@devilloser
2018-12-18T07:39:04.000000Z
字数 6353
阅读 1726
从信息论到GAN
deeplearning
本文希望能从信息论开始整理,最后完成以信息论为基础的生成对抗网络的发展思路。
本文讨论的文章如下:
GAN
LSGAN
DCGAN
WGAN
WGAN-GP
DRAGAN
EBGAN
BGAN
SGAN
bayesian gan
条件生成型GAN:
CGAN
ACGAN
infoGAN
CycleGAN
StarGAN
目录
信息论
信息量与信息熵
目的是对一个信号的信息量进行量化。
信息熵:接收的每条消息中包含的信息的平均量,
(1)单调性:越不可能发生的事信息量越大,比如国足输了比国足赢了信息量要小
(2)非负性:信息熵不能为负,不能在得到信息之后不确定性更大
(3)累加性:多随机事件同时发生存在的总不确定性的量度是可以表示为各事件不确定性的量度的和,即
定义X=x事件的自信息量为:
定义变量X的信息熵为:
K-L散度(Kullback-Leibler Divergence)
对两个不同的分布P(x)和Q(x),可以用K-L散度度量两个分布的差值:
K-L散度具有非负性,可证:
K-L散度的问题是只有三角不等式和非负性,没有共轭对称性,不是一个距离空间。
交叉熵(cross entropy)
这里因为真实样本分布的信息熵为确定值,所以最小化交叉熵就是在最小化K-L散度
当真实样本服从概率为P的(0,1)分布,即
同时预测样本分布服从概率为Q的(0,1)分布,即
则:
cross entropy的优势:
(1)对logits来说交叉熵是凸函数,平方损失函数非凸,二阶导数可能小于0
(2)交叉熵的梯度为:
平方损失函数为:
在sigmoid激活函数中可能会梯度消失。
极大似然估计
假设有m个样本的数据集,由未知的真实数据分布独立生成。令,为由 确定的概率分布,确定的概率分布,将任意输入将任意输入x映射到实数来估计真实概率映射到实数来估计真实概率
数据集越大,抽样越能代表真实数据的分布,更能认为是等于。
GAN
从公式把握思想:
判别器D:
当时,最大化的目的是令判别器在x服从data的概率分布时能准确的预测
当时,最大化的目的是当x服从生成数据的分布时,判别器
生成器G:
最小化是让判别器
理论推导
对于最优判别器:
所以
JS散度
解决了K-L散度没有对称性的缺点
所以生成器最优时:
GAN的问题
(1)梯度不稳定
(2)模型崩塌
原因
(1)我们将真实数据和生成数据通过判别器从高维流形映射到低维流形比较,当判别器很好时,且生成数据的低维流形与真实数据的低维流形不存在重合,
因为时,
同理另一项也为,梯度消失。而且JSD散度没法衡量不重合的两个分布中间到底距离有多大。
GAN的改进
在最优判别器的情况下用散度表示:
(1)最小化会同时最小化的同时最大化,非常矛盾
(2)同时前面一项时
当,时,,生成器生成了不真实的数据,惩罚小
当,时,,生成器生成了不存在的数据,惩罚大
多样性降低
Least Squares Generative Adversarial Networks
f散度族
这是JS散度的推广:
其中需要满足f是凸函数,且。
同样
LSGAN
Loss:
令,:
对于最优判别器:
代入得:
选择散度的原因是不会梯度消失,对离群点(fake sample)惩罚更大,缺点是多样性小了,也又f散度的通病
DCGAN
一些guidelines:
(1)用strided convolutions代替pooling
(2)除了generator的output用Tanh其余用ReLU
(3)在G和D中用batchnorm
(4)去掉了fully connected hidden layers
(5)discriminator中用LeakyReLU
WGAN
Wasserstein distance
其中是联合概率分布
论文中的example 1:
服从
服从
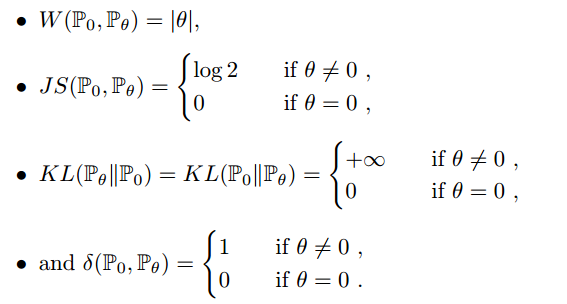
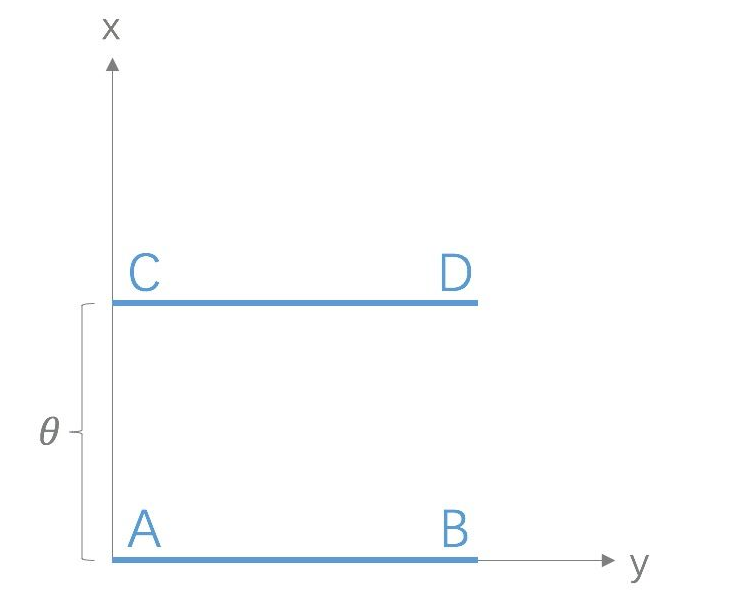
Wasserstein distance理论
(1)当G对连续时,Wasserstein distance对连续
证明:
如果G对连续,
(2)如果G满足Lipschitz定理,则wasserstein distance处处连续,而且几乎处处不相等
Lipschitz定理:存在常数,满足
证明:
求期望而且认为相等,
定义
所以Wasserstein distance满足Lipschitz定理,即W距离在任意处连续,且导数不会是无穷
(3) Wasserstein distance比KL散度,JS散度更适合从一个分布的低维映射学习到该分布
证明:暂略,看不懂
WGAN Loss
这里将K改成了1,因为K只会让f的梯度变成K倍,可以通过对W的clip让满足条件,然后由于是比较两个低维分布的Wasserstein distance,所以需要将softmax去掉,然后近似的将下式看作W距离
所以问题等价成了:
所以,WGAN只改动了四点:
(1)判别器最后一层去掉sigmoid
(2)生成器和判别器的loss不取log
(3)每次更新判别器的参数之后把它们的绝对值截断到不超过一个固定常数c
(4)不要用基于动量的优化算法(包括momentum和Adam),推荐RMSProp,SGD也行
最后一条是玄学
