@xlx9765
2017-06-24T12:55:44.000000Z
字数 789
阅读 160
scrapy爬取川大公管新闻页实验报告
分析过程
首先分析爬取入口,从网站结构可以看出,点击首页more进入新闻列表页,需要爬取新闻列表url。点击单个新闻标题进入新闻详情页。需要爬取新闻标题,发布日期,新闻内容,新闻相关图片。
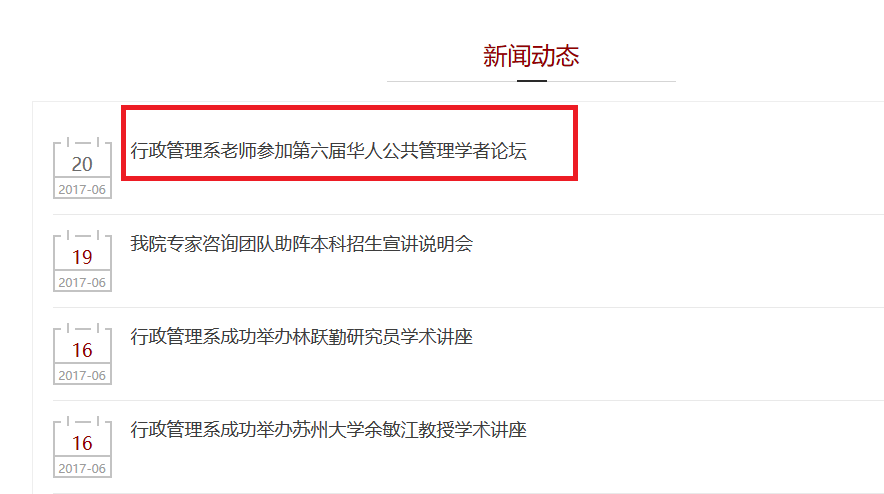
下一页定位与分析
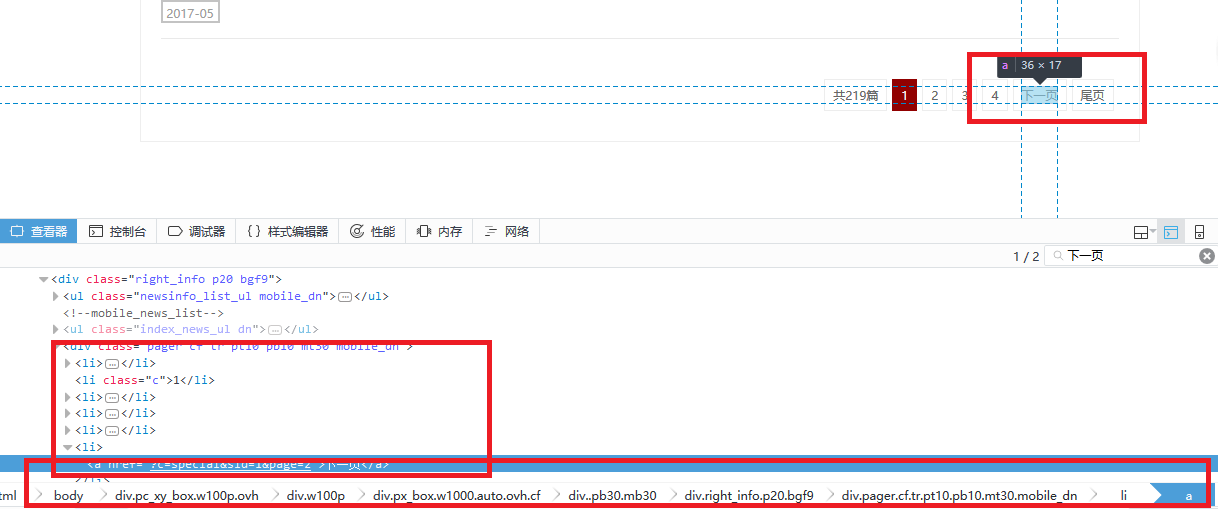
下一页规则
next_page = response.css('div.mobile_pager.dn li.c::text').extract_first()
if next_page is not None:
next_url = int(next_page) + 1
next_urls = '?c=special&sid=1&page=%s' % next_url
print next_urls
next_urls = response.urljoin(next_urls)
yield scrapy.Request(next_urls, callback=self.parse)
抓取内容与规则
title定位
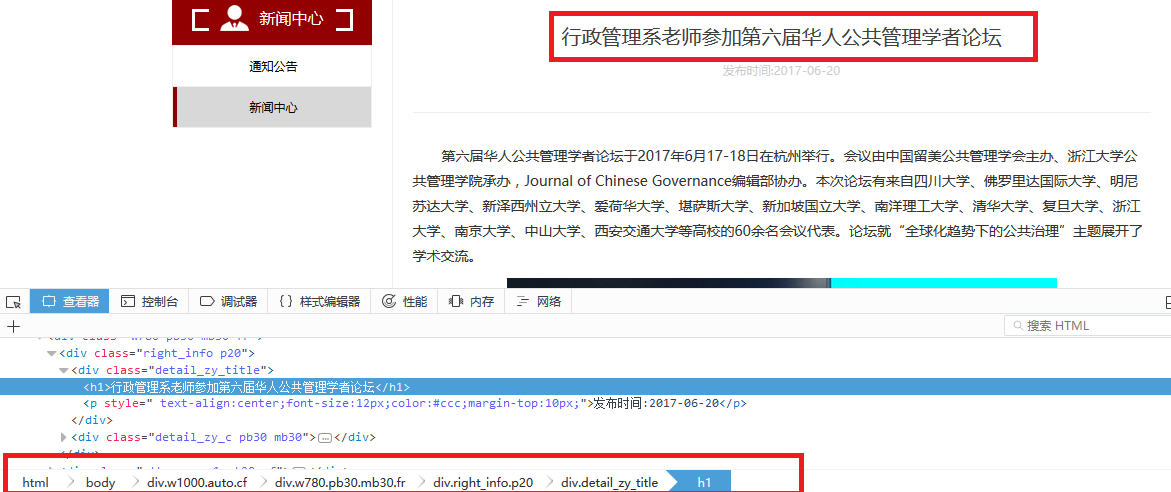
title爬取规则
div.detail_zy_title h1::text
date定位
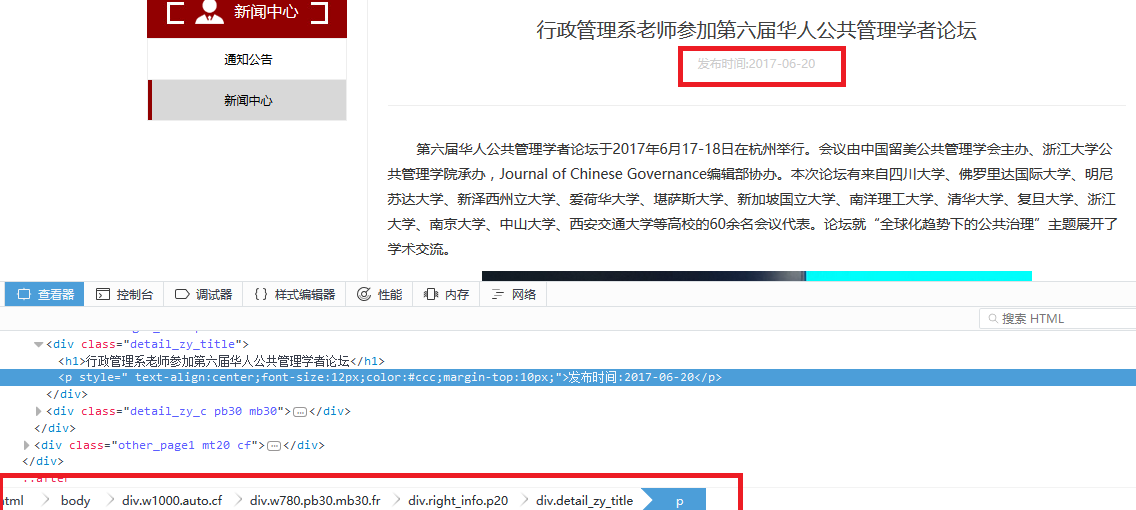
date爬取规则
div.detail_zy_title p::text
content定位
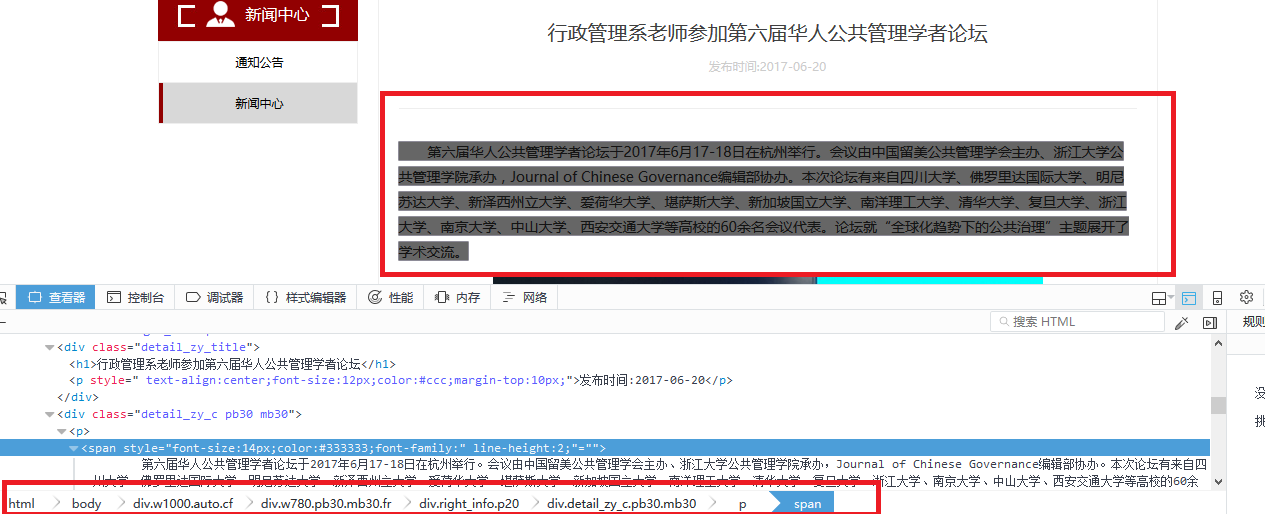
content爬取规则
div.detail_zy_c.pb30.mb30 p span::text
img定位
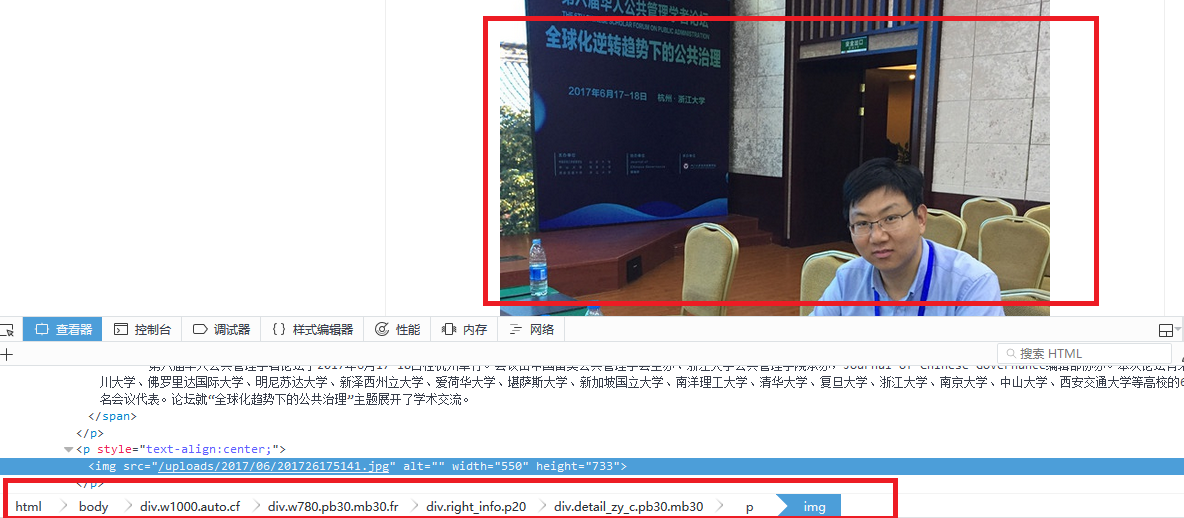
img爬取规则
div.detail_zy_c.pb30.mb30 p img::attr(src)
操作过程
 进入虚拟环境并激活,进入工程,查看工程目录结构。最后正确的代码文件是xlx_scu_ggnews.py ,正确的结果文件是xlx_scu_ggnews.xml.其他文件都是过程中摸索的相关的文件。有多少文件就有多少次爬取过程,还不止。有些心塞吧,期间还一直断网。不过最后爬取成功,十分激动。
进入虚拟环境并激活,进入工程,查看工程目录结构。最后正确的代码文件是xlx_scu_ggnews.py ,正确的结果文件是xlx_scu_ggnews.xml.其他文件都是过程中摸索的相关的文件。有多少文件就有多少次爬取过程,还不止。有些心塞吧,期间还一直断网。不过最后爬取成功,十分激动。

进入爬虫所在文件,并执行爬虫
爬虫代码
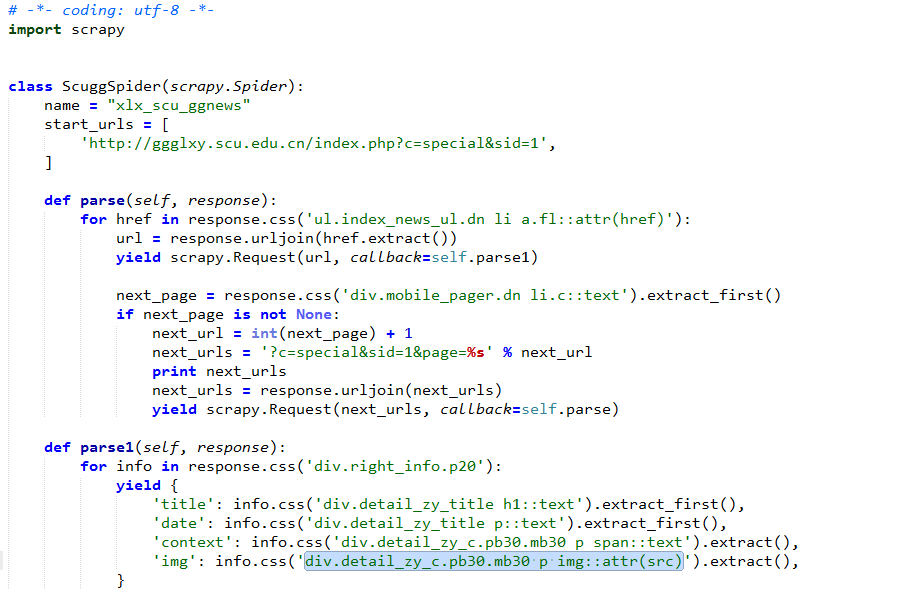
 过程页1
过程页1
 过程页2
过程页2
 爬取结果页
爬取结果页
 爬取结果保存。最终得到川大公管新闻的xml文件。
爬取结果保存。最终得到川大公管新闻的xml文件。
