@liyuj
2017-09-24T12:32:10.000000Z
字数 52729
阅读 11724
Apache-Ignite-2.2.0-中文开发手册
4.SQL网格
4.1.SQL网格
Ignite提供了分布式内存数据库的功能,它水平可扩展,容错并且兼容SQL的ANSI-99标准。它支持完整的DML命令,包括SELECT, UPDATE, INSERT, MERGE以及DELETE,同时它还提供了和分布式数据库有关的DDL命令的一个子集。
基于固化内存架构,数据集和索引可以存储在内存中,也可以存储在磁盘上,这样就可以跨越不同的存储层执行分布式的SQL操作,使得在支持将数据固化到磁盘的前提下获得内存级的性能。

SQL网格使得开发者与Ignite的交互不仅仅可以使用原生的,面向Java、C++和.NET的API,还可以通过JDBC或者ODBC API,这提供了真正的语言层面的跨平台连接性,比如PHP,Ruby以及其他的。
4.2.入门
4.2.1.摘要
目前,对于数据库管理系统的数据定义、数据操作和数据查询来说,SQL仍然是非常受欢迎的语言。虽然SQL通常是与关系型数据库系统相关的,但是目前很多广泛使用的非关系型数据库系统也对SQL提供了不同程度的支持。另外还有大量的基于SQL的工具来提供可视化、报表和商业智能,这是一个很大的市场,这些都使用标准技术比如ODBC或者JDBC来连接数据源。
Ignite支持数据定义语言(DDL)语句,可以在运行时创建和删除表和索引,还可以支持数据操作语言(DML)来执行查询,这些不管是Ignite的原生SQL API还是ODBC和JDBC驱动,都是支持的。
在下面的示例中,会使用一个包含两个表的模式,这些表会用于保存城市以及居住在那里的人的信息,假定一个城市有很多的人,并且人只会居住于一个城市,这是一个一对多(1:m)的关系。
4.2.2.连接
作为入门来说,可以使用一个SQL工具,在后面的SQL工具章节中会有一个示例来演示如何配置SQL工具。
如果希望从源代码入手,下面的示例代码会演示如果通过JDBC以及ODBC驱动来获得一个连接:
JDBC:
// Register JDBC driverClass.forName("org.apache.ignite.IgniteJdbcThinDriver");// Open JDBC connectionConnection conn = DriverManager.getConnection("jdbc:ignite:thin://127.0.0.1/");
ODBC:
// Combining connect stringstd::string connectStr = "DRIVER={Apache Ignite};SERVER=localhost;PORT=10800;SCHEMA=Person;";SQLCHAR outstr[ODBC_BUFFER_SIZE];SQLSMALLINT outstrlen;// Connecting to ODBC serverSQLRETURN ret = SQLDriverConnect(dbc, NULL, reinterpret_cast<SQLCHAR*>(&connectStr[0]), static_cast<SQLSMALLINT>(connectStr.size()),outstr, sizeof(outstr), &outstrlen, SQL_DRIVER_COMPLETE);
JDBC连接会使用thin模式驱动然后接入本地主机(127.0.0.1),一定要确保ignite-core.jar位于应用或者工具的类路径中,具体信息可以查看JDBC驱动相关的章节。
ODBC连接也是接入本地localhost,端口是10800,具体可以查看ODBC驱动相关的文档。
4.2.3.创建表
当前,创建的每个表都会位于PUBLIC模式,在模式和索引章节会有更详细的信息。
下面的示例代码会创建City和Person表:
SQL:
CREATE TABLE City (id LONG PRIMARY KEY, name VARCHAR)WITH "template=replicated"CREATE TABLE Person (id LONG, name VARCHAR, city_id LONG, PRIMARY KEY (id, city_id))WITH "backups=1, affinityKey=city_id"
JDBC:
// Create database tablestry (Statement stmt = conn.createStatement()) {// Create table based on REPLICATED templatestmt.executeUpdate("CREATE TABLE City (" +" id LONG PRIMARY KEY, name VARCHAR) " +" WITH \"template=replicated\"");// Create table based on PARTITIONED template with one backupstmt.executeUpdate("CREATE TABLE Person (" +" id LONG, name VARCHAR, city_id LONG, " +" PRIMARY KEY (id, city_id)) " +" WITH \"backups=1, affinityKey=city_id\"");}
ODBC:
SQLHSTMT stmt;// Allocate a statement handleSQLAllocHandle(SQL_HANDLE_STMT, dbc, &stmt);// Create table based on REPLICATED templateSQLCHAR query[] = "CREATE TABLE City (""id LONG PRIMARY KEY, name VARCHAR) ""WITH \"template=replicated\"";SQLSMALLINT queryLen = static_cast<SQLSMALLINT>(sizeof(query));SQLRETURN ret = SQLExecDirect(stmt, query, queryLen);
CREATE TABLE命令执行之后,会做如下的工作:
- 会自动使用表名创建一个分布式缓存,它会用于存储City和Person类型的对象;
- 会定义一个带有所有参数的SQL表;
- 数据以键-值记录的形式存储,主键列会用作存储对象的键,剩下的字段属于值,这就意味着可以使用键值API来处理数据。
和分布式缓存相关的参数是通过WITH子句传递的,如果忽略了WITH子句,那么缓存会使用CacheConfiguration对象的默认参数来创建。
很多时候将不同的缓存键并置在一起非常有用,通常,业务逻辑需要访问不止一个缓存键,将他们并置在一起会确保具有相同affinityKey的所有键会被缓存在同一个节点上,这样就不需要从远程获取数据以避免耗时的网络开销。
在本示例中,有City和Person对象,并且希望并置Person对象及其居住的City对象,要做到这一点,就像上例所示,使用了WITH子句并且指定了affinityKey=city_id。
4.2.4.创建索引
定义索引可以加快查询的速度,下面是创建索引的示例:
SQL:
CREATE INDEX idx_city_name ON City (name)CREATE INDEX idx_person_name ON Person (name)
JDBC:
// Create indexestry (Statement stmt = conn.createStatement()) {// Create an index on the City tablestmt.executeUpdate("CREATE INDEX idx_city_name ON City (name)");// Create an index on the Person tablestmt.executeUpdate("CREATE INDEX idx_person_name ON Person (name)");}
ODBC:
SQLHSTMT stmt;// Allocate a statement handleSQLAllocHandle(SQL_HANDLE_STMT, dbc, &stmt);// Create an index on the City tableSQLCHAR query[] = "CREATE INDEX idx_city_name ON City (name)";SQLSMALLINT queryLen = static_cast<SQLSMALLINT>(sizeof(query));SQLRETURN ret = SQLExecDirect(stmt, query, queryLen);
4.2.5.插入数据
对数据进行查询之前,需要在两个表中加载部分数据,下面是如何往表中插入数据的示例:
SQL:
INSERT INTO City (id, name) VALUES (1, 'Forest Hill');INSERT INTO City (id, name) VALUES (2, 'Denver');INSERT INTO City (id, name) VALUES (3, 'St. Petersburg');INSERT INTO Person (id, name, city_id) VALUES (1, 'John Doe', 3);INSERT INTO Person (id, name, city_id) VALUES (2, 'Jane Roe', 2);INSERT INTO Person (id, name, city_id) VALUES (3, 'Mary Major', 1);INSERT INTO Person (id, name, city_id) VALUES (4, 'Richard Miles', 2);
JDBC:
// Populate City table
try (PreparedStatement stmt =
conn.prepareStatement("INSERT INTO City (id, name) VALUES (?, ?)")) {
stmt.setLong(1, 1L);
stmt.setString(2, "Forest Hill");
stmt.executeUpdate();
stmt.setLong(1, 2L);
stmt.setString(2, "Denver");
stmt.executeUpdate();
stmt.setLong(1, 3L);
stmt.setString(2, "St. Petersburg");
stmt.executeUpdate();
}
// Populate Person table
try (PreparedStatement stmt =
conn.prepareStatement("INSERT INTO Person (id, name, city_id) VALUES (?, ?, ?)")) {
stmt.setLong(1, 1L);
stmt.setString(2, "John Doe");
stmt.setLong(3, 3L);
stmt.executeUpdate();
stmt.setLong(1, 2L);
stmt.setString(2, "Jane Roe");
stmt.setLong(3, 2L);
stmt.executeUpdate();
stmt.setLong(1, 3L);
stmt.setString(2, "Mary Major");
stmt.setLong(3, 1L);
stmt.executeUpdate();
stmt.setLong(1, 4L);
stmt.setString(2, "Richard Miles");
stmt.setLong(3, 2L);
stmt.executeUpdate();
}
ODBC:
SQLHSTMT stmt;// Allocate a statement handleSQLAllocHandle(SQL_HANDLE_STMT, dbc, &stmt);// Populate City tableSQLCHAR query1[] = "INSERT INTO City (id, name) VALUES (?, ?)";SQLRETURN ret = SQLPrepare(stmt, query1, static_cast<SQLSMALLINT>(sizeof(query1)));char name[1024];int32_t key = 1;strncpy(name, "Forest Hill", sizeof(name));ret = SQLExecute(stmt);key = 2;strncpy(name, "Denver", sizeof(name));ret = SQLExecute(stmt);key = 3;strncpy(name, "Denver", sizeof(name));ret = SQLExecute(stmt);// Populate Person tableSQLCHAR query2[] = "INSERT INTO Person (id, name, city_id) VALUES (?, ?, ?)";ret = SQLPrepare(stmt, query2, static_cast<SQLSMALLINT>(sizeof(query2)));key = 1;strncpy(name, "John Doe", sizeof(name));int32_t city_id = 3;key = 2;strncpy(name, "Jane Roe", sizeof(name));city_id = 2;key = 3;strncpy(name, "Mary Major", sizeof(name));city_id = 1;key = 4;strncpy(name, "Richard Miles", sizeof(name));city_id = 2;
4.2.6.查询数据
数据加载之后,就可以执行查询了。下面就是如何查询数据的示例,其中包括两个表之间的关联:
SQL:
SELECT *FROM CitySELECT nameFROM CityWHERE id = 1SELECT p.name, c.nameFROM Person p, City cWHERE p.city_id = c.id
JDBC:
// Get datatry (Statement stmt = conn.createStatement()) {try (ResultSet rs =stmt.executeQuery("SELECT p.name, c.name " +" FROM Person p, City c " +" WHERE p.city_id = c.id")) {System.out.println("Query results:");while (rs.next())System.out.println(">>> " +rs.getString(1) +", " +rs.getString(2));}}
ODBC:
SQLHSTMT stmt;// Allocate a statement handleSQLAllocHandle(SQL_HANDLE_STMT, dbc, &stmt);// Get dataSQLCHAR query[] = "SELECT p.name, c.name ""FROM Person p, City c ""WHERE p.city_id = c.id";SQLSMALLINT queryLen = static_cast<SQLSMALLINT>(sizeof(query));SQLRETURN ret = SQLExecDirect(stmt, query, queryLen);
4.2.7.修改数据
有时数据是需要修改的,这时就可以执行修改操作来修改已有的数据,下面是如何修改数据的示例:
SQL:
UPDATE CitySET name = 'Foster City'WHERE id = 2
JDBC:
// Updatetry (Statement stmt = conn.createStatement()) {// Update Citystmt.executeUpdate("UPDATE City SET name = 'Foster City' WHERE id = 2");}
ODBC:
SQLHSTMT stmt;// Allocate a statement handleSQLAllocHandle(SQL_HANDLE_STMT, dbc, &stmt);// Update CitySQLCHAR query[] = "UPDATE City SET name = 'Foster City' WHERE id = 2"SQLSMALLINT queryLen = static_cast<SQLSMALLINT>(sizeof(query));SQLRETURN ret = SQLExecDirect(stmt, query, queryLen);
4.2.8.删除数据
可能还需要从数据库中删除数据,下面是删除数据的示例:
SQL:
DELETE FROM PersonWHERE name = 'John Doe'
JDBC:
// Delete
try (Statement stmt = conn.createStatement()) {
// Delete from Person
stmt.executeUpdate("DELETE FROM Person WHERE name = 'John Doe'");
}
ODBC:
SQLHSTMT stmt;// Allocate a statement handleSQLAllocHandle(SQL_HANDLE_STMT, dbc, &stmt);// Delete from PersonSQLCHAR query[] = "DELETE FROM Person WHERE name = 'John Doe'"SQLSMALLINT queryLen = static_cast<SQLSMALLINT>(sizeof(query));SQLRETURN ret = SQLExecDirect(stmt, query, queryLen);
4.2.9.示例
GitHub上有和这个入门文档有关的完整代码。
4.3.分布式DDL
4.3.1.摘要
Ignite支持通过数据定义语言(DDL)语句在运行时创建和删除表和索引,原生的Ignite SQL API还有JDBC以及ODBC驱动也可以用于SQL模式的修改。
全功能DDL支持
在未来的Ignite版本中,还会支持额外的、广泛使用的DDL语句。
4.3.2.创建表
语法:
CREATE TABLE [IF NOT EXISTS] tableName (tableColumn [, tableColumn]...[, PRIMARY KEY (columnName [, columnName]...)] )[WITH "paramName=paramValue [,paramName=paramValue]..."]
tableColumn := columnName columnType [PRIMARY KEY]
目前,通过这种方式创建的表,都位于PUBLIC模式。
下面是创建表的示例:
SQL:
CREATE TABLE IF NOT EXISTS Person (age int, id int, name varchar, company varchar,PRIMARY KEY (name, id))WITH "template=replicated,backups=5,affinitykey=id"
Java:
IgniteCache<PersonKey, Person> cache = ignite.cache("Person");SqlFieldsQuery query = new SqlFieldsQuery("CREATE TABLE IF NOT EXISTS Person (" +" age int, id int, name varchar, company varchar," +" PRIMARY KEY (name, id))" +" WITH \"template=replicated,backups=5,affinitykey=id\"");cache.query(query).getAll();
JDBC:
// Register JDBC driverClass.forName("org.apache.ignite.IgniteJdbcThinDriver");// Open JDBC connectionConnection conn = DriverManager.getConnection("jdbc:ignite:thin://127.0.0.1/");try (Statement stmt = conn.createStatement()) {stmt.execute("CREATE TABLE IF NOT EXISTS Person (" +" age int, id int, name varchar, company varchar," +" PRIMARY KEY (name, id))" +" WITH \"template=replicated,backups=5,affinitykey=id\"");}
PRIMARY KEY列也可以列定义中指定:
SQL:
CREATE TABLE Person (age int, id int PRIMARY KEY, name varchar, company varchar)WITH "atomicity=transactional,cachegroup=somegroup"
Java:
IgniteCache<PersonKey, Person> cache = ignite.cache("Person");SqlFieldsQuery query = new SqlFieldsQuery("CREATE TABLE Person (" +" age int, id int PRIMARY KEY, name varchar, company varchar)" +" WITH \"atomicity=transactional,cachegroup=somegroup\"");cache.query(query).getAll();
JDBC:
// Register JDBC driverClass.forName("org.apache.ignite.IgniteJdbcThinDriver");// Open JDBC connectionConnection conn = DriverManager.getConnection("jdbc:ignite:thin://127.0.0.1/");try (Statement stmt = conn.createStatement()) {stmt.execute("CREATE TABLE Person (" +" age int, id int PRIMARY KEY, name varchar, company varchar)" +" WITH \"atomicity=transactional,cachegroup=somegroup\"");}
CREATE TABLE命令执行之后,会做如下的工作:
- 会使用表名作为名字自动地创建一个分布式缓存,它会用于存储Person类型的对象,Person类型可以对应于一个特定的Java、.NET、C++或者二进制对象;
- 会定义带有所有参数的SQL表;
- 数据以键-值对的形式存储,主键列会用作对象的键,剩下的字段属于值,这意味着也可以使用键-值API来处理数据。
和分布式缓存有关的参数是通过语句的WITH子句传递的,如果忽略了WITH子句,那么缓存会以CacheConfiguration对象的默认参数集进行创建。
在上面的示例中,对于Person表,Ignite创建了一个有一个备份数据的分布式缓存,city_id作为关喜建,这些扩展参数是Ignite特有的,要给这个表设定其他的缓存参数的话,可以使用template参数,然后提供已经注册的缓存配置(通过XML或者代码)。
扩展参数
下面是语句中的WITH子句可用的参数列表:
| 参数 | 值 |
|---|---|
| TEMPLATE= | Ignite中已经注册的大小写敏感的缓存模板名,如果给定名的模板不存在,那么会使用TEMPLATE=PARTITIONED或者TEMPLATE=REPLICATED来创建对应模式的缓存,剩下的参数会使用CacheConfiguration对象的默认值,模板是通过Ignite.addCacheConfiguration方法注册的。 |
| BACKUPS=<备份数量> | 任意可能的数值。 |
| ATOMICITY=<原子化模式> | ATOMIC或者TRANSACTIONAL。 |
| CACHEGROUP=<组名> | 任意缓存组名字。 |
| AFFINITYKEY=<关系键列名> | CREATE TABLE中的列名集合,应该是PRIMARY KEY约束的一部分。 |
附加CREATE TABLE约束
在未来的Ignite版本中,CREATE TABLE命令会支持NOT NULL、AUTO INCREMENT以及其他的约束和功能。
4.3.3.删除表
语法:
DROP TABLE [IF EXISTS] tableName
下面是删除表的示例:
SQL:
DROP TABLE IF EXISTS "Person"
Java:
IgniteCache<PersonKey, Person> cache = ignite.cache("Person");SqlFieldsQuery query = new SqlFieldsQuery("DROP TABLE IF EXISTS \"Person\"");cache.query(query).getAll();
JDBC:
// Register JDBC driverClass.forName("org.apache.ignite.IgniteJdbcThinDriver");// Open JDBC connectionConnection conn = DriverManager.getConnection("jdbc:ignite:thin://127.0.0.1/");try (Statement stmt = conn.createStatement()) {stmt.execute("DROP TABLE IF EXISTS \"Person\"");}
4.3.4.创建索引
语法:
CREATE [SPATIAL] INDEX [IF NOT EXISTS] indexName ON tableName (indexColumn, ...)indexColumn := columnName [ASC|DESC]
这里tableName是存储在分布式缓存中的类型名。
下面是创建简单有序索引的示例:
SQL:
CREATE INDEX idx_person_name ON Person (name)
Java:
IgniteCache<PersonKey, Person> cache = ignite.cache("Person");SqlFieldsQuery query = new SqlFieldsQuery("CREATE INDEX idx_person_name ON Person (name)");cache.query(query).getAll();
JDBC:
// Register JDBC driverClass.forName("org.apache.ignite.IgniteJdbcThinDriver");// Open JDBC connectionConnection conn = DriverManager.getConnection("jdbc:ignite:thin://127.0.0.1/");try (Statement stmt = conn.createStatement()) {stmt.execute("CREATE INDEX idx_person_name ON Person (name)");}
要创建一个组合索引,可以使用如下的命令:
SQL:
CREATE INDEX idx_person_name_birth_date ON Person (name ASC, birth_date DESC)
Java:
IgniteCache<PersonKey, Person> cache = ignite.cache("Person");SqlFieldsQuery query = new SqlFieldsQuery("CREATE INDEX idx_person_name_birth_date ON Person (name ASC, birth_date DESC)");cache.query(query).getAll();
JDBC:
// Register JDBC driverClass.forName("org.apache.ignite.IgniteJdbcThinDriver");// Open JDBC connectionConnection conn = DriverManager.getConnection("jdbc:ignite:thin://127.0.0.1/");try (Statement stmt = conn.createStatement()) {stmt.execute("CREATE INDEX idx_person_name_birth_date ON Person (name ASC, birth_date DESC)");}
加入SPATIAL关键字之后可以定义空间索引:
SQL:
CREATE SPATIAL INDEX idx_person_address ON Person (address)
Java:
IgniteCache<PersonKey, Person> cache = ignite.cache("Person");SqlFieldsQuery query = new SqlFieldsQuery("CREATE SPATIAL INDEX idx_person_address ON Person (address)");cache.query(query).getAll();
JDBC:
// Register JDBC driverClass.forName("org.apache.ignite.IgniteJdbcThinDriver");// Open JDBC connectionConnection conn = DriverManager.getConnection("jdbc:ignite:thin://127.0.0.1/");try (Statement stmt = conn.createStatement()) {stmt.execute("CREATE SPATIAL INDEX idx_person_address ON Person (address)");}
4.3.5.删除索引
语法:
DROP INDEX [IF EXISTS] indexName
SQL:
DROP INDEX idx_person_name
Java:
IgniteCache<PersonKey, Person> cache = ignite.cache("Person");SqlFieldsQuery query = new SqlFieldsQuery("DROP INDEX idx_person_name");cache.query(query).getAll();
JDBC:
// Register JDBC driverClass.forName("org.apache.ignite.IgniteJdbcThinDriver");// Open JDBC connectionConnection conn = DriverManager.getConnection("jdbc:ignite:thin://127.0.0.1/");try (Statement stmt = conn.createStatement()) {stmt.execute("DROP INDEX idx_person_name");}
4.4.分布式DML
4.4.1.摘要
Ignite SQL网格的功能不仅仅限于SELECT操作,还可以使用众所周知的DML语句,比如INSERT、UPDATE或者DELETE修改数据。利用这个优势,依赖Ignite的SQL能力完全可以将其当做分布式内存数据库。
ANSI-99 SQL兼容
DML查询,和所有的SELECT查询一样,都是兼容ANSI-99 SQL标准的。
Ignite在内存中的数据都是以键-值对的形式存储的,因此所有和DML相关的操作都会被转换为相对应的基于键-值的缓存操作命令,比如cache.put(...)或者cache.invokeAll(...)。下面会深入地了解这些DML语句是如何实现的。
4.4.2.DML API
通常来说,所有的DML语句会被拆分为两组,一个是往缓存中添加条目(INSERT和MERGE),还有就是修改已有的数据(UPDATE和DELETE)。
要在Java中执行这些语句需要使用已有的用于SELECT查询的API - SqlFieldsQueryAPI,DML操作使用的API与只读查询是一致的,返回结果也是QueryCursor<List<?>>。唯一的不同是作为DML语句执行的结果,QueryCursor<List<?>>是只有一个long类型的单条目的List<?>,这个数值表示该DML语句影响的缓存条目的数量。而作为SELECT语句的结果,QueryCursor<List<?>>会包含一个从缓存获得的条目列表。
其他的API
DML API不受限于Java,也可以使用ODBC或者JDBC驱动接入Ignite集群,然后执行DML语句。
4.4.3.基本配置
在Ignite中要进行DML操作,需要使用基于QueryEntity的方式或者使用@QuerySqlField注解来配置所有可查询的字段,比如:
使用@QuerySqlField注解:
public class Person {/** Field will be accessible from DML statements. */@QuerySqlFieldprivate final String firstName;/** Indexed field that will be accessible from DML statements. */@QuerySqlField (index = true)private final String lastName;/** Field will NOT be accessible from DML statements. */private int age;public Person(String firstName, String lastName) {this.firstName = firstName;this.lastName = lastName;}}
使用QueryEntity:
<bean class="org.apache.ignite.configuration.CacheConfiguration"><property name="name" value="personCache"/><!-- Configure query entities --><property name="queryEntities"><list><bean class="org.apache.ignite.cache.QueryEntity"><!-- Registering key's class. --><property name="keyType" value="java.lang.Long"/><!-- Registering value's class. --><property name="valueType"value="org.apache.ignite.examples.Person"/><!--Defining fields that will be accessible from DML side--><property name="fields"><map><entry key="firstName" value="java.lang.String"/><entry key="lastName" value="java.lang.String"/></map></property><!--Defining which fields, listed above, will be treated asindexed fields as well.--><property name="indexes"><list><!-- Single field (aka. column) index --><bean class="org.apache.ignite.cache.QueryIndex"><constructor-arg value="lastName"/></bean></list></property></bean></list></property></bean>
除了通过@QuerySqlField加注的或者通过QueryEntity定义的所有字段,还有两个为每个在SQL网格中注册的对象类型预定义的字段_key和_val,这几个预定义字段指向缓存中存储的对象的整个键和值,他们可以像下面这样在DML中直接使用:
//Preparing cache configuration.CacheConfiguration<Long, Person> cacheCfg = new CacheConfiguration<>("personCache");//Registering indexed/queryable types.cacheCfg.setIndexedTypes(Long.class, Person.class);//Starting the cache.IgniteCache<Long, Person> cache = ignite.cache(cacheCfg);// Inserting a new key-value pair referring to prefedined `_key` and `_value`// fields for Person type.cache.query(new SqlFieldsQuery("INSERT INTO Person(_key, _val) VALUES(?, ?)").setArgs(1L, new Person("John", "Smith")));
如果倾向于处理具体的字段,而不是通过执行查询处理整个对象的值,可以执行下面这样的查询:
IgniteCache<Long, Person> cache = ignite.cache(cacheCfg);cache.query(new SqlFieldsQuery("INSERT INTO Person(_key, firstName, lastName) VALUES(?, ?, ?)").setArgs(1L, "John", "Smith"));
注意DML引擎会根据firstName和lastName重新创建一个Person对象,然后将其注入缓存,但是这些字段是需要通过QueryEntity或者@QuerySqlField注解进行定义的,就像上面描述的那样。
4.4.4.高级配置
自定义键
如果只使用预定义的SQL数据类型作为缓存键,那么就没必要对和DML相关的配置做额外的操作,这些数据类型在GridQueryProcessor#SQL_TYPES常量中进行定义,列举如下:
预定义SQL数据类型
1.所有的基本类型及其包装器,除了char和Character;
2.String;
3.BigDecimal;
4.byte[];
5.java.util.Date,java.sql.Date,java.sql.Timestamp;
6.java.util.UUID。
然而,如果决定引入复杂的自定义缓存键,那么在DML语句中要指向这些字段就需要:
- 在
QueryEntity中定义这些字段,与在值对象中配置字段一样; - 使用新的配置参数
QueryEntitty.setKeyFields(..)来对键和值进行区分;
下面的例子展示了如何实现:
Java:
// Preparing cache configuration.CacheConfiguration cacheCfg = new CacheConfiguration<>("personCache");// Creating the query entity.QueryEntity entity = new QueryEntity("CustomKey", "Person");// Listing all the queryable fields.LinkedHashMap<String, String> flds = new LinkedHashMap<>();flds.put("intKeyField", Integer.class.getName());flds.put("strKeyField", String.class.getName());flds.put("firstName", String.class.getName());flds.put("lastName", String.class.getName());entity.setFields(flds);// Listing a subset of the fields that belong to the key.Set<String> keyFlds = new HashSet<>();keyFlds.add("intKeyField");keyFlds.add("strKeyField");entity.setKeyFields(keyFlds);// End of new settings, nothing else here is DML relatedentity.setIndexes(Collections.<QueryIndex>emptyList());cacheCfg.setQueryEntities(Collections.singletonList(entity));ignite.createCache(cacheCfg);
XML:
<bean class="org.apache.ignite.configuration.CacheConfiguration"><property name="name" value="personCache"/><!-- Configure query entities --><property name="queryEntities"><list><bean class="org.apache.ignite.cache.QueryEntity"><!-- Registering key's class. --><property name="keyType" value="CustomKey"/><!-- Registering value's class. --><property name="valueType"value="org.apache.ignite.examples.Person"/><!--Defining all the fields that will be accessible from DML.--><property name="fields"><map><entry key="firstName" value="java.lang.String"/><entry key="lastName" value="java.lang.String"/><entry key="intKeyField" value="java.lang.Integer"/><entry key="strKeyField" value="java.lang.String"/></map></property><!-- Defining the subset of key's fields --><property name="keyFields"><set><value>intKeyField<value/><value>strKeyField<value/></set></property></bean></list></property></bean>
4.4.5.DML操作
MERGE
MERGE是一个非常简单的操作,因为它会被翻译成cache.put(...)或者cache.putAll(...),具体是哪一个,取决于MERGE语句涉及的要插入或者要更新的记录的数量。
下面的示例显示如何通过MERGE命令来更新数据集。一个是提供了条目列表,一个是通过执行子查询注入一个结果集。
MERGE(条目列表):
cache.query(new SqlFieldsQuery("MERGE INTO Person(_key, firstName, lastName)" + "values (1, 'John', 'Smith'), (5, 'Mary', 'Jones')"));
MERGE(子查询):
cache.query(new SqlFieldsQuery("MERGE INTO someCache.Person(_key, firstName, lastName) (SELECT _key + 1000, firstName, lastName " +"FROM anotherCache.Person WHERE _key > ? AND _key < ?)").setArgs(100, 200);
INSERT
MERGE和INSERT命令的不同在于,后者添加的条目必须是缓存中不存在的。
如果要把一个键值对插入缓存,那么最后,INSERT语句会被转换为cache.putIfAbsent(...)操作,否则,如果插入的是多个键值对,那么DML引擎会为每个对创建一个EntryProcessor,然后使用cache.invokeAll(...)将数据注入缓存。
下面的示例显示如何通过INSERT命令插入一个数据集,一个是提供了条目列表,一个是通过执行子查询注入一个结果集。
INSERT(条目列表):
cache.query(new SqlFieldsQuery("INSERT INTO Person(_key, firstName, " +"lastName) values (1, 'John', 'Smith'), (5, 'Mary', 'Jones')"));
INSERT(子查询):
cache.query(new SqlFieldsQuery("INSERT INTO someCache.Person(_key, firstName, lastName) (SELECT _key + 1000, firstName, secondName " +"FROM anotherCache.Person WHERE _key > ? AND _key < ?)").setArgs(100, 200);
UPDATE
这个操作会更新缓存中的值的每个字段。
开始时,SQL引擎会根据UPDATE语句的WHERE条件生成并且执行一个SELECT查询,然后会修改满足条件的已有值。
修改的执行是利用cache.invokeAll(...)实现的。基本上来说,这意味着一旦SELECT查询的结果准备好,SQL引擎就会准备一定数量的EntryProcessors然后执行cache.invokeAll(...)操作,下一步,EntryProcessors修改完数据之后,会进行额外的检查来确保在SELECT和数据实际更新之间没有其他干扰。
下面这个简单示例显示了如何执行UPDATE语句。
cache.query(new SqlFieldsQuery("UPDATE Person set lastName = ? " +"WHERE _key >= ?").setArgs("Jones", 2L));
UPDATE语句无法更新缓存键及其字段
原因是缓存键的状态决定了内部数据的布局及其一致性(键的哈希及其关系,索引完整性),所以目前除非先将其删除,否则无法更新缓存键。比如下面的查询:
UPDATE _key = 11 where _key = 10;
会导致下面的缓存操作:
val = get(10);
put(11, val);
remove(10);
DELETE
DELETE语句的执行也会被拆分为两个阶段,与UPDATE语句的执行类似。
首先,SQL引擎会使用SELECT语句来收集满足WHERE条件并且要被删除的缓存键,下一步,拿到这些键后,会准备一定数量的EntryProcessors然后执行cache.invokeAll(...)操作,当数据将被删除时,会进行额外的检查来确保在SELECT和数据实际删除之间没有其他干扰。
下面这个简单示例显示了如何执行DELETE语句。
cache.query(new SqlFieldsQuery("DELETE FROM Person " +"WHERE _key >= ?").setArgs(2L));
流模式
使用Ignite的JDBC驱动,会通过流模式来获得更快的数据预加载。
4.4.6.修改顺序
如果一个DML语句插入/更新指向_val字段的整个值的同时,还试图修改属于_val的某一个字段时,那么,变更的顺序如下:
- 首先,
_val被插入/更新; - 字段更新。
不管DML语句事实上如何定义,这个顺序是不会改变的。比如下面的语句执行完毕后,Person的最终值会是Mike Smith,尽管在查询中_val位于firstName后面。
cache.query(new SqlFieldsQuery("INSERT INTO Person(_key, firstName, _val)" +" VALUES(?, ?, ?)").setArgs(1L, "Mike", new Person("John", "Smith")));
这与下面的查询的执行类似,这里_val在前面:
cache.query(new SqlFieldsQuery("INSERT INTO Person(_key, _val, firstName)" +" VALUES(?, ?, ?)").setArgs(1L, new Person("John", "Smith"), "Mike"));
对于_val及其字段变更顺序的问题,INSERT、UPDATE和MERGE语句都是一样的。
4.4.7.并发修改
如上所述,UPDATE和DELETE语句在内部会生成SELECT查询,目的是将查询执行的结果集作为要更新的缓存条目的集合。这个集合中的键是不会被锁定的,因此有一种可能就是在并发的情况下,属于某个键的值会被其他的查询修改。DML引擎已经实现了一种技术,即首先避免锁定键,然后保证在DML语句执行更新时值是最新的。
总体而言,引擎会并发地检测要更新的缓存条目的子集,然后重新执行SELECT语句来限制要修改的键的范围。
比如下面的要执行的UPDATE语句:
// Adding the cache entry.cache.put(1, new Person("John", "Smith");// Updating the entry.cache.query(new SqlFieldsQuery("UPDATE Person set firstName = ? " +"WHERE lastName = ?").setArgs("Mike", "Smith"));
在firstName和lastName更新之前,DML引擎会生成SELECT查询来获得符合UPDATE语句的WHERE条件的缓存条目,语句如下:
SELECT _key, _value, "Mike" from Person WHERE lastName = "Smith"
之后通过SELECT获得的条目会被并发地更新:
cache.put(1, new Person("Sarah", "Connor"))
DML引擎在UPDATE语句执行的更新阶段会检测到键为1的缓存条目要被修改,之后会暂停更新并且重新执行一个SELECT查询的修订版本来获得最新的条目值:
SELECT _key, _value, "Mike" from Person WHERE secondName = "Smith"AND _key IN (SELECT * FROM TABLE(KEY long = [ 1 ]))
这个查询只会为过时的键执行,本例中只有一个键1。
这个过程会一直重复,直到DML引擎确信在更新阶段所有的条目都已经更新到最新版。尝试次数的最大值是4,目前并没有配置参数来改变这个值。
DML引擎不会为并发删除的条目重复执行
SELECT语句,重复执行的查询只针对还在缓存中的条目。
4.4.8.已知的限制
WHERE条件中的子查询
INSERT和MERGE语句中的子查询和UPDATE和DELETE操作自动生成的SELECT查询一样,如有必要都会被分布化然后执行,要么是并置,要么是非并置的模式。
然而,如果WHERE语句里面有一个子查询,那么他是不会以非并置的分布式模式执行的,子查询始终都会以并置的模式在本地节点上执行。
比如,有这样一个查询:
DELETE FROM Person WHERE _key IN(SELECT personId FROM "salary".Salary s WHERE s.amount > 2000)
然后DML引擎会生成SELECT查询来获得要删除的条目列表,这个查询会在整个集群中分布化并且执行,如下所示:
SELECT _key, _val FROM Person WHERE _key IN(SELECT personId FROM "salary".Salary s WHERE s.amount > 2000)
然而,IN子句中的子查询(SELECT personId FROM "salary".Salary ...)不会被进一步分布化,只会在一个集群节点的本地数据集上执行。
事务性支持
目前,DML仅仅支持原子模式,意味着如果有一个DML查询作为Ignite事务的一部分,那么它是不会加入事务的写队列,会被立刻执行。
多版本并发控制(MVCC)
一旦Ignite SQL网格使用MVCC进行控制,DML操作也会支持事务模式。
DML语句的执行计划支持
目前DML操作不支持EXPLAIN。
一个方法就是执行UPDATE或DELETE语句自动生成的SELECT语句或者DML语句使用的INSERT或MERGE语句的执行计划,这样会提供一个要执行的DML操作所使用的索引情况。
4.4.9.示例
Ignite在源代码中包含了一个可以立即执行的CacheQueryDmlExample,这个示例演示了上面提到的所有DML操作的用法。
4.5.分布式查询
4.5.1.摘要
Ignite支持任意的SQL查询,没有任何限制。SQL语法是ANSI-99兼容的,也就意味着作为SQL查询的一部分,规范定义的任何SQL函数、聚合、分组以及关联,都是可以使用的。
此外,查询是完全分布式的。SQL引擎的功能不仅仅是将查询映射到特定的节点然后将结果汇总为最终的结果集,它还可以将存储在不同缓存甚至是不同节点上的数据进行关联。此外,引擎是以容错的方式保证,不会因为新节点加入集群或者旧节点离开而获得不完整或者错误的结果。
4.5.2.SQL查询如何工作
Ignite的SQL网格组件是与H2数据库紧紧绑定在一起的,简而言之,H2是一个Java写的,遵循一组开源许可证,基于内存和磁盘的数据库。
当ignite-indexing模块加入节点的类路径之后,一个嵌入式的H2数据库实例就会作为Ignite节点进程的一部分被启动。如果节点是在终端中通过ignite.sh{bat}脚本启动的,那么需要将{apache_ignite}\libs\optional\ignite-indexing目录拷贝到{apache_ignite}\libs\,如果使用的是maven,那么需要将如下的依赖加入pom.xml文件:
<dependency><groupId>org.apache.ignite</groupId><artifactId>ignite-indexing</artifactId><version>${ignite.version}</version></dependency>
Ignite借用了H2的SQL查询解析器以及优化器还有执行计划器。最后,届时H2会在一个特定的节点执行本地化的查询(一个分布式查询会被映射到节点或者查询是以本地模式执行的),然后会将本地的结果集传递给分布式SQL引擎用于后续处理。
然而,数据和索引,通常是存储于Ignite数据网格端的,而Ignite以分布式以及容错的方式执行SQL查询,这个是H2不支持的。
Ignite SQL网格执行查询有两种方式:
首先,如果查询在一个部署有REPLICATED模式缓存的节点上执行,那么Ignite会假定所有的数据都是本地化的,然后将其直接传递给H2数据库引擎执行一个简单的本地化SQL查询,对于LOCAL模式的缓存,也是同样的执行流程。
第二,如果查询执行于PARTITIONED模式缓存,那么执行流程如下:
- 查询会被解析然后拆分为多个映射查询以及一个汇总查询;
- 所有的映射查询都会在持有缓存数据的所有数据节点上执行;
- 所有的节点都会将本地执行的结果集提供给查询发起者(汇总节点),它会通过正确地合并结果集完成汇总的过程。
跨缓存查询的执行流程
跨缓存或者关联查询的执行流程与上面描述的分区缓存查询执行流程没什么不同,后面文档还会提到。
处理带有ORDER BY以及GROUP BY的结果集
带有ORDER BY语句的SQL查询不需要将所有结果集都加载到查询发起(汇总)节点来完成排序。而是查询映射的每个节点都会对自己那部分数据进行排序然后汇总节点以流的方式进行合并。
对于有序的GROUP BY查询也是同样的优化方式,不需要在将其返回给应用之前将所有数据加载到汇总节点用于分组。在Ignite中,来自单独节点的部分结果集可以被逐步地流化、合并、聚合以及返回给应用。
4.5.3.查询类型
在Java API层,通常有两种类型的SQL查询,分别为SqlQuery和SqlFieldsQuery。
替代APIs
Ignite内存SQL网格并不绑定到Java API,可以从.NET, C++通过 ODBC或者JDBC驱动连接到Ignite集群然后执行SQL查询。
SqlQuery
SqlQuery适用于查询执行完毕后需要获得存储于缓存(键和值)中的整个对象的场景,然后返回最终的结果集,下面的代码片段显示了在实践中如何实现:
IgniteCache<Long, Person> cache = ignite.cache("personCache");SqlQuery sql = new SqlQuery(Person.class, "salary > ?");// Find all persons earning more than 1,000.try (QueryCursor<Entry<Long, Person>> cursor = cache.query(sql.setArgs(1000))) {for (Entry<Long, Person> e : cursor)System.out.println(e.getValue().toString());}
SqlFieldsQuery
不需要查询整个对象,只需要指定几个特定的字段即可,这样可以最小化网络和序列化的开销。为此,Ignite实现了一个字段查询的概念。SqlFieldsQuery接受一个常规的ANSI-99 SQL查询作为它的构造器参数,然后像下面的示例那样立即执行:
IgniteCache<Long, Person> cache = ignite.cache("personCache");// Execute query to get names of all employees.SqlFieldsQuery sql = new SqlFieldsQuery("select concat(firstName, ' ', lastName) from Person");// Iterate over the result set.try (QueryCursor<List<?>> cursor = cache.query(sql) {for (List<?> row : cursor)System.out.println("personName=" + row.get(0));}
可查询字段定义
在SqlQuery和SqlFieldsQuery中的指定字段可以被访问之前,他们需要在POJO层面加上注解,或者在QueryEntity中进行定义,以便SQL引擎可以感知到它们,后续章节还会详述。
访问条目的键和值
在SQL查询中使用_key和_val关键字,可以指向条目的整个键和值,而不用写每个字段,如果要在SQL查询执行的结果中返回键或值,也可以使用这两个关键字。
另外,如果键和值是基本类型(int, String, Date等),那么它会被自动地添加到查询的结果集中,比如:SELECT * FROM ...。
4.5.4.跨缓存查询
作为单个SqlQuery和SqlFieldsQuery查询的一部分,查询的数据可以来自多个缓存。这时,缓存名会扮演类似传统RDBMS中SQL查询的模式名的角色。缓存的名字,用于创建IgniteCache的实例,如果用于查询的话,会作为默认的模式名并且不需要显式地指定。其余的存储于不同缓存中的对象,也会被查询,但是需要加上它的缓存名(额外的模式名)作为前缀。
// In this example, suppose Person objects are stored in a// cache named 'personCache' and Organization objects// are stored in a cache named 'orgCache'.IgniteCache<Long, Person> personCache = ignite.cache("personCache");// Select with join between Person and Organization to// get the names of all the employees of a specific organization.SqlFieldsQuery sql = new SqlFieldsQuery("select Person.name "+ "from Person as p, \"orgCache\".Organization as org where "+ "p.orgId = org.id "+ "and org.name = ?");// Execute the query and obtain the query result cursor.try (QueryCursor<List<?>> cursor = personCache.query(sql.setArgs("Ignite"))) {for (List<?> row : cursor)System.out.println("Person name=" + row.get(0));}
上面的示例中,会从personCache创建一个SqlFieldsQuery的实例,之后personCache会作为默认的模式名,这就是Person对象没有通过显式指定的模式名(from Person as p)就能访问的原因。而Organization对象,因为它存储于一个单独的名为orgCache的缓存中,所以在该查询中这个缓存的名字作为模式名必须显式地指定("orgCache".Organization as org)。
修改缓存名
如果希望使用不同于缓存名的模式名,可以通过调用CacheConfiguration.setSqlSchema(...)方法解决。
4.5.5.分布式关联
Ignite支持并置和非并置的分布式SQL关联,此外,如果数据位于不同的缓存,Ignite可以进行跨缓存的关联。
IgniteCache<Long, Person> cache = ignite.cache("personCache");// SQL join on Person and Organization.SqlQuery sql = new SqlQuery(Person.class,"from Person as p, \"orgCache\".Organization as org"+ "where p.orgId = org.id "+ "and lower(org.name) = lower(?)");// Find all persons working for Ignite organization.try (QueryCursor<Entry<Long, Person>> cursor = cache.query(sql.setArgs("Ignite"))) {for (Entry<Long, Person> e : cursor)System.out.println(e.getValue().toString());}
分区和复制模式缓存之间的关联也可以无限制地进行。
然而,如果在至少两个分区模式的数据集之间进行关联,那么一定要确保要么关联的键是并置的,要么为查询开启了非并置关联参数,两种类型的分布式关联模式下面会详述。
分布式并置关联
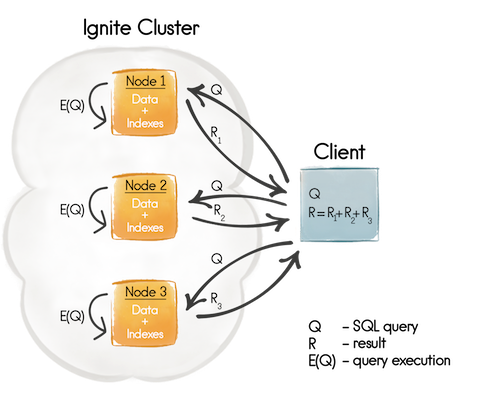
默认情况下,如果一个SQL关联需要跨越多个Ignite缓存,那么所有的缓存都需要是并置的,否则,查询完成后会得到一个不完整的结果集,这是因为在关联阶段一个节点的可用数据只是本地的,如图1所示,首先,一个SQL查询会被发送到待关联数据所在的节点(Q),然后查询在每个节点的本地数据上立即执行(E(Q)),最后,所有的执行结果都会在客户端进行聚合(R)。
分布式非并置关联
虽然关系并置是一个强大的概念,即一旦配置了应用的业务实体(缓存),就可以以最优的方式执行跨缓存的关联,并且返回一个完整且一致的结果集。但还有一种可能就是,无法并置所有的数据,这时,就可能无法执行满足需求的所有SQL查询了。
在实践中不要过度使用基于非并置的分布式关联的方式,因为这种关联方式的性能差于基于关系并置的关联,因为要完成这个查询,要有更多的网络开销和节点间的数据移动。
当通过SqlQuery.setDistributedJoins(boolean)参数为一个SQL查询启用了非并置的分布式关联之后,查询映射的节点就会从远程节点通过发送广播或者单播请求的方式获取缺失的数据(本地不存在的数据),正如图2所示,有一个潜在的数据移动步骤(D(Q))。潜在的单播请求只会在关联在主键(缓存键)或者关系键上完成之后才会发送,因为执行关联的节点知道缺失数据的位置,其他所有的情况都会发送广播请求。
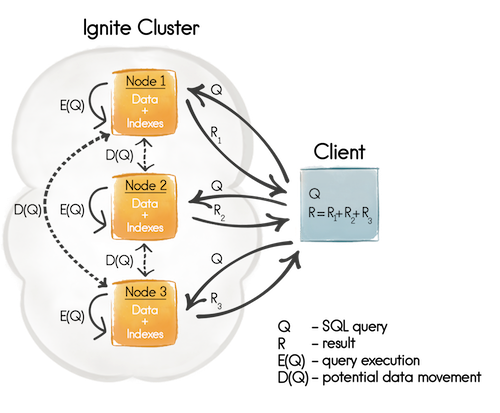
不管是广播还是单播请求,都是由一个节点发送到另一个节点来获取缺失的数据,是按照顺序执行的。SQL引擎会将所有的请求组成若干批量,这个批量的大小是由
SqlQuery.setPageSize(int)参数管理的。
下面的代码片段是从Ignite的发行版的CacheQueryExample中提取的:
IgniteCache<Long, Person> cache = ignite.cache("personCache");// SQL clause query with join over non-collocated data.String joinSql ="from Person, \"orgCache\".Organization as org " +"where Person.orgId = org.id " +"and lower(org.name) = lower(?)";SqlQuery qry = new SqlQuery<Long, Person>(Person.class, joinSql).setArgs("ApacheIgnite");// Enable distributed joins for the query.qry.setDistributedJoins(true);// Execute the query to find out employees for specified organization.System.out.println("Following people are 'ApacheIgnite' employees (distributed join): ", cache.query(qry).getAll());
要了解详细信息,可以参照非并置的分布式关联。
查询复制缓存
如果只在复制缓存所在的数据上执行SQL查询,那么可以设置SqlQuery.setReplicatedOnly(...)为true,这个给SQL引擎的特别提示会为查询产生更高效的执行计划。
4.5.6.已知的限制
事务性SQL
目前,SQL查询仅仅支持原子模式,意味着如果有一个事务已经提交了值A而值B正在提交过程中,然后如果有一个并行的SQL查询的话,会看到A而看不到B。
多版本并发控制(MVCC)
一旦Ignite SQL网格使用MVCC进行控制,SQL网格也会支持事务模式。
4.5.7.示例
关于本文描述的分布式关联如何使用的完整示例,会作为Ignite发行版的一部分进行分发,名为CacheQueryExample,GitHub上也有。
4.6.本地查询
有时,SQL网格中查询的执行会从分布式模式回落至本地模式,在本地模式中,查询会简单地传递至底层的H2引擎,他只会处理本地节点的数据集。
这些场景包括:
- 如果一个查询在部署有
复制缓存的节点上执行,那么Ignite会假定所有的数据都在本地,然后就会隐式地在本地执行一个简单的查询; - 查询在
本地缓存上执行; - 使用
SqlQuery.setLocal(true)或者SqlFieldsQuery.setLocal(true)为查询显式地开启本地模式;
即使查询执行时网络拓扑发生变化(新节点加入集群或者老节点离开集群),前两个场景也会一直提供完整而一致的结果集。
然而,在应用显式开启本地模式的第三个场景中需要注意,原因是如果希望在部分节点的分区缓存上执行本地查询时网络还发生了变化,那么可能得到结果集的一部分,因为这时会触发一个并行的数据再平衡过程。SQL引擎无法处理这个特殊情况。如果仍然希望在分区缓存上执行本地查询,那么需要将查询作为affinityRun(...)或者affinityCall(...)方法的一部分。
4.7.模式和索引
4.7.1.摘要
SQL模式是数据库的一个逻辑对象,它包含了表及其相关的索引。
目前,Ignite支持基于注解、基于QueryEntity或者基于DDL语句的方式定义模式。
另外,Ignite支持高级的索引功能,可以定义包括各种参数的单字段(也可以叫做列)或者分组索引,这些参数可以管理索引,使其位于Java堆或者堆外空间等等。
Ignite中以分布式方式保存的索引和缓存数据集一样,每一个节点都保存数据的一个特定子集,还会保存和管理与这个数据对应的索引。
4.7.2.模式和表
不管是通过注解或者通过QueryEntity的方式,表和索引建立之后,它们所属的模式名为CacheConfiguration对象中配置的缓存名,要修改的话,需要使用CacheConfiguration.setSqlSchema方法。
但是,如果表和索引是通过DDL语句的形式定义的,那么模式名就会完全不同,这时,表和索引所属的模式名默认为PUBLIC。目前,通过这种方式进行的定义,模式名还无法修改,这个问题在未来的版本中会解决。
这时,如果表的建立使用了上述的所有方式,那么一定要确保查询时要指定正确的模式名。比如,嘉定80%的表都是通过DDL配置的,那么通过SqlQuery.setSchema("PUBLIC")方法将查询的默认模式配置成PUBLIC就会很有意义。
Java:
IgniteCache cache = ignite.cache("Person");// Creating City table.cache.qry(new SqlFieldsQuery("CREATE TABLE City " +"(id int primary key, name varchar, region varchar)"));// Creating Organization table.cache.qry(new SqlFieldsQuery("CREATE TABLE Organization " +"(id int primary key, name varchar, cityName varchar)"));// Joining data between City, Organizaion and Person tables. The latter// was created with either annotations or QueryEntity approach.SqlFieldsQuery qry = new SqlFieldsQuery("SELECT o.name from Organization o " +"inner join \"Person\".Person p on o.id = p.orgId " +"inner join City c on c.name = o.cityName " +"where p.age > 25 and c.region <> 'Texas'");// Setting the query's default schema to PUBLIC.// Table names from the query without the schema set will be// resolved against PUBLIC schema.// Person table belongs to "Person" schema (person cache) and this is why// that schema name is set explicitly.qry.setSchema("PUBLIC");// Executing the query.cache.query(qry);
4.7.3.基于DDL的配置
关于DDL的使用,可以参照4.3.分布式DDL相关章节。
4.7.4.基于注解的配置
索引,和可查询的字段一样,是可以通过编程的方式用@QuerySqlField进行配置的。
如下所示,期望的字段已经加注了该注解。
Java:
public class Person implements Serializable {/** Indexed field. Will be visible for SQL engine. */@QuerySqlField (index = true)private long id;/** Queryable field. Will be visible for SQL engine. */@QuerySqlFieldprivate String name;/** Will NOT be visible for SQL engine. */private int age;/*** Indexed field sorted in descending order.* Will be visible for SQL engine.*/@QuerySqlField(index = true, descending = true)private float salary;}
Scala:
case class Person (/** Indexed field. Will be visible for SQL engine. */@(QuerySqlField @field)(index = true) id: Long,/** Queryable field. Will be visible for SQL engine. */@(QuerySqlField @field) name: String,/** Will NOT be visisble for SQL engine. */age: Int/*** Indexed field sorted in descending order.* Will be visible for SQL engine.*/@(QuerySqlField @field)(index = true, descending = true) salary: Float) extends Serializable {...}
id和salary都是索引列,id字段升序排列(默认),而salary降序排列。
如果不希望索引一个字段,但是仍然想在SQL查询中使用它,那么在加注解时可以忽略index = true参数,这样的字段称为可查询字段,举例来说,上面的name就被定义为可查询字段。
最后,age既不是可查询字段也不是索引字段,在Ignite中,从SQL查询的角度看就是不可见的。
Scala注解
在Scala类中,@QuerySqlField注解必须和@Field注解一起使用,这样的话这个字段对于Ignite才是可见的,就像这样的:@(QuerySqlField @field)。
作为替代,也可以使用ignite-scalar模块的@ScalarCacheQuerySqlField注解,他不过是@Field注解的别名。
注册索引类型
定义了索引字段和可查询字段之后,就需要和他们所属的对象类型一起,在SQL引擎中注册。
要告诉Ignite哪些类型应该被索引,需要通过CacheConfiguration.setIndexedTypes方法传入键-值对,如下所示:
/ Preparing configuration.CacheConfiguration<Long, Person> ccfg = new CacheConfiguration<>();// Registering indexed type.ccfg.setIndexedTypes(Long.class, Person.class);
注意,这个方法只接收成对的类型,一个键类一个值类,基本类型需要使用包装器类。
预定义字段
除了用@QuerySqlField注解标注的所有字段,每个表都有两个特别的预定义字段:_key和_val,它表示到整个键对象和值对象的链接。这很有用,比如当他们中的一个是基本类型并且希望用它的值进行过滤时。要做到这一点,执行一个SELECT * FROM Person WHERE _key = 100查询即可。多亏了二进制编组器,不需要将索引类型类加入集群节点的类路径中,SQL查询引擎不需要对象反序列化就可以钻取索引和可查询字段的值。
分组索引
当查询条件复杂时可以使用多字段索引来加快查询的速度,这时可以用@QuerySqlField.Group注解。如果希望一个字段参与多个分组索引时也可以将多个@QuerySqlField.Group注解加入orderedGroups中。
比如,下面的Person类中age字段加入了名为age_salary_idx的分组索引,他的分组序号是0并且降序排列,同一个分组索引中还有一个字段salary,他的分组序号是3并且升序排列。最重要的是salary字段还是一个单列索引(除了orderedGroups声明之外,还加上了index = true)。分组中的order不需要是什么特别的数值,他只是用于分组内的字段排序。
Java:
public class Person implements Serializable {/** Indexed in a group index with "salary". */@QuerySqlField(orderedGroups={@QuerySqlField.Group(name = "age_salary_idx", order = 0, descending = true)})private int age;/** Indexed separately and in a group index with "age". */@QuerySqlField(index = true, orderedGroups={@QuerySqlField.Group(name = "age_salary_idx", order = 3)})private double salary;}
注意,将
@QuerySqlField.Group放在@QuerySqlField(orderedGroups={...})外面是无效的。
4.7.5.基于QueryEntity的配置
索引和字段也可以通过org.apache.ignite.cache.QueryEntity进行配置,它便于利用Spring进行基于XML的配置。
在上面基于注解的配置涉及的所有概念,对于基于QueryEntity的方式也都有效,深入地说,通过@QuerySqlField配置的字段的类型然后通过CacheConfiguration.setIndexedTypes注册过的,在内部也会被转换为查询实体。
下面的示例显示的是如何像可查询字段那样定义一个单一字段和分组索引。
<bean class="org.apache.ignite.configuration.CacheConfiguration"><property name="name" value="mycache"/><!-- Configure query entities --><property name="queryEntities"><list><bean class="org.apache.ignite.cache.QueryEntity"><!-- Setting indexed type's key class --><property name="keyType" value="java.lang.Long"/><!-- Setting indexed type's value class --><property name="valueType"value="org.apache.ignite.examples.Person"/><!-- Defining fields that will be either indexed or queryable.Indexed fields are added to 'indexes' list below.--><property name="fields"><map><entry key="id" value="java.lang.Long"/><entry key="name" value="java.lang.String"/><entry key="salary" value="java.lang.Long "/></map></property><!-- Defining indexed fields.--><property name="indexes"><list><!-- Single field (aka. column) index --><bean class="org.apache.ignite.cache.QueryIndex"><constructor-arg value="id"/></bean><!-- Group index. --><bean class="org.apache.ignite.cache.QueryIndex"><constructor-arg><list><value>id</value><value>salary</value></list></constructor-arg><constructor-arg value="SORTED"/></bean></list></property></bean></list></property></bean>
4.7.6.索引的权衡
为应用选择索引时,需要考虑很多事情。
- 索引是有代价的:它们消耗内存,每个索引需要单独更新,因此当配置了很多索引时,缓存更新的性能会下降。最重要的是,执行查询时如果选择了错误的索引优化器会犯更多的错误。
索引每个字段是错误的!
- 索引只是有序数据结构,如果在字段(a,b,c)上定义了索引,那么记录的排序会是首先是a,然后b,再然后c。
有序索引示例
| A | B | C |
| 1 | 2 | 3 |
| 1 | 4 | 2 |
| 1 | 4 | 4 |
| 2 | 3 | 5 |
| 2 | 4 | 4 |
| 2 | 4 | 5 |
任意条件,比如a = 1 and b > 3,都会被视为有界范围,在log(N)时间内两个边界在索引中可以被快速检索到,然后结果就是两者之间的任何数据。
下面的条件会使用索引:
a = ?
a = ? and b = ?
a = ? and b = ? and c = ?
从索引的角度,条件a = ?和c = ?不会好于a = ?
明显地,半界范围a > ?可以工作得很好。
- 单字段索引不如以同一个字段开始的多字段分组索引(索引(a)不如索引(a,b,c)),因此要优先使用分组索引。
4.8.空间支持
4.8.1.摘要
Ignite除了支持标准ANSI-99标准的SQL查询,支持基本数据类型或者特定/自定义对象类型之外,还可以查询和索引几何数据类型,比如点、线以及包括这些几何形状空间关系的多边形。
空间信息的查询功能,以及对应的可用的函数和操作符,是在SQL的简单特性规范中定义的,Ignite使用的JTS Topology Suite完全实现了这个规范,它和H2一起,以分布式和容错的方式构建了一个独特的空间组件。
4.8.2.引入Ignite空间库
Ignite的空间库(ignite-geospatial)依赖于JTS,它是LGPL许可证,不同于Apache的许可证,因此ignite-geospatial并没有包含在Ignite的发布版中。
因为这个原因,ignite-geospatial的二进制库版本位于如下的Maven仓库中:
<repositories><repository><id>GridGain External Repository</id><url>http://www.gridgainsystems.com/nexus/content/repositories/external</url></repository></repositories>
在pom.xml中添加这个仓库以及如下的Maven依赖之后,就可以将该空间库引入应用中了。
<dependency><groupId>org.apache.ignite</groupId><artifactId>ignite-geospatial</artifactId><version>${ignite.version}</version></dependency>
另外,也可以下载Ignite的源代码自己构建这个库。
4.8.3.执行空间查询
这个空间模块只对com.vividsolutions.jts类型的对象有用。
要配置索引以及/或者几何类型的可查询字段,可以使用和已有的非几何类型同样的方法,首先,可以使用org.apache.ignite.cache.QueryEntity定义索引,他对于基于Spring的XML配置文件非常方便,第二,通过@QuerySqlField注解来声明索引也可以达到同样的效果,他在内部会转化为QueryEntities。
QuerySqlField:
/*** Map point with indexed coordinates.*/private static class MapPoint {/** Coordinates. */@QuerySqlField(index = true)private Geometry coords;/*** @param coords Coordinates.*/private MapPoint(Geometry coords) {this.coords = coords;}}
QueryEntity:
<bean class="org.apache.ignite.configuration.CacheConfiguration"><property name="name" value="mycache"/><!-- Configure query entities --><property name="queryEntities"><list><bean class="org.apache.ignite.cache.QueryEntity"><property name="keyType" value="java.lang.Integer"/><property name="valueType" value="org.apache.ignite.examples.MapPoint"/><property name="fields"><map><entry key="coords" value="com.vividsolutions.jts.geom.Geometry"/></map></property><property name="indexes"><list><bean class="org.apache.ignite.cache.QueryIndex"><constructor-arg value="coords"/></bean></list></property></bean></list></property></bean>
使用上述方法定义了几何类型字段之后,就可以使用存储于这些字段中值进行查询了。
// Query to find points that fit into a polygon.SqlQuery<Integer, MapPoint> query = new SqlQuery<>(MapPoint.class, "coords && ?");// Defining the polygon's boundaries.query.setArgs("POLYGON((0 0, 0 99, 400 500, 300 0, 0 0))");// Executing the query.Collection<Cache.Entry<Integer, MapPoint>> entries = cache.query(query).getAll();// Printing number of points that fit into the area defined by the polygon.System.out.println("Fetched points [" + entries.size() + ']');
完整示例
Ignite中用于演示空间查询的可以立即执行的完整示例,可以在这里找到。
4.9.配置参数
可以通过调整一些与SQL查询有关的参数,来影响查询执行的行为。
这些参数分为全局参数和查询级参数,全局参数在CacheConfiguration层面配置,在该缓存上执行的所有查询都会受到影响。
缓存配置参数
| 属性名 | 描述 | 默认值 |
|---|---|---|
setSqlSchema(...) |
配置当前缓存使用的SQL模式名,这个名字需要符合SQL的ANSI-99标准,加引号的区分大小写,不加引号的不区分大小写。 | 缓存名 |
setSqlEscapeAll(...) |
如果配置为true,所有的SQL表和字段名都会加上双引号,比如"tableName"."fieldsName",这样会强制字段名区分大小写,同时也允许表名和字段名有特殊字符。 |
false |
setSqlOnheapRowCacheSize(...) |
定义缓存在堆内的SQL行数,来避免每次SQL索引访问的反序列化,这个参数只有在该缓存开启了堆外的时候才会起作用。 | 10,240 |
setSnapshotableIndex(...) |
为存储在Java堆内的索引数据开启快照索引实现。 | false |
SqlFields和SqlFieldsQuery配置参数
| 属性名 | 描述 | 默认值 |
|---|---|---|
setCollocated(...) |
为了优化带有GROUP BY的查询的目的使用的并置标志,当Ignite执行分布式SQL查询时,它会向单个节点发送子查询,如果事先知道要查询的数据是在同一个节点上并置在一起的然后又对并置键(主键或者关系键)进行分组,Ignite会通过在远程节点分组数据而有一个显著的性能提升和网络优化。 | false |
setDistributedJoins(...) |
为一个特定的查询开启非并置模式的分布式关联。 | false |
setEnforceJoinOrder(...) |
配置一个标志来强制查询中的表关联顺序,如果配置为true,查询优化器就不会对join子句的表进行重新排序。 |
false |
setReplicatedOnly(...) |
如果SQL查询对应的数据都在复制缓存上,那么可以将该参数设置为true,这是给SQL引擎的一个特别提示,它会为查询产生更高效的执行计划。 |
false |
setLocal(...) |
强制查询在纯本地模式下执行。 | false |
setPageSize(...) |
定义单个响应中可以传输到发起节点的最大条目数, | 1024 |
setPartitions(...) |
设置一个查询执行的分区,该查询只会在特定分区的主节点上执行。 | null |
setTimeout(...) |
配置查询执行的超时时间,如果正在执行的查询超过了该值,其会被自动取消。默认是禁用的,Ignite的1.8及其以后版本才可用。 | 0 |
setAlias(...) |
设置一个查询中用作表名的别名。 | null |
4.10.其他特性
4.10.1.查询取消
Ignite中有两种方式停止长时间运行的SQL查询,SQL查询时间长的原因,比如使用了未经优化的索引等。
第一个方法是为特定的SqlQuery和SqlFieldsQuery设置查询执行的超时时间。
SqlQuery qry = new SqlQuery<AffinityKey<Long>, Person>(Person.class, joinSql);// Setting query execution timeoutqry.setTimeout(10_000, TimeUnit.SECONDS);
第二个方法是使用QueryCursor.close()来终止查询。
SqlQuery qry = new SqlQuery<AffinityKey<Long>, Person>(Person.class, joinSql);// Getting query cursor.QueryCursor<List> cursor = cache.query(qry);// Executing query.....// Halting the query that might be still in progress.cursor.close();
Ignite的1.8及其以后版本开始支持查询取消的API。
4.10.2.自定义SQL函数
Ignite的SQL引擎支持通过额外用Java编写的自定义SQL函数,来扩展ANSI-99规范定义的SQL函数集。
一个自定义SQL函数仅仅是一个加注了@QuerySqlFunction注解的公共静态方法。
// Defining a custom SQL function.public class MyFunctions {@QuerySqlFunctionpublic static int sqr(int x) {return x * x;}}
持有自定义SQL函数的类需要使用setSqlFunctionClasses(...)方法在特定的CacheConfiguration中注册。
// Preparing a cache configuration.CacheConfiguration cfg = new CacheConfiguration();// Registering the class that contains custom SQL functions.cfg.setSqlFunctionClasses(MyFunctions.class);
经过了上述配置的缓存部署之后,在SQL查询中就可以随意地调用自定义函数了,如下所示:
// Preparing the query that uses customly defined 'sqr' function.SqlFieldsQuery query = new SqlFieldsQuery("SELECT name FROM Blocks WHERE sqr(size) > 100");// Executing the query.cache.query(query).getAll();
在自定义SQL函数可能要执行的所有节点上,通过
CacheConfiguration.setSqlFunctionClasses(...)注册的类都需要添加到类路径中,否则在自定义函数执行时会抛出ClassNotFoundException异常。
4.11.JDBC驱动
Ignite提供了一个JDBC驱动,它可以通过标准的SQL语句处理分布式数据,比如从JDBC端直接进行SELECT、INSERT、UPDATE和DELETE。
目前,Ignite支持两种类型的驱动,轻量易用的JDBC Thin模式驱动以及以客户端节点形式直接接入集群,本文会介绍如何配置和使用它们。
4.11.1.JDBC Thin模式驱动
JDBC Thin模式驱动对应用来说是轻量易用的,要使用这种驱动,只需要将ignite-core-{version}.jar放入应用的类路径即可。
驱动会接入集群节点然后将所有的请求转发给它进行处理。节点会处理分布式的查询以及结果集的汇总,然后将结果集反馈给客户端应用。
JDBC连接串如下所示:
jdbc:ignite:thin://host[:port][?<params>]
host是必需的,它定义了要接入的集群节点主机地址;port是接入的端口,如果不指定默认为10800;<params>是可选的,形式如下:
param1=value1?param2=value2?...:paramN=valueN
驱动类名为org.apache.ignite.IgniteJdbcThinDriver,比如,下面就是如何打开到集群节点的连接,监听地址为192.168.0.50:
// Register JDBC driver.Class.forName("org.apache.ignite.IgniteJdbcThinDriver");// Open the JDBC connection.Connection conn = DriverManager.getConnection("jdbc:ignite:thin://192.168.0.50");
下表列出了JDBC连接串支持的所有参数:
| 属性名 | 描述 | 默认值 |
|---|---|---|
distributedJoins |
对于非并置数据是否使用分布式关联 | false |
enforceJoinOrder |
是否在查询中强制表的关联顺序,如果配置为true,查询优化器在关联中不会对表进行重新排序。 |
false |
collocated |
数据是否并置,当执行分布式查询时,它会将子查询发送给各个节点,如果事先知道要查询的数据在相同的节点是并置在一起的,那么Ignite会有显著的性能提升和网络优化。 | false |
replicatedOnly |
查询是否只包含复制表,这是一个潜在的可能提高性能的提示。 | false |
autoCloseServerCursor |
当拿到最后一个结果集时是否自动关闭服务端游标。开启之后,对ResultSet.close()的调用就不需要网络访问,这样会改进性能。但是,如果服务端游标已经关闭,在调用ResultSet.getMetadata()方法时会抛出异常,这时为什么默认值为false的原因。 |
false |
socketSendBuffer |
发送套接字缓冲区大小,如果配置为0,会使用操作系统默认值。 | 0 |
socketReceiveBuffer |
接收套接字缓冲区大小,如果配置为0,会使用操作系统默认值。 | 0 |
tcpNoDelay |
是否使用TCP_NODELAY选项。 |
true |
连接串示例
jdbc:ignite:thin://myHost:接入myHost,其它比如端口为10800等都是默认值;jdbc:ignite:thin://myHost:11900:接入myHost,自定义端口为11900,其它为默认值;jdbc:ignite:thin://myHost:11900?distributedJoins=true&autoCloseServerCursor=true:接入myHost,自定义端口为11900,开启了分布式关联和autoCloseServerCursor优化;
集群配置
为了接收和处理来自JDBC Thin驱动转发过来的请求,一个节点需要绑定到一个本地网络端口10800,然后监听入站请求。
通过IgniteConfiguration配置SqlConnectorConfiguration,可以对参数进行修改:
Java:
IgniteConfiguration cfg = new IgniteConfiguration().setSqlConnectorConfiguration(new SqlConnectorConfiguration());
XML:
<bean id="ignite.cfg" class="org.apache.ignite.configuration.IgniteConfiguration"><property name="sqlConnectorConfiguration"><bean class="org.apache.ignite.configuration.SqlConnectorConfiguration" /></property></bean>
其支持如下的参数:
| 参数名 | 描述 | 默认值 |
|---|---|---|
host |
绑定的主机名或者IP地址,如果配置为null,会使用IgniteConfigiration.localHost。 |
null |
port |
绑定的端口,如果指定的端口已被占用,Ignite会使用portRange属性来查找其他可用的端口。 |
10800 |
portRange |
定义尝试绑定的端口数量,比如,如果端口配置为10800并且端口范围为100,Ignite会从10800开始,在[10800,10900]范围内查找可用端口。 |
100 |
maxOpenCursorsPerConnection |
每个连接打开的服务端游标的最大数量,如果超过了,当试图打开另一个游标时会抛出异常。 | 128 |
threadPoolSize |
执行查询的线程数量。 | max(8,CPU核数) |
socketSendBufferSize |
发送套接字缓冲区大小,如果配置为0,会使用操作系统默认值。 |
0 |
socketReceiveBufferSize |
接收套接字缓冲区大小,如果配置为0,会使用操作系统默认值。 |
0 |
tcpNoDelay |
是否使用TCP_NODELAY选项。 |
true |
4.11.2.JDBC客户端节点模式驱动
JDBC客户端节点模式驱动使用自己的完整功能的客户端节点连接接入集群,这要求开发者提供一个完整的Spring XML配置作为JDBC连接串的一部分,然后拷贝下面所有的jar文件到应用或者SQL工具的类路径中:
{apache_ignite_release}\libs目录下的所有jar文件;{apache_ignite_release}\ignite-indexing和{apache_ignite_release}\ignite-spring目录下的所有jar文件;
这个驱动很重,而且可能不支持Ignite的最新SQL特性,但是因为它底层使用客户端节点连接,它可以执行分布式查询,然后在应用端直接对结果进行汇总。
JDBC连接URL的规则如下:
jdbc:ignite:cfg://[<params>@]<config_url>
<config_url>是必需的,表示指向Ignite客户端节点配置文件的任意合法URL,当驱动试图建立到集群的连接时,这个节点会在Ignite JDBC客户端节点驱动中启动;
<params>是可选的,格式如下:
param1=value1:param2=value2:...:paramN=valueN
驱动类名为org.apache.ignite.IgniteJdbcDriver,比如下面的代码,展示了如何打开一个到集群的连接:
// Register JDBC driver.Class.forName("org.apache.ignite.IgniteJdbcDriver");// Open JDBC connection (cache name is not specified, which means that we use default cache).Connection conn = DriverManager.getConnection("jdbc:ignite:cfg://file:///etc/config/ignite-jdbc.xml");
它支持如下的参数:
| 属性 | 描述 | 默认值 |
|---|---|---|
cache |
缓存名,如果未定义会使用默认的缓存,区分大小写 | |
nodeId |
要执行的查询所在节点的Id,对于在本地查询是有用的 | |
local |
查询只在本地节点执行,这个参数和nodeId参数都是通过指定节点来限制数据集 |
false |
collocated |
优化标志,当Ignite执行一个分布式查询时,他会向单个的集群节点发送子查询,如果提前知道要查询的数据已经被并置到同一个节点,Ignite会有显著的性能提升和网络优化 | false |
distributedJoins |
可以在非并置的数据上使用分布式关联。 | false |
streaming |
通过INSERT语句为本链接开启批量数据加载模式,具体可以参照后面的流模式相关章节。 |
false |
streamingAllowOverwrite |
通知Ignite对于重复的已有键,覆写它的值而不是忽略他们,具体可以参照后面的流模式相关章节。 |
false |
streamingFlushFrequency |
超时时间,毫秒,数据流处理器用于刷新数据,数据默认会在连接关闭时刷新,具体可以参照后面的流模式相关章节。 |
0 |
streamingPerNodeBufferSize |
数据流处理器的每节点缓冲区大小,具体可以参照后面的流模式相关章节。 |
1024 |
streamingPerNodeParallelOperations |
数据流处理器的每节点并行操作数。具体可以参照后面的流模式相关章节。 |
16 |
transactionsAllowed |
目前已经支持了ACID事务,但是仅仅在键-值API层面,在SQL层面Ignite支持原子性,还不支持事务一致性,这意味着使用这个功能的时候驱动可能抛出不支持事务这样的异常。但是,一些BI工具会一直强制事务行为,这时即使不需要事务,也需要将该参数配置为true以满足需求。 |
false |
跨缓存查询
驱动连接到的缓存会被视为默认的模式,要跨越多个缓存进行查询,可以参照3.6.缓存查询章节。
流模式
使用JDBC驱动,可以以流模式(批处理模式)将数据注入Ignite集群。这时驱动会在内部实例化IgniteDataStreamer然后将数据传给它。要激活这个模式,可以在JDBC连接串中增加streaming参数并且设置为true:
// Register JDBC driver.Class.forName("org.apache.ignite.IgniteJdbcDriver");// Opening connection in the streaming mode.Connection conn = DriverManager.getConnection("jdbc:ignite:cfg://streaming=true@file:///etc/config/ignite-jdbc.xml");
目前,流模式只支持INSERT操作,对于想更快地将数据预加载进缓存的场景非常有用。JDBC驱动定义了多个连接参数来影响流模式的行为,这些参数已经在上述的参数表中列出。
这些参数几乎覆盖了IgniteDataStreamer的所有常规配置,这样就可以根据需要更好地调整流处理器。关于如何配置流处理器可以参考流处理器的相关文档来了解更多的信息。
基于时间的刷新
默认情况下,当要么连接关闭,要么达到了streamingPerNodeBufferSize,数据才会被刷新,如果希望按照时间的方式来刷新,那么可以调整streamingFlushFrequency参数。
// Register JDBC driver.Class.forName("org.apache.ignite.IgniteJdbcDriver");// Opening a connection in the streaming mode and time based flushing set.Connection conn = DriverManager.getConnection("jdbc:ignite:cfg://streaming=true@streamingFlushFrequency=1000@file:///etc/config/ignite-jdbc.xml");PreparedStatement stmt = conn.prepareStatement("INSERT INTO Person(_key, name, age) VALUES(CAST(? as BIGINT), ?, ?)");// Adding the data.for (int i = 1; i < 100000; i++) {// Inserting a Person object with a Long key.stmt.setInt(1, i);stmt.setString(2, "John Smith");stmt.setInt(3, 25);stmt.execute();}conn.close();// Beyond this point, all data is guaranteed to be flushed into the cache.
4.11.3.示例
要处理集群中的数据,需要使用下面的一种方式来创建一个JDBCConnection对象:
JDBC Thin驱动:
// Register JDBC driver.Class.forName("org.apache.ignite.IgniteJdbcThinDriver");// Open the JDBC connection.Connection conn = DriverManager.getConnection("`jdbc:ignite:thin://192.168.0.50");
JDBC客户端节点驱动:
// Register JDBC driver.Class.forName("org.apache.ignite.IgniteJdbcDriver");// Open JDBC connection (cache name is not specified, which means that we use default cache).Connection conn = DriverManager.getConnection("jdbc:ignite:cfg://file:///etc/config/ignite-jdbc.xml");
之后就可以执行SELECTSQL查询了:
// Query names of all people.ResultSet rs = conn.createStatement().executeQuery("select name from Person");while (rs.next()) {String name = rs.getString(1);...}// Query people with specific age using prepared statement.PreparedStatement stmt = conn.prepareStatement("select name, age from Person where age = ?");stmt.setInt(1, 30);ResultSet rs = stmt.executeQuery();while (rs.next()) {String name = rs.getString("name");int age = rs.getInt("age");...}
此外,可以使用DML语句对数据进行修改。
INSERT
// Insert a Person with a Long key.PreparedStatement stmt = conn.prepareStatement("INSERT INTO Person(_key, name, age) VALUES(CAST(? as BIGINT), ?, ?)");stmt.setInt(1, 1);stmt.setString(2, "John Smith");stmt.setInt(3, 25);stmt.execute();
MERGE
// Merge a Person with a Long key.PreparedStatement stmt = conn.prepareStatement("MERGE INTO Person(_key, name, age) VALUES(CAST(? as BIGINT), ?, ?)");stmt.setInt(1, 1);stmt.setString(2, "John Smith");stmt.setInt(3, 25);stmt.executeUpdate();
UPDATE
// Update a Person.conn.createStatement().executeUpdate("UPDATE Person SET age = age + 1 WHERE age = 25");
DELETE
conn.createStatement().execute("DELETE FROM Person WHERE age = 25");
4.12.性能和调试
4.12.1.使用EXPLAIN语句
为了读取执行计划以及提高查询性能的目的,Ignite支持EXPLAIN ...语法,注意一个计划游标会包含多行:最后一行是汇总节点的查询,其他是映射节点的。
SqlFieldsQuery sql = new SqlFieldsQuery("explain select name from Person where age = ?").setArgs(26);System.out.println(cache.query(sql).getAll());
执行计划本身是由H2生成的,这里有详细描述。
4.12.2.使用H2调试控制台
当用Ignite进行开发时,有时对于检查表和索引是否正确或者运行在嵌入节点内部的H2数据库中的本地查询是非常有用的,为此Ignite提供了启动H2控制台的功能。要启用该功能,在启动节点时要将IGNITE_H2_DEBUG_CONSOLE系统属性或者环境变量设置为true。然后就可以在浏览器中打开控制台,可能需要点击控制台中的刷新按钮,因为有可能控制台在数据库对象初始化之前打开。

4.12.3.SQL性能和可用性考量
当执行SQL查询时有一些常见的陷阱需要注意:
- 如果查询使用了操作符OR那么他可能不是以期望的方式使用索引。比如对于查询:
select name from Person where sex='M' and (age = 20 or age = 30),会使用sex字段上的索引而不是age上的索引,虽然后者选择性更强。要解决这个问题需要用UNION ALL重写这个查询(注意没有ALL的UNION会返回去重的行,这会改变查询的语意而且引入了额外的性能开销),比如:select name from Person where sex='M' and age = 20 UNION ALL select name from Person where sex='M' and age = 30。 - 如果查询使用了操作符IN,那么会有两个问题:首先无法提供可变参数列表,这意味着需要在查询中指定明确的列表,比如
where id in (?, ?, ?),但是不能写where id in ?然后传入一个数组或者集合。第二,查询无法使用索引,要解决这两个问题需要像这样重写查询:select p.name from Person p join table(id bigint = ?) i on p.id = i.id,这里可以提供一个任意长度的对象数组(Object[])作为参数,然后会在字段id上使用索引。注意基本类型数组(比如int[],long[]等)无法使用这个语法,但是可以使用基本类型的包装器。
示例:
new SqlFieldsQuery("select * from Person p join table(id bigint = ?) i on p.id = i.id").setArgs(new Object[]{ new Integer[] {2, 3, 4} }))
他会被转换为下面的SQL:
select * from "cache-name".Person p join table(id bigint = (2,3,4)) i on p.id = i.id
4.12.4.查询并行化
SQL查询在每个涉及的节点上,默认是以单线程模式执行的,这种方式对于使用索引返回一个小的结果集的查询是一种优化,比如:
select * from Person where p.id = ?
某些查询以多线程模式执行会更好,这个和带有表扫描以及聚合的查询有关,这在OLAP的场景中比较常见,比如:
select SUM(salary) from Person
通过CacheConfiguration.queryParallelism属性可以控制查询的并行化,这个参数定义了在单一节点中执行查询时使用的线程数。
如果查询包含JOIN,那么所有相关的缓存都应该有相同的并行化配置。
注意
当前,这个属性影响特定缓存上的所有查询,可以加速很重的OLAP查询,但是会减慢其他的简单查询,这个行为在未来的版本中会改进。
4.12.5.索引提示
当明确知道对于查询来说一个索引比另一个更合适时,索引提示就会非常有用,他也有助于指导查询优化器来选择一个更高效的执行计划。在Ignite中要进行这个优化,可以使用USE INDEX(indexA,...,indexN)语句,它会告诉Ignite对于查询的执行只会使用给定名字的索引之一。
下面是一个示例:
SELECT * FROM Person USE INDEX(index_age)WHERE salary > 150000 AND age < 35;
4.12.6.查询复制缓存
如果只在复制缓存所在的数据上执行SQL查询,那么可以设置SqlQuery.setReplicatedOnly(...)为true,这个给SQL引擎的特别提示会为查询产生更高效的执行计划。
4.12.7.查询执行流程优化
对于一个SELECT语句,SQL引擎会自动地使用条件段中的主键以及关系键对查询进行优化,比如下面的查询:
SELECT * FROM Person p WHERE p.id = ?
Ignite会计算p.id所属的分区,然后只在该分区所在的节点中执行查询。
4.12.8.高级DML优化
使用UPDATE和DELETE语句时,需要执行一个SELECT查询来获取之后要处理的缓存条目集。在某些情况下,与直接将DML语句转为特定的缓存操作相比,这样可以避免导致显著的性能问题。
总结一下4.4.分布式DML章节的内容,之所以UPDATE和DELETE会自动执行一个SELECT查询,有如下的原因:
UPDATE或者DELETE语句的WHERE子句会使用复杂的过滤。这在使用复杂而高级的条目过滤时就会发生,这时DML引擎需要做额外的工作来准备要被DML语句更新的条目列表;UPDATE语句包括表达式。即使WHERE子句比较简单并且通过使用_key或者_val直接指向要修改的缓存条目,这个表达式的执行结果仍然可能产生新的字段值,这也是为什么DML引擎需要执行一个SELECT来评估表达式的执行结果;UPDATE语句修改一个缓存条目的特定字段。DML引擎首先需要获取当前的缓存条目,再修改然后将其放回缓存。
更快地执行DML
要更快地执行DML操作,需要遵守如下的必要条件:
- DML操作不触发
SELECT查询执行; - 操作只调整单个缓存条目;
如果遵守如下的规则,就能满足上述的条件:
- 只使用
_key和_val关键字来过滤缓存条目; - 在DML语句中只显式使用这些参数,不访问缓存条目的字段或表达式;
- 如果执行一个
UPDATE语句,然后更新整个缓存条目(_val),而不是特定的字段。
可以看下面的示例:
cache.query(new SqlFieldsQuery("UPDATE Person SET _val = ?3" +" WHERE _key = ?1 and _val = ?2").setArgs(7, 1, 2));
UPDATE语句会进行如下的操作:
- 通过指定所属的
_key以及条目的期望值_val来显式地指定要修改的缓存条目; - 通过使用
_val关键字来更新缓存条目的整个值;
作为结果,DML引擎大概会像下面这样执行缓存操作:
cache.replace(7, 1, 2);
4.13.SQL工具
Ignite的JDBC和ODBC驱动使得从SQL工具接入集群然后处理存储在其中的数据成为可能,需要做的仅仅是为SQL工具配置JDBC或者ODBC驱动。在本文中会以DBeaver为例,一步步演示如何进行这些基本的配置。
4.13.1.安装和配置
DBeaver作为我们的示例,是一个针对开发者和数据库管理员的免费开源的统一数据库工具,它支持包括Ignite在内的所有常见数据库。
Ignite有自己的JDBC驱动实现,DBeaver可以用其处理存储于分布式集群中的数据。
针对自己的操作系统下载和安装DBeaver,再下载最新版本的Ignite。
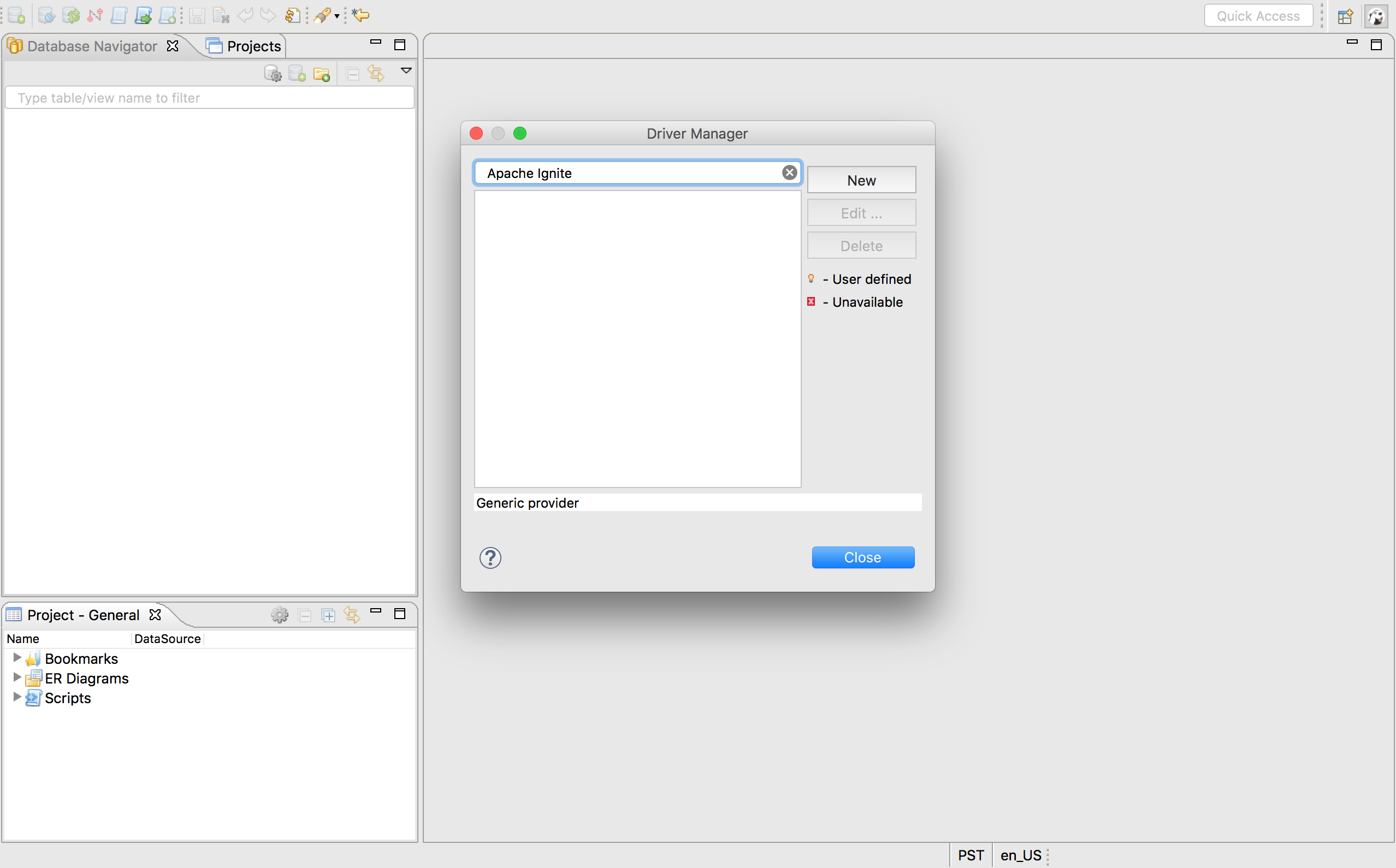
DBeaver安装完成之后,打开它然后选择Database->Driver Manager菜单项来配置Ignite JDBC驱动,使用Apache Ignite作为数据库/驱动名然后点击New按钮
在下一页中输入必要的项目,如下所示:
Driver Name:自定义名字,可以简单地配置为Apache Ignite;Class Name:值为org.apache.ignite.IgniteJdbcThinDriver;URL Template:Ignite的JDBC连接串,作为入门来说可以为jdbc:ignite:thin://127.0.0.1/;Default Port:Ignite JDBC驱动默认使用10800,如果要修改端口号或者连接串,可以见前文描述;Libraries:点击Add file按钮,然后找到包含Ignite JDBC驱动的{apache-ignite-version}/libs/ignite-core-{version}.jar文件,添加之后点击Find Class然后在Driver Class下拉框中显式地选择org.apache.ignite.IgniteJdbcThinDriver;
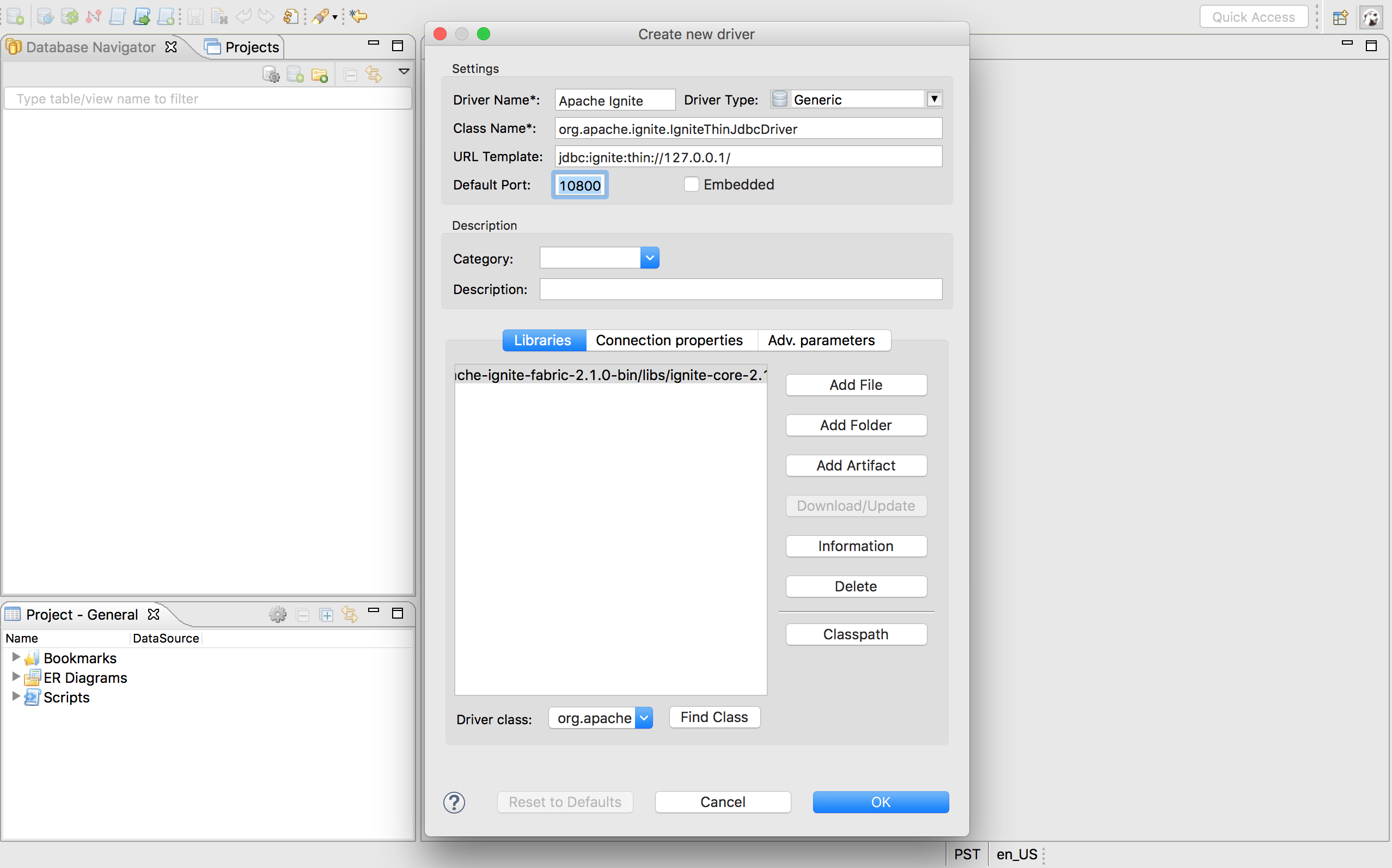
点击OK按钮后完成配置,然后关闭Driver Manager对话框,然后就可以在驱动列表中看到Apache Ignite:
4.13.2.接入集群
下一步就是启动Ignite集群然后通过DBeaver接入。
打开命令行工具然后定位到{apache-ignite-version}/bin,执行ignite.sh或者ignite.bat脚本:
Unix:
./ignite.sh
Windows:
ignite.bat
这个脚本会启动一个Ignite节点,使用同样的脚本可以启动很多的节点,节点启动之后会看到大致如下的输出:
[12:46:46] __________ ________________[12:46:46] / _/ ___/ |/ / _/_ __/ __/[12:46:46] _/ // (7 7 // / / / / _/[12:46:46] /___/\___/_/|_/___/ /_/ /___/[12:46:46][12:46:46] ver. 2.1.0#20170720-sha1:a6ca5c8a[12:46:46] 2017 Copyright(C) Apache Software Foundation[12:46:46][12:46:46] Ignite documentation: http://ignite.apache.org[12:46:46][12:46:46] Quiet mode.[12:46:46] ^-- Logging to file '/Users/dmagda/Downloads/apache-ignite-fabric-2.1.0-bin/work/log/ignite-20d0a1be.0.log'[12:46:46] ^-- To see **FULL** console log here add -DIGNITE_QUIET=false or "-v" to ignite.{sh|bat}[12:46:46][12:46:46] OS: Mac OS X 10.12.6 x86_64[12:46:51] VM information: Java(TM) SE Runtime Environment 1.8.0_77-b03 Oracle Corporation Java HotSpot(TM) 64-Bit Server VM 25.77-b03[12:46:51] Configured plugins:[12:46:51] ^-- None[12:46:58] Ignite node started OK (id=20d0a1be)[12:47:03] Topology snapshot [ver=1, servers=1, clients=0, CPUs=4, heap=1.0GB]
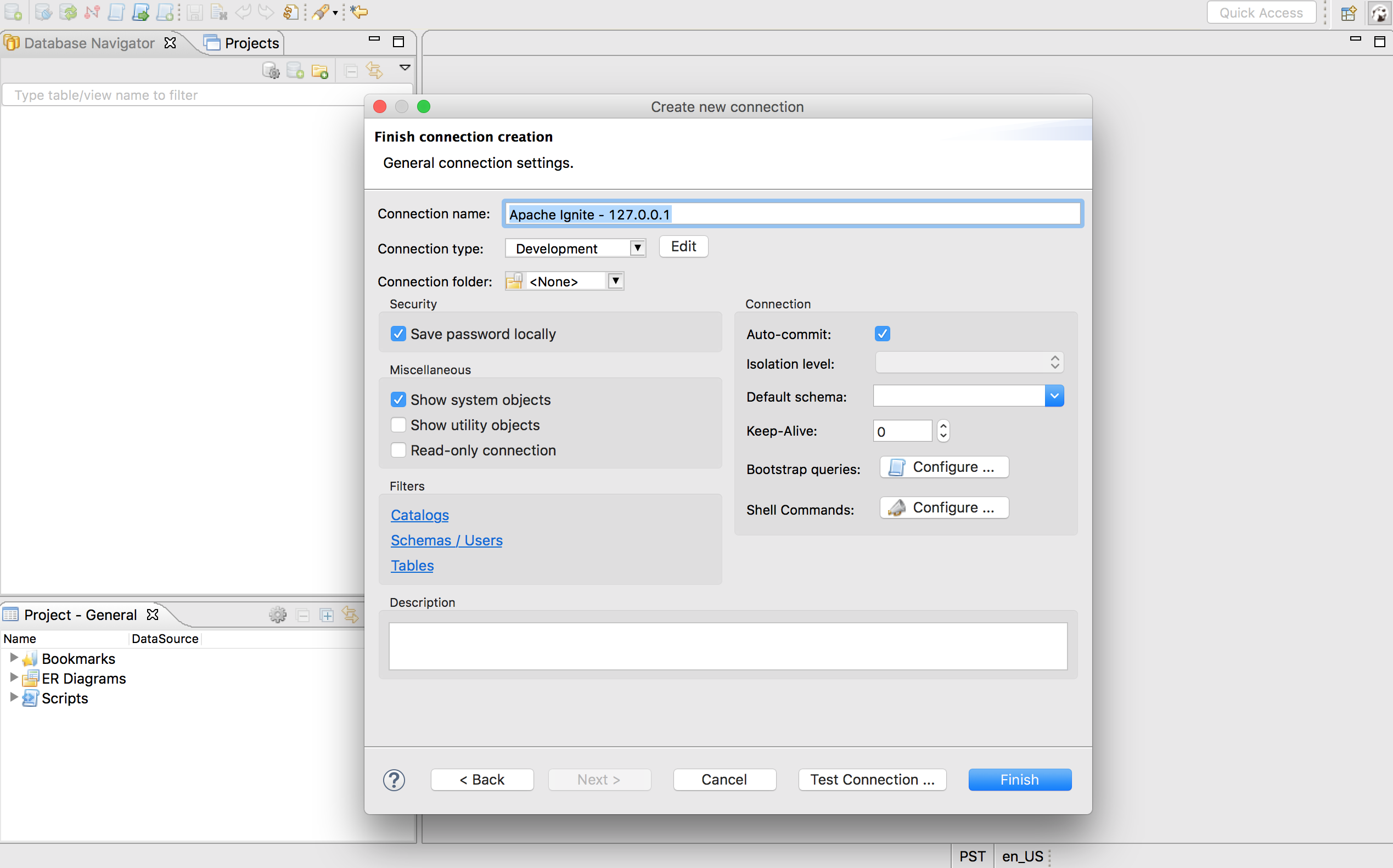
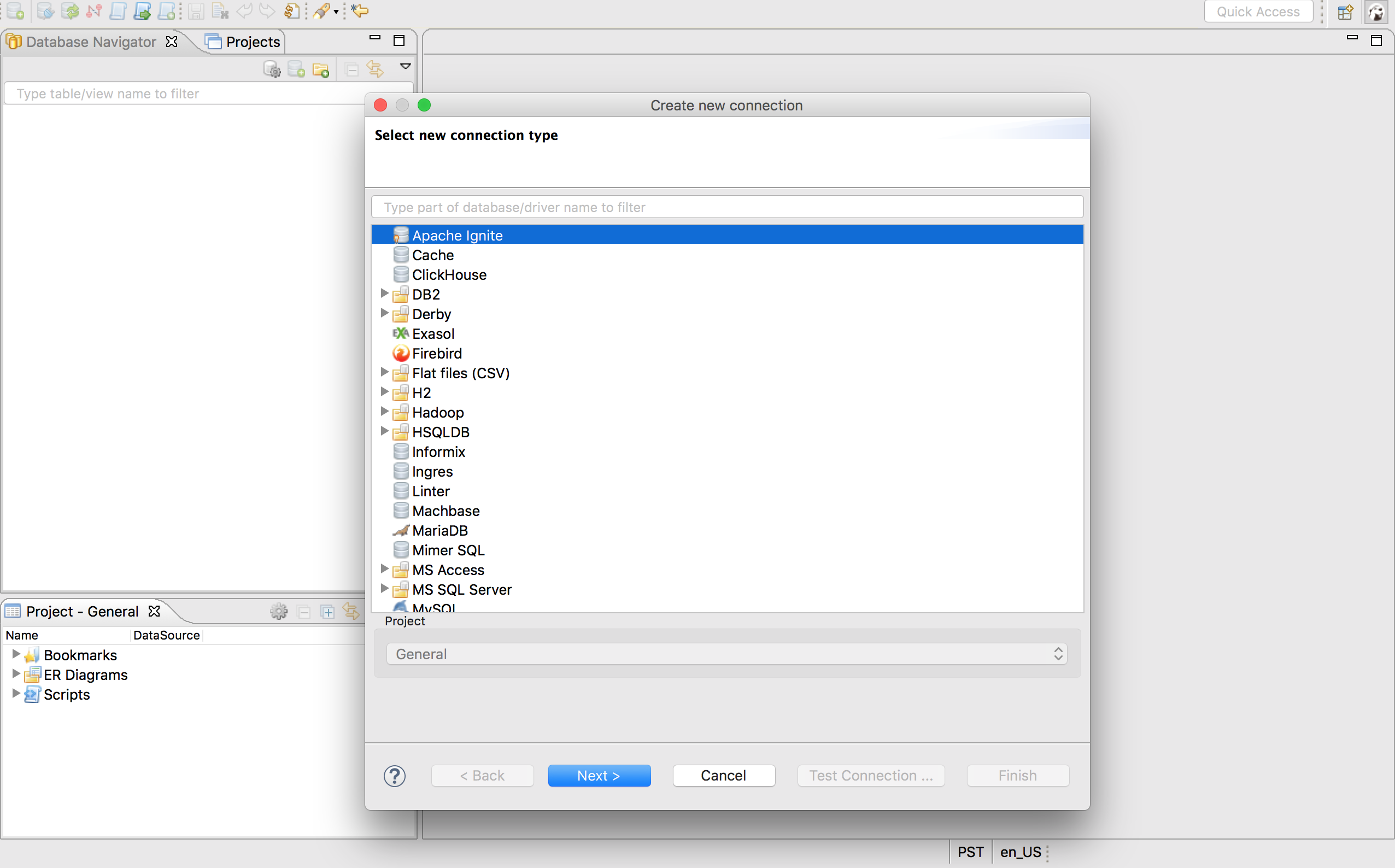
切换到DBeaver然后选择Database->New Connection菜单项,在列表中找到Apache Ignite然后点击Next >按钮:
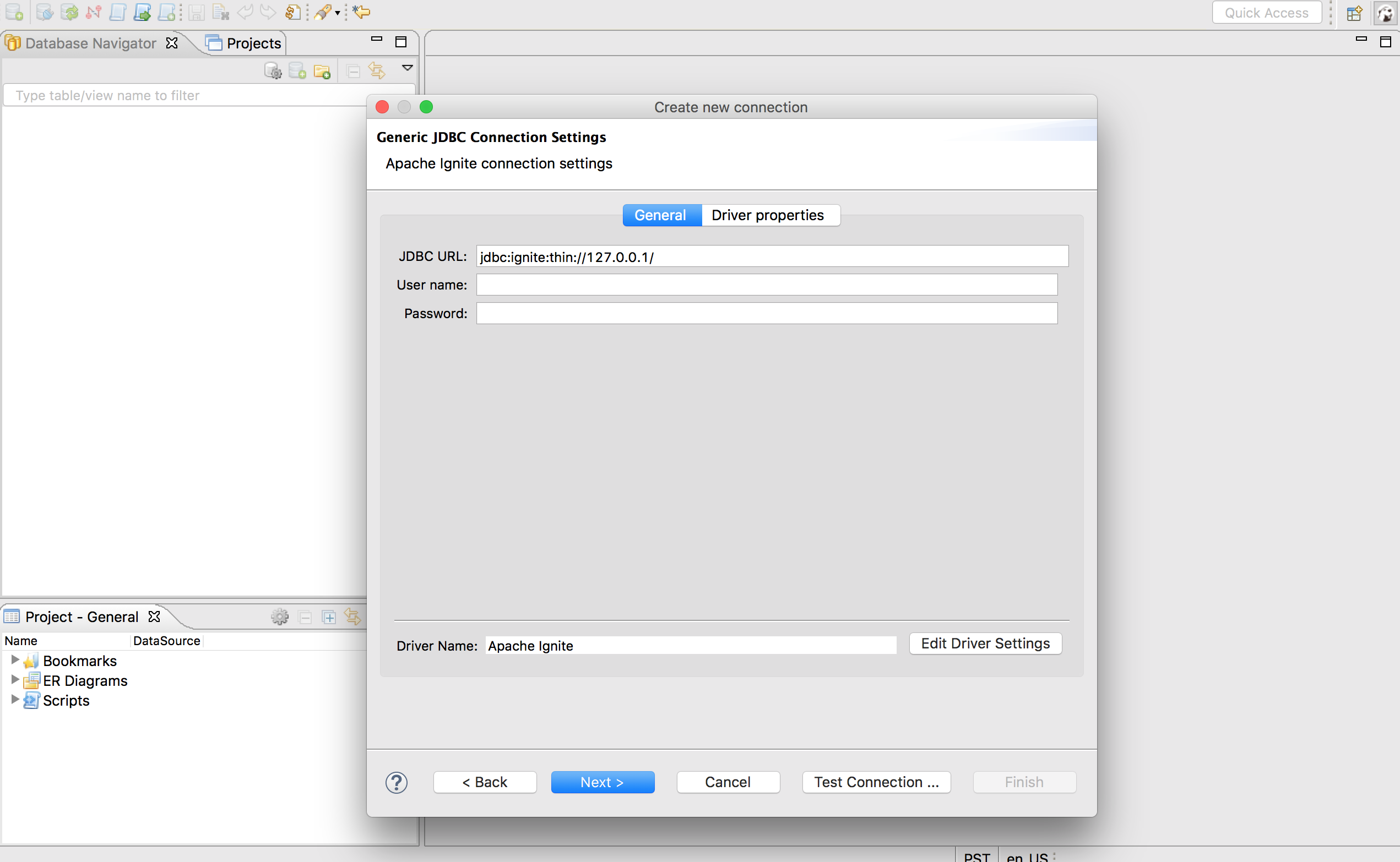
确保JDBC URL配置为前述的jdbc:ignite:thin://127.0.0.1/连接串,然后点击Test Connection ...按钮来验证DBeaver与本地运行的Ignite集群之间的连接。
测试通过之后点击Next >按钮就会跳转到Network界面:
在最后一个界面中确认信息之后点击Finish按钮:
Database Navigator选项卡中就会出现Apache Ignite:
不支持数据库元数据的错误
如果Ignite的版本是2.0或者2.1,在展开Tables、Views或者其他菜单项时,会得到SQL Error: Database metadata not supported by driver这样的错误。Ignite的下一个版本就会支持元数据,但是缺少这个特性并不影响下面会看到的所有使用场景。
4.13.3.数据查询和分析
下一步会定义一个SQL模式,通过DBeaver插入以及查询部分数据,再挑选一些支持的DDL和DML语句。
再一次确保工具已经接入集群,点击右键菜单然后打开SQL Editor:
表和索引的创建
使用下面的SQL语句创建City和Person表:
CREATE TABLE City (id LONG PRIMARY KEY, name VARCHAR)WITH "template=replicated"CREATE TABLE Person (id LONG, name VARCHAR, city_id LONG, PRIMARY KEY (id, city_id))WITH "backups=1, affinityKey=city_id"
将语句粘贴到DBeaver的脚本窗口然后点击Execute SQL Statement菜单项:
创建完表之后,像下面这样定义一些索引:
CREATE INDEX idx_city_name ON City (name)CREATE INDEX idx_person_name ON Person (name)
插入数据
通过如下语句往集群中插入一些记录:
INSERT INTO City (id, name) VALUES (1, 'Forest Hill');INSERT INTO City (id, name) VALUES (2, 'Denver');INSERT INTO City (id, name) VALUES (3, 'St. Petersburg');INSERT INTO Person (id, name, city_id) VALUES (1, 'John Doe', 3);INSERT INTO Person (id, name, city_id) VALUES (2, 'Jane Roe', 2);INSERT INTO Person (id, name, city_id) VALUES (3, 'Mary Major', 1);INSERT INTO Person (id, name, city_id) VALUES (4, 'Richard Miles', 2);
下一步,需要单独(一个一个)地执行所有的语句,在未来的版本中会支持批量插入:
查询数据
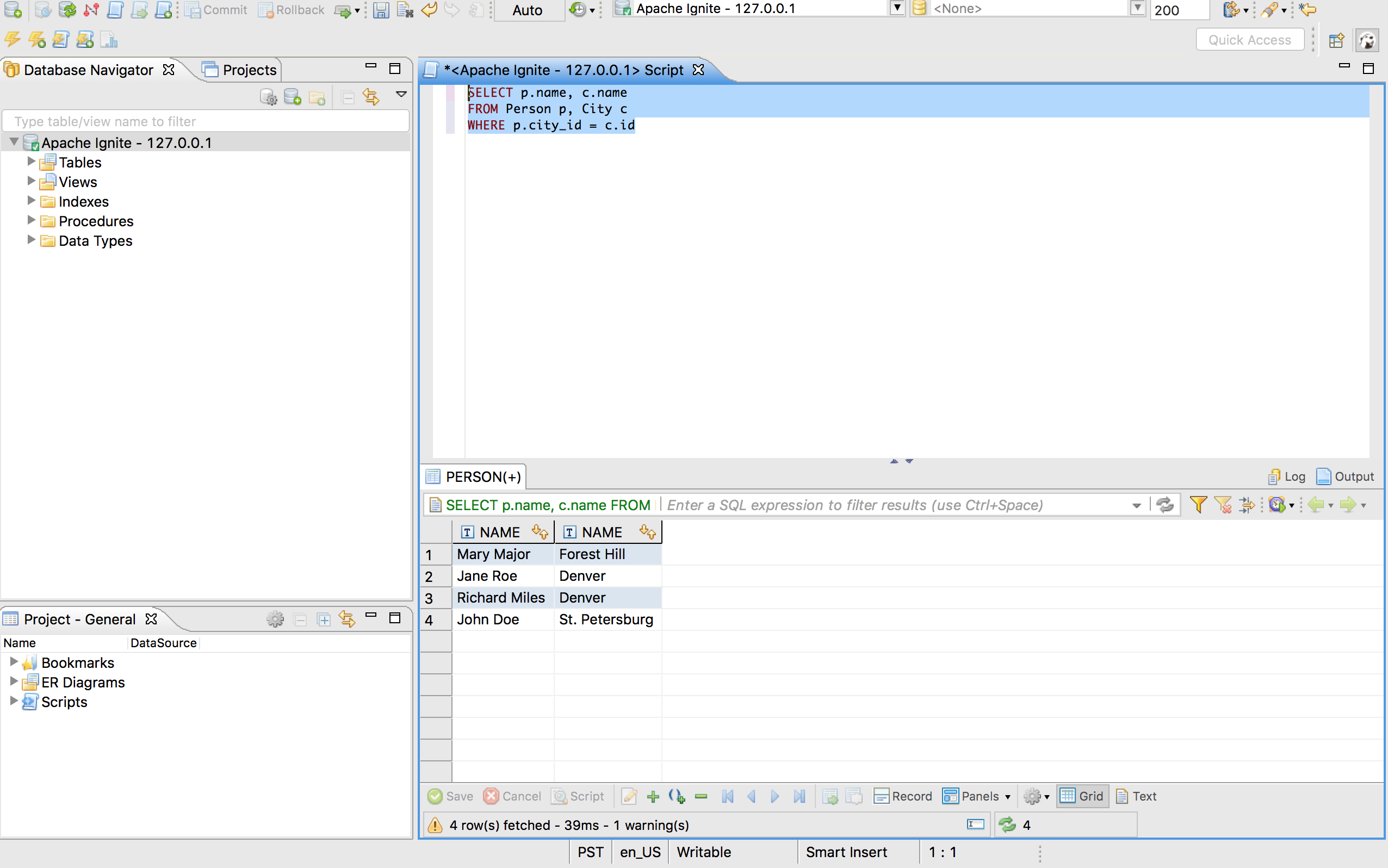
装载数据之后,就可以执行查询了,下面是查询数据的示例,包括两个表之间的关联:
SELECT p.name, c.nameFROM Person p, City cWHERE p.city_id = c.id