@liuhui0803
2017-12-12T06:21:10.000000Z
字数 5139
阅读 3743
深度学习领域四个不可不知的重大突破
人工智能 深度学习 机器学习 数据科学
原作者:Seth Weidman,点击阅读英文原文:The 4 Deep Learning Breakthroughs You Should Know About
为何阅读本文?
无论该领域中的从业者,或是企业组织,为了运用深度学习技术,首先需要做好两个准备:
- “能做什么”:了解深度学习领域的最新进展能够用来做什么。
- “怎么做”:训练新模型,或将现有模型用于生产环境的技术能力。
在开源社区的努力下,第二个问题正变得越来越容易。目前已经有大量优秀的教程在告诉大家,如何使用诸如TensorFlow等库训练并使用深度学习模型,很多教程甚至每周都会发布新的内容,例如Towards Data Science。
因此一旦你明确了自己打算如何使用深度学习技术,那么就可以努力让想法变为现实,虽然这一过程不那么简单,但只需要进行标准化的“开发”工作,例如按照本文介绍的各种教程按图索骥,结合自己的特定用途和/或数据进行修改,根据大家在StackOverflow等网站进行的讨论进行排错,这就可以实现了。这也可以避免很多麻烦的事情,例如并不需要成为(或者雇佣)能够从零开始自行开发神经网络的专家,而且还必须同时具备娴熟的软件工程经验。
这一系列随笔会试图解答上文提出的第一个问题:从较高层面概括谈谈深度学习技术到底能够做些什么,同时会为希望进一步了解的人提供一些资源,并/或通过展示代码进一步解决第二个问题。更具体来说,本文将涉及:
- 那些使用开源的架构和数据集所取得的最新成果。
- 那些促成这些成果的重要架构或其他见解。
- 如果要在你自己的项目中使用类似技术,着手进行前可能需要的最佳资源。
这些突破的共同之处
这些重大突破虽然涉及很多新的架构和创意,但都是从机器学习中常见的“监督式学习(Supervised Learning)”过程中涌现的。尤其是,都涉及下列步骤:
- 收集一个足够庞大,并且恰当的训练数据集。
- 搭建一个神经网络架构(一种复杂的方程组,可通过松散的方式模拟我们的大脑),网络中通常会包含数百万个名为“权重(Weight)”的参数。
- 将数据反复不断送入神经网络,并对每次迭代后神经网络的预测结果与正确结果进行比较,根据差异的具体程度和方向对神经网络的每个权重进行调整。
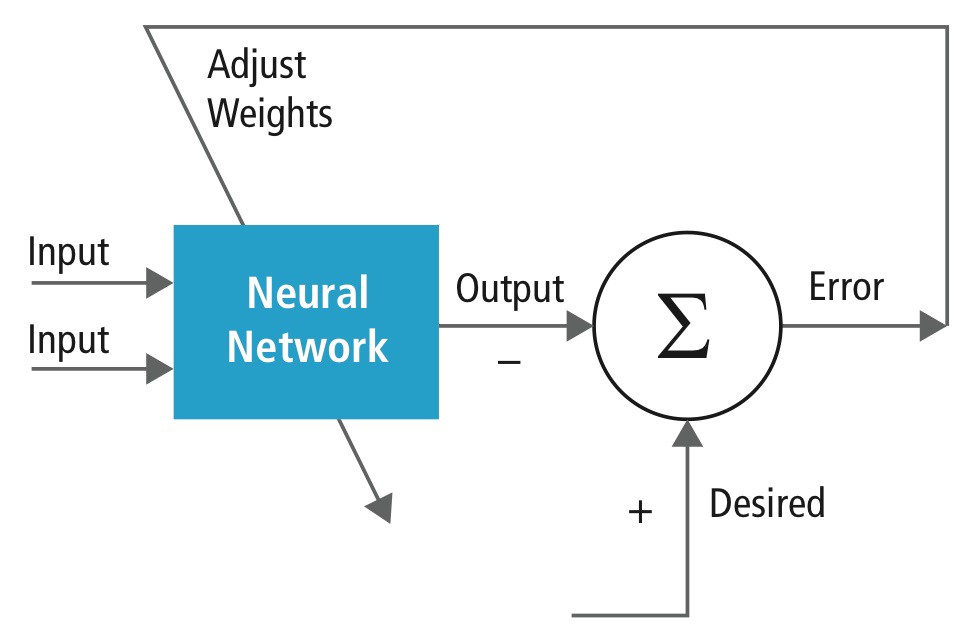
神经网络就是这样训练的:这一过程将重复很多很多次。图源。
类似的过程已经应用于很多领域,并且都已产生了非常“博学”的神经网络。每个领域我们将涉及:
- 训练模型所需的数据
- 所使用的模型架构
- 结果
1. 图片分类
神经网络通过训练可以识别图片中包含的物体。
所需数据
图片分类器的训练需要用到带标签的图片,其中每张图片均属于数量有限的类别中的一种或几种。例如,CIFAR 10数据就是训练图片分类器所用的一种标准化数据集,其中已正确添加了标签的图片共属于10个类别:

CIFAR-10数据中的图片示例。图源
深度学习架构
本文涉及的所有神经网络架构都源自对人类学着解决问题的方法所进行的思考。人类是如何检测图片的?当人类看到一张图片后,我们首先会查看一些最顶层的视觉特征,例如分支、鼻子或车轮。然而为了检测出这些特征,我们需要在潜意识里确定一些底层特征,例如颜色、线条以及其他形状。实际上,为了从原始像素中识别出人类可以认出的复杂特征,例如眼睛,我们必须首先检测像素特征,随后检测像素特征的特征,以此类推。
在深度学习技术诞生前,研究人员会尝试手工提取这些特征,并将其用于预测。就在深度学习技术诞生前一刻,研究人员还在试图使用技术手段(主要是SVM)找出这些手工提取的特征之间蕴含的复杂的非线性关系,据此才能确定图片中包含的到底是猫还是狗。

卷积神经网络(CNN)在每一层提取的特征。图源
现在,研究人员开发的神经网络架构可以从原始像素中学习这些特征,尤其是深度卷积神经网络更是非常适合此类任务。这些网络可以提取像素特征,随后提取像素特征的特征,以此类推,最终将结果送入常规的神经网络层(类似于逻辑回归)并做出最终预测。

针对ImageNet数据集中的图片进行预测的CNN架构预测结果范例。
随后我还将另行撰文,深入介绍如何将卷积神经网络用于图片分类。
重大突破
这些技术催生的结果在于,对于这些架构着力所要解决的问题,即图片分类,可以通过算法实现远胜于人类的效果。例如著名的ImageNet数据集已被广泛用作卷积架构的评测基准,经过训练的神经网络可以获得比人类更准确的图片分类效果:
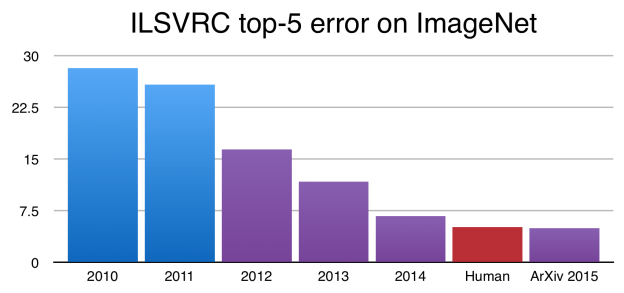
早在2015年,计算机经过训练已可实现比人类更出色的图中物体分类能力。图源
此外,研究人员已经明白如何拍摄一张图片但不立即进行分类,而是首先将图片中最有可能代表物体的区域划分为多个矩形,将每个矩形送入CNN架构,随后对图片中的每个物体进行分类,并在图片中框出每个物体的位置(这种做法也叫做“边界框[Bounding box]”):

使用“Mask R-CNN”进行物体检测。图源
这一系列过程可从技术上总称为“物体检测”,不过大部分最困难的环节都用到了“图片分类”技术。
资源
理论:如果要深入理解CNN的工作原理等理论知识,可参加Andrej Karpathy的Stanford课程。如果希望从更偏重数学知识的角度进一步了解,可参考Chris Olah有关卷积的文章。
代码:如果希望尽快着手构建图片分类器,可以参阅TensorFlow文档提供的这篇介绍范例。
2. 文本生成
神经网络通过训练可以模仿输入的内容生成文本。
所需数据
任何类型的文本均可,例如莎士比亚作品全集。
深度学习架构
神经网络可以对一系列元素中的下一个元素建模,可以查看序列中的上一个字符,并且对于指定的过往序列,还可以判断随后最有可能出现哪个字符。
解决这个问题所用的架构与图片分类所用的架构有很大差异。由于架构本身的差异,我们需要让网络学习不同的东西。之前,我们让网络学习图片中的重要特征,但现在,我们需要让网络关注字符序列并预测序列中的下一个字符。因此网络需要采取与图片分类不同的做法,通过某种方式持续追踪自己的“状态”。例如,如果看到的前序字符分别是“c-h-a-r-a-c-t-e”,此时网络应“存储”该信息,并预测下一个字符应该是“r”。
递归神经网络架构可以做到这一点:可在下一次迭代时将每个神经元的状态重新装入网络,借此学习整个序列(实际过程远比这个复杂,下文再详述)。
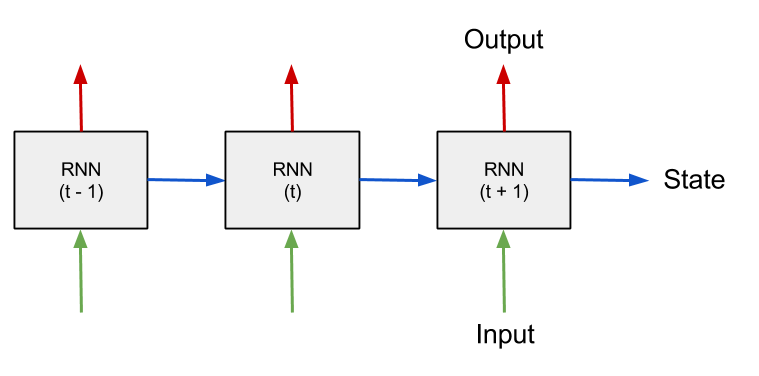
递归神经网络架构图。图源
然而为了真正胜任文本生成的任务,网络还必须能决定要在序列中“回顾”到多远的位置。有时候,例如正处在某个单词中间时,网络只需要“回顾”前面的几个字符就可以确定随后出现的字符,但有时候可能需要“回顾”很多字符才能做出决定,例如正处在句子末尾时。
有一种名叫“LSTM”(Long Short Term Memory,长短期记忆)的特殊Cell很适合这种任务。每个Cell可根据Cell本身的内部权重决定是否要“记住”还是“忘记”,而网络每看到一个新字符后,这个权重都会更新。
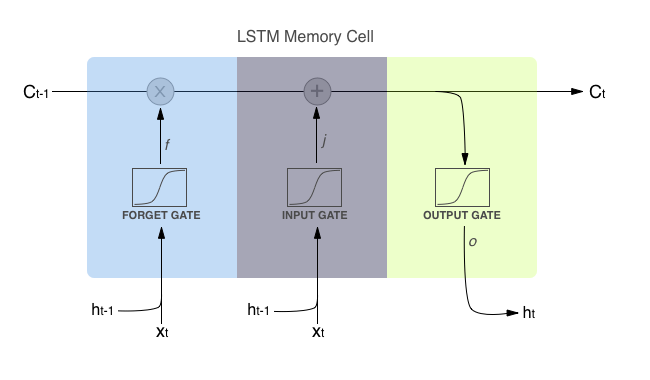
LSTM Cell的内部工作原理。图源
重大突破
简而言之:我们可以生成类似于“characature”这样的文本,不过需要解决一些拼写错误和其他问题,让生成的结果看起来是正确的英语。Andrej Karpathy的这篇文章举了几个有趣的例子,通过莎士比亚的剧本生成了Paul Graham风格的随笔。
这样的架构还可用于通过连续生成的横轴和纵轴坐标生成手写文字,这种做法与通过一个个字符生成语言的方法不谋而合。感兴趣的读者可以试试这个演示。

神经网络的手写笔迹。不过,真的还能叫“手”写吗?图源
随后我还将另行撰文,深入介绍递归神经网络和LSTM的工作原理。
资源
理论:Chris Olah有关LSTM的这篇文章是经典中的经典。同样经典的还有Andrej Karpathy这篇有关RNN的文章,此文介绍了RNN的功能和工作原理。
代码:这里提供了详细的指导,可以告诉我们如何着手构建端到端文本生成模型,以及数据的预处理操作。这个GitHub代码库可以帮助我们用训练好的RNN-LSTM模型生成手写文字。
3. 语言翻译
机器翻译(翻译为另一种语言的能力) 长久以来一直是人工智能领域研究人员最大的梦想。深度学习让这个梦想距离现实更进一步。
所需数据
使用不同语言写出的词句对。例如“I am a student”和“je suis étudiant”这样成对句子组成的数据集,可以训练神经网络实现英语和法语的互译。
深度学习架构
与其他深度学习架构类似,研究人员已经从“理论上”确定了计算机学习翻译语言的最佳方式,并开发出一种可以模仿这种方式的架构。对于语言翻译,从本质上来说需要将一句话(由一系列单词编码而成)翻译为所要表达的基本“含义”,随后将翻译出来的含义翻译为使用另一种语言的单词组成的序列。
句子从单词“转换”成含义的方式必须使用能胜任序列处理的架构,也就是上文提到的“递归神经网络”。

编码器-解码器架构示意图。图源
人们最初在2014年发现这种架构非常适合用于语言翻译,随后以此为基础在不同方向上进行了扩展,尤其是对“注意力”的处理,随后我们将单独撰文介绍。
重大突破
Google的这篇博客文章介绍了这种架构在语言翻译方面所实现的效果,这一技术让其他语言翻译技术显得大为逊色。当然,毕竟Google有大量资源,可以将丰富的训练数据用于这种任务!
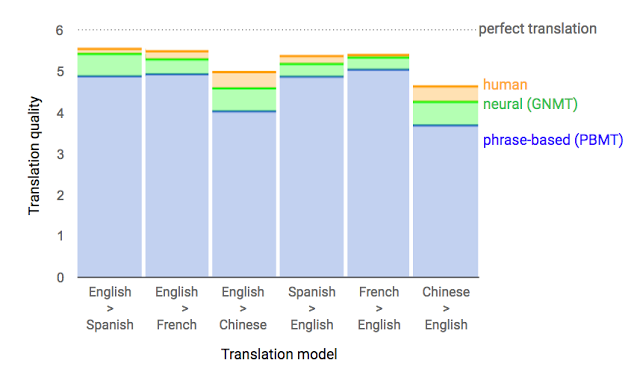
Google Sequence to Sequence模型的表现。图源
资源
代码和理论:Google发布了一篇非常精彩的Sequence to Sequence技术架构教程,可参阅这里。该教程概括介绍了Google Sequence to Sequence模型的大致目标和背后的理论,并介绍了TensorFlow编写相关代码的步骤。此外还本文还涉及“注意力”,这是对最基础的Sequence to Sequence架构进行的扩展,后续发布的另一篇有关Sequence to Sequence的文章将会详细介绍。
4. 生成对抗网络(Generative Adversarial Network)
神经网络通过训练可以生成看似属于特定类型(例如人脸),但并非实拍结果的图片。
所需数据
特性类型的图片,例如一大批人脸图片。
深度学习架构
GAN是一种让人惊讶并且非常重要的技术产物。 全球顶尖人工智能研究人员之一的Yann LeCun曾经说,这是“在他看来,机器学习领域过去十年里最有趣的创意”。借助这种技术,我们竟然可以生成看起来类似训练图片,但实际上并非训练集中实际内容的图片,例如生成看起来是人脸,但并非真正人脸的图片。这是通过同时训练两个神经网络实现的:一个网络负责生成看似逼真的假图片,一个负责检测图片是真是假。如果同时训练这两个网络,让它们“以相同速度”学习(这是GAN的构建过程中最困难的部分),那么负责生成假图片的网络就可以生成非常逼真的结果。
略微深入一些来看,这种技术是这样的:GAN中,我们需要训练的主网络叫做生成器(Generator),它会学习接受随机噪音矢量,并将其转换为逼真的图片。这种网络采取了与卷积神经网络相“反转”的结构,因此可称之为“逆卷积(deconvolutional)”架构。另一个负责区分真假图片的网络是一种卷积网络,这一点与图片分类所用的架构类似,这个网络也叫做“鉴别器(Discriminator)”。
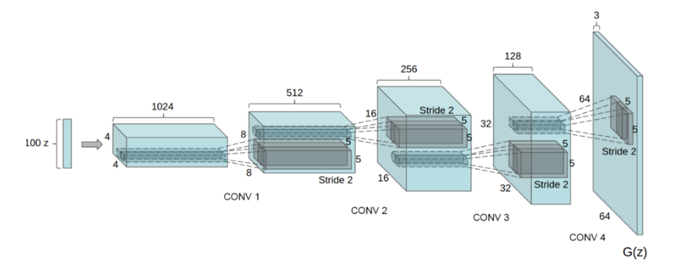
“生成器”的逆卷积架构。图源
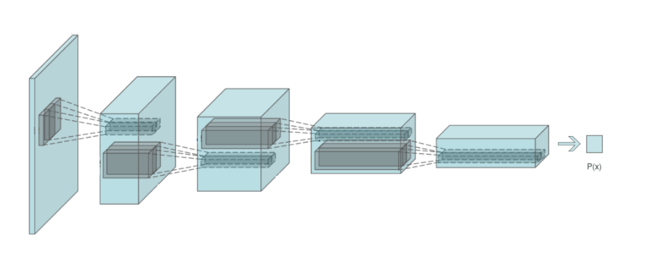
“鉴别器”的卷积架构。图源
GAN中的两个神经网络其实都是卷积神经网络,因为这些神经网络都很擅长从图片中提取特征。
重大突破和资源

GAN通过名人面孔数据集生成的图片。图源
代码:这个GitHub代码库提供了使用TensorFlow训练GAN的教程,同时还提供了一些由GAN生成的令人惊艳的结果图片,例如上图就来自该代码库。
理论:Irmak Sirer的这场讲话可以帮助大家对GAN入门,同时其中还涉及很多监督式学习概念,可以帮助大家理解上述结论。
最后,Arthur Juliani还用另一篇风趣直观的文章介绍了GAN,并提供了在TensorFlow中实现所用的代码。
总结
本文概括介绍了过去五年来,深度学习技术取得重大成果的几个领域。本文涉及的模型有很多开源的实现,因此任何人都可以下载一个“训练完成的”模型,并用于处理自己的数据,例如我们可以下载训练好的图片分类器,随后将其用于图片分类处理,或识别图片中框出的物体。由于大部分工作已经事先完成了,因此若要使用这些最前沿的技术,完全不需要自己成为“深度学习专家”,毕竟研究人员已经把最困难的工作搞定了,我们只需要从事最普通的“开发”工作,即可顺利使用他人创建的模型解决自己遇到的问题。
希望通过阅读本文,你已经对深度学习模型有了一些基本的深入了解,当然也更希望你能距离实用更近一步!
