@liuhui0803
2018-05-03T00:09:20.000000Z
字数 4151
阅读 3065
如何构建AI文化:AI的启蒙之路
软件开发 人工智能 AI AI文化

从九十年代的经验中学习
在Web诞生之初,当时还有专门负责写“代码”的“开发者”。这些代码在写好后会交到“运营”人员手中,而你也知道,实际上企业用来赚钱的网站,当时都是这些运维人员负责的,例如系统管理员、数据中心工作人员、数据库管理员(差点忘了他们至今还存在着,DBA们,你们好啊!)。当时,网站的发布管理需要遵守非常严格的规定,测试过程充满痛苦,任何新内容发布都要经历冗繁的过程。

还记得Joel测试吗?是的,估计听说过这东西的都是三四十岁的“古董级”工程师了。
对于测试中的任何问题,如果你的答案是否定的,那么意味着你的团队文化出现了某种问题。
- 使用源代码控制系统了吗?很多工程师经常担心自己也许会(或者已经)弄坏他人的代码。例如因为硬盘故障导致所有代码丢失。
- 能否一键点击开始构建?工程师总有或多或少的时间要花在构建工作中。需要执行的步骤越多,出错的可能就越大;但生成构建的次数越少,新代码的测试速度就越慢。
- 是否进行每日构建?如果某个构建出错了,可能要在一段时间后才能注意到。(现在大家都开始持续集成了,其实这早已不是新鲜事物!)
- 是否有Bug数据库?电子邮件、即时贴、来自愤怒的客户和“业务”伙伴的电话通话…… 总有某些Bug会被遗忘。还有很多Bug未能妥善记录,甚至无法重现。
- 你是否会在写新代码前先修复Bug?技术债会拖慢新功能的发布速度。如果将整个代码库的重构项目交给小型团队负责,那么可能得等待一年才能最终实现。
- 是否有始终保持最新的计划安排?具体日期毫无意义,该完工的时候终归就完工了。当你胡乱预估的时候,一定得考虑好这类问题。
- 具体规范确定了吗?工程师代替产品经理来思考,但是完工后呢?“这根本不是我想要的!能否实现另外一个如何如何的功能?”
- 程序员们能得到安宁的工作环境吗?咱去喝咖啡吧!嘿,某事我具体该怎么做?天哪,HR发的这封邮件你看了吗?有些工程师问公司能否为他们的耳机买单,被HR拒绝了。
- 你是否已经用上了市面上最棒的工具?爱抱怨的工程师,效率往往都不会太高。
- 你有测试人员吗?Bug的数量往往更多。
- 新招的求职者在面试中是否写出了代码?团队中偶尔就会遇到某些人,简历里充斥着各种时髦的关键字,但工作中遇到具体问题后甚至无法学习新的编程语言来解决问题。
- 是否会进行易用性测试?工程师开发了某个功能,可几个月后发现用户根本不喜欢。这就导致了经典的“易用性问题”。
所有这些问题有一个共通之处:会拖累工程团队的速度。可用的软件发布给用户的速度变慢,用户反馈的速度变慢,产品创新的速度变慢,业务为客户创造价值的速度变慢。
能更快速为用户创造价值的竞争对手终将战胜你自己。这一切可能都因为你没有使用构建系统。
问题一开始可能显得微不足道。这些问题已经可以很熟练地随着时间的积累产生越来越大的影响。对于技术进步,我们往往抱有一种直观线性发展的观点,例如会认为,通过今天所实现的节奏可以预测未来的发展速度。如果随着时间累积,软件交付速度以指数形式减速,我们就会因为这种线性的观点而低估未来的交付速度会慢到何种程度。
衡量速度
于是后来诞生了以“速率(Velocity)”这一概念为主的敏捷社区。这是一种诊断式的指标,用于衡量团队可以用多快的速度基于现有代码库发布复杂代码。在每次冲刺结束后,需要加入用于衡量团队速率的故事点(Story point)。如果速率降低了,意味着团队发布复杂“故事”的速度变慢了,因此可以认为存在方向性错误。赶紧采取措施吧!
问题在于,速率取决于很多东西。我们很难知道该怎样做才能将其推向正确的方向。毫无疑问,这个问题的解决需要时间,所有看似简单快速的解法(例如团队扩员)其实都解决不了最核心的问题。
并且产品的构建并不只是工程师的责任。项目经理、用户体验团队、设计师,人人有责!我们很难单纯使用一个类似于“我们的速度足够快吗”这样的指标来概括地衡量产品构建过程中的方方面面。速率无法完全体现所有这一切,我们可能依然在构建大家并不想要的产品。
接着又出现了精益创业(Lean Startup)。
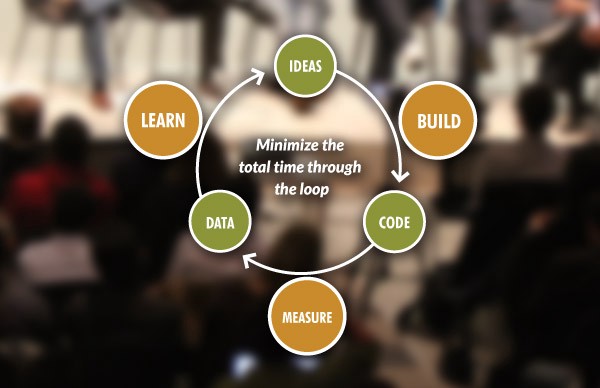
精益创业方法论
对于产品有自己的想法?做出假设 > 构建最小可行产品(MVP) > 验证自己的假设。要尽可能快速地完成整个过程(即一次迭代)。
负责产品构建的人终于看到了这些征兆。速度很重要。迭代的速度很重要。
快速迭代 = 成功。机器学习领域尤其如此。
我们的CTO Prashast曾开发了几个被Google用于搭建生产用机器学习系统的工具,他认为任何机器学习配置都必须能实现快速迭代,对此他是这样解释的:
你不能仅仅“从事机器学习”就开始觉得一切都会奇迹般地生效。训练后就遗忘(Train-and-forget)的心态意味着模型很快将变得陈旧不堪。产品会发生变化,用户会发生变化,行为会发生变化。实际上,持续不断的实验探索和改进是一条漫长的路。你需要首先用简单的事情进行尝试,随后在模型中尝试不同的特征。数据并非总是洁净,你需要用不同的模型进行实验,随后进行A/B测试。生产环境中难免会出错,可能需要花数月时间不断调整才能正常使用。
一旦着手进行,你就需要将其视作一种软件项目。需要构建、测试、部署、迭代。每个迭代周期都会让结果日渐完善。可以迭代的次数越多,机器学习环境的完善速度就越快。
为了验证这种说法,我们与数据科学团队讨论了他们对机器学习技术的使用方式。你可能已经想到了,这个团队涉及的领域很广泛,会有极为老练的团队负责处理PB级别的数据,每天需要交付数十亿次预测结果,而这些结果会被其他团队用于训练自己的第一个模型。
当然,成熟的团队都面对快速迭代做好了准备。Uber的内部机器学习平台就是个例子。
然而这些团队并非总是喜欢这样做,似乎整个团队的启蒙都会经历一条曲线。

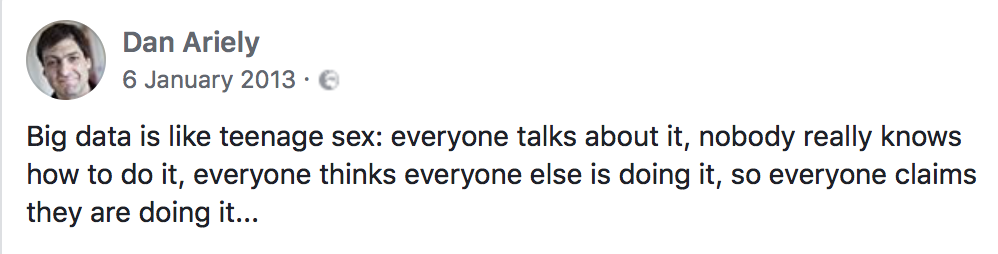
图中内容:大数据就像青少年的“啪啪啪”:大家都在谈,没人知道到底该怎么做,每个人都认为其他所有人都正在做,于是每个人都宣称自己正在做……
关于机器学习,这种说法同样适用!
这方面,不同组织的做法可分为两种类型。一种类型采取了“精益AI”的方法,另一种则采取了“我看一篇文章说我们需要建立自己的AI策略”的方法。
大部分团队都会经历这样的启蒙曲线,原因在于AI文化的构建是一段旅途。团队需要从一些可以快速交付的简单事务着手,借此展示价值并以此为基础进行完善。大部分时候,着手AI方面的工作意味着需要退回曲线上之前的阶段。团队可能需要花费大量时间处理所有数据,进行清洗并重新思考数据基础架构,而这仅仅可能是因为这些因素拖累了AI工作。
对于认为“既然已经有AI策略了,那么我们直接构建机器学习平台吧”,进而直接跳到曲线中间阶段的团队,通常将会失败。这种做法放大了产品团队(包括数据科学家!)和董事会之间的断裂。也难怪数据科学家会感觉受挫并且很多公司开始遇到AI冷启动问题。
想要构建AI文化?那就彻底经历曲线的每个环节并且进行更快速的迭代。
AI团队实现更快速迭代的一些方法包括:
- 清洁、具备妥善的标签,并且足够一致的数据。
- 一键点击式模型训练和部署机制。
- 自服务数据科学。降低迭代对模型本身的工程依赖性,例如尝试新的特征,构建新的模型,自动进行超参数(Hyperparameter)优化。
- 为数据访问、数据操作、聚类模型训练、模型部署和实验、在线预测查询以及候选人计分提供可缩放的高性能系统。
- 基础架构运维人员将数据科学家视作使用自己工作成果的“一等公民”。
- 与生产型机器学习环境完全一致的开发用机器学习环境。
我们用来衡量AI团队文化的Joel测试内容如下:
- 对数据管线进行版本控制并使其可再现。
- 确保管线可以一键(重新)构建。
- 在只需工程人员最少量帮助的情况下部署到生产环境。
- 成功的机器学习系统是一个漫长的游戏,只能在遵守游戏规则的情况下参与。
- 持续改善。实验和迭代是一种工作态度。
因此我们开发了Blurr。将数据汇聚到一起,针对机器学习的需求进行处理、清洗和混合,这种操作并不是只进行一次就够的。这是任何AI工作的基础,而以此为基础进行持续不断的改进,这对任何成功的AI文化都至关重要。Blurr提供了一种基于YAML的高级语言,可供数据科学家/工程师定义数据转换。原本需要花2天时间用Spark代码完成的工作,使用Blurr可以在5分钟内搞定。
Blurr是开源的,因为我们认为开源的方法可以促进AI各领域的创新。该技术的开发甚至都是公开的,我们的每周冲刺都已发布到GitHub,任何人都可以看到。
DevOps工具市场的存在是为了让我们更快速地发布软件。

我们的愿景在于,应该构建一种MLOps市场,帮助团队更快速发布机器学习产品,而Blurr的诞生是我们向着这个目标迈进的第一步。因为目前最大的问题恰恰在于数据本身的迭代。
我们有着数据驱动的文化。AI源自数据,因此我们就有了AI文化!
不,其实你并没有。
“数据驱动”,仅仅只能消除决策工作中人的偏见。应用加载速度变长是坏事吗?这个新模型比原来的好吗?先看看数据再说话吧!
AI文化是一种算法驱动的文化,由人类构建能在生产环境中做决策的机器,并通过部署的算法实现人类设法希望达成的目标(提高广告的点击率、转化率、参与度等)。
AI文化可以很好地适应概率判断(Probabilistic judgement)。推荐这种产品,会比推荐那种产品对客户的吸引力提高60%;40%的时间里,情况都不会变得更好。感觉这些结论很棒吧?那就开始着手并不断完善吧!
AI文化重在持续不断的实验和迭代。组织中的其他所有部分都必须为其提供支持。
人类很复杂。当我们自己只能随机做决策,甚至捎带着具备模式识别能力和认知偏差时,我们会期待着通过机器获得确定性的行为。人类经营着企业并且玩弄权术,在构建AI文化时,这些情况可能会让我们极为受挫。
这使得我好奇,当人类(以及类似企业这种人类发明的社会结构)面对具备超级智能的机器时会怎么办。欢迎来到2029年!
Blurr目前已经发布了开发者预览版,你可以访问GitHub了解详情并给该项目加星!
作者:Avinash Royyuru,阅读英文原文:How to build AI culture: go through the curve of enlightenment
