@liuhui0803
2019-09-17T02:00:20.000000Z
字数 6530
阅读 2178
为你的Azure数据科学项目融入安全保护
Azure AzureDatabricks DevOps 数据科学 安全性
1. 简介
很多公司在想方设法将自己的数据科学项目投入实用。在上一篇博客文章中,我们讨论了如何为数据科学项目配置构建/发布管道,借此即可:1) 以端到端的方式跟踪模型,2) 在模型中构建信任,进而3) 避免出现导致模型预测结果变得不可理解的情况。
在每个构建/发布管道中,安全性都至关重要。常见的安全问题包括:
- 数据和终结点的身份验证和授权
- 数据和终结点的网络隔离
- 密钥在保管库中的安全存储以及密钥的轮换过程
2. 目标
本文我们将为一个用于预测某人收入类型的机器学习模型创建构建/发布管道。为此将使用Azure Databricks创建模型,并将其以HTTPS终结点的形式部署到Web App中。该构建/发布管道融入了如下安全机制:
- 数据存储在第2代Azure存储中,并使用服务终结点连接至一个VNET
- 密钥存储在Azure密钥保管库(Key Vault)中,密钥的轮换包含在构建过程中
- 使用Azure Active Directory对Web App进行身份验证
- (可选)Web App被创建在一个App Service Environment(ASE)VNET中
整个环境可以通过下列架构概述图来体现:
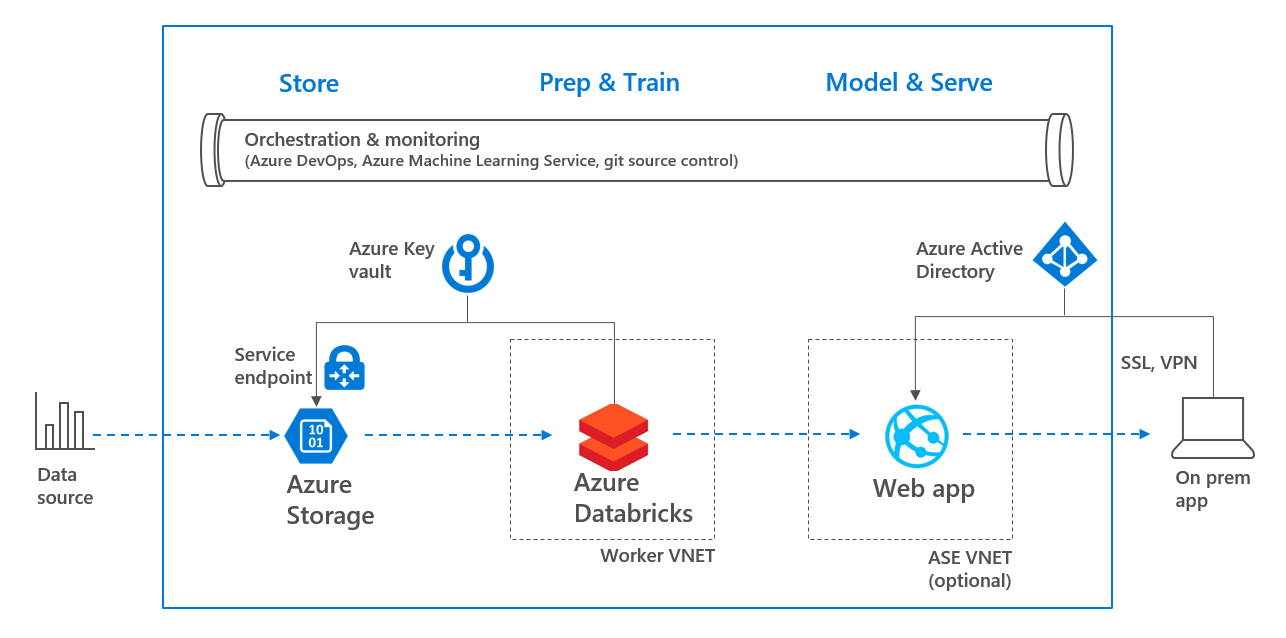
架构概述
下文将执行下列操作:
- 前提要求
- 创建机器学习模型
- 在Azure DevOps中构建模型
- 在Azure DevOps中发布模型
- 结论
不过具体操作和本文的主题关系不大,本文主要侧重于安全性,而非机器学习模型的创建。如果你更关心机器学习方面的内容,建议阅读上一篇博客文章,或参阅这里使用Scikit-learn。
3. 前提要求
首先需要在同一个位置的同一个资源组中创建如下资源。
- Azure CLI
- Azure密钥保管库
- Azure Data Lake存储账户,第2代
- Azure Databricks工作区。如果需要为存储账户设置防火墙规则(参阅步骤4d),需要将Databricks部署到自己的VNET中,请参阅这里
- Azure Machine Learning Service
- Azure DevOps
4. 创建机器学习模型
本步骤需要执行如下操作,并且会尽可能使用Azure CLI来执行。
- 4a. 将存储密钥加入密钥保管库
- 4b. 在Azure Databricks中创建机密范围(Secret scope)
- 4c. 将数据加入存储账户
- 4d. (可选)存储账户的网络隔离
- 4e. 在Azure Databricks中运行Notebook
4a. 将存储密钥加入密钥保管库
在本步骤中,我们将使用Azure CLI将存储账户所用密钥加入密钥保管库。请按照如下方式复制密钥:
az loginaz storage account keys list -g <<resource group>> -n <<stor name>>
随后使用下列代码将存储账户的名称和存储账户密钥添加至Azure密钥保管库。请确保登录Azure CLI的用户有足够权限在密钥保管库中创建/列出/获取密钥。
az keyvault secret set -n stor-key --vault-name <<vault name>> --value <<stor key>>
4b. 在Azure Databricks中创建机密范围
在Databricks中创建一个由Azure密钥保管库支撑的机密范围。这样即可在密钥保管库中存储机密,而无需将密钥存储在Notebook中。请将该机密范围的名称设置为:devaisec。
详见:Secret Scopes – Databricks文档
4c. 将数据加入存储账户
从https://amldockerdatasets.azureedge.net/AdultCensusIncome.csv将数据文件下载到计算机,随后按照如下方法将其加入存储容器:
az storage container create -n dbrdata --account-name <<stor name>>az storage blob upload -f <<...\AdultCensusIncome.csv>>-c dbrdata -n AdultCensusIncome.csv --account-name <<stor name>>
4d. (可选)存储账户的网络隔离
只有在将Databricks工作区部署到自己的VNET时才需要执行这一步操作,详见这里。打开存储账户,选择防火墙,随后添加部署了Databricks工作区的VNET即可。
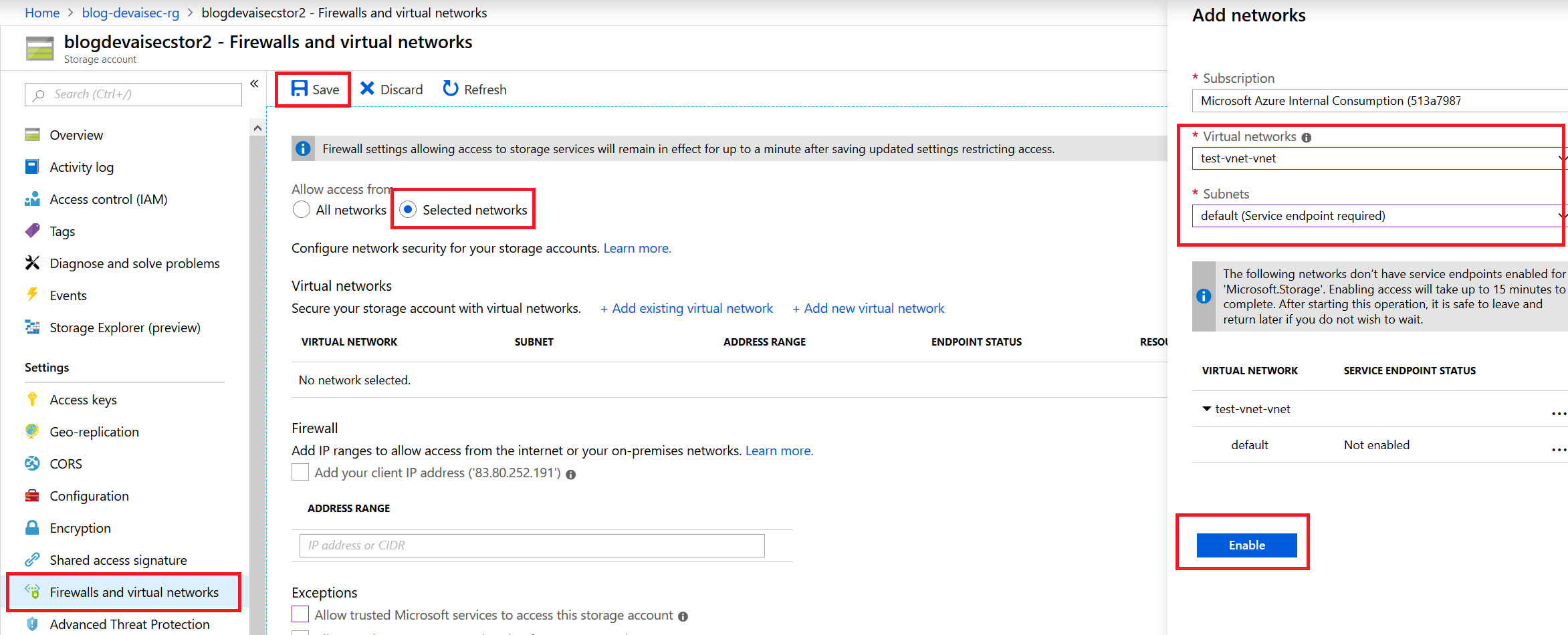
为存储账户添加VNET
请务必同时将Databricks VNET的专用和公用子网加入存储账户的防火墙。
4e. 在Azure Databricks中运行Notebook
打开Azure Databricks工作区,右键点击并选择导入。在随后出现的单选按钮中选择使用URL导入下列Notebook:
https://raw.githubusercontent.com/rebremer/devopsai_databricks/master/project/modelling/1_incomeNotebookExploration_sec.py
将下列变量替换为自己的变量值:
storageAccountName = "<<stor name>>" # 参阅步骤3azureKevVaultstor2Key = "stor-key" # 参阅步骤4asecretScope = "devaisec" # 参阅步骤4bstorageContainer = "dbrdata" # 参阅步骤4cfileName = "AdultCensusIncome.csv" # 参阅步骤4c
另外还需要运行一个供Notebook连接的集群。该集群可以使用默认设置创建,随后就可以运行Notebook创建机器学习模型。
5. 在Azure DevOps中构建模型
Azure DevOps可用于持续构建、测试并部署代码到任何平台和云。为此需要:
- 5a. 在Databricks中创建令牌
- 5b. 创建Azure DevOps项目并添加代码库
- 5c. 创建服务连接
- 5d. 为项目添加机密变量
- 5e. 为项目添加其他变量
- 5f. 创建并构建管道
5a. 在Databricks中创建个人访问令牌
以编程的方式访问Azure Databricks必需具备令牌。请打开Azure Databricks并点击右上角的人像图标。选择用户设置,随后生成新令牌。
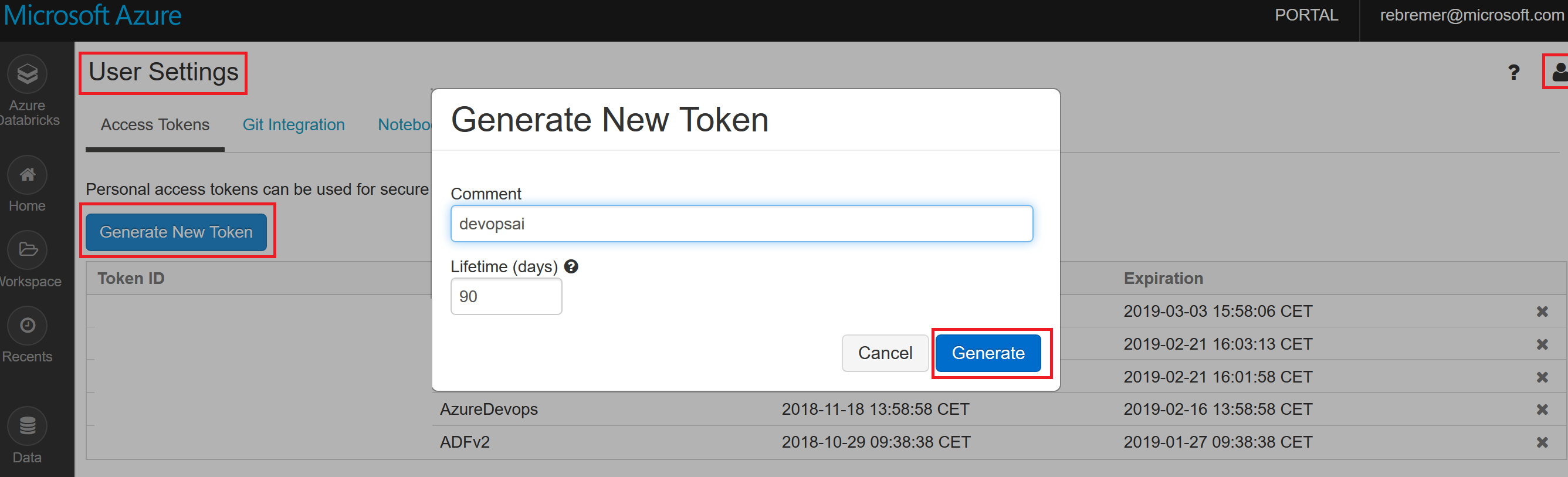
生成Databricks访问令牌
随后将该密钥加入Azure密钥保管库:
az keyvault secret set -n dbr-token --vault-name <<vault name>> --value <<token_id>>az keyvault secret set -n dbr-key --vault-name <<vault name>> --value <<key value>>
此外也可以将你的subscription_id值加入密钥保管库。
az keyvault secret set -n subscription-id--vault-name <<vault name>> --value <<subscription_id>>
个人访问令牌将在构建管道中进行轮换。
5b. 创建Azure DevOps项目并添加代码库
按照这里的介绍新建一个Azure DevOps项目。新建项目后,点击代码库文件夹,并选择导入下列代码库:
https://github.com/rebremer/devopsai_databricks.git
5c. 创建服务连接
从VSTS访问资源组中的资源,这需要具备服务连接。请打开项目设置-服务连接,随后选择Azure Resource Manager。
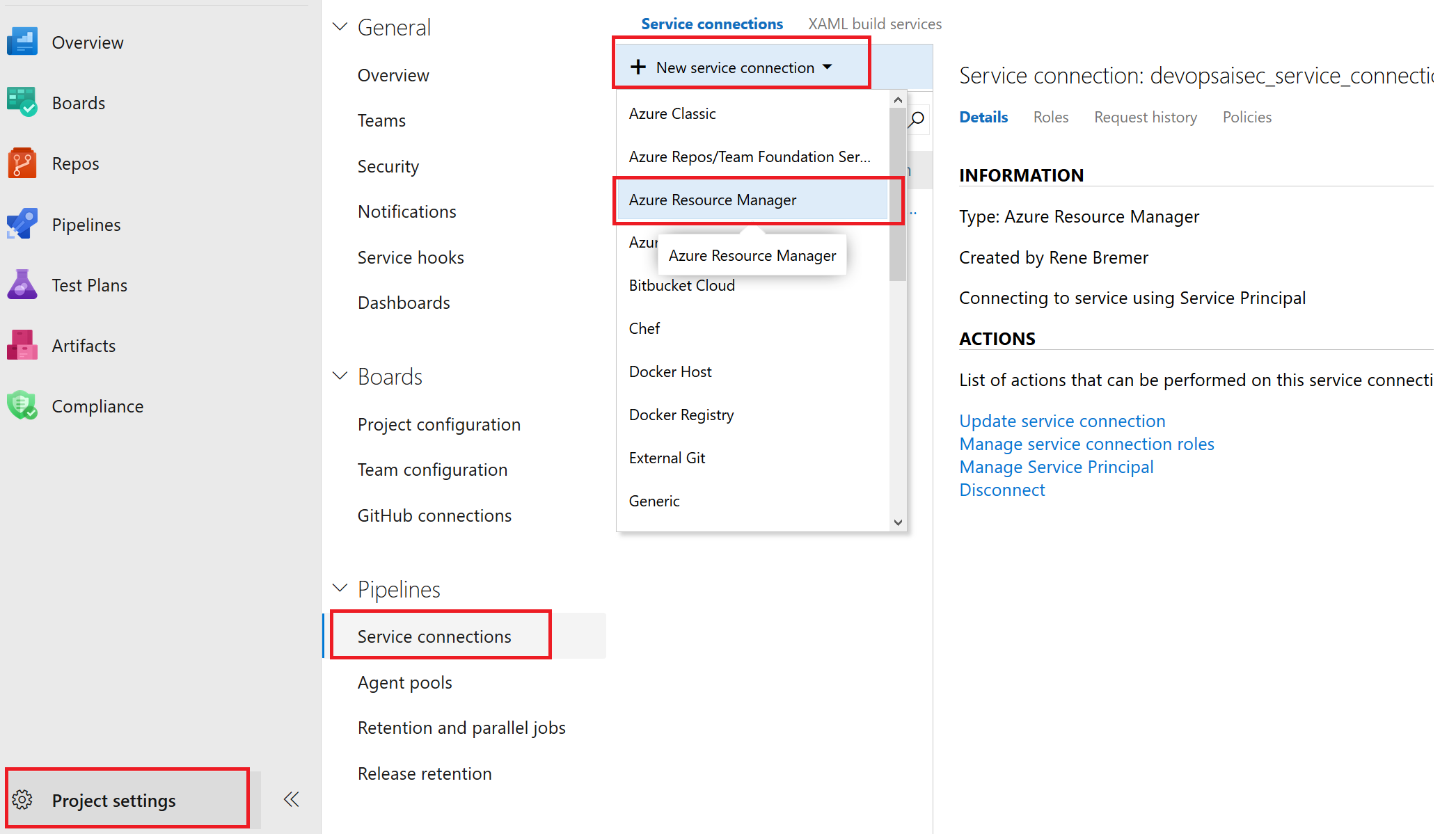
打开服务连接界面
选择服务主体身份验证(Service Principal Authentication)并将范围限制在资源组范围内。将该连接的名称设置为devopsaisec_service_connection。
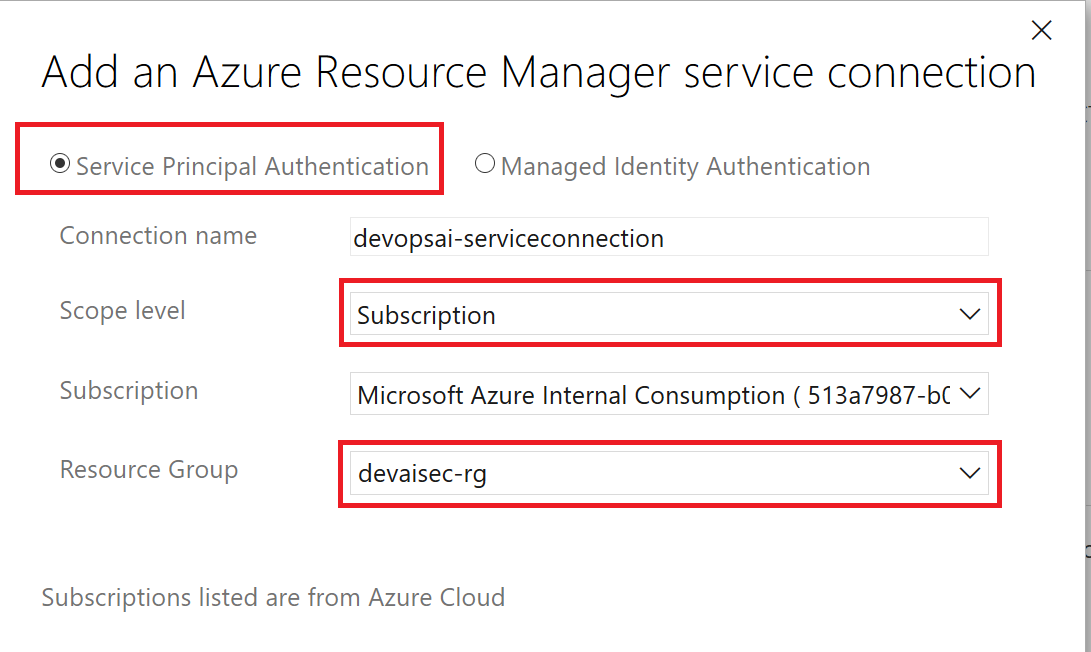
创建Azure Resource Manager服务连接
若要配置从Azure DevOps管道进行密钥轮换,服务主体需要针对Azure密钥保管库具备Set权限。因此请点击服务连接并选择“更新服务连接”以查看该服务连接的应用程序ID,随后点击“使用完整版本的服务连接对话框”链接。
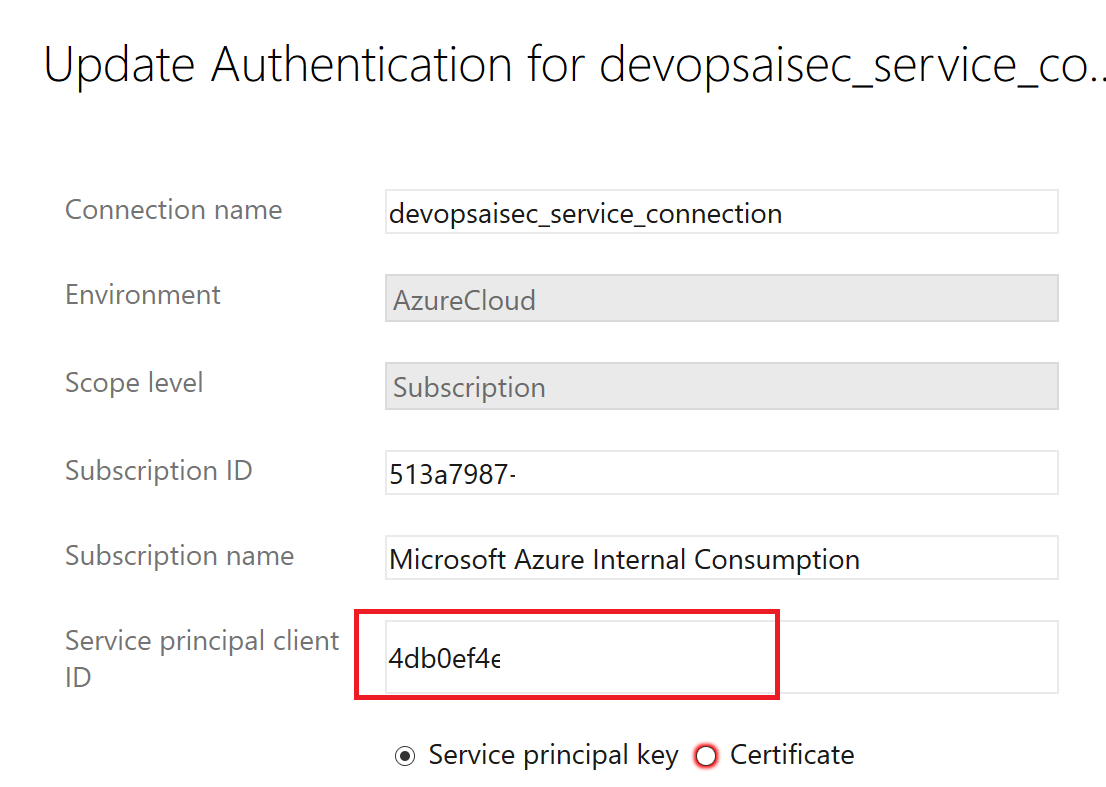
服务连接的应用程序ID
最后,需要在密钥保管库中为服务主体设置Set机密所需的权限(服务连接已经具备Get和List权限)。
az keyvault set-policy --name <<vault name>>--resource-group <<resource group>>--secret-permissions get list set--spn <<application id>>
5d. 为项目添加机密变量
在步骤4a中,存储密钥已添加至Azure密钥保管库。随后在步骤5a添加了Databricks访问令牌和subscription_id。
Azure DevOps项目需要这些机密。因此请点击库并选择将Azure密钥保管库中的机密链接至项目。选中步骤5b创建的服务连接以及存储了机密的密钥保管库,随后点击“授权”。
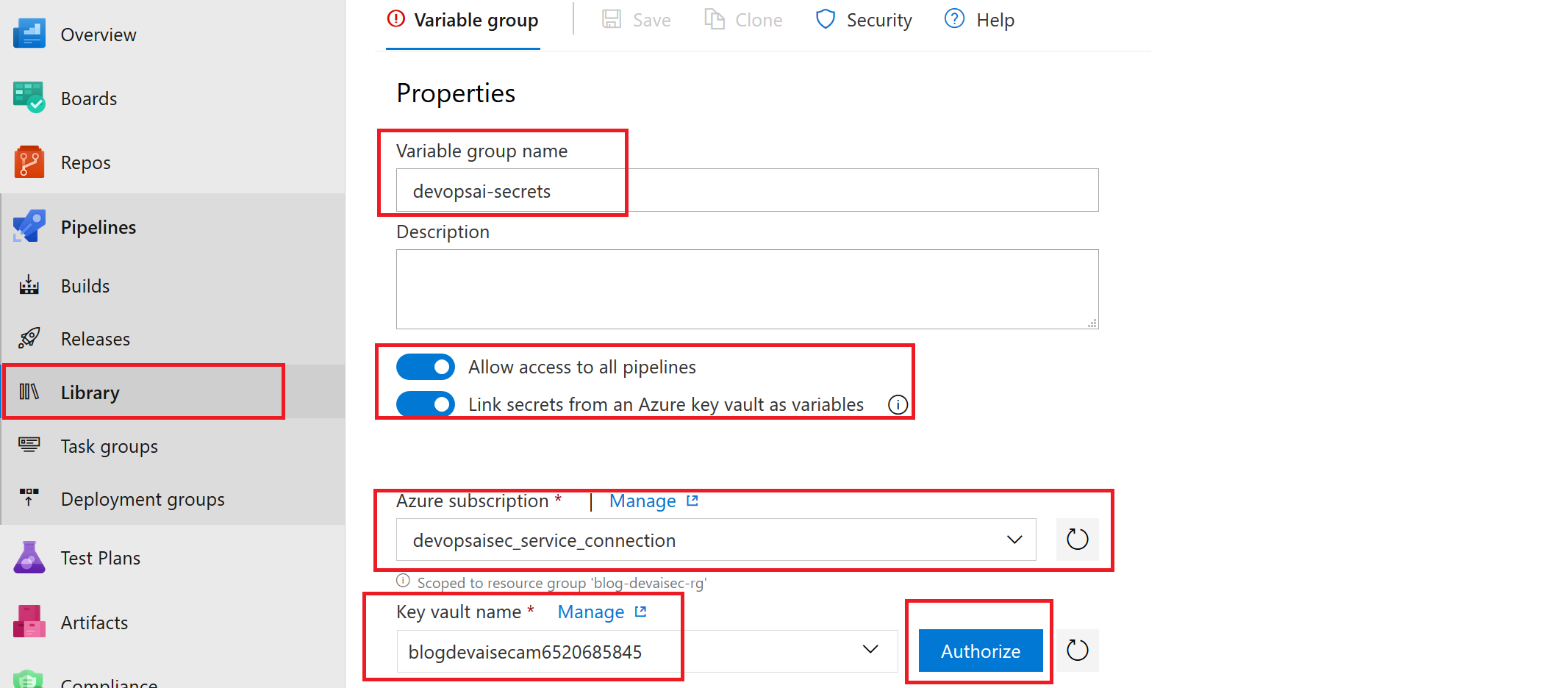
为密钥保管库授权
最后将机密变量“dbr-key”、“dbr-token”和“subscription-id”添加到项目并点击保存。
5e. 为项目添加其他变量
除了机密变量,Azure DevOps项目的正常运行还需要其他配置。因此请打开库,允许访问所有管道,并以组的方式添加如下变量以及相应的值:
amls-name <<azure ml_service name>>dbr-secretscope devaisec <<see step_4b>>dbr-url <<dbr_url, <<your region>>.azuredatabricks.net>>rg-name <<resource group>>stor-container dbrdata <<see step_4c>>stor-name <<store name>>keyvault-name <<vault name>>
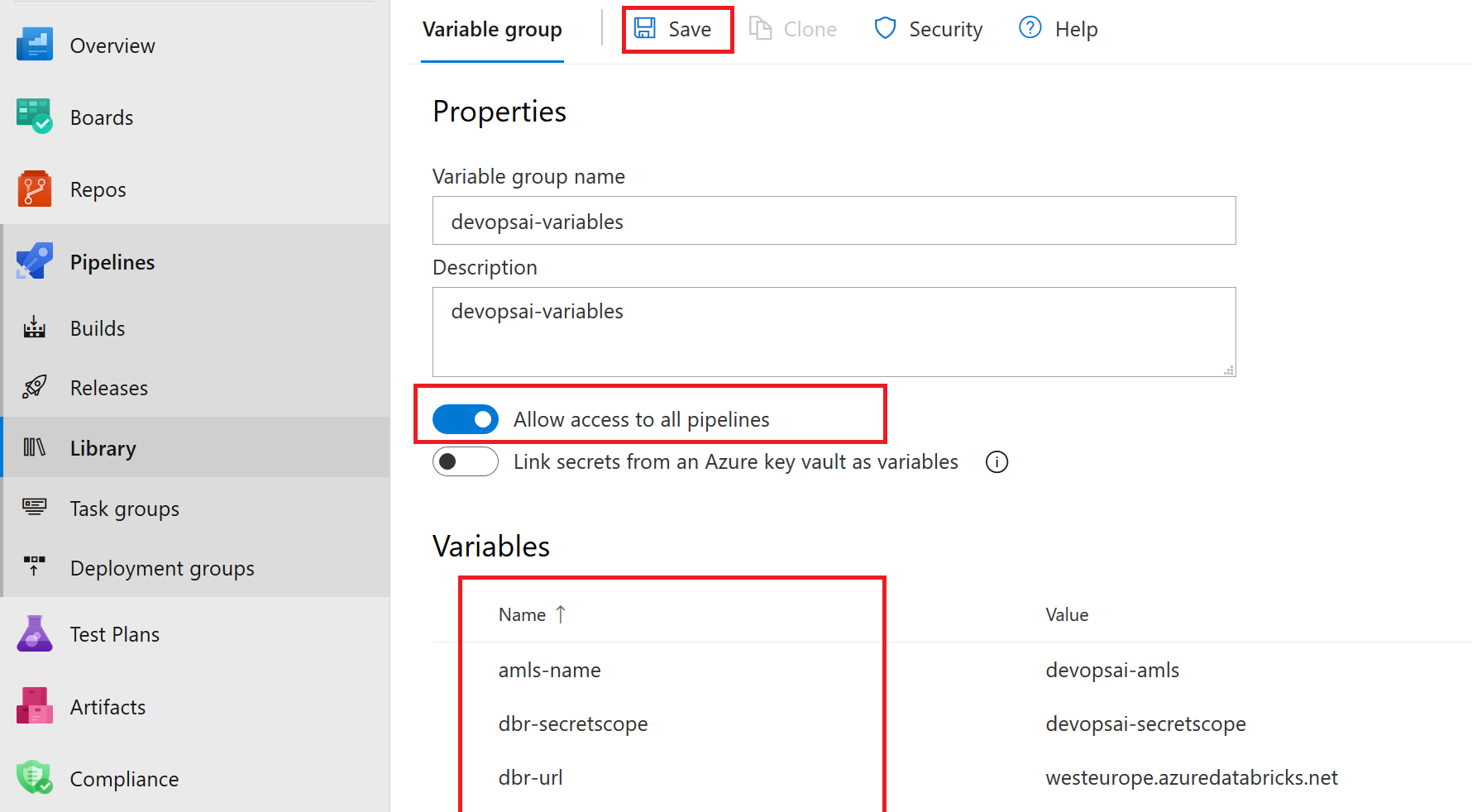
创建要在项目中使用的机密变量组
5f. 创建并构建管道
这一步将创建构建管道。点击“管道”,选择“新建”,随后选择“新建构建管道”。保留默认设置并点击“继续”。在随后出现的界面中,选择“配置即代码”然后点击“应用”。
为Agent Pool选择“hosted Ubuntu 1604”并选择文件路径为:project/configcode_build_sec.yml。随后点击保存,应该能看到下图所示的界面。
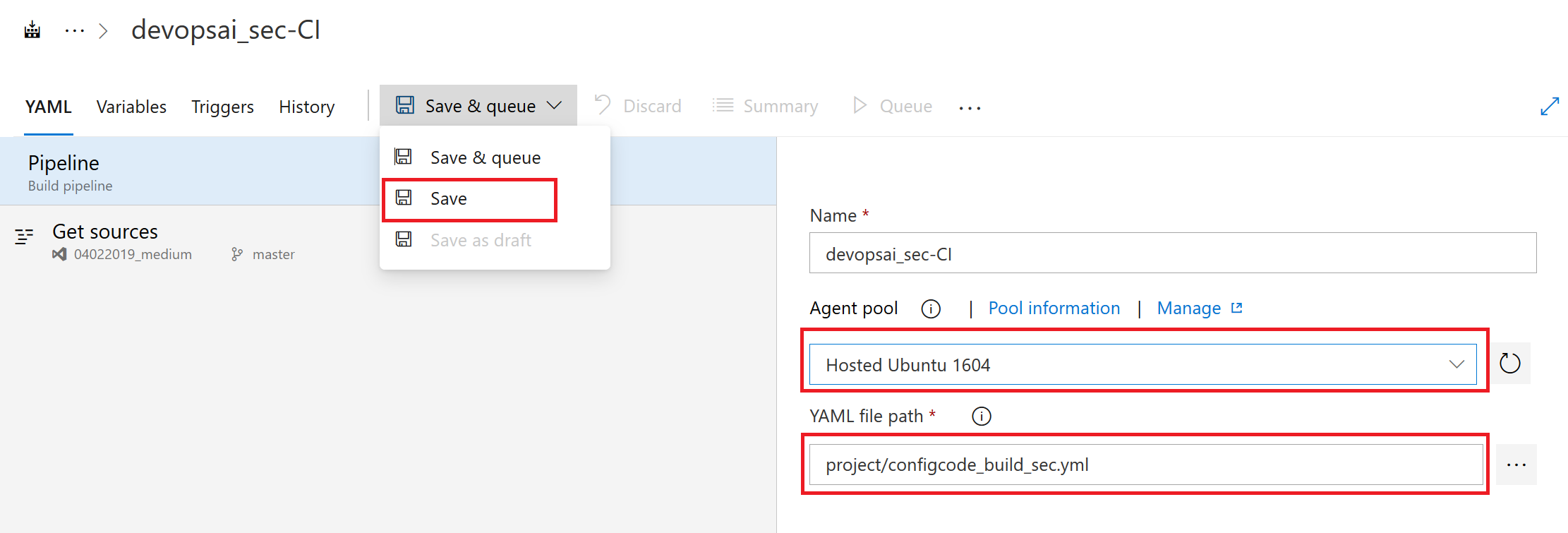
配置即代码
最后链接之前创建的机密变量组。为此请点击变量组,将步骤5d创建的机密变量组,以及步骤5e创建的其他变量组链接起来,最后点击“保存并排队”开始构建。
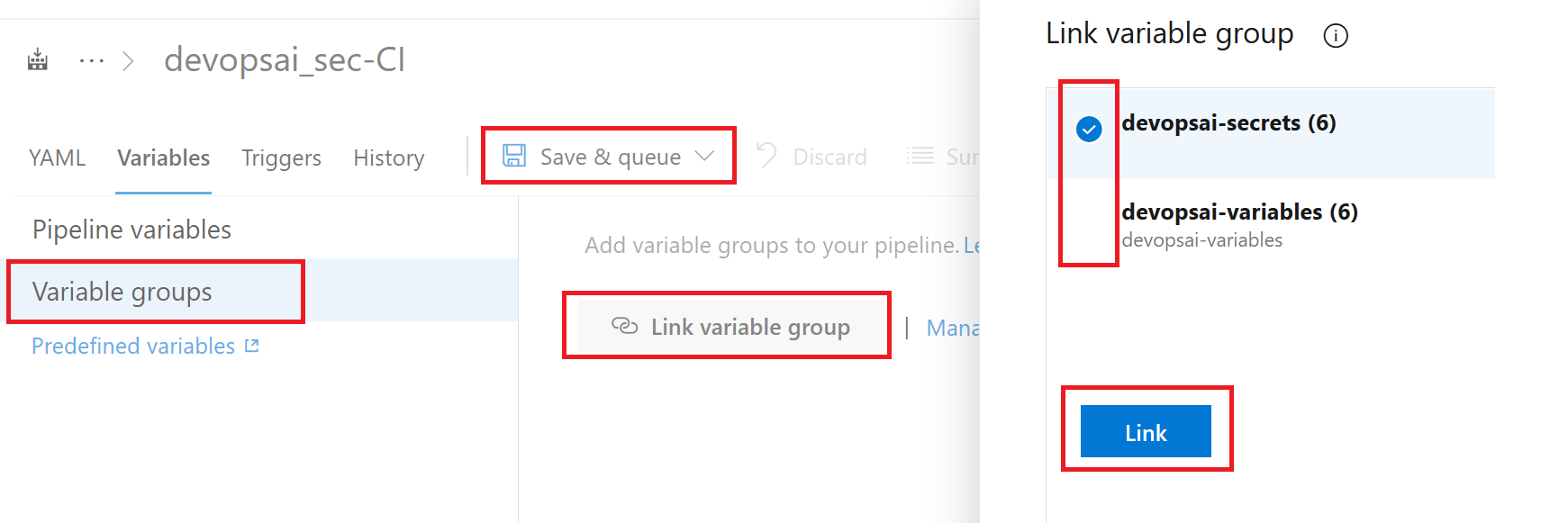
将变量组链接到构建管道并开始构建
成功运行后,即可看到该构建的首次运行和最后运行结果。

构建成功
在这个构建管道中,将执行下列步骤:
- 使用Azure Databricks运行Notebook以创建模型
- 从模型创建要在发布步骤中部署的Docker镜像
- 为了尽可能降低风险,对Databricks令牌执行密钥轮换
- 所创建的构建工件将用作发布管道的输入内容
6. 在Azure DevOps中发布模型
记下来需要创建发布管道。借此即可将机器学习模型作为容器部署到Web应用。
- 6a. (可选)创建App Service Environment
- 6b. 创建Web应用和应用服务计划
- 6c. 创建发布管道
- 6d. 将容器部署到Web应用
- 6e. 在Web应用中启用Azure Active Directory身份验证
- 6f. 在Postman中设置Web应用的身份验证
6a. (可选)创建App Service Environment
为了让Web应用获得完整的网络隔离,这需要使用App Service Environment。所有Web应用和应用服务计划均可部署在同一个App Service Env中。
详见:使用App Service Environment创建内部负载均衡器 - Azure
请注意,App Service Environment的成本可能较高。下文的操作也可以通过未部署在专用ASE中的Web应用实现,不过此时Web应用将获得公共IP。
6b. 使用Azure CLI创建Web应用
执行下列命令在Linux中创建Azure Web:
az appservice plan create -g <<resource group>> -n devaisec-plan --is-linux --sku S1az webapp create -n devaisec-app -g <<resource group>>-p devaisec-plan -i elnably/dockerimagetest
6c. 创建发布管道
本步会将容器部署到Web应用。请打开“管道”,选择“发布”,随后选择“空作业”模板。更改名称并点击保存。

创建发布管道
添加要通过该管道发布的工件。本例中可以选择通过构建管道创建的工件。请务必始终选择默认版本:Latest。
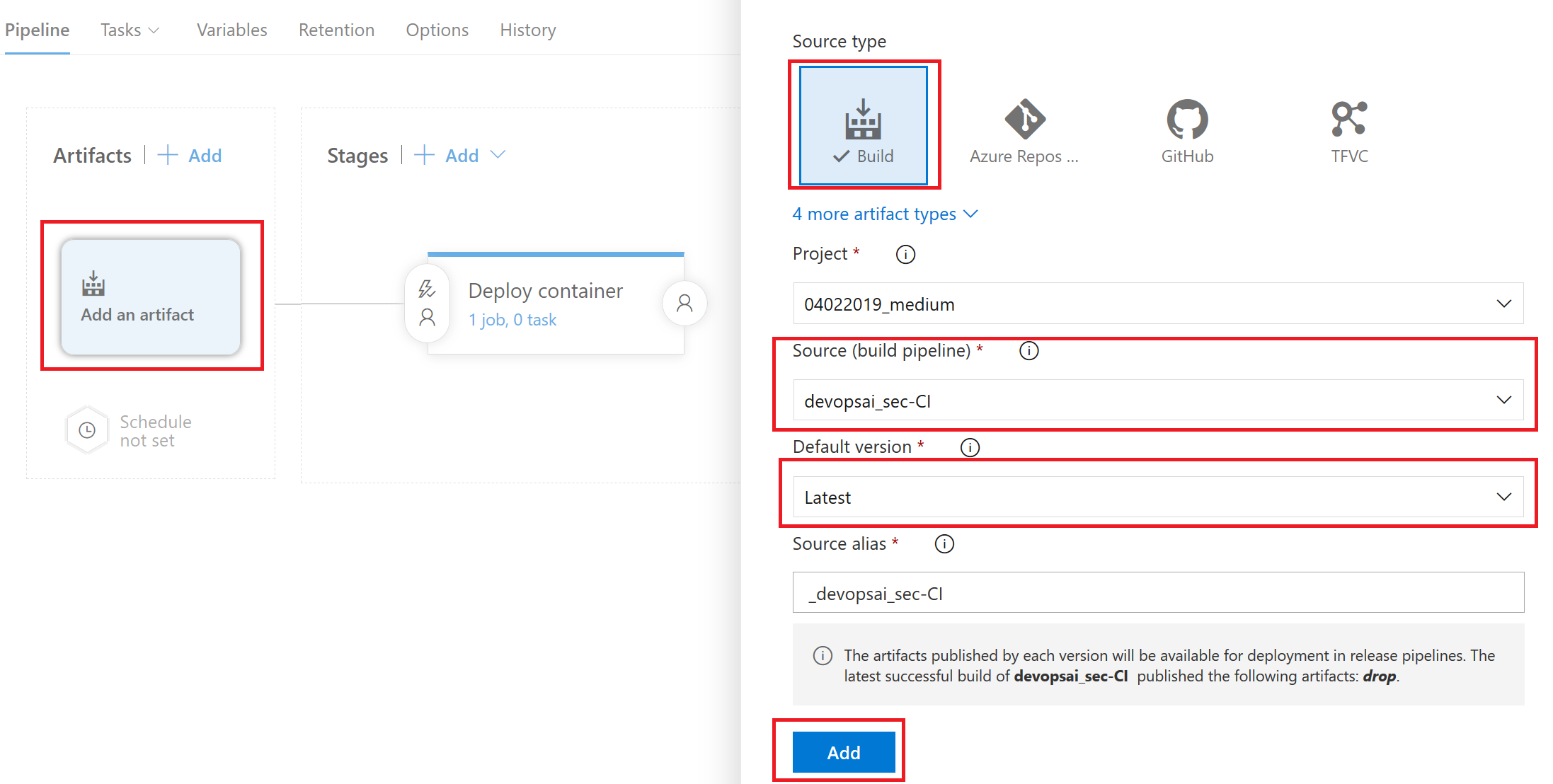
添加发布工件
最后将两个变量组(在步骤5c和步骤5d中创建)添加到发布管道。打开发布管道中的变量,并链接这两个组,具体操作与构建管道中的做法类似。
6d. 将容器部署到Web应用
打开发布管道并选择添加任务。随后将看到代理作业(Agent job)界面。此处也需要将Agent Pool改为Hosted Ubuntu 1604。
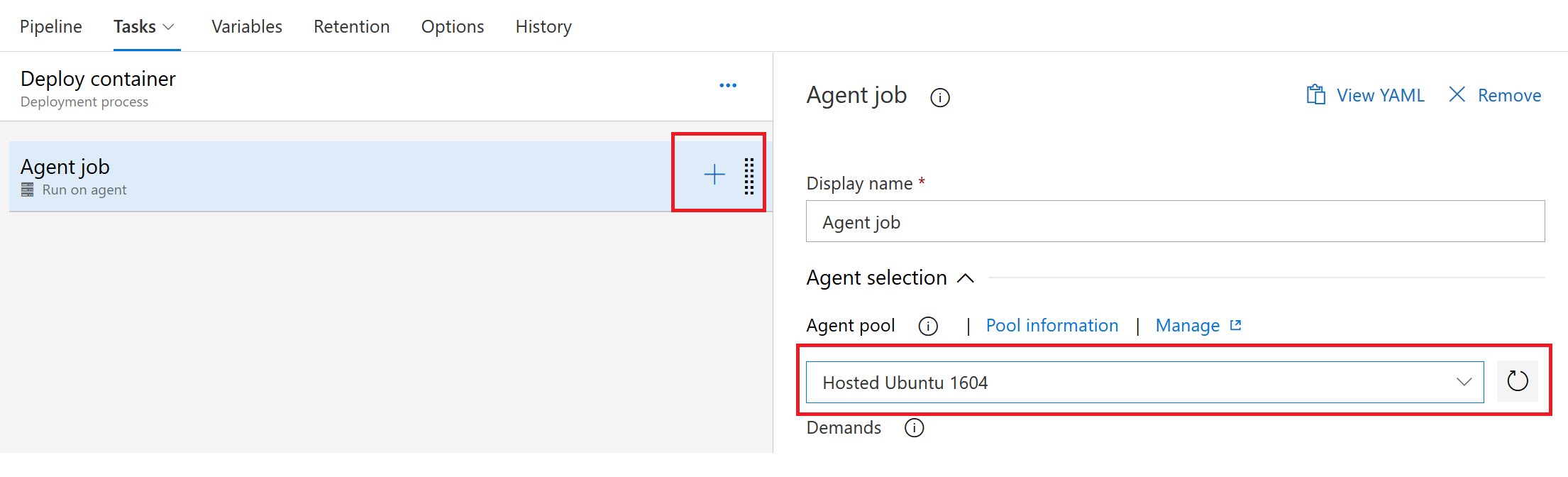
Agent pool Ubuntu 1604
随后通过搜索Azure CLI添加一个新任务。选择devopsaisec_service_connection作为服务连接,并引用“41_deployImageToWebapp_sec.sh”作为脚本路径。随后通过引用变量$(rg-name)的方式使用下列三个参数并用空格分隔:Web应用的名称,容器注册表的名称,以及资源组的名称。
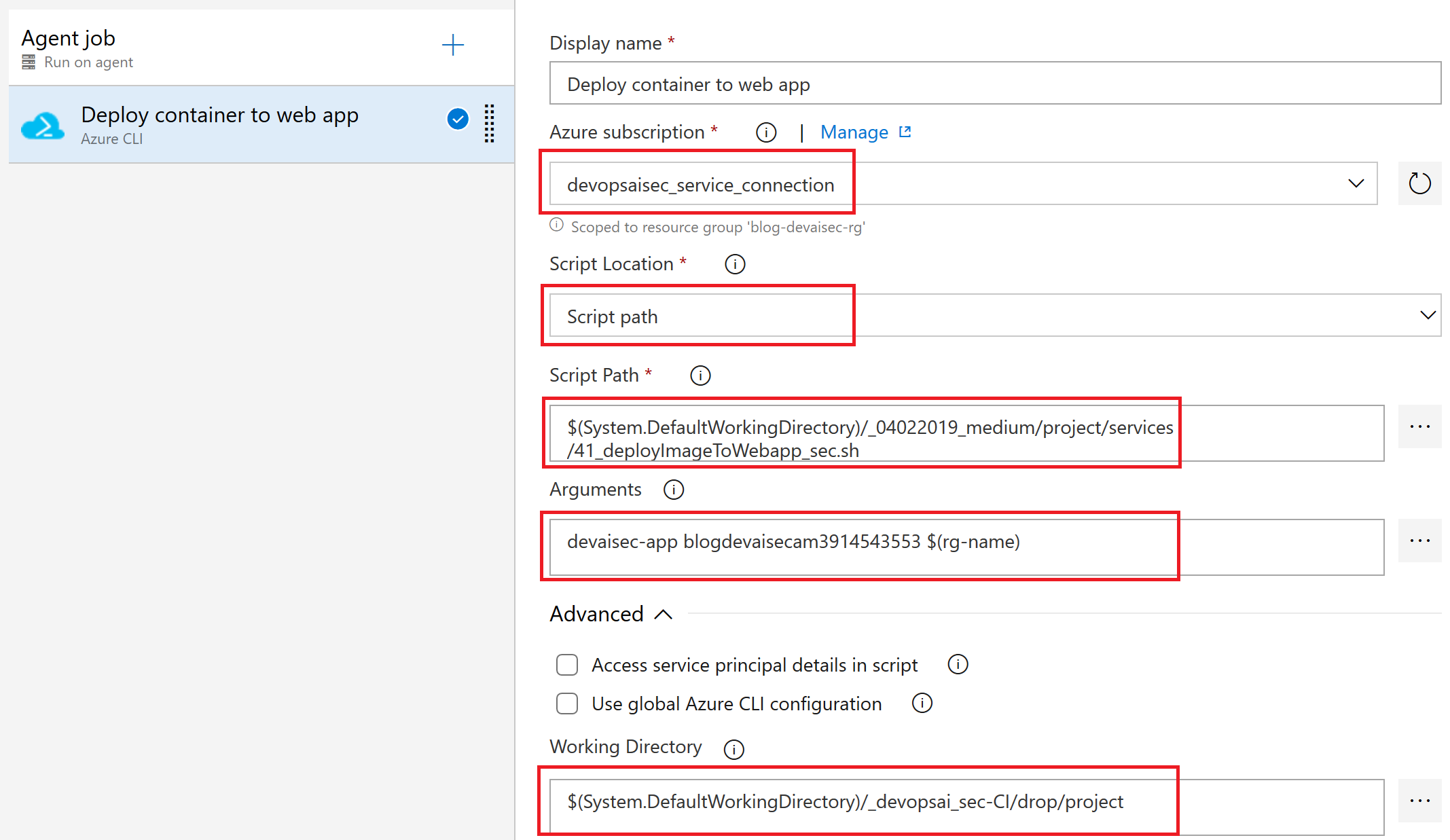
使用Azure CLI将容器部署到Web应用
保存并关闭,随后选择创建发布管道。填写所需变量创建发布。随后部署该发布,为此请点击部署按钮。等待约5分钟,然后确认状态已从“未部署”变为“成功”。
6e. 在Web应用中启用Azure Active Directory身份验证
该步骤将通过Azure门户为Web应用启用Azure Active Directory身份验证。请打开Web应用,选择身份验证/授权,随后选择Azure Active Directory。然后选择快速(Express),并使用Web应用的名称创建一个新的应用注册。
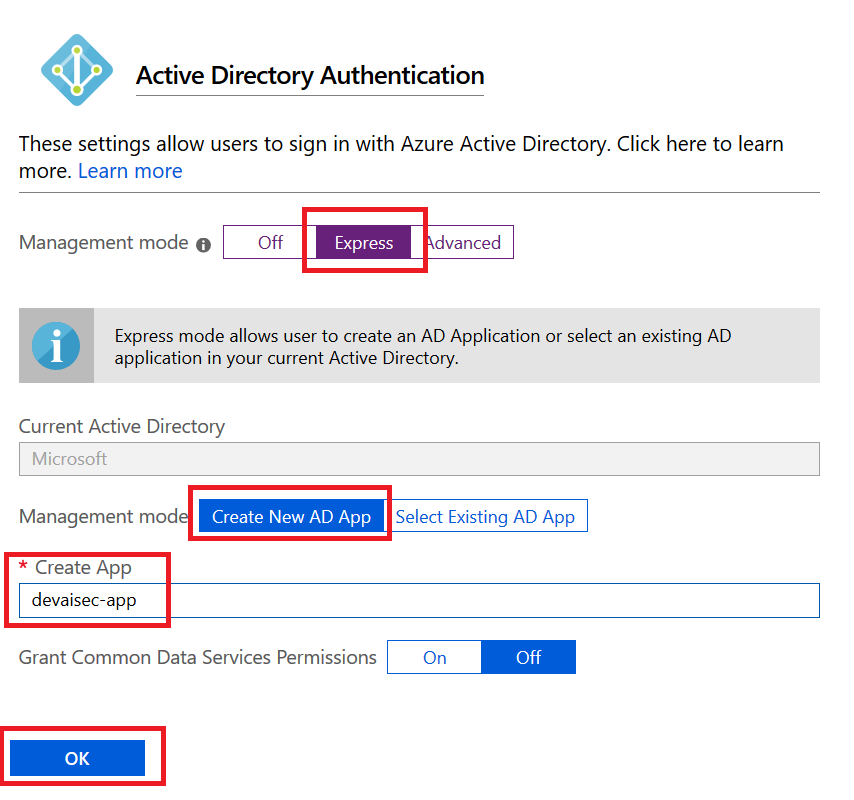
在Web应用中设置AAD身份验证
经过该操作,这个Web应用的URL就需要身份验证,否则将无法使用。
6f. 在Postman中设置Web应用的身份验证
最后还需要配置通过Postman工具对Web应用进行身份验证。下文将介绍具体做法。
在设置了Postman并在Postman中针对Web应用配置了客户端身份验证后,即可使用HTTPS终结点创建预测。项目的project/services/50_testEndpoint.py中提供了载荷范例。本例中将预测三个人的收入类型。
- 所预测的第一个人的收入超过5万,
- 另外两个人的收入低于5万。
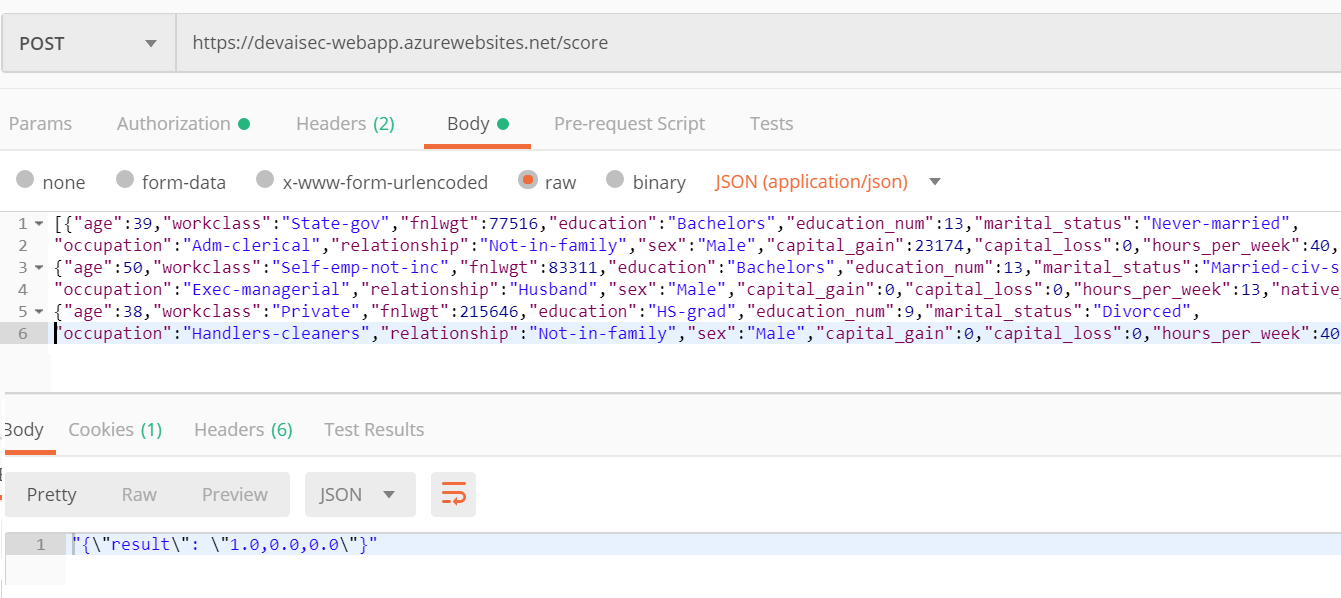
使用Bearer身份验证的Postman可以使用API进行预测
7. 结论
本文我们为机器学习项目创建了安全的端到端管道。其中使用Azure Databricks创建机器学习模型,并将其作为终结点部署到Web应用。这个端到端管道可通过下列方式加以保护:
- 使用Azure Active Directory对Web应用进行身份验证和授权
- 为存储账户和Web应用配置了网络访问控制列表
- 密钥被安全地存储在Azure密钥保管库中,构建管道添加了密钥轮换过程
借此我们即可1) 以端到端的方式跟踪模型,2) 在模型中构建信任,3) 避免出现导致模型预测结果变得不可理解的情况,以及4) 通过AAD、VNET和密钥保管库保护所有数据、终结点和机密。整体架构如下所示:
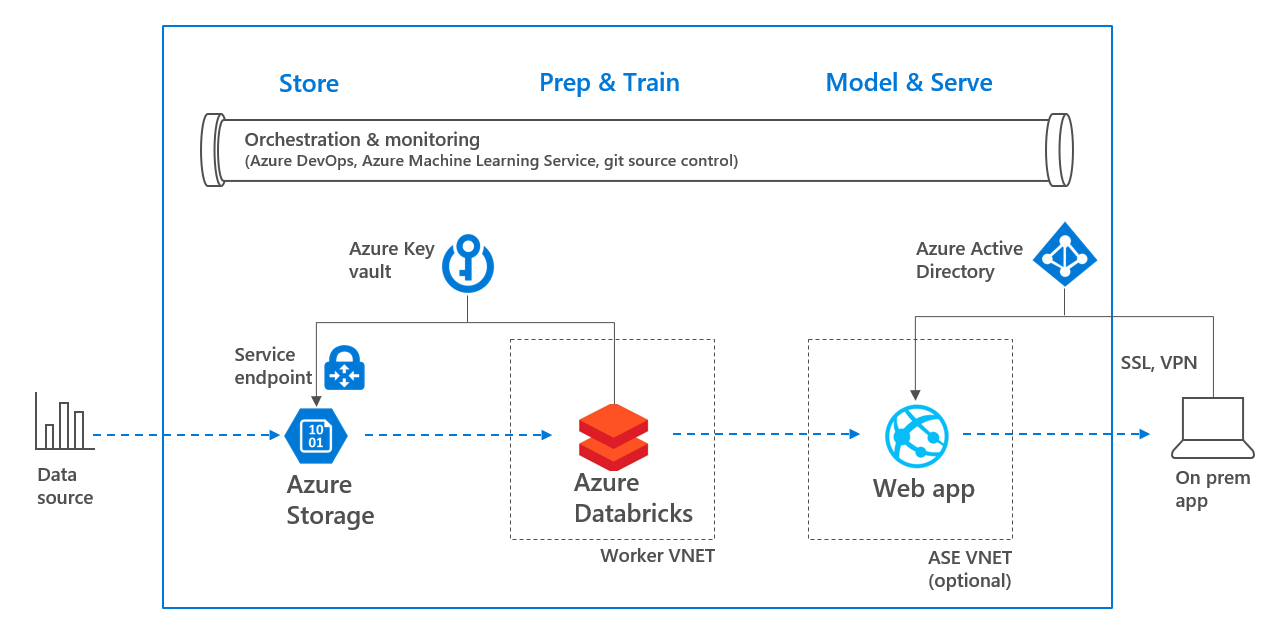
架构概述
本文最初发布于Towards Data Science博客,原作者René Bremer。经原作者授权由InfoQ中文站翻译并分享。点击查看原文:How to embed security in your Azure Data Science Project。
