@liyuj
2017-10-01T16:00:57.000000Z
字数 24646
阅读 4840
Apache-Ignite-2.2.0-中文开发手册
13.ODBC驱动
13.1.ODBC驱动
13.1.1.摘要
Ignite包括一个ODBC驱动,可以通过标准SQL查询和原生ODBC API查询和修改存储于分布式缓存中的数据。
要了解ODBC的细节,可以参照ODBC开发者参考。
Apache Ignite的ODBC驱动实现了ODBC API的3.0版。
13.1.2.集群配置
ODBC驱动在Windows中被视为一个动态库,在Linux中被视为一个共享对象,应用不会直接加载它。作为替代,必要时它会使用一个驱动加载器API来加载和卸载ODBC驱动。
Ignite的ODBC驱动在内部使用TCP协议来接入Ignite集群,这个连接在Ignite中是通过一个叫做OdbcProcessor的组件来处理的。当节点启动时,OdbcProcessor默认是不开启的,要开启这个处理器,需要在IgniteConfiguration中配置OdbcConfiguration:
XML:
<bean id="ignite.cfg" class="org.apache.ignite.configuration.IgniteConfiguration">...<!-- Enabling ODBC. --><property name="odbcConfiguration"><bean class="org.apache.ignite.configuration.OdbcConfiguration"/></property>...</bean>
Java:
IgniteConfiguration cfg = new IgniteConfiguration();...OdbcConfiguration odbcCfg = new OdbcConfiguration();cfg.setOdbcConfiguration(odbcCfg);...
配置了OdbcProcessor之后,就会以默认的配置启动,部分列举如下:
- endpointAddress:绑定的地址,格式是:
hostname[:port_from[..port_to]],默认值是0.0.0.0:10800..10810。如果指定了主机名未指定端口范围,那么会使用默认的端口范围。 - maxOpenCursors:可以同时打开的最大游标数,默认值是128。
- socketSendBufferSize:TCP套接字发送缓冲区大小,默认值是0,表示使用系统默认值。
- socketReceiveBufferSize:TCP套接字接收缓冲区大小,默认值是0,表示使用系统默认值。
- threadPoolSize:线程池中用于处理请求的线程数量,默认值为:
IgniteConfiguration.DFLT_PUBLIC_THREAD_CNT。
可以通过如下方式修改参数:
XML:
<bean id="ignite.cfg" class="org.apache.ignite.configuration.IgniteConfiguration">...<!-- Enabling ODBC. --><property name="odbcConfiguration"><bean class="org.apache.ignite.configuration.OdbcConfiguration"><property name="endpointAddress" value="127.0.0.1:12345..12346"/><property name="maxOpenCursors" value="512"/><property name="socketSendBufferSize" value="65536"/><property name="socketReceiveBufferSize" value="131072"/><property name="threadPoolSize" value="4"/></bean></property>...</bean>
Java:
IgniteConfiguration cfg = new IgniteConfiguration();...OdbcConfiguration odbcCfg = new OdbcConfiguration();odbcCfg.setEndpointAddress("127.0.0.1:12345..12346");odbcCfg.setMaxOpenCursors(512);odbcCfg.setSocketSendBufferSize(65536);odbcCfg.setSocketReceiveBufferSize(131072);odbcCfg.setThreadPoolSize(4);cfg.setOdbcConfiguration(odbcCfg);...
通过OdbcProcessor从ODBC驱动端建立的到集群的连接也是可以配置的,关于如何从驱动端修改连接的配置,可以看这里。
13.1.3.线程安全
Ignite ODBC驱动的当前实现仅仅在连接层提供了线程的安全,这意味着如果没有额外的同步化,无法从多个线程访问同一个连接。不过可以为每个线程创建独立的连接,然后同时使用。
13.1.4.先决条件
Ignite的ODBC驱动官方在如下环境中进行了测试:
| OS | Windows(XP及以上,32位和64位版本) Windows Server(2008及以上,32位和64位版本) Ubuntu(14.x和15.x,64位) |
|---|---|
| C++编译器 | MS Visual C++ (10.0及以上), g++ (4.4.0及以上) |
| Visual Studio | 2010及以上 |
13.1.5.构建ODBC驱动
在Windows中,Ignite现在提供了预构建的32位和64位驱动的安装器,因此如果只是想在Windows中安装驱动,那么直接看下面的安装驱动章节就可以了。
对于Linux环境,安装之前还是需要进行构建,因此如果使用的是Linux或者使用Windows但是仍然想自己构建驱动,那么往下看。
Ignite的ODBC驱动的源代码随着Ignite发行版一起发布,在使用之前可以自行进行构建。关于如何获取和设置Ignite本身,可以参照1.基本概念章节。
因为ODBC驱动是用C++编写的,因此它是作为Ignite C++的一部分提供的,并且依赖于一些C++库,具体点说依赖于utils和binaryIgnite库,这就意味着,在构建ODBC驱动本身之前,需要先构建它们。
在Windows上构建
如果要在Windows上构建ODBC驱动,需要MS Visual Studio 2010及以后的版本,一旦打开了Ignite方案%IGNITE_HOME%\platforms\cpp\project\vs\ignite.sln(或者ignite_86.sln,32位平台),在方案浏览器中左击Ignite项目,然后选择“Build”,Visual Studio会自动地检测并且构建所有必要的依赖。
如果使用VS 2015及以后的版本(MSVC14.0及以后),需要将
legacy_stdio_definitions.lib作为额外的库加入odbc项目的链接器配置以构建项目,要在IDE中将库文件加入链接器,可以打开项目节点的上下文菜单,选择Properties,然后在Project Properties对话框中,选择Linker,然后编辑Linker Input,这时就可以将legacy_stdio_definitions.lib加入分号分割的列表中。
构建过程结束之后,会生成ignite.odbc.dll文件,对于64位版本,位于%IGNITE_HOME%\platforms\cpp\project\vs\x64\Release中,对于32位版本,位于%IGNITE_HOME%\platforms\cpp\project\vs\Win32\Release中。
在Windows中构建安装器
为了简化安装,构建完驱动之后可能想构建安装器,Ignite使用WiX工具包来生成ODBC的安装器,因此需要下载并安装WiX,记得一定要把Wix工具包的bin目录加入PATH变量中。
一切就绪之后,打开终端然后定位到%IGNITE_HOME%\platforms\cpp\odbc\install目录,按顺序执行如下的命令:
64位:
candle.exe ignite-odbc-amd64.wxslight.exe -ext WixUIExtension ignite-odbc-amd64.wixobj
32位:
candle.exe ignite-odbc-x86.wxslight.exe -ext WixUIExtension ignite-odbc-x86.wixobj
完成之后,目录中会出现ignite-odbc-amd64.msi和ignite-odbc-x86.msi文件,然后就可以使用它们进行安装了。
在Linux上构建
在一个基于Linux的操作系统中,如果要构建及使用Ignite ODBC驱动,需要安装选择的ODBC驱动管理器,Ignite ODBC驱动已经使用UnixODBC进行了测试。
要构建驱动及其依赖,还需要额外的GCC,G++以及Make。
如果所有必需的都安装好了,可以通过如下方式构建Ignite ODBC驱动:
d $IGNITE_HOME/platforms/cpplibtoolize && aclocal && autoheader && automake --add-missing && autoreconf./configure --enable-odbc --disable-node --disable-coremake#The following step will most probably require root privileges:make install
构建过程完成后,可以通过如下命令找到ODBC驱动位于何处:
whereis libignite-odbc
路径很可能是:/usr/local/lib/libignite-odbc.so。
13.1.6.安装ODBC驱动
要使用ODBC驱动,首先要在系统中进行注册,因此ODBC驱动管理器必须能找到它。
在Windows上安装
在32位的Windows上需要使用32位版本的驱动,而在64位的Windows上可以使用64位和32位版本的驱动,也可以在64位的Windows上同时安装32位和64位版本的驱动,这样32位和64位的应用都可以使用驱动。
使用安装器进行安装
这时最简单的方式,也是建议的方式,只需要启动指定版本的安装器即可:
- 32位:
%IGNITE_HOME%\platforms\cpp\bin\odbc\ignite-odbc-x86.msi - 64位:
%IGNITE_HOME%\platforms\cpp\bin\odbc\ignite-odbc-amd64.msi
手动安装
要在Windows上手动安装驱动,首先要为驱动在文件系统中选择一个目录,选择一个位置后就可以把驱动放在哪并且确保所有的驱动依赖可以被解析,也就是说,他们要么位于%PATH%,要么和驱动位于同一个目录。
之后,就需要使用%IGNITE_HOME%/platforms/cpp/odbc/install目录下的安装脚本之一,注意,要执行这些脚本,很可能需要管理员权限。
X86:
install_x86 <absolute_path_to_32_bit_driver>
AMD64:
install_amd64 <absolute_path_to_64_bit_driver> [<absolute_path_to_32_bit_driver>]
在Linux上安装
要在Linux上构建和安装ODBC驱动,首先需要安装ODBC驱动管理器,Ignite ODBC驱动已经使用UnixODBC进行了测试。
如果已经构建完成并且执行了make install命令,libignite-odbc.so很可能会位于/usr/local/lib,要在ODBC驱动管理器中安装ODBC驱动并且可以使用,需要按照如下的步骤进行操作:
- 确保链接器可以定位ODBC驱动的所有依赖。可以使用
ldd命令像如下这样进行检查(假定ODBC驱动位于/usr/local/lib):ldd /usr/local/lib/libignite-odbc.so,如果存在到其他库的无法解析的链接,需要将这些库文件所在的目录添加到LD_LIBRARY_PATH; - 编辑
$IGNITE_HOME/platforms/cpp/odbc/install/ignite-odbc-install.ini文件,并且确保Apache Ignite段的Driver参数指向libignite-odbc.so所在的正确位置; - 要安装Ignite的ODBC驱动,可以使用如下的命令:
odbcinst -i -d -f $IGNITE_HOME/platforms/cpp/odbc/install/ignite-odbc-install.ini,要执行这条命令,很可能需要root权限。
到现在为止,Ignite的ODBC驱动已经安装好了并且可以用了,可以像其它ODBC驱动一样,连接、使用。
13.2.连接串和DSN
13.2.1.连接串格式
Ignite的ODBC驱动支持标准的连接串格式,下面是正常的语法:
connection-string ::= empty-string[;] | attribute[;] | attribute; connection-stringempty-string ::=attribute ::= attribute-keyword=attribute-value | DRIVER=[{]attribute-value[}]attribute-keyword ::= identifierattribute-value ::= character-string
简单来说,连接串就是分号分割的键值条目列表,在下面可以看到连接串的示例。
13.2.2.支持的参数
Ignite的ODBC驱动可以使用一些连接串/DSN参数,所有的参数都是大小写不敏感的,因此ADDRESS,Address,address都是有效的参数名,并且指向的是同一个参数。如果参数未指定,会使用默认值,其中的一个例外是ADDRESS属性,如果未指定,会使用SERVER和PORT属性代替:
| 属性关键字 | 描述 | 默认值 |
|---|---|---|
| ADDRESS | 要连接的远程节点的地址,格式为:<host>[:<port>]。比如:localhost, example.com:12345, 127.0.0.1, 192.168.3.80:5893,如果指定了这个属性,SERVER和PORT将会被忽略。 |
|
| SERVER | 要连接的节点地址,如果指定了ADDRESS属性,本属性会被忽略。 |
|
| PORT | 节点的OdbcProcessor监听的端口,如果指定了ADDRESS属性,本属性会被忽略。 |
10800 |
| CACHE | 缓存名,如果未定义会使用默认的缓存,注意,缓存名是区分大小写的。 | |
| DSN | 要连接的DSN名 | |
| PAGE_SIZE | 数据源的响应中返回的行数,默认值会适用于大多数场景,小些的值会导致获取数据变慢,大些的值会导致驱动的额外内存占用,以及获取下一页时的额外延迟。 | 1024 |
| DISTRIBUTED_JOINS | 为在ODBC连接上执行的所有查询开启非并置的分布式关联特性。 | false |
| ENFORCE_JOIN_ORDER | 强制SQL查询中表关联顺序,如果设置为true,查询优化器在关联时就不会对表进行再排序。 |
false |
| PROTOCOL_VERSION | 用于指定使用的ODBC协议版本,目前只有两个版本:1.6.0和1.8.0,如果Ignite版本<1.8.0,需要使用1.6.0协议版本。 | 1.8.0 |
13.2.3.连接串示例
下面的串,可以用于SQLDriverConnectODBC调用,来建立与Ignite节点的连接。
指定缓存:
DRIVER={Apache Ignite};SERVER=localhost;PORT=10800;CACHE=MyCache
默认缓存:
DRIVER={Apache Ignite};SERVER=localhost;PORT=10800
DSN:
DSN=MyIgniteDSN
Legacy节点:
DRIVER={Apache Ignite};ADDRESS=example.com:12901;CACHE=SomeCache;PROTOCOL_VERSION=1.6.0
自定义页面大小:
DRIVER={Apache Ignite};ADDRESS=example.com:12901;CACHE=MyCache;PAGE_SIZE=4096
13.2.4.配置DSN
如果要使用DSN(数据源名)来进行连接,可以使用同样的参数。
要在Windows上配置DSN,需要使用一个叫做odbcad32的系统工具,这是一个ODBC数据源管理器,要启动这个工具,打开控制面板->管理工具->数据源(ODBC),当ODBC数据源管理器启动后,选择添加...->pache Ignite,然后以正确的方式配置DSN。
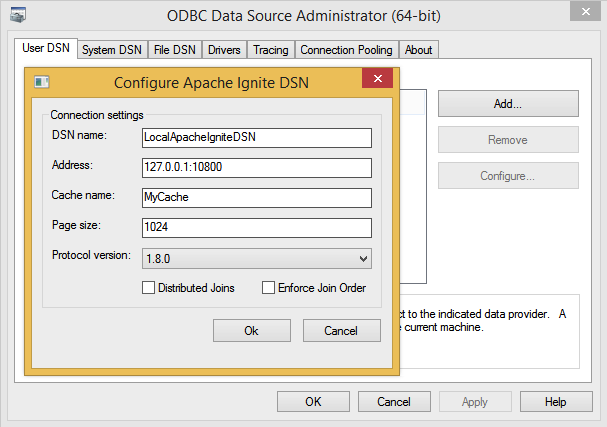
在Linux上配置DSN,需要找到odbc.ini文件,这个文件的位置各个发行版有所不同,依赖于发行版使用的特定驱动管理器,比如,如果使用unixODBC,那么可以执行如下的命令来输出系统级的ODBC相关信息:
odbcinst -j
文件的路径会显示在SYSTEM DATA SOURCES和USER DATA SOURCES属性之间。
找到odbc.ini文件之后,可以用喜欢的任意编辑器打开它,然后像下面这样添加DSN片段:
[DSN Name]description=<Insert your description here>driver=Apache Ignite<Other arguments here...>
13.3.查询和修改数据
像数据库一样访问Ignite。
13.3.1.摘要
本章会详细描述如何接入Ignite集群,如何使用ODBC驱动执行各种SQL查询。
在实现层,Ignite的ODBC驱动使用SQL字段查询来获取Ignite缓存中的数据,这意味着通过ODBC只可以访问这些集群配置中定义的字段。
另外,从Ignite的1.8.0版本开始,ODBC驱动支持DML,这意味着通过ODBC连接不仅仅可以访问数据,还可以修改网格中的数据。
这里是完整的ODBC示例。
13.3.2.配置Ignite集群
第一步,需要对集群节点进行配置,这个配置需要包含缓存的配置以及定义了QueryEntities的属性。如果应用(当前场景是ODBC驱动)要通过SQL语句进行数据的查询和修改,QueryEntities是必须的。
<?xml version="1.0" encoding="UTF-8"?><beans xmlns="http://www.springframework.org/schema/beans"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xmlns:util="http://www.springframework.org/schema/util"xsi:schemaLocation="http://www.springframework.org/schema/beanshttp://www.springframework.org/schema/beans/spring-beans.xsdhttp://www.springframework.org/schema/utilhttp://www.springframework.org/schema/util/spring-util.xsd"><bean id="ignite.cfg" class="org.apache.ignite.configuration.IgniteConfiguration"><!-- Enabling ODBC. --><property name="odbcConfiguration"><bean class="org.apache.ignite.configuration.OdbcConfiguration"/></property><!-- Configuring cache. --><property name="cacheConfiguration"><list><bean class="org.apache.ignite.configuration.CacheConfiguration"><property name="name" value="Person"/><property name="cacheMode" value="PARTITIONED"/><property name="atomicityMode" value="TRANSACTIONAL"/><property name="writeSynchronizationMode" value="FULL_SYNC"/><property name="queryEntities"><list><bean class="org.apache.ignite.cache.QueryEntity"><property name="keyType" value="java.lang.Long"/><property name="valueType" value="Person"/><property name="fields"><map><entry key="firstName" value="java.lang.String"/><entry key="lastName" value="java.lang.String"/><entry key="salary" value="java.lang.Double"/></map></property><property name="indexes"><list><bean class="org.apache.ignite.cache.QueryIndex"><constructor-arg value="salary"/></bean></list></property></bean></list></property></bean><bean class="org.apache.ignite.configuration.CacheConfiguration"><property name="name" value="Organization"/><property name="cacheMode" value="PARTITIONED"/><property name="atomicityMode" value="TRANSACTIONAL"/><property name="writeSynchronizationMode" value="FULL_SYNC"/><property name="queryEntities"><list><bean class="org.apache.ignite.cache.QueryEntity"><property name="keyType" value="java.lang.Long"/><property name="valueType" value="Organization"/><property name="fields"><map><entry key="name" value="java.lang.String"/></map></property><property name="indexes"><list><bean class="org.apache.ignite.cache.QueryIndex"><constructor-arg value="name"/></bean></list></property></bean></list></property></bean></list></property></bean></beans>
从上述配置中可以看出,定义了两个缓存,包含了Person和Organization类型的数据,它们都列出了使用SQL可以读写的特定字段和索引。
预定义字段
除了显式配置的字段外,每个表都有两个特别的预定义字段:_key和_val,它们表示到整个键和值对象的链接。这非常有用,比如,当它们中的一个是基本类型并且希望通过它们的值进行过滤时,要实现这一点,可以执行像SELECT * FROM Person WHERE _key = 100这样的查询。
OdbcConfiguration
确保在配置中显式地配置了OdbcConfiguration。
13.3.3.接入集群
配置好然后启动集群,就可以从ODBC驱动端接入了。如何做呢?准备一个有效的连接串然后连接时将其作为一个参数传递给ODBC驱动就可以了。
另外,也可以像下面这样使用一个预定义的DSN来接入。
SQLHENV env;// Allocate an environment handleSQLAllocHandle(SQL_HANDLE_ENV, SQL_NULL_HANDLE, &env);// Use ODBC ver 3SQLSetEnvAttr(env, SQL_ATTR_ODBC_VERSION, reinterpret_cast<void*>(SQL_OV_ODBC3), 0);SQLHDBC dbc;// Allocate a connection handleSQLAllocHandle(SQL_HANDLE_DBC, env, &dbc);// Prepare the connection stringSQLCHAR connectStr[] = "DSN=My Ignite DSN";// Connecting to Ignite Cluster.SQLRETURN ret = SQLDriverConnect(dbc, NULL, connectStr, SQL_NTS, NULL, 0, NULL, SQL_DRIVER_COMPLETE);if (!SQL_SUCCEEDED(ret)){SQLCHAR sqlstate[7] = { 0 };SQLINTEGER nativeCode;SQLCHAR errMsg[BUFFER_SIZE] = { 0 };SQLSMALLINT errMsgLen = static_cast<SQLSMALLINT>(sizeof(errMsg));SQLGetDiagRec(SQL_HANDLE_DBC, dbc, 1, sqlstate, &nativeCode, errMsg, errMsgLen, &errMsgLen);std::cerr << "Failed to connect to Apache Ignite: "<< reinterpret_cast<char*>(sqlstate) << ": "<< reinterpret_cast<char*>(errMsg) << ", "<< "Native error code: " << nativeCode<< std::endl;// Releasing allocated handles.SQLFreeHandle(SQL_HANDLE_DBC, dbc);SQLFreeHandle(SQL_HANDLE_ENV, env);return;}
13.3.4.查询数据
都准备好后,就可以使用ODBC API执行SQL查询了。
SQLHSTMT stmt;// Allocate a statement handleSQLAllocHandle(SQL_HANDLE_STMT, dbc, &stmt);SQLCHAR query[] = "SELECT firstName, lastName, salary, Organization.name FROM Person ""INNER JOIN \"Organization\".Organization ON Person.orgId = Organization._key";SQLSMALLINT queryLen = static_cast<SQLSMALLINT>(sizeof(queryLen));SQLRETURN ret = SQLExecDirect(stmt, query, queryLen);if (!SQL_SUCCEEDED(ret)){SQLCHAR sqlstate[7] = { 0 };SQLINTEGER nativeCode;SQLCHAR errMsg[BUFFER_SIZE] = { 0 };SQLSMALLINT errMsgLen = static_cast<SQLSMALLINT>(sizeof(errMsg));SQLGetDiagRec(SQL_HANDLE_DBC, dbc, 1, sqlstate, &nativeCode, errMsg, errMsgLen, &errMsgLen);std::cerr << "Failed to perfrom SQL query upon Apache Ignite: "<< reinterpret_cast<char*>(sqlstate) << ": "<< reinterpret_cast<char*>(errMsg) << ", "<< "Native error code: " << nativeCode<< std::endl;}else{// Printing the result set.struct OdbcStringBuffer{SQLCHAR buffer[BUFFER_SIZE];SQLLEN resLen;};// Getting a number of columns in the result set.SQLSMALLINT columnsCnt = 0;SQLNumResultCols(stmt, &columnsCnt);// Allocating buffers for columns.std::vector<OdbcStringBuffer> columns(columnsCnt);// Binding colums. For simplicity we are going to use only// string buffers here.for (SQLSMALLINT i = 0; i < columnsCnt; ++i)SQLBindCol(stmt, i + 1, SQL_C_CHAR, columns[i].buffer, BUFFER_SIZE, &columns[i].resLen);// Fetching and printing data in a loop.ret = SQLFetch(stmt);while (SQL_SUCCEEDED(ret)){for (size_t i = 0; i < columns.size(); ++i)std::cout << std::setw(16) << std::left << columns[i].buffer << " ";std::cout << std::endl;ret = SQLFetch(stmt);}}// Releasing statement handle.SQLFreeHandle(SQL_HANDLE_STMT, stmt);
列绑定
在上例中,所有的列都绑定到SQL_C_CHAR,这意味着获取时所有的值都会被转换成字符串,这样做是为了简化,获取时进行值转换是非常慢的,因此默认的做法应该是与存储采用同样的方式进行获取。
关联和并置
就像直接通过Java、.NET或者C++API进行SQL查询一样,在分区缓存上进行的关联,只有在关联的对象以并置模式存储时才能正常运行,
跨缓存查询
驱动连接的缓存会被视为默认的模式,要跨越多个缓存进行查询,可以使用跨缓存查询功能。
复制和分区缓存
在复制缓存上的查询只会在一个节点上执行,而在分区缓存上的查询会在所有缓存节点上分布式地执行。
13.3.5.插入数据
要将新的数据插入集群,ODBC端可以使用INSERT语句。
SQLHSTMT stmt;// Allocate a statement handleSQLAllocHandle(SQL_HANDLE_STMT, dbc, &stmt);SQLCHAR query[] ="INSERT INTO Person (_key, orgId, firstName, lastName, resume, salary) ""VALUES (?, ?, ?, ?, ?, ?)";SQLPrepare(stmt, query, static_cast<SQLSMALLINT>(sizeof(query)));// Binding columns.int64_t key = 0;int64_t orgId = 0;char name[1024] = { 0 };SQLLEN nameLen = SQL_NTS;double salary = 0.0;SQLBindParameter(stmt, 1, SQL_PARAM_INPUT, SQL_C_SLONG, SQL_BIGINT, 0, 0, &key, 0, 0);SQLBindParameter(stmt, 2, SQL_PARAM_INPUT, SQL_C_SLONG, SQL_BIGINT, 0, 0, &orgId, 0, 0);SQLBindParameter(stmt, 3, SQL_PARAM_INPUT, SQL_C_CHAR, SQL_VARCHAR, sizeof(name), sizeof(name), name, 0, &nameLen);SQLBindParameter(stmt, 4, SQL_PARAM_INPUT, SQL_C_DOUBLE, SQL_DOUBLE, 0, 0, &salary, 0, 0);// Filling cache.key = 1;orgId = 1;strncpy(name, "John", sizeof(firstName));salary = 2200.0;SQLExecute(stmt);SQLMoreResults(stmt);++key;orgId = 1;strncpy(name, "Jane", sizeof(firstName));salary = 1300.0;SQLExecute(stmt);SQLMoreResults(stmt);++key;orgId = 2;strncpy(name, "Richard", sizeof(firstName));salary = 900.0;SQLExecute(stmt);SQLMoreResults(stmt);++key;orgId = 2;strncpy(name, "Mary", sizeof(firstName));salary = 2400.0;SQLExecute(stmt);// Releasing statement handle.SQLFreeHandle(SQL_HANDLE_STMT, stmt);
下面,是不使用预编译语句插入Organization数据:
SQLHSTMT stmt;// Allocate a statement handleSQLAllocHandle(SQL_HANDLE_STMT, dbc, &stmt);SQLCHAR query1[] = "INSERT INTO \"Organization\".Organization (_key, name)VALUES (1L, 'Some company')";SQLExecDirect(stmt, query1, static_cast<SQLSMALLINT>(sizeof(query1)));SQLFreeStmt(stmt, SQL_CLOSE);SQLCHAR query2[] = "INSERT INTO \"Organization\".Organization (_key, name)VALUES (2L, 'Some other company')";SQLExecDirect(stmt, query2, static_cast<SQLSMALLINT>(sizeof(query2)));// Releasing statement handle.SQLFreeHandle(SQL_HANDLE_STMT, stmt);
错误检查
为了简化,上面的代码没有进行错误检查,但是在生产环境中不要这样做。
13.3.6.更新数据
下面使用UPDATE语句更新存储在集群中的部分人员的工资信息:
void AdjustSalary(SQLHDBC dbc, int64_t key, double salary){SQLHSTMT stmt;// Allocate a statement handleSQLAllocHandle(SQL_HANDLE_STMT, dbc, &stmt);SQLCHAR query[] = "UPDATE Person SET salary=? WHERE _key=?";SQLBindParameter(stmt, 1, SQL_PARAM_INPUT,SQL_C_DOUBLE, SQL_DOUBLE, 0, 0, &salary, 0, 0);SQLBindParameter(stmt, 2, SQL_PARAM_INPUT, SQL_C_SLONG,SQL_BIGINT, 0, 0, &key, 0, 0);SQLExecDirect(stmt, query, static_cast<SQLSMALLINT>(sizeof(query)));// Releasing statement handle.SQLFreeHandle(SQL_HANDLE_STMT, stmt);}...AdjustSalary(dbc, 3, 1200.0);AdjustSalary(dbc, 1, 2500.0);
13.3.7.删除数据
最后,使用DELETE语句删除部分记录:
void DeletePerson(SQLHDBC dbc, int64_t key){SQLHSTMT stmt;// Allocate a statement handleSQLAllocHandle(SQL_HANDLE_STMT, dbc, &stmt);SQLCHAR query[] = "DELETE FROM Person WHERE _key=?";SQLBindParameter(stmt, 1, SQL_PARAM_INPUT, SQL_C_SLONG, SQL_BIGINT,0, 0, &key, 0, 0);SQLExecDirect(stmt, query, static_cast<SQLSMALLINT>(sizeof(query)));// Releasing statement handle.SQLFreeHandle(SQL_HANDLE_STMT, stmt);}...DeletePerson(dbc, 1);DeletePerson(dbc, 4);
13.3.8.通过参数数组进行批处理
Ignite的ODBC驱动支持在DML语句中通过参数数组进行批处理。
还是使用上述插入数据的示例,但是只调用一次SQLExecute:
SQLHSTMT stmt;// Allocating a statement handle.SQLAllocHandle(SQL_HANDLE_STMT, dbc, &stmt);SQLCHAR query[] ="INSERT INTO Person (id, orgId, firstName, lastName, resume, salary) ""VALUES (?, ?, ?, ?, ?, ?)";SQLPrepare(stmt, query, static_cast<SQLSMALLINT>(sizeof(query)));// Binding columns.int64_t key[4] = {0};int64_t orgId[4] = {0};char name[1024 * 4] = {0};SQLLEN nameLen[4] = {0};double salary[4] = {0};SQLBindParameter(stmt, 1, SQL_PARAM_INPUT, SQL_C_SLONG, SQL_BIGINT, 0, 0, key, 0, 0);SQLBindParameter(stmt, 2, SQL_PARAM_INPUT, SQL_C_SLONG, SQL_BIGINT, 0, 0, orgId, 0, 0);SQLBindParameter(stmt, 3, SQL_PARAM_INPUT, SQL_C_CHAR, SQL_VARCHAR, 1024, 1024, name, 0, &nameLen);SQLBindParameter(stmt, 4, SQL_PARAM_INPUT, SQL_C_DOUBLE, SQL_DOUBLE, 0, 0, salary, 0, 0);// Filling cache.key[0] = 1;orgId[0] = 1;strncpy(name, "John", 1023);salary[0] = 2200.0;nameLen[0] = SQL_NTS;key[1] = 2;orgId[1] = 1;strncpy(name + 1024, "Jane", 1023);salary[1] = 1300.0;nameLen[1] = SQL_NTS;key[2] = 3;orgId[2] = 2;strncpy(name + 1024 * 2, "Richard", 1023);salary[2] = 900.0;nameLen[2] = SQL_NTS;key[3] = 4;orgId[3] = 2;strncpy(name + 1024 * 3, "Mary", 1023);salary[3] = 2400.0;nameLen[3] = SQL_NTS;// Asking the driver to store the total number of processed argument sets// in the following variable.SQLULEN setsProcessed = 0;SQLSetStmtAttr(stmt, SQL_ATTR_PARAMS_PROCESSED_PTR, &setsProcessed, SQL_IS_POINTER);// Setting the size of the arguments array. This is 4 in our case.SQLSetStmtAttr(stmt, SQL_ATTR_PARAMSET_SIZE, reinterpret_cast<SQLPOINTER>(4), 0);// Executing the statement.SQLExecute(stmt);// Releasing the statement handle.SQLFreeHandle(SQL_HANDLE_STMT, stmt);
注意这种类型的批处理目前只支持INSERT、UPDATE、 DELETE、和MERGE语句,还不支持SELECT,data-at-execution功能也不支持通过参数数组进行批处理。
13.4.规范
ODBC接口一致性
13.4.1.摘要
ODBC定义了若干接口一致性级别,在本章中可以知道Ignite的ODBC驱动支持了哪些特性。
13.4.2.核心接口一致性
| 特性 | 支持程度 | 备注 |
|---|---|---|
| 通过调用SQLAllocHandle和SQLFreeHandle来分配和释放所有处理器类型 | 是 | |
| 使用SQLFreeStmt函数的所有形式 | 是 | |
| 通过调用SQLBindCol,绑定列结果集 | 是 | |
| 通过调用SQLBindParameter和SQLNumParams,处理动态参数,包括参数数组,只针对输入方向, | 是 | |
| 指定绑定偏移量 | 是 | |
| 使用数据执行对话框,涉及SQLParamData和SQLPutData的调用 | 是 | |
| 管理游标和游标名 | 部分 | 实现了SQLCloseCursor,Ignite不支持命名游标 |
| 通过调用SQLColAttribute,SQLDescribeCol,SQLNumResultCols和SQLRowCount,访问结果集的描述(元数据) | 是 | |
| 通过调用目录函数SQLColumns,SQLGetTypeInfo,SQLStatistics和SQLStatistics查询数据字典 | 部分 | 不支持SQLStatistics |
| 通过调用SQLConnect,SQLDataSources,SQLDisconnect和SQLDriverConnect管理数据源和连接,通过SQLDrivers获取驱动的信息,不管支持ODBC那个级别。 | 是 | |
| 通过调用SQLExecDirect,SQLExecute和SQLPrepare预编译和执行SQL语句。 | 是 | |
| 通过调用SQLFetch,或者将FetchOrientation参数设置为SQL_FETCH_NEXT之后调用SQLFetchScroll,获取一个结果集或者多行数据中的一行,只能向前 | 是 | |
| 通过调用SQLGetData,获得一个未绑定的列 | 是 | |
| 通过调用SQLGetConnectAttr、SQLGetEnvAttr、SQLGetStmtAttr,获取所有属性的当前值,或者通过调用SQLSetConnectAttr、SQLSetEnvAttr、SQLSetStmtAttr,将所有属性赋为默认值,以及为特定属性赋为非默认值。 | 部分 | 并不支持所有属性 |
| 通过调用SQLCopyDesc、SQLGetDescField、SQLGetDescRec、SQLSetDescField、SQLSetDescRec,操作描述符的特定字段。 | 否 | |
| 通过调用SQLGetDiagField、SQLGetDiagRec,获得诊断信息。 | 是 | |
| 通过调用SQLGetFunctions和SQLGetInfo,检测驱动兼容性,以及,通过调用SQLNativeSql,在发送到数据源之前检测SQL语句中的任何文本代换的结果 | 部分 | 未实现SQLGetFunctions,SQLGetInfo实现了一部分,实现了SQLNativeSql |
| 使用SQLEndTran的语法提交一个事务,驱动的核心级别不需要支持真事务,因此,应用无法指定SQL_ROLLBACK或者为SQL_ATTR_AUTOCOMMIT连接属性指定SQL_AUTOCOMMIT_OFF | 是 | |
| 调用SQLCancel取消数据执行对话框,以及多线程环境中,在另一个线程中取消ODBC函数的执行,核心级别的接口一致性不需要支持函数的异步执行,也不需要使用SQLCancel取消一个ODBC函数的异步执行。平台和ODBC驱动都不需要多线程地同时自主活动,然而在多线程环境中,ODBC驱动必须是线程安全的,从应用来的请求的序列化是实现这个规范的一致的方式,即使他导致了一系列的性能问题。 | 否 | 当前的ODBC驱动实现不支持异步执行 |
| 通过调用SQLSpecialColumns获得表的行标识符SQL_BEST_ROWID。 | 是 | 当前的实现总是返回空 |
13.4.3.Level1接口一致性
| 特性 | 支持程度 | 备注 |
|---|---|---|
| 指定数据库表和视图的模式(使用两部分命名)。 | 是 | |
| ODBC函数调用的真正异步执行,在给定的连接上,适用的函数要么是全同步的,要么是全异步的。 | 否 | |
使用可滚动的游标,调用SQLFetchScroll时使用FetchOrientation参数而不是SQL_FETCH_NEXT,可以在方法内访问结果集而不是只能向前。 |
否 | |
通过调用SQLPrimaryKeys获得表的主键。 |
部分 | 目前返回空结果集。 |
使用存储过程,通过调用SQLProcedureColumns和SQLProcedures,使用ODBC的转义序列进行存储过程数据字典的查询以及存储过程的调用。 |
否 | |
通过调用SQLBrowseConnect,通过交互式浏览可用的服务器接入一个数据源。 |
否 | |
使用ODBC函数而不是SQL语句来执行特定的数据库操作:带有SQL_POSITION和SQL_REFRESH的SQLSetPos。 |
否 | |
通过调用SQLMoreResults,访问由批处理和存储过程生成的多结果集的内容。 |
是 | |
划定跨越多个ODBC函数的事务边界,获得真正的原子性以及在SQLEndTran中指定SQL_ROLLBACK的能力。 |
否 | Ignite SQL不支持事务 |
13.4.4.Level2接口一致性
| 特性 | 支持程度 | 备注 |
|---|---|---|
| 使用三部分命名的数据库表和视图。 | 否 | Ignite SQL不支持catalog。 |
通过调用SQLDescribeParam描述动态参数。 |
是 | |
| 不仅仅使用输入参数,还使用输出参数以及输入/输出参数,还有存储过程的结果。 | 否 | Ignite SQL不支持输出参数。 |
使用书签,通过在第0列上调用SQLDescribeCol和SQLColAttribute获得书签;通过调用SQLFetchScroll时将参数FetchOrientation配置为SQL_FETCH_BOOKMARK,在书签上进行获取;通过调用SQLBulkOperations时将参数配置为SQL_UPDATE_BY_BOOKMARK、SQL_DELETE_BY_BOOKMARK、SQL_FETCH_BY_BOOKMARK可以进行书签的更新、删除和获取操作。 |
否 | Ignite SQL不支持书签。 |
通过调用SQLColumnPrivileges、SQLForeignKeys、SQLTablePrivileges获取数据字典的高级信息。 |
部分 | SQLForeignKeys已经实现,但是返回空的结果集。 |
通过在SQLBulkOperations中使用SQL_ADD或者在SQLSetPos中使用SQL_DELETE或SQL_UPDATE,使用ODBC函数而不是SQL语句执行额外的数据库操作。 |
否 | |
| 为特定的个别语句开启ODBC函数的异步执行。 | 否 | |
通过调用SQLSpecialColumns获得表的SQL_ROWVER列标识符。 |
部分 | 已实现,但是返回空结果集。 |
为SQL_ATTR_CONCURRENCY语句参数配置除了SQL_CONCUR_READ_ONLY以外的至少一个值。 |
否 | |
登录请求以及SQL查询的超时功能(SQL_ATTR_LOGIN_TIMEOUT和SQL_ATTR_QUERY_TIMEOUT)。 |
否 | |
修改默认隔离级别的功能,在隔离级别为序列化时支持事务的功能。 |
否 | Ignite SQL不支持事务。 |
13.4.5.函数支持
| 函数名 | 支持程度 | 一致性级别 |
|---|---|---|
| SQLAllocHandle | 是 | Core |
| SQLBindCol | 是 | Core |
| SQLBindParameter | 是 | Core |
| SQLBrowseConnect | 否 | Level1 |
| SQLBulkOperations | 否 | Level1 |
| SQLCancel | 否 | Core |
| SQLCloseCursor | 是 | Core |
| SQLColAttribute | 是 | Core |
| SQLColumnPrivileges | 否 | Level2 |
| SQLColumns | 是 | Core |
| SQLConnect | 是 | Core |
| SQLCopyDesc | 否 | Core |
| SQLDataSources | N/A | Core |
| SQLDescribeCol | 是 | Core |
| SQLDescribeParam | 否 | Level2 |
| SQLDisconnect | 是 | Core |
| SQLDriverConnect | 是 | Core |
| SQLDrivers | N/A | Core |
| SQLEndTran | 部分 | Core |
| SQLExecDirect | 是 | Core |
| SQLExecute | 是 | Core |
| SQLFetch | 是 | Core |
| SQLFetchScroll | 是 | Core |
| SQLForeignKeys | 部分 | Level2 |
| SQLFreeHandle | 是 | Core |
| SQLFreeStmt | 是 | Core |
| SQLGetConnectAttr | 否 | Core |
| SQLGetCursorName | 否 | Core |
| SQLGetData | 是 | Core |
| SQLGetDescField | 否 | Core |
| SQLGetDescRec | 否 | Core |
| SQLGetDiagField | 是 | Core |
| SQLGetDiagRec | 是 | Core |
| SQLGetEnvAttr | 是 | Core |
| SQLGetFunctions | 否 | Core |
| SQLGetInfo | 是 | Core |
| SQLGetStmtAttr | 部分 | Core |
| SQLGetTypeInfo | 是 | Core |
| SQLMoreResults | 部分 | Level1 |
| SQLNativeSql | 是 | Core |
| SQLNumParams | 是 | Core |
| SQLNumResultCols | 是 | Core |
| SQLParamData | 是 | Core |
| SQLPrepare | 是 | Core |
| SQLPrimaryKeys | 是 | Level1 |
| SQLProcedureColumns | 否 | Level1 |
| SQLProcedures | 否 | Level1 |
| SQLPutData | 是 | Core |
| SQLRowCount | 是 | Core |
| SQLSetConnectAttr | 否 | Core |
| SQLSetCursorName | 否 | Core |
| SQLSetDescField | 否 | Core |
| SQLSetDescRec | 否 | Core |
| SQLSetEnvAttr | 是 | Core |
| SQLSetPos | 否 | Level1 |
| SQLSetStmtAttr | 部分 | Core |
| SQLSpecialColumns | 否 | Core |
| SQLStatistics | 否 | Core |
| SQLTablePrivileges | 否 | Level2 |
| SQLTables | 是 | Core |
13.4.6.环境属性一致性
| 特性 | 支持程度 | 一致性级别 |
|---|---|---|
SQL_ATTR_CONNECTION_POOLING |
否 | 可选 |
SQL_ATTR_CP_MATCH |
否 | 可选 |
SQL_ATTR_ODBC_VER |
是 | Core |
SQL_ATTR_OUTPUT_NTS |
是 | 可选 |
13.4.7.连接属性一致性
| 特性 | 支持程度 | 一致性级别 |
|---|---|---|
SQL_ATTR_ACCESS_MODE |
否 | Core |
SQL_ATTR_ASYNC_ENABLE |
否 | Level1/Level2 |
SQL_ATTR_AUTO_IPD |
否 | Level2 |
SQL_ATTR_AUTOCOMMIT |
否 | Level1 |
SQL_ATTR_CONNECTION_DEAD |
否 | Level1 |
SQL_ATTR_CONNECTION_TIMEOUT |
否 | Level2 |
SQL_ATTR_CURRENT_CATALOG |
否 | Level2 |
SQL_ATTR_LOGIN_TIMEOUT |
否否 | Level2 |
SQL_ATTR_ODBC_CURSORS |
否否 | Core |
SQL_ATTR_PACKET_SIZE |
否 | Level2 |
否SQL_ATTR_QUIET_MODE |
否 | Core |
SQL否_ATTR_TRACE |
否 | Core |
SQL_AT否TR_TRACEFILE |
否 | Core |
SQL_AT否TR_TRANSLATE_LIB |
否 | Core |
SQL_ATTR_TRANSLATE_OPTION |
否 | Core |
SQL_ATTR_TXN_ISOLATION |
否 | Level1/Level2 |
13.4.8.语句属性一致性
| 特性 | 支持程度 | 一致性级别 |
|---|---|---|
SQL_ATTR_APP_PARAM_DESC |
部分 | Core |
SQL_ATTR_APP_ROW_DESC |
部分 | Core |
SQL_ATTR_ASYNC_ENABLE |
否 | Level1/Level2 |
SQL_ATTR_CONCURRENCY |
否 | Level1/Level2 |
SQL_ATTR_CURSOR_SCROLLABLE |
否 | Level1 |
SQL_ATTR_CURSOR_SENSITIVITY |
否 | Level2 |
SQL_ATTR_CURSOR_TYPE |
否 | Level1/Level2 |
SQL_ATTR_ENABLE_AUTO_IPD |
否 | Level2 |
SQL_ATTR_FETCH_BOOKMARK_PTR |
否 | Level2 |
SQL_ATTR_IMP_PARAM_DESC |
部分 | Core |
SQL_ATTR_IMP_ROW_DESC |
部分 | Core |
SQL_ATTR_KEYSET_SIZE |
否 | Level2 |
SQL_ATTR_MAX_LENGTH |
否 | Level1 |
SQL_ATTR_MAX_ROWS |
否 | Level1 |
SQL_ATTR_METADATA_ID |
否 | Core |
SQL_ATTR_NOSCAN |
否 | Core |
SQL_ATTR_PARAM_BIND_OFFSET_PTR |
是 | Core |
SQL_ATTR_PARAM_BIND_TYPE |
否 | Core |
SQL_ATTR_PARAM_OPERATION_PTR |
否 | Core |
SQL_ATTR_PARAM_STATUS_PTR |
否 | Core |
SQL_ATTR_PARAMS_PROCESSED_PTR |
是 | Core |
SQL_ATTR_PARAMSET_SIZE |
是 | Core |
SQL_ATTR_QUERY_TIMEOUT |
否 | Level2 |
SQL_ATTR_RETRIEVE_DATA |
否 | Level1 |
SQL_ATTR_ROW_ARRAY_SIZE |
是 | Core |
SQL_ATTR_ROW_BIND_OFFSET_PTR |
是 | Core |
SQL_ATTR_ROW_BIND_TYPE |
否 | Core |
SQL_ATTR_ROW_NUMBER |
否 | Level1 |
SQL_ATTR_ROW_OPERATION_PTR |
否 | Level1 |
SQL_ATTR_ROW_STATUS_PTR |
是 | Core |
SQL_ATTR_ROWS_FETCHED_PTR |
是 | Core |
SQL_ATTR_SIMULATE_CURSOR |
否 | Level2 |
SQL_ATTR_USE_BOOKMARKS |
否 | Level2 |
13.4.9.描述符头字段一致性
| 特性 | 支持程度 | 一致性级别 |
|---|---|---|
SQL_DESC_ALLOC_TYPE |
否 | Core |
SQL_DESC_ARRAY_SIZE |
否 | Core |
SQL_DESC_ARRAY_STATUS_PTR |
否 | Core/Level1 |
SQL_DESC_BIND_OFFSET_PTR |
否 | Core |
SQL_DESC_BIND_TYPE |
否 | Core |
SQL_DESC_COUNT |
否 | Core |
SQL_DESC_ROWS_PROCESSED_PTR |
否 | Core |
13.4.10.描述符记录字段一致性
| 特性 | 支持程度 | 一致性级别 |
|---|---|---|
SQL_DESC_AUTO_UNIQUE_VALUE |
否 | Level2 |
SQL_DESC_BASE_COLUMN_NAME |
否 | Core |
SQL_DESC_BASE_TABLE_NAME |
否 | Level1 |
SQL_DESC_CASE_SENSITIVE |
否 | Core |
SQL_DESC_CATALOG_NAME |
否 | Level2 |
SQL_DESC_CONCISE_TYPE |
否 | Core |
SQL_DESC_DATA_PTR |
否 | Core |
SQL_DESC_DATETIME_INTERVAL_CODE |
否 | Core |
SQL_DESC_DATETIME_INTERVAL_PRECISION |
否 | Core |
SQL_DESC_DISPLAY_SIZE |
否 | Core |
SQL_DESC_FIXED_PREC_SCALE |
否 | Core |
SQL_DESC_INDICATOR_PTR |
否 | Core |
SQL_DESC_LABEL |
否 | Level2 |
SQL_DESC_LENGTH |
否 | Core |
SQL_DESC_LITERAL_PREFIX |
否 | Core |
SQL_DESC_LITERAL_SUFFIX |
否 | Core |
SQL_DESC_LOCAL_TYPE_NAME |
否 | Core |
SQL_DESC_NAME |
否 | Core |
SQL_DESC_NULLABLE |
否 | Core |
SQL_DESC_OCTET_LENGTH |
否 | Core |
SQL_DESC_OCTET_LENGTH_PTR |
否 | Core |
SQL_DESC_PARAMETER_TYPE |
否 | Core/Level2 |
SQL_DESC_PRECISION |
否 | Core |
SQL_DESC_ROWVER |
否 | Level1 |
SQL_DESC_SCALE |
否 | Core |
SQL_DESC_SCHEMA_NAME |
否 | Level1 |
SQL_DESC_SEARCHABLE |
否 | Core |
SQL_DESC_TABLE_NAME |
否 | Level1 |
SQL_DESC_TYPE |
否 | Core |
SQL_DESC_TYPE_NAME |
否 | Core |
SQL_DESC_UNNAMED |
否 | Core |
SQL_DESC_UNSIGNED |
否 | Core |
SQL_DESC_UPDATABLE |
否 | Core |
