@kungfuboy
2017-02-24T09:42:04.000000Z
字数 1441
阅读 1742
数据可视化——D3
技术栈
数据可视化,是指将大量的数据处理后归类,并在视觉层面做出差异分明的展示。
说得学术一些,数据可视化分为七个步骤:获取、分析、过滤、挖掘、表现、改善、交互。(出自《Visualizing Data》),前面几步我们通过Ajax请求和业务函数来实现,作为一个库,我们着重进行数据渲染,也就是后三步:表现、改善、交互。
对于Web来说,能在页面上画图的只有两个东西——Canvas和SVG。
两者各自的侧重点还是比较明显的:
先说Canvas,Canvas是HTML5的一个接口,或者说是个标签吧,可以利用它里面的一些方法和属性,绘制出图形,渲染的时候是逐个像素地渲染。并且,它是基于位图的图像,因此不能够改变大小,只能缩放显示,也由此带来一个缺点,它对于文字的渲染能力弱。此外,它不支持事件处理器。
因此,Canvas适合图像密集型的游戏,或者说动画精细、幅度变化大的动画效果。
SVG则是基于XML的图,尽管它同样也属于文档结构,但和DOM不一样,挂在XML的节点上的属性少,因此渲染的代价要小得多,当然,在复杂度相当高的节点操作下,它跟Canvas相比还是吃力的。
说得直白一些,如果你要绘制一张脸,那Canvas更合适,如果你要绘制一些比较规则的图形,那SVG更合适。此外,SVG更容易操作,当然,我们直接选用已经成型的类库,关于操作性就不用比较了。
现如今,数据可视化的类库并不少,像比较知名的百度的Echarts,谷歌的Chart,还有HeightCharts等。上述几个库的使用方式大致是一样的。如下:
var data = {name:'',age:''}var pie = new Pie();pie.setOption(data);
创建一个构造函数,随后调用API,在其中传入一个json对象,json里按你的需要放入数据。
然而,这些库的定制性并不高,例如想要改变初始化的展现方式、修改坐标轴的间距、修改色盘等都是比较复杂的事,在图表比较复杂的时候,这些类库绘制出来的图往往达不到要求,细微的部分无法修改。
因此,很自然地把眼光放在那些定制性更强的类库上——D3,说实话这个选择的过程是毫无痛苦的,因为除了D3几乎没什么能选的,Three.js倒是个选择,可以绘制出3D的漂亮图形,但是接口复杂,况且现在3D绘图尚未成熟,Three也少用于生产。
D3用的是SVG。
D3支持事件处理器,并且是数据驱动的,也就是说只需要关心数据以什么样的形式加载即可,修改XML节点的事情交给D3做,这大大减少了工作量(好吧,其实所有的同类库都是这么做的)。D3将“绘制什么”和“如何绘制”分了开来,和其他类库比,表面上看这增加了工作量,但这可以让绘制出来的库更加贴近业务,视觉上也可以更有追求。
在使用上,D3的语法并不高深,语法类似于JQuery,这大大减少了学习成本,只需要了解各个API的参数和作用,就可以上手工作了。(只是他们也像JQuery一样把读方法和写方法写在一起,否则这个库还可以更轻量一些。)
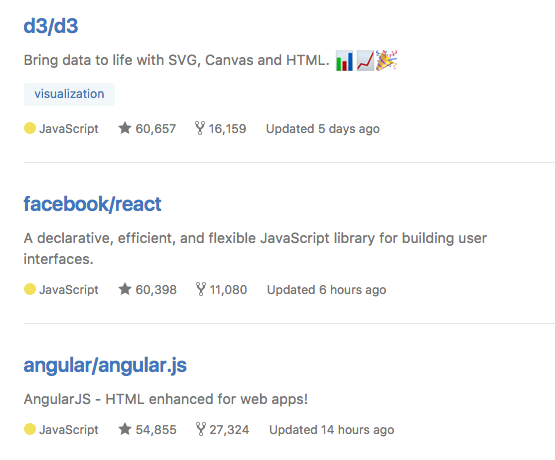
在Github上,D3的排名现在甚至比react和angular更靠前,让同类的库望尘莫及。
关注度高,那么解决问题的效率也会高,况且D3已经出现好几年了,基本成熟稳定。
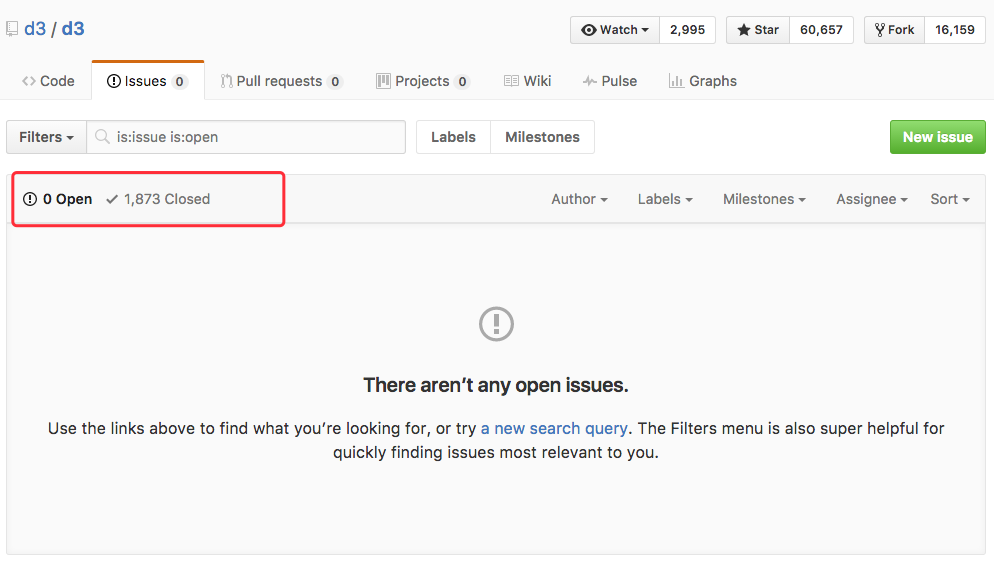
如图,1873个问题,已经全部被解决,找Google的Chart来对比一下就知道这意味着什么……
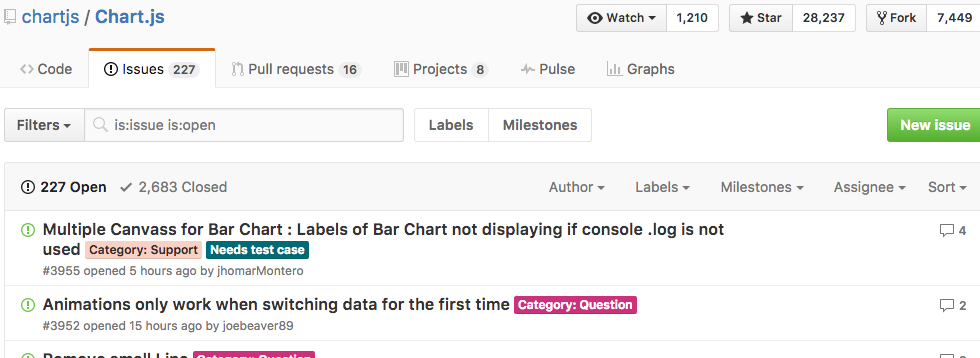
Charts有2600多个坑,其中有200多个未解决。
更多人的选择,直接代表了更火热的社区、更完善的文档资料、更多的技术支持。
