@xishuixixia
2017-06-15T10:25:15.000000Z
字数 4143
阅读 2536
京东618:一个中心五个原则,谈谈物流系统的大促优化实践
京东618 架构 数据库 MySQL
在京东的订单流链路中,可以简单的划分为订单前和订单后两部分,我们在京东主站上搜索商品、浏览商品详情、把商品加入购物车、提交并支付订单等环节属于订单前,订单提交之后,订单信息流就进入订单后的物流系统部分。每逢618大促期间,大家可能会更多的聚焦到网站PV、秒杀系统、交易数据、广告收入等等。其实对于京东来说,其很核心的优势来源于精准的时效承诺、极速的送货体验和极致的售后服务,在大促期间,其物流系统的表现对客户体验至关重要。
ArchSummit全球架构师峰会深圳站将于2016年7月7日~8日在深圳·华侨城洲际酒店召开,京东商城运营研发部总架构师者文明策划了《低延迟系统架构设计》专题,将会为大家分享目前各大互联网企业在低延迟系统架构设计上都有哪些新思路,欢迎关注。
京东物流系统简介
京东物流系统属于订单生产系统,主要包括订单履约、仓储、配送、客户服务和逆向处置中心等等。图1示意了一个简单的正向订单生产流程,逆向生产流程主要由逆向处置中心发起,主要包括售后服务单(退换货等)和安装维修单。
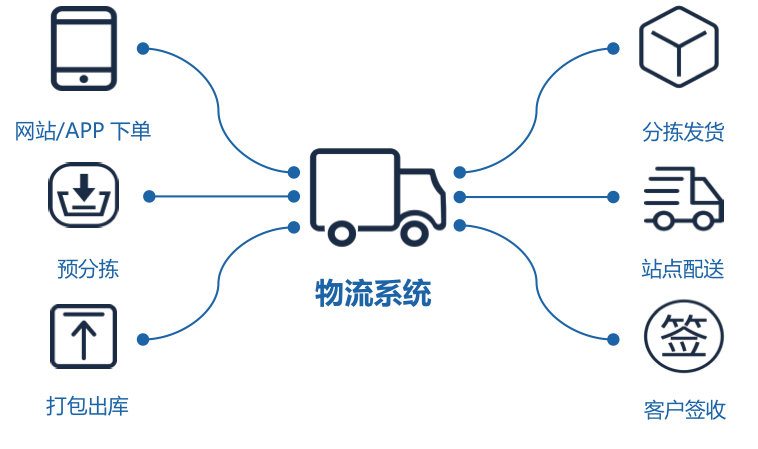
图1 订单生产流程
京东物流系统有如下3大特性:
90%以上为OLTP系统,承载着订单生产相关的所有核心交易流程
领域模型和业务逻辑复杂
强依赖关系型数据库
以上特性也决定了物流系统的大促备战和电商网站、订单交易、秒杀、搜索推荐、广告等系统会大有不同,在很大程度上系统70%以上的性能(容量)取决于DB的性能(容量)。因此,DB是我们每次大促备战的重点。围绕DB侧的备战工作,主要聚焦在慢SQL、垂直和水平拆分、读写分离、生产库和报表库分离、连接池优化、参数调优等方面。
打不死的小强—慢SQL
记得刚加入京东第一次负责618的时候,在618当天就遇到了两次业务反馈系统卡顿的现象,紧急排查发现DB中大量连接堆积,再通过查看当前线程发现是一个慢SQL(耗时10多秒)导致了连接堆积,后来把慢SQL紧急优化上线后系统恢复正常。从那天以后,我深深感受到了慢SQL对我们系统的影响,同时也明白了一点,一个慢SQL对我们的系统总是致命的,我们不能放过任何一个慢SQL。为了说明一个慢SQL对系统的影响,截取了两张数据库CPU使用率在一个慢SQL优化前后的对比图(如图2),从图中也可以看出,前后对比是非常明显的。
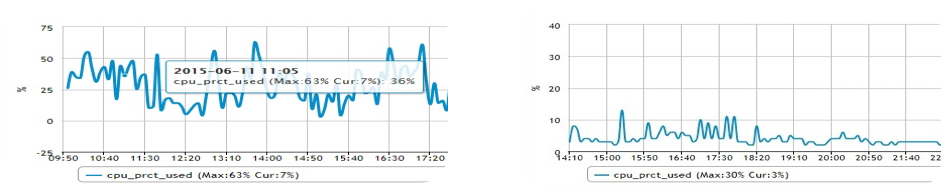
图2 一个慢SQL优化前后CPU负载对比
在数据库优化方面,慢SQL优化是最重要且效果最好的一项工作,如果要用一个比喻去形容慢SQL,打不死的小强是再贴切不过的了,慢SQL在我们的系统中是灭了一茬又一茬,似乎永远消灭不完。通常情况下,慢SQL的出现可能是因为过滤条件中没有索引、SQL语句写的过于复杂、表中数据量过大,做了全表扫描等等,因此我们在进行慢SQL优化时,优先会通过添加索引解决,索引解决不了的才会去优化语法,拆解SQL语句,将大事务化小,通过适当冗余来减少关联,优化数据模型,通过历史数据结转减少数据量等等。总之优化慢SQL的方法很多,各系统要根据各自的特性和场景选择最优且成本最低的方案。
近几年来,京东的业务一直处于持续膨胀之中,系统中总会不断涌入很多新的业务需求,这样也就不可避免的引入了新的慢SQL,所以每次大促,慢SQL优化是一大备战重点。
数据库垂直和水平拆分
跟传统的企业应用系统一样,京东的仓储系统也经历过C/S和B/S时代,V3.0之前用的是SQLServer和.Net平台,而且整个仓储管理是一个系统,包括基础资料、库存、入库、出库、在库等,随着京东业务规模的迅速增长,每次大促的单量峰值也由早期的万级增长到了现在的亿级,这中间仓储系统进行了垂直拆分,将基础资料、库存、入库、出库、在库等拆分为独立系统独立部署(如图3) 。垂直拆分之后仓储系统一分为多,系统的容量也就成倍上升。
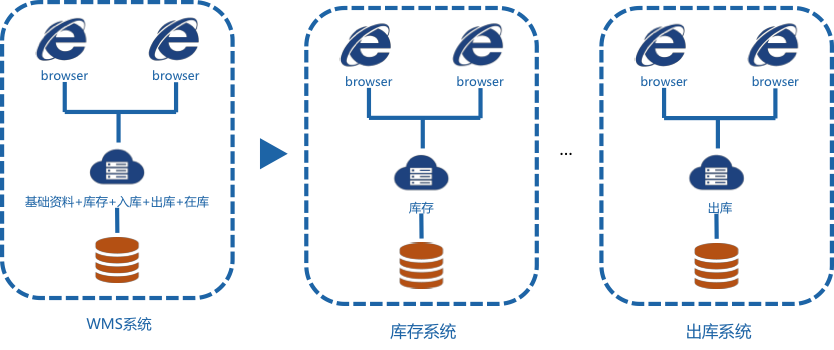
图3 仓储系统数据库垂直拆分
除了仓储系统,其他很多系统(包括配送系统)都经历了垂直拆分的过程,垂直拆分不但可以很好的解耦系统,还能成倍提升系统容量。
京东的配送系统流量比仓储系统还要大,垂直拆分之后的系统容量不足以支撑大促期间的单量冲击,于是在垂直拆分的基础上又做了水平拆分,水平拆分除了常用的分库分表之外,还有部分复杂业务表的模型水平拆分,比如运单表,拆分成基础数据、扩展数据和状态管理三个表,有的表也会按读写比例进行拆分,比如将读多写少的列放一张表,读少写多的列放另一张表。图4是配送系统进行水平拆分的一个示意图。水平拆分之后,目前系统可以轻松应对大促期间的亿级单量,流量还远远未到系统的容量上限。
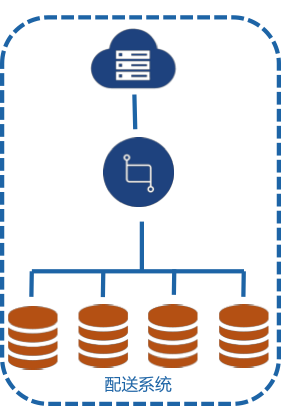
图4 配送系统数据库水平拆分
分离技术
分离技术也是我们每次大促备战中的常用方法,主要包括读/写分离,生产/监控分离和在线/离线分离。
我们大部分系统读写比例大约10:1,对于关系型数据库来说,主要消耗来源于查询,尤其是复杂查询,所以为了提升数据库端的总体容量,必须尽可能的将查询SQL分离到从库上,主库只提供写服务和一些必要的读服务,图5中B为备份库,R为从库,所有从库均可提供读服务,一个主库下可能会挂多个从库,多个从库根据业务场景需求可以做成负载均衡,也可以按业务优先级进行隔离并支持灵活切换。这样主库就只负责生产,避免了那些比较消耗性能的复杂查询影响到生产,同时系统的总体容量也会得到大大提升。
生产/监控分离指的是生产报表和监控报表必须分离开来,所谓生产报表就是业务生产过程中强依赖的报表,比如仓储系统中的积压类报表(拣货、复核、打包等各环节积压数量),配送系统中的分拣差异报表、配送差异报表等等。
这两类报表业务优先级不一样,生产报表是要优先保障的,所以在系统中需要将这两类报表进行隔离,避免监控类报表影响到生产类报表。监控报表是一个独立系统,数据来源有两种路径,一种是从生产库通过binlog复制过来(我们用的是自研的Decomb总线),另一种是从生产库通过消息方式先进入kafka,再从kafka消费到监控系统。因为监控报表业务场景的多样性和复杂性,监控系统的数据库会采用多种技术,比如MySQL、Elasticsearch、HBase、Cassandra等等。
在线/离线分离指的是在线报表和离线报表分离,在线报表是实时或准实时报表,查看的是24小时之内的业务数据,离线报表多为分析类报表,查看的是24小时之前的业务数据。因为二者的业务优先级和技术方案都不尽相同,所以必须要进行分离,避免相互影响。
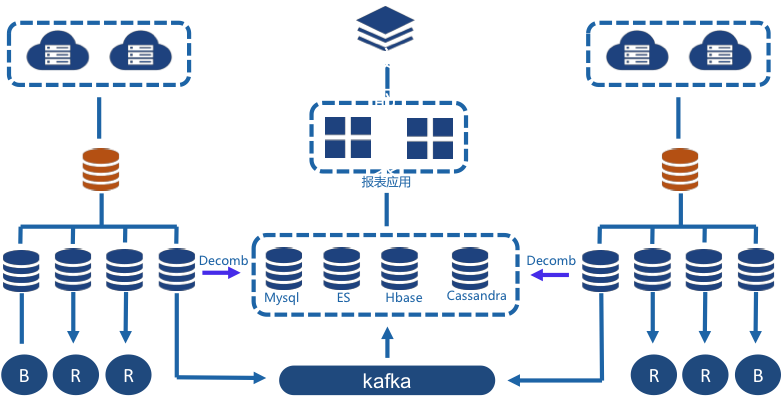
图5 分离技术
DB+技术
经历过多次大促备战之后,给我们最大的感触就是业务规模的增长速度总是快于我们系统的迭代速度,业务规模总是在驱动着系统的迭代升级。面对亿级单量,单纯的引入前面提到的技术已经无法让系统容量发生质的变化,系统容量容易受制于数据库,所以,除了通过分库分表来实现数据库写的分布式,还需要引入一些NoSQL技术,所谓的DB+,也就是DB+NoSQL+分布式,主要包括如下几个方面的改进:
引入KV引擎,将一些数据从关系型数据库(MySQL)迁移到KV引擎中来存储和处理,这样不仅可以大大降低关系型数据库(MySQL)的负担,还能提升数据的读写性能。京东的物流系统中,引入的KV引擎主要包括Redis、HBase、Elasticsearch和Cassandra,Redis用于缓存相对静态的热点数据,HBase是存储,主要存储海量的业务数据和历史数据,Elasticsearch主要存储查询条件相对复杂的数据,Cassandra主要存储一些日志、流水类数据。
引入数据库分库分表中间件,实现数据库写的分布式,做到数据库读写的水平可扩展,真正实现从Scale up到Scale out的转变。
追求BASE模型,容忍分区失败,弱化事务,大事务化小事务,甚至是无事务,舍强一致性取最终一致性。
图6能简单说明DB+的基本思路,系统的存储分两部分,一部分是传统的关系型数据库(MySQL),用来存储结构化,强事务数据,数据库做了Sharding,读写均为分布式,支持弹性扩展。另一个是KV引擎,KV引擎主要包括Redis、HBase、ElasticSearch和Cassandra,Redis主要用来做热点缓存,HBase用来存储数据量级大而且rowkey又比较固定的数据,ElasticSearch用来存储查询条件比较复杂的报表、查询类数据,Cassandra主要用来存储日志、流水类数据,这类数据量级大,读写性能要求也比较高,但是大多都是按key查询。
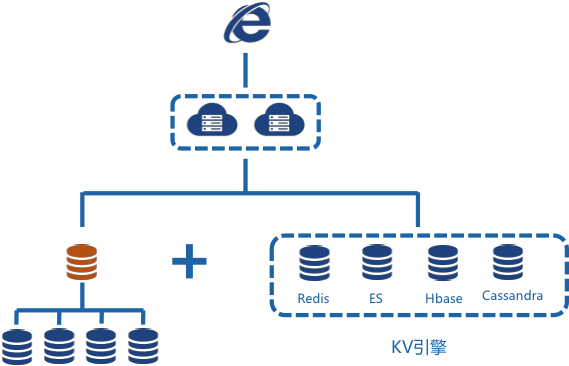
图6 DB+技术
思考总结
在经历过多次大促备战之后,最大的感触是每次大促的业务规模总是在驱动着系统的技术不断的升级。不同的业务量级所需要使用的技术也大不一样,前面介绍的都是每次大促备战的一些技术实践。简而言之,对于OLTP类系统来说,面对大促的优化可以总结为一个中心和五个基本原则。
一个中心就是要以数据库为中心,优化数据库性能为先,从数据库端出发来提升系统容量。五个基本原则就是大系统小做原则、大事务化小原则、分离原则、分布式原则和数据库弱依赖原则。下面分别介绍下:
大系统小做讲的就是合理的垂直拆分,将一个业务系统按照合理的领域模型拆分成多个可以独立部署的子系统,一方面解耦,一方面提升系统的容量和可扩展能力。
大事务化小指的是在业务允许的前提下尽可能将大事务拆成小事务,大事务会严重影响数据库的性能而且容易造成死锁;
分离原则就是要根据业务的不通场景和要求和数据的冷热程度等进行数据的分离,避免不同优先级的业务相互影响;
分布式原则主要说的是要将数据库的写进行分布式,并且真正做到写库可动态扩展;
数据库弱依赖原则简单说就是要尽可能减少对关系型数据库的依赖,能用NoSQL解决的就不用关系型数据库,能异步写库的就不同步写,能最终一致性的就不追求强一致性等等。
现阶段正处于电商高速发展的黄金时期,业务规模还将持续保持快速增长,京东的物流系统也还将持续迭代和演进。
作者介绍
者文明,中科院硕士,清华大学学士,15年电子商务/企业应用领域研发、架构经验,涉及电子商务、互联网、大数据、人工智能等领域,专注电商物流系统架构、实时大数据、智慧物流等解决方案。2012年初加入京东,主要负责京东物流系统架构。
