@devilloser
2018-09-10T06:26:53.000000Z
字数 1939
阅读 1110
knowledge distilling
deeplearning
Distilling the Knowledge in a Neural Network
Distillation
T:温度系数,用来让softmax更加soft
Matching logits is a special case of distillation
target probabilities:,
当T很大时:
假定是0均值的,那:
这样就可以认为优化的loss是mse
A Gift from Knowledge Distillation:Fast Optimization, Network Minimization and Transfer Learning
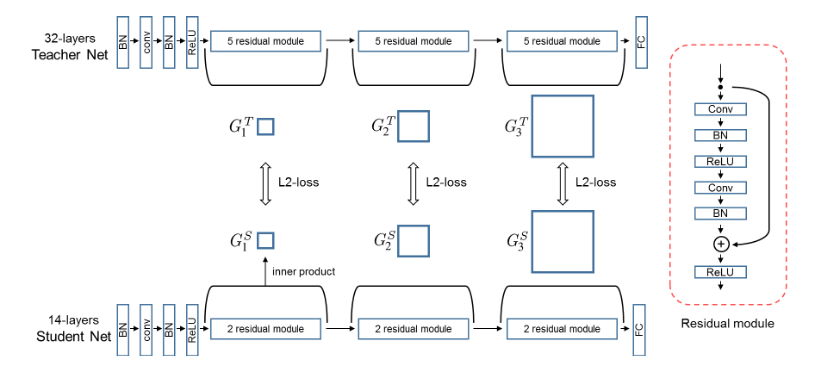
本文思想是学习一种认知的过程
对,,
实验没法证明fast optimization

Like What You Like: Knowledge Distill via Neuron Selectivity Transfer
Maximum Mean Discrepancy
论文中,作者验证了三种常用的核函数,他们分别是
线性核:
多项式核:, 文中采用,
高斯核::高斯核中设为两网络特征的平均距离
利用kernel trick将feature map映射到高维空间,是因为他认为attention map的做法粒度还是比较大。当kernel取二阶多项式核的时候,根据gram矩阵的性质,feature map的channel之间的内积可以转化为feature map空间的相关性,即让student模型学习teacher模型的feature map通道之间的关系或者空间像素点之间的关系。
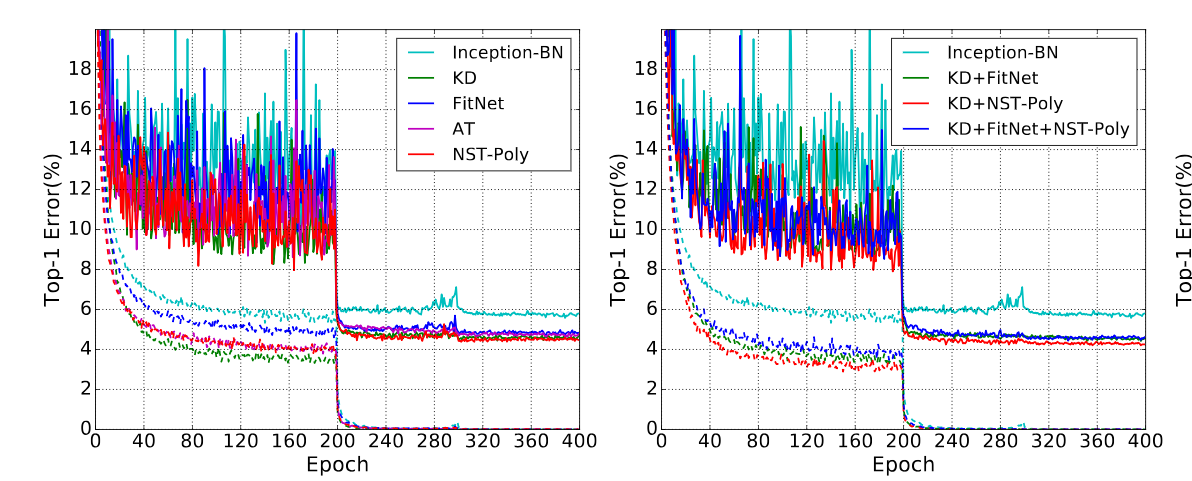
效果如下图:
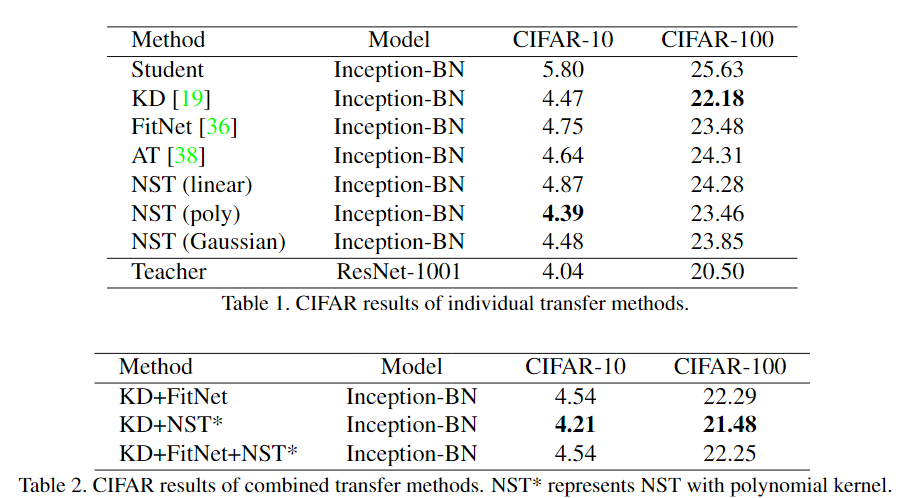
但是Resnet1001不应该这么高的精度,BN-Inception也没有达到它的精度