@liyuj
2017-05-18T15:44:17.000000Z
字数 6829
阅读 6046
Apache-Ignite-中文文档
基于Ignite+Lucene+Log4j2的分布式统一日志查询最佳实践
摘要
目前,企业级应用在集群环境下的日志查询,一直是一个痛点,给开发和运维人员带来了一定的困扰,本文基于新的思路,设计了一种新的技术方案,实现了在一个统一的界面中,像数据库表一样对全集群范围的日志进行查询,极大地方便了开发和运维人员,而且具有很强的灵活性。
1.背景
应用开发时的常规做法,是调用日志系统的API进行日志的记录,日志的具体记录方式,通过日志系统实现库对应的配置文件进行配置,比如使用log4j2的话,可能就是log4j2.xml文件,日志通常是记录到文件中的,如果要查看日志,就得登录该服务器进行实地查看。这样如果应用以集群的方式进行部署,然后又不知道问题出现在哪台服务器,这时就需要登录每一台服务器,这给系统的开发、测试和运维带来了很多的麻烦。
但是和时下的互联网公司不同,企业级应用通常不需要对日志进行分析,通过正常的数据存储,比如数据库,就可以获得绝大部分想要的数据。
2.目标
问题是比较明确的,需求也比较清晰,就是希望能设计一套解决方案解决这个问题,大致整理一下,应该包括如下技术点:
- 对应用透明:对应用的开发者而言,还是像原来那样记录日志,不需要关注日志是如何记录、以什么形式保存在哪里的;
- 有相当的灵活性:希望是可以灵活配置的,除了可以按照关键字查询外,最好还可以灵活地自定义其他的维度,方便根据具体的业务场景,进行有针对性的查询,比如按照时间段进行查询,按照具体的业务指标进行查询等;
- 有统一的查询界面:通过一个统一的界面,能够查询到整个集群范围内的日志,比如输入某个关键词,无需关注日志保存在哪台服务器上;
- 有较高的性能:保证有较高的查询速度;
- 低资源占用:占用较少的系统资源,包括CPU、内存,甚至不需要单独的服务器进行部署;
- 部署简单:不需要复杂的配置,部署简单。
3.架构方案
在综合考虑了前述背景、约束以及设计目标,综合考虑了现有开源社区的解决方案之后,我们决定采用Lucene+Ignite+Log4j2的技术方案,整体架构图如下:
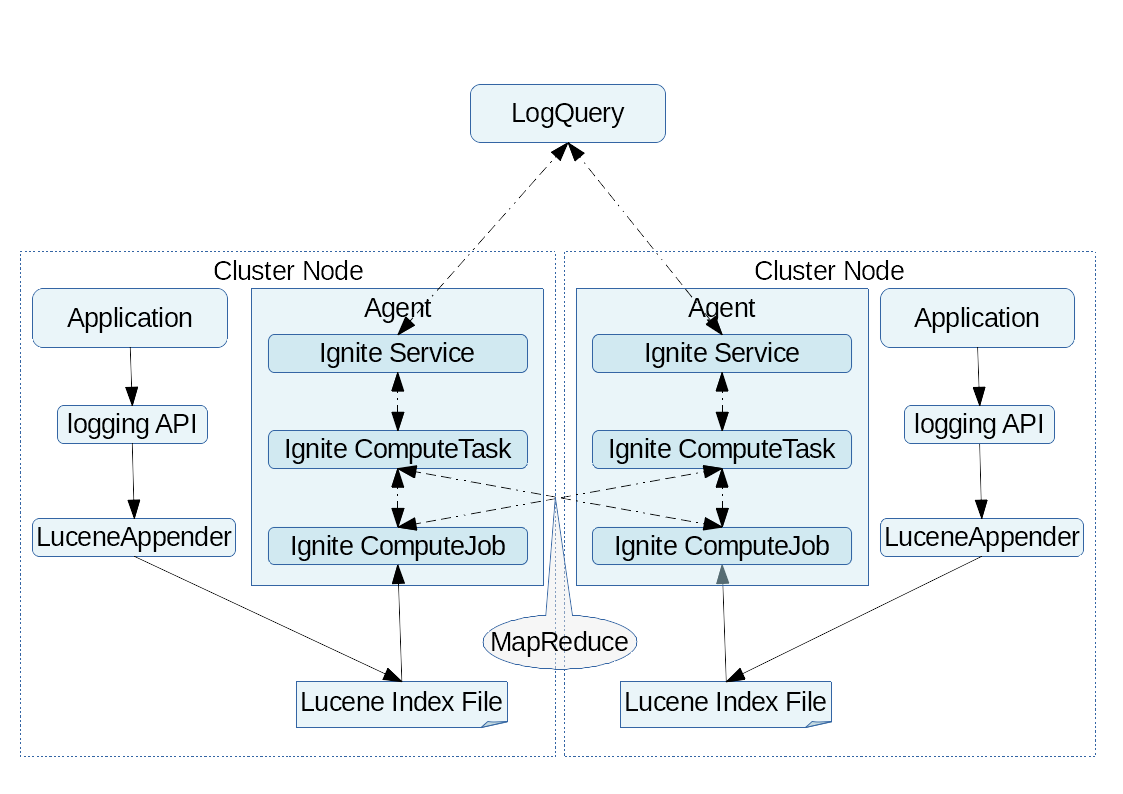
大致描述下设计思路:
- 技术选型:整个技术方案,涉及了三个流行的开源库,分别是:
Lucene、Ignite、Log4j2,我们使用的版本分别是5.5.4、1.9.0和2.7,他们起的作用如下:
- Lucene:用于日志的存储、索引和查询,它为开发者提供了简单明了的API,使用非常方便,
Lucene在这个技术方案中,是实现目标的基础; - Ignite:在这个技术方案中使用了
Ignite的服务网格和计算网格技术,这里,Ignite的服务用于对查询系统暴露接口,Ignite中基于MapReduce范式的嵌入式分布式计算用于任务的分发,查询结果的汇总。Ignite在本技术方案中并非必需,但是使用Ignite的简单API,可以大幅降低本技术方案的实现难度和开发工作量,也使本技术方案变得优雅; - Log4j2:本技术方案中的另一个关键点,就是对
Log4j2进行了扩展,自定义了一套基于Lucene的Appender实现以及对应的log4j2.xml配置方案,它解决了对应用透明的问题,还是整个方案具有灵活性的关键,就是具体对那些属性建立索引、输出那些信息以及输出信息的格式、数据的类型都是在log4j2.xml中进行配置的。
- Lucene:用于日志的存储、索引和查询,它为开发者提供了简单明了的API,使用非常方便,
- 执行流程:
- log4j2.xml配置:首先要进行
log4j2.xml文件的配置,配置方式后面会介绍; - 日志的记录:
log4j2.xml配置好之后,对于应用来说,就按照正常的日志记录方式写代码即可,没有特别的要求,唯一特别要注意的是,如果要针对特别的业务指标建立索引,以名为id的变量为例,那么需要在代码中对相关的上下文变量进行赋值,大体为:ThreadContext.put("id", id);; - Ignite服务的调用:用户通过查询界面输入关键词之后,后台会通过
Ignite服务发布出来的接口调用远程业务系统的服务实现进行实际日志的查询。这里Ignite服务的部署,可以是集群单例,也可以是每节点单例,如果是每节点单例,调用时Ignite会以负载平衡的方式随机地选择一个节点; - 任务的分发:服务的实现会调用
Ignite计算网格的任务(Task),任务会按照集群节点的数量生成对应数量的作业(Job),如果作业数和节点数相等,Ignite会将这些作业平均分到每一个节点上去执行; - 作业的执行:作业的执行过程就是调用
Lucene的API进行实际的查询了,这里没什么特别的,如果只是通过关键字进行查询,会比较简单,如果想通过多维度进行精确地查询,API调用方面会复杂一点,但是都不是难事,不会的可以百度; - 任务的汇总:各个节点查询的结果集,需要汇总后返回给调用端;
- log4j2.xml配置:首先要进行
4.关键技术点
4.1.Ignite
Apache Ignite内存数据组织平台是一个高性能、集成化、混合式的企业级分布式架构解决方案,核心价值在于可以帮助我们实现分布式架构透明化,开发人员根本不知道分布式技术的存在,可以使分布式缓存、计算、存储等一系列功能嵌入应用内部,和应用的生命周期一致,大幅降低了分布式应用开发、调试、测试、部署的难度和复杂度。
4.2.Ignite服务网格
Ignite服务网格以一种优雅的方式实现了分布式RPC,定义一个服务非常简单:
下面通过一个简单的示例演示下Ignite服务的定义、实现、部署和调用:
4.2.1.服务定义
public interface MyCounterService {int get() throws CacheException;}
4.2.2.服务实现
public class MyCounterServiceImpl implements Service, MyCounterService {@Override public int get() {return 0;}}
4.2.3.服务部署
ClusterGroup cacheGrp = ignite.cluster().forCache("myCounterService");IgniteServices svcs = ignite.services(cacheGrp);svcs.deployNodeSingleton("myCounterService", new MyCounterServiceImpl());
4.2.4.服务调用
MyCounterService cntrSvc = ignite.services().serviceProxy("myCounterService", MyCounterService.class, /*not-sticky*/false);System.out.println("value : " + cntrSvc.get());
是不是很简单?
关于服务网格的详细描述,请看这里。
4.3.Ignite计算网格
Ignite的分布式计算是通过IgniteCompute接口提供的,它提供了在集群节点或者一个集群组中运行很多种类型计算的方法,这些方法可以以一个分布式的形式执行任务或者闭包。
本方案中采用的是ComputeTask方式,它是Ignite对于简化内存内MapReduce的抽象。ComputeTask定义了要在集群内执行的作业以及这些作业到节点的映射,还定义了如何处理作业的返回值(Reduce)。所有的IgniteCompute.execute(...)方法都会在集群上执行给定的任务,应用只需要实现ComputeTask接口的map(...)和reduce(...)方法即可,这几个方法的详细描述不在本文讨论的范围内。
下面是一个ComputeTask的简单示例:
IgniteCompute compute = ignite.compute();int cnt = compute.execute(CharacterCountTask.class, "Hello Grid Enabled World!");System.out.println(">>> Total number of characters in the phrase is '" + cnt + "'.");private static class CharacterCountTask extends ComputeTaskSplitAdapter<String, Integer> {@Overridepublic List<ClusterNode> split(int gridSize, String arg) {String[] words = arg.split(" ");List<ComputeJob> jobs = new ArrayList<>(words.length);for (final String word : arg.split(" ")) {jobs.add(new ComputeJobAdapter() {@Override public Object execute() {System.out.println(">>> Printing '" + word + "' on from compute job.");return word.length();}});}return jobs;}@Overridepublic Integer reduce(List<ComputeJobResult> results) {int sum = 0;for (ComputeJobResult res : results)sum += res.<Integer>getData();return sum;}}
通过这样一个简单的类,就实现了梦寐以求的分布式计算!
关于计算网格的详细描述,请看这里。
4.4.自定义的Log4j LuceneAppender扩展
本方案的自定义log4j LuceneAppender扩展,是做到应用无感知,高灵活性和高性能的关键,LuceneAppender的具体实现,不在本文的讨论范围内,但是要介绍下本方案的配置方式,大体配置方式如下(简略):
<Lucene name="luceneAppender" ignoreExceptions="true" target="target/lucene/index" expiryTime="1296000"><IndexField name="logId" pattern="$${ctx:logId}" /><IndexField name="time" pattern="%d{UNIX_MILLIS}" type = "LongField"/><IndexField name="level" pattern="%-5level" /><IndexField name="content" pattern="%class{36} %L %M - %msg%xEx%n" /></Lucene>
其中:target属性表示索引文件的位置,expiryTime属性表示索引过期时间(秒),IndexField标签表示具体的索引项,其中name属性是字段名,pattern属性同log4j自身的pattern属性,type属性表示字段类型,目前支持LongField,TextField以及StringField。
4.5.Lucene分析器
LuceneAppender的实现细节虽然本文不会详细讨论,但是要重点说下分析器的问题。
4.5.1.需求
日志记录的场景整体上还是比较明确的,有哪些信息会被记录到日志中相对比较容易被预见到,根据前述的配置方案,Lucene中具体的索引项,是通过IndexField标签进行配置的,这些项目整体上可分为两类,一类是有具体含义的字段,比如时间,一类是内容不确定的字段,比如日志的内容,对于有具体含义的字段,应该不分词,查询时精确匹配,而对于像内容这样的内容不明确字段,也应该是不分词,但是查询时采用模糊匹配,这样的设计针对日志查询这个场景来说,还是比较合理的。
4.5.2.常见分析器对比
Lucene内置了很多的分析器,常见的比如:WhitespaceAnalyzer、SimpleAnalyzer、StopAnalyzer、StandardAnalyzer、CJKAnalyzer、KeywordAnalyzer等,它们各自特点如下:
| 分析器 | 空格拆分 | 符号拆分 | 数字拆分 | 无用词拆分 | 文字转小写 | 标记文本类型 | 中日韩文字处理 |
|---|---|---|---|---|---|---|---|
WhitespaceAnalyzer |
是 | 否 | 否 | 否 | 否 | 否 | 无 |
SimpleAnalyzer |
是 | 是 | 是 | 否 | 是 | 否 | 无 |
StopAnalyzer |
是 | 是 | 是 | 是 | 是 | 否 | 无 |
StandardAnalyzer |
是 | 部分 | 否 | 否 | 是 | 是 | 逐个拆分 |
CJKAnalyzer |
是 | 部分 | 否 | 是 | 是 | 是 | 双字拆分 |
KeywordAnalyzer |
否 | 否 | 否 | 否 | 否 | 否 | 无 |
4.5.3.结论
根据上述的需求分析,以及对现有的常见分析器对比,KeywordAnalyzer分词器是比较合适的,但是,它有两个约束,一个是区分大小写,如果希望不区分大小写,则需要进行相应的扩展开发,一个是关键字不能多于256个字符,这个约束应该问题不大。
5.优缺点
5.1.优点
- 资源占用少:日志的记录过程,和常规日志的记录没多大区别,没有额外的CPU和内存占用,唯一有较大消耗的,是
Lucene的索引文件需要占用磁盘空间,如果对占用磁盘空间敏感,或者对日志的长期保存没有严格要求,本方案中可以设定索引过期时间,超期的索引会被删除。整个方案是可以不需要额外的服务器软硬件资源进行部署的; - 部署简单:本方案只需要开发一个单独的代理模块和应用部署在一起即可,另外就是查询界面,可以根据需要集成在相应的系统中即可,比如监控系统等;
- 灵活性强:可以根据需要,在日志配置文件中进行灵活的配置,可以配置记录哪些项目,什么格式等,查询界面也可以灵活地定制,根据需要以适应具体的业务场景;
- 开发学习简单:本方案中需要学习的技术不多,只需要熟悉
Ignite和Lucene的开发即可,查询界面可以根据需要而定,没有严格要求。
5.2.缺点
- 需要一定的开发量:这不是一套开箱即用的解决方案,包括查询界面等,是需要开发的,但是工作量不大,如果还有其他的需求,比如日志分析等,只能自行开发;
- 依赖Ignite的集群部署:这套方案查询的范围是Ignite构建的集群或者在这个集群范围内定义的集群组。因此一方面应用要通过Ignite构建集群,另外一方面如果集群内应用较多,为了避免相互干扰,对集群分组也是必要的,这方面可以算做一个强约束。
6.其他的相关方案
仅就开源社区而言,还存在Elastic Stack、Flume等日志处理技术,功能各有侧重,但如果仅仅想做分布式日志的查询的话,这些方案略重,如果这些方案不满足需求需要开发,则工作量略大,以Elastic Stack为例,整个技术栈使用的技术较多,对开发者要求较高,整体定制成本较高。另外这些方案都需要额外,甚至较多的服务器软硬件资源,部署成本较高。
7.适用领域
这套方案整体上来说适用于,或者说面向的是以集群方式部署的企业级交付型软件,厂商可以不受约束的掌控整个方案的方方面面,对客户来说,部署成本也较低。这套方案对于软件的规模没什么限制,整个集群有很多个应用也可以。这类应用对日志处理的需求,功能边界定义可以做到比较清晰,需求不会扩的很大,这样的话,定制ELK解决方案的代价就显得太大了。
而对于互联网公司来说,内部有好多错综复杂的系统,数量可能几十上百,更多的都有,这时在ELK整个技术栈的基础上进行定制,可能更划算,引入这套方案甚至可能都不可行。
8.总结
本方案另辟蹊径,通过新的技术栈,较少的代码解决了长期困扰分布式日志查询这个行业痛点,另外,本方案也开阔了思路,即Ignite这种嵌入式的分布式计算技术,MapReduce计算方式,有非常多的使用场景,不仅仅可以用于常规的计算,还可以用于各种集群环境的数据收集等场景,想象空间很大。
本方案中Lucene作为全文检索领域的行业标准,得到了广泛的应用,大量的解决方案都基于Lucene进行定制开发,Elastic Stack底层也构建于Lucene之上。
如果本方案能称为最佳实践,那么Ignite功不可没。这一类的技术还有其他技术可选,比如Infinispan等,只是这一类的开源嵌入式内存并行计算技术,还没有得到业界的关注而已。
