@liyuj
2018-01-27T11:11:50.000000Z
字数 9046
阅读 4596
Apache-Ignite-2.3.0-中文开发手册
2.内存文件系统
2.1.内存文件系统
Ignite有一个独特的功能,叫做Ignite文件系统(IGFS),就是一个分布式的内存文件系统,IGFS提供了和Hadoop HDFS类似的功能,但是只在内存中。事实上,除了他自己的API,IGFS还实现了Hadoop的文件系统API,可以透明地加入Hadoop或者Spark的运行环境。
IGFS将每个文件的数据拆分成独立的数据块然后将他们保存进一个分布式内存缓存中。然而,与Hadoop HDFS不同,IGFS不需要一个name节点,它通过一个哈希函数自动确定文件数据的位置。
IGFS可以独立部署,也可以部署在HDFS之上,这时他成为了一个存储于HDFS中的文件的透明缓存层。
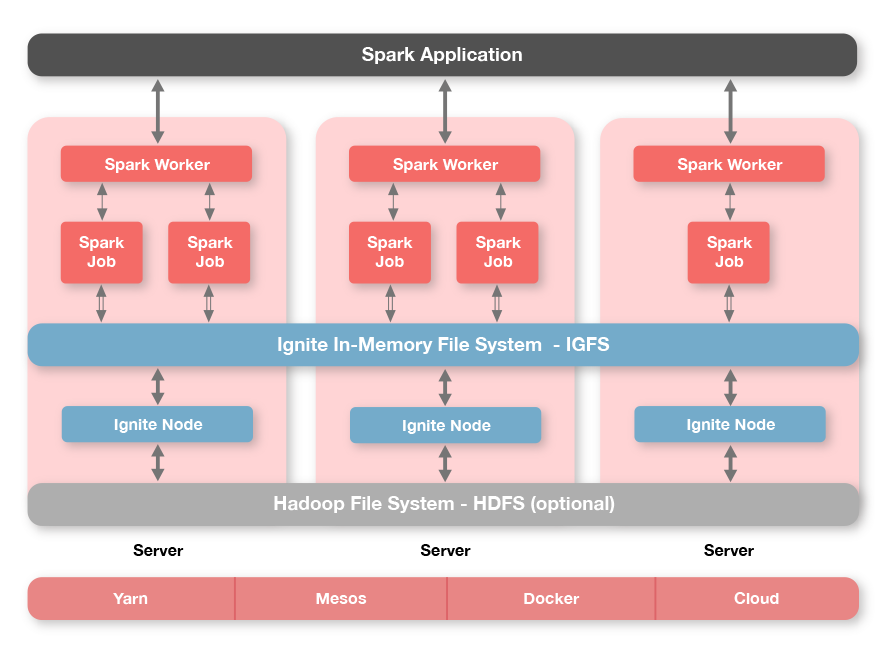
2.2.IGFS原生Ignite API
Ignite文件系统(IGFS)是一个内存级的文件系统,他可以在现有的缓存基础设施基础上对文件以及文件夹进行操作。
IGFS既可以作为一个纯粹的内存文件系统,也可以委托给其他的文件系统(比如各种Hadoop文件系统实现)作为一个缓存层。
另外,IGFS提供了在文件系统数据上执行MapReduce任务的API。
2.2.1.IgniteFileSystem
IgniteFileSystem接口是一个进入Ignite文件系统实现的入口,他提供了正常的文件系统操作的方法,比如create,delete,mkdirs等等,以及执行MapReduce任务的方法。
Ignite ignite = Ignition.ignite();// Obtain instance of IGFS named "myFileSystem".IgniteFileSystem fs = ignite.fileSystem("myFileSystem");
IGFS可以通过Spring XML文件或者编程的方式进行配置。
XML:
<bean class="org.apache.ignite.configuration.IgniteConfiguration">...<property name="fileSystemConfiguration"><list><bean class="org.apache.ignite.configuration.FileSystemConfiguration"><!-- Distinguished file system name. --><property name="name" value="myFileSystem" /></bean></list></property></bean>
Java:
IgniteConfiguration cfg = new IgniteConfiguration();...FileSystemConfiguration fileSystemCfg = new FileSystemConfiguration();fileSystemCfg.setName("myFileSystem");fileSystemCfg.setMetaCacheName("myMetaCache");fileSystemCfg.setDataCacheName("myDataCache");...cfg.setFileSystemConfiguration(fileSystemCfg);
2.2.2.文件以及目录操作
IgniteFileSystem fs = ignite.fileSystem("myFileSystem");// Create directory.IgfsPath dir = new IgfsPath("/myDir");fs.mkdirs(dir);// Create file and write some data to it.IgfsPath file = new IgfsPath(dir, "myFile");try (OutputStream out = fs.create(file, true)) {out.write(...);}// Read from file.try (InputStream in = fs.open(file)) {in.read(...);}// Delete directory.fs.delete(dir, true);
2.3.IGFS作为Hadoop文件系统
Ignite Hadoop加速器提供了一个叫做IgniteHadoopFileSystem的Hadoop兼容IGFS实现,Hadoop可以以即插即用的形式运行在这个文件系统上,然后显著地减少了I/O和改善了延迟和吞吐量。
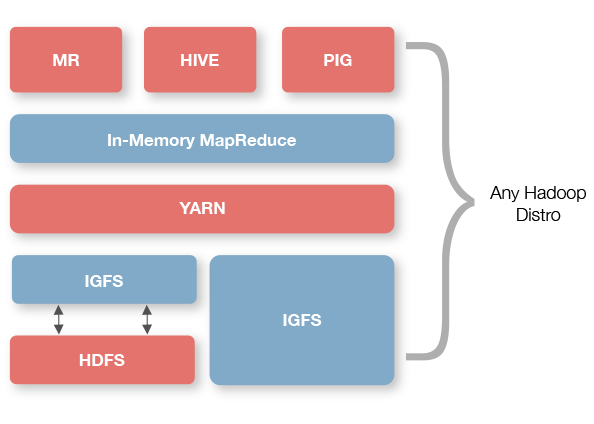
2.3.1.配置Ignite
Ignite Hadoop加速器在Ignite集群内部执行文件系统操作,必须满足几个前置条件:
1)IGNITE_HOME环境变量必须设置以及指向Ignite的安装根目录。
2)每个节点都必须在类路径上包含Hadoop的jar文件。可以参照各个Hadoop发行版的Ignite安装向导来了解详细信息。
3)IGFS必须在集群节点上进行了配置。可以参照13.2.IGFS原生Ignite API章节来了解如何进行配置。
4)要让IGFS接收来自Hadoop的请求,需要配置一个端点(默认的配置文件是${IGNITE_HOME}/config/default-config.xml)。Ignite提供两种类型的端点:
shmem:工作于共享内存(Windows不可用)tcp:工作于标准Socket API
如果与Ignite节点是在同一台机器上执行文件系统操作那么共享内存端点是推荐的做法。注意如果在共享内存通信模式下port参数也可以用于执行客户端-服务端握手的初始化。
XML:
<bean class="org.apache.ignite.configuration.FileSystemConfiguration"><property name="name" value="myIgfs"/>...<property name="ipcEndpointConfiguration"><bean class="org.apache.ignite.igfs.IgfsIpcEndpointConfiguration"><property name="type" value="SHMEM"/><property name="port" value="12345"/></bean></property>....</bean>
Java:
FileSystemConfiguration fileSystemCfg = new FileSystemConfiguration();...IgfsIpcEndpointConfiguration endpointCfg = new IgfsIpcEndpointConfiguration();endpointCfg.setType(IgfsEndpointType.SHMEM);...fileSystemCfg.setIpcEndpointConfiguration(endpointCfg);
TCP端点可以用于或者Ignite节点位于其他机器或者共享内存不可用的场合。
XML:
<bean class="org.apache.ignite.configuration.FileSystemConfiguration"><property name="name" value="myIgfs"/>...<property name="ipcEndpointConfiguration"><bean class="org.apache.ignite.igfs.IgfsIpcEndpointConfiguration"><property name="type" value="TCP"/><property name="host" value="myHost"/><property name="port" value="12345"/></bean></property>....</bean>
Java:
FileSystemConfiguration fileSystemCfg = new FileSystemConfiguration();...IgfsIpcEndpointConfiguration endpointCfg = new IgfsIpcEndpointConfiguration();endpointCfg.setType(IgfsEndpointType.TCP);endpointCfg.setHost("myHost");...fileSystemCfg.setIpcEndpointConfiguration(endpointCfg);
如果host参数未设置,默认值是127.0.0.1。
如果port参数未设置,默认值是10500。
如果ipcEndpointConfiguration未设置,那么对于Linux系统共享内存端点会使用默认的端口,对于WindowsTCP端口会使用默认的端口。
2.3.2.运行Ignite
配置Ignite节点后,通过如下方式可以启动:
$ bin/ignite.sh
2.3.3.配置Hadoop
要使用Ignite作业跟踪器运行Hadoop作业,需要满足如下的前提条件:
1)IGNITE_HOME环境变量必须设置以及指向Ignite的安装根目录。
2)Hadoop必须在类路径上包含Ignite jar文件:${IGNITE_HOME}\libs\ignite-core-[version].jar和${IGNITE_HOME}\libs\hadoop\ignite-hadoop-[version].jar。
这个可以通过若干种方式实现:
- 将这几个jar文件加入
HADOOP_CLASSPATH环境变量; - 将这些jar文件拷贝或者建立符号链接到Hadoop存放共享库的文件夹中,可以参照Ignite针对各个Hadoop发行版的安装向导来了解详细信息;
3)对于将要执行的活动必须配置Ignite的Hadoop加速器文件系统,至少要提供文件系统类的全限定名;
XML:
<configuration>...<property><name>fs.igfs.impl</name><value>org.apache.ignite.hadoop.fs.v1.IgniteHadoopFileSystem</value></property>...</configuration>
如果要将Ignite文件系统设置为默认的文件系统,可以增加如下的属性:
XML:
<configuration>...<property><name>fs.default.name</name><value>igfs://myIgfs@/</value></property>...</configuration>
这里的value是一个配有IGFS的Ignite节点的端点URL,本章节的末尾会提供这个URL的规则。
如何将配置传递给Hadoop作业有若干种方式:
第一,可以创建独立的带有这些配置属性的core-site.xml然后用于作业的运行;
第二,可以通过编程的方式为特定的作业设置这些属性。
Java:
Configuration conf = new Configuration();...conf.set("fs.igfs.impl", "org.apache.ignite.hadoop.fs.v1.IgniteHadoopFileSystem");conf.set("fs.default.name", "igfs://myIgfs@/");...Job job = new Job(conf, "word count");
第三,在Hadoop环境中可以修改默认的core-site.xml中的fs.igfs.impl属性。
警告
在默认的core-site.xml文件中不要修改fs.default.name属性,因为HDFS无法启动。可以使用全限定路径访问IGFS,比如这样,igfs://myIgfs@/path/to/file,而不是/path/to/file。
2.3.4.运行Hadoop
如何运行一个作业取决于对Hadoop如何进行配置。
如果创建了独立的core-site.xml:
hadoop --config [path_to_config] [arguments]
注意使用定制的Hadoop启动器脚本可以轻易的引用一个单独的Hadoop配置目录和Ignite库,比如hadoop-ignited:
export IGNITE_HOME=[path_to_ignite]# Add necessary Ignite libraries to the Hadoop client classpath:VERSION=[ignite_version_identifier]export HADOOP_CLASSPATH=${IGNITE_HOME}/libs/ignite-core-${VERSION}.jar:${IGNITE_HOME}/libs/ignite-hadoop/ignite-hadoop-${VERSION}.jar:${IGNITE_HOME}/libs/ignite-shmem-1.0.0.jarhadoop --config [path_to_config_directory] "${@}"
使用IGFS通过这种方式运行一个Hadoop作业,需要运行命令hadoop-ignited ...,如果要在默认的Hadoop上运行同样的作业,只需要使用同样的参数运行hadoop ...。
如果通过编程方式启动一个作业,那么提交它:
Java:
...Job job = new Job(conf, "word count");...job.submit();
2.3.5.文件系统URI
访问IGFS的URI具有如下的结构:igfs://[name]@[host]:[port]/,这里:
name:要连接的IGFS的名字(通过FileSystemConfiguration.setName(...))指定的);host:可选的Ignite端点主机(IgfsIpcEndpointConfiguration.host),默认为127.0.0.1;port:可选的Ignite端点端口 (IgfsIpcEndpointConfiguration.port),默认为10500;
URI示例:
igfs://myIgfs@myHost:12345/:连接到运行在指定主机和端口上的名为myIgfs的IGFS;igfs://myIgfs@myHost/:连接到运行在指定主机和默认端口上的名为myIgfs的IGFS;igfs://myIgfs@/:连接到运行在localhost和默认端口上的名为myIgfs的IGFS;igfs://myIgfs@:12345/:连接到运行在localhost和指定端口上的名为myIgfs的IGFS;
2.3.6.高可用IGFS客户端
高可用(HA)IGFS客户端是基于Ignite客户端节点的,Ignite客户端节点是在执行Hadoop作业的主机上启动的。常规的TCP客户端接入上述的集群后,在重连后是不支持已经打开的IGFS I/O流的,而Ignite的客户端节点是没有这个问题的。
要配置使用Ignite的客户端节点接入集群,需要为Hadoop作业配置属性fs.igfs..config_path,值为Ignite节点配置的路径:
Configuration conf = new Configuration();...conf.set("fs.default.name", "igfs://myIgfs@/");conf.set("fs.igfs.myIgfs.config_path", "ignite/config/client.xml");...Job job = new Job(conf, "word count");
服务端节点的XML配置文件这里也是可以使用的,强制使用客户端模式启动主要是为了IGFS连接。
2.4.Hadoop文件系统缓存
Ignite Hadoop加速器包含了一个IGFS二级文件系统实现IgniteHadoopIgfsSecondaryFileSystem,它可以对任何Hadoop文件系统实现进行通读和通写。
要使用二级文件系统,可以在IGFS配置中指定或者通过编程的方式实现。
XML:
<bean class="org.apache.ignite.configuration.FileSystemConfiguration">...<property name="secondaryFileSystem"><bean class="org.apache.ignite.hadoop.fs.IgniteHadoopIgfsSecondaryFileSystem"><constructor-arg value="hdfs://myHdfs:9000"/></bean></property></bean>
Java:
ileSystemConfiguration fileSystemCfg = new FileSystemConfiguration();...IgniteHadoopIgfsSecondaryFileSystem hadoopFileSystem = new IgniteHadoopIgfsSecondaryFileSystem("hdfs://myHdfs:9000");...fileSystemCfg.setSecondarFileSystem(hadoopFileSystem);
在Ignite节点启动过程中,Ignite默认不会在类路径中包含Hadoop的库文件,如果决定使用HDFS作为一个二级文件系统,那么需要提前按照如下步骤进行操作:
- 使用Ignite发行版的
Apache Ignite Hadoop Accelerator版本(如果自行构建发行版可以使用-Dignite.edition=hadoop); - 如果使用Apache的Hadoop发行版,启动一个Ignite节点之前需要设置HADOOP_HOME环境变量。如果使用其他的Hadoop发行版(HDP, Cloudera, BigTop等),一定确保
/etc/default/hadoop文件存在并且有适当的内容。
作为一个选择,可以在Ignite节点类路径中手工添加必要的Hadoop依赖,这些依赖的groupId是org.apache.hadoop,他们已经在modules/hadoop/pom.xml文件中列出,当前,他们是:
- hadoop-annotations
- hadoop-auth
- hadoop-common
- hadoop-hdfs
- hadoop-mapreduce-client-common
- hadoop-mapreduce-client-core
2.5.IGFS模式
IGFS可以工作于四种操作模式:PRIMARY,PROXY,DUAL_SYNC和DUAL_ASYNC。这些模式既可以配置整个文件系统,也可以配置特定的路径。他们是在IgfsMode枚举中定义的,默认文件系统操作于DUAL_ASYNC模式。
如果未配置二级文件系统,配置成DUAL_SYNC或者DUAL_ASYNC模式的所有路径都会回退到PRIMARY模式。
XML:
<bean class="org.apache.ignite.configuration.FileSystemConfiguration">...<!-- Set default mode. --><property name="defaultMode" value="DUAL_SYNC" /><!-- Configure '/tmp' and all child paths to work in PRIMARY mode. --><property name="pathModes"><map><entry key="/tmp/.*" value="PRIMARY"/></map></property></bean>
Java:
FileSystemConfiguration fileSystemCfg = new FileSystemConfiguration();...fileSystemCfg.setDefaultMode(IgfsMode.DUAL_SYNC);...Map<String, IgfsMode> pathModes = new HashMap<>();pathModes.put("/tmp/.*", IgfsMode.PRIMARY);fileSystemCfg.setPathModes(pathModes);
2.5.1.PRIMARY模式
该模式中,IGFS作为基本的独立分布式内存文件系统,不会使用二级文件系统。
2.5.2.PROXY模式
IGFS对于工作于PROXY模式的路径的操作是受限的,在这些路径上的任何操作都会抛出异常。
2.5.3.DUAL_SYNC模式
该模式中,当数据被请求并且还没有缓存在内存中时,IGFS会在二级文件系统中进行同步地通读,当数据在IGFS中被更新/创建时对其进行同步地通写。实际上,该模式下IGFS是在二级文件系统之上作为一个智能缓存层的。
2.5.4.DUAL_ASYNC模式
与DUAL_SYNC相同,但是对于二级文件系统的读写是异步方式执行的。
在IGFS更新和二级文件系统更新之间存在一个滞后,但是这个模式下更新的性能显著好于DUAL_SYNC模式。
