@devilogic
2018-07-12T15:16:59.000000Z
字数 42616
阅读 1955
算法变形引擎
devilogic
应看雪大哥之邀写一篇介绍变形引擎技术的文章。来丰富《加密与解密》第四版的内容。说实话已经好久没有直接搞这样的技术了。一直在折腾自己的一家小公司。所以这方面的武功已经废得差不多了。下文如果觉得有不妥之处还望见谅。
变形引擎原理介绍
变形引擎最先是在病毒中进行使用,其目的是对抗特征码提取。一个基础的模式如下所示:其中aaa等表示一些汇编指令。这里就不列出具体指令了。
解密代码(用来解密加密后的病毒体):aaabbbccc加密后的病毒体:调用(call) 感染模块aaabbbccc感染模块:aaabbbccc调用(call) 算法变形引擎aaabbbccc算法变形引擎(生成新的解密代码并写入到新的病毒体中):aaabbbccc
以上的原理就是,利用算法变形引擎,将解密头算法进行变形,其实虽然称是解密算法,不如称为模式处理更为贴切。例如:。这样的式子,其中是要加密的字节,而是加密后的字节。那么解密公式就变成。而其中的是一个使用随机数控制的所谓的密钥。在数学的意义上,其实这个并没有所谓的强度。但是在生成的汇编代码却起到了特征变换的效果。在实际写程序的意义上也可以得到实现。因为它的实现并不困难。
这里有一篇08年,我原来写的Vulcano病毒分析。http://bbs.pediy.com/showthread.php?t=78862 这里详细分析了一个完整的算法变形引擎。
为什么称作是算法变形引擎,而不直接叫变形引擎呢?因为就我理解而言,病毒体并没有实现真正的变形。而本文所介绍的并非以上这种引擎,而是其中的一个子集,其作用呢也并非对抗特征码扫描,而是在软件保护上放置一个可变换的“加解密算法”的模块,这样每次加密时使用新的算法进行解密,毕竟很多情况下,破解者对加解密算法的强度不是很在意。他们只关心解密的整体流程。本文的这个小程序是用来来对抗静态脱壳机。是一个基本的框架。由于时间有限,在我的设想中仅仅算完成了个开头吧。待有空再补齐吧。
代码变形引擎介绍
首先,同学们可以从以下地址中迁出一套完整的源代码。
https://git.coding.net/devilogic/polycypt.git
我们一边看代码一边完成一个简单的算法变形的框架。在这里吐槽一下,在如今浮躁的社会,尤其是移动软件保护这个浮躁的领域。这点小代码也许在客户面前就是价值几万一年的产品或者一个牛逼技术的控标点。算了这里不是吐槽的地方,希望段哥审稿没有发现。
这里利用了虚拟解释语言的一个原理,就是首先我们写一个虚拟机只负责解释我们自己定义的指令,然后只处理我们自己规定的一个可执行文件格式。随后在写一个对应的汇编器,负责汇编代码。最后写一个变形引擎,每次由这个引擎生成加解密代码。在加密程序中,使用虚拟机执行随机加密算法字节码,在解密体中使用虚拟机执行随机解密算法字节码。
polycypt的编译与使用
目前只是一个基础的版本,算法的变形力度不够,以下是简单的帮助。
- pcvm 虚拟机
- pcasm 汇编器
- polycypt 算法变形引擎
其中为了进行测试,使用了 "xxx_main.cpp",进行外部测试。可单独编译成库进行使用。
使用polycypt随机生成加解密算法,执行
polycypt -t template_path result_dir 命令。
在result_dir中生成4个文件encrypt.asm,decrypt.asm,encrypt.pbc,decrypt.pbc,其中.asm文件是生成的汇编源代码,用于查看。.pbc是编译后的字节码文件。用pcvm进行执行。
template_path是模版路径,用于算法支持。<可选项>
pcvm编译与使用
编译pcvm时导入以下文件:
1. pcfile.h
2. pcvm.h
3. pcvm.cpp
4. pcvm_main.cpp
调试器开启
if (vm.run((unsigned char*)codes, codesize, entry, false) == false) {printf("error : %d\n", vm.error());}
虚拟机的run接口最后一个参数,如果设置为true则启动调试器模式。运行后会出现一个简单的调试器如下:
调试只有三条指令
- c 继续运行
- q 退出
- h 帮助
使用命令
usage: pcvm [options] <bytecode file>-d disasm-i <port> <file> bind input io to file-o <port> <file> bind output io to file
pcasm编译与使用
编译pcasm时导入以下文件:
1. pcfile.h
2. pcvm.h
3. pcasm.h
4. pcasm.cpp
5. pcvm_main.cpp
使用命令
usage: pcasm <asm file> [out file]
polycypt编译与使用
编译polycryt时导入以下文件:
1. pcfile.h
2. pcasm.h
3. pcasm.cpp
4. pcasm.cpp
5. polycypt_alg0.cpp
6. polycypt_alg0.h
7. polycypt_error.h
8. polycypt_factory.cpp
9. polycypt_factory.h
10. polycypt.cpp
11. polycypt.h
12. polycypt_main.cpp
使用命令
usage: polycypt [options] <output path>-t <template dir path>
虚拟机的设计与实现
这里的虚拟机设定不必太过于复杂,因为我们要达到的目的就是做基本的算术运算。可以控制一些基本流程。但是一些辅助操作还是要考虑,例如:虚拟机对外的数据的读入与输出。所以我也并没有费太多时间,核心的源文件也只有一个pcvm.cpp,想要嵌入到自己的代码中,只需要使用这个文件即可。
pcvm类的结构说明
我们首先按照重要程度来分析一下pcvm这个类。
class pcvm {public:pcvm();virtual ~pcvm();public:/* 字节序确定,但在这个版本中并没什么卵用(估计以后也不会支持) */static bool is_big_endian();/* 调试支持,用于调试PCVM */#ifdef SUPPORT_DEBUGER/* 反汇编指定缓存代码 */bool disasm_all(unsigned char *buf, size_t bufsize);#endif/* 从偏移entry_offset处运行codes缓存中cs个字节长的代码* 这里支持一个调试选项如果将debug设置为true,则运行起来* 后会启动一个简单的调试器的控制台 */bool run(const unsigned char *codes,size_t cs,unsigned entry_offset=0#ifdef SUPPORT_DEBUGER,bool debug=false#endif);/* 以下八个函数,用于设定与获取外部数据的流 */bool set_input_io(int io, unsigned char *stream);bool set_output_io(int io, unsigned char *stream);bool set_input_io_size(int io, size_t size);bool set_output_io_size(int io, size_t size);unsigned char *get_input_io(int io);unsigned char *get_output_io(int io);size_t get_input_io_size(int io);size_t get_output_io_size(int io);/* 获取出错函数 */int error();private:/* 重置整个虚拟机 */void reset();/* 执行指令ins */bool call(unsigned ins);/* 以下三个函数都是与获取寄存器相关的 */bool invalid_register(int i);bool registers(int i, unsigned &v, bool four=false);bool set_registers(int i, unsigned r, bool four=false);/* 读取与写入数据到指定的内存地址 */bool read_memory(unsigned char *address, unsigned char *v);bool write_memory(unsigned char *address, unsigned v);/* 读取一条指令 */bool readi(unsigned &i);/* 判定偏移是否合法 */bool invalid_offset(unsigned off);/* 通过偏移计算地址 */bool calc_address(unsigned off, unsigned **addr);/* 与设置与获取字节序相关 */unsigned short get_te16(unsigned char *address);unsigned int get_te32(unsigned char *address);void set_te16(unsigned char *address, unsigned short v);void set_te32(unsigned char *address, unsigned v);/* 当虚拟机解释指令时,会将指令拆解成8种模式,无论指令再多* 模式就这8种。这些函数会在指令执行函数中进行调用。*/bool handle_ins_mode_op(unsigned ins, unsigned &op);bool handle_ins_mode_op_imm(unsigned ins, unsigned &op,unsigned &imm);bool handle_ins_mode_op_reg(unsigned ins, unsigned &op,unsigned ®);bool handle_ins_mode_op_reg_imm(unsigned ins, unsigned &op,unsigned ®, unsigned &imm);bool handle_ins_mode_op_reg_reg(unsigned ins, unsigned &op,unsigned ®1, unsigned ®2);bool handle_ins_mode_op_mem_imm(unsigned ins, unsigned &op,unsigned **address,unsigned &imm);bool handle_ins_mode_op_mem_reg(unsigned ins, unsigned &op,unsigned **address,unsigned ®);bool handle_ins_mode_op_mem_mem(unsigned ins, unsigned &op,unsigned **address1,unsigned **address2);/* 将4字节的整数指令转换成对应的模式结构 */bool ins_2_opocde_mode(unsigned ins,unsigned &opcode,unsigned &mode);bool ins_2_mode_op(unsigned ins, pcvm_ins_mode_op &mode);bool ins_2_mode_op_imm(unsigned ins, pcvm_ins_mode_op_imm &mode);bool ins_2_mode_op_reg(unsigned ins, pcvm_ins_mode_op_reg &mode);bool ins_2_mode_op_reg_imm(unsigned ins,pcvm_ins_mode_op_reg_imm &mode);bool ins_2_mode_op_reg_reg(unsigned ins,pcvm_ins_mode_op_reg_reg &mode);bool ins_2_mode_op_mem_imm(unsigned ins,pcvm_ins_mode_op_mem_imm &mode);bool ins_2_mode_op_mem_reg(unsigned ins,pcvm_ins_mode_op_mem_reg &mode);bool ins_2_mode_op_mem_mem(unsigned ins,pcvm_ins_mode_op_mem_mem &mode);/* 指令执行 */bool iMOV(unsigned ins, unsigned mode);bool iPUSH(unsigned ins, unsigned mode);bool iPOP(unsigned ins, unsigned mode);... 略去/* 下面是支持调试器的辅助函数 */#ifdef SUPPORT_DEBUGERvoid show_dbg_info();bool disasm(unsigned ins, std::string &out);void debugger(unsigned curr_ip);#endifprivate:/* 寄存器组 */unsigned _registers[PCVM_REG_NUMBER];/* 标志寄存器 */pcvm_flags_register _flags;/* 整个内存空间 */unsigned char *_space;/* 字节码在内存中的位置 */unsigned char *_code;/* 栈在内存中的位置 */unsigned char *_stack;/* 代码长度 */size_t _code_size;/* 栈长度 */size_t _stack_size;/* 指令执行函数队列 */ins_handle_fptr _handles[PCVM_OP_NUMBER];/* 输入与输出流设定 */unsigned char *_io_input[PCVM_IO_INPUT_NUMBER];unsigned char *_io_output[PCVM_IO_OUTPUT_NUMBER];size_t _io_input_size[PCVM_IO_INPUT_NUMBER];size_t _io_output_size[PCVM_IO_OUTPUT_NUMBER];/* 关机标志 */bool _shutdown;/* 字节序判定 */bool _is_big_endian;/* 出错代码 */int _error;};
我想在看过以上代码之后,大概这个虚拟机是什么样子的,上面的注释已经描述的比较清晰了。随后会针对一些核心功能进行详细介绍。
I/O设定
在上述代码中有一组这样的函数。
/* 以下八个函数,用于设定与获取外部数据的流 */bool set_input_io(int io, unsigned char *stream);bool set_output_io(int io, unsigned char *stream);bool set_input_io_size(int io, size_t size);bool set_output_io_size(int io, size_t size);unsigned char *get_input_io(int io);unsigned char *get_output_io(int io);size_t get_input_io_size(int io);size_t get_output_io_size(int io);
这几个函数是用于设定虚拟机对外数据的输入与输出的。在运行虚拟代码之前,可以通过上述函数要输入或者输出的数据,并使用get*_io函数获取输入或输出内容,如果要获取其对应的长度则使用get*_io_size。在后边指令解析有一组中断指令int 0,int 1,int 2,int 3来完成以上设定。
寄存器说明
在文件pcvm.h的13-31行,定义了以下枚举体,用来描述虚拟机的寄存器设定。
enum PCVM_REG {PCVM_REG_IP, /* 地址寄存器 */PCVM_REG_SB, /* 栈基寄存器 */PCVM_REG_SP, /* 栈指针寄存器 */PCVM_REG_RET, /* 返回地址寄存器 */PCVM_REG_R4, /* 通用寄存器 */PCVM_REG_R5, /* 通用寄存器 */PCVM_REG_R6, /* 通用寄存器 */PCVM_REG_R7, /* 通用寄存器 */PCVM_REG_R8, /* 通用寄存器 */PCVM_REG_R9, /* 通用寄存器 */PCVM_REG_R10, /* 通用寄存器 */PCVM_REG_R11, /* 通用寄存器 */PCVM_REG_R12, /* 通用寄存器 */PCVM_REG_R13, /* 通用寄存器 */PCVM_REG_R14, /* 通用寄存器 */PCVM_REG_R15, /* 通用寄存器 */PCVM_REG_NUMBER};
总共有16个寄存器,但是其实算法变形引擎并不需要这么多,起初我直接设定是256个寄存器,最后发现实在没那个必要。其中前4个寄存器都有特殊的功能。
标志寄存器说明
在文件pcvm.h142-149行中中定义了一个结构:
typedef struct {unsigned int C : 1;unsigned int Z : 1;unsigned int S : 1;unsigned int O : 1;unsigned int A : 3;unsigned int reserve : 25;} pcvm_flags_register;
其实在虚拟机实际执行过程中并没有全部用到这些标志,因为此虚拟机毕竟不是要支持多复杂的语言来设计的,本着够用的原则先凑合着吧。再者其实在这个引擎中,这个标志位的设计有些画蛇添足了。自己做的虚拟机并不一定要完全模拟现实中机器的一些特性设定。只是为了程序可以顺利运行而做的设计,再者就是之前受真实的机器的影响在写程序时自然就这样写了一个结构。
| 标志 | 意义 |
|---|---|
| C | 运算结果是否产生进位 |
| Z | 运算结果是否为0 |
| S | 为1,则操作数值为有符号运算,0为无符号运算 |
| O | 溢出位,但是貌似并没有使用 |
| A | 取值为1,2,3,分别对应的1字节访问,2字节访问,4字节访问 |
内存读取与写入
这里首先看两个函数
读内存
bool pcvm::read_memory(unsigned char *address, unsigned char *v) {/* 访问寄存器如果为1,则使用1字节读取 */if (_flags.A == 1) {*v = *address;}/* 访问寄存器如果为2,则使用2字节读取 */else if (_flags.A == 2) {*(unsigned short*)v = get_te16(address);}/* 访问寄存器如果为3,则使用4字节读取 */else if (_flags.A == 3) {*(unsigned int *)v = get_te32(address);}else {_error = PCVM_ERROR_INVALID_FLAG_A;return false;}return true;}
与写内存
bool pcvm::write_memory(unsigned char *address, unsigned v) {/* 访问寄存器如果为1,则使用1字节写入 */if (_flags.A == 1) {*address = (unsigned char)(v & 0xFF);}/* 访问寄存器如果为2,则使用2字节写入 */else if (_flags.A == 2) {set_te16(address, (unsigned short)(v & 0xFFFF));}/* 访问寄存器如果为3,则使用4字节写入 */else if (_flags.A == 3) {set_te32(address, v);}else {_error = PCVM_ERROR_INVALID_FLAG_A;return false;}return true;}
因为是一个简单的虚拟机所以并未涉及更多的指令,只是简单的使用了标志寄存器来控制内存的访问粒度。
内存地址计算
通过以下函数可知pcvm的地址管理并不是十分的严谨。但是足够了。由于当指令访问内存时只可以通过寄存器中保存的偏移来计算内存地址。例如:
mov [r1], 5,那么[]中只可以是寄存器,不能是其他的。造成这种原因是因为我想把指令放到4字节内而不想做更复杂的处理。
bool pcvm::calc_address(unsigned off, unsigned **addr){/* 首先检测偏移是否正确 */if (invalid_offset(off)) {_error = PCVM_ERROR_INVALID_ADDRESS;return false;}/* _space就是虚拟机执行的内存空间的起始地址 */*addr = reinterpret_cast<unsigned*>(_space + off);return true;}
OPCODE编码
在pcvm.h中的33-60行。定义了一个枚举体。
enum PCVM_OP {PCVM_OP_MOV, /* 数据移动指令 */PCVM_OP_PUSH, /* 压栈指令 */PCVM_OP_POP, /* 弹栈指令 */PCVM_OP_CMP, /* 对比指令 */PCVM_OP_CALL, /* 调用函数指令 */PCVM_OP_RET, /* 返回指令 */PCVM_OP_JMP, /* 跳转指令 */PCVM_OP_JE, /* 结果为0则指令 */PCVM_OP_JNE, /* 结果不为0指令 */PCVM_OP_JB, /* 小于则跳转指令 */PCVM_OP_JA, /* 大于则跳转指令 */PCVM_OP_JBE, /* 小于等于则跳转指令 */PCVM_OP_JAE, /* 大于等于则跳转指令 */PCVM_OP_AND, /* 与指令 */PCVM_OP_OR, /* 或指令 */PCVM_OP_NOT, /* 非指令 */PCVM_OP_ADD, /* 加法指令 */PCVM_OP_SUB, /* 减法指令 */PCVM_OP_MUL, /* 乘法指令 */PCVM_OP_DIV, /* 除法指令 */PCVM_OP_MOD, /* 取模指令 */PCVM_OP_SHL, /* 左移指令 */PCVM_OP_SHR, /* 右移指令 */PCVM_OP_INT, /* 中断指令 */PCVM_OP_NOP, /* 空指令指令 */PCVM_OP_NUMBER};
这里列出了这个虚拟机的所有指令,只有25条。最基本的流程控制欲算术指令。有一个INT指令。对于不同的参数进行不同操作。这些指令基本可以完成变形引擎的基础需求。
指令编码详解
在这节中主要探讨指令的具体执行流程。首先让我们探讨一下pcvm的指令编码的8种模式。
在pcvm.h的72-82行中定义了下列枚举体。用来解释指令的编码。
enum PCVM_INS_MODE {PCVM_INS_MODE_OP, /* opcode */PCVM_INS_MODE_OP_IMM, /* opcode imm */PCVM_INS_MODE_OP_REG, /* opcode reg */PCVM_INS_MODE_OP_REG_IMM, /* opcode reg, imm */PCVM_INS_MODE_OP_REG_REG, /* opcode reg, reg */PCVM_INS_MODE_OP_MEM_IMM, /* opcode mem, imm */PCVM_INS_MODE_OP_MEM_REG, /* opcode mem, reg */PCVM_INS_MODE_OP_MEM_MEM, /* opcode mem, mem */PCVM_INS_MODE_NUMBER};
此虚拟机的一条指令固定4字节,32位。下表列出了以上8种模式的字节编码:
| 模式名称 | 编码 | 举例说明 |
|---|---|---|
| PCVM_INS_MODE_OP | 5:opcode,3:mode,24:- | nop |
| PCVM_INS_MODE_OP_IMM | 5:opcode,3:mode,4:-,20:imm | push 5 |
| PCVM_INS_MODE_OP_REG | 5:opcode,3:mode,4:reg,20:- | pop r6 |
| PCVM_INS_MODE_OP_REG_IMM | 5:opcode,3:mode,4:reg,20:imm | mov r4, 1 |
| PCVM_INS_MODE_OP_REG_REG | 5:opcode,3:mode,4:reg1,4:reg2,16:- | mov r4,r5 |
| PCVM_INS_MODE_OP_MEM_IMM | 5:opcode,3:mode,4:reg,20:imm | mov [r2], 3 |
| PCVM_INS_MODE_OP_MEM_REG | 5:opcode,3:mode,4:reg1,4:reg2,16:- | mov [r3], r2 |
| PCVM_INS_MODE_OP_MEM_MEM | 5:opcode,3:mode,4:reg1,4:reg2,16:- | mov [r3], [r2] |
同样还定义了一组结构体用来记录解码后的信息,类似如下:
typedef struct {unsigned int opcode : 5;unsigned int mode : 3;unsigned int reserve : 24;} pcvm_ins_mode_op;typedef struct {unsigned int opcode : 5;unsigned int mode : 3;unsigned int reserve : 4;unsigned int imm : 20;} pcvm_ins_mode_op_imm;...省略
这里定义了一组函数来将一个4字节的整数转换成上述的结构体。
bool ins_2_opocde_mode(unsigned ins, unsigned &opcode,unsigned &mode);bool ins_2_mode_op(unsigned ins, pcvm_ins_mode_op &mode);bool ins_2_mode_op_imm(unsigned ins, pcvm_ins_mode_op_imm &mode);...省略
因为每条指令的模式都存在两种字段opcode与mode,所以无论后面的函数在执行后第一个调用的函数就是ins_2_opocde_mode,由它来解析指令。
bool pcvm::ins_2_opocde_mode(unsigned ins,unsigned & opcode,unsigned & mode) {/* 通过位移来获取拆解整数 */opcode = ins >> 27;mode = (ins >> 24) & 0x07;/* 验证opcode合法性 */if (opcode >= PCVM_OP_NUMBER) {_error = PCVM_ERROR_INVALID_OPCODE;return false;}/* 验证mode合法性 */if (mode >= PCVM_INS_MODE_NUMBER) {_error = PCVM_ERROR_INVALID_MODE;return false;}return true;}
其余的解码函数都要首先调用以上的函数并填充解码结构。这里使用ins_2_mode_op_reg_imm来讲解,其余几个函数都与之类似。
bool pcvm::ins_2_mode_op_reg_imm(unsigned ins,pcvm_ins_mode_op_reg_imm & mode) {unsigned op = 0, mod = 0;/* 解析出opcode与mode */if (ins_2_opocde_mode(ins, op, mod) == false) return false;/* 填充解码结构 */mode.opcode = op;mode.mode = mod;mode.reg = (ins >> 20) & 0x0F;mode.imm = ins & 0xFFFFF;return true;}
解码处理函数
定义了8个函数,具体的指令执行函数就是执行这些函数来获取自己所需的信息。命名规范为handle_ins_mode_xxx,它们是一组外层函数其内还是调用ins_2_mode_xxx来实现。这里就不一一说明了。
bool handle_ins_mode_op(unsigned ins, unsigned &op);bool handle_ins_mode_op_imm(unsigned ins, unsigned &op,unsigned &imm);...省略
这里有几个与内存相关的函数在调用ins_2_mode_xxx进一步的对内存地址进行核算。
算术指令
关于算术指令的处理模式都大致相同一共有5种。其中iNOT是个特例,因为它只有not reg一种模式。随后再对它进行分析
| 模式 |
|---|
| 算术指令 reg, imm |
| 算术指令 reg, reg |
| 算术指令 mem, imm |
| 算术指令 mem, reg |
| 算术指令 mem, mem |
下表列出了所有算术指令。
| 指令函数 |
|---|
| iAND |
| iOR |
| iNOT |
| iADD |
| iSUB |
| iMUL |
| iDIV |
| iMOD |
| iSHL |
| iSHR |
这里以iADD为例做解释:
bool pcvm::iADD(unsigned ins, unsigned mode) {unsigned v1 = 0, v2 = 0;unsigned opcode = 0;/* 判断模式是否是add reg, imm */if (mode == PCVM_INS_MODE_OP_REG_IMM) {unsigned reg = 0, imm = 0;/* 从中取出reg与imm的具体值 */if (handle_ins_mode_op_reg_imm(ins, opcode, reg, imm) == false)return false;/* 将reg中的值读取出来到v1 */if (registers(reg, v1) == false) return false;/* 将imm写入到v2的值中 */if (write_memory(reinterpret_cast<unsigned char*>(&v2), imm) == false)return false;/* 如果S标志被设置,那么作为有符号数进行计算 */if (_flags.S) {int v1_ = (int)v1;int v2_ = (int)v2;v1_ += v2_;v1 = (unsigned)v1_;}/* 作为无符数直接进行计算 */else {v1 += v2;}/* 将结果设置到reg处 */if (set_registers(reg, v1) == false) return false;}/* 处理add reg, reg模式 */else if (mode == PCVM_INS_MODE_OP_REG_REG) {unsigned reg1 = 0, reg2 = 0;/* 从ins中取出opcode,以及两个寄存器的索引 */if (handle_ins_mode_op_reg_reg(ins, opcode, reg1, reg2) == false)return false;/* 读取出两个寄存器的值 */if (registers(reg1, v1) == false) return false;if (registers(reg2, v2) == false) return false;/* 查看符号标志位* 如果是有符号位则进行类型转换*/if (_flags.S) {int v1_ = (int)v1;int v2_ = (int)v2;v1_ += v2_;v1 = (unsigned)v1_;}else {v1 += v2;}/* 设置寄存器的值 */if (set_registers(reg1, v1) == false) return false;}/* 处理add [mem], imm模式 */else if (mode == PCVM_INS_MODE_OP_MEM_IMM) {unsigned *address = nullptr, imm = 0;/* 取出opcode,要访问的地址以及立即数 */if (handle_ins_mode_op_mem_imm(ins, opcode, &address, imm) == false)return false;/* 取出立即数并写入到v2临时变量中 */if (write_memory(reinterpret_cast<unsigned char*>(&v2), imm) == false)return false;/* 从address的地址中取出数值 */if (write_memory(reinterpret_cast<unsigned char*>(&v1), *address) == false)return false;/* 按照符号进行处理 */if (_flags.S) {int v1_ = (int)v1;int v2_ = (int)v2;v1_ += v2_;v1 = (unsigned)v1_;}else {v1 += v2;}/* 最终把结果写入到address指向的地址中 */if (write_memory(reinterpret_cast<unsigned char*>(address), v1) == false)return false;}/* 处理add [mem], reg模式 */else if (mode == PCVM_INS_MODE_OP_MEM_REG) {unsigned *address = nullptr, reg = 0;/* 从ins中取出opcode, address以及要操作的寄存器 */if (handle_ins_mode_op_mem_reg(ins, opcode, &address, reg) == false)return false;/* 从address指向的内存中取出数值 */if (write_memory(reinterpret_cast<unsigned char*>(&v1), *address) == false)return false;/* 从寄存器中读取出值 */if (registers(reg, v2) == false)return false;/* 按照符号寄存器进行运算 */if (_flags.S) {int v1_ = (int)v1;int v2_ = (int)v2;v1_ += v2_;v1 = (unsigned)v1_;}else {v1 += v2;}/* 将结果写入到address指向的内存中 */if (write_memory(reinterpret_cast<unsigned char*>(address), v1) == false)return false;}/* 处理add [mem1], [mem2]模式 */else if (mode == PCVM_INS_MODE_OP_MEM_MEM) {unsigned *address1 = nullptr, *address2 = nullptr;/* 从指令中取出两个要操作的地址 */if (handle_ins_mode_op_mem_mem(ins, opcode, &address1, &address2) == false)return false;/* 从两个地址中取出数值 */if (write_memory(reinterpret_cast<unsigned char*>(&v1), *address1) == false)return false;if (write_memory(reinterpret_cast<unsigned char*>(&v2), *address2) == false)return false;/* 按照符号寄存器进行计算 */if (_flags.S) {int v1_ = (int)v1;int v2_ = (int)v2;v1_ += v2_;v1 = (unsigned)v1_;}else {v1 += v2;}/* 将结果写入到address1指向的内存中 */if (write_memory(reinterpret_cast<unsigned char*>(address1), v1) == false)return false;}else {_error = PCVM_ERROR_INVALID_MODE;return false;}return true;}
基本算术指令都是按照这个流程来运行的,只是最后的具体运算不同而已。唯一不同的是NOT指令。它只有一种模式就是对寄存器中的值做非运算,见下代码:
bool pcvm::iNOT(unsigned ins, unsigned mode){unsigned opcode = 0;/* 处理 not reg */if (mode == PCVM_INS_MODE_OP_REG) {unsigned reg = 0, value = 0;/* 从ins中取出opcode以及reg */if (handle_ins_mode_op_reg(ins, opcode, reg) == false)return false;/* 做NOT操作 */if (registers(reg, value) == false) return false;if (set_registers(reg, ~value) == false) return false;}else {_error = PCVM_ERROR_INVALID_MODE;return false;}return true;}
数据转移指令
下表列出了所有数据转移指令。
| 指令函数 |
|---|
| MOV |
| PUSH |
| POP |
首先看一下著名的MOV:
bool pcvm::iMOV(unsigned ins, unsigned mode) {unsigned opcode = 0;/* 处理 mov reg, imm */if (mode == PCVM_INS_MODE_OP_REG_IMM) {unsigned reg = 0, imm = 0;if (handle_ins_mode_op_reg_imm(ins, opcode, reg, imm) == false)return false;/* 最后直接设置立即数到指定的寄存器 */return set_registers(reg, imm);}/* mov reg,reg */else if (mode == PCVM_INS_MODE_OP_REG_REG) {unsigned reg1 = 0, reg2 = 0;if (handle_ins_mode_op_reg_reg(ins, opcode, reg1, reg2) == false)return false;unsigned v = 0;/* 从源寄存器中读取设置到目的寄存器中 */if (registers(reg2, v) == false) return false;return set_registers(reg1, v);}/* 此处省略吧 !!!* 剩下的就是其余的处理*/}
压栈操作,压栈只能处理两种模式,push imm以及push reg
bool pcvm::iPUSH(unsigned ins, unsigned mode) {unsigned opcode = 0;/* 压栈,首先读取当前栈寄存器的值,然后减去一个4字节(32位系统) */unsigned offset = _registers[PCVM_REG_SP] - sizeof(unsigned);/* push imm */if (mode == PCVM_INS_MODE_OP_IMM) {unsigned imm = 0;if (handle_ins_mode_op_imm(ins, opcode, imm) == false)return false;/* 校验偏移是否有效 */if (invalid_offset(offset)) {_error = PCVM_ERROR_INVALID_ADDRESS;return false;}/* 通过offset计算虚拟内存的地址 */unsigned *address = nullptr;if (calc_address(offset, &address) == false) return false;/* 写入到内存 */if (write_memory(reinterpret_cast<unsigned char*>(address), imm) == false)return false;}/* push reg */else if (mode == PCVM_INS_MODE_OP_REG) {/* 省略了... 与之前大同小异 */}else {_error = PCVM_ERROR_INVALID_MODE;return false;}/* 重新设置栈寄存器的指针 */_registers[PCVM_REG_SP] -= sizeof(unsigned);return true;}
弹栈操作,只能处理一种模式pop reg
bool pcvm::iPOP(unsigned ins, unsigned mode) {unsigned opcode = 0;/* pop reg */if (mode == PCVM_INS_MODE_OP_REG) {unsigned reg = 0;if (handle_ins_mode_op_reg(ins, opcode, reg) == false)return false;/* 取出当前栈指向的偏移并转换成地址 */unsigned offset = _registers[PCVM_REG_SP];if (invalid_offset(offset)) {_error = PCVM_ERROR_INVALID_ADDRESS;return false;}unsigned *address = nullptr;if (calc_address(offset, &address) == false) return false;/* 从栈地址中读取出值并设置给寄存器 */if (set_registers(reg, *address) == false) return false;}else {_error = PCVM_ERROR_INVALID_MODE;return false;}/* 最后移动栈指针 */_registers[PCVM_REG_SP] += sizeof(unsigned);return true;}
流程控制指令
下表列出了所有流程指令。
| 指令函数 |
|---|
| CALL |
| RET |
| JMP |
| JE |
| JNE |
| JB |
| JA |
| JBE |
| JAE |
除了跳转指令,使用cmp指令来判定流程走向。
cmp指令
可以处理以下几种模式,cmp reg, imm,cmp reg, reg,cmp mem, imm,cmp mem, reg,cmp mem, mem。
bool pcvm::iCMP(unsigned ins, unsigned mode) {/* ...以下代码忽略,其意思就是从各种模式中取出数据 *//* 最后的值相减 */int res = static_cast<int>(v1) - static_cast<int>(v2);/* 最后设置一些标志位 */if (res == 0) _flags.Z = 1; else _flags.Z = 0;if (res < 0) _flags.C = 1; else _flags.C = 0;return true;}
各种跳转指令
这里只列出一些有代表意义的,例如CALL,RET与JMP其余的判定跳转只是在JMP的基础上增加了标志位判定而已。
call指令
这个指令只能处理两种模式call imm与call reg。代码分析如下:
bool pcvm::iCALL(unsigned ins, unsigned mode) {/** 得到返回地址栈的偏移*/unsigned offset = _registers[PCVM_REG_SP] - sizeof(unsigned);if (invalid_offset(offset)) {_error = PCVM_ERROR_INVALID_ADDRESS;return false;}/* 通过偏移得到地址 */unsigned *address = nullptr;if (calc_address(offset, &address) == false) return false;/*将当前的地址也就是call指令的后一条指令的地址写入到返回地址栈*/unsigned next_address = _registers[PCVM_REG_IP];if (write_memory(reinterpret_cast<unsigned char*>(address), next_address) == false)return false;unsigned opcode = 0, jmpto = 0;/* call imm模式 */if (mode == PCVM_INS_MODE_OP_IMM) {unsigned imm = 0;if (handle_ins_mode_op_imm(ins, opcode, imm) == false)return false;jmpto = imm;}/* call reg模式 */else if (mode == PCVM_INS_MODE_OP_REG) {unsigned reg = 0, imm;if (handle_ins_mode_op_reg(ins, opcode, reg) == false)return false;/* 从寄存器中读取出偏移 */if (registers(reg, imm, true) == false) return false;jmpto = imm & 0xFFFFF;}else {_error = PCVM_ERROR_INVALID_MODE;return false;}/* 设定栈与调用地址 */_registers[PCVM_REG_IP] = jmpto;_registers[PCVM_REG_SP] = offset;return true;}
ret指令
好吧,到了返回指令了,也很简单从栈中取出返回地址设定IP寄存器即可。
bool pcvm::iRET(unsigned ins, unsigned mode) {/** 把偏移从栈中弹出*/unsigned offset = _registers[PCVM_REG_SP];if (invalid_offset(offset)) {_error = PCVM_ERROR_INVALID_ADDRESS;return false;}unsigned *address = nullptr;/* 通过偏移计算地址 */if (calc_address(offset, &address) == false) return false;/* 取出最后的返回地址 */_registers[PCVM_REG_IP] = *address;/* 将栈恢复 */_registers[PCVM_REG_SP] = offset + sizeof(unsigned);return true;}
jmp指令
处理两种模式jmp imm与jmp reg。其中寄存器与立即数保存的都直接是地址,取出后直接设置给IP寄存器即可,这里没按照现实计算机的偏移原则是因为觉得实在没有必要弄那么复杂,而虚拟机的内存已经限定在了1MB内,所以直接使用地址即可。
bool pcvm::iJMP(unsigned ins, unsigned mode){unsigned opcode = 0, address = 0;/* jmp imm */if (mode == PCVM_INS_MODE_OP_IMM) {unsigned imm = 0;if (handle_ins_mode_op_imm(ins, opcode, imm) == false)return false;address = imm;}/* jmp reg */else if (mode == PCVM_INS_MODE_OP_REG) {unsigned reg = 0, imm;if (handle_ins_mode_op_reg(ins, opcode, reg) == false)return false;if (registers(reg, imm, true) == false) return false;address = imm & 0xFFFFF;}else {_error = PCVM_ERROR_INVALID_MODE;return false;}/* 设定跳转地址 */_registers[PCVM_REG_IP] = address;return true;}
其余的条件跳转指令,只不过是增加了标志位判定而已。举个例子:
bool pcvm::iJE(unsigned ins, unsigned mode){/* 判定标志位是否为0 */if (_flags.Z == 0) {return true;}return iJMP(ins, mode);}
其余几个都大同小异而已。
中断指令
首先这里列出了各个中断的说明,其实说是中断也就是这样一个名字而已,使用这种设计减少了指令的个数,而且可以方便的扩展功能而已。
| 中断号 | 说明 |
|---|---|
bool pcvm::iINT(unsigned ins, unsigned mode){unsigned opcode = 0;if (mode == PCVM_INS_MODE_OP_IMM) {unsigned imm = 0;if (handle_ins_mode_op_imm(ins, opcode, imm) == false)return false;/* int 0* 从R4寄存器中取出输入端口号* 从R5寄存器中取出要读取数据的长度* 然后将数据写入到当前栈指针所指向的内存* 最后将长度写入到R4寄存器中*/if (imm == 0) {unsigned port = 0, size = 0;if (registers(PCVM_REG_R4, port) == false) return false;if (port >= PCVM_IO_INPUT_NUMBER) {_error = PCVM_ERROR_INVALID_IO_ACCESS;return false;}if (registers(PCVM_REG_R5, size) == false) return false;/* fixme: check size */unsigned offset = _registers[PCVM_REG_SP];if (invalid_offset(offset)) {_error = PCVM_ERROR_INVALID_ADDRESS;return false;}unsigned *address = nullptr;if (calc_address(offset, &address) == false) return false;if (_io_input[port] == nullptr) {_error = PCVM_ERROR_IO_NOT_BOUNAD;return false;}/* 写入数据 */memcpy(address, _io_input[port], size);if (set_registers(PCVM_REG_R4, size) == false) return false;}/* int 1* 从R4寄存器中取出输出端口号* 从R5寄存器中取出要写入数据的长度* 然后将当前栈指针所指向的内存的数据写入到端口的缓存中* 最后将长度写入到R4寄存器中*/else if (imm == 1) {unsigned port = 0, size = 0;if (registers(PCVM_REG_R4, port) == false) return false;if (port >= PCVM_IO_INPUT_NUMBER) {_error = PCVM_ERROR_INVALID_IO_ACCESS;return false;}if (registers(PCVM_REG_R5, size) == false) return false;/* fixme: check size */unsigned offset = _registers[PCVM_REG_SP];if (invalid_offset(offset)) {_error = PCVM_ERROR_INVALID_ADDRESS;return false;}unsigned *address = nullptr;if (calc_address(offset, &address) == false) return false;if (_io_output[port] == nullptr) {_error = PCVM_ERROR_IO_NOT_BOUNAD;return false;}memcpy(_io_output[port], address, size);if (set_registers(PCVM_REG_R4, size) == false) return false;}/* int 2* 从R4寄存器中读取出输入端口* 将指定的端口中存在多少个数据放入到R5中*/else if (imm == 2) {unsigned port = 0;if (registers(PCVM_REG_R4, port) == false) return false;if (port >= PCVM_IO_INPUT_NUMBER) {_error = PCVM_ERROR_INVALID_INT_PARAM;return false;}set_registers(PCVM_REG_R5, _io_input_size[port]);}/* int 3* 从R4寄存器中读取出输出端口* 将要写入多少个数据长度放入到指定输出端口保存长度中* 上层可以通过get_output_io_size(port)来获取这个长度*/else if (imm == 3) {unsigned port = 0, size = 0;if (registers(PCVM_REG_R4, port) == false) return false;if (port >= PCVM_IO_OUTPUT_NUMBER) {_error = PCVM_ERROR_INVALID_INT_PARAM;return false;}if (registers(PCVM_REG_R5, size) == false) return false;_io_output_size[port] = size;}/* int 4* 读取R4寄存器的值只可以是1,2,4。用来控制对数据的操作粒度* 1表示1字节,2表示2字节,4表示4字节。*/else if (imm == 4) {unsigned unit = 0;if (registers(PCVM_REG_R4, unit) == false) return false;if ((unit != 1) || (unit != 2) || (unit != 4)) {_error = PCVM_ERROR_INVALID_INT_PARAM;return false;}_flags.A = unit;}/* int 5* R4为大于0表示以后采用无符号计算* R4小于等于0则采用有有符号计算*/else if (imm == 5) {unsigned sign = 0;if (registers(PCVM_REG_R4, sign) == false) return false;_flags.S = !(sign > 0);}/* int 9* 直接关机*/else if (imm == 9) {_shutdown = true;}else {_error = PCVM_ERROR_INVALID_INT_NUMBER;return false;}}else {_error = PCVM_ERROR_INVALID_MODE;return false;}return true;}
虚拟机调试器
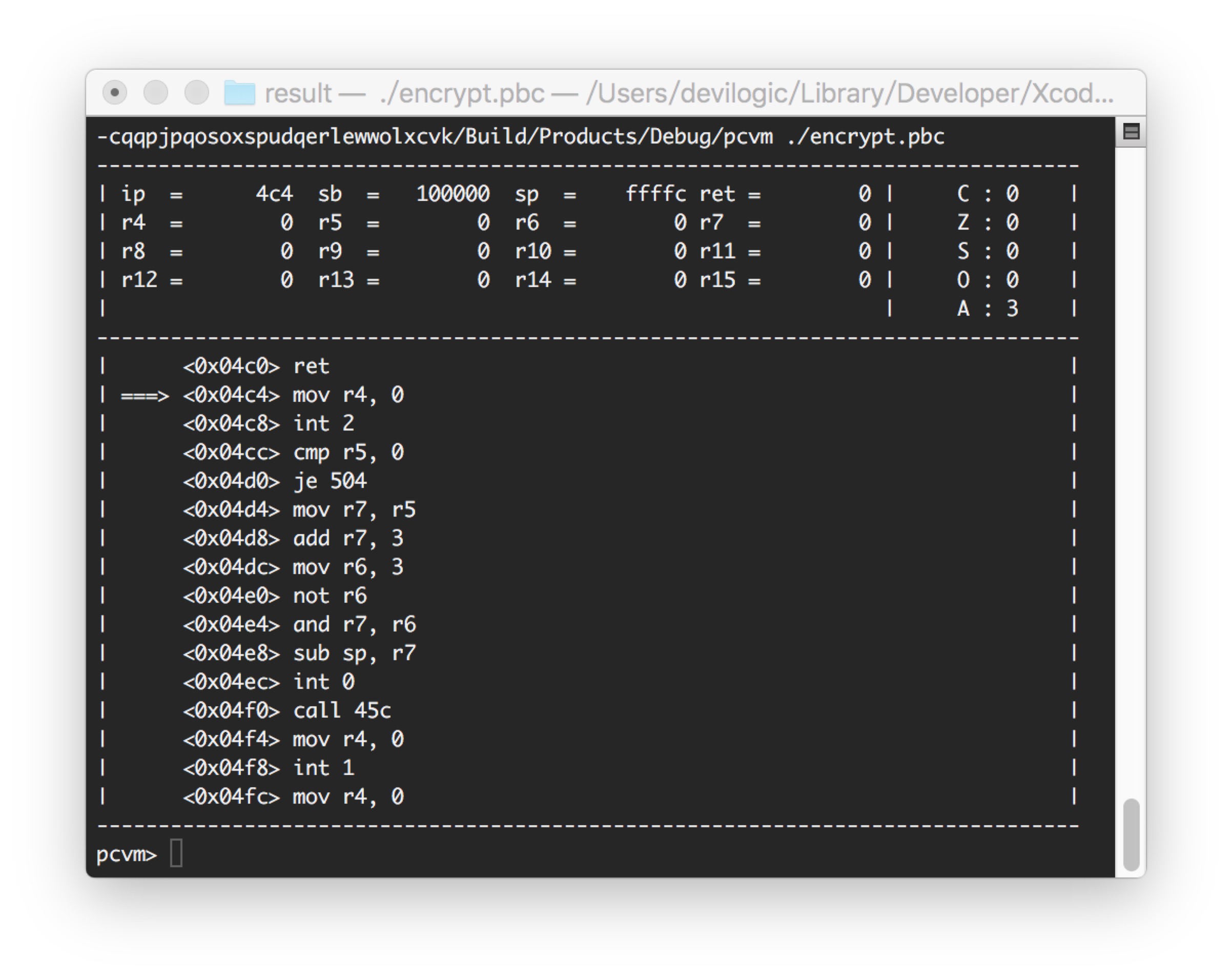
如果SUPPORT_DEBUGER宏开始,则虚拟机的整个代码会将调试器模块编译到其中。其主要入口函数为debugger。并在run函数中的循环中调用。
while (_shutdown == false) {/* 每在执行一条指令前首先进入调试器,如果调试模式开启的化。*/#ifdef SUPPORT_DEBUGERif (debug) {debugger(_registers[PCVM_REG_IP]);}#endifif (readi(ins) == false) {if (_error == PCVM_ERROR_OVER_CODE_SIZE_LIMIT) {_error = PCVM_ERROR_SUCCESS;return true;}return false;}if (call(ins) == false) return false;}return true;
每执行一次会弹出一个如下图所示的简单界面。
调试只有三条指令
- c 继续运行
- q 退出
- h 帮助
其实简单的排错够了。有兴趣的朋友直接读代码即可,实现很简单。
虚拟机汇编器的设计与实现
现在进入汇编器的代码分析,这个汇编器比较简单,不过汇编器一直都没复杂过。因为我并没有设计宏的概念,所以不涉及到什么语法上的处理。所以本汇编器,没有语法处理部分,就是使用词法处理将字符串转换成标记,按照每条指令可以处理的模式进行汇编。其中稍微麻烦一点的是需要将标签记录下来,以供当汇编完成后的重定位处理。
最后定义了一个很简单的文件格式将代码写入到其中。汇编器只有三份文件pcasm.h,pcasm.cpp,pcasm_main.cpp。
汇编器结构介绍
在pcasm.h中可以看到完整的汇编器所需的结构的定义。
标签定义,其中有两项,address是全局文件的地址。mode_address是当前模块的地址
typedef struct {unsigned address;unsigned mode_address;} pcasm_label;
重定位项的类型,其实只有一个其实就是基地址重定位,后边在链接一节中会详细说明。
enum {PCASM_REL_FIXLST20B,PCASM_REL_NUMBER};
重定位项结构,type其实只有一个值就是上面枚举体定义的。address是当前要重定位的地址。symbol是符号字符串,用于表明要重定位的是哪个标签。用于去符号表中进行查询。
typedef struct {int type;unsigned address;std::string symbol;} pcasm_relocate;
词法分析中所用到的标记结构,token表示标记的整型定义,这些值我在这个结构的后边列出了。text是标记的字面值结构,用于保存这个结构当前的值,例如一个字符串,一个整数,一个寄存器等等,用于后边的汇编。这里需要一点点编译原理的知识,其实如果往深里将,做软件保护壳和做一个编译器没什么区别,如果要做一个精品,需要以下一个流程。
其实把这个流程进行扩展可以完成一个二进制编译器。其实我一直想做一个这种程序,人生有很多无奈,从去年年底就开始计划写,由于每天要处理种种事情,所以并没有大量时间进行编写,虽然时间挤挤就有了,但是有时候还真挤不出来。
typedef struct {int token;pcasm_text text;} pcasm_token;enum {TOKEN_OP, /* OPCODE */TOKEN_REG, /* 寄存器 */TOKEN_IMM, /* 立即数 */TOKEN_DEF_LABEL, /* 定义标记 */TOKEN_REF_LABEL, /* 引用标记 */TOKEN_COLON, /* 冒号 */TOKEN_LPARAM, /* 左括号 */TOKEN_RPARAM, /* 右括号 */TOKEN_COMMA, /* 逗号 */TOKEN_INCLUDE, /* include文件包含 */TOKEN_STRING, /* 字符串 */TOKEN_EOF, /* 到达末尾了 */TOKEN_NUMBER /* 标记数量 */};
标记字面值,在token里的子结构,用于根据token的不同,提供不同的值对应。从下面字段中的名称就可以看出它们是对应哪些标记了。别告诉我,你看不懂,如果这样的话,你手中的这本书可以直接丢到书柜了。
typedef struct {unsigned opcode;std::string str;unsigned reg;unsigned imm;std::vector<unsigned char> data;} pcasm_text;
下面就是汇编器的主类定义,这里因为篇幅原因,将一些不重要的函数以及重复性过高的函数去掉了。
class pcasm {public:pcasm();virtual ~pcasm();/* 主流程入口 */bool compile(const std::string &asm_file, std::vector<unsigned char> &bytecodes, bool is_file=true);/* 汇编并做重定位处理 */bool make(const std::string &asm_file, std::vector<unsigned char> &bytecodes);/* 将代码写入到pc文件格式中 */bool make_pcfile(unsigned char *bytecodes, size_t bcsize, unsigned char **pcfile, size_t &pcfile_size);/* 获取当前出错代码 */int error();public:/* 初始化 */static void init();/* 链接操作,其实就是负责重定位 */static int pclink(std::vector<unsigned char> &bytecodes);/* 获得汇编好后代码的入口偏移 */static unsigned entry();private:/* 重新设定此类的所有数据 */void reset();/* 汇编成一条指令函数集合 */unsigned write_mode_op(unsigned opcode);unsigned write_mode_op_imm(unsigned opcode, unsigned imm);/* 省略... *//* 具体指令编译函数 */bool MOV_REG_LAB(unsigned opcode, std::vector<unsigned char> &bytecodes);bool MOV_MEM_LAB(unsigned opcode, std::vector<unsigned char> &bytecodes);/* 省略... */bool cMOV(std::vector<unsigned char> &bytecodes);/* 其余指令省略... *//* 处理包含文件标记 */bool cInclude(std::vector<unsigned char> &bytecodes);/* 定义一个标记 */bool cDefLabel(pcasm_token &token);/* 第一遍处理 */bool pass1();/* 第二遍处理 */bool pass2(std::vector<unsigned char> &bytecodes);/* 进行词法扫描 */bool scanner(pcasm_token &token);/* 进行汇编主入口 */bool parser(std::vector<unsigned char> &bytecodes);/* 设置出错代码 */void set_error(int err);/* 当前一组标记是否匹配 */bool match(std::vector<int> tokens);/* 增加地址 */bool plus_address(unsigned plus=sizeof(unsigned));private:/* 操作当前的字符串流 */bool teste();int readc();bool plusp(int plus=1);bool decp(int dec=1);/* 汇编操作集合 */int write_ins(int ins, std::vector<unsigned char> &bytecodes);int write_datas(const std::vector<unsigned char> &datas, std::vector<unsigned char> &bytecodes);int write_imm(unsigned data, std::vector<unsigned char> &bytecodes);int write_string(const std::string &str, std::vector<unsigned char> &bytecodes);/* 对词法标记的操作集合 */pcasm_token next_token();void rollback_token(int num = 1);/* 忽略... */};
首先让我们从compile开始吧。
bool pcasm::compile(const std::string & asm_file, std::vector<unsigned char> &bytecodes, bool is_file) {reset();/* 如果是文件,则读取文件 */if (is_file) {std::string source = s_read_file(asm_file);if (source == "") return false;_source = source;}else {/* 直接使用字符串作为源代码 */_source = asm_file;}/* 第一遍处理 */if (pass1() == false) return false;/* 第二遍处理 */if (pass2(bytecodes) == false) return false;return true;}
而make与make_pcfile只是对上面这个函数进行了进一步的封装而已。下面我们就来看下这两遍处理。
第一遍处理
bool pcasm::pass1(){pcasm_token token;_token_source.clear();/* 循环扫描源代码文本并将标记填充到_token_source向量中 */do {if (scanner(token) == false) {return false;}_token_source.push_back(token);} while (token.token != TOKEN_EOF);return true;}
第一遍处理的功能还是很明确,就是在填充一个由标记组成的队列。而scanner就是在返回词法标记而已。以下列出部分代码。
bool pcasm::scanner(pcasm_token &token){int c = 0;std::string str;/* 测试是否到达源代码末尾 */while (teste() == false) {/* 读取一个字符 */c = readc();/* 跳过空白符 */if ((c == ' ') || (c == '\t') || (c == '\r') || (c == '\n')) {continue;}/* 处理注释 */else if (c == ';') {do {c = readc();if (c == -1) {token.token = TOKEN_EOF;return true;}} while (c != '\n');continue;}switch (c) {/* 16进制数的读取 */case 'x':str.clear();do {c = readc();if (s_is_hexchar(c) == false) {decp();break;}str.push_back(c);} while (true);if (str.empty() == false) {char *hexptr = nullptr;token.text.imm = static_cast<unsigned>(strtol(str.c_str(), &hexptr, 16));token.token = TOKEN_IMM;return true;}else {_error = PCASM_ERROR_SCAN_INVALID_CHAR;return false;}break;/* 中间的部分省略了好多... *//* 关于标签的操作,这个是最复杂的一个了 */case '@':token.text.str.clear();/* 读取一个字符 */c = readc();if (c == -1) {_error = PCASM_ERROR_SCAN_QUOTATION_NOT_CLOSE;return false;}/* 如果当前字符是字母或者是下划线* 继续读取,标签只允许字母,数字,下划线* 并且只能以下划线与字母开头*/if ((isalpha(c)) || (c == '_')) {int len = 1;while ((c == '_') || isalnum(c)) {if (len >= PCASM_MAX_LABEL) {_error =PCASM_ERROR_SCAN_LABNAME_OVER_LIMIT;_errstr = token.text.str;return false;}token.text.str.push_back(c);c = readc();len++;}/* 如果标号名后接一个冒号则视为标号的定义 */if (c == ':') {token.token = TOKEN_DEF_LABEL;return true;}/* 如果仅是标号名则视为引用标号 */else {token.token = TOKEN_REF_LABEL;return true;}}break;default:_error = PCASM_ERROR_SCAN_NOT_MATCH_TOKEN_START_CHAR;return false;}}token.token = TOKEN_EOF;return true;}
第二遍处理
pass2这个函数只是一个外包装而已,忽略它,在它里面调用了pass2函数。这个函数主要就是从pass1压入的标记队列中,依次取出并且按照既定的规范开始进行汇编。
bool pcasm::parser(std::vector<unsigned char> &bytecodes){pcasm_token token;do {/* 取得下一个标记 */token = next_token();/* 遇到末尾则退出 */if (token.token == TOKEN_EOF) {break;}/* 遇到指令标记 */else if (token.token == TOKEN_OP) {/* 执行对应的指令汇编函数* _handles是一个私有变量,保存了各条指令的汇编函数指针* 直接从标记字面值中获取索引进行寻址。*/if ((this->*_handles[token.text.opcode])(bytecodes) == false)return false;/* 汇编一条指令则增加地址 */if (plus_address() == false) return false;}/* 遇到include标记则调用cInclude函数 */else if (token.token == TOKEN_INCLUDE) {if (cInclude(bytecodes) == false)return false;}/* 遇到标记定义 */else if (token.token == TOKEN_DEF_LABEL) {if (cDefLabel(token) == false)return false;}/* 遇到立即数 */else if (token.token == TOKEN_IMM) {if (plus_address(write_imm(token.text.imm, bytecodes)) == false)return false;}/* 遇到字符串 */else if (token.token == TOKEN_STRING) {if (plus_address(write_string(token.text.str, bytecodes)) == false)return false;}else {_error = PCASM_ERROR_SYNTAX_INCONFORMITY_TOKEN;return false;}} while (true);return true;}
指令地址
这里我设计了两个地址_address其实是模块内的地址,就是单一一个文件拥有的地址,还有一个s_address就是全局地址,是当链接成完整的一套字节码程序时的真实地址。在最初本想使用_address作为唯一的地址,然后在链接的阶段在做重定位并合成最后的地址,这样做更符合一个真实的链接器的过程,但是实在由于我太懒了,所以就偷工减料了。这里特别指出这些。
bool pcasm::plus_address(unsigned plus){/* 任意单一的模块不能超过1MB的空间 */if (s_address >= (1024 * 1024)) {_error = PCASM_ERROR_CODE_OVER_LIMIT;return false;}_address += plus; /* 全局的地址增加 */s_address += plus;return true;}
指令汇编
在汇编器类中定义一个变量ins_compile_fptr _handles[PCVM_OP_NUMBER];,它是一个函数指针队列,保存了每条指令的汇编函数。这个变量在pcasm::pcasm的构造函数中进行填充。
pcasm::pcasm(){reset();_handles[PCVM_OP_MOV] = &pcasm::cMOV;_handles[PCVM_OP_PUSH] = &pcasm::cPUSH;_handles[PCVM_OP_POP] = &pcasm::cPOP;_handles[PCVM_OP_CMP] = &pcasm::cCMP;_handles[PCVM_OP_CALL] = &pcasm::cCALL;/* 省略... */
其中cXXX函数,c表示compile,编译的意思,而后边跟的就是指令的名称。这里拿cMOV函数来举例,其余的指令与之基本相同。
bool pcasm::cMOV(std::vector<unsigned char> &bytecodes){if (MOV_REG_IMM(PCVM_OP_MOV, bytecodes) ||MOV_REG_REG(PCVM_OP_MOV, bytecodes) ||MOV_MEM_IMM(PCVM_OP_MOV, bytecodes) ||MOV_MEM_REG(PCVM_OP_MOV, bytecodes) ||MOV_MEM_MEM(PCVM_OP_MOV, bytecodes) ||MOV_REG_LAB(PCVM_OP_MOV, bytecodes) ||MOV_MEM_LAB(PCVM_OP_MOV, bytecodes)) {return true;}return false;}
以上函数的参数是汇编输出字节码的缓存队列,在函数中调用了一组MOV_XXX_YYY的一组函数,从函数名可以看出mov指令的语法结构。函数会依次进行调用,如果前者不为true则进入下一个。直到其中一个成功。让我们进入MOV_REG_IMM看看。
bool pcasm::MOV_REG_IMM(unsigned opcode, std::vector<unsigned char> &bytecodes){/* 语法: "mov reg, 12345" *//* 以下将此指令的模式压入一个tokens的队列 */std::vector<int> tokens;tokens.push_back(TOKEN_REG);tokens.push_back(TOKEN_COMMA);tokens.push_back(TOKEN_IMM);/* 以tokens为目标来检查当前的代码是否匹配 */if (match(tokens) == false) {_error = PCASM_ERROR_SYNTAX_NOT_MATCH_TOKEN;return false;}/* 如果语法匹配则调用对应的指令汇编函数合并成一个4字节 */int ins = write_mode_op_reg_imm(opcode, _text_stack[0].reg, _text_stack[2].imm);/* 最后将汇编好的指令ins写入到输出缓存bytecodes中 */write_ins(ins, bytecodes);return true;}
以上代码中,出现了一个_text_stack这样的变量来获取寄存器以及立即数的具体值,让我们先看下match函数的实现。
bool pcasm::match(std::vector<int> tokens){pcasm_token token;_text_stack.clear();_err_on_token = TOKEN_NUMBER;if (tokens.empty()) return false;int count = 0;/* 遍历我们的目标标记队列 */for (auto t : tokens) {count++;/* 计数标记 *//* 获取下一个标记 */token = next_token();/* 如果当前读取的标记与目标队列中取出的标记相同* 则将它的字面值压入到_text_stack中*/if (token.token == t) {_text_stack.push_back(token.text);}/* 如果没有匹配* 则调用rollback_token函数进行回退*/else {rollback_token(count);_text_stack.clear();_error = PCASM_ERROR_SYNTAX_NOT_MATCH_TOKEN;_err_on_token = t;return false;}}return true;}
以上函数当在标记不匹配的时候要将读取的标记再次压入到标记流中。
void pcasm::rollback_token(int num){if (_token_pos - num < 0) _token_pos = 0;else _token_pos -= num;}
以上函数实现也比较简单,就是将当前标记的位置变量_token_pos减少参数num个来完成标记流的回退。与之对应的是next_token函数。用于从标记流中获取标记。
pcasm_token pcasm::next_token(){if (_token_source.empty()) {pcasm_token token;token.token = TOKEN_NUMBER;return token;}/* 这里最重要的就是控制_token_pos的值以达到控制* 标记流的作用*/return _token_source[_token_pos++];}
当匹配完成后就是调用类似名为write_xxx之类的函数汇编一条4字节的指令了。让我们看一个例子:
/* | 5 : opcode | 3 : mode | 24 : -| */unsigned pcasm::write_mode_op(unsigned opcode) {unsigned ins = 0;;ins = opcode << 27;ins |= (PCVM_INS_MODE_OP << 24);return ins;}
就是按照编码规则做了一些位操作而已。在真实的汇编器中,无疑这部分就是按照体系结构的编码规则做操作而已。汇编器就是这么的简单。
如果一条指令没有引用标记则大体流程也就这样了,无疑就是调用不同模式的写入函数以及填充不同的编码模式而已。而如果一条指令引用了标记则就会牵扯出重定位一说。大多出现在跳转指令以及内存访问模式中。
重定位信息
这里说先说明下为什么需要重定位。下面拿push label这条指令来举例。
bool pcasm::PUSH_LAB(unsigned opcode, std::vector<unsigned char> &bytecodes){std::vector<int> tokens;/* 压入一个"引用标号"的标记 */tokens.push_back(TOKEN_REF_LABEL);/* 如果不匹配则退出 */if (match(tokens) == false) {_error = PCASM_ERROR_SYNTAX_NOT_MATCH_TOKEN;return false;}/* 建立一个重定位项目 */pcasm_relocate rel;rel.type = PCASM_REL_FIXLST20B;/* 当前指令的地址,以后重定位需要 */rel.address = s_address;/* 符号的名称 */rel.symbol = _text_stack[0].str;/* 压入s_relocates,重定位列表 */s_relocates.push_back(rel);/* 写入opocde imm一条指令, 后边的imm为0* 这个imm就是后边重定位时要修正的偏移*/int ins = write_mode_op_imm(opcode, 0);write_ins(ins, bytecodes);return true;}
上边的代码就是一个普通的push imm的操作。但是由于push指令后的立即数可以由一个标号表示。
到这里首先讲讲为什么要重定位,其实重定位分为静态重定位与动态重定位两种。其中后者在操作系统加载到内存时使用。而静态重定位用于在编译时将各个文件合并到一起时规划地址。而我们现在做的就是静态重定位。下面看一片代码。来解释静态重定位。
test:;; 一些指令push test;; 其余一些指令
这个test是标号,如果test在push之前,那么可以很容易的计算出地址。在指令push后直接写入地址就好。如果test在push后,在push时就不能直接写入地址了。因为此时还不知道test的地址。所以首先需要遍历所有的代码统计所有的标记,然后转换成地址。在其后链接的时候在将地址填上。
标记定义
在scanner中,如果发现标号的定义则返回TOKEN_DEF_LABEL标记。随后则调用cDefLabel函数。
bool pcasm::cDefLabel(pcasm_token &token){/* 如果没有发现符号,则创建符号 */if (s_symbols.find(token.text.str) == s_symbols.end()) {s_symbols[token.text.str] = std::shared_ptr<pcasm_label>(new pcasm_label);if (s_symbols[token.text.str] == nullptr) {_error = PCASM_ERROR_ALLOC_MEMORY;_errstr = token.text.str;return false;}/* 写入模块地址与当前的地址 */s_symbols[token.text.str]->mode_address = _address;s_symbols[token.text.str]->address = s_address;}/* 符号存在 */else {_error = PCASM_ERROR_SYNTAX_SAME_LABEL;return false;}return true;}
包含文件
在parser中如果发现了TOKEN_INCLUDE标记。则调用cInclude。
bool pcasm::cInclude(std::vector<unsigned char> &bytecodes){pcasm_token token;token = next_token();/* 如果非字符串则直接退出 */if (token.token != TOKEN_STRING) {_error = PCASM_ERROR_SYNTAX_NOT_MATCH_TOKEN;return false;}/* 如果在符号表中没有找到这个字符串,* 则创建一个pcasm的类*/if (s_sources.find(token.text.str) == s_sources.end()) {s_sources[token.text.str] = std::shared_ptr<pcasm>(new pcasm());if (s_sources[token.text.str] == nullptr) {_error = PCASM_ERROR_ALLOC_MEMORY;return false;}/* 在标记中存在源文件的字符串使用make生成对应字节码 */if (s_sources[token.text.str]->make(token.text.str, bytecodes) == false) {_error = s_sources[token.text.str]->error();_errstr = token.text.str;return false;}}return true;}
当遇到包含标签就会进入指定的源文件进行汇编操作,并且在同一个字节码缓存内,一同作为输出。
汇编立即数
在parser中如果发现了TOKEN_IMM标记。则调用write_imm。此函数会将立即数标记中的数写入到字节码队列中。并返回写入的字节数,最后返回的字节数增加到当前地址上修正这些地址。
int pcasm::write_imm(unsigned data, std::vector<unsigned char> &bytecodes){/* 好吧一个字节一个字节的写到字节码队列中 */unsigned char *ptr = reinterpret_cast<unsigned char*>(&data);for (int i = 0; i < sizeof(int); i++) {bytecodes.push_back(*ptr++);}return sizeof(unsigned);}
汇编字符串
在parser中如果发现了TOKEN_STRING标记。则调用write_string。
int pcasm::write_string(const std::string &str, std::vector<unsigned char> &bytecodes) {/* 遍历字符串并且压入字节码队列 */for (auto c : str) {bytecodes.push_back(c);}/* 字符串如果不够4字节的对齐则使用0字节补齐 */int s1 = str.size();int s2 = s_up4(s1);if (s2 > s1) {s1 = s2 - s1;while (s1--) {bytecodes.push_back(0);}}/* 返回写入到字节数(包含补齐的0字节) */return s2;}
链接处理
链接过程是独立的,由外部进行调用。
int pcasm::pclink(std::vector<unsigned char>& bytecodes){/* 如果字节码队列为空则直接退出 */if (bytecodes.empty()) return false;/* 分配一块内存空间 */size_t size = bytecodes.size();/* 分配最后链接后的空间 */unsigned char *ptr = new unsigned char[size + 1];if (ptr == nullptr) {return PCASM_ERROR_ALLOC_MEMORY;}/* 遍历所有字节代码并写入 */size_t i = 0;for (auto b : bytecodes) {ptr[i++] = b;}/* 遍历所有重定位项目 */for (auto r : s_relocates) {/* 从重定位表中找到符号,如果找不到则返回链接失败 */if (s_symbols.find(r.symbol) == s_symbols.end()) {return PCASM_ERROR_LINK_NOT_FOUND_LABEL;}/* 从重定位项中取出要重定位的地址* 随后取出要重定位的指令*/unsigned ins = *reinterpret_cast<unsigned*>(ptr + r.address);/* 好吧,随后将符号的地址设置给指令 */ins |= (s_symbols[r.symbol]->address & 0xFFFFF);*reinterpret_cast<unsigned*>(ptr + r.address) = ins;}bytecodes.clear();/* 再将重定位好的代码再次写回到字节码队列中 */for (size_t i = 0; i < size; i++) {bytecodes.push_back(ptr[i]);}if (ptr) delete[] ptr;return PCASM_ERROR_SUCCESS;}
s_relocates里保存了所有标号的重定位信息。填充这个结构在指令汇编的时候,如果遇到XXX_YYY_LAB的函数。则填充这个变量。
随机加密算法生成器的设计与实现
好了,有了以上的两个基础就可以进入我们的真正的目的了。为了到达我们真正的目的,写了N行代码就是为了实现这个最终目的。
程序自己写程序
其实这节的标题就是我一直以来的梦想,这里先意淫一下。没别的意思,按照本文的程度还远远没有达到。
框架设计
在文件polycypt.h中定义了这个框架。这个框架会随机选取一个算法工厂类进行使用。
/* 变形引擎配置 */typedef struct {/* 算法引擎工厂索引,-1表示随机 */int factory;} polycypt_config;class polycypt {public:polycypt();polycypt(const polycypt_config &config);virtual ~polycypt();/* 运行* output_dir : 结果输出目录* template_dir : 算法模块目录*/bool run(const std::string &output_dir, const std::string &template_dir);/* 出错代码 */int error();private:void reset(); /* 重设 */void load_algs(); /* 加载算法 */int random(size_t n = 100); /* 生成一个随机值 */private:/* 配置 */polycypt_config _config;/* 工厂类队列 */std::vector<std::shared_ptr<polycypt_factory> > _factories;/* 出错代码 */int _error;};
在运行后,调用make后进行加解密算法的对称生成,本引擎的目的就在于此,运行一次后就依照算法模板随机生成一套加解密对应的算法。当然这里提到了模板,我毕竟还没实现我的梦想,另外一方面这只是一个框架引擎,我并没有实现很牛逼的生成算法。
当前的工作原理是这样的首先随机选取一个算法模板,然后调用加解密算法生成工厂。当前引擎自带一个DEMO,在一个叫做polycypt_alg0.cpp的文件中实现。而下面的函数就会按照参数配置随机生成加解密算法。
/* output_dir : 结果输出目录* template_dir : 模板目录* generate_source : TRUE:输出生成的源代码*/bool polycypt_factory::make(const std::string &output_dir, const std::string &template_dir, bool generate_source) {/* 获取临时模板目录 */std::string template_file = template_dir;if (*template_file.end() != '/') {template_file.append("/");}/* 默认的汇编源代码文件 */template_file.append("startup.asm");/* 读取模板文件 */_startup_template = s_read_file(template_file);if (_startup_template == "") {_error = POLYCYPT_ERROR_READ_FILE;return false;}std::string local_dir = output_dir;if (*local_dir.end() != '/') {local_dir.append("/");}/* 产生对应的加解密算法 */std::string encrypt_source, decrypt_source;if (generate(encrypt_source, decrypt_source) == false) {return false;}/* 如果generate_source为TRUE则将加解密算法的源代码输出 */if (generate_source) {/* 生成加解密源代码的路径 */std::string encrypt_source_path, decrypt_source_path;encrypt_source_path = local_dir + "encrypt.asm";decrypt_source_path = local_dir + "decrypt.asm";/* 生成对应的加解密源文件,其实没什么用,就是让开发者* 看看生成的什么东西*/if (s_write_text_file(encrypt_source_path, encrypt_source) == false) {_error = POLYCYPT_ERROR_WRITE_FILE;return false;}if (s_write_text_file(decrypt_source_path, decrypt_source) == false) {_error = POLYCYPT_ERROR_WRITE_FILE;return false;}}/* 编译加解密算法成对应的字节码 */if (compile(encrypt_source, decrypt_source) == false) {return false;}/* 对解密算法生成的字节码进行链接 */if (pcasm::pclink(_encrypt_bytecodes) != PCASM_ERROR_SUCCESS) {_error = POLYCYPT_ERROR_LINK;return false;}/* 对加密算法生成的字节码进行链接 */if (pcasm::pclink(_decrypt_bytecodes) != PCASM_ERROR_SUCCESS) {_error = POLYCYPT_ERROR_LINK;return false;}/* 将生成好的文件写入到算法变形引擎固有的文件格式中 */std::string en_file, de_file;en_file = local_dir + "encrypt.pbc";de_file = local_dir + "decrypt.pbc";if (make_pcfile(en_file, _encrypt_bytecodes) == false) {return false;}if (make_pcfile(de_file, _decrypt_bytecodes) == false) {return false;}return true;}
这个算法工厂就是可以自行进行编写,然后后台引擎进行调用。
算法工厂类
所有的插桩算法都是继承自这个类,所有算法实现的基础模型都是基于这个类来实现。
class polycypt_factory {public:polycypt_factory();virtual ~polycypt_factory();/* 产生加解密算法 */virtual bool generate(std::string &encrypt, std::string &decrypt);/* 编译 */virtual bool compile(const std::string &encrypt, const std::string &decrypt);/* 产生编译后的字节码并输出 */virtual bool make(const std::string &output_dir, const std::string &template_dir, bool generate_source=false);protected:/* 这里都是内置的一些功能函数 */virtual void reset();/* 产生一个随机的符号名称 */virtual bool make_symbol(std::string &symbol);/* 产生随机数 */virtual int random(size_t n = 100);/* 产生pc格式的文件 */virtual bool make_pcfile(const std::string &path, std::vector<unsigned char> &bytecodes);protected:/* 产生加密算法 */virtual bool generate_encrypt(std::string &encrypt);/* 产生解密算法 */virtual bool generate_decrypt(std::string &decrypt);protected:/* 这些是做高级的算法生成支持 */unsigned _ip; /* ip地址寄存器 */unsigned _registers[PCVM_REG_NUMBER]; /* 寄存器队列 */bool _idle_registers[PCVM_REG_NUMBER]; /* 空闲寄存器 */int _error; /* 错误代码 *//* startup.asm的模板字符串 */std::string _startup_template;/* 汇编器 */pcasm _asmer;/* 加密算法字节码 */std::vector<unsigned char> _encrypt_bytecodes;/* 解密算法字节码 */std::vector<unsigned char> _decrypt_bytecodes;};
以后的算法类主要重载两个接口。
virtual bool generate_encrypt(std::string &encrypt);virtual bool generate_decrypt(std::string &decrypt);
其余的接口可以不实现。polycypt类会调用选定的工厂类的generate_encrypt函数以及generate_decrypt函数。产生两对字符串,随后调用compile进行遍历,这里就不具体展开这一细节了。
DEMO介绍
这里是一个DEMO,实现文件是polycypt_alg0.cpp。继承自polycypt_factory工厂类。这个算法并没有做到我想象的程度,只是一个例子而已。
就是每次随机生成一个密码表,并且随机使用其中一个。然后循环异或目标而已。
class polycypt_alg0 : public polycypt_factory {public:polycypt_alg0();virtual ~polycypt_alg0();protected:/* 产生加密算法 */virtual bool generate_encrypt(std::string &encrypt);/* 产生解密算法 */virtual bool generate_decrypt(std::string &decrypt);protected:/* 产生xor的汇编代码 */virtual bool generate_xor(std::ostringstream &oss);/* 产生随机的密钥 */virtual bool generate_keytab(std::ostringstream &oss);/* 产生算法起始 */virtual bool generate_algorithm_start(std::ostringstream &oss);/* 产生算法结束 */virtual bool generate_algorithm_end(std::ostringstream &oss);private:std::ostringstream _keytab; /* 密钥表 */int _keyidx; /* 密钥索引 */};
xor指令
因为虚拟机没有xor指令。所以只能使用模拟来完成。这个函数就是依次将汇编字符串写入字符串缓存中。
/* (~a & b) | (a & ~b) */bool polycypt_alg0::generate_xor(std::ostringstream &oss) {/** r10 = 密钥* r11 = 数据指针* r12 = 临时变量* r13 = 临时变量*/oss << "@xor:\n";oss << "push r4\n";oss << "sub sp, 4\n";oss << "mov [sp], [r11]\n";oss << "pop r4\n";oss << "not r4\n"; /* ~a */oss << "mov [r12], r4\n";oss << "and [r12], [r10]\n"; /* ~a & b */oss << "sub sp, 4\n";oss << "mov [sp], [r10]\n";oss << "pop r4\n";oss << "not r4\n"; /* ~b */oss << "mov [r13], [r11]\n";oss << "and [r13], r4\n"; /* a & ~b */oss << "or [r13], [r12]\n"; /* (~a & b) | (a & ~b) */oss << "sub sp, 4\n";oss << "mov [sp], [r13]\n";oss << "pop r3\n";oss << "pop r4\n";oss << "ret\n";return true;}
产生随机密钥表
随机产生一组密钥表。
bool polycypt_alg0::generate_keytab(std::ostringstream &oss) {/* 密钥表 */oss << "@keytab:\n";/* 两个循环 16 * 16 = 256 */for (int i = 0; i < 16; i++) {for (int j = 0; j < 16; j++) {char buf[64] = {0};/* 随机产生一个4字节的数 */sprintf(buf, "x%x", random(0xFFFFFFFF));oss << buf;oss << " ";}oss << "\n";}oss << "\n";return true;}
算法起始与结束
产生算法的起始代码以及结束代码。
bool polycypt_alg0::generate_algorithm_start(std::ostringstream &oss) {/** r10 = 密钥* r11 = 数据指针* r12 = 临时变量1* r13 = 临时变量2*/generate_xor(oss);oss << _keytab.str();oss << "@key: 0\n";oss << "@data: 0\n";oss << "@tmp1: 0\n";oss << "@tmp2: 0\n";oss << "@algorithm:\n";oss << "push r5\n";oss << "push r4\n";oss << "mov r4, sp\n";oss << "add r4, 12\n";oss << "div r5, 4\n";/* 获取密钥表 */oss << "push r6\n";char buf[64] = {0};sprintf(buf, "%d", _keyidx);oss << "mov r6, " << buf << "\n";oss << "mul r6, 4\n";oss << "add r6, @keytab\n";oss << "mov r10, @key\n";oss << "mov [r10], [r6]\n";oss << "pop r6\n";/* 设置临时变量 */oss << "mov r12, @tmp1\n";oss << "mov r13, @tmp2\n";/* 设置数据指针 */oss << "mov r11, @data\n";/* 循环处理加解密功能 */oss << "@loop:\n";oss << "cmp r5, 0\n";oss << "je @algorithm_end\n";oss << "mov [r11], [r4]\n";oss << "call @xor\n";/* 保存结果 */oss << "mov [r4], r3\n";oss << "add r4, 4\n";oss << "sub r5, 1\n";oss << "jmp @loop\n";return true;}
产生算法末尾块,用于跳出函数。
bool polycypt_alg0::generate_algorithm_end(std::ostringstream &oss) {oss << "@algorithm_end:\n";oss << "pop r4\n";oss << "pop r5\n";oss << "ret\n";return true;}
_startup.asm
这套汇编代码就是一个启动函数,用于链接加解密代码。
;;;; startup.asm;; polycypt;;;; Created by logic.yan on 16/3/28.;; Copyright © 2016年 nagain. All rights reserved.;;@_start:;; 从I/O端口0读取数据长度mov r4, 0int 2;; 如果 r5 是 0, 则退出cmp r5, 0je @exit;; r5是数据长度, 4字节对齐;; ~3u & (3 + v)mov r7, r5add r7, 3mov r6, 3not r6and r7, r6;; 分配内存空间sub sp, r7int 0;; 调用对应的算法call @algorithm@output2io:;; 写入数据到I/O端口0之后解密到sp指针处,r5是加解密数据的长度mov r4, 0int 1;; 设置输出I/O端口0的数据长度mov r4, 0int 3;; exit@exit:;; 是否内存空间add sp, r7int 9
之后的想法
其实,上述东西真没实现我想要的东西,但是一个框架算是有了。从工厂类的类变量可以看出来其实我想做的是自扩散的生成算法。而不仅仅这个。汇编语言其实还是不是很方便。就算简单的四折混合运算直接喷成汇编代码考虑的东西也会很多。如果之后有时间,我会先再加一个简单的语言编译器。然后再利用随机生成对应的源代码。这样就不用考虑寄存器选取,堆栈等问题。生成的算法也更强大一些。
