@WillireamAngel
2018-03-09T06:25:50.000000Z
字数 7312
阅读 3596
SQL菜鸟教程
数据库
SQL教程
SQL:Structured Query Language(结构化查询语言)
RDBMS:Relational Database Management System(关系型数据库管理系统 )
SQL语法
SELECT - 从数据库中提取数据
UPDATE - 更新数据库中的数据
DELETE - 从数据库中删除数据
INSERT INTO - 向数据库中插入新数据
CREATE DATABASE - 创建新数据库
ALTER DATABASE - 修改数据库
CREATE TABLE - 创建新表
ALTER TABLE - 变更(改变)数据库表
DROP TABLE - 删除表
CREATE INDEX - 创建索引(搜索键)
DROP INDEX - 删除索引
use DB:选择数据库
set names utf8:设置使用字符集
SQL SELECT 语句
SELECT column_name,column_nameFROM table_name;
or
SELECT * FROM table_name;
SQL SELECT DISTINCT 语句
列出不同的值
SELECT DISTINCT column_name,column_nameFROM table_name;
SQL WHERE 子句
提取满足标准的记录
SELECT column_name,column_nameFROM table_nameWHERE column_name operator value;
SQL 使用单引号来环绕文本值(大部分数据库系统也接受双引号),数值字段勿用引号。
| 运算符 | 描述 |
|---|---|
| = | 等于 |
| <> | 不等于。注释:在 SQL 的一些版本中,该操作符可被写成 != |
| > | 大于 |
| < | 小于 |
= |
大于等于 |
| <= | 小于等于 |
| BETWEEN | 在某个范围内 |
| LIKE | 搜索某种模式 |
| IN | 指定针对某个列的多个可能值 |
Where 子句
Select * from emp where empno=7900;
Where +条件(筛选行)
条件:列,比较运算符,值
比较运算符包涵:= > < >= ,<=, !=,<> 表示(不等于)
Select * from emp where ename='SMITH';
例子中的 SMITH 用单引号引起来,表示是字符串,字符串要区分大小写。
逻辑运算
And:与 同时满足两个条件的值。
Select * from emp where sal > 2000 and sal < 3000;
查询 EMP 表中 SAL 列中大于 2000 小于 3000 的值。
Or:或 满足其中一个条件的值
Select * from emp where sal > 2000 or comm > 500;
查询 emp 表中 SAL 大于 2000 或 COMM 大于500的值。
Not:非 满足不包涵该条件的值。
select * from emp where not sal > 1500;
查询EMP表中SAL小于1500的值。
逻辑运算的优先级:() not and or
特殊条件
1.空值判断: is null
Select * from emp where comm is null;
查询 emp 表中 comm 列中的空值。
2.between and (在 之间的值)
Select * from emp where sal between 1500 and 3000;
查询 emp 表中 SAL 列中大于 1500 的小于 3000 的值。
注意:1500 为下限,3000 为上限,下限在前,上限在后,查询的范围包涵有上下限的值。
3.In
Select * from emp where sal in (5000,3000,1500);
查询 EMP 表 SAL 列中等于 5000,3000,1500 的值。
4.like
Like模糊查询
Select * from emp where ename like 'M%';
查询 EMP 表中 Ename 列中有 M 的值,M 为要查询内容中的模糊信息。
% 表示多个字值,_ 下划线表示一个字符;
M% : 为能配符,正则表达式,表示的意思为模糊查询信息为 M 开头的。
%M% : 表示查询包含M的所有内容。
%M_ : 表示查询以M在倒数第二位的所有内容。
SQL ORDER BY
ORDER BY 关键字用于对结果集按照一个列或者多个列进行排序。
ORDER BY 关键字默认按照升序对记录进行排序。如果需要按照降序对记录进行排序,您可以使用 DESC 关键字。
SELECT column_name,column_nameFROM table_nameORDER BY column_name,column_name ASC|DESC;
SQL INSERT INTO
第一种形式无需指定要插入数据的列名,只需提供被插入的值即可:
INSERT INTO table_nameVALUES (value1,value2,value3,...);
第二种形式需要指定列名及被插入的值:
INSERT INTO table_name (column1,column2,column3,...)VALUES (value1,value2,value3,...);
SQL UPDATE
更新表中记录,执行没有 WHERE 子句的 UPDATE 要慎重,再慎重。
UPDATE table_nameSET column1=value1,column2=value2,...WHERE some_column=some_value;
SQL DELETE
删除表中的行
DELETE FROM table_nameWHERE some_column=some_value;
SQL 高级教程
SQL SELECT TOP, LIMIT, ROWNUM 子句
用于规定返回子句
SELECT column_name(s)FROM table_nameLIMIT number;
SELECT TOP 50 PERCENT * FROM Websites;
SQL LIKE
搜索列的指定模式
SELECT column_name(s)FROM table_nameWHERE column_name LIKE pattern;
SQL 通配符
通配符与SQL操作符一起使用,用于搜索表中的数据。
| 通配符 | 描述 |
|---|---|
| % | 替代 0 个或多个字符 |
| _ | 替代一个字符 |
| [charlist] | 字符列中的任何单一字符 |
| [^charlist]或[!charlist] | 不在字符 |
SQL IN
子句规定多个值
SELECT column_name(s)FROM table_nameWHERE column_name IN (value1,value2,...);
IN 与 = 的异同:
- 相同点:均在WHERE中使用作为筛选条件之一、均是等于的含义
- 不同点:IN可以规定多个值,等于规定一个值
SQL BETWEEN
选取介于两个值之间的数据范围内的值。
SELECT column_name(s)FROM table_nameWHERE column_name BETWEEN value1 AND value2;
SQL 别名
通过使用 SQL,可以为表名称或列名称指定别名。
列的 SQL 别名语法
SELECT column_name AS alias_nameFROM table_name;
表的 SQL 别名语法
SELECT column_name(s)FROM table_name AS alias_name;
使用别名情况:
- 在查询中涉及超过一个表
- 在查询中使用了函数
- 列名称很长或者可读性差
- 需要把两个列或者多个列结合在一起
SQL 连接(JOIN)
SQL JOIN 子句用于把来自两个或多个表的行结合起来,基于这些表之间的共同字段。
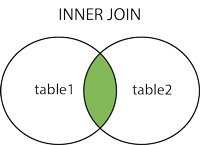
INNER JOIN:如果表中有至少一个匹配,则返回行
SELECT column_name(s)FROM table1INNER JOIN table2ON table1.column_name=table2.column_name;
or
SELECT column_name(s)FROM table1JOIN table2ON table1.column_name=table2.column_name;
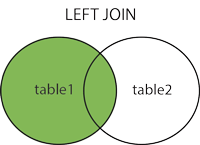
LEFT JOIN:即使右表中没有匹配,也从左表返回所有的行
SELECT column_name(s)FROM table1LEFT JOIN table2ON table1.column_name=table2.column_name;
or
SELECT column_name(s)FROM table1LEFT OUTER JOIN table2ON table1.column_name=table2.column_name;
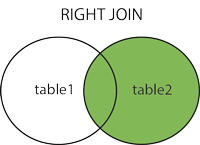
RIGHT JOIN:即使左表中没有匹配,也从右表返回所有的行
SELECT column_name(s)FROM table1RIGHT JOIN table2ON table1.column_name=table2.column_name;
or
SELECT column_name(s)FROM table1RIGHT OUTER JOIN table2ON table1.column_name=table2.column_name;
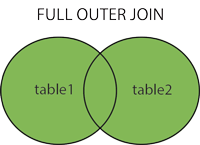
FULL JOIN:只要其中一个表中存在匹配,则返回行
SELECT column_name(s)FROM table1FULL OUTER JOIN table2ON table1.column_name=table2.column_name;
SQL UNION
合并两个或多个SELECT语句的结果集
UNION 操作符选取不同的值。如果允许重复的值,请使用 UNION ALL。
SELECT column_name(s) FROM table1UNIONSELECT column_name(s) FROM table2;
UNION 结果集中的列名总是等于 UNION 中第一个 SELECT 语句中的列名。
SELECT column_name(s) FROM table1UNION ALLSELECT column_name(s) FROM table2;
SQL SELECT INTO
SELECT INTO 语句从一个表复制数据,然后把数据插入到另一个新表中。
CREATE TABLE 新表 SELECT * FROM 旧表
复制所有的列插入到新表中:
SELECT *INTO newtable [IN externaldb]FROM table1;
只复制希望的列插入到新表中:
SELECT column_name(s)INTO newtable [IN externaldb]FROM table1;
SQL INSERT INTO SELECT
从一个表复制数据,然后把数据插入到一个已存在的表中。
从一个表中复制所有的列插入到另一个已存在的表中:
INSERT INTO table2SELECT * FROM table1;
或者只复制希望的列插入到另一个已存在的表中:
INSERT INTO table2(column_name(s))SELECT column_name(s)FROM table1;
SQL CREATE DB
创建DB
CREATE DATABASE dbname;
SQL CREATE TABLE
CREATE TABLE 语句用于创建数据库中的表。
表由行和列组成,每个表都必须有个表名。
CREATE TABLE table_name(column_name1 data_type(size),column_name2 data_type(size),column_name3 data_type(size),....);
column_name 参数规定表中列的名称。
data_type 参数规定列的数据类型(例如 varchar、integer、decimal、date 等等)。
size 参数规定表中列的最大长度。
SQL 约束
SQL 约束用于规定表中的数据规则。如果存在违反约束的数据行为,行为会被约束终止。
CREATE TABLE table_name(column_name1 data_type(size) constraint_name,column_name2 data_type(size) constraint_name,column_name3 data_type(size) constraint_name,....);
约束:
- NOT NULL - 指示某列不能存储 NULL 值。
- UNIQUE - 保证某列的每行必须有唯一的值。每个表可以有多个 UNIQUE 约束,但是每个表只能有一个 PRIMARY KEY 约束。
create table tb2(tb2_id int unique,tb2_name varchar(20),tb2_age int,unique(tb2_name));
select * from tb2;insert into tb2(tb2_id,tb2_name,tb2_age) values (1,'张三',20);
--违反唯一约束
insert into tb2 values(2,'张三',25);
--建表时,创建约束,有约束名
create table tb3(tb3_id int ,tb3_name varchar(20),tb3_age int,constraint no_id unique (tb3_id))insert into tb3 values (1,'张三',20);insert into tb3(tb3_id,tb3_age) values(2,24);select * from tb3;
--已经有了tb3_id为1的行记录,再次插入,违反唯一约束
insert into tb3(tb3_id,tb3_name,tb3_age) values(1,'李四',25);
--给tb3表添加主键约束,主键名为:pk_id
alter table tb3 add constraint pk_id primary key (tb3_id);
--给tb3_name添加唯一约束
alter table tb3 add constraint un_name unique (tb3_name);
--已存在姓名为张三的记录,违反唯一约束
insert into tb3 values (3,'张三',26);
--mysql 删除约束的语句,使用index,oracle SqlServer等使用constraint
alter table tb3 drop index un_name;
--删除约束后,允许存在多个tb3_name为张三的记录
insert into tb3 values (3,'张三',26);
- PRIMARY KEY - NOT NULL 和 UNIQUE的结合。确保某列(或两个列多个列的结合)有唯一标识,有助于更容易更快速地找到表中的一个特定的记录。
PRIMARY KEY 约束唯一标识数据库表中的每条记录。主键必须包含唯一的值。主键列不能包含 NULL 值。每个表都应该有一个主键,并且每个表只能有一个主键。 FOREIGN KEY - 保证一个表中的数据匹配另一个表中的值的参照完整性。
CHECK - 保证列中的值符合指定的条件。
CHECK 约束用于限制列中的值的范围。
如果对单个列定义 CHECK 约束,那么该列只允许特定的值。
如果对一个表定义 CHECK 约束,那么此约束会基于行中其他列的值在特定的列中对值进行限制。- DEFAULT - 规定没有给列赋值时的默认值。
SQL CREATE INDEX
CREATE INDEX index_nameON table_name (column_name)
SQL DROP
通过使用 DROP 语句,可以轻松地删除索引、表和数据库。
SQL ALTER
ALTER TABLE 语句用于在已有的表中添加、删除或修改列。
SQL Auto Increment
Auto-increment 会在新记录插入表中时生成一个唯一的数字。
ALTER TABLE table_name CHANGE column_name column_name data_type(size) constraint_name AUTO_INCREMENT;
SQL 视图
CREATE VIEW view_name ASSELECT column_name(s)FROM table_nameWHERE condition
SQL 日期
http://www.runoob.com/sql/sql-dates.html
SQL NULL 值
SQL NULL 函数
SQL ISNULL()、NVL()、IFNULL() 和 COALESCE() 函数
SQL 通用数据类型
http://www.runoob.com/sql/sql-datatypes-general.html
SQL DB 数据类型
http://www.runoob.com/sql/sql-datatypes.html
SQL 函数
SQL Aggregate 函数
SQL Aggregate 函数计算从列中取得的值,返回一个单一的值。
有用的 Aggregate 函数:
AVG() - 返回平均值
COUNT() - 返回行数
FIRST() - 返回第一个记录的值
LAST() - 返回最后一个记录的值
MAX() - 返回最大值
MIN() - 返回最小值
SUM() - 返回总和
SQL Scalar 函数
SQL Scalar 函数基于输入值,返回一个单一的值。
有用的 Scalar 函数:
UCASE() - 将某个字段转换为大写
LCASE() - 将某个字段转换为小写
MID() - 从某个文本字段提取字符,MySql 中使用
SubString(字段,1,end) - 从某个文本字段提取字符
LEN() - 返回某个文本字段的长度
ROUND() - 对某个数值字段进行指定小数位数的四舍五入
NOW() - 返回当前的系统日期和时间
FORMAT() - 格式化某个字段的显示方式
提示:在下面的章节,我们会详细讲解 Aggregate 函数和 Scalar 函数。
