@liuhui0803
2016-08-12T02:36:08.000000Z
字数 4948
阅读 5515
如何在AWS EC2上搭建多可用区域高可用Cassandra集群
Cassandra
摘要:
本文介绍了如何通过AWS EC2多可用区域配置高可用的Cassandra。该配置的成本和性能与单一可用区域的部署几乎完全相同。
正文:

本文作者为Stream软件架构师Alessandro Pieri。若要详细了解Stream的API可访问他们的5分钟交互式教程。
最初由Facebook在2009年开发的Apache Cassandra是一种可借助大量服务器处理海量数据,免费开源的分布式数据库引擎。Stream使用Cassandra作为信息源(Feed)的主要数据存储。选择Cassandra原因在于它能:
- 自动Shard数据
- 在不停机,不丢失数据的情况下解决部分故障
- 近乎线性的伸缩
如果已经在使用Cassandra,你的集群很可能已经配置为可以接受1或2个节点的丢失。然而如果整个可用区域(Availability zone)故障该怎么办?
本文将介绍如何配置Cassandra以便承受整个可用区域的故障。随后我们将分析从一个可用区域迁移至多个可用区域之后对可用性、成本,以及性能的影响。
概要1:可用区域是什么?
AWS会在相互隔离的不同地理位置运营服务,这样的地理位置也叫做地区(Region)。每个地区都包含少量(通常为3-4个)在物理上相对独立的可用区域。不同可用区域使用低延迟网络连接在一起,但每个地区是相互独立的,如下图所示:
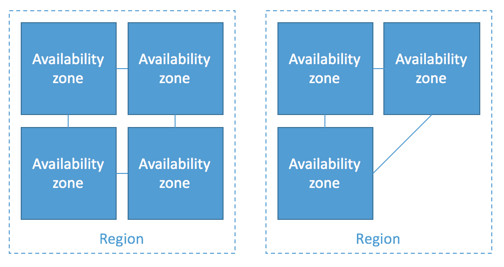
为了实现高可用,AWS提供的资源可以承载于多个可用区域中。通过在多个可用区域承载,确保了即使一个可用区域故障应用依然可以继续运行。
概要2:Cassandra的高可用
Cassandra的主要优势之一在于可以跨越多个节点自动对数据创建Shard,该产品甚至可以用近乎线性的方式进行伸缩,因此将节点数量增加一倍即可让容量增加几乎一倍。
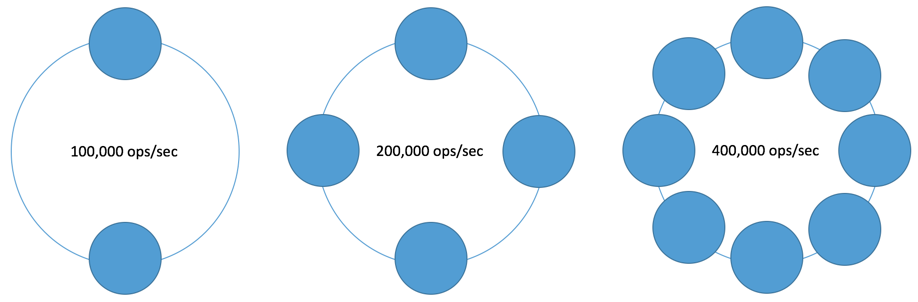
Cassandra提供了一个名为“副本因子(Replication factor)”的设置,该设置定义了数据可以存在多少个副本。如果将副本因子设置为1并且一个节点故障了,所有数据都将丢失,因为此时数据只存储在1个位置。将副本因子设置为3可以将数据始终保存在3个不同节点中,就算一个节点故障数据也不会受到影响。
为Cassandra配置多个可用区域
介绍完基本概念后,一起看看如何为Cassandra配置多个可用区域。
如果你是Cassandra新手,想要了解如何配置集群,可以从本文开始入门。
第1部分 - Snitch
第一步需要确保Cassandra知道自己位于哪个地区和哪个可用区域。这一过程是通过“Snitch”实现的,Snitch可以持续追踪与网络拓扑有关的信息。Cassandra提供了多个内建的Snitche,其中Ec2Snitch和Ec2MultiRegionSnitch可配合AWS使用。Ec2Snitch适用于单一地区的部署,Ec2MultiRegionSnitch适合跨越多个地区的集群。
Cassandra可以理解数据中心和机柜有关的概念。EC2 Snitch会将每个EC2地区视作数据中心,并将可用区域视作机柜。
用户可以在cassandra.yaml中更改Snitch设置。然而要注意,更改Snitch设置是一种具备潜在破坏性的操作,需要妥善规划。详情请阅读Cassandra文档中有关更改Snitch设置的介绍。
# 如果在将数据插入集群后更改Snitch设置,必须运行完整修复,因为Snitch会影响副本的存储位置。## Cassandra提供了拆箱即用的:...# - Ec2Snitch:# 适用于单一地区的EC2部署,可通过EC2 API加载地区和可用区域信息。地区会被视作数据中心,可用区域会被视作机柜。# 只能使用私有IP,因此无法跨地区使用。# - Ec2MultiRegionSnitch:# 使用公有IP作为broadcast_address以实现跨地区连接。(因此也可以将Seed地址设置为公有IP地址。)需要在公有IP的防火墙上打开storage_port或ssl_storage_port。(对于地区内流量,Cassandra会在建立连接后切换至私有IP。)## 设置Snitch的完整类名称后即可使用自定义Snitch,类名称被假定位于你的Classpath中。endpoint_snitch:Ec2Snitch
上述内容摘自cassandra.yaml
第2部分 – 副本因子
副本因子决定了集群中存在的副本数量。副本策略(也叫做副本放置策略)决定了副本跨越集群分布的方式。这些设置都是Keyspace属性。
默认情况下Cassandra会使用“SimpleStrategy”副本策略。该策略在给集群中放置副本时会忽略所在的地区或可用区域。NetworkTopologyStrategy可感知机柜,按照设计可支持多数据中心部署。
CREATE KEYSPACE mykeyspace WITH replication = {'class': 'NetworkTopologyStrategy','us-east': '3'};
在上述代码片段中声明了一个名为“mykeyspace”的Keyspace,并通过NetworkReplicationStrategy将副本仅放置在“美国-东部”数据中心,副本因子设置为3。
若要更改现有Keyspace,可以使用下列代码。但是要注意,更改运行中Cassandra集群的副本策略是一种敏感操作。详情请阅读完整文档。
ALTER KEYSPACE mykeyspace WITH REPLICATION = {'class' : 'NetworkTopologyStrategy','us-east' : '3'};
第3部分 – 一致性级别
在通过Cassandra读写时,可以在客户端指定“一致性级别”。换句话说,可以指定需要在Cassandra集群中具备多少个节点,随后才能认为读写请求是有效的。
如果请求需要满足更高可用性级别要求,并超出了Cassandra本地可用区域中可应答节点的数量,此时将通过其他地区查询。为了在一个可用区域故障后保持正常运行,需要确保剩余节点依然可以满足所用可用性级别的要求。下文将进一步讨论故障场景和一致性级别。
解决可用区域的故障
某个可用区域故障后Cassandra集群的行为方式取决于多种因素:
- 故障的规模(有多少个可用区域故障了)
- 集群所用的可用区域数量
- 副本因子(RF)
- 一致性级别(CL)
下列示意图演示了几个场景:

图2:一致性级别对可用性的影响
在左侧显示的第一个场景中有一个在2个可用区域中使用6个节点(每个可用区域3个节点)运行的集群,RF=2。当1个可用区域故障后,半个集群脱机。由于有2个可用区域并且RF=2,可以确保至少1个节点依然存储了整个数据集。从集群示意图旁边的表格中可以看到,查询结果取决于请求对一致性级别的要求。例如CL=ONE的查询可以成功处理,因为此时依然有至少1个可用节点。但是对于CL要求更高的查询,例如QUORUM和ALL始终会失败,因为这两个查询都需要同时从2个节点得到响应。
在第二个场景中我们在3个不同可用区域使用9个节点运行Cassandra,副本因子为3。在这个部署中,如果1个可用区域故障,整个集群无疑可以提供更高弹性。此时Cassandra依然可以满足CL=QUORUM查询的要求。
然而还要注意,当一个可用区域故障后,其余2个集群中服务的剩余容量是不同的。第一个集群配置中将损失50%的容量,而第二个配置中只损失33%的容量。
多可用区域的配置会造成多大延迟?
由于Cassandra的本质特征以及云环境不同因素(例如网络延迟、磁盘I/O、主机使用率等)的波动,多可用区域配置对查询延迟的影响往往很难估算。
测试中我们使用了cassandra-stress工具为单一和多可用区域配置的集群生成读取和写入负载。为了尽量将误差降至最低,并降低磁盘I/O对结果的干扰,我们使用了具备临时存储的实例,而没有使用网络附加存储(EBS)。
随后我们搭建了两个测试场景:
第一个场景使用6个i2.xlarge实例(AWS网络性能 = “moderate”)搭建集群,并在不使用增强联网(Enhanced networking)的情况下运行:
| - | 中位数 | 第95百分位数 |
|---|---|---|
| 写入 | - | - |
| 单一可用区域 | 1.0 | 2.5 |
| 多可用区域(3个) | 1.5 | 2.8 |
| 读取 | - | - |
| 单一可用区域 | 1.0 | 2.6 |
| 多可用区域(3个) | 1.5 | 23.5 |
表1。场景1:单一可用区域和多可用区域性能测试(时间单位为毫秒)。配置:Cassandra 2.0.15;RF=3;CL=1
第二个场景使用6个i2.2xlarge实例(AWS网络性能 = “high”)搭建集群,并启用增强联网功能:
| - | 中位数 | 第95百分位数 |
|---|---|---|
| 写入 | - | - |
| 单一可用区域 | 0.9 | 2.4 |
| 多可用区域(3个) | 1.1 | 2.3 |
| 读取 | - | - |
| 单一可用区域 | 0.7 | 1.5 |
| 多可用区域(3个) | 1.0 | 1.9 |
表2。场景2:单一可用区域和多可用区域性能测试(时间单位为毫秒)。配置:Cassandra 2.0.15;RF=3;CL=1
有趣的是两种类型实例的网络性能也有差异。在使用i2.2xlarge并启用增强联网的情况下,单一和多可用区域部署的差别很小。因此我们建议启用增强联网并选择使用“High”网络性能的实例类型。
另一个有趣的发现是,Cassandra的读取操作(在某种程度上)是可以感知机柜的。在对查询进行协调时,Cassandra节点会将请求路由至延迟最低的对端(Peer)。这个功能叫做“动态Snitching”,已包含在Cassandra 0.6.5及以后的版本中。
借助动态Snitching,针对Cassandra的大部分读取请求并不会“命中”不同可用区域内的节点,这样就使得Cassandra可以在某种程度上感知机柜。我们可以在读取测试总重现这一行为,如下图所示:
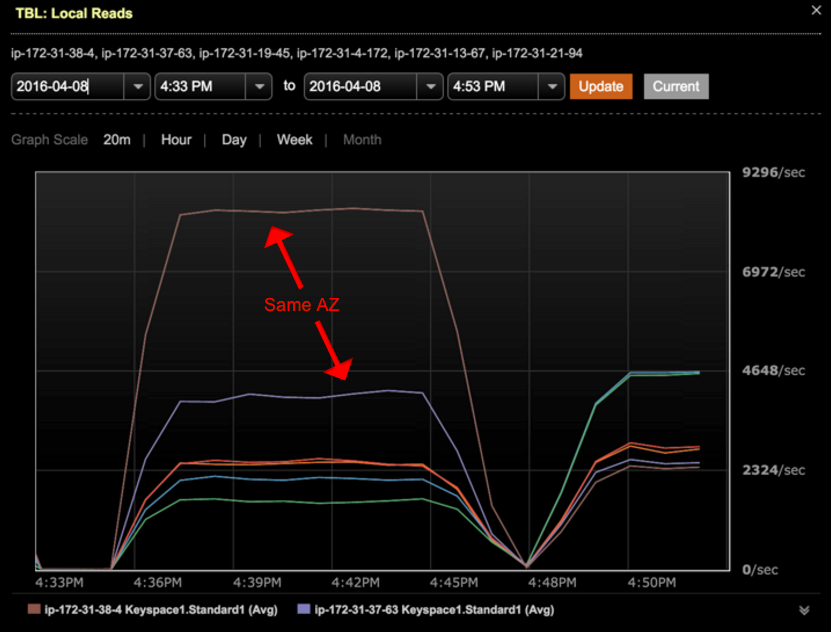
图1。多可用区域配置中每节点的本地读取请求数量。此时将首选同一可用区域内的副本。配置:包含6个节点的集群,跨越3个可用区域。所执行读取的一致性级别为“1”
从图1中可以看到总共1千万的读取请求是如何分散到整个集群中的。从图中可见,大部分请求是在本地可用区域内处理的。
关于增强联网:AWS在最新发布的实例产品中提供了增强联网功能。使用增强联网可有效降低实例间延迟。该功能的详细信息请参阅此链接。
所需可用区域数量指南
Cassandra可配置为这样的方式:每个可用区域至少有1个完整的数据集副本。Cassandra将这种配置视作自包含(Self-contained)可用区域。为了实现这种配置,需要将节点分布到数量与副本因子数量相同或更小数量的可用区域中。另外还建议每个可用区域运行相同数量的节点。
总的来说,建议进行如下配置:
可用区域数量 <= 副本因子
Stream选择使用副本因子为3的3个可用区域。这样即可确保每个可用区域都有数据的完整副本,并且在某个可用区域故障后依然有足够的容量处理读写请求。
结论
Cassandra是一种很棒的数据库。Stream大幅依赖该技术确保为上千万最终用户提供信息源(Feed)。简而言之,我们能做到这一点主要是因为Cassandra可以:
- 自动Shard数据
- 在不停机,不丢失数据的情况下解决实例故障
- (近乎)线性的伸缩
本文介绍了如何通过AWS EC2多可用区域配置高可用的Cassandra。该配置的成本和性能与单一可用区域的部署几乎完全相同。主要结论为:
- 跨越多个可用区域放置节点可以提高Cassandra集群的可用性,以及可用区域故障后的弹性。
- 在多可用区域内运行无需额外的存储,成本的增加幅度很小。可用区域之间的流量虽不免费,但对大部分用例来说这并不是太大的问题。
- 副本因子设置为3,同时使用3个可用区域,对大部分用例来说都是一种很好的起点。这样的配置确保了Cassandra集群能够实现自包含。
- AWS在确保可用区域之间低延迟方面做出了不错的成绩。尤其是使用网络性能设置为“High”的实例并启用增强联网功能的情况下。
作者:Alessandro Pieri,阅读英文原文:How To Setup A Highly Available Multi-AZ Cassandra Cluster On AWS EC2
