@buptzym
2016-05-04T04:00:13.000000Z
字数 1063
阅读 995
词向量的关系解法
未分类
您的邮件给了我巨大的启发。
我们把三种情况的关系和对应的矩阵全部列出来:

从这个例子上可以看出,显然一一对应的结构是最合适的,这意味着文章的每个字都与另一篇文章的每个字一一对应。极端情况下,两篇文章完全一致,那么矩阵只有对角线有值,是单位阵。
因此,我们认为矩阵的对角区域的值分布地越集中,相似度越高。
但是,有些问题需要考虑:
1.矩阵是否是方阵?
不一定,文章的长度不一样就不是方阵。但如果向量长度特别大,那么矩阵的规模就难以维护了。此时没有必要把每个词都列进去,找出TFIDF排名靠前的前n个词即可。不够n个的补零。这样矩阵就成了方阵了。
方阵更适合计算,但不是必须的。而且该矩阵也不是对称矩阵。
2.将最大元素移到对角线
一一对应肯定最佳,但如果是乱序,那么形成的矩阵,在对角线上无法达到最大。此时需要重排矩阵,使其在不改变矩阵的结构下,尽量让较大的值往对角线移动。

要么只能交换行,要么只能交换列。我们选择交换列,在一行中找出最大的值,将该值对应的列,与第一列交换。
之后,在虚线所围的子矩阵中,继续执行上述操作。
这样的复杂度并不高,可以接受。
3. 如何评估对角线区域对相似度的贡献?
经过上述步骤,对角线上尽可能集中了较大的值。形成了一个对角线带。宽度可以根据需求来选择。如图中灰色区域所示。

一个最佳的对角带,应当均值尽可能高,同时,差别不能太大。
举个例子,两篇文章,第一段非常相似,但后面的不同。和两篇文章,每段都比较相似,可能它们的相似度均值差不多,但明显后者比前者相似度评分更高。
如果将对角线上的元素值,画成曲线,就是下面的图:
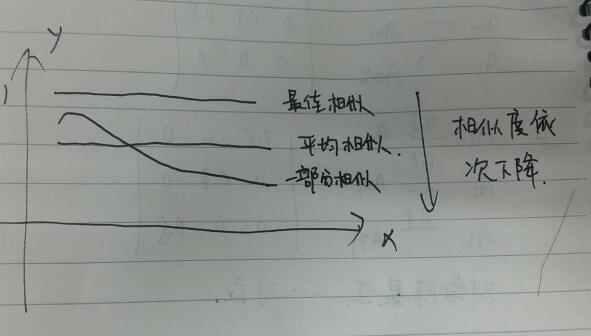
按图来说,曲线越高,越水平,那么相似度越大。由于缺乏更好的数学工具去描述这种特性,那么我们用对角带所有实数值的均值和方差来代替。
4.是否要考虑对角带之外的部分?
应当考虑。因为对角带之外的元素,也对相似度做出了贡献,只是权重没有那么高而已。而对角线之外的元素,方差的大小基本上无关紧要。
因此,我们能得到一个经验公式:
对角带方差越小,因此用的方式来描述。由于输入矩阵的每个元素都在[0,1]范围之内,所以以上三个部分的值,都不会超过1。
a,b,c的值应当根据实际情况来给出,并进行调整。
考虑极端情况,如果两篇文章全部都是由同一个词组成的,那么构成了一个满1矩阵。此时肯定大于1。因此需要使用sigmoid函数,对其进行压缩。使关系总能保证在的范围之内。
