@liuhui0803
2017-09-15T05:07:52.000000Z
字数 12533
阅读 4116
Dropbox高吞吐量低延迟Web服务器优化之法(下篇)
nginx 优化 流量 Web服务器 测试
摘要:
本文从硬件和驱动等底层内容,Linux内核及TCP/IP栈,以及库和应用程序层面的调优等角度介绍了针对常规用途Web服务器,尤其是nginx进行性能优化的思路。文章共分为上下两篇,上篇主要介绍硬件、驱动方面的优化措施和建议;下篇主要介绍Linux系统以及应用程序等方面的措施和建议。
正文:
本文最初发布于Dropbox官方博客,原作者Alexey Ivanov,经授权由InfoQ中文站翻译并分享。
操作系统:网络栈
有关Linux网络栈的调优,市面上有大量书籍、视频以及教程,然而其中大部分都在介绍“sysctl.conf cargo-culting”之类的操作。尽管新版内核已经不需要执行类似十年前的那种调优操作,而大量TCP/IP新功能默认已经启用并进行过优化,但人们依然在复制粘贴“上古时代”针对2.6.18/2.6.32版内核进行调优时所用的sysctls.conf。
为了验证与网络有关的优化是否有效,我们应当:
- 通过
/proc/net/snmp和/proc/net/netstat收集整个系统的不同TCP指标。 - 将通过
ss -n --extended –info或通过调用getsockopt(TCP_INFO)/getsockopt(TCP_CC_INFO)针对每个连接获得的指标汇总到Web服务器。 - 针对采样的TCP通信流应用tcptrace(1)。
- 通过应用/浏览器分析RUM指标。
为了获得有关网络优化的优质信息,我通常会选择CDN技术方面的行业大会,毕竟他们对这方面更了解,例如Fastly on LinuxCon Australia就不错。Linux内核开发人员有关网络的观点也能提供很大的价值,例如netdevconf talks和NETCONF transcripts。
此外PackageCloud有关Linux网络栈的深入解读也值得一看,尤其是他们的做法更重视监视,而非盲目地进行调优:
开始前有件事需要再次提醒:升级你的内核!网络栈方面的改进数不胜数,IW10这样的东西甚至无需再提(毕竟那是2010年的“老古董”啦)。下文我会主要介绍一些近期更热门的技术,例如TSO autosizing、FQ、pacing、TLP以及RACK。作为升级内核版本的额外福利,缩放能力方面也会获得大幅改善,例如取消路由缓存、无锁侦听Socket、SO_REUSEPORT、以及其他等等等等。
概述
最近有关Linux网络的论文中,有一篇名为“Making Linux TCP Fast(为Linux的TCP提速)”的比较瞩目。这份四页篇幅的论文汇总介绍了多年来Linux内核的相关改进,并将Linux发送端的TCP栈拆分为下列功能模块:
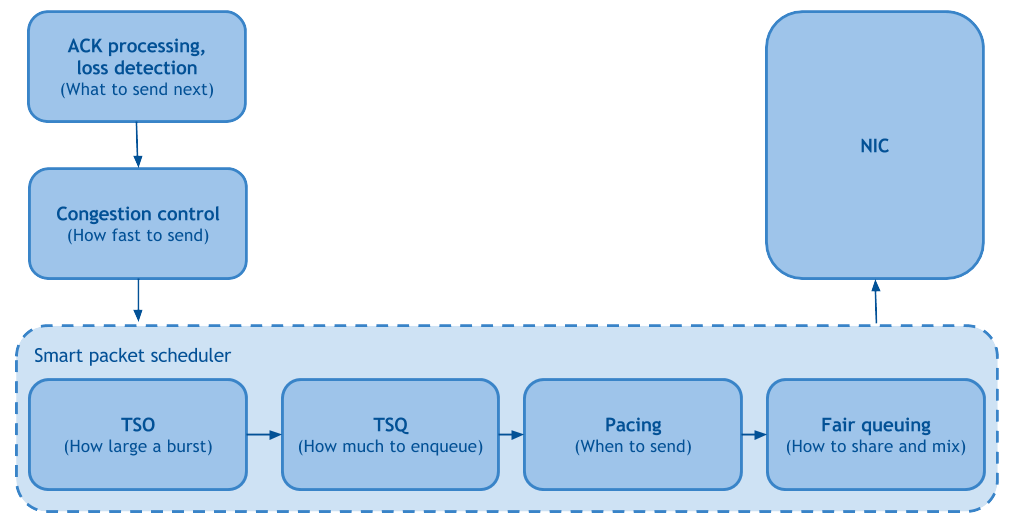
公平队列和Pacing
公平队列(Fair Queueing)可提高处理网络通信时的公平性,降低TCP流之间的线端阻塞(Head of line blocking),借此大幅降低丢包率。Pacing可按照一段时间内拥塞控制机制设置的速率对数据包进行调度,借此进一步降低丢包率,提高吞吐率。
但是需要注意:公平队列和Pacing需要通过fq qdisc命令在Linux中启用。一些人可能已经知道,这些也是使用BBR的前提要求(但现在已经不是了),但这两个功能都可以配合CUBIC使用,将丢包率降低最多15-20%,进而让基于丢包(Loss-based)的CC实现更高吞吐率。但是别在(版本号低于3.19的)老版本内核中使用该功能,因为这样做最终只能对ACK进行Pacing进而拖累到上传/RPC。
TSO Autosizing和TSQ
这两项技术可以对TCP栈内的缓冲进行限制,借此在不影响吞吐率的前提下降低延迟。
拥塞控制
拥塞控制(Congestion Control)算法本身就是个很大的课题,几年来在这一领域有很多研究。其中一些研究成果衍生出了tcp_cdg(CAIA)、tcp_nv(Facebook)以及tcp_bbr(Google)。本文不准备深入介绍这些技术的内部原理,不过需要提出一个结论:在拥塞的判断和指示方面,所有这些技术都更加依赖延迟的增加而非丢包。
在所有新出现的拥塞控制机制中,BBR也许是最知名,经历过最完善测试,最实用的一个。该技术的基本思路在于,根据数据包的交付速率为网络路径创建模型,随后通过执行控制回路(Control loop)实现最大化带宽和最小化RTT。这一点也正是我们的代理栈所要实现的。
在边缘PoP上进行BBR实验产生的初始数据显示,文件下载速度有了一定提升:
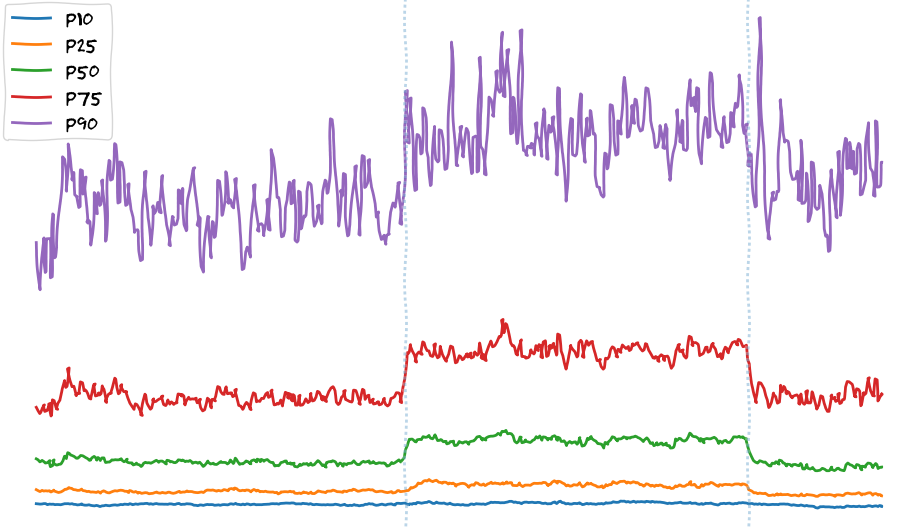
在东京PoP上进行了为期6小时的TCP BBR实验:X轴-时间,Y轴-客户端下载速度
在这里我想强调的是,在所有百分位数值上都观察到了速度的提升,但这与后端的变更无关。这些变化通常只能让p90+的用户(使用最快速度网络连接的用户)获益,因为我们本认为其他所有人的带宽本身就较为有限。诸如改动拥塞控制机制或启用FQ/pacing等网络层面的调优措施发现,用户自己的带宽并未受限,如果一定要说,他们被限制的其实是TCP。
如果你想进一步了解BBR,APNIC针对BBR提供了一个很棒的入门级介绍(以及这种机制与基于丢包的拥塞控制机制的对比)。如果想要进一步深入了解BBR,也许可以通读bbr-dev邮件列表的归档内容(置顶内容中提供了大量实用链接)。如果对拥塞控制机制的常规细节感兴趣,那么可以考虑关注Internet Congestion Control Research Group的相关活动。
ACK的处理和丢包检测
有关拥塞控制已经说的够多了,再来谈谈丢包检测,当然需要再次提醒,首先请确保自己运行了最新内核。诸如TLP和RACK等全新的启发式技术正在被逐步纳入TCP,而诸如FACK和ER等较老的技术正在逐步淡出。当然,这些新技术默认就已启用,因此升级后无需调整任何系统设置即可使用。
用户空间分区和HOL
用户空间Socket API提供了内含的缓冲机制,一经发送就无法对块进行重新排序,因此在一些多路复用场景(如HTTP/2)中可能导致HOL拥塞以及H2 priorities的倒置。TCP_NOTSENT_LOWAT这个Socket选项(以及对应的net.ipv4.tcp_notsent_lowat sysctl)按照设计可解决这类问题,为此需要设置一个阈值,借此让Socket决定自己何时可写(例如epoll其实是会对应用撒谎的)。这样也可解决HTTP/2优先次序的问题,但也可能对吞吐率产生负面影响,因此一定要自行测试。
Sysctls
任何网络优化措施都离不开sysctls的调优。但首先我想谈谈那些你不愿碰触的东西:
- net.ipv4.tcp_tw_recycle=1—不建议使用—这种方式无法适用于NAT后面的用户,但如果升级了内核,所有人都将无法使用。
- net.ipv4.tcp_timestamps=0—除非你清楚所有副作用并且全都能接受,否则不要禁用。例如一个不怎么明显的副作用是:会失去面向syncookie的窗口伸缩和SACK选项。
对于sysctls,应该考虑使用:
net.ipv4.tcp_slow_start_after_idle=0—“Slowstart after idle”的主要问题在于,“闲置”被定义为一个RTO,这个时间段有些太短了。net.ipv4.tcp_mtu_probing=1—你和客户端之间存在ICMP黑洞时会显得较为有用(大部分情况下都会存在)。net.ipv4.tcp_rmem、net.ipv4.tcp_wmem—应该结合BDP进行调优,但是别忘了数值并不总是越大越好。echo 2 > /sys/module/tcp_cubic/parameters/hystart_detect—如果使用了fq+cubic,那么也许有助于让tcp_cubic提早退出Slow-start状态。
另外需要注意,Curl的作者Daniel Stenberg发布过一个名为TCP Tuning for HTTP的RFC草案(虽然讨论并不热烈),其中提到希望将有关HTTP的所有系统调优措施汇总到一个位置进行。
应用程序层:中间层
工具
与内核类似,确保用户空间工具为最新状态也非常重要。因此首先需要升级各种工具,例如可以将新版本的perf、bcc等工具打包到一起。
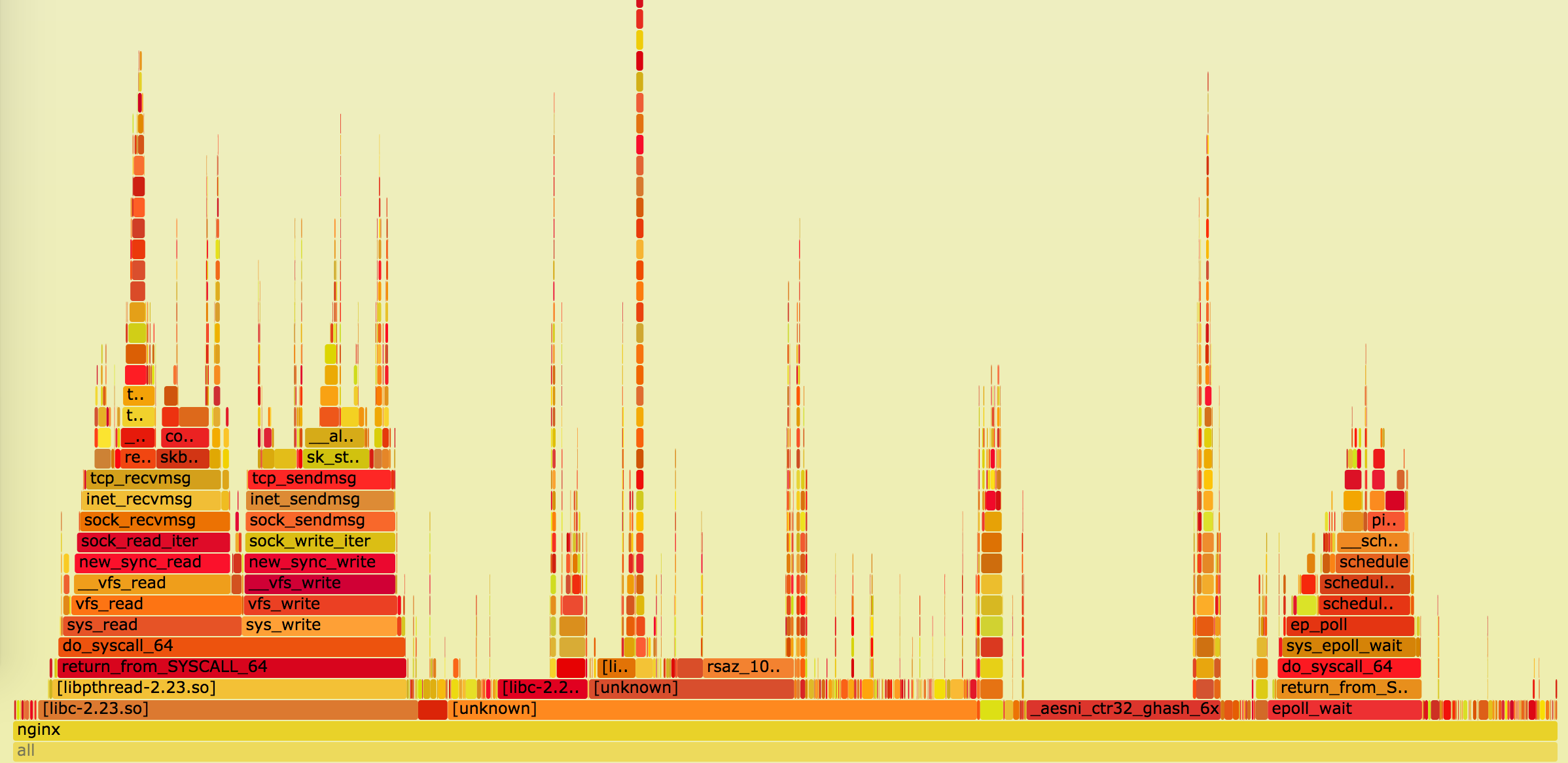
准备好新版工具后,就可以妥善调优整个系统并随时观察系统行为。本文的这部分内容将主要探讨通过perf top进行的on-CPU Profiling、on-CPU Flamegraphs以及通过bcc的funclatency创建的Adhoc直方图。
编译器工具链
如果希望编译面向硬件进行优化的汇编程序,现代化的编译器工具链将显得至关重要,很多Web服务器的常用库中都包含了这些工具。
除了性能,新版编译器还能提供大量新增的安全功能(例如-fstack-protector-strong或SafeStack),这些功能往往是边缘位置必须的。现代化工具链还能提供很多其他价值,例如你可能希望针对使用Sanitizer(例如AddressSanitizer和friends)编译的库文件运行测试。
系统库
系统库也需要升级,例如glibc,否则在处理-lc、-lm、-lrt等底层函数时可能措施一些最新实现的优化机制。这一过程中也不能忘了要自行测试,毕竟偶尔会遇到回归问题。
Zlib
通常来说,Web服务器需要负责处理压缩任务。取决于通过代理传输的数据量,你可能偶尔会在perf top中发现与zlib有关的条目,例如:
# perf top...8.88% nginx [.] longest_match8.29% nginx [.] deflate_slow1.90% nginx [.] compress_block
从最底层优化这些东西的方式有很多,Intel、Cloudflare以及独立的zlib-ng都有对应的项目,它们都可以通过zlib分支借助新的指令集提供更出色的性能。
Malloc
截至这里,所有优化措施主要都针对CPU,接下来一起谈谈有关内存的优化。如果配合FFI大量使用了Lua,或大量使用自行管理内存的第三方模块,可能会观察到由于碎片化造成的内存用量增长。为了解决这些问题,可考虑改为使用jemalloc或tcmalloc。
使用自定义的malloc可以获得下列收益:
- 将nginx库分散到整个环境中,借此降低glibc版本升级和操作系统迁移产生的影响。
- 更完善的introspection、profiling和stats。
PCRE
如果nginx配置中使用了大量复杂的正则表达式或严重依赖Lua,那么可能会在perf top中看到大量与pcre有关的条目。为了对此进行优化,可使用JIT编译PCRE,并通过pcre_jit on;在nginx中启用。
若要查看优化后的效果,可直接查看Flame图,或使用funclatency:
# funclatency /srv/nginx-bazel/sbin/nginx:ngx_http_regex_exec -u...usecs : count distribution0 -> 1 : 1159 |********** |2 -> 3 : 4468 |****************************************|4 -> 7 : 622 |***** |8 -> 15 : 610 |***** |16 -> 31 : 209 |* |32 -> 63 : 91 | |
TLS
如果TLS止于边缘位置,无需经由CDN处理,那么TLS性能优化将产生很大的效果。这方面的调优将主要侧重于服务器端的效率。
面对当今的技术,首先需要决定要使用的TLS库:Vanilla OpenSSL、OpenBSD的LibreSSL或Google的BoringSSL都可以。在确定要使用的TLS库后,需要妥善地进行构建:例如OpenSSL针对构建环境提供了大量可实现优化的启发式构建方法;BoringSSL提供了确定性构建方法,可惜这种方法过于保守,只是禁用了某些默认启用的优化措施。无论如何,使用现代化的CPU都将物超所值:大部分TLS库可以充分利用AES-NI和SSE,以及ADX和AVX512等指令集。你可以使用TLS库内建的性能测试工具,例如BoringSSL提供的bssl speed进行测试。
性能的提升幅度并非主要来自所用的硬件,而是来自于打算使用的密码套件(Ciphersuite),因此需要慎重优化。另外要注意,这方面的改动可能(并且终将会!)影响到Web服务器的安全性,速度最快的密码套件并不一定就是最好的。如果不确定使用怎样的加密设置,可以首先从Mozilla SSL Configuration Generator加以了解。
非对称加密
如果你的服务位于边缘位置,那么你可能会观察到相当大数量的TLS握手,并且非对称加密操作耗费了大量CPU运算能力,因此这方面也绝对有必要进行优化。
为了优化服务器端的CPU用量,可以改为使用ECDSA证书,一般来说,这种证书会比RSA快10倍。并且这种证书更小,在容易丢包的情况下可以加快握手速度。但ECDSA严重依赖于系统中随机数生成器的质量,因此如果使用OpenSSL,请确保提供了足够的熵(对于BoringSSL则无需担心这个问题)。
另外要补充一点,大并不总意味着更好,例如使用4096 RSA证书会导致性能降低10倍:
$ bssl speedDid 1517 RSA 2048 signing ... (1507.3 ops/sec)Did 160 RSA 4096 signing ... (153.4 ops/sec)
同时也别忘了,小也不一定就是更好的选择:如果为ECDSA使用非公用p-224 field,相比更为公用的p-256,性能可能降低60%左右:
$ bssl speedDid 7056 ECDSA P-224 signing ... (6831.1 ops/sec)Did 17000 ECDSA P-256 signing ... (16885.3 ops/sec)
因此这方面有一个经验得来的规则:使用率最高的加密技术往往就是最优化的技术。
在使用RSA证书运行妥善优化后的OpenTLS库时,你可能会在perf top中看到下列条目:AVX2-capable,而非ADX-capable(例如Haswell)将会使用AVX2代码路径:
6.42% nginx [.] rsaz_1024_sqr_avx21.61% nginx [.] rsaz_1024_mul_avx2
而较新的硬件会配合ADX代码路径使用通用的蒙哥马利乘法(Montgomery multiplication):
7.08% nginx [.] sqrx8x_internal2.30% nginx [.] mulx4x_internal
对称加密 如果需要大批量传输诸如视频、照片或常规文件之类的数据,那么可能会开始在分析器的输出结果中看到于对称加密有关的条目。此时只需要确保CPU支持AES-NI,并将服务器端首选项设置为使用AES-GCM密码运算。妥善调优后的硬件会在perf top中显示下列内容:
8.47% nginx [.] aesni_ctr32_ghash_6x
但是不仅服务器需要处理加密和解密,客户端也需要通过性能没那么强的CPU承担类似的负担。在不进行硬件加速的情况下这一过程可能充满了挑战,因此可以考虑使用哪怕不进行硬件加密,从设计上就可以运行足够快的算法,例如ChaCha20-Poly1305。这也有助于降低某些移动客户端的TTLB。
BoringSSL为ChaCha20-Poly1305提供了拆箱即用的支持,对于OpenSSL 1.0.2,则可以考虑使用Cloudflare提供的补丁。BoringSSL也可支持“Equal preference cipher groups(等价加密算法组)”,因此可以使用下列配置让客户端根据自己的硬件特性决定要使用的加密算法(厚着脸皮引用了cloudflare/sslconfig):
ssl_ciphers '[ECDHE-ECDSA-AES128-GCM-SHA256|ECDHE-ECDSA-CHACHA20-POLY1305|ECDHE-RSA-AES128-GCM-SHA256|ECDHE-RSA-CHACHA20-POLY1305]:ECDHE+AES128:RSA+AES128:ECDHE+AES256:RSA+AES256:ECDHE+3DES:RSA+3DES';ssl_prefer_server_ciphers on;
应用程序层:上层
我们可以收集RUM数据来衡量这一层面的优化效果,为此可以在浏览器中使用Navigation Timing API和Resource Timing API。需要重点关注的指标包括TTFB和TTV/TTI。将这些数据保存成易于查询和制图的格式有助于简化后续的迭代。
压缩
Nginx中的压缩可从mime.types文件着手,该文件定义了不同文件扩展和作为响应的MIME类型之间的默认对应关系。随后需要定义要将哪些类型传递给压缩程序,例如使用gzip_types。如果希望获得完整列表,可以使用mime-db自动生成自己的mime.types,并在gzip_types中添加.compressible == true。
启用gzip时需要注意两个问题:
- 会增加内存用量。若要解决该问题可限制
gzip_buffers。 - 缓冲导致TTFB增加。若要解决该问题可使用 [gzip_no_buffer]。
另外要注意,Http压缩并非只能使用gzip:nginx提供了第三方ngx_brotli模块,相比gzip可将压缩比提高最多30%。
对于压缩设置本身,需要讨论两个单独的用例:静态数据和动态数据。
- 对于静态数据,通过在构建过程中对静态资产预先进行压缩,可实现最大压缩率。我们曾在为静态内容部署Brotli一文中针对gzip和brotli详细讨论过这个问题。
- 对于动态数据,需要就一整个往返过程进行慎重的权衡:压缩数据耗时 + 传输耗时 + 客户端解压缩耗时。因此直接设置最高压缩级别可能并不是最合理的做法,不仅从CPU用量,同时从TTFB的角度来看都是如此。
缓冲
代理内部的缓冲会对Web服务器性能产生巨大影响,尤其是在延迟方面。Nginx代理模块提供了丰富的缓冲选项,可以针对每个不同的位置进行开关,每一个从用途来看都很有必要。我们可以针对两个方向通过proxy_request_buffering和proxy_buffering分别控制缓冲。如果缓冲已启用,可通过client_body_buffer_size和proxy_buffers设置内存用量上限,达到这些阈值后,请求/响应将缓冲到磁盘上。为了加快响应速度,可将proxy_max_temp_file_size设置为“0”已禁用该功能。
最常见的缓冲设置方法包括:
- 在内存中缓冲一定数量的请求/响应,随后溢出到磁盘。如果启用请求缓冲,那么只有在接收完毕后才会将请求发往后端,通过使用响应缓冲,只要准备好开始响应,即可立即释放后端线程。这种方式有助于提高吞吐率,降低后端延迟和内存/IO用量(不过如果使用了SSD,这本身也不算什么大问题)。
- 不缓冲。对于延迟敏感型路由,缓冲也许不是最佳做法,流式传输数据更是如此。对于这类情况,可以禁用缓冲,但后端需要应对速度缓慢的客户端(包括恶意进行的慢速POST/慢速读取类攻击)。
- 通过X-Accel-Buffering头,由应用程序控制的响应缓冲。
无论使用哪种方式,别忘了针对TTFB和TTLB测试所获得的效果。另外正如上文提到的,缓冲会影响到IO用量甚至后端的使用率,因此一定要密切监视。
TLS
接下来准备从较高层面谈谈TLS,以及如何通过正确的nginx配置改善延迟。下文要提到的大部分优化措施都源自High Performance Browser Networking(高性能浏览器网络)一书的“Optimizing for TLS(TLS优化)”一节,以及nginx.conf 2014大会上的Making HTTPS Fast(er)(让HTTPS快上加快)演讲。下文提到的调优措施会同时影响到服务器的性能和安全性,如果对此不确定,建议首先参阅Mozilla的Server Side TLS Guide并/或咨询你的安全团队。
我们可以使用下列方式验证优化结果:
- 使用WebpageTest测试性能影响。
- 使用SSL Server Test from Qualys或Mozilla TLS Observatory测试对安全性的影响。
会话恢复
就像数据库管理员们经常挂在嘴边的说法:“查询速度的改进优化永无止境”,TLS领域也是如此:如果将握手结果缓存起来,延迟即可减少一个RTT。具体实现方法有两个:
- 可以让客户端存储所有会话参数(通过签名并加密的方式),并在下次握手时发送给你(类似于Cookie)。在nginx端这种方式可通过
ssl_session_tickets指令来配置。这种方式不耗费服务器端的内存,但存在一些局限:
- 需要具备为TLS会话创建、轮换、分发随机加密/签名密钥的基础架构。另外要注意,绝对不能:1) 使用源代码控制系统存储票证(Ticket)密钥;2) 从其他非暂存来源,例如日期或证书生成这些密钥。
- PFS无法针对每个会话应用,只能针对每个TLS票证密钥应用,因此如果攻击者获得一个此类票证密钥,他就有可能在票证有效期内解密所捕获的任何流量。
- 加密方式受制于票证密钥的大小。如果使用128位票证密钥,此时就没必要使用AES256。Nginx可同时支持128位和256位的TLS票证密钥。
- 并非所有客户端均可支持票证密钥(不过所有现代化浏览器都可支持)。
- 或者可以将TLS会话参数存储在服务器上,只向客户端提供一个引用(ID)。这可以通过
ssl_session_cache指令实现。这种做法的优势在于可以在会话间维持PFS,并可大幅减小攻击面。不过票证密钥也有一些局限:
- 每个会话在服务器上耗费大约256字节内存,这也意味着无法长时间存储太多会话。
- 无法轻易跨服务器共享。因此或者通过负载均衡器将同一个客户端送至同一台服务器以保留本地缓存,或基于ngx_http_lua_module等技术编写分布式TLS会话存储。
另外要注意,如果选择会话票证的方式,那么有必要使用三个,而非一个密钥,例如:
ssl_session_tickets on;ssl_session_timeout 1h;ssl_session_ticket_key /run/nginx-ephemeral/nginx_session_ticket_curr;ssl_session_ticket_key /run/nginx-ephemeral/nginx_session_ticket_prev;ssl_session_ticket_key /run/nginx-ephemeral/nginx_session_ticket_next;
此时将永远使用当前密钥加密,但同时可接受使用上一个或下一个密钥加密的会话。
OCSP装订(Stapling)
OCSP响应需要进行装订,否则:
- TLS握手可能需要更长时间,因为客户端需要联系证书颁发机构获取OCSP状态。
- OCSP获取失败可能危及可用性。
- 可能威胁到用户隐私,因为用户的浏览器将联系第三方服务,对方将获知用户打算访问你的站点。
若要装订OCSP响应,你可以定期从证书颁发机构获取,将结果分发到你的Web服务器,并通过ssl_stapling_file指令使用:
ssl_stapling_file /var/cache/nginx/ocsp/www.der;
TLS记录大小
TLS会将数据拆分为名叫记录(Record)的块,只有在收到完整数据后才能验证并解密。若要衡量这一过程的延迟,可检测网络栈和应用程序相应的TTFB差值。
默认情况下nginx使用16k大小的块,这个大小甚至无法纳入IW10拥塞窗口,因此还需要一个额外的往返。Nginx自带设置记录大小的方法,为此可使用ssl_buffer_size指令:
- 为通过优化降低延迟,可将其设置为较小值,如4k。进一步减小可能会增大CPU开销。
- 为通过优化提高吞吐率,可保留默认的16k设置。
静态调优可能会面临两个问题:
- 需要手工调整。
- 只能针对每个nginx配置或每个服务器块设置
ssl_buffer_size,因此如果服务器上同时运行了对延迟/吞吐率有不同要求的多个工作负载,则需要进行一定的取舍。
此外还有另一种方法:动态调整记录大小。Cloudflare为nginx提供了一个补丁,可获得动态调整记录大小的功能,通过这种方式,最开始的配置过程可能较为痛苦,但只要辛苦配置完成,就可以获得相当棒的效果。
TLS 1.3
TLS 1.3的功能听起来确实很赞,但除非你具备必要的资源,可随时对TLS的各种问题进行排错,否则不建议启用。因为:
避免事件循环拖延
Nginx是一种基于事件循环(Event loop)的Web服务器,这意味着它在同一时间只能做一件事。虽然看起来多个事情可以同时执行,例如时分多路复用,但所有nginx都是通过在不同事件之间快速切换来实现的,这一过程中依然只能挨个处理所有事件。造成这种错觉的原因在于每个事件的处理只需要几微秒时间。但如果某个事件的处理耗费了太多时间,例如可能需要等待磁盘旋转起来,此时延迟将会激增。
如果你开始发现自己的nginx在ngx_process_events_and_timers函数内部花费了太多时间,而且呈双峰状分布,那么可能是受到了事件循环拖延(Eventloop stall)的影响。
# funclatency '/srv/nginx-bazel/sbin/nginx:ngx_process_events_and_timers' -mmsecs : count distribution0 -> 1 : 3799 |****************************************|2 -> 3 : 0 | |4 -> 7 : 0 | |8 -> 15 : 0 | |16 -> 31 : 409 |**** |32 -> 63 : 313 |*** |64 -> 127 : 128 |* |
AIO和线程池
由于事件循环拖延,尤其是等待磁盘旋转起来的原因主要来自IO,也许应该首先调查这一方面。例如可以通过fileslower衡量影响程度:
# fileslower 10Tracing sync read/writes slower than 10 msTIME(s) COMM TID D BYTES LAT(ms) FILENAME2.642 nginx 69097 R 5242880 12.18 00021218124.760 nginx 69754 W 8192 42.08 00021215984.760 nginx 69435 W 2852 42.39 00021218454.760 nginx 69088 W 2852 41.83 0002121854
为了解决这个问题,nginx可以支持将IO卸载到线程池(此外也支持AIO,但Unix中的原生AIO存在很多问题,因此除非知道自己在做什么,否则请尽量避免使用)。最基本的设置包含下列内容:
aio threads;aio_write on;
对于更复杂的情况则可设置自定义的thread_pool,例如针对每个磁盘设置一个,这样如果一个驱动器变得不稳定,也不会影响其他请求。线程池可大幅降低nginx进程卡在D状态的几率,可同时改善延迟和吞吐率。但这种方式并不能彻底避免事件循环拖延,因为目前并不能将所有IO操作卸载给线程池。
日志 日志的写入一样需要花费不菲的时间,因为需要占用磁盘。为了确定日志写入导致的影响,可以运行ext4slower并查看对access/error日志的引用:
# ext4slower 10TIME COMM PID T BYTES OFF_KB LAT(ms) FILENAME06:26:03 nginx 69094 W 163070 634126 18.78 access.log06:26:08 nginx 69094 W 151 126029 37.35 error.log06:26:13 nginx 69082 W 153168 638728 159.96 access.log
这种问题是可以解决的,我们可以为access_log指令使用buffer参数,在内存中对日志的访问进行缓冲处理(Spooling),随后再写入硬盘。通过使用gzip参数,还可以首先压缩日志,随后再写入磁盘,借此进一步降低IO压力。
但为了彻底消除日志写入造成的IO拖延,可以通过syslog写入日志,通过这种方式可将日志全面集成到nginx的事件循环中。
Open file cache
由于open(2)调用固有的阻塞性,并且Web服务器会例行公事般打开/读取/关闭文件,因此可从所打开文件的缓存中获益。如果想要了解这种方式的性能改进程度,可查看ngx_open_cached_file函数的延迟:
# funclatency /srv/nginx-bazel/sbin/nginx:ngx_open_cached_file -uusecs : count distribution0 -> 1 : 10219 |****************************************|2 -> 3 : 21 | |4 -> 7 : 3 | |8 -> 15 : 1 | |
如果看到有太多打开的调用,或有些调用花费了太多时间,则可打开Open file缓存:
open_file_cache max=10000;open_file_cache_min_uses 2;open_file_cache_errors on;
启用open_file_cache后可通过opensnoop观察所有缓存未命中情况,并决定是否需要对缓存的限制进行调优:
# opensnoop -n nginxPID COMM FD ERR PATH69435 nginx 311 0 /srv/site/assets/serviceworker.js69086 nginx 158 0 /srv/site/error/404.html...
总结
本文涉及的所有优化措施都只针对本地运行的单一Web服务器环境。其中一些措施有助于改进缩放性和性能,有些有助于降低响应请求时的延迟,或提高客户端访问速度。但在我们的感受来看,大量可被用户感受到的性能提升来自更高层面的优化,这些优化甚至会影响到Dropbox Edge Network整体,例如入站/出站流量工程以及智能内部负载均衡。这些问题往往涉及一些边缘知识,并且才刚开始进入进入整个业界的视野内。
