@liyuj
2017-09-24T12:32:44.000000Z
字数 7982
阅读 5042
Apache-Ignite-2.2.0-中文开发手册
5.数据注入和流处理
5.1.数据注入和流处理
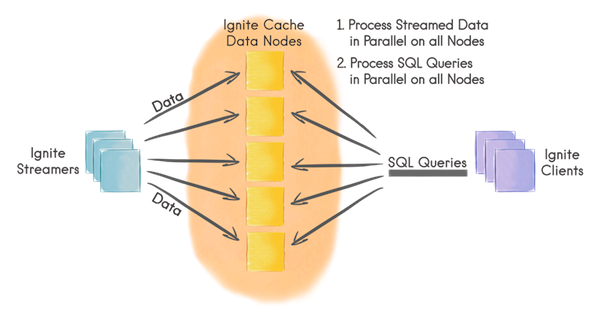
Ignite流处理和数据注入功能可以以可扩展以及容错的方式处理持续不断的数据流或者在集群中预加载初始数据。在一个中等规模的集群中,数据注入Ignite或者预加载数据的速度可以很高,甚至轻易地达到每秒处理百万级的事件。
工作方式
- 客户端节点通过Ignite数据流处理器向Ignite缓存中注入有限的或者持续的数据流;
- 数据在Ignite数据节点间自动分区,每个节点持有均等的数据量;
- 数据流可以在Ignite数据节点上以并置的方式直接并行处理;
- 客户端也可以在数据流上执行并发的SQL查询。
数据加载
从像Ignite持久化存储或者第三方存储这样的数据源中进行数据的预加载,在下面的5.2.数据加载章节中有详细描述。
数据流处理器
数据流处理器是通过IgniteDataStreamerAPI定义的,他可以往Ignite数据流缓存中注入大量的持续不断的数据流,数据流处理器对于所有流入Ignite的数据以可扩展和容错的方式提供了至少一次保证。
查询数据
可以和Ignite的SQL、TEXT以及基于谓词的缓存查询一起使用Ignite数据索引能力的全部功能来在数据流中进行查询。
与已有的流处理技术集成
Ignite可以与各种常见的流处理技术和产品进行集成,比如Kafka,Camel或者JMS,可以容易且高效地将流式数据注入Ignite。
5.2.数据加载
5.2.1.摘要
数据加载通常用于启动时初始化缓存数据,用标准的缓存put(...)和putAll(...)操作加载大量的数据通常是比较低效的。Ignite提供了IgniteDataStreamerAPI和CacheStoreAPI,他们有助于以一个更高效的方式将大量数据注入Ignite缓存。
5.2.2.IgniteDataStreamer
数据流处理器是通过IgniteDataStreamerAPI定义的,他可以将大量的连续数据注入Ignite缓存。数据流处理器以可扩展和容错的方式在数据被发送到集群节点之前通过把批量数据放在一起以获得高性能。
数据流处理器可以用于任何时候将大量数据载入缓存,包括启动时的预加载。
想了解更多信息请参照5.3.数据流处理器。
5.2.3.IgniteCache.loadCache()
要从比如关系数据库这样的第三方存储中预加载大量的数据可以使用CacheStore.loadCache()方法,他可以在不传入要加载的所有键的情况下进行缓存的数据加载。
在所有保存该缓存的每一个集群节点上IgniteCache.loadCache()方法会委托给CacheStore.loadCache()方法,如果只想在本地节点上加载,可以用IgniteCache.localLoadCache()方法。
对于分区缓存以及像关系数据库这样的第三方存储,如果键没有映射到某个节点,不管是主节点还是备份节点,都会被自动忽略。
这与Ignite持久化存储无关,因为每个节点只会存储属于它的数据。
下面是一个第三方存储的CacheStore.loadCache()实现的例子,对于CacheStore的完整例子,可以参照16.2.第三方存储章节。
public class CacheJdbcPersonStore extends CacheStoreAdapter<Long, Person> {...// This method is called whenever "IgniteCache.loadCache()" or// "IgniteCache.localLoadCache()" methods are called.@Override public void loadCache(IgniteBiInClosure<Long, Person> clo, Object... args) {if (args == null || args.length == 0 || args[0] == null)throw new CacheLoaderException("Expected entry count parameter is not provided.");final int entryCnt = (Integer)args[0];Connection conn = null;try (Connection conn = connection()) {try (PreparedStatement st = conn.prepareStatement("select * from PERSONS")) {try (ResultSet rs = st.executeQuery()) {int cnt = 0;while (cnt < entryCnt && rs.next()) {Person person = new Person(rs.getLong(1), rs.getString(2), rs.getString(3));clo.apply(person.getId(), person);cnt++;}}}}catch (SQLException e) {throw new CacheLoaderException("Failed to load values from cache store.", e);}}...}
分区感知的数据加载
在上面描述的第三方存储场景中同样的查询会在所有节点上执行,每个节点会迭代所有的结果集,忽略掉不属于该节点的所有键,效率不是很高。如果数据库中的每条记录都保存分区ID的话这个情况会有所改善。可以通过org.apache.ignite.cache.affinity.Affinity接口来获得要存储在缓存中的任何键的分区ID。
下面的代码片段可以获得每个要存储在缓存中的Person对象的分区ID。
IgniteCache cache = ignite.cache(cacheName);Affinity aff = ignite.affinity(cacheName);for (int personId = 0; personId < PERSONS_CNT; personId++) {// Get partition ID for the key under which person is stored in cache.int partId = aff.partition(personId);Person person = new Person(personId);person.setPartitionId(partId);// Fill other fields.cache.put(personId, person);}
当Person对象知道自己的分区ID,每个节点就可以只查询属于自己所属分区的数据。要做到这一点,可以将一个Ignite实例注入到自己的CacheStore,然后用它来确定本地节点所属的分区。
下面的代码片段演示了用Affinity来只加载本地分区的数据,注意例子代码是单线程的,然而它可以通过分区ID高效地并行化。
public class CacheJdbcPersonStore extends CacheStoreAdapter<Long, Person> {// Will be automatically injected.@IgniteInstanceResourceprivate Ignite ignite;...// This mehtod is called whenever "IgniteCache.loadCache()" or// "IgniteCache.localLoadCache()" methods are called.@Override public void loadCache(IgniteBiInClosure<Long, Person> clo, Object... args) {Affinity aff = ignite.affinity(cacheName);ClusterNode locNode = ignite.cluster().localNode();try (Connection conn = connection()) {for (int part : aff.primaryPartitions(locNode))loadPartition(conn, part, clo);for (int part : aff.backupPartitions(locNode))loadPartition(conn, part, clo);}}private void loadPartition(Connection conn, int part, IgniteBiInClosure<Long, Person> clo) {try (PreparedStatement st = conn.prepareStatement("select * from PERSONS where partId=?")) {st.setInt(1, part);try (ResultSet rs = st.executeQuery()) {while (rs.next()) {Person person = new Person(rs.getLong(1), rs.getString(2), rs.getString(3));clo.apply(person.getId(), person);}}}catch (SQLException e) {throw new CacheLoaderException("Failed to load values from cache store.", e);}}...}
注意键和分区的映射依赖于affinity函数中配置的分区数量(参照org.apache.ignite.cache.affinity.AffinityFunctio)。如果affinity函数配置改变,数据库中存储的分区ID必须相应地更新。
5.3.数据流处理器
5.3.1.摘要
数据流处理器是通过IgniteDataStreamerAPI定义的,用于将大量的持续数据流注入Ignite缓存。数据流处理器以可扩展以及容错的方式,为将所有的数据流注入Ignite提供了至少一次保证。
5.3.2.IgniteDataStreamer
快速地将大量的数据流注入Ignite的主要抽象是IgniteDataStreamer,在内部他会适当地将数据整合成批次然后将这些批次与缓存这些数据的节点并置在一起。
高速加载是通过如下技术获得的:
- 映射到同一个集群节点上的数据条目会作为一个批次保存在缓冲区中;
- 多个缓冲区可以同时共处;
- 为了避免内存溢出,数据流处理器有一个缓冲区的最大数,他们可以并行的处理;
要将数据加入数据流处理器,调用IgniteDataStreamer.addData(...)方法即可。
// Get the data streamer reference and stream data.try (IgniteDataStreamer<Integer, String> stmr = ignite.dataStreamer("myStreamCache")) {// Stream entries.for (int i = 0; i < 100000; i++)stmr.addData(i, Integer.toString(i));}
允许覆写
默认的话,数据流处理器不会覆写已有的数据,这意味着如果遇到一个缓存内已有的条目,他会忽略这个条目。这是一个最有效的以及高性能的模式,因为数据流处理器不需要在后台考虑数据的版本。
如果预想到数据可能在数据流缓存中可能存在以及希望覆写它,设置IgniteDataStreamer.allowOverwrite(true)即可。
流处理器,CacheStore以及允许覆写
AllowOverwrite属性如果是false(默认),持久化存储会被忽略,即使SkipStore属性也是false。
只有当AllowOverwrite为true时,CacheStore才会被调用。
5.3.3.StreamReceiver
对于希望执行一些自定义的逻辑而不仅仅是添加新数据的情况,可以利用一下StreamReceiverAPI。
流接收器可以以并置的方式直接在缓存该数据条目的节点上对数据流做出反应,可以在数据进入缓存之前修改数据或者在数据上添加任何的预处理逻辑。
注意
StreamReceiver不会自动地将数据加入缓存,需要显式地调用任意的cache.put(...)方法。
5.3.4.StreamTransformer
StreamTransformer是一个StreamReceiver的简单实现,他会基于之前的值来修改数据流缓存中的数据。更新是并置的,即他会明确地在数据缓存的集群节点上发生。
在下面的例子中,通过StreamTransformer在文本流中为每个发现的确切的单词增加一个计数。
Java8:
CacheConfiguration cfg = new CacheConfiguration("wordCountCache");IgniteCache<String, Long> stmCache = ignite.getOrCreateCache(cfg);try (IgniteDataStreamer<String, Long> stmr = ignite.dataStreamer(stmCache.getName())) {// Allow data updates.stmr.allowOverwrite(true);// Configure data transformation to count instances of the same word.stmr.receiver(StreamTransformer.from((e, arg) -> {// Get current count.Long val = e.getValue();// Increment count by 1.e.setValue(val == null ? 1L : val + 1);return null;}));// Stream words into the streamer cache.for (String word : text)stmr.addData(word, 1L);}
Java7:
CacheConfiguration cfg = new CacheConfiguration("wordCountCache");IgniteCache<Integer, Long> stmCache = ignite.getOrCreateCache(cfg);try (IgniteDataStreamer<String, Long> stmr = ignite.dataStreamer(stmCache.getName())) {// Allow data updates.stmr.allowOverwrite(true);// Configure data transformation to count instances of the same word.stmr.receiver(new StreamTransformer<String, Long>() {@Override public Object process(MutableEntry<String, Long> e, Object... args) {// Get current count.Long val = e.getValue();// Increment count by 1.e.setValue(val == null ? 1L : val + 1);return null;}});// Stream words into the streamer cache.for (String word : text)stmr.addData(word, 1L);
5.3.5.StreamVisitor
StreamVisitor也是StreamReceiver的一个方便实现,他会访问流中的每个键值组。注意,访问器不会更新缓存。如果键值组需要存储在缓存内,那么需要显式地调用任意的cache.put(...)方法。
在下面的示例中,有两个缓存:marketData和instruments,收到market数据的瞬间就会将他们放入marketData缓存的流处理器,映射到特定market数据的集群节点上的marketData的流处理器的StreamVisitor就会被调用,在分别收到market数据后就会用最新的市场价格更新instrument缓存。
注意,根本不会更新marketData缓存,它一直是空的,只是直接在数据将要存储的集群节点上简单利用了market数据的并置处理能力。
CacheConfiguration<String, Double> mrktDataCfg = new CacheConfiguration<>("marketData");CacheConfiguration<String, Double> instCfg = new CacheConfiguration<>("instruments");// Cache for market data ticks streamed into the system.IgniteCache<String, Double> mrktData = ignite.getOrCreateCache(mrktDataCfg);// Cache for financial instruments.IgniteCache<String, Double> insts = ignite.getOrCreateCache(instCfg);try (IgniteDataStreamer<String, Integer> mktStmr = ignite.dataStreamer("marketData")) {// Note that we do not populate 'marketData' cache (it remains empty).// Instead we update the 'instruments' cache based on the latest market price.mktStmr.receiver(StreamVisitor.from((cache, e) -> {String symbol = e.getKey();Double tick = e.getValue();Instrument inst = instCache.get(symbol);if (inst == null)inst = new Instrument(symbol);// Update instrument price based on the latest market tick.inst.setHigh(Math.max(inst.getLatest(), tick);inst.setLow(Math.min(inst.getLatest(), tick);inst.setLatest(tick);// Update instrument cache.instCache.put(symbol, inst);}));// Stream market data into Ignite.for (Map.Entry<String, Double> tick : marketData)mktStmr.addData(tick);}
