@liuhui0803
2017-04-26T11:46:16.000000Z
字数 2968
阅读 2559
数据伸缩性和可用性的实现之路
云计算 数据中心 运维
摘要:
本文介绍了通过具备自服务伸缩能力的分布式系统实现伸缩性,通过物理部署、严格的运维规程、弹性应用程序实现可用性,打造可伸缩、高可用数据存储的方法。
正文:
今天的Web世界规模还在爆发式增长着,尤其是社交网络和电子商务应用的用户数与日俱增,这也意味着我们需要处理的数据总量水涨船高。Web已经如此普遍,每个人都在用,上至二十世纪九十年代的科学家在使用Web交换科研文档,下至五六岁的孩童通过表情符号讨论猫咪。这就不得不提伸缩性。伸缩性是指洗痛、网络,或进程通过增大自身规模适应数据量增长趋势的潜力。Web拉近了人与人之间的距离,也意味着不会在遇到“停机”这样的问题。业务全天候运营,身处不同时区的买家在不断地买买买,这也对数据存储的可用性提出了更高要求。本文概括介绍了为数据提供实现伸缩性和可用性所需要采取的方法。
本文将介绍如何通过下列方法为应用程序提供可伸缩、高可用的数据存储。
- 伸缩性:具备自服务伸缩能力的分布式系统
- 数据容量分析
- 检查数据访问模式
- 不同的数据切片(Sharding)技术
- 自服务伸缩能力
- 可用性:物理部署、严格的运维规程、弹性应用程序
伸缩性
随着Web技术的发展,尤其是Web 2.0网站的涌现,造成了数百万用户同时读写数据的情况,这种情况下,就算简单的数据库操作也不得不考虑伸缩性的问题。系统的伸缩有两种方式:垂直伸缩和水平伸缩。本文主要侧重于水平伸缩,这种方式会同时将数据以及简单的操作所产生的负载分摊/切分至多台服务器,并且这些服务器不共享内存、CPU和磁盘。虽然某些实现中磁盘和存储是共享的,但这种情况下的自动伸缩会遇到一定的挑战。

在构建可伸缩的数据存储时,须考虑以强制的方式实施下列措施。
数据容量分析:首先必须清楚地理解应用程序在峰值极端情况下,以及平均每秒事务数、峰值查询数、数据载荷大小、预期吞吐量、备份等需求。这样在设计数据存储的伸缩能力时即可确定需要多少台物理服务器,数据存储在内存大小、磁盘容量、CPU内核数、I/O吞吐量,以及其他资源方面对硬件配置的需求。
检查数据访问模式:对应用程序进行伸缩的最简单方法是首先了解应用的访问模式。考虑到分布式系统的本质,对数据存储的所有实时查询必须具备访问键(Key),这是为了避免跨越不同服务器进行操作可能产生的分散(Scatter)和聚集(Gather)问题。在分布式数据存储的每个切片(Shard)中,数据必须与访问键保持对齐。很多应用程序可能会使用多个访问键。例如在电商应用中,可能需要按照产品ID或用户ID获取数据,此时可以考虑以冗余的方式将数据与两个键分别对齐并存储,或将数据与参考键对齐并存储,具体方法取决于应用程序的需求。
不同的数据切片技术:我们可以通过多种方式将数据切片并存储在分布式存储系统中。基于函数的切片(Function-based sharding)和基于查询的切片(Lookup-based sharding)是最常用的两种机制。基于函数的切片是指对键应用确定性函数,进而获得切片值的切片方式。这种方式中,分布式数据存储中所存储的每个项都具备切片键,这样可以实现更高效的检索。此外,如果切片键不是随机的,可能导致系统中产生热点(Hot spot)。基于查询的切片是指使用查询表存储键的开始和结束范围的方法。客户端可以通过缓存该查询表避免单点故障。很多NoSQL数据库会通过此类方式实现缩放性。
自服务伸缩能力:自服务伸缩,即自动伸缩,犹如可伸缩系统“皇冠上的一颗宝石”。数据存储在设计和架构方面必须能预先为伸缩提供足够的容量,但快速回弹能力和云服务可以实现名副其实的垂直和水平伸缩。自服务垂直伸缩可以为现有节点提供更多资源,借此增加节点容量;自服务水平伸缩则可以通过“扩大”或“缩小”功能增加或减少分布式数据存储系统中的节点数量。
可用性
处理读写操作的数据存储必须高可用。可用性是指系统或组件持续运作所需的足够长时间的能力。下图列出了在架构模式、物理部署、严格的运维规程方面保障可用性,打造高可用数据存储的方法。
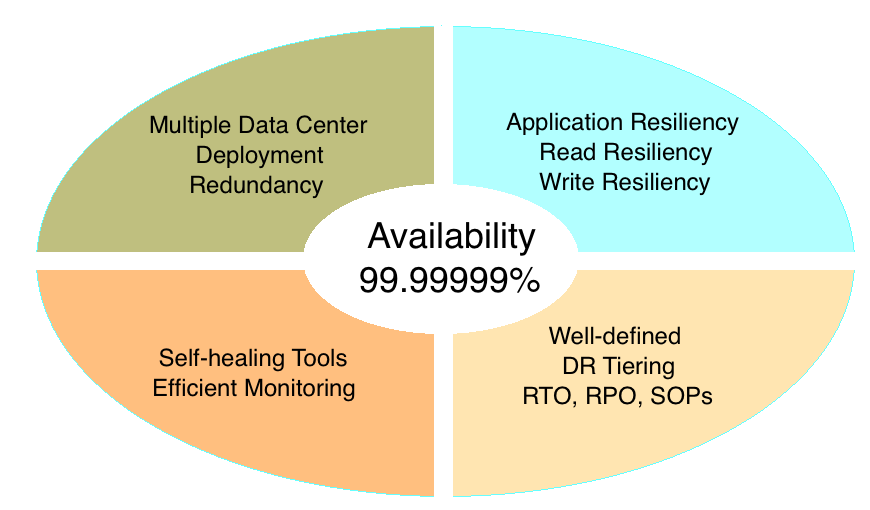
多数据中心部署:分布式数据存储必须部署在不同数据中心内,并具备灾难恢复所需的冗余副本。为避免跨界点访问产生较高网络延迟,数据中心的地理位置必须慎重选择。理想的方式是将主要节点均匀地部署在多个数据中心中,并在每个数据中心设置本地和远程副本。分布式数据存储固有的特性可将停机的范围减小“切片数量”倍。此外如果整个数据中心彻底故障,跨越多个数据中心均匀分布的节点可以保证仅1/n的数据不可用。
自愈工具:必须通过高效的监视和自愈工具监视分布式数据存储系统中节点的运行状况。如遇故障,这些工具不仅可用于监视,而且可以帮助我们恢复故障的组件,或通过某种机制帮助我们将最新副本“升级”为主副本。这种自愈机制必须结合每个应用程序的具体需求慎重选择,一些执行写入密集型操作的应用程序无法处理数据不一致问题,此时自愈工具只能用于监视,并在需要恢复时按需向应用程序发出通知。
妥善定义的DR分层、RTO、RPO,和SOP:严格的运维规程可以催生极高的可用性指标(系统持续运行时间的预期值与正常运行时间与停机时间预期值总和的比值)。对于任何大型企业,必须妥善定义灾难恢复层,并为不同层定义相关的预期停机时间。如果要对可用性的下降情况进行预测,必须在模拟的生产环境中妥善测试恢复时间目标(Recovery Time Objective,RTO)和恢复点目标(Recovery Point Objective,RPO)。以往的很多危机证明,全面的SOP将会成为我们的救世主,尤其是在大型企业中,运维可通过SOP尽可能早地恢复系统。
应用程序弹性数据存储:硬件可以故障,但系统必须能继续正常运行。应用程序弹性是指应用程序对某一组件的问题做出响应并继续尽可能正常提供服务的能力。应用程序可以通过多种方式实现为数据库读写操作实现高可用性,但应用程序面向读取操作获得的弹性使得应用程序能够在主要节点失败后从副本读取数据。弹性也可以成为分布式数据存储系统的功能之一,例如很多NoSQL数据库已经这样做了。如果新插入的数据与原有数据无任何关联,此时可采用轮转(Round-robin)插入的方法,即主节点不可用的情况下,新插入的数据可写入其他节点。相反,如果新插入的数据与原有数据有紧密的关联,该采取怎样的方法将主要取决于应用程序对一致性的需求。
主要结论在于,为了构建可伸缩、高可用的数据存储,我们必须采用系统化的方式实现上文提到的不同方法。这些方法是必须使用,并且非常广泛的,但并不一定彻底,我们也可以根据需要使用其他方法。如果以业务增长和24/7运营为目标,并且已经实现了妥善的缩放性和高可用措施,那么将会有一片广阔的天空等待我们翱翔。
参考
图片来源:freeimageslive.co.uk – freebie.photography
作者:Mansi Narula,阅读英文原文:An Approach to Achieve Scalability and Availability of Data Stores
