@liuhui0803
2016-07-08T07:21:59.000000Z
字数 3183
阅读 2385
机器学习驱动编程:新世界的新编程
战略
摘要:
正文:
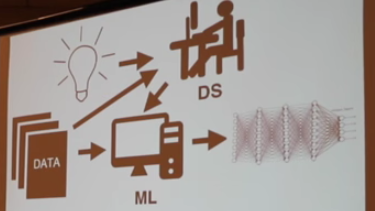
如果今天要重新建立Google,这家公司的大部分系统将会是通过学习得来的,而非编写代码而来。Google的25,000名开发者中原本有大概10%精通机器学习,现在这一比例可能会达到100% -- Jeff Dean
和天气一样,大家都会抱怨编程,但谁也没有为此做点什么。这种情况正在发生变化,就像突如其来的暴风雨一样,这些变化也来自一个出乎意料的方向:机器学习/深度学习。
我知道很多人对深度学习都听厌了。谁不是呢?但是编程技术很长时间来都处在一成不变的情况下,是时候做点什么改变这一情况了。
各种有关编程的“战斗”还在继续,但解决不了任何问题。函数还是对象,这种语言还是那种语言,这朵公有云还是那朵公有云或者这朵私有云亦或那朵“填补了空白”的云,REST还是Unrest,这种字节级编码还是另一种编码,这个框架还是那个框架,这种方法论还是那种方法论,裸机还是容器或者虚拟机亦或Unikernel,单层还是微服务或者NanoService,最终一致还是事务型,可变(Mutable)还是不可变(Immutable),DevOps还是NoOps或者SysOps,横向扩展还是纵向扩展,中心化还是去中心化,单线程还是大规模并行,同步还是异步。诸如此类永无止境。
年复一年,天天如此。我们只是创造了调用函数的不同方法,但最终的代码还需要我们人类来编写。更强大的方法应该是让机器编写我们需要的函数,这就是机器学习大展拳脚的领域了,可以为我们编写函数。这种年复一年天天如此的无聊活动还是交给机器学习吧。
机器学习驱动的编程
我最初是和Jeff Dean聊过之后开始接触用深度学习方式编程的。当时我针对聊天内容写了篇文章:《Jeff Dean针对Google大规模深度学习的看法》。强烈建议阅读本文了解深度学习技术。围绕本文的主题,本次讨论的重点在于深度学习技术如何有效地取代人工编写的程序代码:
Google的经验是对于大量子系统,其中一些甚至是通过机器学习方式获得的,使用更为通用的端到端机器学习系统取代它们。通常当你有大量复杂的子系统时,必须通过大量复杂代码将它们连接在一起。Google的目标是让大家使用数据和非常简单的算法取代这一切。
机器学习将成为软件工程的敏捷工具
Google研究总监Peter Norvig针对这个话题进行过详细的讨论:用深度学习与可理解性对抗软件工程和验证。他的大致想法如下:
软件。你可以将软件看作为函数构建的规范,而实现相应的函数就可以满足规范的要求。
机器学习。以(x,y)对为例,你会猜测某一函数会使用x作为参数并生成y作为结果,这样就能很好地概括出x这个新值。
深度学习。依然是以(x,y)对为例,可以通过学习知道你所组建的表征(Representation)具备不同级别的抽象,而非简单直接的输入和输出。这样也可以很好地概括出x这个新值。
软件工程师并不需要介入这个循环,只需要将数据流入机器学习组件并流出所需的表征。
表征看起来并不像代码,而是类似这样:
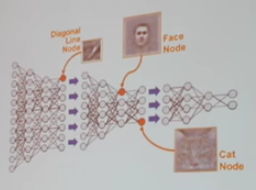
这种全新类型的程序并非人类可以理解的函数分解(Functional decomposition),看起来更像是一堆参数。
在机器学习驱动的编程(MLDP)世界里,依然可以有人类的介入,不过这些人再也不叫“程序员”了,他们更像是数据科学家。
可以通过范例习得程序的部分内容吗?可以。
有一个包含超过 2000 行代码的开源拼写检查软件的例子,这个软件的效果始终不怎么好。但只要通过包含 17 行代码的朴素贝叶斯分类器就能以同样性能实现这个软件的功能,但代码量减少了100倍,效果也变得更好。
AlphaGo是另一个例子,该程序的结构是手工编写的,所有参数则是通过学习得到的。
只通过范例可以习得完整的程序吗?简单的程序可以,但大型传统程序目前还不行。
在Jeff Dean的讲话中,他介绍了一些有关使用神经网络进行序列学习的顺序的细节。借助这种方法可以从零开始构建最尖端的机器翻译程序,这将是一种端到端学习获得的完整系统,无需手工编写大量代码或机器学习的模型即可解决一系列细节问题。
另一个例子是学习如何玩Atari出品的游戏,对于大部分游戏机器可以玩得和人一样好,甚至比人玩得更好。如果按照传统方式对不同组件进行长期的规划,效果肯定不会像现在这么好。
神经图灵机(Neural Turing Machine)也是一次学习如何用程序编写更复杂程序的尝试,但Peter认为这种技术不会走的太远。
正如你所期待的,Norvig先生的这次讲话非常棒,很有远见,值得大家一看。
Google正在以开源代码的方式从GitHub收集数据
深度学习需要数据,如果你想要创建一个能通过范例学习如何编程的AI,肯定需要准备大量程序/范例作为学习素材。
目前Google和GitHub已经开始合作让开源数据更可用。他们已经从GitHub Archive将超过3TB的数据集上传至BigQuery,其中包含超过280万个开源GitHub代码库中包含的活动数据,以及超过1.45亿次提交,和超过20亿不同的文件路径。
这些都可以当作很棒的训练数据。
就真的完美无缺吗?
当然不是。神经网络如同“黑匣子”般的本质使其难以与其他技术配合使用,这就像试图将人类潜意识行为与意识行为背后的原因结合在一起一样。
Jeff Dean还提到了Google搜索评级团队在搜索评级研究工作中运用神经网络技术时的犹豫。对于搜索评级,他们想要了解整个模型,了解做出某一决策的原因。当系统出现错误后他们还想了解为什么会出现这样的错误。
为了解决这样的问题,需要创建配套的调试工具,而相关工具必须具备足够的可理解性。
这样的做法会有效的。针对搜索结果提供的机器学习技术RankBrain发布于2015年,现在已成为第三大最重要的搜索评级指标(指标共有100项)。详情可访问:Google将利润丰厚的网页搜索技术交给AI计算机处理。
Peter还通过一篇论文《机器学习:技术债的高利率信用卡》进一步介绍了相关问题的更多细节。缺乏明确的抽象层,就算有Bug你也不知道到底在哪。更改任何细节都要改变全局,很难进行纠正,纠正后的结果更是难以预测。反馈环路,机器学习系统生成数据后会将这些数据重新送入系统,导致反馈环路。诱惑性损害(Attractive Nuisance),一旦一个系统使得所有人都想使用,这样的系统很可能根本无法在不同上下文中使用。非稳态(Non-stationarity),随着时间流逝数据会产生变化,因此需要指出到底需要使用哪些数据,但这个问题根本没有明确答案。配置依赖性,数据来自哪里?数据准确吗?其他系统中出现的改动是否会导致这些数据产生变化,以至于今天看到的结果和昨天不一样?训练用数据和生产用数据是否不同?系统加载时是否丢弃了某些数据?缺乏工具,标准化软件开发有很多优秀的工具可以使用,但机器学习编程是全新的,暂时还没有工具可用。
MLDP是未来吗?
这并不是一篇“天呐,世界末日到了”这样的文章,而是一篇类似于“有些事你可能没听说过,世界又将为此产生变化,这多酷啊”的文章。
这种技术依然处于非常早期的阶段。对程序的部分内容进行学习目前已经是可行的,而对大规模复杂程序进行学习目前还不实用。但是当我们看到标题类似于Google如何将自己重塑为一家“机器学习为先”的公司这样的文章,可能还不明白这到底真正意味着什么。这种技术不仅仅是为了开发类似AlphaGo这样的系统,最终结果远比这个还要深刻。
相关文章
与Google研究总监Peter Norvig的对话
Peter Norvig撰写的用深度学习与可理解性对抗软件工程和验证
