@Yano
2016-09-24T04:32:04.000000Z
字数 9503
阅读 11144
正则表达式 必知必会
正则

简介
推荐阅读:Jeffrey Friedl 《精通正则表达式(第3版)》,本文是该书的读书笔记。
本文「作业部落」地址:https://www.zybuluo.com/Yano/note/475174
PDF版本下载地址:http://pan.baidu.com/s/1eSC2kGM
定义
正则表达式:regular expression, regex,是用来描述或者匹配一系列符合某个句法规则的字符串的单个字符串。正则表达式这个概念最初是由Unix中的工具软件(例如sed和grep)普及开的。
分类
- BREs, 基本的正则表达式(Basic Regular Expression)
- EREs, 扩展的正则表达式(Extended Regular Expression)
- PREs, Perl 的正则表达式(Perl Regular Expression)
Linux常用文本工具
只有掌握了正则表达式,才能全面地掌握 Linux 下的常用文本工具(例如:grep、egrep、GUN sed、 Awk 等)的用法。
grep, egrep
1)grep 支持:BREs、EREs、PREs 正则表达式- grep 指令后不跟任何参数,则表示要使用 ”BREs“- grep 指令后跟 ”-E" 参数,则表示要使用 “EREs“- grep 指令后跟 “-P" 参数,则表示要使用 “PREs"2)egrep 支持:EREs、PREs 正则表达式- egrep 指令后不跟任何参数,则表示要使用 “EREs”- egrep 指令后跟 “-P" 参数,则表示要使用 “PREs"3)grep 与 egrep 正则匹配文件,处理文件方法a. grep 与 egrep 的处理对象:文本文件b. grep 与 egrep 的处理过程:查找文本文件中是否含要查找的 “关键字”(关键字可以是正则表达式) ,如果含有要查找的 ”关健字“,那么默认返回该文本文件中包含该”关健字“的该行的内容,并在标准输出中显示出来,除非使用了“>" 重定向符号,c. grep 与 egrep 在处理文本文件时,是按行处理的
sed
1)sed 文本工具支持:BREs、EREs- sed 指令默认是使用"BREs"- sed 命令参数 “-r ” ,则表示要使用“EREs"2)sed 功能与作用a. sed 处理的对象:文本文件b. sed 处理操作:对文本文件的内容进行 --- 查找、替换、删除、增加等操作c. sed 在处理文本文件的时候,也是按行处理的
Awk(gawk)
1)Awk 文本工具支持:EREs- awk 指令默认是使用 “EREs"2)Awk 文本工具处理文本的特点a. awk 处理的对象:文本文件b. awk 处理操作:主要是对列进行操作
匹配单个字符
Ben是一个正则表达式。正则表达式可以包含纯文本(甚至可以只包含纯文本)。
匹配纯文本
文本
Hello, my name is Ben. Please visit my website at http://www.forta.com/.
正则表达式
Ben
结果

匹配任意字符
.字符可以匹配任何一个单个的字符。
文本
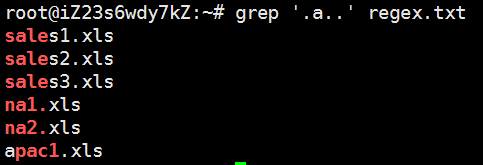
sales1.xlssales2.xlssales3.xlsna1.xlsna2.xlsorders3.xlsapac1.xlseurope2.xls
正则表达式
sales.
结果

匹配一组字符
匹配多个字符中的某一个
sales1.xlssales2.xlssales3.xlsna1.xlsna2.xlssa1.xlsca1.xlsorders3.xlsapac1.xlseurope2.xls
正则表达式
[ns]a.\.xls
结果

使用字符区间
在使用正则表达式的时候,会频繁地用到一些字符区间(0-9、A-Z)。为了简化字符区间的定义,正则表达式提供一个特殊的元字符:-作为连字符。
正则表达式
[ns]a[0-9]\.xls
结果

匹配任何一个字母(无论大小写)或数字
[A-Za-z0-9]
取非匹配
字符集合通常用来指定一组必须匹配其中之一的字符。但是在某些场合下,我们需要反过来做,给出一组不需要得到的字符。换句话说:除了那个字符集合里的字符,其他字符都可以匹配,使用字符^。
正则表达式
[ns]a[^0-9]\.xls
结果:上述输入没有结果,因为没有匹配字符串。
小结
元字符[和]用来定义一个字符集合,必须匹配该集合里的字符之一。定义一个字符集合的具体方法有两种:
1. 把所有的字符都列举出来
2. 利用元字符-以字符区间的方式给出
字符集合可以用元字符^来求非,这将把给定的字符集合强行排除在匹配操作外——除了该字符集合里的字符,其他字符都可以被匹配。
使用元字符
对特殊字符进行转义
元字符是一些在正则表达式里有特殊含义的字符。英文句号.是一个元字符,用来匹配任何一个单个字符;左方括号[也是一个元字符,表示一个字符集合的开始。
因为元字符在正则表达式中有特殊的含义,所以这些字符无法代表它们本身。需要在元字符的前面加上一个反斜杠进行转义——转义序列\.将匹配.本身。
文本
\home\ben\sales\
正则表达式
\\
结果

匹配空白字符
在进行正则表达式搜索的时候,我们经常会遇到需要对原始文本里的非打印空白字符进行匹配的情况。比如找出所有的制表符或换行符,这类字符很难被直接输入到正则表达式里,可以用如下的特殊元字符来输入。
| 元字符 | 说明 |
|---|---|
| [\b] | 回退(并删除)一个字符(Backspace键) |
| \f | 换页符 |
| \n | 换行符 |
| \r | 回车符 |
| \t | 制表符 |
| \v | 垂直制表符 |
文本
"101","Ben","Forta""102","Jim","James"
正则表达式
\r\n\r\n
结果
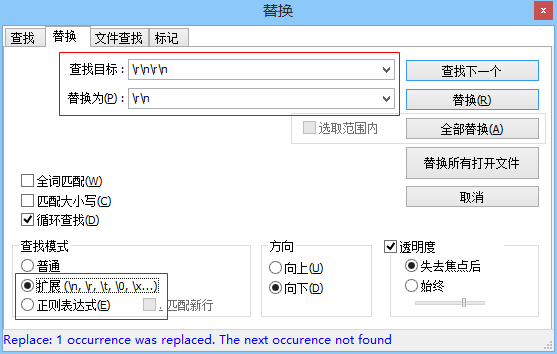
"101","Ben","Forta""102","Jim","James"
分析
\r\n匹配一个“回车+换行”组合,Windows操作系统都把这个组合作为文本行的结束标签。使用正则表达式\r\n\r\n进行的搜索将匹配两个连续的行尾标签,正是两条记录之间的空白行。
匹配文本结束标签
- Windows:\r\n
- Linux : \n
同时适用于Windows和Linux系统的正则表达式,应该包含一个可选的\r和一个必须被匹配的\n。
匹配特定的字符类别
字符集合(匹配多个字符中的某一个)是最常见的匹配形式,而一些常用的字符集合可以用特殊元字符来替代。
匹配数字(非数字)
| 元字符 | 说明 |
|---|---|
| \d | 任何一个数字字符(等价于[0-9]) |
| \D | 任何一个非数字字符(等价于[^0-9]) |
匹配字母和数字(非字母和数字)
| 元字符 | 说明 |
|---|---|
| \w | 任何一个字母数字字符或下划线字符([a-zA-Z0-9_]) |
| \W | 任何一个非字母数字字符或下划线字符([^a-zA-Z0-9_]) |
文本
11213A1C2E348075M1B4F2
正则表达式
\w\d\w\d\w\d
结果

匹配空白字符(非空白字符)
另一种常见的字符类别是空白字符。
| 元字符 | 说明 |
|---|---|
| \s | 任何一个空白字符(等价于[\f\n\r\t\v]) |
| \S | 任何非一个空白字符(等价于[^\f\n\r\t\v]) |
小结
主要讲解用来匹配特定字符(制表符、换行符)和用来匹配一个字符集合或字符类(数字、字母数字字符)的元字符。这些简短的元字符可以用来简化正则表达式模式。
重复匹配
有多少个匹配
需要一种能够匹配多个字符的方法,可以通过几个特殊的元字符来实现。
匹配一个或多个字符
要想匹配同一个字符(或字符集合)的多次重复,只要简单地给这个字符(或字符集合)加上一个+字符作为后缀就可以了。+匹配一个或多个字符(至少一个,不匹配零个字符的情况)。
比如:a匹配a本身,a+将匹配一个或多个连续出现的a。
文本
Send personal email to ben@forta.com. For questionsabout a book use support@forta.com. Feelfree to send unsolicited email to spam@forta.com.
正则表达式
\w+@\w+\.\w+
结果

这个模式把原始文本里的3个电子邮件地址全都正确匹配出来了。正则表达式中第一个\w+匹配一个或多个字母数字字符,再用第二个\w+匹配@后面的一个或多个字符,然后匹配一个.字符(使用转移序列.),最后用第三个\w+匹配电子邮件地址的剩余部分。
匹配零个或多个字符
+匹配一个或多个字符,但不匹配零个字符——+最少也要匹配一个字符。那么,如果你想匹配一个可有可无的字符——也就是该字符可以出现零次或多次的情况,你该怎么办呢?
这种匹配需要用*元字符来完成,把它放在一个字符(或一个字符集合)的后面,就可以匹配该字符(或字符集合)连续出现零次或多次的情况。
文本
Hello .ben@forta.com is my email.
正则表达式
\w+[\w.]*@[\w.]+\.\w+
结果

\w+:负责匹配电子邮件地址中第一个字符(一个字母数字字符,但是不包括.)。
[\w.]*:负责匹配电子邮件第一个字符之后、@字符之前的所有字符——这个部分可以包含零个或多个字母数字字符和.字符。
匹配零个或一个字符
?只能匹配一个字符(或字符集合)的零次或一次出现,最多不超过一次。如果需要在一段文本里匹配某个特定的字符,而该字符可能出现、也可能不出现,?无疑是最佳的选择。
文本
The URL is http://www.forta.com/, to connectsecurely use https://www.forta.com/
正则表达式
https?://[\w./]+
结果

这个模式的开头部分是https?。?在这里的含义是:前面的字符s要么不出现,要么最多出现一次。
在Windows上使用模式\r\n\r\n去匹配空白行,在Linux系统的正则表达式是\n\n。同时适用于Windows和Linux系统的正则表达式应该包含一个可选的\r和一个必须的\n。
[\r]?\n[\r]?\n
匹配的重复次数
正则表达式里的+ * ?解决了许多问题,但是光靠这些还不够。比如:
- +和*匹配的字符个数没有上限。我们无法为它们将匹配的字符个数设定一个最大值。
- +、*和?至少匹配零个或一个字符。我们无法为它们将匹配的字符个数另行设定一个最小值。
- 如果只使用+和*,我们无法把它们将匹配的字符个数设定为一个精确的数字。
为了解决这些问题并且对重复性匹配有更多的控制,正则表达式语言提供了一个用来设定重复次数的语法。重复次数要用{}来给出——把数值写在它们之间。
为重复匹配次数设定一个区间
为重复匹配次数设定一个最小值和最大值,这种区间必须以{2, 4}这样的形式给出,含义是最少重复2次、最多重复4次。
文本
4/8/0310-6-20042/2/201-01-01
正则表达式
\d{1,2}[-\/]\d{1,2}[-\/]\d{2,4}
结果

匹配“至少重复多少次”
{3,}表示至少重复3次,与之等价的说法是“必须重复3次或更多次”。
防止过度匹配
文本
<B>AK</B> and <B>HI</B>
正则表达式
<[Bb]>.*</[Bb]>
结果

这个正则表达式匹配了所有字符,而不是预期的标签内的内容。为什么会这样?因为*和+都是所谓的贪婪型元字符,它们在进行匹配时的行为模式是多多益善而不是适可而止的。
在不需要这种“贪婪行为”的时候该怎么办?答案是使用这些元字符的“懒惰型”版本。懒惰型元字符的写法很简单,只要给贪婪型元字符加上一个?后缀即可。
| 贪婪型元字符 | 懒惰型元字符 |
|---|---|
| * | *? |
| + | +? |
| {n,} | {n,}? |
对于上面的例子,使用正则表达式
<[Bb]>.*?</[Bb]>
结果

小结
正则表达式的真正威力体现在重复次数匹配方面。
- +:匹配字符的一次或多次出现
- ?:匹配字符的0次或一次出现
- *:匹配字符的0次或多次出现
- {}:精确地设定重复次数
元字符分贪婪型和懒惰型两种;在需要防止过度匹配的场合下,使用懒惰型元字符来构造你的正则表达式。
位置匹配
边界
位置匹配用来解决在什么地方进行字符串匹配操作的问题。例如使用cat正则搜索文本,scatter也会被匹配到,如果只是想搜索cat这个单词,就需要边界。
单词边界
单词边界由限定符\b指定,匹配一个单词的开始或结尾。\b匹配的是这样的位置,这个位置位于一个能够用来构成单词的字符(字母、数字和下划线,也就是与\w相匹配的字符)和一个不能用来构成单词的字符(\W)之间。
如果不想匹配单词边界,使用\B。
文本
The cat scattered his food.
正则表达式
\bcat\b
结果

字符串边界
单词边界可以用来进行与单词有关的位置匹配(单词的开头、单词的结束、整个单词)。字符串边界有着类似的用途,用来进行与字符串有关的位置匹配(字符串的开头、字符串的结束、整个字符串)。用来定义字符串边界的元字符有两个:
- ^:定义字符串开头
- $:定义字符串结尾
文本
<?xml version="1.0" ?>xmlns:blablablaxmlns:blablabla
正则表达式
^\s*<\?xml.*\?>
结果

小结
正则表达式不仅可以用来匹配任意长度的文本块,还可以用来匹配出现在字符串中特定位置的文本。\b用来指定一个单词边界(\B刚好相反)。^和$用来指定字符串边界(字符串的开头和结束)。
使用子表达式
什么是子表达式
我们已经知道了如何匹配一个字符的连续多次重复。比如\d+将匹配一个或多个数字字符,而https?将匹配http或https。但是这两个用来表明重复次数的元字符只作用于紧挨着它的前一个字符或元字符。
子表达式是一个更大的表达式的一部分;把一个表达式划分为一系列子表达式的目的是为了把那些子表达式当作一个独立的元素来使用。子表达式必须用()括起来。
文本
Hello, my name is yano I like 123
正则表达式
( ){2,}
结果

( )是一个子表达式,它是一个独立的元素,紧跟在它后面的{2,}将作用于这个子表达式(而不仅仅是分号)。
子表达式的嵌套
子表达式允许嵌套,多重嵌套的子表达式可以构造出功能极其强大的正则表达式来,但是难免会让模式变得难以阅读和理解。
如何匹配一个IP地址?
一个合法的IP地址里的各组数字必须满足:
- 任何一个1位或2位数字
- 任何一个以1开头的3位数字
- 任何一个以2开头、第2位数字在0~5之间的3位数字
- 任何一个以25开头、第3位数字在0~5之间的3位数字
正则表达式
(((\d{1,2})|(1\d{2})|(2[0-4]\d)|(25[0-5]))\.){3}((\d{1,2})|(1\d{2})|(2[0-4]\d)|(25[0-5]))
小结
子表达式的作用是把同一个表达式的各个相关部分组合在一起。子表达式必须用()来定义。子表达式的常见用途包括:对重复次数元字符的作用对象作出精确的设定和控制、对|操作符的OR条件作出精确的定义等等。
回溯引用:前后一致匹配
回溯引用有什么用
首先看一个例子。HTML程序员经常使用标题标签(<H1>到<H6>,以及配对的结束标签)来定义和排版Web页面里的标题文字。假设需要找到某个Web页面的所有标题文字,不管它的级别是多少。
文本
<BODY><H1>Welcom to my Homepage</H1>Content is divided into two sections:<H2>ColdFusion</H2>Happy Fish<H2>Wireless</H2>EXIT</BODY>
正则表达式
<[hH]1>.*</[hH]1>
结果

模式<[hH]1>.*</[hH]1>只能匹配一级标题,但是如何才能匹配任意级别的标题呢?如果使用一个字符集合来代替1,如下所示:
正则表达式
<[hH][1-6]>.*?</[hH][1-6]>
结果

这个模式匹配任何一级标题的开始标签和结束标签,但是匹配还是会有问题,如果一个HTML的文本有问题,<H2>开始标签对应的结束标签是</H3>怎么办?如下所示:
文本
<BODY><H1>Welcom to my Homepage</H1>Content is divided into two sections:<H2>ColdFusion</H2>Happy Fish<H2>Wireless</H3>EXIT</BODY>
正则表达式
<[hH][1-6]>.*?</[hH][1-6]>
结果

在这个例子中,原始文本里有一个标题是以<H2>开头、以<H3>结束的。这显然是一个不合法的标题,但是它与我们所使用的模式匹配上了。出现这种情况的根源是这个模式的第2部分对模式的第1部分毫无所知。要想彻底解决这个问题,就只能求助于回溯引用。
回溯引用匹配
对于上述文本,使用正则表达式
<[hH]([1-6])>.*?</[hH]\1>
结果

并没有匹配错误标签,因为使用了回溯引用。这次用()把[1-6]括了起来,使它成为了一个自表达式。这样我们就可以用来匹配标题结束标签的</[Hh]\1>用\1来引用这个自表达式。自表达式([1-6])匹配数字1~6,\1只能匹配与之相同的数字。这样一来,<H2>Wireless</H3>就不会被匹配到了。
回溯引用在替换操作中的应用
到目前为止,博客介绍的正则表达式都是用来执行搜索的,即在一段文本里查找特定的内容。但是我们所编写的绝大多数正则表达式模式也可以用来搜索文本,但是还可以用来完成各种复杂的替换操作。正则表达式更适用于复杂的替换,尤其是需要使用回溯引用的场合。
假如我们需要把原始文本里的电子邮件地址全都转换为可点击的链接,该怎么办?
文本
Hello, ben@forta.com is my email address.
正则表达式
(\w+[\w.]*@[\w\.]+\.\w+)
替换
<A HREF="mailto:$1">$1</A>
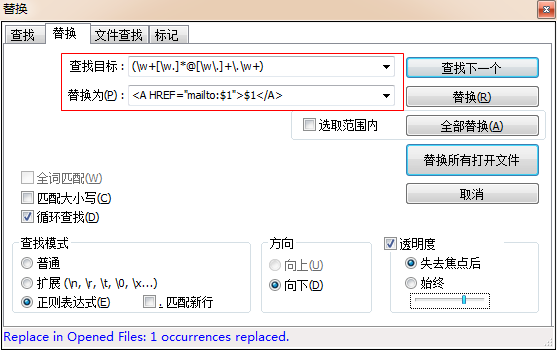
结果
Hello, <A HREF="mailto:ben@forta.com">ben@forta.com</A> is my email address.
替换操作需要用到两个正则表达式:一个用来给出搜索模式,另一个用来给出匹配文本的替换模式。回溯引用可以跨模式使用,在第一个模式里被匹配的子表达式可以用在第二个模式里。这次正则表达式加了一对(),把它变成了一个子表达式,这样被匹配到的文本就可以用在替换模式里了。<A HREF="mailto:$1">$1</A>使用了两次被匹配的子表达式($1)。
大小写转换
用来进行大小写转换的元字符
| 元字符 | 说明 |
|---|---|
| \E | 结束\L或\U转换 |
| \S | 把下一个字符转换为小写) |
| \L | 把\L到\E之间的字符全部转换为小写 |
| \u | 把下一个字符转换为大写 |
| \U | 把\U到\E之间的字符全部转换为大写 |
\l和\u只能把下一个字符(或子表达式)转换为小写或大写。\L和\U将它后面的所有字符转换为小写或大写,直到遇到\E为止。
下面将一级标题的标题文字转换为大写:
文本
<BODY><H1>Welcom to my Homepage</H1>Content is divided into two sections:<H2>ColdFusion</H2>Happy Fish<H2>Wireless</H3>EXIT</BODY>
正则表达式
(<[Hh]1>)(.*?)(</[Hh]1>)
替换
$1\U$2\E$3
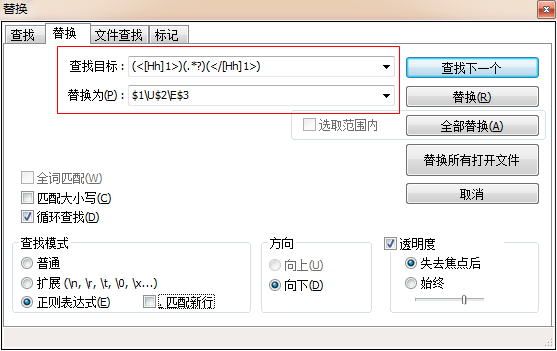
结果
<BODY><H1>WELCOM TO MY HOMEPAGE</H1>Content is divided into two sections:<H2>ColdFusion</H2>Happy Fish<H2>Wireless</H3>EXIT</BODY>
小结
子表达式用来定义字符或表达式的集合。除了可以用在重复匹配操作以外,还可以在模式的内部被引用,这种引用被称为回溯引用。回溯引用在文本匹配和文本替换操作里非常有用。
前后查找
有时候需要正则表达式标记要匹配的文本的位置(而不仅仅是文本本身)。这就引出了前后查找(lookaround,对某一位置的前后内容进行查找)的概念。
前后查找
我们现在要把一个Web页面的页面标题提取出来。HTML页面标题是出现在<TITLE>和</TITLE>标签之间的文字。而这对标签又必须嵌在HTML代码的<HEAD>部分里。
文本
<HEAD><TITLE>Ben Forta's Homepage</TITLE></HEAD>
正则表达式
<TITLE>.*</TITLE>
结果

但是这个模式的效果不够理想,因为只有页面标题才是我们需要的。我们现在需要一种模式,它包含的匹配本身并不返回,而是用于确定正确的匹配位置,它并不是匹配结果的一部分——前后查找。
向前查找
向前查找指定了一个必须匹配,但不在结果中返回的模式。向前查找实际上就是一个子表达式,从语法上看,一个向前查找模式其实就是一个以?=开头的子表达式,需要匹配的文本跟在=后面。
我们来看一个例子。例子里的原始文本是一些URL地址,现在需要把它们的协议名部分提取出来。
文本
http://www.forta.com/https://mail.forta.com/ftp://ftp.forta.com/
正则表达式
.+(?=:)
结果

在上面列出的URL地址里,协议名和主机名之间以一个:分隔。模式.+匹配任意文本(第一个匹配是http),子表达式(?=:)匹配:。注意,被匹配到的:并没有出现在最终的匹配结果里;我们用?=向正则表达式引擎表明只要找到:就行了,不要把它包括在最终的匹配结果里——用术语来讲,就是“不消费”它。
向后查找
?=向前查找,查找出现在匹配文本之后的字符,但不消费这个字符?<=向后查找,查找出现在匹配文本之后的字符,但不消费这个字符
把向前查找和向后查找结合起来
文本
<HEAD><TITLE>Ben Forta's Homepage</TITLE></HEAD>
正则表达式
(?<=<TITLE>).*
结果

(?<=<TITLE>)是一个向后查找操作,匹配但不消费<TITLE>;(?=</TITLE>)是一个向前查找操作,匹配但不消费</TITLE>。
对前后查找取非
向前查找和向后查找通常用来匹配文本,其目的是为了确定将被返回为匹配结果的文本的位置。这种用法被称为正前向查找和正后向查找。正指的是寻找匹配的事实。
前后查找还有一种不太常见的用法叫负前后查找,指的是不与给定模式相匹配的文本。前后查找必须用!来取非,替换掉=。各种前后查找操作符如下表所示:
| 操作符 | 说明 |
|---|---|
| (?=) | 正向前查找 |
| (?!) | 负向前查找 |
| (?<=) | 正前后查找 |
| (? | 负向后查找 |
小结
有了向后查找,我们就可以对最终的匹配结果包含且只包含哪些内容,做出更精确的控制。前后查找操作是我们可以利用子表达式来指定文本匹配操作的发生位置,并收到只匹配不消费的效果。
END
我的简书博客:http://www.jianshu.com/users/6835c29fc12a/latest_articles
