@buptzym
2017-01-19T12:19:59.000000Z
字数 1833
阅读 707
深度学习的基础知识
学习笔记
深度学习一统天下,所有其他方法一律拜倒...尤其是有了tf这种框架之后:
- 计算表达统一,如果表示成一种形式,就便于优化了。
- 能够从网络角度表达特征,形成丧病的端到端的模型。
然后涌现出一堆新名词,简单的DNN,再到CNN,RNN,再到DSSM,LSTM。总不至于和别人讨论都不知道基本概念吧! 这篇文章来帮助复习这些基础知识。
最基本的神经网络
两层网络可以表达异或,三层网络就能足够表达分类了。使用反向传播算法,能够快速更新权重和梯度。
之前我就写过一篇神经网络入门的文章,现在看来依旧醍醐灌顶,感觉都忘光了。不过这张图真是印象深刻,分三步走。

不过,还有不少问题没有解决。
- 如果层数太多,那么后向传过来的参数,可能更新起来就很不给力了,所谓山高皇帝远。
- 如何保证网络不会过拟合
- 对于时序问题,如何解决。
RNN(循环神经网络)
RNN有两种意思,循环神经网络和递归神经网络。后者更复杂,先谈前者。普通NN的网络,是没有记忆性的。比如要对电影中的时间点做分类(尿点,槽点,高潮),如果拿出一帧图,是不可能实现的。你肯定会说,我做一个窗口把数据丢进去就好了! 聪明!可是这个窗口得多大呢?
窗口太小了,信息量不够,太大了,大到整个电影,那还对时间点做毛分类啊,成了对电影做分类了。这个例子,也对文本一样适用。
所以,这种具有前后依赖的问题,不是靠简单提特征就能解决的。需要对现有模型做改进。
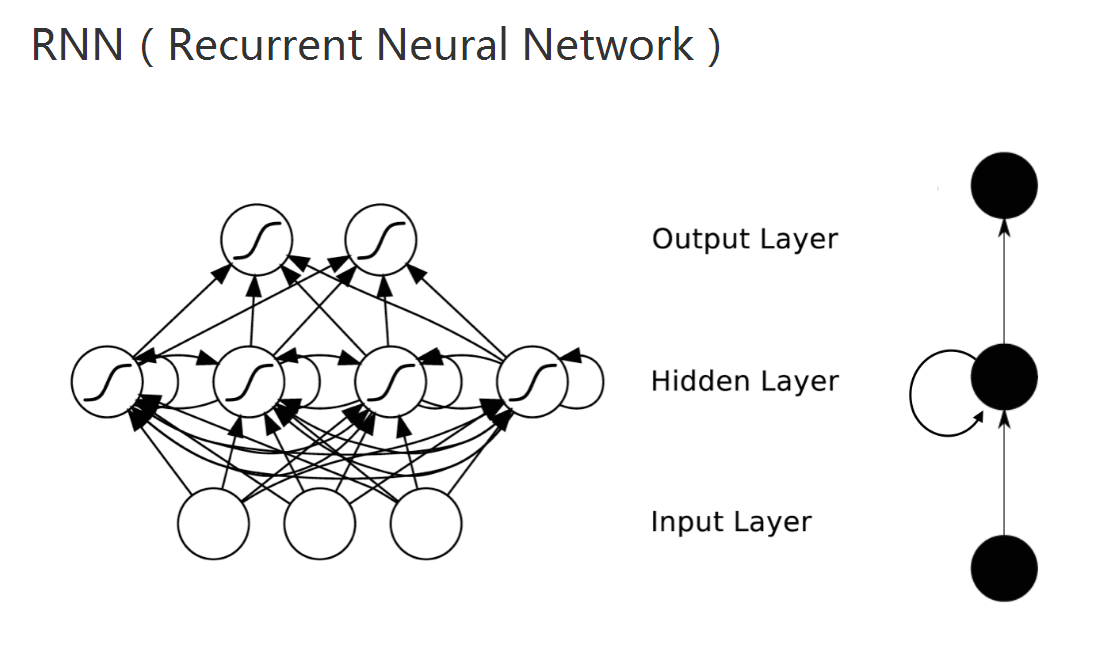
看起来复杂,其实就是将模型展开而已:
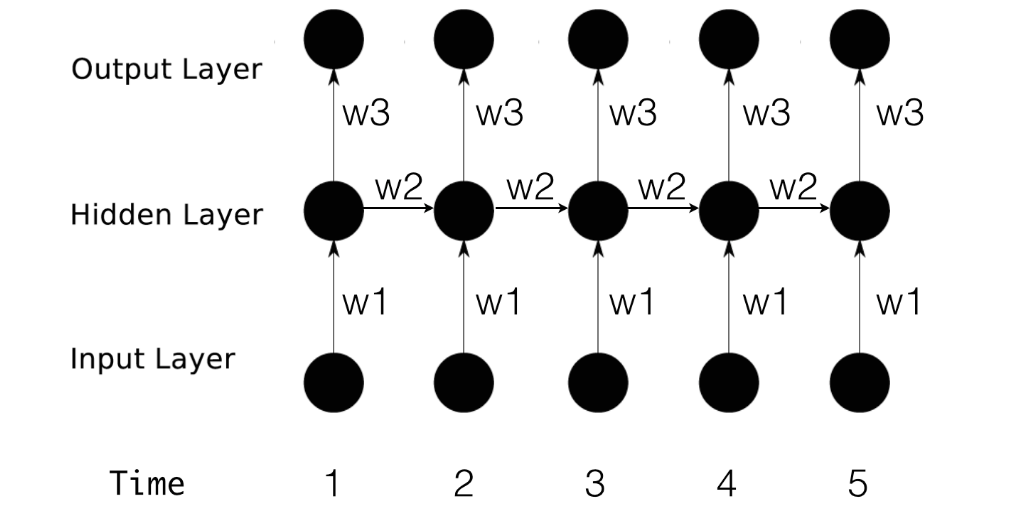
在训练和预测时,只需要对原有的BP算法做改造,加上前一个时间的分量。
LSTM
RNN可以解决记忆性,但是依然不能解决长程依赖,因此需要进一步修改网络结构去解决该问题。
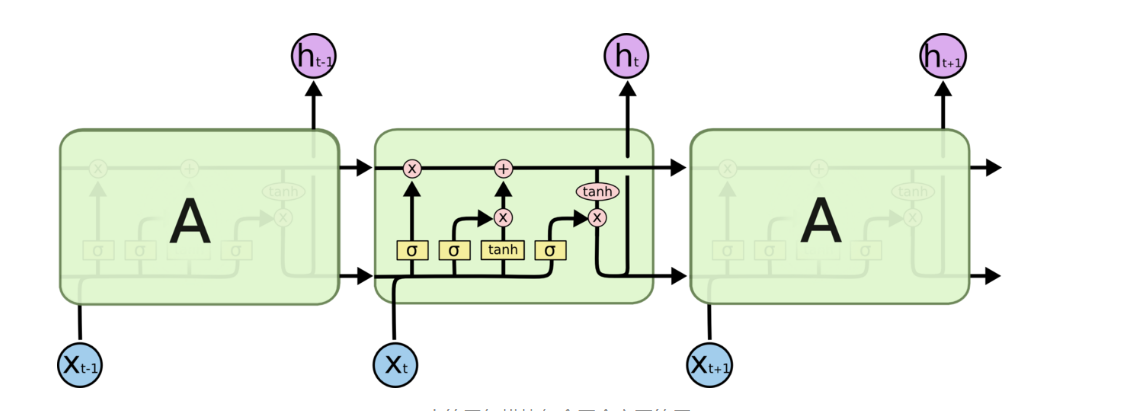
里面定义了更多的子结构和算子,可是为什么要这么设计,这样做就能实现长程记忆吗?太可怕了。换个图看得更清楚:
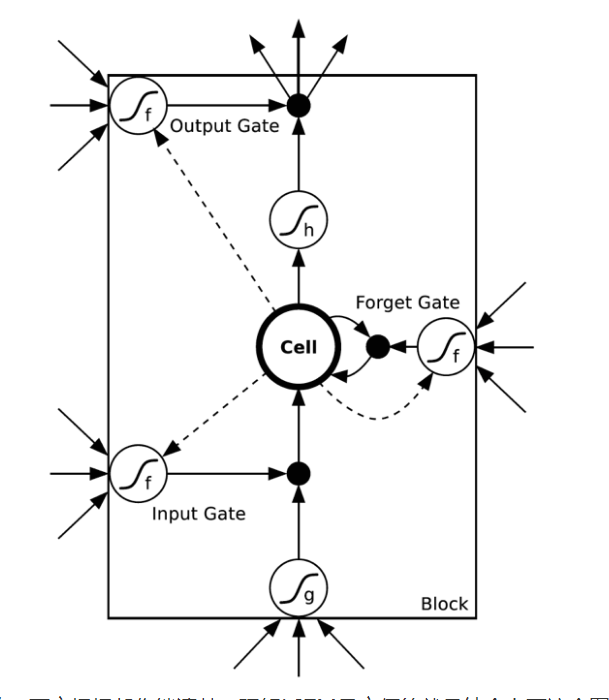
用不同的时期间隔来训练LSTM记忆单元,这样可以迫使某些记忆单元记住长期信息,而其它的记忆单元可以更加关注短期记忆。这种方法更符合直觉,也避免了过多的超参数调优。
CNN
CNN当然不是那个电视台,而是卷积神经网络。
卷积的概念本身不新奇,对一个序列从左到右卷积,能够获取一段区间内连续的特征。同样也可以对矩阵做处理,就能获取图片在某个区域内整体的信息。

对图片做分类,最大的问题是特征太多,训练很可能不充分,CNN通过两个手段较好地解决了这个问题:
- 局部感知
将网络分成多层,每一层不需要对整个图形做感知,而仅需检查某一部分就可以了,也就是所谓卷积。参考上面的动图。

- 共享权重
一张图片不同位置的特性是可以共用的,例如边缘和形状检测。
- 多卷积核
既然共享了权重,就肯定不能只使用一种卷积核,否则就只能检测边缘了。根据需求,可以设计多个卷积核,分别检测边缘,眼睛,人脸... 这种层次化结构也反映了知识的树状结构。
- Pooling
这又是个新概念,虽然有共享权重了,但因为卷积核种类很多,那么权重还是太多,因此对同一个卷积核在不同位置得到的权重,可以做池化,max-pooling或 average—pooling, 这就是为什么如果可视化某些卷积核时,图形会变得比较模糊。
Word2Vec
这是个典型地将深度学习用在文本挖掘的例子,
GANs
对抗学习: 20 年来机器学习领域最酷的想法, 左右互搏。一个生成器,一个判别器。
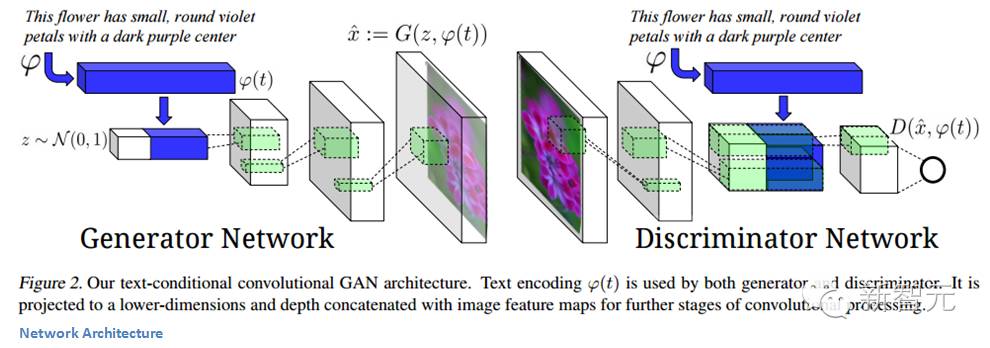
当学习编程或攀岩时,如果你一直接收某个专家的“beta(反馈建议)”,则可以进步得更快。在你获得足够的经验能够自我反馈批评之前,有一个外部的批评家来纠正你每一小步的错误可以更容易训练你大脑的生成网络。即使有一个内部批评家在监督你,学习一个有效的生成网络仍然需要认真的练习。
如何提升精度?
训练数据要够多,可以对原始数据做变换,比如加噪音,镜像翻转。
mini-batch比SGD效果更好,SGD很可能导致梯度无法进行。
合理的learning rate, 随着训练进行,该值可以慢慢减少。
为了避免在梯度上陷入某个特定值,需要增加动量,这样能冲上某个特定的值。
其他扩展知识
deep or fat? 哪个更好?
虽然产生的参数一致,但fat网络无法定制结构,需要更多的训练数据,而deep网络的分层性质,可以分层训练,还能迁移。通常来说,deep更好。
当然,deep很有可能出现BP训练不够充分的问题,将激活函数从sigmoid修改为ReLU(线性),反而能训练出来。
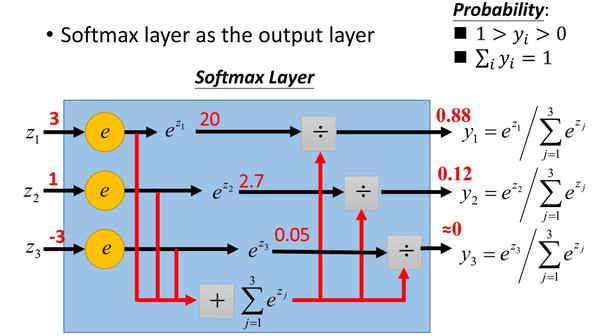
Softmax
这个不属于深度学习的概念。二分类时,可以很方便的sigmoid, 但多分类时,sigmoid就不管用了! 就需要softmax了。