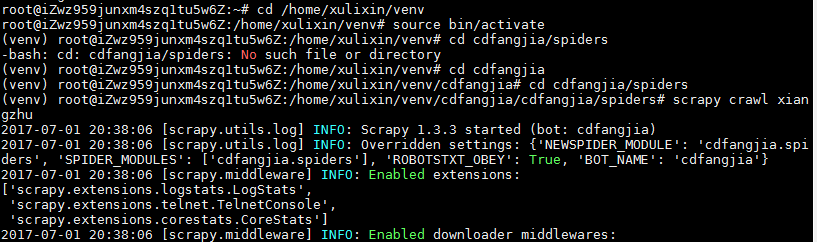
将爬取结果保存为xml格式,如下是爬取结果页和保存代码。
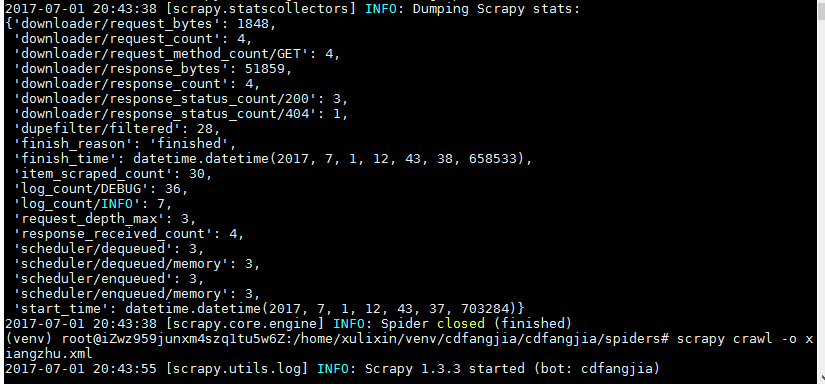
如图为爬取结果,

这是json格式的爬取结果,

如图显示,总共爬取到228条数据。
爬取完成。
