@shaobaobaoer
2019-05-21T12:33:29.000000Z
字数 11543
阅读 1576
基于自然语言处理的媒体营销策略分析_new
NLP 数据挖掘
0x00 概要
我们的实验是基于自然语言处理的媒体营销策略分析,我们将分析对应媒体的推特与用户的相关评论。我们提出的假设如下所示:
- H1: 用户在对媒体发布推特的评论中,对于该品牌名称的描述词的情感分数均值有一定意义。根据消费心理学中的消费动机模型。用户的购买动机与用户对该品牌的内隐态度与情感有强相关,这就意味着,用户在推特评论中对该品牌名称描述词的情感分数在一定程度上决定了用户对于该品牌的内隐态度与情感,这将部分决定用户的消费动机。
- H2: 媒体发布推特的情感分数与用户对该推特评论的情感分数成正比,也就是说,媒体推文发布推特越积极,用户对该推特的评论也就越积极。
我们拟定抓取五个公司的数据,五个公司分为两大类,一个大类为软饮料公司,包括可口可乐和百事可乐。应一个大类为快餐业公司,包括麦当劳,肯德基和汉堡王。
0x01 数据清洗与准备工作
数据爬虫部分
由于推特的API申请遇上了很多麻烦,所以我们最终采用了半手动半自动的爬取方式。
所谓手动是我们需要自己利用webdriver 提供的浏览器定位到我们需要爬取得推特上。就好像这样子

并且手动下拉将所有评论加载出来。可能由于推特得某些限制,我们并不能获取所有得评论,对于某些热门的推特,特别是那种评论数过千的,官方会删选出大概250条左右的热门评论。
所谓自动是利用python selenium 来爬取对应媒体的相关推特与用户评论。利用 selenium 库下的webdriver 以及xpath路径,可以轻松帮助我们获取我们想要的信息。由于页面已经定位完毕,而基本上所有的xpath都是固定的。所以我们可以迅速爬取数据,代码相关部分在附录中。这里列取了三个重要的xpath如下所示:
- "TweetTextSize--jumbo"
- 通过
driver.find_elements_by_class_name可以迅速定位到改文本对应的title。也就是官方发布的推特原文上。
- 通过
- "/html/body/div[44]/div2/div3/div/div/div1/div3/div/div/div/div/ol1/li[{}]/ol/li/div1/div2/div3/p"
- 通过
driver.find_element_by_xpath可以迅速定位到用户的评论上。其中{}位置为我们可以传入迭代器的部分。
- 通过
- "/html/body/div[44]/div2/div3/div/div/div1/div3/div/div/div/div/ol1/li[{i}]/ol/div1/li/div/div2/div3/p"
- 通过
driver.find_element_by_xpath可以迅速定位到用户的评论上。其中{}位置为我们可以传入迭代器的部分。该位置与前面的不同地方在于有些用户会写形如@coca-cola\nxxxx的文本。如果利用上述的xpath则定位不到对应文本。
- 通过
数据爬虫信息展示
最终爬去下来的信息如下所示,每个文本的第一行为媒体发布的推特。第二行开始为用户的评论。
我们爬去媒体推特的要求有以下几点
- 发布日期在2019年
- 用户的评论数至少有60条(数据未清洗前)根据推特的相关后台操作,单个推特用户最多的评论数大概在250条左右。
- 该推特必须是由媒体自己发布的,不可以是转载的。
- 考虑到技术原因,我们无法对图片和视频数据进行分析。我们会选取的官方推特至少包含一句完整的英文句子。如果官方推特的内容过短,并且以展示视频或者图片为主,我们会过滤这条推特。
数据清洗
在爬取完毕数据之后,我们需要对数据进行清洗。数据清洗是在整个数据挖掘中非常重要的一步。清洗的结果将会直接关系到最后我们数据是否适合我们的模型。对于数据而言,我们将数据清洗为两种程度的数据。
一种为待分析数据,我们会将这些数据传入我们之后的词云词频分析,描述词分析和推特TAG分析的步骤中去。而另一种为纯文本的数据,我们会将这些数据传入我们训练完毕的文本情感二分类的RNN网络中去。
待分析数据清洗
对于待分析数据,我们的清洗步骤如下所示:
- 编译#号,将#置换为
jingSHARPhao并在最后替换回去 - 替换一些html转义词。比如
"。因为在之前制作数据的过程中,为了让数据容易被csv迭代器读取,所以我们编码了部分字符 - 替换一些特殊的编码字符。特别是表情符号,以及一些非ASCII字符,如果不去除,会对我们之后的分析带来很大麻烦
- 去除url
- 去除推特ID
- 这里说明一下,由于我们没有拿到推特的API账户,所以分析推特ID变得有些无力,做是可以做,但是考虑到种种问题,我们最终决定将它去除
- 把缩写转变成完整形式
- 去除掉数字和特殊字符
- 这么做尽管有风险,但我们认为数字在情感表达的过程中作用微乎其微
- 另一方面,可能有些非英文(比如日文,法文等)在我们的词袋中,这些对于我们的数据有害无益,只能去除
- 重新返回#,这样做是为了之后分析推特的TAG
- 返回内容
纯文本数据清洗
考虑到我们的模型由于时间和资源有限,学习不是非常彻底。我们将原始数据按照如下步骤清洗:
- 替换一些html转义词
- 替换一些特殊的编码字符
- 去除url
- 去除推特ID
- 去掉推特TAG
- 所有内容小写
- 把缩写转变成完整形式
- 去除掉数字和特殊字符
- 这么做尽管有风险,但我们认为数字在情感表达的过程中作用微乎其微
- 另一方面,可能有些非英文(比如日文,法文等)在我们的词袋中,这些对于我们的数据有害无益,只能去除
- 返回内容
与刚才不同的是,我们洗掉了推特TAG,并且把所有字母转变为了小写形式。对于推特TAG这种我们在字典中几乎很难找到的单词,我们应该做到最大程度上的去除。我们不可否认的是,可能纯0向量的单词对于我们的模型影响不是非常大,但是能去除还是去除为好。另外,这样的清洗过程和我们在训练LSTM模型的时候的过程是一样。因此这些清洗好的数据可以直接输入到预测模型中,不需要二次处理。
清洗数据展示
# analyzeNo thanks impossible burger glyphosate amp #roundupburger #glyphosphate# cleanno thanks impossible burger glyphosate amp
0x02 词云与词频分析
在进行词云与词频分析前,我们给出以下假设
- 对于一些以卖正餐为主的餐饮业媒体,比如汉堡王,肯德基而言。更加倾向于去描述他们的食材,产品的口感
- 对于一些以卖饮料为主的餐饮业媒体,比如星巴克,可口可乐而言。更加倾向于去描述他们的用料,创意,产品的香气。
词云和词频分析是文本处理的第一步,通过筛选媒体推特和用户对于他们评论的词频并制作词云,我们能够非常直观得发现一些非常有用的信息,并得出我们之后的结论。
为了节约空间,我们只给出了词云图,没有给出词频图。
在进行词频与词云分析之前,我们需要对数据进行二次清洗,清洗的内容比较简单,包括以下方面
- 将所有的文本合并。并将每个文本加上一个句号。
- 去除掉一些噪声,所谓噪声就是一些特定词性的词语,比如说连词,be动词,空格,逗号等
- 去除掉一些特别短的句子,这里我们将阈值设置为2。我们将自动忽略句子的长度小于等于2的句子。
- 最后,将所有的词语转变为原型。比如说 better 和 best其实都是一个词语good。这样做能够让我们最后的统计结果更加优质。利用自然语言处理库 spacy可以轻松处理这些。而在之后的分析中,我们还会用到这个库
百事可乐
百事可乐我们一共抓去了25条官方推特和若干用户评论。词云与词频分析的结果如下所示。
百事可乐的媒体推特词云图

百事可乐的用户评论词云图

可口可乐
可口可乐我们一共抓去了11条官方推特和若干用户评论。词云与词频分析的结果如下所示。
可口可乐的媒体推特词云图
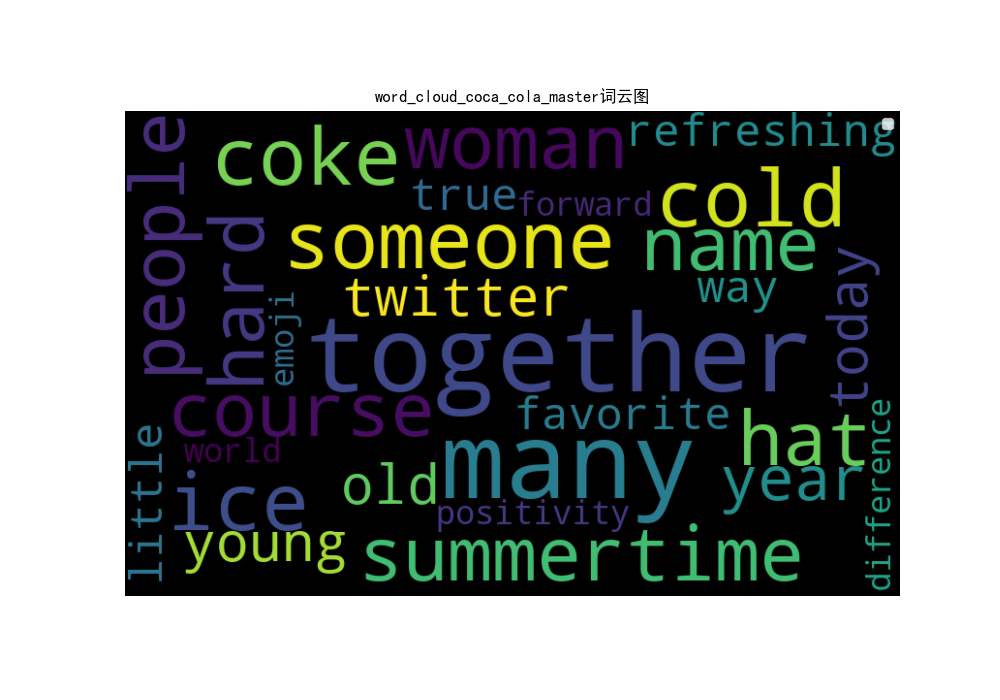
可口可乐的用户评论词云图

汉堡王
汉堡王我们一共抓去了25条官方推特和若干用户评论。词云与词频分析的结果如下所示。
汉堡王的媒体推特词云图

汉堡王的用户评论词云图

我们发现对于汉堡王而言,媒体倾向于使用today(n=6),cake(n=6)等词语。并且也常常使用一些能够描述汉堡王食材,口味的词语,比如bacon(n=3)或者chicken(n=3)。而对于口味的描述词则不太能够看的到。
另外一方面,对于汉堡王的官方推特,用户的评论除了关注品牌词语(burger king n=276)之外,还会关注汉堡王的app(app n=98) 和食材(bacon n=76;food n=64)。
KFC
综合分析
在分析完毕用户和官方评论的向量中,我们找到一些共性的内容。在之后,我们将要用户在推特中的评论的形容词。并计算出品牌描述词的向量。那么哪些名词最能够代表该品牌呢?品牌的名字自然是我们需要考虑的内容之一,另外我们还考虑到用户可能会用一些别名或者缩写来表示该品牌。比如说用户有时候会用 bg 或者 B.G. 来表示burger king。上述的词云分析已经帮助我们找到了一些代表品牌的单词。我们将这些单词写成一个字典数据并传入到我们之后的品牌描述词分析中
{"Burburger_king": ["burger king", "bk", "burger"],"pepsi": ["pepsi", "drink", "cola", "coke"],"coca_cola": ["coke", "coca cola", "product"],'kfc': ["chicken", "kfc", "bacon"],'McDonalds': ["big mac", "fry", "big fry", "bacon"]}
0x03 品牌描述词分析
品牌描述词概念
所谓品牌描述词,我们大概界定了两种词性,一种为形容词,一种为副词。而描述词所描述的词,一般的词性为名词。之所以分析描述词,是因为我们可以通过用户的描述来得出用户对这个某推特的相关情感分数。
比如说这样的一个语句
Boycott nasty Burger King their nasty milk shakes
我们首先将这个语句给拆成一个个单词,注意,由于Burger King 是大写的,所以我们的自然语言处理库会将它辨识成为一个单独的名词。
之后我们需要遍历这个名词的前驱节点,如果它的前驱节点的词性是 ADV 那么我们就返回它的前驱节点。相关代码非常简单,如下所示:
def ptag_for_certain_token(sentence, token, ptag):''':param sentence: 当前的句子:param token: 需要找的单词:param ptag: 对应的修饰词词性:return:'''sentences = [sent for sent in sentence.sents if token in sent.string]pwrds = []for sent in sentences:for word in sent:pwrds.extend([child.lemma_ for child in word.childrenif child.pos_ == ptag])return Counter(pwrds)
我们通过上述函数,可以定位到用户对于 burger king 的描述是 nasty 。这样nasty就被传入了我们待统计的形容词中。
通过之前的词云,我们可以定位到一些用户经常提及的名词,对于汉堡王而言,除了burger king之外,我们还定位到了其他的词语,比如说burger和bp。其他的品牌也是类似的。
从品牌描述词到情感分数
在我们统计完毕情感描述词之后,我们需要统计用户对品牌描述词的情感分数。我们之前谈及,由于我们没有获取到推特的开发者账户,所以我们无法从单个用户角度进行分析。但是用户的对品牌描述词的情感分数均值有一定意义,因此我们可以在我们爬去的多个品牌之间进行纵向比较。
我们采用的积极消极情感数据字典来自于SentiWordNet(http://sentiwordnet.isti.cnr.it/)这是一个出色的公开词典。 从技术上讲,该资源包含标有极性分数的普林斯顿WordNet数据。
其数据包括了正分数和负分数,以及对词语如此判别的相关语句。可以在github 上找到它的相关数据。

我们不使用我们训练的LSTM模型的原因是,我们的模型的优势是对一个文本的分析,而不是单个单词的分析。因为在训练的过程中我们是输入的是特定长度的单词向量组合成的一句话,对于长度不足的单词向量我们将用0向量填充。关于我们的LSTM会在后文中细说,但是对于单个的单词,我们就需要非常多的零向量来填充,所以会导致我们最后的数据出现一些问题。所以我们最终决定采用网上的开源模型。
我们利用了pandas 库来迅速读取我们的数据文件,对于某个特定的单词,Python优秀的数据结构能够帮助我们迅速返回单词的积极或者消极情感分数。另外,如果该单词不在字典中,则返回一个-1。交给我们的后续处理。通过调用下面的代码,我们能够迅速返回要给单词的积极情感分数,消极类似。
t = senti_word["PosScore"][senti_word["SynsetTerms"] == word]if t.__len__() == 0:return -1else:return np.average(t)
汉堡王的品牌描述词与情感分数分析
对于 Burgurking 的分析,结果如下所示
=============================================Burburger_king品牌描述词与其情感分析正面情感均值 0.18669109504866543负面情感均值 0.12297212326992261
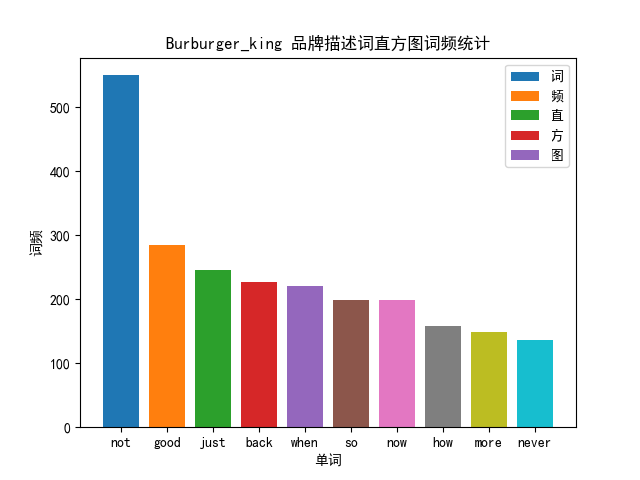
我们不难看出,not的次数是最多的。已经达到了550词。值得注意的一点是我们不会把一句句子中任意位置出现的not给包含进去,word.children 指挥返回当前 word 的前面一个词语。但是我们无法排除掉一些对于该品牌有负面想法,并且一直在刷负面评论的用户。我们在后面的分析中也发现了这个问题。从某种程度上来看,这也反映了一定的真实性。
0x04 基于LSTM的文本情感判别网络
训练数据集
我的训练数据集采用了 Sentiment 140 来自斯坦福大学的数据集包含了160万条推特文本。每个字段信息为
- 推文的极性(0 =负,4 =正)
- 推文的ID(2087)
- 推文的日期(2009年5月16日星期六23:58:44)
- 查询(lyx)。如果没有查询,则此值为NO_QUERY。
- 发推文的用户(robotickilldozr)
- 推文的文本()
下载地址为 http://cs.stanford.edu/people/alecmgo/trainingandtestdata.zip
数据清洗与相关参数定义
我们所作的数据清洗工作于之前的基本相同。最后,我们将文本分为两个数据集。neg 和 pos。另外,我们只需要选推文的内容即可。由于设备方面的问题,160万条的推特文本我们的机器GPU无法装下,所以我们采用了数据集的子集来训练,也就是按照一定的随机顺序切分出了16万条推特文本,其中积极文本8万条,消极文本8万条。
清洗完的数据如下所示。以下文本全部为积极文本

以下是我们的一些描述性统计,其中积极文本8W条,平均长度11.30。消极文本8W条,平均长度12.17。我们的字典采用了 en_vectors_web_lg 其中有已经训练好的单词向量 27221 条。这将会作为我们word_embedding层的权重输入,并且冻结。而所有16W条推文中,只有1813个单词不在我们的字典中,可见我们的字典包含的东西还是很全的。
-------------------- POSITIVE TEXT --------------------Total positive sentences: 80001The average length of positive sentences: 11.30733365832927-------------------- NEGATIVE TEXT --------------------Total negative sentences: 80001The average length of negative sentences: 12.176685291433857The number of words which have pretrained-vectors in vocab is: 27221The number of words which do not have pretrained-vectors in vocab is : 1813
相关超参数
在开始网络之前,我们需要定义一些超参数
# 定义网络超参数HIDDEN_SIZE = 512LEARNING_RATE = 0.001KEEP_PROB = 0.5EPOCHES = 50BATCH_SIZE = 256
网络描述
我们采用的是LSTM网络,相比于其他网络比如说RNN,CNN而言,LSTM更加擅长捕捉长序列的关系。LSTM由于有记忆单元的存在,所以能够很好地学习和把我序列前后地依赖关系。因此在自然语言处理领域,有其独特地一番优势。我们建立地LSTM网络结构如下所示:
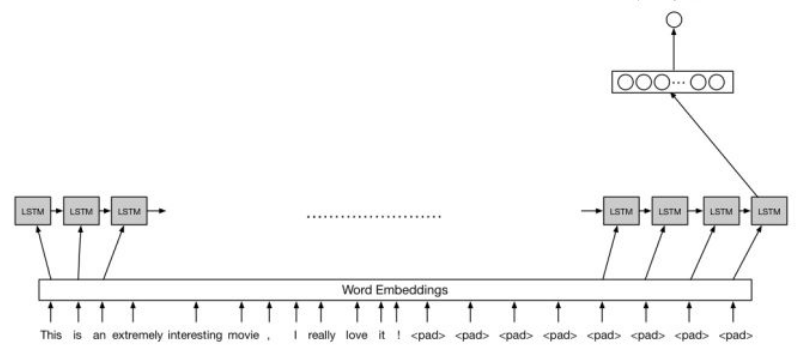
由于我们地词典比较大,而我们机器的GPU显存不是很充足,所以我最终采用了一个时间步的LSTM。相关的代码如下所示:

- 在embeddings层中,我们直接将向量输入到了LSTM单元中。而不是采用求和或者求平均的操作。
- 为了防止过拟合,我们利用drop_out 减去一些数据。
- 在执行完毕最后一个LSTM单元之后,我们取出LSTM单元 open gate的结果,然后传入到一个全连接层中,最终得到输出结果。
- 我们利用 sigmod 交叉熵损失函数作为我们的损失函数
- 在evaluation层中,我们定义,如果最后的输出分数值大于0.5则定义为POS,否则定义为NEG
网络正确性与评估
...
【这里有张图片,之前我忘记保存了...】
在50次迭代后,我们训练集的正确率已经达到了99%,而测试集的正确率也已经到了 78%。由于硬件的原因,我们没办法考虑多个LSTM的时间步,所以距离性能非常优秀的网络还有一定的距离,但是我们的网络已经可以满足我们的需要了。
此时我们停止训练,取出网络的主干,并加载我们的参数,就可以完成预测了。
0x05 基于SPSS的统计分析
建立完毕模型之后,现在通过输入一句句子就能够计算出该句子的情感分数了。我们之前认为:媒体发布推特的情感分数与用户对该推特评论的情感分数成正比,也就是说,媒体推文发布推特越积极,用户对该推特的评论也就越积极。因此,我们记 用户对该推特评论的情感分数均值 为 ,记 该推文的情感分数 为 。则上述假设可以简记为
现在,我们输入某个特定广告词的数据并用spss加载它们。我们写了一个简单的函数来计算 和
得益于我们之前的网络部分,我们现在可以将用户评论情感分数均值和媒体推特情感分数进行比较了。
数据相关性分析
由于 与 都是连续变量,所以我们采用了皮尔逊相关系数,并利用双尾检验来检查数据的相关性。结果如下所示
| 推特账号 | mean(SM) | Std(SM) | mean(SU) | Std(SU) | 相关 | 备注 |
|---|---|---|---|---|---|---|
| coca_cola | .06 | .13 | .06 | .03 | × | sig=.67 |
| Burburger_king | .04 | .23 | .03 | .04 | √ | sig<.01 |
| pepsi | .06 | .14 | .05 | .04 | × | sig=.33 |
| kfc | .04 | .06 | .00 | .03 | × | sig=.50 |
| McDonalds | .02 | .10 | .04 | .04 | √ | sig<.01 |
| 全部数据 | .04 | .15 | .04 | .04 | √ | sig<.01 |
回归分析
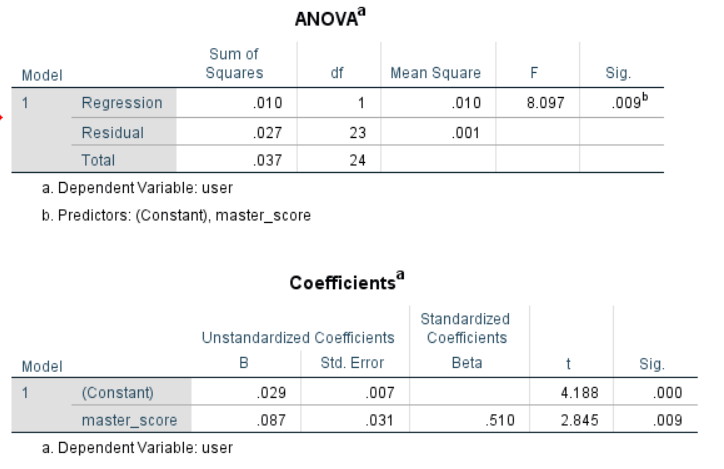
以 推文的情感分数 为自变量,用户对该推特评论的情感分数均值 为因变量,一元线性回归的结果表明,对于汉堡王而言, 可以预测 。(a=.05 sig<.01 F=8.10)
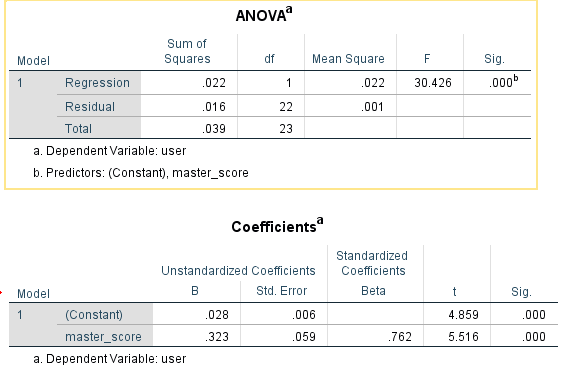
以 推文的情感分数 为自变量,用户对该推特评论的情感分数均值 为因变量,一元线性回归的结果表明,对于麦当劳而言, 可以预测 。(a=.05 sig<.01 F=30.42)
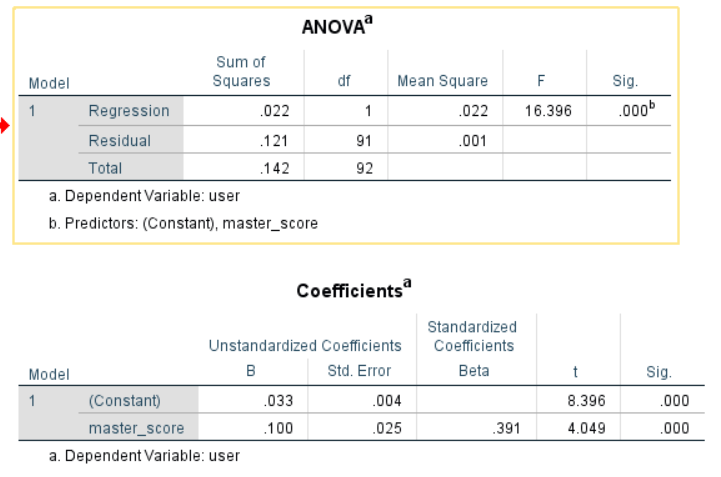
以 推文的情感分数 为自变量,用户对该推特评论的情感分数均值 为因变量,一元线性回归的结果表明,对于我们爬取所有的五个品牌的数据而言, 可以预测 。(a=.05 sig<.01 F=30.42)
0x06 总体结果分析
通过对于上述结果的内容进行挖掘,我们发现了一些共性的问题,将在这部分进行探讨并得出一些结论。
媒体发布推特的情感分数与用户对该推特评论的情感分数成正比。
在上述SPSS的分析结果中,我们发现汉堡王和麦当劳 推文的情感分数可以预测用户对该推特评论的情感分数均值。而同类的快餐类媒体肯德基则没有这样的现象。甚至二者的数据不存在相关性。我们推测这可能是用户群体的关系,但是由于我们对于用户信息的挖掘程度不是很充足,结论也只能得到这一步。
另一方面,对于百事可乐和可口可乐而言,我们之前的假设并不成立。尽管可口可乐和百事可乐是软饮料公司的两大巨头,但是还有非常多的因素影响着我们的结果。而且我们仅仅爬取了2019年中评论数大于50的群体,所以在结果的解释上有些偏颇。对此,我们保留结论。如果日后有机会,我们会继续对这个问题进行探讨。
最后,我们发现了当我们将所有的数据整合到一起的时候,所有的数据具有相关性并且可以建立回归方程。我们推测汉堡王和麦当劳中显著的数据带动了所有的数据。当然也有可能是其他三个品牌数据量比较小,在数据量增大之后,增大了数据点落在正态分布区间内的概率,从而使得我们的结果显著。对此,我们可以认为媒体发布推特的情感分数与用户对该推特评论的情感分数成正比。
官方发布推特的积极性情感普遍比较高。并倾向于用积极的形容词来形容它们的产品
我们综合了SPSS分析中的所有数据,我们发现,媒体发布推特中,有积极情绪倾向的与消极情绪倾向的比例大概为2:1。我们所说的倾向是指大于0的情感维度代表积极,反之代表消极。因此我们认为官方发布推特的积极性情感普遍比较高。这也是一个比较容易被接受的观点。
用户倾向于在推文的评论中调侃该公司的竞争对手
在可口可乐的用户评论词云中,我们发现pepsi单词总数为54个,为所有名词词频的第四名。而百事可乐的用户评论词云中,我们发现coca cola单词总数为48个,为所有名词词频的第十六名。但是在百事可乐和可口可乐的媒体发布词云中,两者几乎没有互相谈及对方。
另一方面,在汉堡王和麦当劳的用户评论词云中,我们也发现了KFC一词占据了一定词频。同样的结论,我们发现媒体并没有互相谈及对方。
我们以可口可乐的一条推文为例,阐释该结果。我们选取的该条推文是在所有可口可乐的数据中,用户评论中带有pespi单词最多的数据。该推文的部分数据如下所示(第一行为推文原文,下面为用户评论)
Together we can make world of difference #TogetherIsBeautifulThis is what villian would sayviva pepsiPepsi has an initiative on here to help feed the hungry Any good PR like that from CocaCola Keep those cola wars humanity driven...
在该条推文中,我们发现有超过20个pepsi单词。而推文的意思是让我们一起创造世界的不同。用户调侃的内容主要包括了和百事一起,或者说百事和可口可乐各有自己的侧重点。通过浏览该数据,我们大概得出用户的内容是调侃的为多。那么用户的情感也都应该是欢快的。对此,我们专门对于可口可乐的所有推文评论中的两个品牌词语进行分析,得到的结论如下所示
可口可乐评论中,用户对于百事可乐 pepsi 的描述词情感均值分数正面情感均值 0.14522299066395455负面情感均值 0.07420494836488813可口可乐评论中,用户对于可口可乐 coca cola 的描述词情感均值分数正面情感均值 0.18035180753668315负面情感均值 0.07402833096573377
我们发现,两者的负面情感分数基本相同,但是用户对于可口可乐的评价分数更加高一些。这就意味着尽管用户是在调侃。那么对于每条的分数如何呢?
首先我们对比积极分数,我们不难发现,在所有10个数据文件中,在可口可乐推文的用户评论中,与可口可乐相关的品牌描述词积极情感均值普遍比百事可乐的品牌描述词积极情感均值高
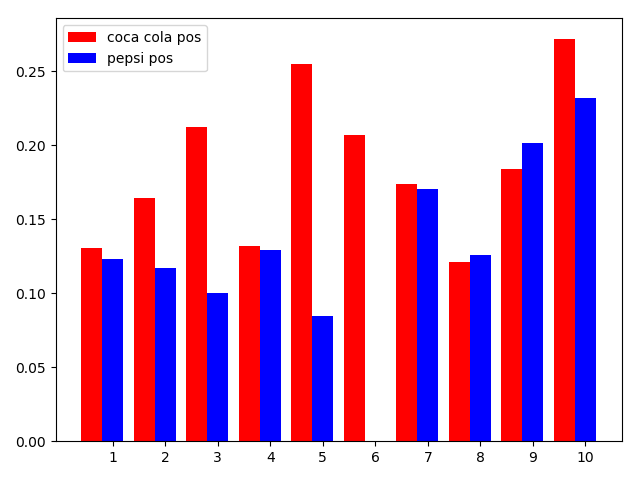
之后我们对比消极分数,我们又发现,在所有10个数据文件中,在可口可乐推文的用户评论中,与可口可乐相关的品牌描述词消极情感均值普遍比百事可乐的品牌描述词消极情感均值低
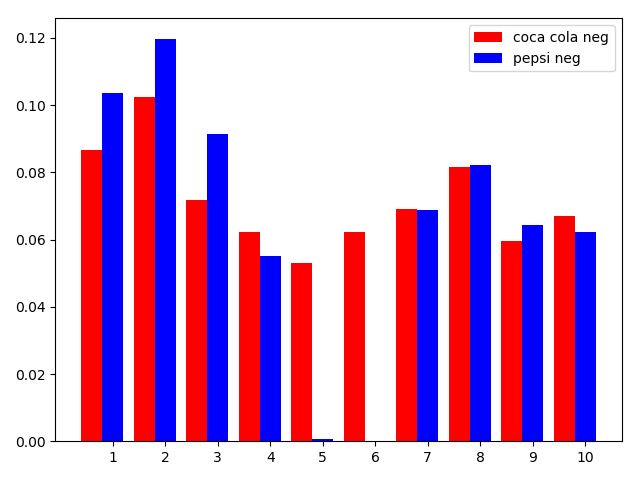
通过可口可乐与百事可乐的分析,我们发现这种调侃更加倾向于一种良性的调侃,而不是恶意的。更多的用户只是想在谈及本公司的产品的时候稍微提及一下与他的竞争者,起到找乐子的目的,而不是一定认为该公司竞争者的产品比本公司的产品更加优秀。
尽管这个结论仅仅是通过分析了一家公司,比较片面,但是也从一定程度上说明了问题。
0x07 不足,思考与总结
在实践过程中,我们遇到了一些困难,在完成模型之后,我们也认识到我们的实验部分还有诸多可以提高的地方。我们认为,我们的研究存在以下几点不足
缺乏对于推特媒体平台特点的分析
由于在实验初期,我们尝试申请推特的开发者账户,遇上了很多问题。尽管推特官方在回复我们的邮件中谈及,会尽快审批我们的开发者账户,但是直到我们研究报告完成。依然没有收到推特官方的回复。因此,我们在爬取文本的时候只能用selenium爬虫而不是通过推特的官方API接口获取数据。
这就导致了我们没法对一类的问题进行分析。比如说推特的TAG(形如#KFC,微博等中国的自媒体平台也有这样的TAG)。由于收集的数据零散并且密度比较低。所以一个TAG可能只有不到十条用户回复提及,所以我们没办法分析TAG。
另一方面,本来我们还希望对评论用户的位置来进行分析。希望能够发现媒体发布推特情感分数与用户地理位置聚集程度之间的关系。我们尝试了用爬虫去访问用户主页并爬取数据,但是推特平台的反爬虫机制阻止了我们密集的网络请求,为此我们小组牺牲了两个推特账号。并且对于评论者数据的分析也只能放弃。
数据总数不足,无法体现大数据与数据挖掘特点
尽管我们的数据总数爬了很多。但是如果从数据挖掘与大数据分析角度出发,我们数据还有些少。尽管每个媒体发布推特底下的评论数一般都有百余条,但是我们总体爬取的推特数量比较少。最多的百事可乐,我们一共爬取了25组数据,每组数据包括了一句官方发布的原始推文和至少50条的用户评论。最少的是KFC,一共爬取了9组数据。而且用户的评论有些是空语句或者简短的语气词,表情符号等,这些都不在我们的分析范围只能只能剔除。尽管剔除之后数据干净了很多,但是总体数量大打折扣。
另外由于技术原因,我们无法分析用户发布的表情包和图片,这些也限制了我们最终的一些结果。但是考虑到图文结合需要用到多模态神经网络,这对于我们而言技术难度实在太高,因此我们放弃了分析图片的想法。
模型存在过拟合现象
我们的模型采用了长短期记忆网络,由于时间比较仓促,而我们小组成员的精力有限。我们没有对我们爬取的推特数据集进行标注,而是直接把所有爬取的数据输入到了我们训练完毕的网络中去。这可能导致我们的模型可能仅仅是对于16万条推特数据集拟合的比较好,而对于我们爬取的数据拟合得不太妥当。
另外,我们仅仅采用了单个时间步的LSTM网络。而且我们的Word Embedding 层采用了 spacy的预训练单词向量,并且冻结了权重。由于硬件等问题,我们没办法利用更加复杂的LSTM网络。所以在模型的性能上还有诸多可以提升的地方。
