@zhangsiming65965
2019-03-11T02:48:23.000000Z
字数 54953
阅读 286
云计算考题(140条详细答案版)
云计算考题
---Author:张思明 ZhangSiming
---Mail:1151004164@cnu.edu.cn
---QQ:1030728296
如果有梦想,就放开的去追;
因为只有奋斗,才能改变命运;
1.Rsync有几种模式?
三种模式:
1.本地间类似cp命令的数据传输模式;(本地间数据传输)
2.借助SSH通道在两台不同IP服务器间的数据传输模式;(网络间数据传输)
3.多组服务器之间,以socket监听进程的方式启动Rsync server端的数据传输模式。(C/S数据传输)
2.Rsync的socket模式的监听端口号?
默认监听873端口。
3.Rsync的限速参数?
--bwlimit=rate(带宽)
4.NFS挂载原理?
1.首先NFS服务端启动RPC服务,RPCsocket监听进程,默认监听固定端口111;
2.其次NFS服务端再启动NFS服务,NFS服务启动的时候需要向RPC服务进行注册端口信息,告诉RPC服务自己哪些端口开放供其他主机连接NFS共享存储网络磁盘;
3.NFS客户端安装RPC插件包,利用rpcbind连接NFS服务端rpcsocket监听进程,索要NFS服务器的端口号;
4.NFS服务端的RPC监听进程把自身开放挂载NFS的其中一个端口返回给NFS客户端,同时进行标记;
5.NFS客户端TCP三次握手到目标端口号,挂载到NFS服务端。
5.NFS服务的监听端口号?
NFS服务本身不监听任何端口,NFS服务端的rpc服务监听111端口。
6.NFS在/etc/fstab里配置开机自动挂载失败了。为什么?
因为/etc/fstab会优先于网络被Linux系统加载。网络没启动时,NFS客户端就无法连接到NFS服务端,从而无法实现开机挂载。
解决办法(两种):
1.chkconfig --level 2345 netfs on。(netfs的作用是在network服务启动后,强制二次读入/etc/fstab)
2.将nfs客户端挂载命令放在/etc/rc.local中。
7.Rsync+inotify每秒支持的并发传输文件数?(小于1秒)
200个文件。(10-100k)
8.企业自定义yum源的命令叫什么?请手写一个简单的自定义yum源文件(包路径:/root/rpm/)(详细描述.此题8分)
企业自定义yum源的命令: createrepo
[root@ZhangSiming yum.repos.d]# pwd/etc/yum.repos.d[root@ZhangSiming yum.repos.d]# cat local.repo[local]name=localbaseurl=file:///root/rpmgpgcheck=0enabled=1
9.mysql默认端口号
MySQLsocket监听进程默认监听端口3306。
10.新安装的mysql设置root密码的命令
mysqladmin -uroot password '密码'
11.创建一个叫做yunjisuan的库?
create database yunjisuan;
12.删除一个叫做yunjisuan的库?
drop database yunjisuan;
13.查看mysql.user表里的user.host.password字段的所有数据
select user,host,password from mysql.user;
14.MySQL插入一条数据(写语句的架构即可)
insert into 空间名.表名 (字段1,字段2…)values ('字段1 的值','字段2的值'…);insert into 空间名.表名 values ('字段1 的值','字段2的值'…);#第二种写法values中必须根据表中有几个字段就按顺序给几个值例子:insert into mysql.user (host,user) values ('localhost','root');insert into yunjisuan.user values ('zhangsan','1860011869');
15.MySQL更新一条数据(写语句的架构即可)
update 空间名.表名 set 字段1='字段1的值',字段2='字段2的值',… where 字段名='字段值';#where后面的字段条件表达式匹配具体要更改哪一行的字段数据例子:update mysql.user set password=password('666666') where host='localhost';
16.MySQL删除一条数据(写语句的架构即可)
delete from 空间名.表名 where 字段名='字段值';#where后面的字段条件表达式匹配具体要求删除哪一行的字段数据例子:delete from mysql.user where host='192.168.17.200';
17.授权账号yunjisuan拥有192.168.200.0/24网段的所有登陆和修改权限.密码333333
grant all on *.* to 'yunjisuan'@'192.168.200.%' identified by '333333';flush privileges;
18.让mysql的设置立刻生效(刷新)。
flush privileges;
19.查看当前用户的权限记录
show grants;
20.查看yunjisuan@'192.168.200.%'账号的权限记录
show grants for yunjisuan@'192.168.200.%';#hostIP的''引号必须加,user用户名的''引号可以不加
21.修改账户yunjisuan@'192.168.200.%'的密码为:666666
update mysql.user set password=password('666666') where user='yunjisuan' && host='192.168.200.%';flush privileges;
22.什么叫慢查询日志.它用来做什么的?如何打开慢查询日志(写出文件命令)(详细描述.此题8分)
慢查询日志用于记录所有执行时间超过long_query_time秒的SQL语句,可用于找出执行时间过长的SQL语句,便于优化,默认未开启。
开启方法:
[root@ZhangSiming ~]# cat /etc/my.cnf[mysqld]long_query_time = 5log-slow-queries = mysql_slow.log
之后重启mysqld服务器,慢查询日志文件就出现/usr/local/mysql/data/
目录下,默认叫mysql_slow.log文件
23.索引的分类(五种)
1.普通索引:最基本的索引类型,没有唯一性之类的限制
2.唯一性索引:与普通索引的区别在于,索引列的所有值都只能出现一
次,必须唯一,但是可为空
3.主键索引:是一种特殊的唯一性索引,必须指定为PRIMARY KEY,具有唯
一性的同时且不能为空
4.全文索引:全文索引,全文检索
5.单列索引与多列索引:索引可以是单列上创建的索引,也可以是多列上
创建的索引
24.事务的四个属性
1.原子性(Atomicity)
2.一致性(Conistency)
3.隔离性(Isolation)
4.持久性(Durability)
25.查看系统内置变量 autocommit的信息
show variables like 'autocommit';
26.mysql数据库的全备命令(备份所有的库所有的表)
mysqldump -u用户名 -p密码 [选项(--events --opt)] --all-databases | gzip [选项] > 备份文件路径
27.msyql数据库备份指定库(benet.yunjisuan)的命令
mysqldump -u用户 -p密码 benet yunjisuan > 备份文件路径#指定库不需要加任何--databases等选项
28.MySQL数据库开启二进制日志的配置文件的参数是什么?
[root@ZhangSiming ~]# cat /etc/my.cnf[mysqld]log-bin=mysql-bin
之后重启mysql,可以发现二进制日志文件在/usr/local/mysql/data/目录下
29.控制MySQL二进制日志大小的参数是什么?
max_binlog_size = 1024000#指定每次到达这个容量的时候建立新的二进制日志文件
30.MySQL数据库强制刷新binlog日志的配置文件参数
flush logs;
31.MyISAM引擎的特点(三条)
1.只对读数据支持非常好,不支持事务,功能单一,对系统资源占用小;
2.读写阻塞互斥;
3.一旦一个用户在写入数据,引擎直接对数据表进行表级别的锁定,其他用户不能写也不能读,不支持多用户并发写;
4.可以缓存索引,但是不缓存数据;
5.内存占用小,对服务器要求较低。
32.InnoDB引擎的特点(三条)
1.支持事务,支持事务的四种隔离级别,读写阻塞与事务隔离级别有关;
2.一旦写入数据,行级别锁定(但是全表扫描仍然会是表级别锁定);对写支持好,可以支持并发写;
3.可以缓存索引,也可以缓存数据;
4.对CPU、内存占用大,对服务器硬件资源要求比较高。
33.MySQL主从复制原理详解(基于二进制日志的主从复制)(详细描述.此题8分)
操作流程:
- 主库:
1.开启binlog二进制日志log-bin = mysql-bin
2.创建主从复制账号及密码
3.修改/etc/my.cnf配置文件[mysqld]模块中 server-id=1- 从库:
1.开启中继日志 relay-log = relay-bin
2.在从库进行主从复制验证信息录入,告诉从:主库IP地址和端口号、主从复制账号及密码、要同步的binlog日志名及在当前binlog日志中所处的位置
3.修改配置文件server-id 不等于1
4.在从库激活主从复制 start slave
详细过程及原理:
1.在从库上执行start slave命令激活主从复制
2.一旦主库的二进制日志文件发生改变,从库的I/O线程会通过主从复制账号向主库进行验证,验证信息包括:
(1)主库IP和主库mysql socket进程的端口port
(2)从库主从复制的账号和密码
(3)复制主库哪个二进制文件的名字
(4)这个二进制文件中position具体位置
3.验证成功后,主库的IO线程就会把二进制日志文件中的二进制数据和一个最新的POS数据复制传递给从库的IO线程,从库的IO线程就会把传递过来的二进制数据放到中继日志末端(relay-log),把POS数据传到从库中的master.info中(代表这次完成后主从复制复制到了新的POS位置,下次从这个位置开始复制)
ps:从库找主库验证信息也保存在这个master.info中
4.从库的SQL线程会实时检测本地的relay-log中I/O线程新增加的日志内容,然后及时地把relay-log文件中的二进制数据翻译解析为一条一条的SQL语句,执行保存到从库的data数据目录中,完成主从复制
34.MySQL临时锁表只读命令
flush table with read lock;
35.MySQL解除临时锁表只读命令
unlock tables;
36.开启MySQL中继日志的配置文件参数
[root@ZhangSiming ~]# cat /etc/my.cnf[mysqld]relay-log=relay-bin
之后重启mysql,可以发现二进制日志文件在/usr/local/mysql/data/目录下
37.输入命令临时跳过一条sql线程的解析的命令
set global sql_slave_skip_counter=1;#在MySQL主从同步,从库中执行
38.MySQL主从复制延迟时间.在哪里查看?(写出参数)
show slave status\G#下面显示的信息有一句Seconds_Behind_Master: 0#0表示没有延迟
39.MySQL主从复制延迟时间大.都有哪些可能的原因及你建议的解决办法?(详细描述.此题8分)
1.主库的从库太多,导致复制延迟
解决:一般一个主库五个从库最多,不可再添加从库
2.从库的硬件条件比主库差,导致复制延迟
解决:提升从库硬件条件
3.慢SQL语句太多
解决:开启从库的慢查询日志,会记录执行时间超过指定时间的SQL语句,告诉开发,让开发去更新优化语句
4.主从复制的设计问题,从库的SQL线程为单线程,只能一条一条处理并发过来的SQL语句,所以会有延迟
解决:更新版本,mysql5.6版本之后从库的SQL线程为多线程,大大降低了延迟
5.主从库之间的网络问题
解决:优化网络
6.主库读写压力大,导致复制的时候就产生了延迟
解决:更新主库硬件配置
40.假如MySQL的binlog日志把系统盘空间占满了.你如何在不影响数据安全的情况下解决这个问题?
MySQL主从复制环境:
主库:mysql> show master status;+------------------+----------+--------------+------------------+| File | Position | Binlog_Do_DB | Binlog_Ignore_DB |+------------------+----------+--------------+------------------+| mysql-bin.000004 | 204 | | |+------------------+----------+--------------+------------------+1 row in set (0.00 sec)#查看MySQL主库正在使用哪个二进制日志文件从库:mysql> show slave status\G*************************** 1. row ***************************Slave_IO_State: Waiting for master to send eventMaster_Host: 192.168.17.183Master_User: checkaccountMaster_Port: 3306Connect_Retry: 60Master_Log_File: mysql-bin.000004Read_Master_Log_Pos: 204...省略以下信息...#看从库复制主库二进制文件复制到了哪里,确认没有复制延迟主库:mysql> purge master logs to 'mysql-bin.000004'; #删除正在使用的二进制日志之前的所有二进制日志Query OK, 0 rows affected (0.00 sec)mysql> show master logs;+------------------+-----------+| Log_name | File_size |+------------------+-----------+| mysql-bin.000004 | 204 |+------------------+-----------+1 row in set (0.00 sec)#可以看到,只剩最新的二进制日志文件了;既然从库已经备份好了的数据,就可以从主库删除相关二进制日志文件从而优化磁盘空间[root@ZhangSiming ~]# cat /etc/my.cnf[mysqld]log-bin=mysql-binexpire_logs_days = 7#最后再主库加入二进制日志过期时间,7天默认销毁mysql> show variables like '%expire%';+------------------+-------+| Variable_name | Value |+------------------+-------+| expire_logs_days | 7 |+------------------+-------+1 row in set (0.00 sec)
41.MySQL5.6x版和MySQL5.7x版本的数据库有什么新特性?
MySQL5.6版本新特性
1.支持启用GTID,在配置主从复制,传统的方式里,你需要找到binlog和POS点,然后change master to 指向。在mysql5.6里,无须再知道binlog和POS点,只需要知道master的IP/端口/账号密码即可,因为同步复制是自动的,MySQL通过内部机制GTID自动找点同步,避免了增量同步的遗漏或者重复;
2.从库支持无损复制、延迟复制、基于库级别的并行复制;
3.基于Row复制只保存改变的列,大大节省磁盘空间,网络,内存等;
4.mysqlbinlog可远程备份binlog;
5.可统计信息的持久化。避免主从之间或数据库重启后,同一个SQL的执行计划有差异;
6.支持全文索引;
7.支持把Master和Slave的相关信息记录在Table中;原来是记录在文件里,现在则记录在表里,增强可用性;
8.支持多线程复制:事实上是针对每个database开启相应的独立线程,即每个库有一个单独的sql_thread;从库支持多SQL线程。
MySQL5.7版本新特性
1.支持在线开启GTID复制;
2.可在线修改Buffer pool的大小;
3.可查看当前正在执行的SQL的执行计划;(EXPLAIN FOR CONNECTION)
4.引入了查询改写插件(Query Rewrite Plugin),可在服务端对查询进行改写;
5.引入ALTER USER命令,可用来修改用户密码,密码的过期策略,及锁定用户等;
6.mysql.user表中存储密码的字段从password修改为authentication_string;
7.支持表空间加密;
8.优化了Performance Schema,其内存使用减少;
9.同一触发事件(INSERT,DELETE,UPDATE),同一触发时间(BEFORE,AFTER),允许创建多个触发器。在此之前,只允许创建一个触发器;
10.引入了新的逻辑备份工具-mysqlpump,支持表级别的多线程备份;
11.引入了新的客户端工具-mysqlsh,其支持三种语言:JavaScript, Python and SQL。两种API:X DevAPI,AdminAPI,其中,前者可将MySQL作为文档型数据库进行操作,后者用于管理InnoDB Cluster;
12.mysql_install_db被mysqld --initialize代替,用来进行实例的初始化;
13.可设置SELECT操作的超时时长;(max_execution_time)
14.可通过SHUTDOWN命令关闭MySQL实例;
15.SQL线程变为组提交,批量结息SQL语句,再往从库中写。
42.用户访问网站的基本流程(详细描述.此题8分)
1.用户在WEB浏览器输入域名;
2.DNS解析出域名对应的IP地址;
3.WEB浏览器TCP三次握手连接到WEB服务器,之后WEB浏览器给WEB服务器发送一个HTTP请求URL,告诉WEB服务器用户想要干什么;
4.WEB服务器响应用户的请求,发送一个响应报文给WEB浏览器;
5.WEB服务器关闭http连接,TCP连接(连接保持时间后)WEB浏览器遵循HTTP协议解析响应包到屏幕上给用户。(静态网页Web浏览器解析,动态网页WEB服务器解析)
43.DNS域名解析流程(DNS递归查询.DNS迭代查询)(详细描述.此题8分)
DNS递归查询:
1.主机查看内存有没有映射;
2.主机查看本地映射文件有没有映射;
3.主机将DNS域名解析请求发给本地设置的DNS服务器;(LDNS)
4.LDNS查看内存有没有映射;
5.LDNS查看映射文件有没有映射;
6.LDNS查看域名记录本文件有没有映射,如果都没有,就会请求外援进行DNS迭代查询。
DNS迭代查询: 比如查找www.baidu.com的ip地址
1.LDNS向根服务器请求www.baidu.com域名解析;(全球公开的最大的DNS服务器,根服务器,有十三个,其中一种服务器叫做点服务器,所有和点有关系的.com、.cn、.xx都在这里可以找到)
2.根DNS服务器会把对应的.comDNS服务器地址返回给LDNS;
3.LDNS获取到.com对应的DNS服务器地址后,就会去.com服务器请求www.baidu.com域名的解析,.com服务器会把baidu.com对应的DNS服务器地址返回给LDNS;、
4.LDNS再去baidu.com服务器请求www.baidu.com域名的解析,baidu.com服务器会反馈www.baidu.com对应的IP解析记录。如果此时还没有找到解析记录,就表示企业的域名人员没有为www.baidu.com域名做解析,即网站还没架设好;
5.最后,LDNS保存内存一份映射,之后发给主机;主机同样保存内存一份映射之后用解析出的ip三次握手连接到百度WEB服务器;这种从根DNS服务器开始一点一点迭代的过程叫做DNS迭代查询。
44.http和https的默认端口号?
http协议默认访问WEB服务器的80端口;
https协议默认访问WEB服务器的443端口,用于私密支付
45.返回码:200.301.302.304.403.404.500.502.503.504的含义(详细描述.此题8分)
| 状态返回码 | 含义 | 解释 |
|---|---|---|
| 200 | OK | 服务器成功返回网页,成功的http请求 |
| 301 | Moved Permanently | 永久重定向,所有请求的网页被永久跳转到被设定的新的位置 |
| 302 | Moved temporarily | 临时重定向,所有请求的网页被临时跳转到被设定的新的位置 |
| 304 | Not Modified | 触发了缓存,没有真正连接到WEB服务器 |
| 403 | Forbidden | 禁止访问,权限拒绝响应客户端的请求 |
| 404 | Not Found | 服务器找不到客户端请求指定的页面 |
| 500 | Internal Server Error | 内部服务器错误,一般为服务器的设置或者内部程序问题导致 |
| 502 | Bad Gateway | 坏的网关,一般为反向代理服务器下面的节点出问题导致;看看是不是哪个路由器出的问题 |
| 503 | Service Unavailable | 服务当前不可用,可能是因为服务器超载或者停机维护导致 |
| 504 | Gateway Timeout | 网关超时,一般是服务器过载导致没有在指定的时间内返回数据给前端服务器 |
46.URL由什么组成?所谓请求是什么东东?uri又是什么?
HTTP请求:是指从客户端到服务器端的请求消息。包括:主机名、端口、对资源的请求方法、统一资源标识符及使用的协议等;
URL:统一资源定位符,URL是Internet上用来描述信息资源的字符串,主要用在各种WWW客户程序和服务器程序上网页地址,一个用户的完整请求就是一个URL;
URI:统一资源标识符,表示页面的存储路径和资源的具体地址;
URL=域名+URI
47.http协议里GET和POST请求的区别?
GET请求:客户端请求指定的资源信息,服务端返回指定资源;对用户输入的信息不做任何处理,是一种快速的读请求,缺点是容易被黑客截获;
POST请求:将客户端的数据提交到服务器;是一种加密的对服务器的写请求,信息不会出现在URL上,不公开,很安全,一般用于注册表单。
48.什么是静态网页.什么是动态网页?
静态网页:在网站设计中,纯粹HTML格式的网页(可以包含图片,视频,JS(前端功能实现),CSS(样式)等)通常被称为“静态网页”;静态网页一般没有后台数据库支持,不含后端程序,不含可交互页面的网页,是独立存在在服务器上的静态网页文件;
动态网页:动态网页的URL后缀不是.htm,.html等静态网页的常见后缀扩展名形式,而是以.asp,.php,.js等形式作为后缀的,并且一般在动态网页网址中会有标志性的符号“?,&”,动态网页大多数情况下有数据库支持,包含后端程序,服务器解析这些程序或者读取后端数据库返回一个完整的网页内容,网页交互性较好。
49.伪静态网页的本质是什么?
伪静态网页的本质是PHP解析器根据.php文件中的动态php代码激活解析为SQL语句,去到数据库拿取生成临时动态网页到PHP内存里。先存到本地磁盘中,伪装为一个静态网页的形式.html,再返回给用户。好处是,下次用户再访问,直接把保存的.html静态网页文件返回给用户,加大了效率。(但是如果更新频繁的业务不适用与这种伪静态)
50.前端语言的种类.后端语言的种类
前端:html、CSS、JavaScript等
后端:PHP、JSP、ASP等…
51.报头是什么?主体是什么?
WEB服务的器HTTP响应报文结构:响应报文头部+响应报文主体;
报头:记录了访问用户和服务端的属性信息,用来说明WEB服务器响应WEB客户端URL的状况,包括协议及版本号,状态返回码等;
主体:用户请求的网页内容,文本或者二进制图片视频等…
52.什么是IP.PV.UV?(网站流量统计中)
IP(独立IP):即Unique Visitor
,独立IP数是指不同IP地址的计算机访问网站时被计算的总次数,一天内相同的IP地址的客户端访问网站页面只被计算一次;
PV(访问量):即Page View,页面浏览量或点击访问量,每次刷新WEB服务器的网站的页面就会被计算一个PV;
UV(独立访客):即Unique Visitor,访问您网站的一台电脑客户端为一个独立访客,就是浏览器的cookie。这种方式用作网站的流量数基本准确,但是无法排除一台电脑多个用户使用的情况。
53.Nginx服务三大功能?
1.WEB服务,相比于Apache支持更多的并发连接访问,而且占用资源更少,效率更高;
2.反向代理负载均衡;
3.前端业务数据缓存服务。
54.apache和nginx的网络模型是什么?
apache采用的是传统的select模型,同步阻塞I/O事件处理模型,处理大量并发连接的读写时比较低效;
nginx采用最新的epoll模型,异步非阻塞I/O事件处理模型,效率高。
55.同步阻塞I/O和异步非阻塞I/O的含义?(详细描述.此题8分)
阻塞:一个线程调用过程必须完成才返回;期间如果遇到I/O读写,线程就在那里等待I/O读写完成,I/O读写完成才返回;线程这个等待就叫做阻塞;
同步阻塞I/O:程序运行过程中触发了I/O读写,线程就卡在原地等着,线程等待整个I/O过程结束才返回,同步必然阻塞。
异步非阻塞I/O:程序运行过程中触发了I/O读写,线程会直接返回,去进行其他工作;等待下一个程序也触发了I/O读写,线程再回来处理;效率极高,没有浪费,异步非阻塞。
56.什么叫做连接保持.它的作用是什么?(详细描述.此题8分)
连接保持:保持的是TCP三次握手;在传输完成之后,服务器不是立即断开连接,而是会保持数据传输状态一段时间以等待新的数据,这个时间称为连接保持时间。好处是减少了TCP每次都要三次握手对于时间和资源的浪费,加大了效率。
57.如果用户是通过IP地址访问网站的.如何让它只能看指定的server网站?
在Nginx配置文件中,server监听端口后追加default_server。
...省略...server {listen 80 default_server; #在端口后加default_serverserver_name www.zhangsiming.com ;location / {root html;index index.html index.htm;}...省略...
58.nginx的location五种优先级过滤规则(中文和符号都要写.并解释含义)(详细描述.此题8分)
优先级从高到低:1.location = 字符串 :精确前缀匹配;
2.location ^~字符串 :前缀字符串优先匹配;
3.location ~(~*)正则 :正则匹配,*忽略大小写;
4.location 字符串 : 常规字符串前缀匹配;(/images/优先级高于/images)
5.location / : 默认匹配,默认最后进这个location。
59.nginx的403访问报错有可能是什么原因?
1.Nginx配置文件里没有配置默认首页参数,或者网站根目录下没有对应的index.html、index.htmindex.php等文件;Nginx在跳转首页没成功的情况下,会触发安全机制返回403权限拒绝,不会把整个根目录给你看;
2.网站的根目录或者内部程序文件没有nginx程序用户访问权限,nginx程序用户看不了里面的内容自然会返回403权限拒绝;(文件内容要有r权限,目录要有x权限)
3.配置文件里配置了allow ip;deny ip等权限限制,导致某个IP地址的客户没有权限访问返回403;
4.自行编写的return 403;
60.nginx的404访问报错有可能是什么原因?
服务器找不到客户端请求的指定页面,可能是客户端请求了服务器上不存在的资源导致
61.LNMP服务器运行原理?(详细描述.此题8分)
LNMP指的是Linux+Nginx+MySQL+PHP
- 静态请求:
1.静态请求URL到达负载均衡服务器,被负载均衡到Nginx;
2.Nginx处理静态请求(图片、视频、.html结尾的网页);Nginx的监听进程收到请求后,将请求传递给Nginxworker进程,Nginxworker中的Nginx processes线程去干活根据不同URI进入不同location去拿取需要的文件到Nginx内存中,之后返回给负载均衡服务器返回给用户。
- 动态请求:
1.动态请求的http数据包通过负载均衡到Nginx Web服务器,由于Nginx处理不了动态请求,准备发给后方的PHP;
2.Nginx基于fastcgi接口规则,通过Nginx上的fastcgi客户端fastcgi_pass将http数据包转换为fastcgi数据包发送给PHP上的fastcgi服务端PHP-fpm;fastcgi数据包大小比较大,格式非常严谨,因此PHP解析的速度非常快;
3.fastcgi数据包传输到PHP后,PHP先把.php文件中的代码读取到PHP内存中,对于静态部分不作处理,对于动态代码,PHP解析器php.ini解析开发写的PHP代码,激活PHP代码为SQL语句去找MySQL去拿取动态数据代码,取回来替换.php文件中原本的动态代码,之后从PHP内存中把处理后的.php文件内容返回给Nginx,进一步返回给用户。
62.fastcgi是什么?它的客户端和服务端名字叫啥?
fastcgi是一个可伸缩的,高速地在HTTP服务器和动态脚本语言间通信的接口;Nginx和PHP之间的传输是基于这种接口规则。
| 对比 | fastcgi数据包 | http数据包 |
|---|---|---|
| 是否严谨 | 格式严谨 | 格式松散 |
| 解析速度 | 快 | 慢 |
| 大小 | 大 | 小 |
| 应用环境 | 内网降低了带宽的影响,所以使用fastcgi数据包 | 外网受带宽影响,使用http数据包更合适 |
fastcgi Client为fastcgi_pass------在Nginx内;
fastcgi Server 为php-fpm -------在PHP内。
63.fastcgi服务端监听什么端口
PHP-fpm默认监听9000端口,为socket进程。
64.在nginx配置文件里.哪行代码体现了fastcgi客户端和服务端的数据传输过程?
location ~ \.(php|php5)?$ {root html/blog;fastcgi_pass 127.0.0.1:9000;#这行代码提现了fastcgi数据传输过程(IP:端口)fastcgi_index index.php;#这行代码指定了动态首页include fastcgi.conf;#这行代码include了Nginx自身带的优化fastcgi文件}#这个location实现的功能就是过滤出动态请求的URL并传递给PHP
65.什么叫做高可用?什么叫做单点故障?
高可用:集群中任意一个节点失效的情况下,该节点上的所有业务会自动转移到其他正常节点上,不影响整个集群的运行,即保持了企业业务的7*24小时运行;
单点故障:就是集群中一个节点服务器出现故障,导致整个集群不能正常工作。
66.lvs四层负载均衡和nginx七层反向代理的本质区别?(详细描述.此题8分)
LVS和Nginx负载均衡的本质区别:LVS是通过转发数据包实现的负载均衡;Nginx是通过反向代理实现的负载均衡。(Nginx新版本也支持转发数据包--with-stream模块)
| 对比 | LVS四层负载均衡 | Nginx七层负载均衡 |
|---|---|---|
| 工作在OSI模型的哪层 | 传输层 | 应用层 |
| 负载均衡本质 | 通过调度算法转发数据包 | Nginx反向代理发起新的请求 |
| 抗并发能力 | 大 | 小 |
| 效率 | 高 | 不如LVS高 |
| 实现的功能 | 少 | 多 |
| 能否改变数据包内的数据 | 不能 | 可以 |
| 能否实现分业务负载均衡 | 不能 | 可以根据location实现分业 |
67.手写一个简单的负载均衡配置文件(必须包含server模块和upsteam模块内容)(详细描述.此题8分)
(1)服务器池的名字www_pools
(2)RS节点两个.IP地址为:192.168.200.100.192.168.200.200
worker_processes 1;events {worker_connections 1024;}http {include mime.types;default_type application/octet-stream;sendfile on;keepalive_timeout 65;upstream www_pools {server 192.168.200.100 weight=1;server 192.168.200.200 weight=1;}server {listen 80 ;server_name www.yunjisuan.com;location / {proxy_pass http://www_pools;#在http段下注意不要少了http://proxy_set_header host $host;proxy_set_header host $host;#后方RS节点的日志格式也要相应调整}}}
68.新搭建的nginx反向代理.但后方节点RS的访问日志里没有用户的真实来源IP。
请问这是为什么?以及如何让后方Web访问日志记录用户的真实来源IP地址。
这是因为Nginx反向代理负载均衡给后方节点RS的请求,是Nginx反向代理服务器作为来源IP发起的新请求,所以后方节点RS的访问日志中只能查出Nginx反向代理服务器的IP。
解决:
#Nginx反向代理服务器配置文件worker_processes 1;events {worker_connections 1024;}http {include mime.types;default_type application/octet-stream;sendfile on;keepalive_timeout 65;upstream www_pools {server 192.168.200.100 weight=1;server 192.168.200.200 weight=1;}server {listen 80 ;server_name www.yunjisuan.com;location / {proxy_pass http://www_pools;proxy_set_header X-Forwarded-For $remote_addr;#通过Nginx内置变量remote_addr记录用户真正的来源IP并赋值给Nginx反向代理服务器发起的新请求头部中的X-Forward-For变量}}}#Web节点配置文件worker_processes 1;events {worker_connections 1024;}http {include mime.types;default_type application/octet-stream;sendfile on;keepalive_timeout 65;log_format main ‘$remote_addr-$remote_user[$time_local]“$request”’‘$status $body_bytes_sent “$http_referer”’‘“$http_user_agent”“$http_x_forward_for”’;#设置后方Web节点的日志格式,引用和这个日志格式,就可以显示真实的来源IP了access_log logs/access.log main;server {listen 80 ;server_name www.yunjisuan.com ;location / {root html;index index.html;}}}
69.新搭建的nginx反向代理.后边RS虚拟了两个网站.bbs和www。但是.我们发现无论用bbs还是www域名访问反向代理时.只能看到RS的第一个bbs网站请问这是为什么?以及要如何避免这种问题?
因为虽然Nginx反向代理服务器收到请求后,知道了用户请求的域名,但是Nginx反向代理服务器没有记录这个域名到发起的新请求中,而是直接用IP去找了后方RS节点服务器,所以后面RS节点收到新请求后,默认只给到第一个server。
解决:
#Nginx反向代理服务器配置文件worker_processes 1;events {worker_connections 1024;}http {include mime.types;default_type application/octet-stream;sendfile on;keepalive_timeout 65;upstream www_pools {server 192.168.200.100 weight=1;server 192.168.200.200 weight=1;}server {listen 80 ;server_name www.yunjisuan.com;location / {proxy_pass http://www_pools;proxy_set_header host $host;#代码的意思是,在Nginx反向代理服务器发起新请求时,把用户输入的$host域名赋给proxy_set_header新请求头部里的host部分,这样就告诉了后端RS节点用户请求的域名,就可以根据域名返回指定的server内容了}}}
70.什么叫做会话保持?Nginx反向代理服务器实现会话保持的四种方法?(详细描述.此题8分)
会话(session):如果用户需要登录,那么可以理解为经过三次握手以后,客户端与服务器端建立的就是会话;
连接(connection):如果用户不需要登录,那么可以理解为经过三次握手以后,客户端与服务器端建立的就是连接;
会话保持:是指在负载均衡器上的一种机制,可以识别客户端与服务器之间交互过程的关联性,在作负载均衡的同时并且保证一系列相关联的访问请求都会分配到一台后方节点上。
Nginx反向代理服务器实现会话保持的四种方法:
1.ip_hash
当新的请求到达时,Nginx反向代理服务器先将其IP通过hash算法算出一个值,在所有的客户端请求中,只要hash的值相同,就会被分配到同一台服务器,该方法可以有效解决会话保持;但是不足的是如果某个IP频繁访问,经过ip_hash算法都会去到一个后端服务器,就失去了负载均衡的意义;
2.consistent_hash一致性哈希调度算法
Nginx默认没有,需要从Tengine上打补丁,一般用于代理后端缓存服务memcached等场景,根据用户请求的URI或者指定字符串进行一致性哈希算法计算,然后调度到后端服务器上,可有效解决会话保持问题;
3.cookie共享方式
两种方式:
(1)独立用户第一次过来就记录了一个cookie,LVS或者Nginx反向代理就记住了,之后每次这个独立访客都给到一个后端服务器;
(2)将验证信息写入cookie,发给第二个接待用户的后端服务器。连接过来的时候,从cookie比对验证信息,实现会话保持;4.session共享方式
每次同一个用户过来比对验证的时候,不在和本地验证,把验证信息保存在数据库缓存(kafka、Redis)中(修改PHP配置文件,把session存放的位置放到远程数据库缓存服务器),当切换界面,负载均衡连接到不同的Web服务器的时候,所有的后端节点服务器从数据库缓存中找随机图片验证的答案,进行比对,实现会话保持。(企业用的多)
71.简单描述网站图片盗链的本质是什么?
盗链是指服务提供商自己不提供服务的内容,通过技术手段绕过其它有利益的广告或最终用户界面,直接在自己的网站上向最终用户提供其它服务提供商的服务内容,骗取最终用户的浏览和点击率。盗链者不提供资源或提供很少的资源,而真正的服务提供商却得不到任何的收益。
72.NginxWeb服务器图片访问基本流程原理?(详细描述.此题8分)
1.浏览器根据请求URL找到对应的.html文件,解析文件中文字内容;
2.之后,浏览器处理解析html文件中的图片动态代码,发起一个新的静态请求去找这个图片;
3.静态服务器本地有的就从存储(NFS、GlusterFS)中拿取返回,本地没有的图片去网络找图片文件;
4,将找回的图片替换动态代码区域,和文字一并返回给用户。
73.Keepalived三大功能?
1.管理LVS软件负载均衡;
2.实现对LVS后端RS节点健康检查功能;
3.作为系统网络服务的高可用功能。
74.Keepalived是基于什么协议实现的故障转移?此协议的作用是什么?(详细描述.此题8分)
Keepalived是基于VRRP协议(虚拟路由冗余协议)实现的故障切换转移;
VRRP协议的作用:VRRP是一种容错协议,此协议的出现就是为了解决静态路由的单点问题,它利用广播的方式实现高可用对之间的通信,并可以在主节点出现故障的时候自动把业务转移到备节点。
75.Keepalived故障切换转移原理完整描述?(详细描述.此题8分)
Keepalived故障切换转移原理完整描述:
1.Keepalived高可用服务之间的故障切换转移,是通过VRRP协议实现的;
2.在Keepalived服务正常工作时,首先根据优先级选举出Master节点,Master 节点拥有VIP。Master节点通过发送ARP报文(多播),将自己的虚拟MAC地址通知给与它连接的设备或者主机,从而承担报文转发任务;(用户的请求会来到Master节点上)
3.期间Master节点周期性发送多播,用以告诉备节点自己还活着;
4.如果备节点在一段时间内收不到Master节点发出的广播包,就判定Master节点死亡,将根据优先级竞争重新选举新的Master节点,继承VIP;
5.选举的新的Master节点代替原有Master节点发送广播给其他备节点,承担报文转发任务;
6.优先级高的Master节点恢复时,VIP又自动漂移回来,用户继续访问VIP去到原来的Master节点。
76.keepalived高可用对上是有脚本的。分别都是什么脚本?描述一下脚本的作用和设计思路?(详细描述.此题8分)
Keepalived检测漂移脚本(主上)
作用:实现Nginx服务不正常时候也正常漂移接管VIP的功能。
设计思路:
当检测不出Nginx服务的端口(80)的时候,关闭Keepalived服务,使VIP漂移。
检测高可用裂脑脚本(备上)
作用:实现检测裂脑的功能。
设计思路:
1.如果备服务器可以ping通主服务器心跳线网卡,同时nmap或者telnet检测对方nginx正常工作,但是备Keepalived服务器有vip就报警------防火墙挡住了心跳包;
2.如果备服务器ping不通主服务器心跳线网卡,就ping主Keepalived服务器另外一块网卡。如果ping另外一个块网卡成功了,同时nmap或者telnet检测对方nginx正常工作,但是备Keepalived服务器有vip就报警------心跳线断了。
77.为何keepalived高可用对之间要用专门的心跳线进行连接?
因为在同一局域网中,可能有多组keepalived高可用队。如果不用专门的心跳线,当有keepalived主机发生宕机时,备份服务器却还会收到同网段其他高可用主机发送的广播报,而不会启动接管程序,从而导致服务中止,所以必须要专门的心跳线进行连接,以避免出现上述情况。
心跳线好处:
1.防止中间其他设备故障引起裂脑;(交换机等)
2.防止与其他高可用对互相收广播包冲突。
78.tomcat的端口号是多少?
Tomcat服务端监听端口:8080
Tomcat监听SHUTDOWN命令进程端口:8005
Tomcat ajp连接端口:8009
79.tomcat四种基础的安全优化两种基础性能优化?
四种安全优化:
1.降权启动:普通用户启动Tomcat;
2.telnet管理端口保护:修改默认的8005为其他的端口;
3.ajp连接端口保护:屏蔽掉Tomcat的8009端口;
4.禁用管理端:删除webapps目录下不需要用到的目录,并清除webapps/ROOT初始安装下面的所有文件。规避可能的代码漏洞。
2种基础性能优化:
1.屏蔽DNS查询:进制DNS反向解析,enableLookups="false"
2.JVM调优:优化catalina.sh脚本
80.生产环境下某台tomcat服务器.在刚发布的时候一切都很正常.在运行一段时间后就出现CPU占用很高的问题.基本上是负载一天比一天高。诸如此类问题.请排查!
问题分析:
1.程序密集频繁调用CPU,联系开发排查情况;
2.程序代码出现死循环。
优化排查过程:
1.首先查找进程高的PID号(先找到是哪个PID号的进程导致的)
[root@ZhangSiming ~]# top -H -n1#-H:显示所有线程数、-n:显示几次的静态结果top - 20:04:35 up 4 min, 2 users, load average: 0.06, 0.08, 0.04Threads: 154 total, 1 running, 153 sleeping, 0 stopped, 0 zombie%Cpu(s): 0.0 us, 5.9 sy, 0.0 ni, 94.1 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 stKiB Mem : 997956 total, 574916 free, 208536 used, 214504 buff/cacheKiB Swap: 2097148 total, 2097148 free, 0 used. 622588 avail MemPID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND1504 root 20 0 2266976 80436 13348 S 6.7 8.1 0:00.09 java1541 root 20 0 161980 2176 1536 R 6.7 0.2 0:00.01 top1 root 20 0 125348 3824 2564 S 0.0 0.4 0:01.06 systemd2 root 20 0 0 0 0 S 0.0 0.0 0:00.00 kthreadd...省略...
2.之后查看占用CPU、MEM高的进程的线程调用情况
[root@ZhangSiming ~]# yum -y install strace &>/dev/null#yum安装strace[root@ZhangSiming ~]# strace -p 1504strace: Process 1504 attachedfutex(0x7f4db2fb59d0, FUTEX_WAIT, 1505, NULL^Cstrace: Process 1504 detached<detached ...>#这个1505就是线程号
3.最后利用jstack找出高占用线程调用的开发代码,交给开发处理
[root@ZhangSiming ~]# printf "%x\n" 15055e1#将线程号换为16进制[root@ZhangSiming ~]# jstack 1504 | grep 5e1 -A 30#用jstack追踪1504中过滤高占用线程的代码调用情况,返回给开发"main" #1 prio=5 os_prio=0 tid=0x00007f4dac009000 nid=0x5e1 runnable [0x00007f4db2fb3000]java.lang.Thread.State: RUNNABLEat java.net.PlainSocketImpl.socketAccept(Native Method)at java.net.AbstractPlainSocketImpl.accept(AbstractPlainSocketImpl.java:409)at java.net.ServerSocket.implAccept(ServerSocket.java:545) #这里显示的为java代码中的545行...省略...
81.tomcat的日志文件叫什么名字?
Linux下Tomcat的标准输出与标准错误都会输出到/usr/local/tomcat/logs/catalina.out;
/usr/local/tomcat/logs下除了catalina.out还有两种日志文件:catalina.{yyyy-MM-dd}.log和localhost.{yyyy-MM-dd}.log;
catalina.{yyyy-MM-dd}.log是tomcat自己运行的一些日志,这些日志还会输出到catalina.out,但是应用向console(控制台)输出的日志不会输出到catalina.{yyyy-MM-dd}.log;
localhost.{yyyy-MM-dd}.log主要是应用初始化(listener, filter, servlet)未处理的异常最后被tomcat捕获而输出的日志,而这些未处理异常最终会导致应用无法启动。
82.MHA故障切换转移原理(详细描述.此题8分)
1.从宕机崩溃的master保存二进制日志事件(binlog events);
2.识别含有最新更新的slave,如果MHA配置文件设置了优先备选的主,就识别这个主;
3.应用差异的中继日志(relay log)到其他的slave;
4.应用从master保存的二进制日志事件(binlog events);
5.提升一个slave为新的master;
6.使其他的slave连接新的master进行复制。
83.MySQL的从库的relay-log日志如果太大了怎么办?
[root@ZhangSiming ~]# mysql -uroot -S /usr/local/mysql/tmp/mysql3307.sock -e "show slave status\G" | grep Seconds_Behind_MasterSeconds_Behind_Master: 0#查看MySQL主从同步是否有延迟,0代表没有延迟[root@ZhangSiming ~]# mysql -uroot -S /usr/local/mysql/tmp/mysql3307.sock -e "stop slave;"#先停止MySQL主从复制[root@ZhangSiming ~]# mysql -uroot -S /usr/local/mysql/tmp/mysql3307.sock -e "reset slave;"#再用reset slave直接删除master.info和relay-log.info文件,并删除所有的relay log,然后重新生成一个新的relay log
然后在MySQL配置文件中修改参数"max_relay_log_size",可限制以后生成的relay_log文件大小。
84.MHA的MySQL高可用架构.如何解决MHA管理端的单点问题?
在企业中,除了主库和备库,其它每个从库上都装MHA管理端,这样就保证了MHA管理端的高可用性,当master出现故障时,他们都可以自动将合适的slave提升为新的master,然后将所有其他的slave重新指向新的master。
85.什么叫做DevOps
DevOps(Development和Operations的组合词)是一种重视“软件开发人员”和“IT运维技术人员”之间沟通合作的文化、运动或惯例。透过自动化“软件交付”和“架构变更”的流程,来使得构建、测试、发布软件能够更加地快捷、频繁和可靠。
86.什么叫做CI/CD流水线
CI/CD流水线指的是DevOps自动化的一个持续构建、持续部署和持续交付的流程。
- 持续集成(Continuous Integration):代码合并,构建,部署,测试都在一起,不断地执行这个过程,并对结果反馈;
- 持续部署(Continuous Deployment):部署到测试环境、预生产环境、生成环境;
- 持续交付(Continuous Delivery):将最终产品发布到生产环境、给用户使用。
87.请描述DevOps自动化CI/CD自动化测试的基本流程(jenkins+svn+ansible实现)(详细描述.此题8分)
1.开发提交代码变更到SVN服务器;
2.Jenkins拉取变更的代码,通过Jenkins集成构建,利用ansible(一般为Jenkins从节点)部署到测试环境服务器;
3.测试人员在测试服务器上进行测试并将测试结果反馈给开发。
88.生产环境服务器自动化代码上线需要ansible吗?
可以不需要,因为Jenkins自身的Pipeline流水线脚本配合相关插件就具有部署到集群的功能
但是,一般生产环境中,对于一个部署系统的要求绝对不仅仅是一个自动化的部署过程,实际生产中需要解耦构建和部署过程、管理复杂的部署环境、
支持多种部署策略等;所以,一般需要ansible独立作为部署工具。
89.jenkins+svn和jenkins+svn+ansible的使用环境差异在哪里?
对于上线代码到一台服务器
二者没有任何区别;Jenkins+svn方法需要安装部署插件即可实现部署的功能,Jenkins+svn+ansible方法可以在Jenkins上安装ansible可视化插件方便看部署过程;
对于上线代码到多台服务器集群
Jenkins+svn需要把集群节点全部配置为Jenkins从节点,之后启用Jenkins Pipeline项目,比较麻烦;Jenkins+svn+ansible可以直接把节点写入ansible配置文件,利用ssh远程部署,比较方便。
90.Zabbix-sever端的Pollers进程和Trappers进程的作用
Pollers进程:用于Zabbix Server的主动模式,Zabbix Server端主动收集数据用的进程,数量越多Zabbix Server压力越大;
Trappers进程:用于Zabbix Server的被动模式,Zabbix Server负责处理Agent端推送过来的数据的进程,Zabbix Server被动模式的时候,这个Trapper进程数量要多一点。
91.ZabbixServer默认监听端口?ZabbixAgent默认监听端口?
Zabbix Server默认监听10051端口;
Zabbix Agent默认监听10050端口。
92.Zabbix-agent主动模式和被动模式的区别?及在哪修改agent主动模式
Zabbix-agent主动模式:是Agent端主动把数据推送给Server端,Server端通过10051端口来接收数据;
Zabbix-agent被动模式:是Zabbixserver端主动找Agent端要数据,这种模式对Server端的压力非常大。
Zabbix-agent默认是被动模式,可以在/etc/zabbix/zabbix_agentd.conf修改配置开启Zabbix-agent的主动模式:
[root@ZhangSiming ~]# cat /etc/zabbix/zabbix_agentd.conf | grep ServerActiveServerActive=192.168.17.133:10051#ServerActive后接Zabbix Server的IP+端口#然后Web监控项选择Zabbix主动模式
93.Zabbix-server的监控模式有四种.哪四种?分别是做什么用的?(详细描述.此题8分)
Zabbix Server的四种监控模式:
1.agent代理程序接口模式:设置监控项item来监控监控操作系统,以及软件服务,需要添加各种监控项;
2.SNMP:监控网络设备,交换机路由器。一旦开启了,Zabbix Server端会启一个snmp的端口,等路由器交换机通过SNMP协议发数据包;
3.JMX:专用于监听根java有关的模式;Tomcat外部主动监听是不行的,只有内部送数据出来,从JMX接口;服务端开启JMX就是让java虚拟机(Tomcat)通过JMX主动把数据送出来;
4.IPMI:监控服务器的硬件(需要安装IPMtools的安装包,获取硬件设施,进行推送)。
94.企业中Zabbix-server的监控频率是如何设定的?
监控频率:每次监控数据之间间隔的时间
通过Zabbix Web界面监控项设置中的数据更新时间来设置,一般不低于60s,在工作中通常设为90s,在特殊时间内可设置不同的监控频率,空闲时间一般为300s。
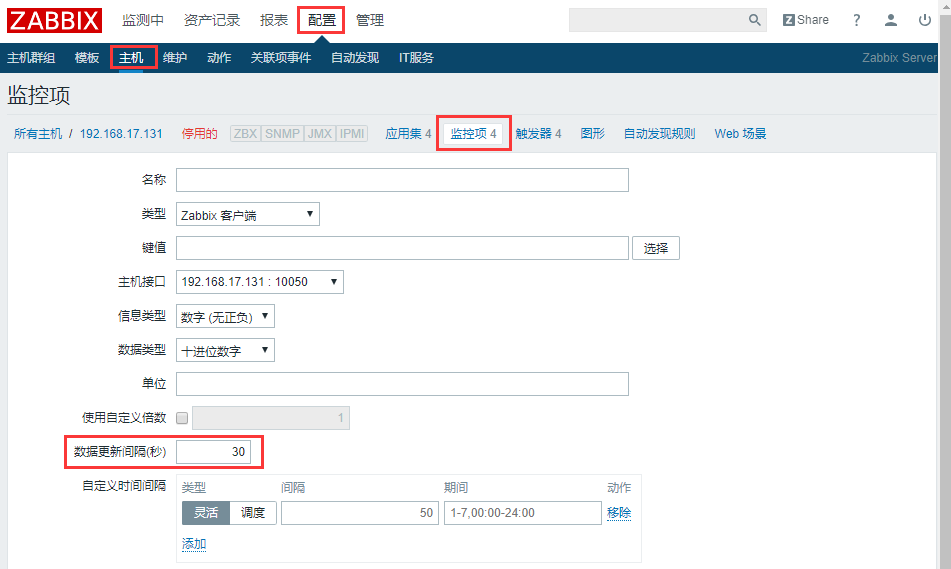
95.企业中Zabbix-server的报警频率是如何设定的?
告警频率:比如每次出现问题警报3次,每次间隔的时间就是告警频率
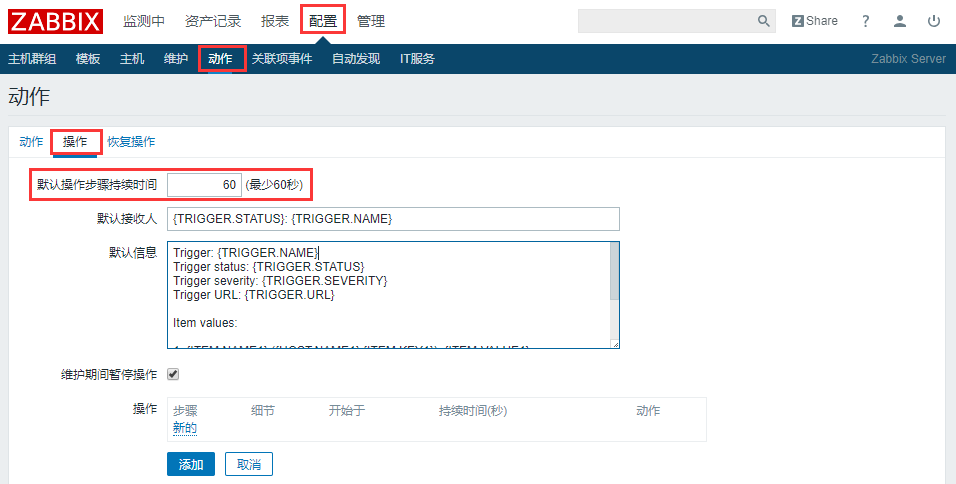
通过在Zabbix Web界面:配置-动作-创建动作-操作-默认持续步骤持续时间来设置。一般最少设为60s,即每分钟进行发送。同时在操作细节中设定发送次数,即每分钟发送次数,一般设为3次。
96.ZabbixServer如何开启java支持?
#Zabbix server必须有jdk环境[root@ZhangSiming ~]# java -versionjava version "1.8.0_171"Java(TM) SE Runtime Environment (build 1.8.0_171-b11)Java HotSpot(TM) 64-Bit Server VM (build 25.171-b11, mixed mode)#编译Zabbix server支持JMX[root@ZhangSiming ~]# cd /usr/src/zabbix-3.2.4/[root@ZhangSiming zabbix-3.2.4]# ./configure --prefix=/usr/local/zabbix --with-mysql --with-net-snmp --with-libcurl --enable-server --enable-agent --enable-proxy --enable-java --with-libxml2 && make && make install#开启JavaPollers进程,指定JAVAGateway端口[root@ZhangSiming zabbix]# pwd/usr/local/zabbix[root@ZhangSiming zabbix]# sed -n '215p;223p;231p' etc/zabbix_server.confJavaGateway=127.0.0.1JavaGatewayPort=10052StartJavaPollers=5[root@ZhangSiming zabbix]# /usr/local/zabbix/sbin/zabbix_java/startup.sh[root@ZhangSiming zabbix]# /etc/init.d/zabbix_server start
97.ZabbixServer的java gateway干啥的?监听端口多少?
JavaGateway用来采集TomcatJMX提供的客户端数据,本身是作为一个Tomcat数据采集器的功能而存在。
监听端口为:10052
98.ZabbixServer的Java Pollers进程的作用?
当Zabbix Server需要知道java应用程序的某项性能的时候,会启动自身的一个JavaPollers进程去连接JavaGateway请求数据,JavaGateway作为一个采集器去JMX接口采集Tomcat数据之后返回给,JavaPollers进程,最后回到Zabbix Server。
99.KVM和Docker的本质区别.至少说三点(虚拟化类型.资源占用.程序安全)(详细描述.此题8分)
| KVM | Docker |
|---|---|
| 硬件级,服务器级别的虚拟化,多用来在真实的服务器上做虚拟化 | 容器级,操作系统级别的虚拟化 |
| 一个独立的KVM相当于一个独立的操作系统,是系统级别的安全隔离,各个操作系统之间是非常安全的,硬件级别的虚拟化, 多用做服务器虚拟化 | Docker存在一个一直都不能解决的安全问题,因为Docker是进程级别的隔离,在操作系统里面,所以黑客只要入侵成功了一个Docker,就相当于跨过了防火墙层面,来到了操作系统中,就可以自由攻击其他Docker;大企业不用云也是怕这一点,因为黑客很容易通过云入侵,之后入侵到整个操作系统里 |
| 各个单独的操作系统是占用硬盘的,KVM对硬盘大小的占用比较高,因为每虚拟一个操作系统,都需要占用硬盘空间,对CPU,Mem,Disk占用都高 | Docker对硬件资源占用少,CPU,Mem,Disk占用都少;启动一个Docker只是启动一个进程;启动一个KVM是启动一个操作系统,区别巨大! |
100.写出至少20个docker命令?(详细描述.此题8分)
| Docker命令 | 作用 |
|---|---|
| search | search命令用于在官方公有镜像仓库查找镜像 |
| pull | pull命令用于从Docker Hub上下载公有镜像 |
| images | images用于本地镜像的信息查看 |
| build | build命令用于本地自定义镜像的构建,需要创建Dockerfile文件 |
| run | run命令用于运行一个本地镜像 |
| ps | ps命令用于查看已经运行的镜像的进程 |
| attach | attach命令用于从本地系统中切入到某个STATUS状态是UP的Docker里 |
| stop | stop命令用于停止一个正在运行着的Docker进程 |
| start | start命令用于启动一个已经停止了的Docker;第一次启动的时候是run(-d -it)命令 |
| rm | rm命令用于删除一个已经停止了的容器进程 |
| rmi | rmi命令用于删除一个未用作容器启动的本地镜像 |
| commit | commit命令是将一个更改过得容器进程的容器状态保存为一个新的镜像 |
| exec | exec命令用于在本地操作系统上直接向容器进程发布执行命令并返回结果 |
| cp | cp命令用于在容器进程和本地系统之间复制文件;cp命令可以实现shell-->容器;同时也可以实现容器-->shell |
| create | create命令用于创建一个容器进程,但是不启动它;区别于run命令,run直接创建容器进程之后,后台启动这个进程了 |
| diff | diff命令用于对容器进程与镜像源进行对比,找出发生了改变的文件或者文件夹 |
| events | events命令用于时时检测容器的变化情况;启动容器进程或者再容器内操作之类的全部都会被检测到,并前台输出给用户看 |
| export | export命令用于将容器进程的文件系统导出到本地;通俗点说,就是导出一个容器快照,这个快照可以通过import快速恢复容器快照时候容器的状态 |
| import | import命令用于将export导出的文件系统创建为一个镜像;通俗点说,就是恢复export导出的容器快照;注:从容器快照通过import导入可以重新制定tag名字等镜像信息 |
| history | 命令history用于查看一个镜像的历史修改记录 |
| info | info命令用于查看当前操作系统的docker运行信息 |
| inspect | inspect命令用于查看某个镜像的详细信息 |
| kill | kill命令用于强行停止一个或多个正在运行状态的容器进程 |
| save | save命令用于将一个镜像的文件导出到本地 export是从容器进程快照导出到本地; save是直接保存一个镜像到本地,注意区别 |
| load | load命令用于将save导出的镜像存储文件重新加载为镜像(和源镜像的名字标识完全一样) |
| logs | logs命令用于输出一个容器进程内的操作日志;记录容器中输出到终端的内容 |
| pause && unpause | pause和unpause命令用于一个或多个容器进程的暂停和恢复(容器启动进程) |
| port | port命令用于列出一个容器的端口映射及协议 |
| rename | rename命令用于给容器(启动)进程重命名 |
| restart | restart命令用于重启一个容器进程 |
| stats | stats命令用于实时输出容器的资源使用情况 |
| tag | tag命令用于从一个指定的镜像创建另外一个镜像 |
| top | top命令用于显示指定容器的进程信息 |
| update | update命令用于调整一个或多个容器的启动配置 |
| version && wait | version命令用于显示docker的版本信息;wait用于捕捉一个或多个容器的退出状态,并返回退出状态码 |
| login && logout && push | login用于登陆docker hub官方公有仓库;logout用于登出docker hub官方公有仓库;push用于将本地镜像提交到docker hub |
101.docker如何限制容器的内存和CPU?如何动态扩展CPU和内存?
限制内存:
[root@ZhangSiming ~]# docker run -dit -m 100m --memory-swap=100m centos9bd6196ba0942377c935e7628ea0e06279137f6ed8cda1b0d32cc33c99f7955b#-m限制内存大小、--memory-swap为设置内存+swap的使用限额;如果不设置,默认可以超出-m设置的内存大小2倍才杀掉进程
限制CPU:
[root@ZhangSiming ~]# docker run -dit -c 1024 --cpuset-cpus="0" centos7e2e43f8c8dd7240e65915e1afea995aeda29c35d6eff5a887a689ff3234ff58#-c:限制docker间占用CPU资源的比重,默认比重1024;-cpuset-cpus="CPU编号":使用哪个编号的CPU#查看Linux系统CPU编号的方法[root@ZhangSiming ~]# cat /proc/cpuinfo | grep processorprocessor : 0processor : 1#两个CPU,编号为0和1
动态扩展内存和CPU:
[root@ZhangSiming ~]# docker ps -aCONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES7e2e43f8c8dd centos "/bin/bash" 4 minutes ago Up 3 minutes suspicious_brattain[root@ZhangSiming ~]# docker update -m 100m --memory-swap=150m 7e2e43f8c8dd7e2e43f8c8dd[root@ZhangSiming ~]# docker update -c 512 --cpuset-cpus="0" 7e2e43f8c8dd7e2e43f8c8dd#使用docker update动态扩展内存和CPU
102.Git分布式版本控制系统和SVN中央版本控制系统的区别?
svn管理方便,逻辑明确,更符合一般人的思维习惯,并且易于管理,集中化服务器更能保持安全性,由于只有一个中央版本仓库,代码一致性非常高。但是中央服务器压力太大,数据库容量共用,开发必须联网到中央服务器,还有着单点问题;
Git适合分布式开发,强调个体;远程公共服务器的压力不会太大,支持离线工作,并且任意两个开发之间可以很容易的解决冲突,支持私人远程仓库GitLab;就是学习起来要比SVN更难一点。
103.工作区.暂存区.本地仓库.远程仓库代表的含义?(详细描述.此题8分)
工作区:使用者建立的本地git项目目录;
暂存区:将工作区里变更的部分(与上一版本不同的部分)暂时存储起来,准备提交到本地仓库的区域---git add;
本地仓库:在本地创建的git版本仓库,用于提交工作区的变更---git commit;
远程仓库:GitLab(私有)、GitHub(公有)或者用户在服务器上所建立的一个远程仓库---git push。
104.git fetch.git merge.git pull的区别?
git pull = git fetch + git merge
git pull:获取并整合另一个仓库或者分支;
git fetch:从另外一个软件仓库下载对象或引用到本地;
git merge:融合git fetch拉取的代码到本地软件仓库。
注:工作中一般不用git pull因为怕出现版本冲突。
105.git如何回滚代码到任意版本.请写出大概命令步骤?(详细描述.此题8分)提示:git reflog与git log --pretty=oneline
[root@Zhangsiming aaa]# git log --pretty=oneline#git log看历史版本a8c2aa5394fcc218e3c636de47663252e88acded 3253bb2ed1585fb8ea5b0947a61e7825f1cfec50e 2460ac29f2c34c389ef55d4341d705ca1d5142ddc 1[root@Zhangsiming aaa]# git tag v1.2#历史有三个版本,现在处于版本3,tagv1.2#利用哈希码回滚到版本1[root@Zhangsiming aaa]# git reset --hard 460ac29f2c34c389ef55d4341d705ca1d5142ddcHEAD is now at 460ac29 1[root@Zhangsiming aaa]# ls1[root@Zhangsiming aaa]# git log --pretty=oneline460ac29f2c34c389ef55d4341d705ca1d5142ddc 1#此时用git log无法查看未来版本,需要用git reflog#利用哈希码回滚到未来版本[root@Zhangsiming aaa]# git reflog460ac29 HEAD@{0}: reset: moving to 460ac29f2c34c389ef55d4341d705ca1d5142ddca8c2aa5 HEAD@{1}: commit: 3253bb2e HEAD@{2}: commit: 2460ac29 HEAD@{3}: commit (initial): 1[root@Zhangsiming aaa]# git reset --hard 253bb2eHEAD is now at 253bb2e 2[root@Zhangsiming aaa]# ls1 2#利用tag回滚到未来版本tagv1.2[root@Zhangsiming aaa]# git reflog253bb2e HEAD@{0}: reset: moving to 253bb2e460ac29 HEAD@{1}: reset: moving to 460ac29f2c34c389ef55d4341d705ca1d5142ddca8c2aa5 HEAD@{2}: commit: 3253bb2e HEAD@{3}: commit: 2460ac29 HEAD@{4}: commit (initial): 1[root@Zhangsiming aaa]# git reset --hard v1.2HEAD is now at a8c2aa5 3[root@Zhangsiming aaa]# ls1 2 3#利用HEAD指针回滚到上一版本[root@Zhangsiming aaa]# git log --pretty=onelinea8c2aa5394fcc218e3c636de47663252e88acded 3253bb2ed1585fb8ea5b0947a61e7825f1cfec50e 2460ac29f2c34c389ef55d4341d705ca1d5142ddc 1[root@Zhangsiming aaa]# git reset --hard HEAD^HEAD is now at 253bb2e 2[root@Zhangsiming aaa]# ls1 2[root@Zhangsiming aaa]# git reset --hard HEAD~1HEAD is now at 460ac29 1[root@Zhangsiming aaa]# ls1#HEAD^和HEAD~1都是指向上一版本的版本指针
106.Git分支合并的代码出现冲突如何解决?(详细描述.此题8分)
[root@ZhangSiming aaa]# cat filehello world[root@ZhangSiming aaa]# git branchdev* master#现在处于master分支,file文件里的内容是hello world[root@ZhangSiming aaa]# git checkout devSwitched to branch 'dev'[root@ZhangSiming aaa]# vim file[root@ZhangSiming aaa]# git add *[root@ZhangSiming aaa]# git commit -m "zhangsiming"[dev f1cbbfa] zhangsiming1 file changed, 1 insertion(+), 1 deletion(-)#切换分支到dev分支,修改file内容为hello zhangsiming并提交到本地仓库[root@ZhangSiming aaa]# git checkout masterSwitched to branch 'master'[root@ZhangSiming aaa]# vim file[root@ZhangSiming aaa]# git add *[root@ZhangSiming aaa]# git commit -m "lihaiying"[master 0b384b3] lihaiying1 file changed, 1 insertion(+), 1 deletion(-)#切换分支回master分支,修改file文件的内容为hello lihaiying并提交到本地仓库[root@ZhangSiming aaa]# git merge devAuto-merging fileCONFLICT (content): Merge conflict in fileAutomatic merge failed; fix conflicts and then commit the result.#合并dev分支到master分支,提示冲突,文件为file[root@ZhangSiming aaa]# cat file<<<<<<< HEADhello lihaiying=======hello zhangsiming>>>>>>> dev[root@ZhangSiming aaa]# vim file[root@ZhangSiming aaa]# cat filehello lihaiying#修改冲突文件内容[root@ZhangSiming aaa]# git add *[root@ZhangSiming aaa]# git commit -m "fixed"[master d43d7ff] fixed[root@ZhangSiming aaa]# git branch -d devDeleted branch dev (was f1cbbfa).[root@ZhangSiming aaa]# git branch* master#提交修改后的文件,删除dev分支,完成分支合并,解决了冲突
什么情况下会出现分支冲突?
比如现在在master分支,基于这个分支创建一个dev分支,然后可以进行任意修改,并且合并dev分支回到master分支,不会有问题;
如果用户在操作dev分支的时候,master分支别其他人修改了,合并的时候dev分支和master分支存在同文件同行内容不同,才会产生冲突。
107.Git将本地仓库用作远程仓库时的初始化命令?(只初始化本地仓库.不能提交代码)
[root@Zhangsiming aaa]# git init --bareInitialized empty Git repository in /root/aaa/[root@Zhangsiming aaa]# lsbranches config description HEAD hooks info objects refs#本地远程仓库的URL为:用户@IP:仓库绝对路径例如:git@192.168.17.132:/home/git/repos
108.GitLab私有仓库一共有几种权限设置.他们之间的差别在哪?(详细描述.此题8分)
项目组成员的五种权限:
| 权限名称 | 权限功能 |
|---|---|
| Guest访客 | 只能发表评论,不能读写项目库 |
| Reporter报告者 | 只能克隆代码,进行测试;不能上传提交代码,一般为产品测试人员 |
| Developer开发人员 | 可以进行代码的读写,但是不能进行分支的合并(只能提交分支合并申请给Master),一般为产品开发程序员 |
| Master主程序员 | 可以添加项目成员,可以添加标签,可以创建和保护分支,一般为产品经理 |
| Owner所有者 | 拥有所有权限,一般不用此权限,运维人员拥有此权限 |
109.svn数据迁移到GitLab是通过什么命令实现的?这个命令在什么版本的Git里有?(详细描述.此题8分)
#SVN服务器开启SVN服务[root@ZhangSiming ~]# svnserve -d -r /application/svndata/[root@ZhangSiming ~]# ps -elf | grep svn1 S root 1215 1 0 80 0 - 45179 inet_c 09:18 ? 00:00:00 svserve -d -r /application/svndata/0 R root 1217 1186 0 80 0 - 28176 - 09:18 pts/0 00:00:00 grep --color=auto svn#git服务器拉取[root@ZhangSiming git-2.9.5]# mkdir /svnqianyi[root@ZhangSiming git-2.9.5]# cd /svnqianyi[root@ZhangSiming svnqianyi]# which git-svn/usr/bin/git-svn[root@ZhangSiming svnqianyi]# git-svn clone --no-metadata svn://192.168.17.160/yunjisuan/master/ /svnqianyiInitialized empty Git repository in /svnqianyi/.git/A master.txtr1 = ed493f9a510ee02469f9261c9dd65bb989105ba0 (refs/remotes/git-svn)Checked out HEAD:svn://192.168.17.160/yunjisuan/master r1[root@ZhangSiming svnqianyi]# tree ..└── master.txt0 directories, 1 file
git-svn命令只有git 2.9.5版本以后才有。
110.GitLab的备份和恢复命令分别是什么?
#开启GitLab服务[root@ZhangSiming svnqianyi]# gitlab-ctl restart[root@ZhangSiming svnqianyi]# netstat -antup | grep gitlabtcp 0 0 127.0.0.1:9229 0.0.0.0:* LISTEN 15013/gitlab-workho#进行GitLab备份[root@ZhangSiming svnqianyi]# gitlab-rake gitlab:backup:createDumping database ...Dumping PostgreSQL database gitlabhq_production ... [DONE]doneDumping repositories ...* demo/demo ... [DONE][SKIPPED] WikidoneDumping uploads ...doneDumping builds ...doneDumping artifacts ...doneDumping pages ...doneDumping lfs objects ...doneDumping container registry images ...[DISABLED]Creating backup archive: 1550108504_2019_02_14_11.2.3_gitlab_backup.tar ... done#数据恢复的时候需要这个码Uploading backup archive to remote storage ... skippedDeleting tmp directories ... donedonedonedonedonedonedonedoneDeleting old backups ... skipping#进行GitLab数据恢复#停止相关的数据连接服务[root@ZhangSiming svnqianyi]# gitlab-ctl stop unicorn[root@ZhangSiming svnqianyi]# gitlab-ctl stop sidekiq[root@ZhangSiming svnqianyi]# gitlab-rake gitlab:backup:restore BACKUP=1550108504_2019_02_14_11.2.3#进行GitLab数据恢复#重启GitLab[root@ZhangSiming svnqianyi]# gitlab-ctl restart#可以检查一下恢复情况[root@ZhangSiming svnqianyi]# gitlab-rake gitlab:check SANITIZE=true
111.Jenkins的Pipeline流水线发布PHP项目基本构建流程?(详细描述.此题8分)
1.编写流水线脚本,流水线脚本分为三个阶段:拉取PHP项目代码阶段、部署阶段、完成反馈阶段,并且每个Pipeline节点下内容一致都包括上面三部分;
2.把流水线脚本和PHP项目代码提交到GitLab仓库;
3.启动Jenkins服务,访问Web界面;
4.添加Pipeline需要发布到的服务器为Jenkins从节点;
5.创建一个基于Pipeline发布PHP的流水线项目;
6.添加选择参数化构建(流水线脚本不支持git参数化构建);
7.配置流水线项目,添加连接远程git仓库的凭据配置,选择并配置"Pipeline script from SCM",从远程GitLab仓库拉取流水线脚本;
8.进行项目构建。
112.Jenkins的Pipeline流水线发布JAVA项目基本构建流程?(详细描述.此题8分)
1.编写流水线脚本,流水线脚本分为四个阶段:拉取JAVA项目代码阶段、maven构建阶段、部署阶段、完成反馈阶段,由于JAVA需要启动Tomcat,需要在部署阶段添加环境变量:JENKINS_NODE_COOKIE=dontkillme,并且每个Pipeline节点下内容一致都包括上面四部分;
2.把流水线脚本和JAVA项目代码提交到GitLab仓库;
3.启动Jenkins服务,访问Web界面;
4.添加Pipeline需要发布到的服务器为Jenkins从节点;
5.创建一个基于Pipeline发布JAVA的流水线项目;
6.添加选择参数化构建(流水线脚本不支持git参数化构建);
7.配置流水线项目,添加连接远程git仓库的凭据配置,选择并配置"Pipeline script from SCM",从远程GitLab仓库拉取流水线脚本;
8.进行项目构建。
113.分布式存储的最大的两个瓶颈在哪?
1.GlusterFS对小文件,尤其是海量小文件存储效率和访问性能表现差,小文件一律推到CDN;
2.网络带宽瓶颈。
114.Glusterfs的存储卷的动态(在线)扩容命令?
[root@GlusterFS1 zhangside]# gluster volume add-brick gs2 replica 2 GlusterFS1:/gluster/brick2 GlusterFS2:/gluster/brick2 force #进行复制卷的扩容,如果第一次指定的replica为2,扩容也必须是2的倍数volume add-brick: success[root@GlusterFS1 zhangside]# gluster volume rebalance gs2 start #扩容完了进行平衡数据,否则不会生效
115.Glusterfs的磁盘平衡功能的用处是什么?以及命令是什么?
[root@GlusterFS1 zhangside]# gluster volume rebalance gs2 start
如果扩容之后不进行磁盘平衡,写入的数据还是会写入到原来的磁盘中;需要先将本地的所有数据进行一次平衡,之后的写入才会平均地写入到每个磁盘中。
116.Glusterfs的默认连接端口范围
默认访问端口:24007~24011
Glusterfs各个节点之间连接的TCP端口:49152~49162
117.写出五条Glusterfs的优化参数中文版?
| 优化参数 | 说明 | 缺省值 |
|---|---|---|
| Auth.allow | IP访问授权 | allow all |
| Cluster.min-free-disk | 剩余磁盘空间阈值 | 10% |
| Cluster.stripe-block-size | 条带大小 | 128KB |
| Network.frame-timeout | 请求等待时间 | 1800s |
| Network.ping-timeout | 客户端等待时间 | 42s |
| Nfs.disabled | 关闭NFS服务 | OFF |
| Performance.io-thread-count | IO线程数 | 16 |
| Performance.cache-refresh-timeout | 缓存校验周期 | 1s |
| Performance.cache-size | 读缓存大小 | 32MB |
| Performance.quick-read | 优化读取小文件的性能 | off |
| Performance.read-ahead | 用预读的方式提高读取的性能,有利于应用频繁持续性的访问文件,当应用完成当前数据块读取的时候,下一个数据块就已经准备好了 | off |
| Performance.write-behind | 写入数据时,先写入缓存内,再写入硬盘内,以提高写入的性能 | off |
| Performance.io-cache | 缓存已经被读过的 | off |
118.Glusterfs服务器我们通常需要监控哪些选项?
监控使用Zabbix的自带模板;
监控项:CPU,内存,主机存活,磁盘空间,主机运行时间,系统负载LOAD等...
119.请说出.一台Glusterfs节点服务器爆炸以后.你是如何处理的(恢复数据的步骤)?
STEP1:首先配置一台与故障机完全一致的机器(IP,硬盘,等等...),查看故障节点的UUID
[root@GlusterFS2 ~]# gluster peer statusNumber of Peers: 3Hostname: GlusterFS3Uuid: 07f31c0f-3c17-4928-a1fe-b008593fe327State: Peer in Cluster (Disconnected) #记录下这个UUIDHostname: GlusterFS1Uuid: c4ef65ed-9dec-4e85-8577-ffb3eb35f471State: Peer in Cluster (Connected)Hostname: GlusterFS4Uuid: e3b38653-2ede-43d6-8e63-4260801b359cState: Peer in Cluster (Connected)#把新主机的环境设置为和GlusterFS3一致[root@GlusterFS5 glu]# hostname -I192.168.17.226 #IP一致[root@GlusterFS5 glu]# df -hT | tail -2df: `/zhangsiming': Stale file handle/dev/sdb ext4 20G 172M 19G 1% /gluster/brick1/dev/sdc ext4 20G 172M 19G 1% /gluster/brick2[root@GlusterFS5 glu]# which glusterfs/usr/sbin/glusterfs #安装glusterfs工具
STEP2:把UUID赋给新主机,执行修复命令
[root@GlusterFS5 glu]# vim /var/lib/glusterd/glusterd.info[root@GlusterFS5 glu]# cat /var/lib/glusterd/glusterd.infoUUID=07f31c0f-3c17-4928-a1fe-b008593fe327operating-version=30712#自动检测修复成功[root@GlusterFS2 ~]# gluster peer statusNumber of Peers: 3Hostname: GlusterFS3Uuid: 07f31c0f-3c17-4928-a1fe-b008593fe327State: Peer Rejected (Connected)Hostname: GlusterFS1Uuid: c4ef65ed-9dec-4e85-8577-ffb3eb35f471State: Peer in Cluster (Connected)Hostname: GlusterFS4Uuid: e3b38653-2ede-43d6-8e63-4260801b359cState: Peer in Cluster (Connected)#如果是Volume中的brick坏了,还要在新机器执行修复命令[root@GlusterFS2 ~]# gluster volume heal gs2 fullLaunching heal operation to perform full self heal on volume gs2 has been successfulUse heal info commands to check status#查看修复状态[root@glusterfs04 ~]# gluster volume heal gs2 infoBrick glusterfs03:/gluster/brick1Status: ConnectedNumber of entries: 0Brick glusterfs04:/gluster/brick1Status: ConnectedNumber of entries: 0#修复成功
120.lvs有几种模式?模式之间的本质区别在哪?(一句话解释)
LVS有四种工作模式:
- NAT(Network Address Translation)
- TUN(Tunneling)
- DR(Direct Routing)
- FULLNAT(Full Network Address Translation)
DR模式是直接路由模式;
TUN模式与DR模式的本质区别是LVS和后方可以跨网段;
NAT模式与其他模式的本质区别是访问来回都需要经过LVS,别的模式回的时候不需要经过LVS;
FULLNAT模式与其他模式的区别是访问来的时候,DNAT和SNAT一起做。
121.lvs负载均衡器上有几块网卡?它的后方Web节点.在什么模式下也需要双网卡?
两块网卡,DR模式。
122.LVS的direct routing模式的详细原理解
1.用户输入域名,经过DNS解析,DNS解析出来网关的公网IP,GIP;
2.同网段数据传输依靠MAC地址转换,因此网关要先进行ARP协议获取LVS的MAC地址;
3.在网关设置DNAT,修改目标IP地址,给到LVS服务器(已知VIP获取VMAC);
4.LVS将数据包转发到RS节点池,期间因为是同网段所以IP地址没有变,只是MAC地址的改变,LVS也需要获取后方RS的MAC地址才能修改目标MAC地址,把数据包发送过去(已知RIP获取RMAC);
5.为了防止后方的RS节点收到数据包发现目标地址不是RIP而是VIP丢包,后方RS节点就需要绑定VIP地址;并且需要抑制VIP这个地址的VRP响应;
6.处理完成后,返回给用户。网关DNAT管一去一回,改回源为GIP,目标是CIP给到用户。
123.redis的默认监听端口?
Redis默认监听6379端口;
Sentinel默认监听6800端口。
124.redis部署必做的四种初始调优?
- 调整系统文件描述符
[root@ZhangSiming redis]# vim /etc/security/limits.conf[root@ZhangSiming redis]# tail -1 /etc/security/limits.conf* - nofile 10240[root@ZhangSiming redis]# exitlogout#退出登录之后重新登录使更改生效[root@ZhangSiming ~]# ulimit -n10240#单个进程文件描述符备改为10240
- 调整系统TCP连接数
[root@ZhangSiming ~]# echo "net.core.somaxconn = 10240" >> /etc/sysctl.conf[root@ZhangSiming ~]# sysctl -pnet.core.somaxconn = 10240#调整TCP连接数为10240
- 调整系统内存分配策略
[root@ZhangSiming ~]# echo "vm.overcommit_memory = 1" >> /etc/sysctl.conf[root@ZhangSiming ~]# tail -1 /etc/sysctl.confvm.overcommit_memory = 1[root@ZhangSiming ~]# sysctl -pnet.core.somaxconn = 10240vm.overcommit_memory = 1#调整vm.overcommit_memory为1[root@ZhangSiming ~]# sysctl -a | grep commitsysctl: reading key "net.ipv6.conf.all.stable_secret"sysctl: reading key "net.ipv6.conf.default.stable_secret"sysctl: reading key "net.ipv6.conf.ens32.stable_secret"sysctl: reading key "net.ipv6.conf.lo.stable_secret"vm.nr_overcommit_hugepages = 0vm.overcommit_kbytes = 0vm.overcommit_memory = 1#调整生效vm.overcommit_ratio = 50
- 关闭系统内核的巨大内存页支持
[root@ZhangSiming ~]# echo 'echo never > /sys/kernel/mm/transparent_hugepage/enabled' >> /etc/rc.local[root@ZhangSiming ~]# echo 'echo never > /sys/kernel/mm/transparent_hugepage/defrag' >> /etc/rc.local[root@ZhangSiming ~]# echo never > /sys/kernel/mm/transparent_hugepage/enabled[root@ZhangSiming ~]# echo never > /sys/kernel/mm/transparent_hugepage/defrag[root@ZhangSiming ~]# tail -2 /etc/rc.localecho never > /sys/kernel/mm/transparent_hugepage/enabledecho never > /sys/kernel/mm/transparent_hugepage/defrag#根据日志中警告提示修改
125.redis的两种数据持久化模式是什么?两种模式间有何区别?(详细描述.此题8分)
rdb存储和aof存储;
rdb存储是通过在配置文件中设置save属性开启,每次触发设置的save格式自动触发存储;
aof存储,执行aof重写后会创建一个当前aof文件的体积优化版本。即使重写失败,也不会有任何的数据丢失,因为旧的aof文件在重写操作成功之前不会被修改。从Redis2.4版本开始,aof重写由Redis自行触发,bgrewriteaof命令仅仅用于手动触发重写操作。
126.平滑修改redis配置文件的方法(无需重启redis)?
[root@ZhangSiming ~]# redis-cli config set appendonly yesOK[root@ZhangSiming ~]# redis-cli config rewriteOK
127.redis中必须被屏蔽掉的危险命令都有什么?(至少写出3个)
[root@ZhangSiming ~]# sed -n "28p;58p;59p;60p" /usr/local/redis/conf/redis.confappendonly norename-command flushall ""rename-command flushdb ""rename-command keys ""#在配置文件最后设置重命名命令为空,就可以屏蔽了;但是注意对于flushall命令,必须设置appendonly no ,否则服务器无法启动[root@ZhangSiming ~]# redis-server /usr/local/redis/conf/redis.conf[root@ZhangSiming ~]# redis-cli flushdb(error) ERR unknown command `flushdb`, with args beginning with:[root@ZhangSiming ~]# redis-cli flushall(error) ERR unknown command `flushall`, with args beginning with:[root@ZhangSiming ~]# redis-cli keys(error) ERR unknown command `keys`, with args beginning with:[root@ZhangSiming ~]# redis-cli get key(nil)#成功屏蔽掉敏感命令
128.redis手动关闭主从复制的命令(只能在从上进行)
[root@ZhangSiming ~]# redis-cli slaveof no oneOK[root@ZhangSiming ~]# redis-cli config rewriteOK
129.我们平时是如何分析redis的Key和Key的大小的?我们为什么要分析?(详细描述,此题8分)
使用pip安装rdbtools工具分析key及key的大小
[root@ZhangSiming ruby-2.2.7]# which rdb/usr/bin/rdb[root@ZhangSiming ruby-2.2.7]# rdb -c memory /data/redis-cluster/7000/dump.rdb > /root/memory.csv#从内存中把.rdb文件键值的所有软链接导入到了/root/memory.csv方便分析WARNING: python-lzf package NOT detected. Parsing dump file will be very slow unless you install it. To install, run the following command:pip install python-lzf[root@ZhangSiming ruby-2.2.7]# cat /root/memory.csv | tr ',' ' ' | sort -k4n | head#tr是替换命令,把逗号替换为空格,之后sort-k4按照第四行排列,-rn是按照数字倒叙排列(大的在上边),之后head看前十行就得到了最大的前十的key的大小database type key size_in_bytes encoding num_elements len_largest_element expiry0 string key3_00002 72 string 11 110 string key3_00003 72 string 11 110 string key3_00006 72 string 11 110 string key3_00007 72 string 11 110 string key3_00010 72 string 11 110 string key3_00014 72 string 11 110 string key3_00018 72 string 11 110 string key3_00020 72 string 11 110 string key3_00021 72 string 11 11#可以找出异常的键值进行优化操作
由于Redis是单进程工作只能使用单核CPU,所以在Redis中不易单key过大,这个单key指的是string类型的。当单key过大时,每一次访问都会造成redis阻塞,其他请求只能等待了,如果应用中设置了1秒超时等,那么用户就会得到一个错误信息。最后删除的时候也会造成redis阻塞;
如果是集群模式下,无法做到负载均衡,导致请求倾斜到某个实例上,而这个实例的QPS会比较大,内存占用也较多;对于Redis单线程模型又容易出现CPU瓶颈,当内存出现瓶颈时,只能进行纵向库容,使用更高配的服务器;
涉及到大key的操作,尤其是使用hgetall、lrange 0 -1、get、hmget 等操作时,网卡可能会成为瓶颈,也会到导致堵塞其它操作,qps 就有可能出现突降或者突升的情况,趋势上看起来十分不平滑,严重时会导致应用程序连不上,实例或者集群在某些时间段内不可用的状态;
假如这个key需要进行删除操作,如果直接进行DEL 操作,被操作的实例会被Block住,导致无法响应应用的请求,而这个Block的时间会随着key的变大而变长。
130.你们公司生产环境的服务器是如何做操作系统安全和性能优化?
系统性能优化
1.精简化安装系统
精简安装策略:
1.仅安装需要的,按需安装,不用不装;
2.开发包、基本网络包、基本应用包。
2.关闭NetworkManager服务并关闭开机自启动
[root@ZhangSiming ~]# systemctl stop NetworkManager[root@ZhangSiming ~]# systemctl disable NetworkManager
3.进行配置DNS设置
1./etc/resolv.conf:临时修改DNS地址,重启网卡会被网卡里面的DNS配置覆盖;
2./etc/sysconfig/network-scripts/ifcfg-ens32网卡中配置DNS。
4.修改服务器自身主机名
[root@ZhangSiming tomcat]# cat /etc/hostnameZhangSiming#修改之后重启生效,仅限于CentOS7.5
5.服务器自身主机名映射
[root@ZhangSiming tomcat]# tail -1 /etc/hosts127.0.0.1 ZhangSiming#注意一定要有127.0.0.1的映射,因为有些服务需要验证自身的主机名有没有被映射
6.更新常用的yum源及必要软件包的安装
[root@ZhangSiming ~]# cat yum.sh#!/bin/bashping -c 1 www.baidu.com &>/dev/nullif [ $? != 0 ];thenecho "network problem"exit 1fiyum -y install https://dl.fedoraproject.org/pub/epel/epel-release-latest-7.noarch.rpm &>/dev/nullyum -y install http://repository.it4i.cz/mirrors/repoforge/redhat/el7/en/x86_64/rpmforge/RPMS/rpmforge-release-0.5.3-1.el7.rf.x86_64.rpm &>/dev/nullyum -y clean all &>/dev/nullyum makecache &>/dev/nullyum -y update &>/dev/nullecho "yum is ready!"[root@ZhangSiming ~]# sh yum.shyum is ready!#yum配置优化完成[root@ZhangSiming ~]# ls /etc/yum.repos.d/epel.repo local.repo mirrors-rpmforge-testingepel.repo.rpmnew mirrors-rpmforge rpmforge.repoepel-testing.repo mirrors-rpmforge-extras#注意,CentOS7和CentOS6的网yum源地址不同,自行查找下载配套的即可
7.修改时区与定时自动更新服务器时间
推荐时间服务器:ntp.sjtu.edu.cn ntp1.aliyun.com
[root@ZhangSiming ~]# yum -y install ntpdate[root@ZhangSiming ~]# cp /usr/share/zoneinfo/Asia/Shanghai /etc/localtime#修改时区[root@ZhangSiming ~]# ntpdate ntp.sjtu.edu.cn#校准时间23 Feb 14:58:12 ntpdate[1523]: step time server 202.108.6.95 offset -2.118379 sec[root@ZhangSiming ~]# echo '*/5* * * * /usr/sbin/ntpdate ntp.sjtu.edu.cn >> /var/log/ntp.log 2>&1; /sbin/hwclock -w' >> /var/spool/cron/root#加入定时任务,每5分钟执行一次;/sbin/hwclock -w 的意思是将时钟信息刷新到bios里[root@ZhangSiming ~]# crontab -l*/5* * * * /usr/sbin/ntpdate ntp.sjtu.edu.cn >> /var/log/ntp.log 2>&1; /sbin/hwclock -w
8.必须开启的5个服务(其他服务全关闭)
crond:定时任务、network:网络服务、rsyslog:日志服务、sshd:远程连接服务、sysstat:系统工具包
[root@ZhangSiming ~]# systemctl enable crond.service[root@ZhangSiming ~]# systemctl enable network.service[root@ZhangSiming ~]# systemctl enable sshd.service[root@ZhangSiming ~]# systemctl enable sysstat.service[root@ZhangSiming ~]# systemctl enable syslog.service
9.删除无关的用户和用户组
10.定时自动清理垃圾文件
1.普通大文件;
2.cron定时任务产生的邮件文件和小碎片文件。
11.线上服务器系统内核参数优化策略
[root@ZhangSiming ~]# sed -n '60,67p' /etc/security/limits.conf* soft core unlimited* hard core unlimited#开启并且不限制core文件大小,* soft fsize unlimited* hard fsize unlimited#不限制最大文件大小* soft nofile 65536* hard nofile 65536#单个进程的最大文件打开数为65536* soft nproc 65536* hard nproc 65536#最大进程数为65536[root@ZhangSiming ~]# exitlogout#退出登录即可生效
12.文件系统优化选择
- ext4:Linux原生态文件格式
- xfs:Centos7开始默认支持
建议:
读操作频繁,同时小文件众多的应用:首选ext4文件系统
写操作频繁的应用,首选xfs。
13.代码程序优化
交给开发来做。
服务器安全优化
1.selinux配置
[root@ZhangSiming tomcat]# sestatusSELinux status: disabled[root@ZhangSiming tomcat]# vim /etc/selinux/config[root@ZhangSiming tomcat]# sed -n '7p' /etc/selinux/configSELINUX=disabled#SELINUX再生产环境中不是很好用,一般需要关闭
2.iptables配置
[root@ZhangSiming ~]# systemctl start firewalld[root@ZhangSiming ~]# iptables -Fiptables -P INPUT ACCEPTiptables -Fiptables -A INPUT -p tcp -m tcp --dport 80 -j ACCEPTiptables -A INPUT -s 1.1.1.0/24 -p tcp -m tcp --dport 22 -j ACCEPTiptables -A INPUT -s 2.2.2.2/32 -p tcp -m tcp --dport 22 -j ACCEPTiptables -A INPUT -i eth1 -j ACCEPTiptables -A INPUT -i lo -j ACCEPTiptables -A INPUT -m state --state RELATED,ESTABLISHED -j ACCEPTiptables -A INPUT -p tcp -m tcp --tcp-flags FIN,SYN,RST,PSH,ACK,URG NONE -j DROPiptables -A INPUT -p tcp -m tcp --tcp-flags FIN,SYN FIN,SYN -j DROPiptables -A INPUT -p tcp -m tcp --tcp-flags SYN,RST SYN,RST -j DROPiptables -A INPUT -p tcp -m tcp --tcp-flags FIN,RST FIN,RST -j DROPiptables -A INPUT -p tcp -m tcp --tcp-flags FIN,ACK FIN -j DROPiptables -A INPUT -p tcp -m tcp --tcp-flags PSH,ACK PSH -j DROPiptables -A INPUT -p tcp -m tcp --tcp-flags ACK,URG URG -j DROPiptables -P INPUT DROPiptables -P OUTPUT ACCEPTiptables -P FORWARD DROP#上述为firewalld配置范例,根据不同公司有不同修改
3.线上服务器ssh登陆安全策略
[root@ZhangSiming ~]# cat -n /etc/ssh/sshd_config.bak | sed -n '17p;38p;43p;47p;65p;79p;115p'cat: /etc/ssh/sshd_config.bak: No such file or directory[root@ZhangSiming ~]# cat -n /etc/ssh/sshd_config | sed -n '17p;38p;43p;47p;65p;79p;115p'17 Port 22221#修改端口为22221,一个是不用默认端口安全,一个是1w以上的端口不会被nmap扫描出来38 PermitRootLogin no#禁止root用户登录(小规模服务方便管理可以开启)43 PubkeyAuthentication yes#允许使用ssh公钥连接47 AuthorizedKeysFile .ssh/authorized_keys#公钥放置位置65 PasswordAuthentication no#不允许密码认证连接方式79 GSSAPIAuthentication no#关闭GSSAPI认证,加快ssh速率115 UseDNS no#关闭DNS反向解析,加快ssh速率
把公钥放到需要连接的服务器,然后管理人员通过私钥即可xshell连接到对应服务器。
注意两点:
1.公钥权限600,不能太高,不安全。事实上太高也连不上;
2.如果想要登录普通用户,可以公钥发普通用户家目录对应位置;也可以root公钥连接上了之后su - 普通用户(sudo提前提好相应权限)
4.管理用户用户sudo权限策略
[root@ZhangSiming ~]# vim /etc/sudoers[root@ZhangSiming ~]# sed -n '93p' /etc/sudoersyunjisuan ALL=(ALL) NOPASSWD:ALL[root@ZhangSiming ~]# su - yunjisuanLast login: Sat Feb 23 13:58:57 CST 2019 on pts/0[yunjisuan@ZhangSiming ~]$ sudo -lMatching Defaults entries for yunjisuan on ZhangSiming:!visiblepw, always_set_home, match_group_by_gid, env_reset,env_keep="COLORS DISPLAY HOSTNAME HISTSIZE KDEDIR LS_COLORS",env_keep+="MAIL PS1 PS2 QTDIR USERNAME LANG LC_ADDRESS LC_CTYPE",env_keep+="LC_COLLATE LC_IDENTIFICATION LC_MEASUREMENT LC_MESSAGES",env_keep+="LC_MONETARY LC_NAME LC_NUMERIC LC_PAPER LC_TELEPHONE",env_keep+="LC_TIME LC_ALL LANGUAGE LINGUAS _XKB_CHARSET XAUTHORITY",secure_path=/sbin\:/bin\:/usr/sbin\:/usr/binUser yunjisuan may run the following commands on ZhangSiming:(ALL) NOPASSWD: ALL#由于不能给所有人root账号,所以把给普通运维的账号sudo提权为root账号的权限,方便管理
5.重要文件安全策略(/etc/sudoers、/etc/shadow、/etc/passwd、/etc/grub.conf)
#i锁就是设定文件不能被删除、改名、设定链接关系,同时不能写入或新增内容[root@ZhangSiming /]# chattr +i /etc/sudoers[root@ZhangSiming /]# chattr +i /etc/shadow[root@ZhangSiming /]# chattr +i /etc/passwd[root@ZhangSiming /]# chattr +i /etc/grub.conf#CentOS6是grub.conf,CentOS7已经改为grub2.cfg并且已经系统保护好了[root@ZhangSiming /]# chattr +i /etc/grub2.cfgchattr: Operation not supported while reading flags on /etc/grub2.cfg
6.系统磁盘及磁盘分区优化
磁盘分区,RAID设置,swap设置等......
131.生产环境服务器如何评估CPU的性能好坏?
- 查看cpu是否支持超线程
[root@ZhangSiming ~]# cat /proc/cpuinfo | grep "physical id" | uniq | wc -l1#cpu个数[root@ZhangSiming ~]# cat /proc/cpuinfo | grep "cores" | uniq | wc -l1#cpu物理核心总个数[root@ZhangSiming ~]# cat /proc/cpuinfo | grep "processor" | uniq | wc -l1#cpu逻辑核心个数#如果cpu总物理核心个数等于逻辑核心个数,那么cpu不支持超线程
- cpu性能评估工具------vmstat
[root@ZhangSiming ~]# vmstat 3 5#每3秒刷新一次,输出5次procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----r b swpd free buff cache si so bi bo in cs us sy id wa st3 0 0 343264 2784 536164 0 0 14 35 59 69 0 0 100 0 00 0 0 343264 2784 536164 0 0 0 0 81 84 0 0 100 0 00 0 0 343264 2784 536164 0 0 0 0 78 81 0 0 100 0 00 0 0 343264 2784 536164 0 0 0 0 84 90 0 0 100 0 00 0 0 343264 2784 536164 0 0 0 0 80 82 0 0 100 0 0
参数详解
| 字符 | 部位 | 解释 |
|---|---|---|
| r | procs | 表示运行和等待cpu时间片的进程数,这个值如果长期大于系统CPU个数,说明CPU不足,需要增加CPU |
| b | procs | 表示在等待资源的进程数,比如正在等待I/O,或者内存交换等。长期大于0,那么说明CPU不足 |
| swpd | memory | 表示切换到内存交换区的内存数量(以k为单位)。如果swpd的值不为0,或者比较大,只要si,so的值长期为0,这种情况下一般不用担心,不会影响系统性能 |
| free | memory | 表示当前空闲的物理内存数量(以k为单位) |
| buff | memory | 表示buffers cache的内存数量,一般对块设备的读写才需要缓冲 |
| cache | memory | 表示page cached的内存数量,一般作为文件系统cached,频繁访问的文件都会被cached,如果cache值较大,说明cached的文件数较多,如果此时IO中bi比较小,说明文件系统效率比较好 |
| si | swap | 表示由磁盘调入内存,也就是内存进入内存交换区的数量 |
| so | swap | 表示由内存调入磁盘,也就是内存交换区进入内存的数量。(一般情况下,si,so的值都为0,如果si,so的值长期不为0,则表示系统内存不足。需要增加系统内存) |
| bi | io | 表示从块设备读入数据的总量(即读磁盘)(每秒kb) |
| bo | io | 表示写入到块设备的数据重量(即写磁盘)(每秒kb) |
| in | system | 表示在某一时间间隔中观测到的每秒设备中断数 |
| cs | system | 表示每秒产生的上下文切换次数 |
| us | cpu | 显示了用户进程消耗的CPU时间百分比。us的值比较高时,说明用户进程消耗的cpu时间多,但是如果长期大于50%,就需要考虑优化程序或算法 |
| sy | cpu | 显示了内核进程消耗的CPU时间百分比。Sy的值比较高时,说明内核消耗的CPU资源很多 |
| id | cpu | 显示了CPU处在空闲状态的时间百分比 |
| wa | cpu | 显示了IO等待所占用的CPU时间百分比 |
- cpu性能评估工具------iostat(主要评估磁盘)
[root@ZhangSiming ~]# iostat -c 3 5#3秒刷新一次,显示5次的数据Linux 3.10.0-862.el7.x86_64 (ZhangSiming) 02/23/2019 _x86_64_ (1 CPU)avg-cpu: %user %nice %system %iowait %steal %idle0.14 0.00 0.21 0.02 0.00 99.63avg-cpu: %user %nice %system %iowait %steal %idle0.00 0.00 0.00 0.00 0.00 100.00avg-cpu: %user %nice %system %iowait %steal %idle0.00 0.00 0.00 0.00 0.00 100.00avg-cpu: %user %nice %system %iowait %steal %idle0.00 0.00 0.33 0.00 0.00 99.67avg-cpu: %user %nice %system %iowait %steal %idle0.00 0.00 0.00 0.00 0.00 100.00
参数详解
| 字符 | 解释 |
|---|---|
| %user | cpu处在用户模式下的时间百分比 |
| %nice | cpu处在nice值的用户下的时间百分比 |
| %system | cpu处在系统模式下的时间百分比 |
| %iowait | cpu处在io等待下的时间百分比(如果%iowait的值过高,表示硬盘存在I/O瓶颈) |
| %steal | 管理程序维护另一个虚拟处理器时,虚拟CPU的无意识等待时间百分比 |
| %idle | CPU空闲时间百分比 |
总标准:
| 影响因素 | 评判标准 | 评判标准 | 评判标准 |
|---|---|---|---|
| 好 | 坏 | 糟糕 | |
| cpu | user%+sys%<70 | user%+sys%=85 | user%+sys%>=90 |
132.生产环境服务器如何评估MEM的性能好坏?
- 评估内存------free -m
[root@ZhangSiming ~]# free -mtotal used free shared buff/cache availableMem: 974 112 335 7 526 648Swap: 2047 0 2047#剩余内存335M#buffers+cache526M#系统可用的剩余内存648M
一般情况我们可以这样去判断内存:
- 系统可用剩余内存总量/系统物理内存重量>70%时,表示系统内存资源非常充足,不影响系统性能;
- 系统可用剩余内存总量/系统物理内存重量<20%时,表示系统内存资源紧缺,需要增加系统内存;
- 20%<系统可用剩余内存总量/系统物理内存重量<70%时,表示系统内存资源基本能满足应用需求,暂时不影响系统性能
- 评估内存------sar
[root@ZhangSiming ~]# sar -r 3#-r显示内存信息,每3s刷新一次Linux 3.10.0-862.el7.x86_64 (ZhangSiming) 02/23/2019 _x86_64_ (1 CPU)07:00:40 PM kbmemfree kbmemused %memused kbbuffers kbcached kbcommit %commit kbactive kbinact kbdirty07:00:43 PM 343240 654716 65.61 2784 401072 286760 9.26 305456 148532 007:00:46 PM 343224 654732 65.61 2784 401072 286760 9.26 305460 148532 007:00:49 PM 343224 654732 65.61 2784 401072 286760 9.26 305460 148532 0
| 字符 | 解释 |
|---|---|
| kbmemfree | 表示空闲物理内存大小 |
| kbmemused | 表示已经使用的物理内存大小 |
| %memused | 表示已经使用内存占总内存百分比 |
| kbbuffers | 表示buffers占用的大小 |
| kbcached | 表示cache占用的大小 |
| kbcommit | 表示应用程序当前使用的内存大小 |
| %commit | 表示应用程序的使用百分比 |
总标准:
| 影响因素 | 评判标准 | 评判标准 | 评判标准 |
|---|---|---|---|
| 好 | 坏 | 糟糕 | |
| 内存 | si=0;so=0 | si、so有但是不多 | si、so非常多 |
133.生产环境服务器如何评估磁盘I/O的性能好坏?
3.4 磁盘I/O
首先可以根据磁盘硬件品牌型号种类进行一定的区分评估。
- 评估磁盘------iostat -d
[root@ZhangSiming ~]# iostat -d 2 3Linux 3.10.0-862.el7.x86_64 (ZhangSiming) 02/23/2019 _x86_64_ (1 CPU)Device: tps kB_read/s kB_wrtn/s kB_read kB_wrtnsda 0.71 10.86 28.97 186175 496650scd0 0.03 0.64 0.00 11000 0dm-0 0.69 10.25 28.84 175669 494451dm-1 0.01 0.13 0.00 2228 0Device: tps kB_read/s kB_wrtn/s kB_read kB_wrtnsda 0.00 0.00 0.00 0 0scd0 0.00 0.00 0.00 0 0dm-0 0.00 0.00 0.00 0 0dm-1 0.00 0.00 0.00 0 0Device: tps kB_read/s kB_wrtn/s kB_read kB_wrtnsda 0.00 0.00 0.00 0 0scd0 0.00 0.00 0.00 0 0dm-0 0.00 0.00 0.00 0 0dm-1 0.00 0.00 0.00 0 0
| 字符 | 解释 |
|---|---|
| Device | 设备名称 |
| tps | 表示每秒到物理磁盘的传送数,也就是每秒的I/O流量。一个传送就是一个I/O请求,多个逻辑请求可以被合并为一个物理I/O请求 |
| kB_read/s | 每秒读取的数据块 |
| kB_wrtn/s | 每秒写入的数据块 |
| kB_read | 读取的所有数据块总数 |
| kB_wrtn | 写入的所有数据块总数 |
总标准:
| 影响因素 | 评判标准 | 评判标准 | 评判标准 |
|---|---|---|---|
| 好 | 坏 | 糟糕 | |
| 磁盘 | iowait%<20 | iowait%=35 | iowait%=50 |
134.生产环境服务器如何评估网络环境的性能好坏?
• 网卡/交换机的选择:起码千兆网卡/千兆普通交换机/万兆核心交换机
• 操作系统双网卡绑定:通过绑定提高网卡带宽吞吐量
- 网络性能评估工具------ping
[root@ZhangSiming ~]# ping www.baidu.comPING www.a.shifen.com (61.135.169.125) 56(84) bytes of data.64 bytes from 61.135.169.125 (61.135.169.125): icmp_seq=1 ttl=128 time=23.5 ms64 bytes from 61.135.169.125 (61.135.169.125): icmp_seq=2 ttl=128 time=30.7 ms64 bytes from 61.135.169.125 (61.135.169.125): icmp_seq=3 ttl=128 time=86.3 ms64 bytes from 61.135.169.125 (61.135.169.125): icmp_seq=4 ttl=128 time=27.3 ms^C--- www.a.shifen.com ping statistics ---4 packets transmitted, 4 received, 0% packet loss, time 3006msrtt min/avg/max/mdev = 23.555/42.012/86.392/25.749 ms#time值表示两台主机间的延迟情况#packet loss表示网络丢包率,值越小,网络质量越高
- 网络性能评估工具------netstat
[root@ZhangSiming ~]# netstat -rn#查看路由状况Kernel IP routing tableDestination Gateway Genmask Flags MSS Window irtt Iface0.0.0.0 192.168.17.2 0.0.0.0 UG 0 0 0 ens32192.168.17.0 0.0.0.0 255.255.255.0 U 0 0 0 ens32[root@ZhangSiming ~]# netstat -i#查看网卡接口状况Kernel Interface tableIface MTU RX-OK RX-ERR RX-DRP RX-OVR TX-OK TX-ERR TX-DRP TX-OVR Flgens32 1500 63500 0 0 0 16182 0 0 0 BMRUlo 65536 0 0 0 0 0 0 0 0 LRU#route -n也可以看路由状况[root@ZhangSiming ~]# route -nKernel IP routing tableDestination Gateway Genmask Flags Metric Ref Use Iface0.0.0.0 192.168.17.2 0.0.0.0 UG 100 0 0 ens32192.168.17.0 0.0.0.0 255.255.255.0 U 100 0 0 ens32
- 跟踪网络路由状态工具------mtr(推荐)/traceroute
[root@ZhangSiming ~]# traceroute www.baidu.comtraceroute to www.baidu.com (61.135.169.125), 30 hops max, 60 byte packets1 gateway (192.168.17.2) 0.134 ms 0.146 ms 0.084 ms2 * * *3 * * *4 * * *5 * * *#traceroute虽然可以追踪网络路由,但是中间路由都被***屏蔽了,难以得到直观的显示[root@ZhangSiming ~]# mtr -n -c 2 --report www.baidu.com#-n:不用主机解析#-c:发送数据包数量#--report:结果显示Start: Sat Feb 23 19:21:09 2019HOST: ZhangSiming Loss% Snt Last Avg Best Wrst StDev1.|-- 192.168.17.2 0.0% 2 0.2 0.2 0.2 0.2 0.02.|-- 192.168.43.1 0.0% 2 3.1 7.7 3.1 12.3 6.53.|-- ??? 100.0 2 0.0 0.0 0.0 0.0 0.04.|-- ??? 100.0 2 0.0 0.0 0.0 0.0 0.05.|-- 114.247.23.161 0.0% 2 21.3 24.3 21.3 27.2 4.16.|-- 114.247.9.129 0.0% 2 19.0 25.1 19.0 31.2 8.67.|-- 61.51.169.205 0.0% 2 30.3 26.3 22.2 30.3 5.78.|-- 61.148.143.106 0.0% 2 22.9 22.6 22.4 22.9 0.09.|-- 123.125.248.110 0.0% 2 20.6 21.8 20.6 23.0 1.410.|-- ??? 100.0 2 0.0 0.0 0.0 0.0 0.011.|-- ??? 100.0 2 0.0 0.0 0.0 0.0 0.012.|-- 61.135.169.121 0.0% 2 20.5 21.1 20.5 21.7 0.0#mtr这个命令虽然也有看不出来的,但是基本上得到的信息比traceroute多的多
135.如果开发说Xshell连接不上内网服务器,请问诸如此类问题,你如何排查?
1.ping服务器IP地址看通不通;
2.如果ping不通就ifconfig检查网卡启动没启动,网卡没有启动就检查网卡配置文件;
3.如果网卡启动了,虚拟机还要查看虚拟网络配置,选择的网络模式,是否开启dhcp等;
4.上述没有问题再查看xshell编辑连接信息是否正确;
5.检查服务器selinux或者iptables是否关闭;
6.检查服务器是否开启了sshd服务,检查sshd服务22端口有没有开启,配合系统日志进行排查;
7.sshd没有问题就排查sshd配置文件进行登录权限等问题的排查;
8.实在连不上可以尝试重启服务器。
136.NginxWeb前端安全优化有哪些?(自己总结)
- 调整参数隐藏Nginx软件版本号信息;
- 更改源码隐藏或更改Nginx软件名;
- 更改Nginx服务的默认用户;
- 编写脚本实现Nginx access日志轮询;
- 不记录不需要的访问日志;
- 访问日志的权限设置;
- 根据扩展名限制程序和文件访问;
- 禁止访问指定目录下的所有文件和目录;
- 限制网站来源IP访问;
- 配置Nginx,禁止非法域名解析访问企业网站;
- Nginx图片及目录防盗链解决方案;
- Nginx错误页面的优雅显示;
- 单机LNMP环境目录权限严格控制措施;
- Nginx企业网站集群超级安全设置;
- Nginx防爬虫优化;
- 利用Nginx限制HTTP的请求方法;
- 使用普通用户启动Nginx(监牢模式)。
137.NginxWeb前端性能优化有哪些?(自己总结)
- 优化Nginx服务的worker进程个数;
- 优化绑定不同的Nginx进程到不同的CPU上;
- Nginx事件处理模型优化;
- 调整Nginx单个进程允许的客户端最大连接数;
- 配置Nginx worker进程最大打开文件数;
- 开启高效文件传输模式;
- 优化Nginx连接参数,调整连接超时时间;
- 上传文件大小的限制(动态应用);
- FastCGI相关参数调优(配合PHP引擎动态服务);
- 配置Nginx gzip压缩实现性能优化(重要);
- 配置Nginx expires缓存实现性能优化;
- 使用CDN做网站内容加速;
- Nginx程序架构优化(解耦优化);
- 限制单IP并发连接数;
- 限制虚拟主机总连接数;
- 控制客户端请求Nginx的速率。
138.如果用户反映,访问公司的网站慢,请问诸如此类问题,你如何排查?
1.首先自己访问自己的网站看是服务器的问题还是用户的问题,用户的问题可以建议带宽或者DNS;
2.如果是服务器的问题,可以利用浏览器的调试功能,调试网络看看各种数据加载的速度,进行问题排查;
3.然后针对服务器的负载情况,可以去查看下服务器硬件(网络带宽、CPU、内存、磁盘)的消耗状况。带宽方面查看流量监控看是不是已经到了峰值,带宽不够用了,看一下是不是硬件老化问题,重启服务器试试;
3.如果发现硬件资源消耗都不高,那就看看是不是网站的开发代码的问题了。这个可以通过查服务日志来找,特别地,mysql有个慢查询的日志功能,可以看到是不是慢SQL语句特别多;
4.最后看是不是数据库的表或者库过大了,数据库的瓶颈问题;
6.最后可以看看公司有没有启用CDN加速;
7.如果上述都不能很好地解决问题,就得加服务器优化甚至考虑更换架构了。
139.ELK基本工作原理(详细描述,此题8分)
1.Packetbeat(搜集网络流量数据)、Topbeat(搜集系统、进程和文件系统级别的 CPU 和内存使用情况等数据)、Filebeat(搜集文件数据)、Winlogbeat(搜集 Windows 事件日志数据)收集数据发送给Logstash;
2.Logstash过滤优化数据发送给Elasticsearch,如果前端有消息队列就发给消息队列(Kafka或者Redis);
3.Elasticsearch存储日志数据,Kibana拉取Elasticsearch的数据进行数据可视化,在Web UI上可以查看分析。
140.如何对Kibana进行访问权限控制?
1.修改Kibana配置文件中的server.host选项,设置为0.0.0.0表示不限制,可以针对性的设置只有本地127.0.0.1可以访问;
2.可以用Nginx进行访问权限限制,先allow或者deny相应ip之后,proxy_pass推送给Kibana平台。
