@windwolf
2020-05-20T02:39:14.000000Z
字数 11550
阅读 557
Sailing 之 实体计算规则
Sailing
背景
贸易, 物流和金融行业, 一个单据内部往往包含了大量的字段, 这些字段之间也有着错综复杂的逻辑关系.
就拿基本的出口销售订单来说:
每个订单明细的外销单价, 数量, 汇率, FOB金额之间存在一组计算关系;
每个订单明细的预估采购单价, 数量, 不含税金额, 增税率, 增税额, 含税金额, 退税率, 退税额之间存在一组计算关系;
每个订单明细的数量, 箱号, 包装件数, 每件数量, 每件毛重, 毛重, 每件净重, 净重, 每件体积, 体积之间存在一组计算关系;
以上内容往往还需要汇总到整单;
每个订单预估费用的增减性质, 费用名称, 费用额, 费用比例, 整单金额存在一组计算关系;
以上费用预付项目也需要汇总到整单;
以上费用还需要分门别类分摊到订单明细;
传统上需要在上述这些字段对应的表单元素上绑定事件, 在事件处理器中编写和这个字段有关系计算逻辑.
大多数情况下, 这些计算关系还是级联的, 这时还需要针对各种UI组件的特性来决定需要编写多少级联计算逻辑.
这种做法会导致以下几个问题:
1. UI逻辑和业务逻辑混杂. 由于业务逻辑必须写在UI触发的事件处理器上, 导致业务逻辑和UI高度耦合.
2. 容易遗漏业务逻辑. 一个字段变化后, 往往需要重新计算多个字段, 这些很容易遗漏. 比如数量变化后, 需要计算不含税金额; 需要计算每件数量; 需要重新分摊费用(如果按照数量分摊);
3. 级联计算不容易分析. 比如数量变化后, 需要重新计算不含税金额, 从而级联计算含税金额, 退税额, FOB金额等. 这些级联是否需要在数量变化的时候硬编码, 往往取决于级联的UI组件的类型, 更有甚者, 一不小心可能引起死循环, 这些问题很难通过代码静态分析清楚.
4. 业务逻辑高度冗余. 为了规避问题3, 采取的策略往往是在每个字段触发时, 硬编码所有的级联计算, 这就引起了问题2, 同时导致同样的代码在多个UI组件事件处理器中反复出现, 对修改业务逻辑的人来说, 这就是噩梦本梦.
5. 调试困难. 修改了一个字段后的完整计算逻辑可能分散在多个级联的事件处理器中, 导致调试非常困难.
这种方法的好处是无限的自由度. 由于工作在UI框架这个层面, 因此几乎能处理任何场景.
框架
为了解决以上这些问题, 我们需要做到以下几点:
- 业务计算逻辑需要和UI彻底隔离
- 一条业务计算逻辑只写一遍
- 无需关注如何级联计算
- 高性能
- 容易调试
显然, 硬编码计算逻辑后顺序执行的办法是行不通的, 我们需要一个规则引擎.
使用这个引擎只需要做两件事:
- 编写一套计算规则;
- 将整个实体和本次触发的位置传入引擎;
引擎就会按照规则级联触发若干的规则, 并将结果应用到实体中. 等规则触发安定后, 返回修改后的实体.
以下为规则引擎的架构图
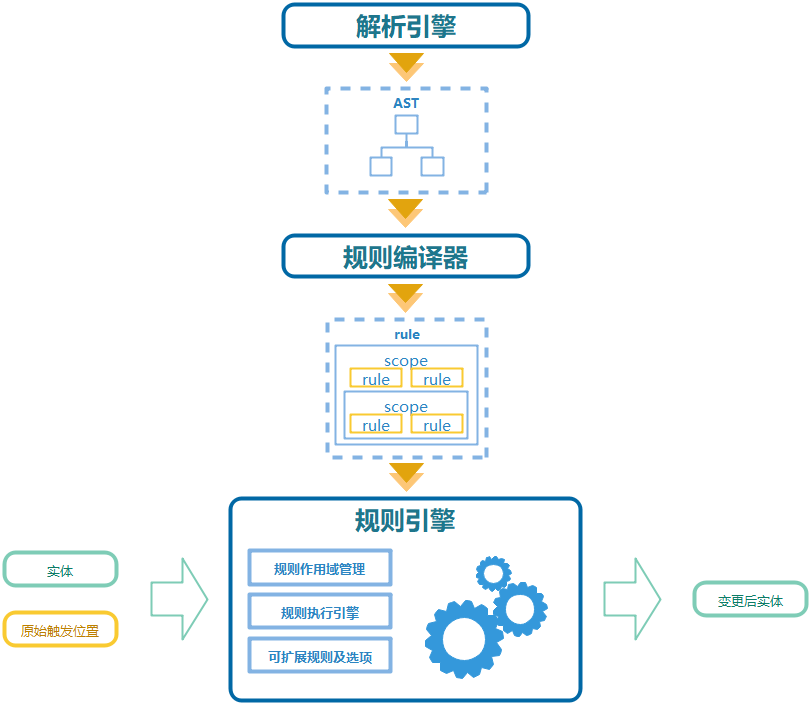
规则引擎分为规则编译器, 和执行引擎两部分.
规则编译器负责将业务规则文本编译成执行引擎方便执行的内部结构. 执行引擎包括了四种基本规则, 八种规则选项, 以及作用域管理器.
其中执行引擎包含了Assign, VarDeclare, Append, Remove四条规则以及一组可扩展的规则选项, 目前包括: include, exclude, condition, trigger, atnew, multiUpdate, multiTrigger, cache, break八个选项.
使用说明
赋值规则
让我们先从一个简单的例子来看看规则引擎是怎么工作的.
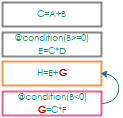
C=A+B; //规则一E=C*D; //规则二H=E+G;G=C*F;
以上就是计算规则定义. 虽然计算规则的语法看起来很像普通的QSS脚本, 但含义并不相同.
这里并不是从上往下按顺序执行的赋值语句, 而是四条规则, 这四条规则是并列的.
每行代表一条规则, 用分号结尾. 双斜杠后面的内容表示注释.
每条规则中等号右侧是一个QSS表达式, 其中出现的任何字段如果发生了变更就会触发这条规则;
规则执行时, 首先对QSS表达式求值, 随后将值应用到等号左侧指定的字段上.
规则执行后, 如果字段的值发生了变化, 可能又会触发其他计算规则, 如此级联触发, 只到不再触发其他规则(默认情况下, 已经触发过的规则不再触发).
上例中, 如果在表单上改动了
A, 则:
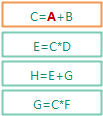
首先触发第一条规则, 因为这条规则的右侧引用了A.
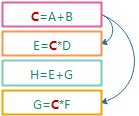
这条规则改动了C,C出现再第二, 四条规则中, 因此连锁触发图中紫框表示当前正在执行的规则, 橘框表示待执行的规则, 绿框表示未触发的规则, 灰框表示已经执行过的规则, 下文同.
如果同时触发了多条规则, 那么规则的触发顺序是从上往下的.
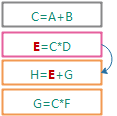
第二条规则改动了E, 因此连锁触发第三条规则.
级联触发的规则的执行顺序会排在现有执行队列的最后.
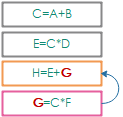
第四条规则执行时, 也会连锁触发第三条规则. 需要注意的是: 即使上一步中已经触发了这条规则, 现在还是会再次把这条规则加入到待执行规则队列, 之后最后因为已经执行过了, 所以不会重复执行.
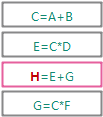
第三条规则执行后, 没有连锁触发下一条规则. 在这个之后, 这条规则还会再执行一遍, 因为这条规则之前触发了两次, 但第二次执行的时候, 什么也不会发生.
此外, 还需要注意一个细节, 规则求值后复制给字段时, 采用的是值传递, 也就是说, 会另外复制一份之后再赋值.
condition选项
有些时候, 规则触发需要附加一定的条件, 只有条件满足的情况下才能触发. 例如:
@condition(B>=0)C=A+B;E=C*D;H=E+G;@condition(B<0)G=C*F;
第二, 四条规则带有条件.
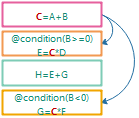
前两步过程和之前的例子一样.
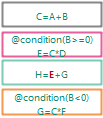
当将要执行第二条规则时, 发现条件步满足, 于是跳过执行.
第四条规则触发时, 条件满足, 因此继续触发.
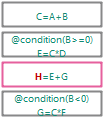
后续执行和前例相同.
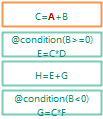
需要注意的是, condition中出现的字段也会作为规则触发依据.
批量添加选项
如果相同的选项需要附加到多条规则上, 一种办法是在每条规则上添加选项, 例如:
@condition(B>=0)C=A+B;@condition(B>=0)G=C*F;
如果添加的选项一样的话, 也可以简写为以下形式:
@condition(B>=0) {C=A+B;G=C*F;}
include/exclude选项
一般情况下, 赋值规则右边以及condition中出现的所有字段都作为这条规则的触发条件, 但有时候需要对这条规则做一些修订. 可以使用include额外增加触发字段, 用exclude排除触发字段.
@exclude(A) @include(D, E) C=A+B;
上例中的规则, 一般情况下触发条件为A和B, 加上include选项之后, 变成A, B, D, E, 再加上exclude选项之后, 变成B, D, E.
multiUpdate选项和multiTrigger选项
默认情况下, 每个字段(不是每条规则)只会更新一次, 换句话说, 某条规则一旦修改了某个字段, 那么即便另外一条规则也触发了修改这个字段, 此时字段的值也不会变. 加上multiUpdate选项就可以绕过这个限制.
看一个例子
A=B+C;E=D+B;@multiUpadte() A=E+F;
当B字段修改时, 会触发第一条, 第二条规则. 第一条规则修改了A, 第二条规则级联触发了第三条规则, 第三条规则也会执行. 如果没有加上multiUpdate选项, A不会发生变化, 因为之前已经修改过了, 加上了之后, A的值会再次修改.
此外, 默认情况下, 每条规则也只会触发一次,
加上multiTrigger选项可以绕过这个限制.
A=B+C;E=A*A;@multiTrigger() @multiUpadte() D=E+B;
当B变更后, 默认情况下, 先触发第一, 第三条规则, 此时D的值为老的E加上新的B, 随后通过触发规则二, 并级联触发规则三. 此时规则三已经触发过了, 不执行, 因此得到了错误的结果. 如果加上multiTrigger选项后, 规则三会再次触发, 此时再配合multiUpdate可以确保D得到正确的值.
important选项
很多情况下, 为了确保有些规则必定会执行, 会在规则上添加multiUpdate和multiTrigger选项, 但添加了这两个选项会有两个副作用: 一个是规则重复触发导致规则爆炸, 性能变差; 另一个是不小心的话会引入无限循环. 为此特别添加了一个important选项.
附加这个选项后的规则, 平时的行为和普通规则无异, 仅在规则执行的最后, 会统一触发一遍, 触发后实际执行与否也受condition选项控制, 且执行后不再连锁触发其他规则.
作用域
大多数时候, 单据实体没有前面的这么简单, 往往带有层次结构, 例如:
- A(基本字段)
- B(基本字段)
- C(一对一子对象)
- C1(基本字段)
- C2(基本字段)
- C3(一对多子对象)
- C31(基本字段)
- C32(基本字段)
- D(一对多子对象)
- D1(基本字段)
- D2(基本字段)
- D3(一对一子对象)
- D31(基本字段)
- D32(基本字段)
当我们要定义子对象(无论是)上的规则时, 需要声明作用域. 使用with关键字来声明一个作用域. 例如:
with C {C1 = C2 * 10;C2 = parent.A + 10;}
上例中声明了一个作用域C, 并在这个作用域中定义了两条规则. 这个的意思是, 这两条规则都是在定义在
C这个一对一的子对象中的, C1表示的是C中的C1, C2也类似.
在子对象中应用父对象的字段, 可以用parent关键字.
事实上, 所有的规则都有作用域, 顶层的也不例外, 规则引擎会自动为顶层规则建立一个默认的指向根对象的作用域.
再来看一个例子:
with D {D1 = D2 * D3.D31;}
上例定义了一个在D作用域中的规则. D是一个一对多的集合子对象, 这条规则会绑定到D集合中的每个元素上. 可以理解为每个集合元素上都有一整套规则的副本.
假设D集合中有两个元素, 那么第一个元素中的D2变化时, 默认情况下, 只会触发对第一个元素中的D1的修改, 不影响第二个元素.
这个例子里还有个细节需要注意下: 规则右边部分是标准QSS, 因此也可以使用成员访问操作符.
trigger选项和分摊函数
上例中提到了对集合性质的作用域来说, 每个集合元素都有一份规则的副本, 也就是说, 集合元素中字段变化只会触发当前元素中的规则. 对大部分情况来说, 这一点没有问题, 但对于需要做费用分摊的场合来说, 这个就有问题了. 此时就需要用到trigger选项.
比如: 希望建C.C3.C31的值合计后, 按照D.D1的比例分摊到D.D2中,
with D {@trigger(all) D2 = #分摊(#sum(parent.C.C3.C31), D1);}
分析一下这条规则, 当D中某个元素的D1变化时, 会触发绑定到当前元素的这条规则, 正常情况下, 当前元素的D2会改变成分摊后的值. 但一般来说, D1改变了, 也会同时影响D集合中其他元素的D2值. 为了解决这个问题, 加上了@trigger(all)选项. 加上这个选项后, 这条规则不仅在当前元素中会触发, 还会在绑定的所有元素中触发. 换句话说, 没有这个选项时, 规则时按照绑定来触发的, 加上后, 规则按照规则来触发.
这个例子另外还有几个细节需要注意下:
- 一个是右边的QSS可以使用外部函数;
- 一个是parent.C.C3.C31是QSS的向量化用法;
分摊函数的基本作用是: 将A分摊到一个集合中的每一个元素的某个字段中, 分摊时候的比例根据元素中B字段的占比, 最后一条等于A的剩余分摊数, 依此来避免舍入误差.
分摊函数完整的函数签名如下:
#分摊(total, depTotal, dep, filter=, rounding=)
前三个索引位置参数, 后两个是命名参数.
- total: 数值, 位置索引参数, 必填. 待分摊的总数.
- depTotal: 数值, 位置索引参数, 必填. 分摊依据总数.
- dep: 数值, 位置索引参数, 必填. 当前行分摊依据.
- filter: lambda, 命名参数, 可选. 将集合的每一条应用到这个表达式中, 并根据返回值来分组, 每组分别计算分摊. 如果不填, 则所有的元素按一个分组算.
- rounding: 整数, 位置索引参数, 必填. 分摊值舍入的小数位数. 默认不舍入. 规则引擎在字段赋值的时候会自动根据字段类型进行舍入, 所以在金额计算的时候, 往往需要提供这个参数, 确保舍入在分摊函数内部进行, 保证里外一致.
此外, 一般来说使用分摊函数必定需要trigger选项配合.
中间变量定义规则
在回顾一下上面分摊的例子.
with D {@trigger(all) D2 = #分摊(#sum(parent.C.C3.C31), D1);}
如果D集合中有100行, 一点某一行的D1变化了, 会触发100次规则计算, 每次计算的时都会重新合计C.C3.C31的值, 而这个值再整个过程中并不会发生变化. 从性能角度考虑, 更好的办法是计算一次并缓存起来. 中间变量定义规则就是整个作用.
改造后的分摊规则如下:
let _sum_C31:decimal2 = #sum(parent.C.C3.C31); //规则一with D {@trigger(all) D2 = #分摊(parent._sum_C31, D1); //规则二}
规则声明了一个名为_sum_C31的临时变量, 并进一步说明了整个变量的类型为decimal2. 这个变量的值为C.C3.C31的合计, 但求值过程只会在第一次使用的前一刻才会发生.
类型说明不是必须的, 但说明了之后, 可以让运行时行为更加智能, 比如这个例子里面说明了类型为decimal2, 那么元数据验证的时候, 可以发现类型不兼容的情况, 规则引擎也可以在执行时自动按两位小数舍入.
再来分析规则触发级联关系. 如果C.C3.C31变化了, 会触发规则一, 然后级联触发规则二; 与此同时, 如果D.D1变化了, 会触发规则二, 而规则二会检测到变量_sum_C31还没有求过值, 因此触发规则一的求值.
上面提到的第一种情况是常规的级联触发机制, 是推shi我们已经比较熟悉了; 第二种情况正好相反, 是拉式的, 其出发点是通过拉式惰性计算来提高性能.
外部数据源
有时候, 规则计算时需要用到实体以外的信息, 此时可以使用外部变量:
A = B*:E; // E为外部变量
每套计算规则规定了可以使用哪些外部变量, 详情参见手册.
变量定义规则的一个通常用法是从外部数据源提取一个值缓存起来.
cache选项
一套规则实例时可以多次使用的, ERP6.0中每个单据详情会创建一个单据实例, 每次界面上数据输入引起的规则触发都使用这一个单据实例. 默认情况下, 多次字段变更规则触发之前是会缓存临时变量的值的, 这样可以明显提高性能, 但如果这个行为影响了业务逻辑, 那么可以通过添加cache选项关闭缓存.
@cache(disable)let _E:decimal2 = #sum(:E); //规则一with D {@trigger(all) D2 = #分摊(parent._E, D1); //规则二}
上例中, 每次规则二触发, 都会连锁触发规则一.
增加/删除规则
赋值规则关注如何改变一个字段的值, 有时候我们需要动态向一个集合中添加或者删除元素, 此时可以使用append/remove规则. 看例子:
@condition(...)append D = new (D1=1, D2=3); // 某些条件下新增一行, D的元素, 内容为D1=1, D2=3
with D {@condition(...)remove; // 某些条件下删除当前行D}
这两条规则比较容易理解. 不展开了.
atnew选项
有些规则只需要在集合中添加新元素时触发, 可以使用atnew选项:
with D {@atnewD1 = D2;}
以上这条规则只会在D集合中新加了一个元素时, 在该元素上触发.
break选项
正常情况下, 赋值规则会级联触发其他规则. 如果有些特殊情况需要例外的话, 可以加上这个选项:
@break()A = B+C.C1; // 规则一with D {D1 = parent.A+D2; // 规则二}
上例中, 修改了B会触发规则一, 但不会进一步连锁触发规则二.
important选项
有些规则有计算方向的问题, 而有些规则是在任何情况下都成立的, 我们不希望看到这类规则因为触发条件等原因而意外的没有执行.
为这类规则添加important选项后, 那么无论是否触发与否, 都会在本轮规则执行的最后全部执行一遍(当然是要在满足condition的前提下), 以确保数据满足规则.
@important()A = B+C.C1;
important规则默认的执行顺序就是规则的自然先后顺序, 如果需要指定执行顺序, 在选中参数中指定顺序号, 越小的越高; 不填相当于0; 顺序号相同的规则采用自然先后顺序.
@important()A1 = B+C.C1; //第二条执行@important()A2 = parent.A+D2; //第三条执行@important(-1)A3 = parent.A+D2; //第一条执行@important(1)A4 = D2 * D3.D31; //第四条执行
context选项
实体计算规则可以在前台执行, 也可以在后台执行. 但前后台支持的qss环境不尽相同. 比如, 后台可以调用各种服务函数, 而前台环境不允许在实体规则中调用异步函数.
context选项可以用来控制规则在前后台的执行条件. context有三个选项:
all: 前后台都会执行. 这个也是context选项的默认值.
back: 仅在后台执行.
front: 仅在前台执行.
E = B+C.C1; // 前后端都执行@context()F = B+C.C1; // 前后端都执行@context(all)G = B+C.C1; // 前后端都执行@context(front)H = B+C.C1; // 仅在前台执行@context(back)J = B+C.C1; // 仅在后台执行
综合使用实例
下面看一个正式的例子, 是出运明细单中的实体计算:
// 总金额是个Element, 对规则引擎来说, 算子对象, 因此需要加上作用域with 总金额 {金额 = #isNull(#合计(parent.明细.销售总价),0);}合计金额 = #isNull(#合计(明细.销售总价),0);合计商品数量 = #isNull(#合计(明细.商品数量.数量),0);合计计价数量 = #isNull(#合计(明细.计价数量.数量),0);最终消费国=贸易国别;// 这个外部变量是通过UI上一个非绑定组件控制的, 可以由用户控制, 所以关闭缓存.@cache(disable)let totalLock=#env().status.findComponent('锁定总价').uiElement.value;// 设置了客户后, 付款客户跟着变@condition(客户!=null)付款客户=客户;折USD金额=总金额.金额*折USD汇率;折CNY金额=总金额.金额*折CNY汇率;with 费用 {// 默认为增加类型@condition(增减类型==null){增减类型=1;}折CNY金额=#isNull(金额.金额,0)*折CNY汇率;折USD金额=#isNull(金额.金额,0)*折USD汇率;}with 明细 {@condition(parent.totalLock==null||!parent.totalLock){销售总价=销售单价*计价数量.数量;}// :triggerMetadata是一个特殊外部变量, 保持本次级联触发的原始变更字段的路径// 下面规则的意思是: 计算模式是锁定总价的前提下, 数量变了算单价, 计算模式不是锁定总价的前提下, 总价变了算单价@condition(计价数量!=null && 计价数量.数量!=0 && ((parent.totalLock!=null && parent.totalLock && (:triggerMetadata=="明细.计价数量.数量" || :triggerMetadata=="明细.商品数量.数量")) || ((parent.totalLock==null || !parent.totalLock) && :triggerMetadata=="明细.销售总价"))) {销售单价=销售总价/计价数量.数量;}// 以下为新增明细时的初始化@atnew() {装运期限=parent.装运期限;@condition(订单号 ==null||订单号=='')订单号=parent.客户订单号;@condition(创建日期 != #dateNow())创建日期=#dateNow();}with 计价数量 {@condition(parent.商品和计价数量换算率>0)数量=#isNull(parent.商品数量.数量/parent.商品和计价数量换算率,0);@condition(parent.商品和计价数量换算率==1){组 = parent.商品数量.组;项 = parent.商品数量.项;}// 和计算单价类似的逻辑@condition(parent.parent.totalLock!=null && parent.parent.totalLock && parent.销售单价!=null && parent.销售单价!=0 && :triggerMetadata=="明细.销售单价") {数量=parent.销售总价/parent.销售单价;}}销售单价折USD=销售单价*parent.折USD汇率;销售总价折USD=销售总价*parent.折USD汇率;销售总价折CNY=销售总价*parent.折CNY汇率;with 采购数量 {@condition(parent.商品和采购数量换算率!=null && parent.商品数量.数量!=0)数量=#isNull(parent.商品数量.数量/parent.商品和采购数量换算率,0);with 组 {@condition(parent.parent.商品和采购数量换算率==1 && id==null) {id=parent.parent.商品数量.组.id;名称=parent.parent.商品数量.组.名称;}}with 项 {@condition(parent.parent.商品和采购数量换算率==1 && 名称==null) {id=parent.parent.商品数量.项.id;名称=parent.parent.商品数量.项.名称;英文名称=parent.parent.商品数量.项.英文名称;}}}@condition(parent.totalLock==null || !parent.totalLock) {采购总价=#isNull(采购单价*采购数量.数量,0);}@condition(:triggerMetadata=="明细.采购数量.数量" || :triggerMetadata=="明细.采购数量.数量")) || ((parent.totalLock==null || !parent.totalLock) && :triggerMetadata=="明细.采购总价"))) {采购单价=采购总价/采购数量.数量;}增值税额=采购总价/(1+海关编码.增值税率)*海关编码.增值税率;// 增退税率相同的情况下, 退税额直接等于增税额, 防止出现舍入误差@condition(海关编码.增值税率==海关编码.退税率) 退税额 = 增值税额;@condition(海关编码.增值税率!=海关编码.退税 退税额=采购总价/(1+海关编码.增值税率)*海关编码.退税率;@trigger(all) {运费=#分摊(parent.成本预测.国外运费折USD,#合计(parent.明细.销售总价),销售总价);保费=#分摊(parent.成本预测.保费折USD,#合计(parent.明细.销售总价),销售总价);其它=#分摊(parent.成本预测.国外其它费用折USD,#合计(parent.明细.销售总价),销售总价);佣金=#分摊(parent.成本预测.佣金折USD,#合计(parent.明细.销售总价),销售总价);国内费用合计=#分摊(parent.成本预测.国内费用折CNY,#合计(parent.明细.销售总价),总价);}佣金比例=#isNull(佣金,0)/销售总价折USD*100;商品FOB金额=销售总价折USD-运费-保费-其它-佣金;// 盈亏计算会不止一次的触发@trigger(all) @multiTrigger() @multiUpdate() {盈亏=#分摊(parent.成本预测.销售毛利,#合计(parent.明细.销售总价),销售总价);}换汇成本=(采购总价-退税额+国内费用合计)/商品FOB金额;with 海关编码{hs13位编码=编码+ciq码;}}with 成本预测 {let 含税采购金额=#isNull(#合计(parent.明细.采购总价),0);退税收入= #isNull(#合计(parent.明细.退税额),0);@condition(含税采购金额!=0)国内费用折CNY=含税采购金额*国内费用比例;@include(parent.费用.费用性质) @include(parent.费用.费用名称) {let _国外其他费用:销售#销售订单_费用=#过滤(parent.费用,f=>f.费用性质==0 && f.费用名称 '保费' && f.费用名称 != '运费' && f.费用名称 != '佣金');let _国外运费:销售#销售订单_费用 = #过滤(parent.费用,f=>f.费用性质==0 && f.费用名称 '运费');let _国外保费:销售#销售订单_费用 = #过滤(parent.费用,f=>f.费用性质==0 && f.费用名称 '保费');let _国外佣金:销售#销售订单_费用 = #过滤(parent.费用,f=>f.费用性质==0 && f.费用名称 '佣金');}// 大括号内的规则全都附带了include@include(parent.费用.折USD金额) {国外其它费用折USD=#isNull(#合计(_国外其他费用.折USD金额*_国外其他费用.增减类型),0);国外其它费用折CNY=#isNull(#合计(_国外其他费用.折CNY金额*_国外其他费用.增减类型),0);国外运费 = _国外运费.count()>0?(true:_国外运费.first().金额;null);国外运费折USD = _国外运费.count()>0?(true:_国外运费.first().折USD金额;0);国外运费折USD汇率 = _国外运费.count()>0?(true:_国外运费.first().折USD汇率;0);保费 = _国外保费.count()>0?(true:_国外保费.first().金额;null);保费折USD = _国外保费.count()>0?(true:_国外保费.first().折USD金额;0);保费折USD汇率 = _国外保费.count()>0?(true:_国外保费.first().折USD汇率;0);佣金 = _国外佣金.count()>0?(true:_国外佣金.first().金额;null);佣金折USD = _国外佣金.count()>0?(true:_国外佣金.first().折USD金额;0);佣金折USD汇率 = _国外佣金.count()>0?(true:_国外佣金.first().折USD汇率;0);}@include(parent.费用.增减类型) @include(parent.费用.费用性质)let _国内费用:销售#销售订单_费用=#过滤(parent.费用,f=>f.费用性质==1);@include(parent.费用.折CNY金额){国内费用折CNY=#isNull(#合计(_国内费用.折CNY金额*_国内费用.增减类型),0);}国外运费折USD=国外运费.金额*国外运费折USD汇率;保费折USD=保费.金额*保费折USD汇率;佣金折USD=佣金.金额*佣金折USD汇率;收购价=含税采购金额;货款实际成本=收购价-退税收入;实际成本=收购价-退税收入+国内费用折CNY;总收入金额折CNY=parent.折CNY金额;总收入金额折USD=parent.折USD金额;总费用=#isNull(#合计(parent.费用.折CNY金额*parent.费用.增减类型),0);let 总费用折USD=#isNull(#合计(parent.费用.折USD金额*parent.费用.增减类型),0);净收入金额折USD=总收入金额折USD-国外运费折USD-保费折USD-佣金折USD-国外其它费用折USD;净收入金额折CNY=净收入金额折USD*美元折CNY汇率;销售毛利= 净收入金额折CNY-实际成本;@condition(净收入金额折CNY!=0) {销售毛利率=销售毛利/净收入金额折CNY;}换汇成本=实际成本/净收入金额折USD;}
规则执行调试分析
未完待续
