@devilloser
2018-07-19T07:57:34.000000Z
字数 1822
阅读 846
CVPR2018 video action
action
A Closer Look at Spatiotemporal Convolutions for Action Recgonition
文章链接
A Closer Look at Spatiotemporal Convolutions for Action Recognition
贡献
1)残差中的3D conv和2D conv的作用
2)提出了R(2+1)D conv:replace N*t*d*d conv with N*1*d*d conv and M*t*1*1 conv
advantages
1) it doubles the number of nonlinearities in the network due to the additional ReLU between the 2D and 1D convolution in each block
2) forcing the 3D convolution into separate spatial and temporal components renders the optimization easier
MiCT: Mixed 3D/2D Convolutional Tube for Human Action Recognition
文章链接
MiCT: Mixed 3D/2D Convolutional Tube for Human Action Recognition
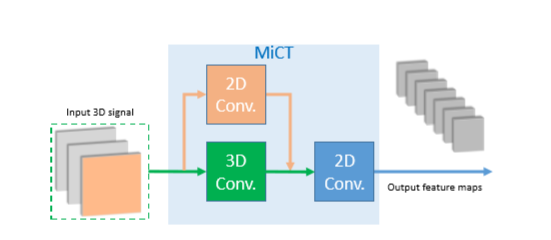
贡献
Mixed 2D/3D Convolutional Tube (MiCT)
advantages
efficient
Optical Flow Guided Feature: A Fast and Robust Motion Representation for Video Action Recognition
文章链接
Optical Flow Guided Feature: A Fast and Robust Motion Representation for Video Action Recognition
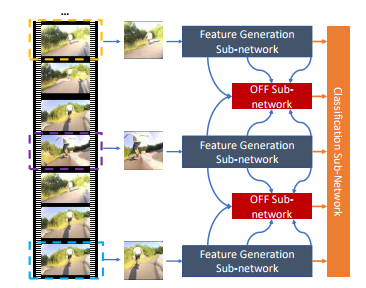
贡献
optical flow guided feature
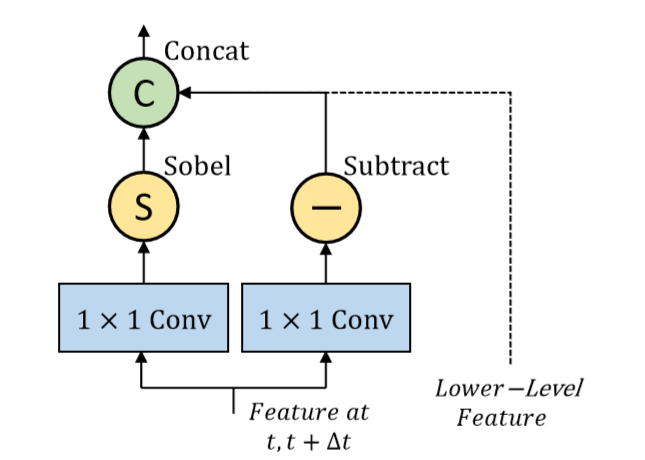
1×1 conv可以reduce channel
边缘检测算子:
sobel算子
当G大于某个阈值时认为是边界
laplace算子
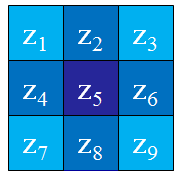
经验值,
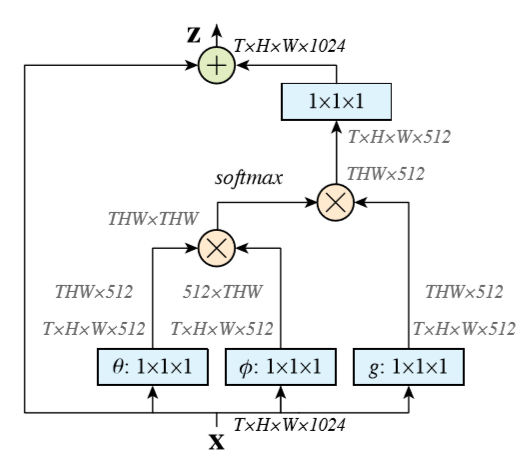
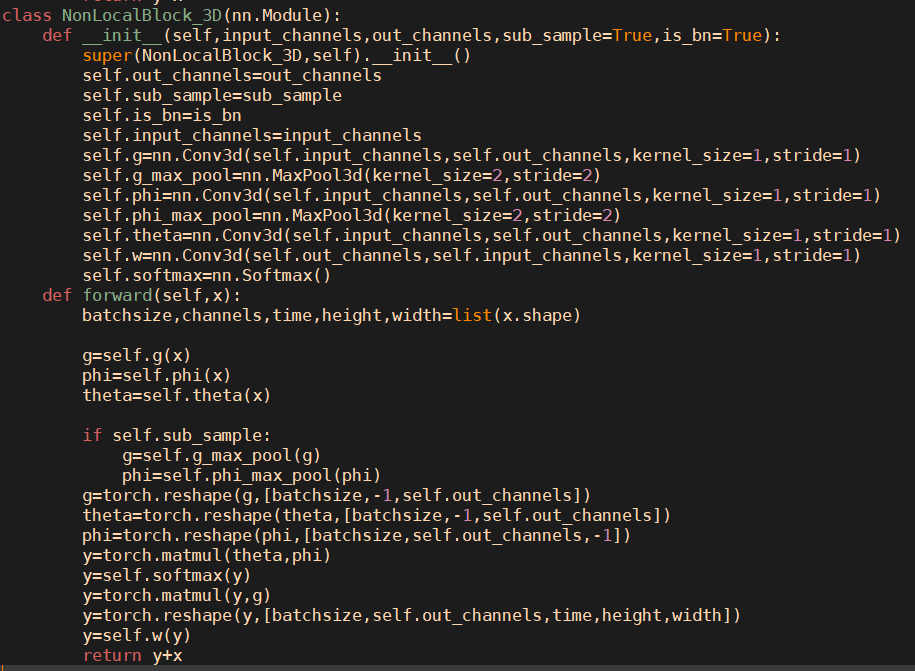
Non-local Neural Networks
贡献
讲non-local mean算法套用在conv network中
实现
non-local mean:
Gaussian
embedded Gaussian
set
dot
Concatenation
set
总结
temporal信息的提取:
non-local network
3D conv
对成熟模型的feature map重新提取信息
