@liuhui0803
2016-05-20T00:00:27.000000Z
字数 10983
阅读 3268
广度、深度、易用性,详解6大机器学习云
机器学习 分析 云计算 数据科学 大数据

图片来源:Shutterstock
Amazon、Microsoft、Databricks、Google、HPE和IBM机器学习技术,广度、深度,易用性详解。
我们所谓的“机器学习”可能表现为多种形式。最纯粹的机器学习技术为分析师提供了一系列数据探索工具,丰富的机器学习模型,健壮的解决方案算法,以及通过解决方案进行预测的方法。Amazon、Microsoft、Databricks、Google以及IBM云平台都提供了预测API,分析师可将其用于不同领域。HPE Haven OnDemand针对二分类(Binary classification)问题提供了有限的预测API。
然而并非所有机器学习问题都只能从零开始着手解决。一些问题可通过对足够广泛的样本进行训练以实现广泛的应用,例如语音到文字、文字到语音、文本分析,以及面部识别,这些问题都可以通过“成品”解决方案完成。当然,很多机器学习云供应商会通过API提供这些能力,帮助开发者将这些功能融入自己的应用程序中。
这些服务可以识别并记录口述的美国英语(以及其他几种语言)。但不同服务对同一个人口语识别能力的高低取决于讲话者的语调和口音,以及解决方案训练时使用的语调和口音样本。Microsoft Azure、IBM、Google和Haven OnDemand都提供了现成的语音到文字转换服务。
机器学习方面的问题有很多种。例如,尝试通过其他观测结果预测连续变量(例如销量)可能会遇到回归问题(Regression problem),尝试预测特定的一系列观测结果可以归于哪种类别(例如垃圾邮件)可能会遇到分类问题(Classification problem)。Amazon、Microsoft、Databricks、Google、HPE,以及IBM提供了解决一系列机器学习问题所需的工具,不过这些工具的完善程度各有不同。
本文将简要介绍这六大商用机器学习解决方案。Google已于三月公布了自己的云端机器学习工具和应用程序,但Google Cloud Machine Learning目前还没有正式上市。
AI简史
人工智能(AI)有着曲折的历史。早期研究主要专注于玩游戏(跳棋和国际象棋)和证明各种定理,随后这个领域开始专注于自然语言处理、反向推理(Backward chaining)、正向推理(Forward chaining)以及神经网络。在二十世纪七十年代“AI的冬天”结束后,八十年代逐渐出现了大量商用的专业AI系统,不过当时从事这一领域的公司并没有坚持太久。
二十世纪九十年代,第一次海湾战争期间部署的调度程序DART让美国国防部高级研究计划局(DARPA)30年来在AI方面的投入一次回本,同一时期IBM超级计算机深蓝(Deep Blue)战胜了国际象棋大师Garry Kasparov。二十一世纪初,自主型机器人已经广泛应用于远程勘探(Nomad、Spirit以及Opportunity)和家居清洁(Roomba)。2010年前后,我们开始使用基于视觉的游戏系统(Microsoft Kinect)和无人驾驶汽车(Google),IBM Watson战胜了电视猜谜节目"Jeopardy"过去两届冠军,最近机器(Google AlphaGo)还战胜了九段围棋冠军。
自然语言处理技术继续完善,我们已经可以通过手机与Apple Siri、Google Now,以及Microsoft Cortana直接对话(或打字)交流。最终,通过历史数据对计算学习理论和模式识别与优化算法持续不断的完善,终于在机器学习技术中被发扬光大。
Amazon Machine Learning
Amazon希望让机器学习成为一种任何人都可以轻松使用的技术。该公司特意与了解业务问题解决方式的分析师合作,而这些分析师可能并不了解数据科学和机器学习算法。
一般来说,为了使用Amazon Machine Learning,首先需要清理数据并将其以CSV格式上传至S3;随后创建、训练,并评估ML模型;最后创建批处理或实时预测。整个过程以及其中的每个步骤都是交互式的。尽管Amazon有多种算法可供选择,但机器学习并不是那种简单、静态的神丹妙药。
Amazon Machine Learning支持三种类型的模型:二分类(Binary classification)、多级分类(Multiclass classification)以及回归(Regression),每种类型需要一种算法。为了进行优化,Amazon Machine Learning使用了随机坡降法(Stochastic Gradient Descent,SGD),这种方法可以让多个序列传递至训练数据,并为每个小批量样本更新要素权重(Feature weight),借此试图将损失函数(Loss function)降至最低。损失函数代表着实际值和预测值之间的差异。这种坡降法最适合用于只存在连续可微分损失函数的情况,例如逻辑和平方损失函数。
在二分类方面,Amazon Machine Learning使用了逻辑回归(逻辑损失函数外加SGD)。
在多级分类方面,Amazon Machine Learning使用了多项式逻辑回归(多项式逻辑损失外加SGD)。
在回归方面,Amazon Machine Learning使用了线性回归(平方损失函数外加SGD)。
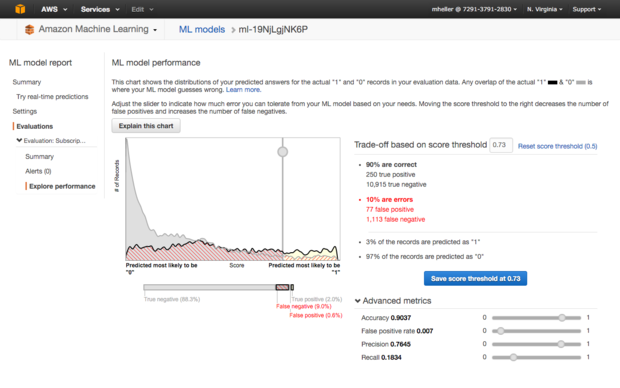
通过在Amazon Machine Learning中训练并评估二分类模型后,可选择自己的评分阈值以实现自己需要的错误率。上图中将阈值的值从默认值增加至0.5,这样便可以为营销和销售领域生成更强壮的线索。
Amazon Machine Learning通过目标数据的类型确定要解决的机器学习任务类型。例如,使用数值目标变量预测问题意味着回归;使用非数值目标变量预测问题,如果只有两种目标状态则意味着二分类,如果有超过两种目标状态则意味着多级分类。
Amazon Machine Learning中所用功能的选择保存在“配方”中。针对数据源完成描述性统计(Descriptive statistics)的计算后,Amazon会创建一个默认配方,用户可以直接使用,或使用自己机器学习模型中的数据将其替代。
准备好满足评估需求的模型后,即可借此设置实时Web服务或生成批处理预测(Batch of prediction)。然而要注意,与基本物理常数不同,人们的行为会随时间产生变化。因此需要定期检查模型产生的预测精确度指标,并按需再次进行训练。
Azure Machine Learning
与Amazon不同,Microsoft希望为有经验的数据科学家提供一整套种类各异的算法和工具。因此Azure Machine Learning已被包含在更大规模的Microsoft Cortana Analytics Suite套件中。Azure Machine Learning也为模型的训练和评估用数据流提供了拖拽式界面。
Azure Machine Learning Studio包含了导入数据集,训练和发布实验性模型,在Jupyter Notebook中处理数据,以及保存训练后模型等功能。Machine Learning Studio自带数十种数据集样本,五种数据格式转换器,读写数据的多种方法,数十种数据转换,以及三种特征选择选项。通过Azure Machine Learning,您可以使用多种可用于异常检测、分类、聚类,以及回归的模型;四种可用于计分模型的方法;三种用于评估模型的策略;以及六种用于培训模型的过程。您还可以使用多种OpenCV(开源计算机视觉)模块、统计函数,以及文本分析功能。
其中包含的内容非常多,只要您了解业务、数据和模型,理论上已经足够用任何类型的模型处理任何种类的数据。如果打包式的Azure Machine Learning Studio模块无法满足需求,还可以使用Python或R模块自行进行开发。
您可以使用Jupyter Notebook开发和测试Python 2与Python 3语言模块,使用Azure Machine Learning Python客户端库对其进行扩展(以便处理Azure中存储的现有数据),此外还支持 Scikit-learn、Matplotlib,以及NumPy。Azure Jupyter Notebook最终也将支持R。目前可以在本地使用RStudio,随后若有必要可改为使用Azure作为输入和输出位置,或者也可以在Microsoft Data Science虚拟机中安装RStudio。
通过Azure Machine Learning Studio新建实验时,可以完全从零开始,或选择使用Microsoft提供的大约70个样本,其中涵盖了大部分常用模型。此外Cortana Gallery中还提供了社区创建的更多内容。
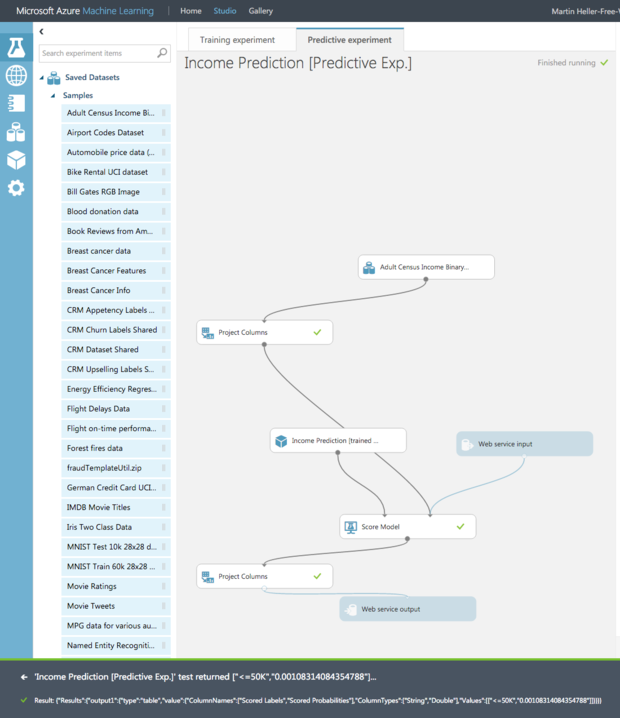
Azure Machine Learning Studio可以快速生成用于发布已训练模型所需的Web服务。在Azure Machine Learning中,只需要简单的五步交互式操作即可创建一个简单的模型。
Cortana Analytics Process(CAP)首先需要完成一些规划和设置操作,除非您是一位训练有素的数据科学家,已经熟悉业务问题、数据和Azure Machine Learning,并且已经为项目创建了必要的CAP环境,否则这一步是非常关键的。可行的CAP环境需要包含一个Azure存储帐户,一个Microsoft Data Science虚拟机,一个HDInsight(Hadoop)群集,以及一个通过Azure Machine Learning Studio创建的机器学习工作空间。如果对繁多的选择感到困惑,Microsoft提供了用于介绍选择每种技术具体原因的文档。CAP依然包含五个处理步骤:数据摄入、探索性数据分析和预处理、功能创建、模型创建,以及模型的部署和使用。
Microsoft最近通过预览版Azure发布了一系列源自牛津计划的认知服务,这些服务已经预先针对语音、文字分析、面部识别、表情检测,以及类似的其他功能进行过训练,通过对您自己的模型进行训练,这些服务可以起到有益的补充作用。
Databricks
Databricks是一种基于Apache Spark的商用云服务,这种开源群集计算框架包含了一个机器学习库,一个群集管理器,一个类似Jupyter的交互式“笔记本”,仪表板,以及作业调度功能。Databricks(公司)是由Spark的创造者建立的,通过Databricks(服务),几乎可以不费吹灰之力组建并扩展Spark群集。
该服务提供的MLlib库以及一系列不同类型的机器学习和统计算法,均针对基于内存的分布式Spark架构进行过优化。MLlib的实施除此之外还提供了概要统计、相关性分析、采样、假设验证测试、分配和回归、协同过滤、聚类分析、维度缩减、特征提取和变换函数,以及优化算法。换句话说,对于有经验的数据科学家来说,这是一套非常完备的一体式解决方案。
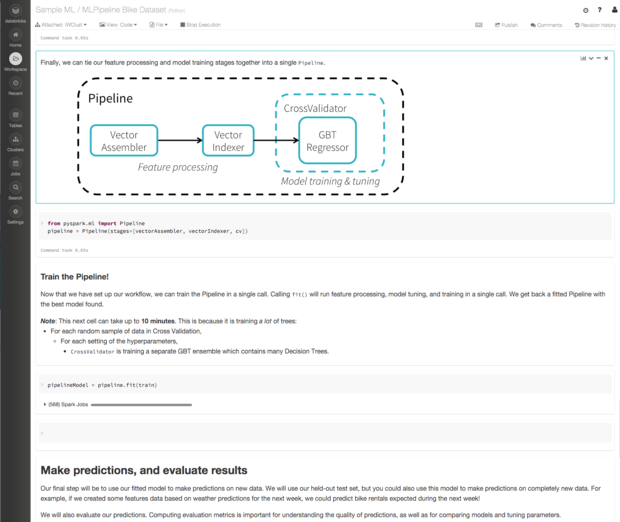
这个正在运行的Databricks笔记本使用Python开发而来,演示了对众所周知的公共自行车租用数据集进行分析的一种方法。在笔记本的这个部分中,正在通过交叉验证的方式运行多个Gradient-Boosted Tree回归,借此对管线进行训练。
Databricks在设计上是一种可扩展,相对较为易用的数据科学平台,适合了解统计学,并且至少可以完成少量编程工作的人。为了更好地使用该技术,您需要对SQL,或Scala、R、Python三种技术中的一种有所了解。如果对打算使用的编程语言非常熟悉,将能获得更好的使用效果,这样便可以将精力专注于学习Spark技术本身,通过Databricks笔记本样本运行免费的Databricks社区版群集掌握这个技术。
Google Cloud Machine Learning
Google最近公布了一系列与机器学习有关的产品。其中最有趣的可能是依然处于有限预览阶段的Cloud Machine Learning和Cloud Speech API。Google Translate API可以针对超过80种语言及其变体进行语言识别和翻译,Cloud Vision API可识别图片中不同类型的特征,目前这两项服务也已可用,从Google的演示来看效果还不错。
Google Prediction API可以训练、评估,并预测回归和分类问题,但目前无法选择所用的算法。该服务的历史可追溯至2013年。
Google目前的机器学习技术Cloud Machine Learning Platform使用Google的开源TensorFlow库进行训练和评估。由Google Brain团队开发的TensorFlow是一种通用库,可使用数据流图谱(Data flow graphs)进行数值计算。这个库能够与Google Cloud Dataflow、Google BigQuery、Google Cloud Dataproc、Google Cloud Storage,以及Google Cloud Datalab实现集成。
通过查看GitHub上的TensorFlow代码库以及访问TensorFlow.org网站并阅读TensorFlow白皮书可以知道,这个库使用了一些C、C++,以及Python代码。用户可以借助TensorFlow将计算功能部署至台式机、服务器,甚至移动设备中方的一个或多个CPU或GPU上,并且包含各种内建的训练和神经网络算法。从极客的角度来说,如果满分是10分,可以给这个技术打出9分的成绩。不仅因为该技术的应用范围已经远远超过业务分析领域,甚至可以被很多数据科学家进行更广泛的运用。
Google Translate API、Cloud Vision API,以及新发布的Google Cloud Speech API都是预先训练过的ML模型。根据Google的介绍,Cloud Speech API与Google应用中的语音搜索功能,以及Google Keyboard中的语音输入功能使用了相同的神经网络技术。
HPE Haven OnDemand
Haven OnDemand是HPE在云机器学习领域的试水之作。Haven OnDemand的企业搜索和格式转换是其中最强大的服务,考虑到这些服务都基于HPE的私有搜索引擎IDOL,这一点也就不足为奇了。只不过Haven OnDemand更有趣的功能目前还没完工。
Haven OnDemand目前提供了用于音频-视频分析、连接器、格式转换、图形分析、HP Labs沙箱(实验性API)、图像分析、策略、预测、概要查询和操控、搜索、文本分析,以及非结构化文本索引等API。我曾随便挑选了几个API来体验这些API是如何调用和使用的。
Haven的语音识别目前只支持6种语言以及相应的变体。使用高质量的美国英语测试文件进行测试的识别准确率尚可,但并不完美。
Haven OnDemand Connectors可用于从外部系统获取信息,并通过Haven OnDemand API更新外部信息,这些技术已经相当成熟,但主要是因为这些实际上就是IDOL连接器。文字提取API可以使用HPE KeyView从您提供的文件中提取元数据和文本内容,该API利用了业已成熟的KeyView,可处理超过500种不同文件格式。
图形分析等一系列预览服务目前只能用于针对英文维基百科进行过训练的索引内容,目前无法使用自己的数据对其进行训练。
图像分析方面,我测试过条码识别,该功能可以正常使用,而面孔识别方面,HPE样本数据的识别效果好于我自己的测试图片效果。图像识别功能目前仅限识别有限的企业徽标,实用性不怎么强。
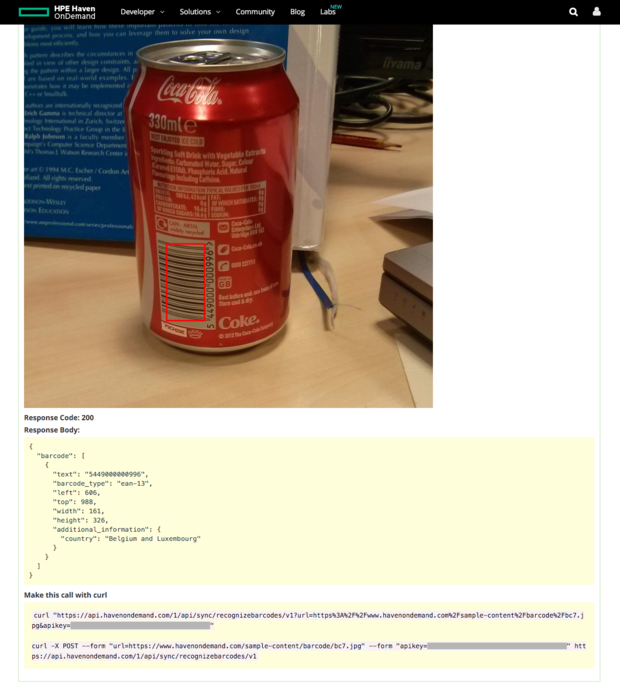
Haven OnDemand条码识别API可以区分出图片中的条码(上图红框)并将其转换为数字,就算条码位于曲面上,以大约20度俯角拍摄,或者图片较为模糊,也能顺利识别。该API并不会执行查询条码对应的数字或识别对应的产品等额外的工作。
最后我很失望地发现,HPE的预测分析只能处理二分类问题,不支持多级分类和回归,当然还无法对学习过程进行引导。这一点严重限制了改技术的适用性。
从好的方面来看,Train Prediction API可以自动验证、探索、分离、筹备CSV或JSON数据,并使用多种参数训练决策树、逻辑回归、朴素贝叶斯,以及支持向量机(Support vector machine,SVM)二分类模型。随后可以通过数据的评价分离(Evaluation split)对分类程序进行测试,并将最佳模型以服务的方式发布出来。
Haven OnDemand Search可使用IDOL引擎针对公共和私有文本索引执行高级搜索。文本分析API的支持范围涵盖从简单的自动补全和术语扩展到语言识别、概念提取,以及情绪分析等方方面面。
IBM Watson和Predictive Analytics
IBM提供的机器学习服务基于曾在电视猜谜节目Jeopardy中获得冠军的Watson技术以及IBM SPSS Modeler。该公司目前已经针对开发者、数据科学家,以及业务用户等不同用户群提供了一系列云机器学习服务。
SPSS Modeler是一款Windows应用程序,最近刚刚作为一种云服务发布。Modeler Personal Edition包含数据访问和导出,自动数据制备、清洗(Wrangling)和ETL,超过30种机器学习算法和自动建模,R扩展能力,以及Python脚本功能。更昂贵的版本可以通过IBM SPSS Analytic Server for Hadoop/Spark访问大数据,并获得冠军/挑战者功能、A/B测试、文本和实体分析,以及社交网络分析功能。
SPSS Modeler中的机器学习算法与Azure Machine Learning和Databricks的Spark.ml所用算法不相上下,特征选择方法和可支持的格式选择方面也在伯仲之间。尽管自动建模(训练、测试一批模型并择优选择)功能也有一定可比性,不过在SPSS Modeler中使用这些功能的方法比其他产品更为直观。
IBM Bluemix托管的Predictive Analytics Web服务可以通过应用SPSS模型暴露评分API,并供用户在自己的应用中调用。除了Web服务,Predictive Analytics还可以支持通过批处理作业使用其他数据对模型进行再次训练和再次评估。
除Predictive Analytics之外,Watson目前提供了18种Bluemix服务。AlchemyAPI提供了一套三种服务(AlchemyLanguage、AlchemyVision,以及AlchemyData),可以帮助企业和开发者围绕文本和图像领域的内容和上下文构建认知应用程序。
Concept Expansion可分析文本并学习同义词,或根据上下文进行解析。Concept Insights可根据维基百科的话题将用户提供的文档链接至预先创建的概念图谱。
Dialog Service可用于设计应用程序通过对话接口,通过自然语言和用户概要信息与用户进行交互的方式。Document Conversion服务可以将单个HTML、PDF,或Microsoft Word文档转换为统一规格的HTML、纯文本,或一系列JSON格式的应答单位(Answer unit),并结合其他Watson服务使用。
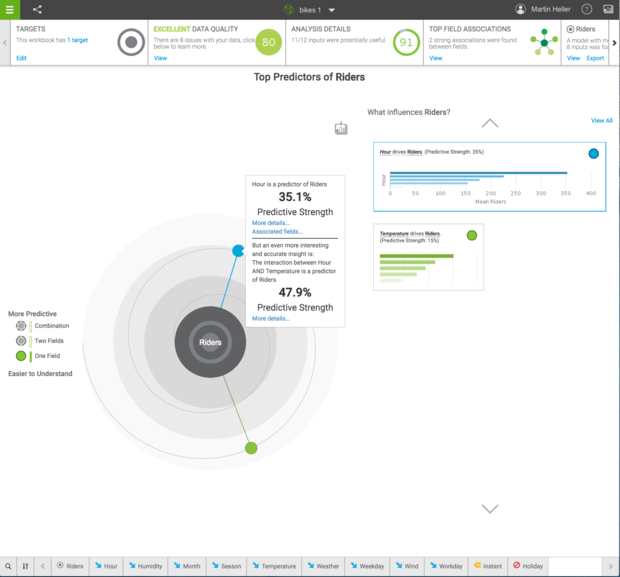
使用Watson分析上文提到过的自行车租用数据集。Watson提供了一个决策树模型,可实现48%的预测强度。这个工作表并不区分工作日和非工作日的租用情况。
Language Translation可支持多个知识领域和语言对。在新闻和对话领域中,可支持英语和巴西葡萄牙语、法语、现代标准阿拉伯语,以及西班牙语之间的互译。在专利领域,可支持英语和巴西葡萄牙语、中文、韩文,以及西班牙语之间的互译。这个翻译服务还可以识别使用62种语言书写的纯文本。
通过使用自己提供的类和短语进行训练后,Natural Language Classifier服务可通过认知计算技术为语句、问题,或短语返回最匹配的类。Personality Insights可从事务型和社交媒体数据(包含一个人所撰写的至少1000个词)中获得洞察力,借此了解此人的心理特质,该服务可返回JSON格式的特征树。Relationship Extraction可将语句解析为组成部分,并通过上下文分析检测出不同部分(的话语内容和作用)之间的关系。
此外还可通过其他Bluemix服务改善搜索结果的相关性,对6种语言进行文本和语音之间的双向转换,识别文本中蕴含的情绪,以及分析可视化的场景和对象。
Watson Analytics使用了IBM自有的自然语言处理技术对机器学习进行简化,使其可以被业务分析师和其他非数据科学家的业务角色所顺利使用。
机器学习曲线
具体需要评估哪些机器学习技术,这取决于您本人与团队成员所具备的技能。对于数据科学家以及包含数据科学家的团队来说,可选的范围相当广泛。善于编程的数据科学家甚至可以获得更多选择:Google、Azure以及Databricks对于编程的需求比Amazon和SPSS Modeler更高,但同时也更灵活。
Bluemix上运行的Watson Services为开发者的云应用程序提供了更多预训练的能力,Azure的多个服务,三个Google cloud API,以及Haven OnDemand的一些API还提供了相关文档。
新发布的Google TensorFlow库适合精通Python、C++或C的高端机器学习程序员。Google Cloud Machine Learning Platform似乎更适合了解Python和云数据管线的高端数据科学家。
虽然Amazon Machine Learning和Watson Analytics宣称目标对象主要是业务分析师或“任何业务角色”(不管这个称呼是什么意思),我依然怀疑这样的说法在很大程度上是真实的。如果需要开发机器学习应用程序,但是只有很少或全无统计学、数学,或者编程方面的知识背景,那么我只能认为您已经准备好召集了解这些知识的人组建团队了。
| InfoWorld 评分 | 模型的多样化(25%) | 开发难易度(25%) | 集成能力(15%) | 性能(15%) | 相关服务(10%) | 价值(10%) | 总分(100%) |
|---|---|---|---|---|---|---|---|
| Amazon Machine Learning | 8 | 9 | 9 | 9 | 8 | 9 | 8.7 |
| Azure Machine Learning | 9 | 8 | 9 | 9 | 8 | 9 | 8.7 |
| Databricks with Spark 1.6 | 10 | 9 | 9 | 9 | 8 | 9 | 9.2 |
| HPE Haven OnDemand | 7 | 8 | 8 | 8 | 7 | 8 | 7.5 |
| IBM Watson和Predictive Analytics | 10 | 9 | 9 | 9 | 9 | 8 | 9.2 |
总结
Amazon Machine Learning / Amazon
数据分析和建模费用:每小时42分;批处理预测:每1000次预测10分,向上舍入到下个1000次;实时预测:每次预测0.01分,向上舍入到最接近的“便士数”,外加使用的每10MB内存每小时0.1分
| 优势 | 劣势 |
|---|---|
| Amazon Machine Learning服务可代替用户完成模型的选择 | 探索式数据分析超出机器学习服务范围 |
| 为模型提供了实时和批处理预测 | 机器学习服务不允许分析师对算法进行修改 |
| 服务可随时随地按需为模型提供相应的图表和诊断 | 无法导入或导出模型 |
| 可处理来自S3、RDS MySQL以及Redshift的训练数据 | - |
| 服务可自动完成某些文本处理任务 | - |
| API可通过Linux、Windows或Mac OS X使用 | - |
Azure Machine Learning / Microsoft
免费的ML Studio开发工具,但存在一些局限,缺乏生产用Web API;标准层ML成本为每月每席位9.99美元,每小时实验时间1美元,生产用API计算每小时2美元,每1000笔生产用API事务0.50美元,存储费用另计。Data Science虚拟机价格范围介于每小时0.02美元到9美元之间,具体取决于所用内存数、CPU、存储、网络,以及SQL Server的版本
| 优势 | 劣势 |
|---|---|
| 丰富的模型,并可通过R或Python编写其他模型 | 挑选适宜的功能以及确定最佳模型需要具备数据科学家的经验 |
| 可使用拖拽式界面轻松设计并训练模型 | 探索式数据分析需要一定的Python或R编程经验 |
| 可对Azure云中的实时数据进行探索式数据分析 | 将R的结果传递至工作流的过程很繁琐 |
| 可免费上手使用 | - |
| 可通过任何网页浏览器访问 | - |
Databricks with Spark 1.6 / Databricks
Spark和Hadoop是免费的。Databricks社区版也是免费的。Databricks根据可用容量,支持的模型以及可提供的功能对服务划分了不同计划。Databricks Starter(3用户)成本为每月99美元,外加每节点每小时40分
| 优势 | 劣势 |
|---|---|
| 不费吹灰之力便可组建并扩展Spark群集 | 不像BI产品那么易用,不过可与多种BI产品集成 |
| 为数据科学家提供了种类丰富的ML方法 | 假定用户已经熟悉编程、统计,以及ML方法 |
| 使用R、Python或Scala和SQL提供了协作式笔记本界面 | - |
| 免费上手,使用价格低廉 | - |
| 可为生产环境轻松安排作业调度 | - |
Haven OnDemand / Hewlett Packard Enterprise
Free版:1个资源单位(RU),每月10K个API单位;Explorer版:1个RU,20K个API单位,每月10美元;Innovator版:10个RU,50K个API单位,每月85美元;Entrepreneur版:35个RU,120K个API单位,每月315美元
| 优势 | 劣势 |
|---|---|
| 强大的文档格式转换功能 | 一些服务尚未完工 |
| 强大的企业搜索功能 | 一些服务由于存在局限而导致实用性受限 |
| 价格合理 | - |
IBM Watson和Predictive Analytics / IBM
Bluemix Predictive Analytics:Free计划(2个模型);付费的服务实例(每实例20个模型)每月10美元,外加每1000次实时预测0.50美元,每1000次批处理预测0.50美元,以及分析和建模所用计算时间每小时0.45美元。Windows版IBM SPSS Modeler:每用户每年4350-11300美元。Watson Analytics:免费(500MB存储);付费版每月每用户30美元(2GB存储)起
| 优势 | 劣势 |
|---|---|
| SPSS Modeler通过即点即用式应用程序提供了丰富的模型 | SPSS Modeler按目前标准来说很贵 |
| Bluemix Predictive Analytics Web服务价格合理功能完善 | Bluemix Predictive Analytics Web服务需要具备SPSS模型 |
| Watson Bluemix服务以合理价格为开发者提供了良好的功能 | IBM Watson Analytics的易用性依然有待改善 |
| IBM Watson Analytics可使用自然语言建模,适合相对没有接受过太多培训的人 | - |
作者:Martin Heller。
阅读英文原文:Review: 6 machine learning clouds
