@zhangsiming65965
2019-03-18T02:43:02.000000Z
字数 21387
阅读 499
ELK日志分析平台(中)
消息队列与数据库缓存
---Author:张思明 ZhangSiming
---Mail:1151004164@cnu.edu.cn
---QQ:1030728296
如果有梦想,就放开的去追;
因为只有奋斗,才能改变命运;
一、Elasticsearch深入讲解
1.1对比MySQL数据库理解Elasticsearch数据库
| Elasticsearch | 含义 | MySQL |
|---|---|---|
| Index | 索引是多个文档的集合(必须是小写字母) | Database |
| Type | 一个Index可以定义一种或多种类型,将Document逻辑分组 | Table |
| Document | Index里每条记录称为Document,若干文档构建一个Index | Row |
| Field | 字段,Elasticsearch存储的最小单元 | Column |
- Node:运行单个Elasticsearch实例的服务器;
- Cluster:一个或多个节点构成集群;
- Shards:Elasticsearch将Index分成若干份,每一份就是一个分片;
- Replicas:Index的一份或多份副本。
1.2部署Elasticsearch-Cluster
| IP | 作用 |
|---|---|
| 192.168.17.139 | Elasticsearch-Node1(用部署好的) |
| 192.168.17.140 | Elasticsearch-Node2(新部署) |
| 192.168.17.141 | Elasticsearch-Node3(新部署) |
#部署两台Elasticsearch节点(与之前部署方式相同)#修改Elasticsearch-Node1的配置文件[root@ZhangSiming elasticsearch]# pwd/usr/local/elasticsearch[root@ZhangSiming elasticsearch]# vim config/elasticsearch.yml[root@ZhangSiming elasticsearch]# sed -n '17p;23p;33p;37p;56p;69p;73p' config/elasticsearch.ymlcluster.name: es-clusternode.name: node-1path.data: /usr/local/elasticsearch/datapath.logs: /usr/local/elasticsearch/logsnetwork.host: 192.168.17.139discovery.zen.ping.unicast.hosts: ["192.168.17.139", "192.168.17.140","192.168.17.141"]discovery.zen.minimum_master_nodes: 1#这个数值要和ELasticsearch-Node集群中的node.master:true总和一致,否则集群会组件失败#Elasticsearch集群配置[root@ZhangSiming elasticsearch]# scp config/elasticsearch.yml root@192.168.17.140:/usr/local/elasticsearch/config/elasticsearch.ymlroot@192.168.17.140's password:elasticsearch.yml 100% 2947 2.7MB/s 00:00[root@ZhangSiming elasticsearch]# scp config/elasticsearch.yml root@192.168.17.141:/usr/local/elasticsearch/config/elasticsearch.ymlroot@192.168.17.141's password:elasticsearch.yml 100% 2947 2.5MB/s 00:00#scp到另外两个节点之后更换配置文件里的network.host为自身和node.name为2,3即可#启动三台Elasticsearch[root@ZhangSiming elasticsearch]# su -s /bin/bash elk bin/start.sh[root@ZhangSiming elasticsearch]# curl -X GET "192.168.17.139:9200/_cat/health?v"epoch timestamp cluster status node.total node.data shards pri relo init unassign pending_tasks max_task_wait_time active_shards_percent1552197192 13:53:12 es-cluster green 3 3 0 0 0 0 0 0 - 100.0%#集群健康检查成功
- 如果出现下面的报错
[root@ZhangSiming elasticsearch]# cat logs/es-cluster.log#查看集群日志[2019-03-10T13:41:04,380][INFO ][o.e.d.z.ZenDiscovery ] [node-1] failed to send join request to master [{node-2}{L_zSuq3kS22qVUEqdiYKBQ}{nO795s-tTnmFL_N8fQnAGQ}{192.168.17.140}{192.168.17.140:9300}], reason [RemoteTransportException[[node-2][192.168.17.140:9300][internal:discovery/zen/join]]; nested: NotMasterException[Node [{node-2}{L_zSuq3kS22qVUEqdiYKBQ}{nO795s-tTnmFL_N8fQnAGQ}{192.168.17.140}{192.168.17.140:9300}] not master for join request]; ], tried [3] times
这是因为Node-2的数据目录data包括Node-1的部分,一定是偷懒没有重新配置一台Elasticsearch,直接scp的吧!解决办法是情况连接不上的Node的data数据目录重新启动即可。
1.3Elasticsearch数据库的操作
命令格式:
curl -X<verb> '<protocol>://<host>:<port>/<path>?<query_string>' -d '<body>'
| 参数 | 描述 |
|---|---|
| verb | HTTP方法,比如GET,POST,PUT,HEAD,DELETE |
| host | ES集群中的任意节点主机名 |
| port | ES HTTP服务端口,默认9200 |
| path | 索引路径 |
| query_string | 可选的查询请求参数。例如?pretty参数将格式化输出JSON数据 |
| -d | 里面放一个GET的JSON格式请求主体 |
| body | 自己写的JSON格式的请求主体 |
#列出数据库所有索引[root@ZhangSiming elasticsearch]# curl -X GET "192.168.17.139:9200/_cat/indices?v"health status index uuid pri rep docs.count docs.deleted store.size pri.store.size#创建一个索引[root@ZhangSiming elasticsearch]# curl -X PUT "192.168.17.139:9200/zhangsiming"{"acknowledged":true,"shards_acknowledged":true,"index":"zhangsiming"}#查看数据库索引索引[root@ZhangSiming elasticsearch]# curl -X GET "192.168.17.139:9200/_cat/indices?v"health status index uuid pri rep docs.count docs.deleted store.size pri.store.sizegreen open zhangsiming htsNjF_qRJ2bSIZrsRLqeA 5 1 0 0 2.2kb 1.1kb
Elasticsearch命令操作官方文档:
https://www.elastic.co/guide/en/elasticsearch/reference/current/_index_and_query_a_document.html
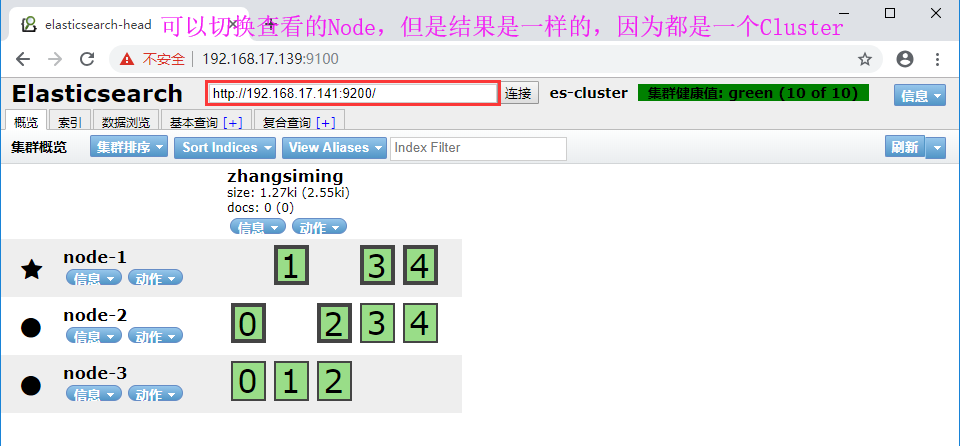
1.4Head插件图形管理Elasticsearch
#Head插件下载[root@ZhangSiming elasticsearch]# wget https://npm.taobao.org/mirrors/node/latest-v4.x/node-v4.4.7-linux-x64.tar.gz--2019-03-10 14:18:29-- https://npm.taobao.org/mirrors/node/latest-v4.x/node-v4.4.7-linux-x64.tar.gzResolving npm.taobao.org (npm.taobao.org)... 114.55.80.225Connecting to npm.taobao.org (npm.taobao.org)|114.55.80.225|:443... connected.HTTP request sent, awaiting response... 302 FoundLocation: http://cdn.npm.taobao.org/dist/node/latest-v4.x/node-v4.4.7-linux-x64.tar.gz [following]--2019-03-10 14:18:29-- http://cdn.npm.taobao.org/dist/node/latest-v4.x/node-v4.4.7-linux-x64.tar.gzResolving cdn.npm.taobao.org (cdn.npm.taobao.org)... 61.240.131.233, 61.240.131.230, 61.240.131.227, ...Connecting to cdn.npm.taobao.org (cdn.npm.taobao.org)|61.240.131.233|:80... connected.HTTP request sent, awaiting response... 200 OKLength: 12189839 (12M) [application/octet-stream]Saving to: ‘node-v4.4.7-linux-x64.tar.gz’100%[======================================>] 12,189,839 1.26MB/s in 13s2019-03-10 14:18:42 (926 KB/s) - ‘node-v4.4.7-linux-x64.tar.gz’ saved [12189839/12189839][root@ZhangSiming elasticsearch]# tar xf node-v4.4.7-linux-x64.tar.gz -C /usr/local/[root@ZhangSiming elasticsearch]# mv /usr/local/node-v4.4.7-linux-x64/ /usr/local/node-v4.4[root@ZhangSiming elasticsearch]# echo -e 'NODE_HOME=/usr/local/node-v4.4\nPATH=$NODE_HOME/bin:$PATH\nexport NODE_HOME PATH' >> /etc/profile[root@ZhangSiming elasticsearch]# tail -3 /etc/profileNODE_HOME=/usr/local/node-v4.4PATH=$NODE_HOME/bin:$PATHexport NODE_HOME PATH[root@ZhangSiming elasticsearch]# . /etc/profile[root@ZhangSiming elasticsearch]# yum install -y git &>/dev/null#拉取Head代码[root@ZhangSiming elasticsearch]# git clone git://github.com/mobz/elasticsearch-head.gitCloning into 'elasticsearch-head'...remote: Enumerating objects: 32, done.remote: Counting objects: 100% (32/32), done.remote: Compressing objects: 100% (26/26), done.remote: Total 4260 (delta 8), reused 21 (delta 6), pack-reused 4228Receiving objects: 100% (4260/4260), 2.21 MiB | 44.00 KiB/s, done.Resolving deltas: 100% (2337/2337), done.[root@ZhangSiming elasticsearch]# cd elasticsearch-head/[root@ZhangSiming elasticsearch-head]# npm install#安装插件[root@ZhangSiming elasticsearch-head]# lsDockerfile npm-debug.logDockerfile-alpine package.jsonelasticsearch-head.sublime-project plugin-descriptor.propertiesGruntfile.js proxygrunt_fileSets.js README.textileindex.html _siteLICENCE srcnode_modules test[root@ZhangSiming elasticsearch-head]# vim Gruntfile.js#修改源码包里的配置文件[root@ZhangSiming elasticsearch-head]# sed -n '90,97p' Gruntfile.jsconnect: {server: {options: {port: 9100,base: '.',keepalive: true,hostname: '*'}#授权插件连接Elasticsearch的APi,这是因为Elasticsearch5.0+版本以后,要想连接API必须先要进行授权才行。[root@ZhangSiming elasticsearch-head]# echo -e 'http.cors.enabled: true\nhttp.cors.allow-origin: "*"' >> /usr/local/elasticsearch/config/elasticsearch.yml[root@ZhangSiming elasticsearch-head]# ps -elf | grep elasticsearch0 S elk 2213 1 0 80 0 - 568185 futex_ 13:52 pts/2 00:00:19 /usr/local/jdk//bin/java -Xms100M -Xmx100M -XX:+UseConcMarkSweepGC -XX:CMSInitiatingOccupancyFraction=75 -XX:+UseCMSInitiatingOccupancyOnly -XX:+AlwaysPreTouch -Xss1m -Djava.awt.headless=true -Dfile.encoding=UTF-8 -Djna.nosys=true -XX:-OmitStackTraceInFastThrow -Dio.netty.noUnsafe=true -Dio.netty.noKeySetOptimization=true -Dio.netty.recycler.maxCapacityPerThread=0 -Dlog4j.shutdownHookEnabled=false -Dlog4j2.disable.jmx=true -Djava.io.tmpdir=/tmp/elasticsearch.wymbh4OP -XX:+HeapDumpOnOutOfMemoryError -XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:+PrintTenuringDistribution -XX:+PrintGCApplicationStoppedTime -Xloggc:logs/gc.log -XX:+UseGCLogFileRotation -XX:NumberOfGCLogFiles=32 -XX:GCLogFileSize=64m -Des.path.home=/usr/local/elasticsearch -Des.path.conf=/usr/local/elasticsearch/config -cp /usr/local/elasticsearch/lib/* org.elasticsearch.bootstrap.Elasticsearch -d0 S root 2377 1709 0 80 0 - 28176 pipe_w 14:26 pts/2 00:00:00 grep --color=auto elasticsearch[root@ZhangSiming elasticsearch-head]# kill -9 2213[root@ZhangSiming elasticsearch-head]# su -s /bin/bash elk /usr/local/elasticsearch/bin/start.sh#启动Head图形插件[root@ZhangSiming elasticsearch-head]# npm run start> elasticsearch-head@0.0.0 start /usr/local/elasticsearch/elasticsearch-head> grunt server>> Local Npm module "grunt-contrib-jasmine" not found. Is it installed?Running "connect:server" (connect) taskWaiting forever...Started connect web server on http://localhost:9100

二、Logstash深入讲解(二)
2.1Logstash条件判断符号
- 比较操作符
| 符号 | 含义 |
|---|---|
| == | 相等 |
| != | 不等 |
| > | 大于 |
| < | 小于 |
| <= | 小于等于 |
| >= | 大于等于 |
| =~ | 正则匹配 |
| !~ | 不匹配正则 |
| in | 包含 |
| not in | 不包含 |
- 布尔操作符
| 符号 | 含义 |
|---|---|
| and | 与 |
| or | 或 |
| nand | 与非 |
| xor | 或非 |
- 一元运算符
| 符号 | 含义 |
|---|---|
| ! | 取反 |
| () | 复合表达式 |
| !() | 对复合表达式取反 |
2.2Logstash-Input模块下的Stdin,File,Tcp,Beats插件
2.2.1stdin示例
从标准输入获取数据。
[root@ZhangSiming logstash]# cat config/logstash.confinput {stdin{}}filter {}output {stdout {codec => rubydebug}}
- 测试
[root@ZhangSiming logstash]# bin/logstash -f config/logstash.conf -tSending Logstash\'s logs to /usr/local/logstash/logs which is now configured via log4j2.properties[2019-03-10T15:57:06,540][INFO ][logstash.modules.scaffold] Initializing module {:module_name=>"fb_apache", :directory=>"/usr/local/logstash/modules/fb_apache/configuration"}[2019-03-10T15:57:06,607][INFO ][logstash.modules.scaffold] Initializing module {:module_name=>"netflow", :directory=>"/usr/local/logstash/modules/netflow/configuration"}[2019-03-10T15:57:08,036][WARN ][logstash.config.source.multilocal] Ignoring the 'pipelines.yml' file because modules or command line options are specifiedConfiguration OK#配置文件检测成功[2019-03-10T15:57:13,493][INFO ][logstash.runner ] Using config.test_and_exit mode. Config Validation Result: OK. Exiting Logstash#前台启动Logstash进行测试[root@ZhangSiming logstash]# bin/logstash -f config/logstash.conf192.168.17.1 - - [10/Mar/2019:12:39:13 +0800] \"GET / HTTP/1.1" 304 0 "-" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36"{"@version" => "1","@timestamp" => 2019-03-10T07:59:36.345Z,"message" => "[root@ZhangSiming logstash]# bin/logstash -f config/logstash.conf 192.168.17.1 - - [10/Mar/2019:12:39:13 +0800] \"GET / HTTP/1.1\" 304 0 \"-\" \"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36\"","host" => "ZhangSiming\"}#前台标准输入输入什么,filter不设置就是不过滤,测试输出就输出什么
2.2.2File示例
读取文件的内容作为传入数据。
[root@ZhangSiming logstash]# cat config/logstash.confinput {file {path => "/usr/local/nginx/logs/access.log"tags => "123"type => "syslog"#path是读取的文件路径,tags是标签,type是类型}}filter {}output {stdout {codec => rubydebug}}
- 测试
#进行一次的Nginx访问[root@ZhangSiming ~]# > /usr/local/nginx/logs/access.log[root@ZhangSiming ~]# curl -I localhostHTTP/1.1 200 OKServer: nginx/1.10.2Date: Sun, 10 Mar 2019 08:06:01 GMTContent-Type: text/htmlContent-Length: 612Last-Modified: Thu, 07 Mar 2019 11:02:45 GMTConnection: keep-aliveETag: "5c80fa55-264"Accept-Ranges: bytes[root@ZhangSiming ~]# cat /usr/local/nginx/logs/access.log127.0.0.1 - - [10/Mar/2019:16:06:01 +0800] "HEAD / HTTP/1.1" 200 0 "-" "curl/7.29.0"#Logstash过滤结果{\"host" => "ZhangSiming","@timestamp" => 2019-03-10T08:06:02.555Z,"message" => "127.0.0.1 - - [10/Mar/2019:16:06:01 +0800] \"HEAD / HTTP/1.1\" 200 0 \"-\" \"curl/7.29.0\"","tags" => [[0] "123"],"path" => "/usr/local/nginx/logs/access.log","type" => "syslog","@version" => "1"}
2.2.3TCP示例
通过监听TCP端口接收日志。
[root@ZhangSiming logstash]# cat config/logstash.confinput {tcp {port => 12345type => "nc"}}filter {}output {stdout {codec => rubydebug}}
- 测试
#安装网络调试工具netcat(nc)[root@ZhangSiming ~]# which nc/usr/bin/nc[root@ZhangSiming ~]# echo "zhangsiming" | nc 192.168.17.145 12345#nc开启一个终端ip为192.168.17.145的12345端口,传入字符"zhangsiming"#Logstash过滤结果{"type" => "nc","@timestamp" => 2019-03-10T08:12:47.172Z,"message" => "zhangsiming","@version" => "1","port" => 39808,"host" => "ZhangSiming"}
2.2.4Beats示例
此处稍后完善!
更多Input模块下的插件请看官网链接:
https://www.elastic.co/guide/en/logstash/current/plugins-inputs-file.html
2.3Logstash-Input(OutPut)-Codec插件
该插件主要实现输入输出的转码功能。
其中一个功能是,codec => json {xxxx}将json格式数据进行编码转换,更加易于观看。
注意,codec只是个转码插件,需要在输出插件里面引用,否则你都什么都没输入,转码谁?
[root@ZhangSiming logstash]# cat config/logstash.confinput {stdin {codec => json {charset => ["UTF-8"]#json格式转为UTF-8}}}filter {}output {stdout {codec => rubydebug}}
- 测试
#生成一段json数据[root@ZhangSiming ~]# pythonPython 2.7.5 (default, Apr 11 2018, 07:36:10)[GCC 4.8.5 20150623 (Red Hat 4.8.5-28)] on linux2Type "help", "copyright", "credits" or "license" for more information.>>> import json>>> data = [{'a':1,'b':2,'c':3,'d':4,'e':5}]>>> json = json.dumps(data)>>> print json[{"a": 1, "c": 3, "b": 2, "e": 5, "d": 4}]#Logstash过滤输出[{"a": 1, "c": 3, "b": 2, "e": 5, "d": 4}]{"@version" => "1","host" => "ZhangSiming","d" => 4,"@timestamp" => 2019-03-10T08:24:07.253Z,"c" => 3,"b" => 2,"e" => 5,"a" => 1}
2.4Logstash-Filter-json、kv插件
json插件:设置相应条件,将json结构化解析;
kv插件:将输入的数据按照指定字符进行切割。
#json插件示例[root@ZhangSiming logstash]# cat config/logstash.confinput {stdin {}}filter {json {source => "message"target => "content"#把message字段的json格式解析到content字段中}}output {stdout {codec => rubydebug}}#kv插件示例[root@ZhangSiming logstash]# cat config/logstash.confinput {stdin {}}filter {kv {field_split => "&?"}}output {stdout {codec => rubydebug}}
- json插件测试
#python生成json代码[root@ZhangSiming ~]# pythonPython 2.7.5 (default, Apr 11 2018, 07:36:10)[GCC 4.8.5 20150623 (Red Hat 4.8.5-28)] on linux2Type "help", "copyright", "credits" or "license" for more information.>>> import json>>> data = [{'a':1,'b':2,'c':3,'d':4,'e':5}]>>> json = json.dumps(data)>>> print json[{"a": 1, "c": 3, "b": 2, "e": 5, "d": 4}]#Logstash过滤输出[{"a": 1, "c": 3, "b": 2, "e": 5, "d": 4}]{"@version" => "1","@timestamp" => 2019-03-10T08:52:11.661Z,"host" => "ZhangSiming","message" => "[{\"a\": 1, \"c\": 3, \"b\": 2, \"e\": 5, \"d\": 4}]","content" => [[0] {"a" => 1,"c" => 3,"b" => 2,"e" => 5,"d" => 4}]}
- kv插件测试
name=zhangsiming class=169 skill=k8s{"@timestamp" => 2019-03-10T08:57:21.945Z,"@version" => "1","message" => "name=zhangsiming class=169 skill=k8s",#默认都会输出到message字段中"host" => "ZhangSiming","name" => "zhangsiming class=169 skill=k8s"}name=zhangsiming&class=169&skill=k8s{"class" => "169","skill" => "k8s","@timestamp" => 2019-03-10T08:57:36.279Z,"@version" => "1","name" => "zhangsiming","host" => "ZhangSiming","message" => "name=zhangsiming&class=169&skill=k8s"}
2.5Logstash-Filter-grok插件
2.5.1 grok自定义正则的数据抓取模式
前面用到过,这个插件比较强大,可以用来自定义正则抓取数据,形成新的字段。
#自定义字段正则抓取Nginx-access.log[root@ZhangSiming logstash]# cat /usr/local/nginx/logs/access.log127.0.0.1 - - [10/Mar/2019:16:06:01 +0800] "HEAD / HTTP/1.1" 200 0 "-" "curl/7.29.0"#编写filter[root@ZhangSiming logstash]# cat config/logstash.confinput {stdin {}}filter {grok {match => {"message" => '(?<ip>[0-9.]+) .*\[(?<time>[0-9a-zA-Z/:]+) .*HTTP/1.1" (?<mark>[0-9]+) (?<size>[0-9]+) .*'#把日志完整的用正则表示,需要自定义的字段用(?<字段名>正则匹配)表示占位出来即可#注意这里.*\[(?<time>[0-9a-zA-Z/:]+)的 "["前有个转义符号,这个是必须有的,否则会启动不起来Logstash,因为怕和后面的正则冲突了}}}output {stdout {codec => rubydebug}}
- 测试
127.0.0.1 - - [10/Mar/2019:16:06:01 +0800] "HEAD / HTTP/1.1" 200 0 "-" "curl/7.29.0"{"message" => "127.0.0.1 - - [10/Mar/2019:16:06:01 +0800] \"HEAD / HTTP/1.1\" 200 0 \"-\" \"curl/7.29.0\"","host" => "ZhangSiming","time" => "10/Mar/2019:16:06:01","@timestamp" => 2019-03-10T09:13:51.559Z,"@version" => "1","ip" => "127.0.0.1","size" => "0","mark" => "200"}
2.5.2 grok内置正则的数据抓取模式
为了方便用户抓取数据方便,官方自定义了一些内置正则的默认抓取方式。
Grok默认的内置正则模式,官方网页示例: https://github.com/logstash-plugins/logstash-patterns-core/blob/master/patterns/grok-patterns
[root@ZhangSiming logstash]# vim config/logstash.conf[root@ZhangSiming logstash]# cat config/logstash.confinput {stdin {}}filter {grok {match => {"message" => "%{IP:client} .*\"%{WORD:method} %{URIPATHPARAM:request} HTTP/1.1\" %{NUMBER:num} %{NUMBER:size}.*"#引用官方内置的正则模式的好处是,自定义字段的正则不需要我们写了,直接引用官方写好的就行了#同理,恰当的地方注意运用转义符号}}}output {stdout {codec => rubydebug}}
- 测试
#Logstash过滤输出127.0.0.1 - - [10/Mar/2019:17:23:53 +0800] "GET /index.html HTTP/1.1" 200 612 "-" "curl/7.29.0"{"client" => "127.0.0.1","message" => "127.0.0.1 - - [10/Mar/2019:17:23:53 +0800] \"GET /index.html HTTP/1.1\" 200 612 \"-\" \"curl/7.29.0\"","host" => "ZhangSiming","num" => "200","request" => "/index.html","size" => "612","method" => "GET","@timestamp" => 2019-03-10T09:45:16.108Z,"@version" => "1"}
2.5.3 grok自定义内置字段,引入文档的数据抓取模式
也可以将自定义正则的字段写入一个文件,在grok中patterns_dir引入这个文件。
[root@ZhangSiming logstash]# vim patterns[root@ZhangSiming logstash]# cat patternsSTRING .*#引用标签+正则[root@ZhangSiming logstash]# vim config/logstash.conf[root@ZhangSiming logstash]# cat config/logstash.confinput {stdin {}}filter {grok {patterns_dir => "/usr/local/logstash/patterns"match => {"message" => "%{IP:client} .*\"%{WORD:method} %{URIPATHPARAM:request} HTTP/1.1\" %{NUMBER:num} %{NUMBER:size}%{STRING:nouse}"}}}output {stdout {codec => rubydebug}}
- 测试
127.0.0.1 - - [10/Mar/2019:17:23:53 +0800] "GET /index.html HTTP/1.1" 200 612 "-" "curl/7.29.0"{"host" => "ZhangSiming","request" => "/index.html","@version" => "1","size" => "612","message" => "127.0.0.1 - - [10/Mar/2019:17:23:53 +0800] \"GET /index.html HTTP/1.1\" 200 612 \"-\" \"curl/7.29.0\"","@timestamp" => 2019-03-10T09:55:31.483Z,"client" => "127.0.0.1","nouse" => " \"-\" \"curl/7.29.0\"",#成功过滤出来了"num" => "200","method" => "GET"}
2.5.4 grok多模式匹配的数据抓取
有的时候,我们可能需要抓取多种日志格式的数据。因此,我们需要配置grok的多模式匹配的数据抓取。
[root@ZhangSiming logstash]# vim patterns[root@ZhangSiming logstash]# cat patternsSTRING .*NAME .*[root@ZhangSiming logstash]# vim config/logstash.conf[root@ZhangSiming logstash]# cat config/logstash.confinput {stdin {}}filter {grok {patterns_dir => "/usr/local/logstash/patterns"match => ["message",'%{IP:client} .*\"%{WORD:method} %{URIPATHPARAM:request} HTTP/1.1\"%{NUMBER:num} %{NUMBER:size}.*"%{STRING:nouse}"',"message",'%{IP:client} .*\"%{WORD:method} %{URIPATHPARAM:request} HTTP/1.1\" %{NUMBER:num} %{NUMBER:size}.*&%{NAME:name}&'#如果是上面这个格式,就走上面的message字段匹配,如果是下面这个格式,就走下面的message字段匹配#注意message后面不是=>,改为了","#注意上下两行之间第一行结尾要用","#注意match =>后面的{}改为了[]]}}output {stdout {codec => rubydebug}}
- 测试
#Logstash根据不同的日志内容,匹配不同的message,提取不同的字段127.0.0.1 - - [10/Mar/2019:17:23:53 +0800] "GET /index.html HTTP/1.1" 200 612"welcome to yunjisuan"{"num" => "200","client" => "127.0.0.1","message" => "127.0.0.1 - - [10/Mar/2019:17:23:53 +0800] \"GET /index.html HTTP/1.1\" 200 612\"welcome to yunjisuan\"","size" => "612","method" => "GET","nouse" => "welcome to yunjisuan","host" => "ZhangSiming","request" => "/index.html","@timestamp" => 2019-03-10T10:27:15.418Z,"@version" => "1"}127.0.0.1 - - [10/Mar/2019:17:23:53 +0800] "GET /index.html HTTP/1.1" 200 612&zhangsiming&{"num" => "200","client" => "127.0.0.1","message" => "127.0.0.1 - - [10/Mar/2019:17:23:53 +0800] \"GET /index.html HTTP/1.1\" 200 612&zhangsiming&","size" => "612","method" => "GET","name" => "zhangsiming","host" => "ZhangSiming","request" => "/index.html","@timestamp" => 2019-03-10T10:27:50.860Z,"@version" => "1"}
2.6Logstash-Filter-geoip插件
geoip插件可以对IP的来源进行分析,并通过Kibana的地图功能形象的显示出来。
#下载geoip插件包并移动到/usr/local/logstash[root@ZhangSiming ~]# wget http://geolite.maxmind.com/download/geoip/database/GeoLite2-City.tar.gz--2019-03-10 18:39:19-- http://geolite.maxmind.com/download/geoip/database/GeoLite2-City.tar.gzResolving geolite.maxmind.com (geolite.maxmind.com)... 104.17.201.89, 104.17.200.89, 2606:4700::6811:c959, ...Connecting to geolite.maxmind.com (geolite.maxmind.com)|104.17.201.89|:80... connected.HTTP request sent, awaiting response... 302 FoundLocation: http://120.52.51.14/geolite.maxmind.com/download/geoip/database/GeoLite2-City.tar.gz [following]--2019-03-10 18:39:20-- http://120.52.51.14/geolite.maxmind.com/download/geoip/database/GeoLite2-City.tar.gzConnecting to 120.52.51.14:80... connected.HTTP request sent, awaiting response... 200 OKLength: 28513410 (27M) [application/gzip]Saving to: ‘GeoLite2-City.tar.gz’100%[======================================>] 28,513,410 4.79MB/s in 5.6s2019-03-10 18:39:26 (4.81 MB/s) - ‘GeoLite2-City.tar.gz’ saved [28513410/28513410][root@ZhangSiming ~]# tar xf GeoLite2-City.tar.gz[root@ZhangSiming ~]# lsaaa GeoLite2-City_20190305 logstash-6.2.3.tar.gzanaconda-ks.cfg GeoLite2-City.tar.gz nginx-1.10.2.tar.gzcommon_install.sh jdk-8u60-linux-x64.tar.gz[root@ZhangSiming ~]# cp GeoLite2-City_20190305/GeoLite2-City.mmdb /usr/local/logstash/vendor/bundle/jruby/2.3.0/gems/logstash-filter-geoip-5.0.3-java/vendor/#这个是geoip数据库默认存放位置,也可以任意指定在Logstash目录中,但是注意配置文件中对应的database需要指定正确#修改Logstash配置文件[root@ZhangSiming logstash]# vim config/logstash.conf[root@ZhangSiming logstash]# cat config/logstash.confinput {stdin {}}filter {grok {patterns_dir => "/usr/local/logstash/patterns"match => ["message",'%{IP:client} .*\"%{WORD:method} %{URIPATHPARAM:request} HTTP/1.1\" %{NUMBER:num} %{NUMBER:size}.*"%{STRING:nouse}"',"message",'%{IP:client} .*\"%{WORD:method} %{URIPATHPARAM:request} HTTP/1.1\" %{NUMBER:num} %{NUMBER:size}.*&%{NAME:name}&']}geoip {source => "client"database => "/usr/local/logstash/vendor/bundle/jruby/2.3.0/gems/logstash-filter-geoip-5.0.3-java/vendor/GeoLite2-City.mmdb"#这里路径要对应上}}output {stdout {codec => rubydebug}}
- 测试
119.147.146.189 - - [10/Mar/2019:17:23:53 +0800] "GET /index.html HTTP/1.1" 200 612 &zhangsiming&{"message" => "119.147.146.189 - - [10/Mar/2019:17:23:53 +0800] \"GET /index.html HTTP/1.1\" 200 612 &zhangsiming&","method" => "GET","num" => "200","name" => "zhangsiming","client" => "119.147.146.189","request" => "/index.html","@timestamp" => 2019-03-10T11:27:05.871Z,"host" => "ZhangSiming","@version" => "1","size" => "612","geoip" => {"ip" => "119.147.146.189","latitude" => 23.1167,"country_name" => "China","continent_code" => "AS","timezone" => "Asia/Shanghai","country_code2" => "CN","region_name" => "Guangdong","country_code3" => "CN","region_code" => "GD","location" => {"lat" => 23.1167,"lon" => 113.25},"longitude" => 113.25}}#只有geoip数据库里面有的ip才会定位到
2.7Logstash-Outer-elasticsearch插件
将输出写入elasticsearch,方便kibana读取,还可以指定索引等...ELKStack平台都是Logstash过滤之后写入到Elasticsearch数据库中,在Kibana查看,这里就不多赘述了。
三、Kibana深入讲解
3.1Logstash配置文件修改
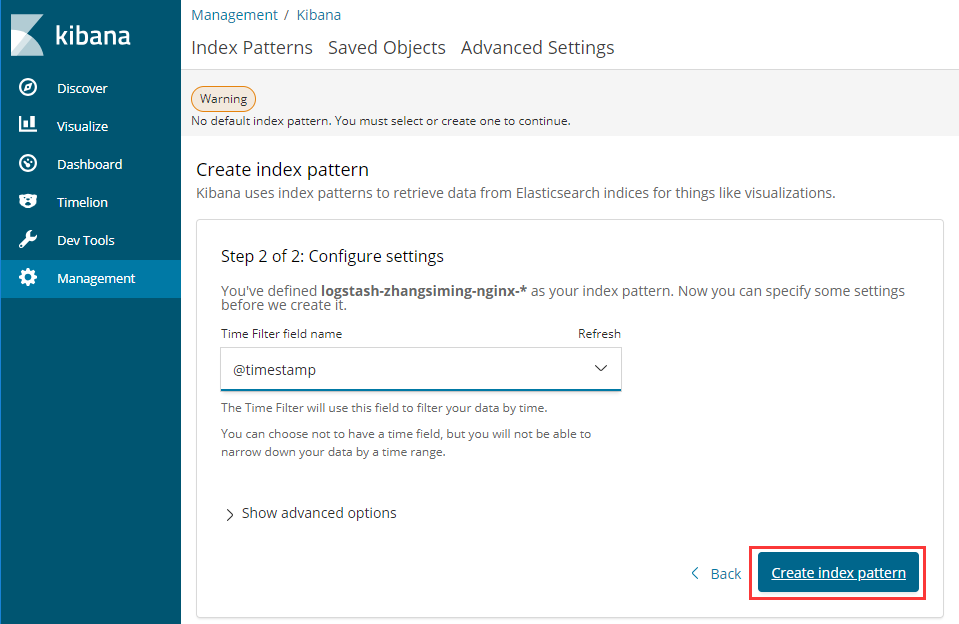
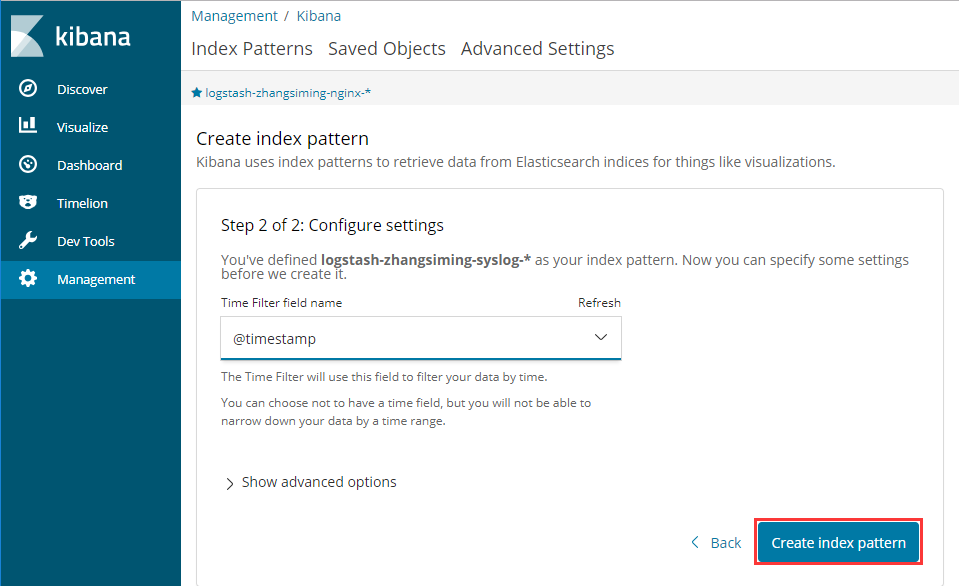
[root@ZhangSiming logstash]# vim config/logstash.conf[root@ZhangSiming logstash]# cat config/logstash.confinput {file {path => ["/usr/local/nginx/logs/access.log"]type => "system"tags => ["nginx","test"]start_position => "beginning"}file {path => ["/var/log/messages"]type => "system"tags => ["syslog","test"]start_position => "beginning"}#来源数据为两个地方,且都放到type:system中,分别tag,并从开始的部分同步}filter {}output {if [type] == "system" {if [tags][0] == "nginx" {elasticsearch {hosts => ["http://192.168.17.139:9200","http://192.168.17.140:9200","http://192.168.17.141:9200"]index => "logstash-zhangsiming-nginx-%{+YYYY.MM.dd}"}stdout { codec => rubydebug }}else if [tags][0] == "syslog" {elasticsearch {hosts => ["http://192.168.17.139:9200","http://192.168.17.140:9200","http://192.168.17.141:9200"]index => "logstash-zhangsiming-syslog-%{+YYYY.MM.dd}"}stdout { codec => rubydebug }}}}#使用if语句进行判断,不同数据写入不同的index
3.2Kibana配置文件
[root@ZhangSiming kibana]# sed -n '7p;21p' config/kibana.ymlserver.host: "127.0.0.1"elasticsearch.url: "http://192.168.17.139:9200"#Nginx对Kibana做访问限制,Elasticsearch只要连接其中一个节点即可访问这个cluster
如果elasticsearch里没有任何索引,那么kibana是都取不到的,这就是为什么我们一开始看数据的时候需要从KibanaWeb界面交互创建索引。如果已经存在,就不需要创建了。
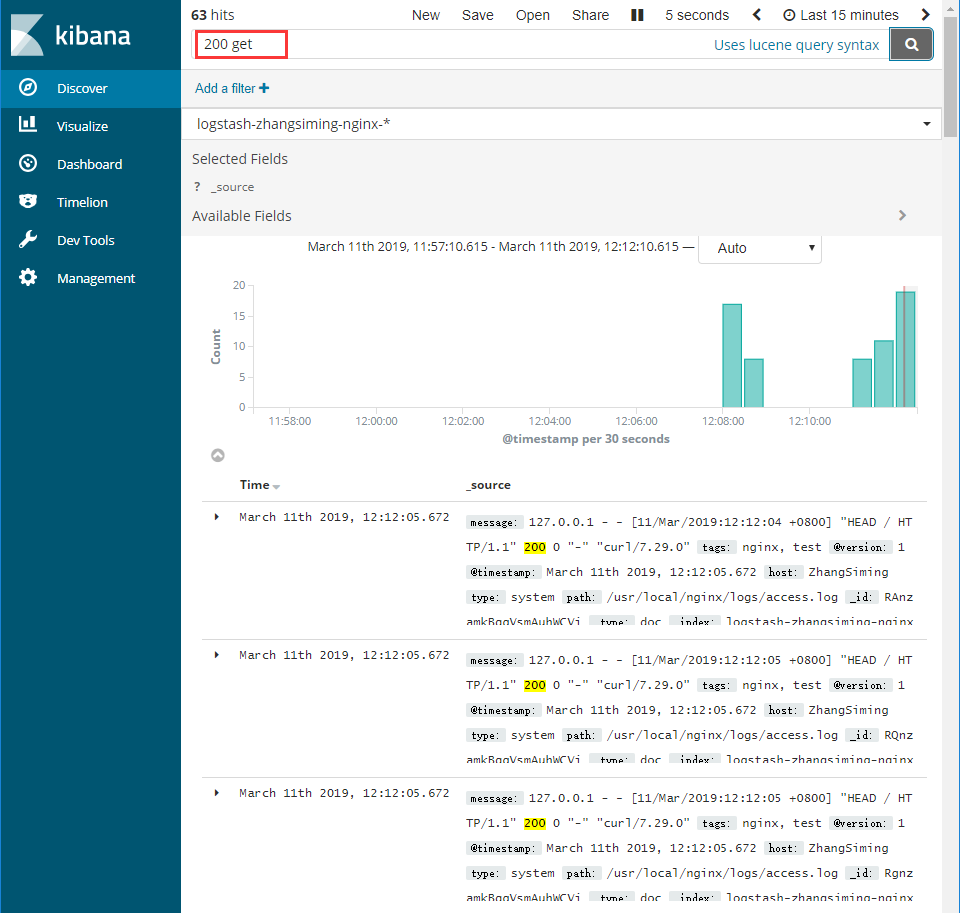
3.3访问KibanaWeb界面
先要开启Elasticsearch-Cluster,再启动Logstash(启动较慢,需要耐心等待),最后启动Kibana。