@liyuj
2016-09-02T13:59:32.000000Z
字数 2999
阅读 5367
Apache-Ignite-1.7.0-中文开发手册
4.交互式SQL
4.1.Ignite与Apache Zeppelin
4.1.1.概览
Apache Zeppelin,是一个支持交互式数据分析的基于Web的笔记本,他可以用SQL,Scala以及其他的工具来生成漂亮的数据驱动的,交互式以及可协同的文档。
Zeppelin通过Ignite的SQL解释器从缓存中获得分布式的数据,此外,当SQL无法满足需求时Ignite解释器可以执行任何的Scala代码。比如,可以将数据注入缓存或者执行分布式计算。
4.1.2.Zeppelin安装和配置
为了通过Ignite解释器启动,需要用2个简单的步骤来安装Zeppelin:
- 克隆Zeppelin的Git仓库:
git clone https://github.com/apache/incubator-zeppelin.git
- 从源代码构建:
cd incubator-zeppelinmvn clean install -Dignite-version=1.2.0-incubating -DskipTests
用指定的Ignite版本构建Zeppelin
在构建Zeppelin时可以通过ignite-version属性来指定Ignite的版本,需要使用1.1.0-incubating以及之后的版本。添加Ignite解释器
Ignite和Ignite解释器默认已经在Zeppelin中配置了。另外也可以将如下的解释器类名加入相应的配置文件或者环境变量中(可以参照Zeppelin安装向导的配置章节)。
org.apache.zeppelin.ignite.IgniteInterpreterorg.apache.zeppelin.ignite.IgniteSqlInterpreter
注意第一个解释器会成为默认值。
一旦Zeppelin安装配置好了,可以用如下的命令来启动:
./bin/zeppelin-daemon.sh start
然后可以在浏览器中打开启动页(默认的启动页地址是 http://localhost:8080).
也可以参照Zeppelin安装文档.
4.1.3.配置Ignite解释器
点击Interpreter菜单项,这个页面包含了所有的已配置的解释器组的设置信息。向下滚动到Ignite章节然后点击Edit按钮可以修改属性的值,点击Save按钮可以保存配置的变更,不要忘了配置变更后重启解释器。
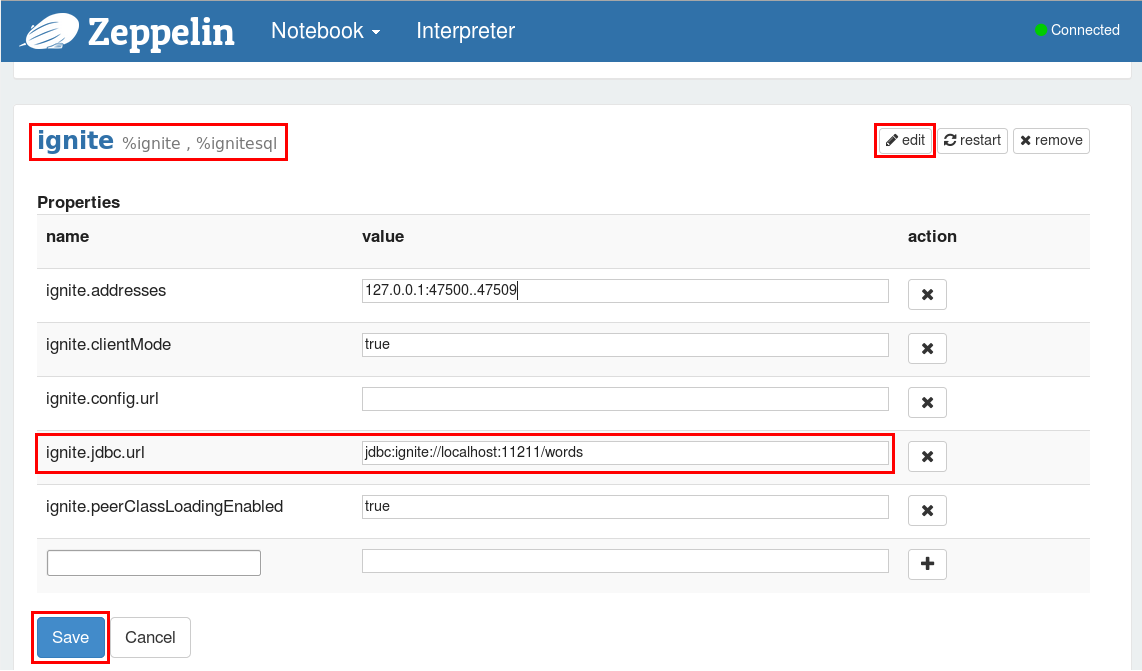
配置Ignite SQL 解释器
Ignite SQL解释器只需要ignite.jdbc.url属性,他的值是JDBC连接地址,在后面的示例中会用到words缓存,因此像下面这样编辑ignite.jdbc.url属性:
jdbc:ignite://localhost:11211/words
要了解详细信息可以参照3.19.JDBC驱动章节。
配置Ignite解释器
在大多数简单的场景中,Ignite解释器需要下述属性:
ignite.addresses:逗号分割的Ignite集群主机列表,要了解细节信息可以参照2.4.集群配置章节;ignite.clientMode:可以以客户端节点也可以以服务端节点连接到Ignite集群,要了解细节可以参照1.6.客户端和服务器端章节。可以使用true或者false分别以客户端或者服务端模式连接到集群。ignite.peerClassLoadingEnabled:启用对等类加载,要了解细节可以参照2.5.零部署章节。可以用true或者false分别启用或者禁用对等类加载。
对于更复杂的场景,可以通过指向Ignite配置文件的ignite.config.url属性来自定义Ignite配置,注意如果定义了ignite.config.url属性,那么上述的属性都会被忽略。
4.1.4.使用Ignite解释器
启动Ignite集群
在使用Zeppelin之前需要启动Ignite集群,下载Ignite发行版然后解压压缩包:
unzip apache-ignite-fabric-1.6.0-bin.zip -d <dest_dir>
示例是以一个单独的Maven工程的形式提供的,因此要启动运行只需要简单地导入<dest_dir>/apache-ignite-fabric-1.6.0-bin/pom.xml文件到喜欢的IDE中即可。
启动如下的示例:
org.apache.ignite.examples.ExampleNodeStartup:启动一个或者多个Ignite节点;org.apache.ignite.examples.streaming.wordcount.StreamWords:启动客户端节点使数据持续流入words缓存。
现在已经准备好通过Zeppelin来访问Ignite集群了。
在Zeppelin中创建新的笔记
通过Notebook菜单项创建(或者打开已有的)笔记。
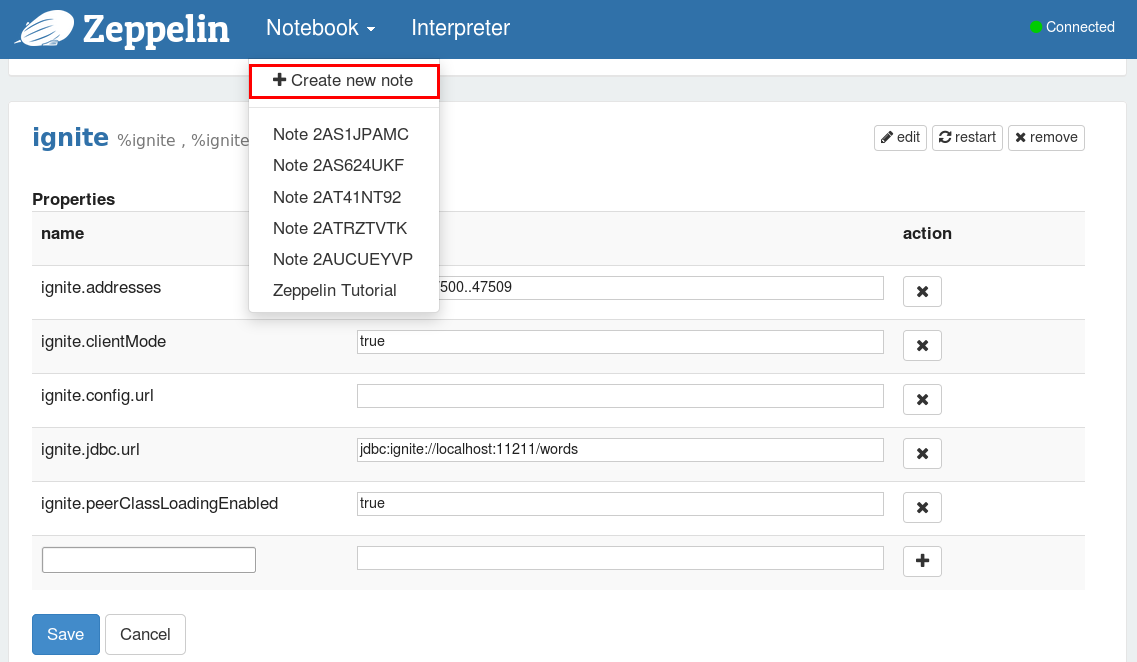
创建新的笔记之后需要再次点击Notebook菜单项来打开创建的笔记,点击笔记的名字可以对他重新命名,输入新的标题然后按下回车键。
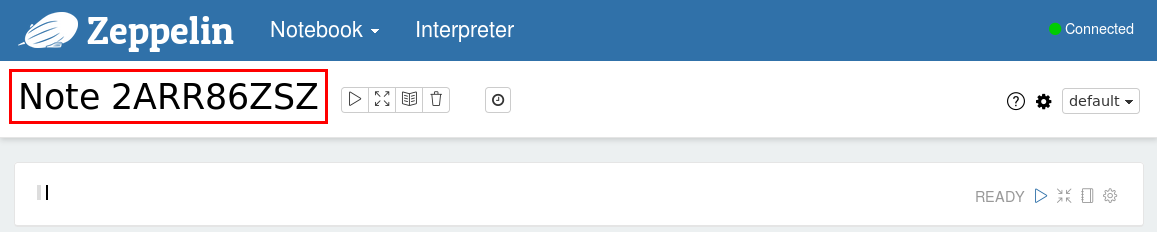
笔记创建之后就可以输入SQL语句或者Scala代码,通过点击Execute按钮来执行(蓝色三角形图标)。
使用Ignite SQL解释器
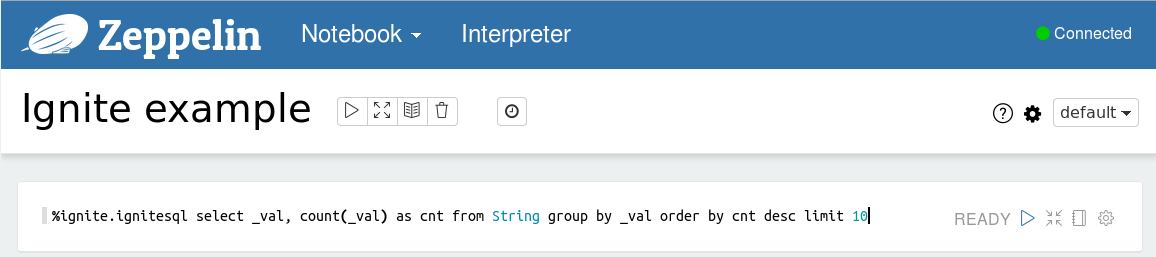
要执行SQL查询要使用%ignite.ignitesql前缀以及SQL语句,比如查询words缓存中最初的是个单词,可以使用如下的查询:
%ignite.ignitesql select _val, count(_val) as cnt from String group by _val order by cnt desc limit 10
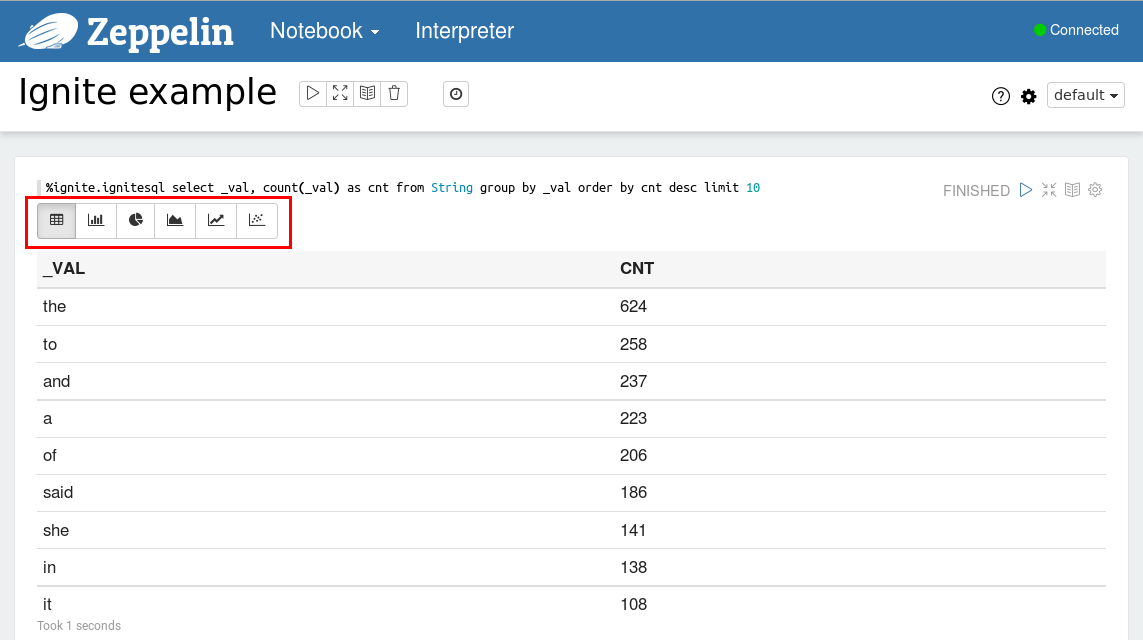
执行示例之后可以以表格或者图形的形式查看结果,可以通过点击相应的图标来切换视图。
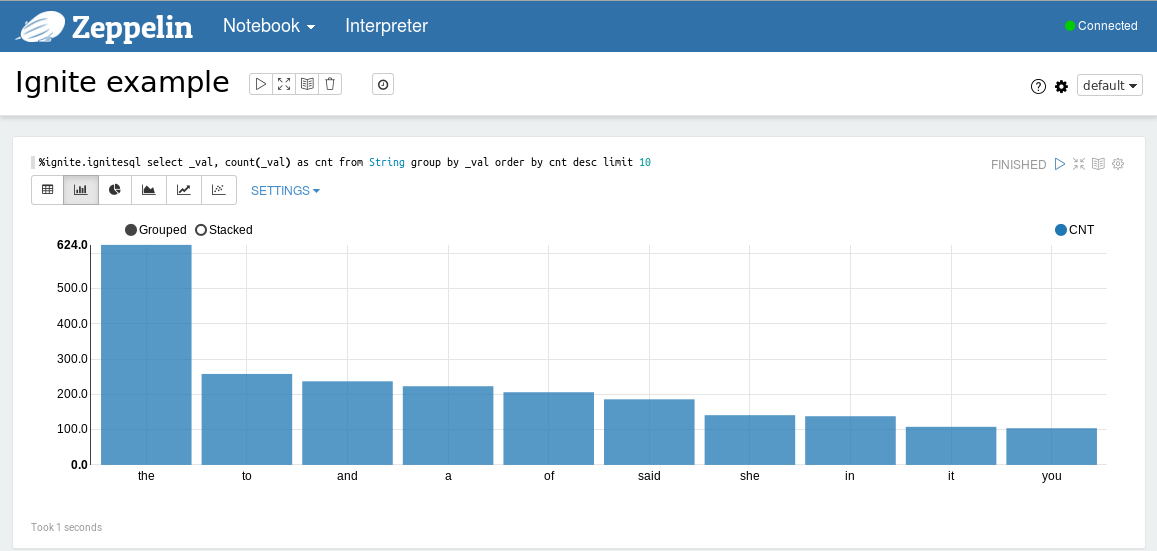
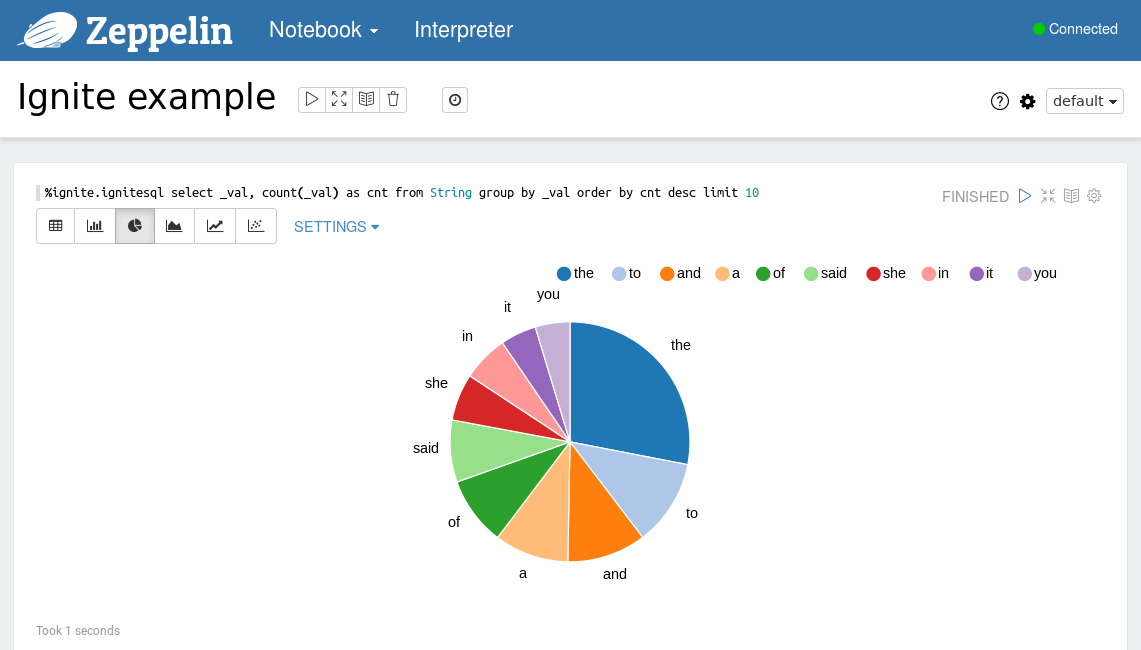
使用Ignite解释器
要执行Scala代码片段需要使用%ignite前缀以及代码片段,比如可以在所有的单词中查询平均值,最小值以及最大值。
%igniteimport org.apache.ignite._import org.apache.ignite.cache.affinity._import org.apache.ignite.cache.query._import org.apache.ignite.configuration._import scala.collection.JavaConversions._val cache: IgniteCache[AffinityUuid, String] = ignite.cache("words")val qry = new SqlFieldsQuery("select avg(cnt), min(cnt), max(cnt) from (select count(_val) as cnt from String group by _val)", true)val res = cache.query(qry).getAll()collectionAsScalaIterable(res).foreach(println _)
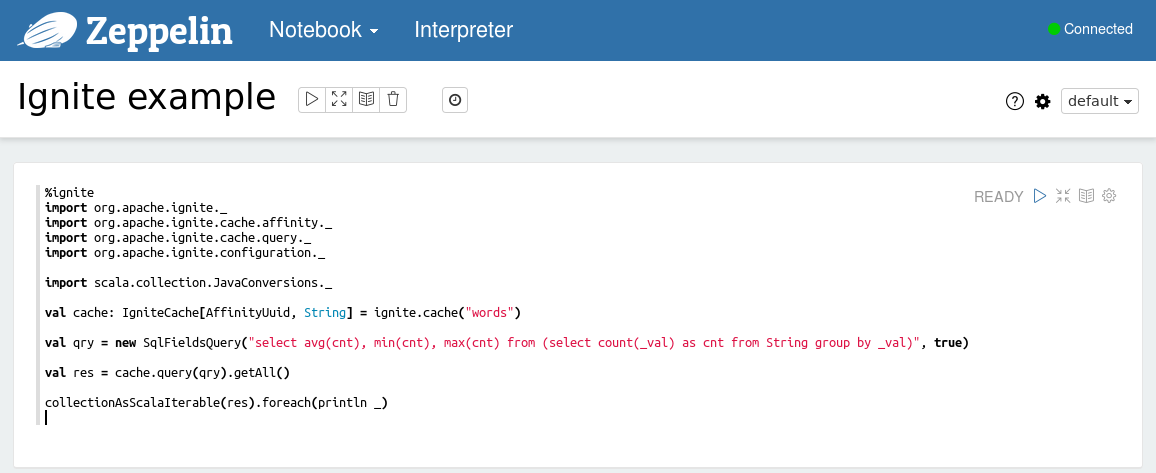
执行这个示例之后就可以看到Scala REPL的输出:
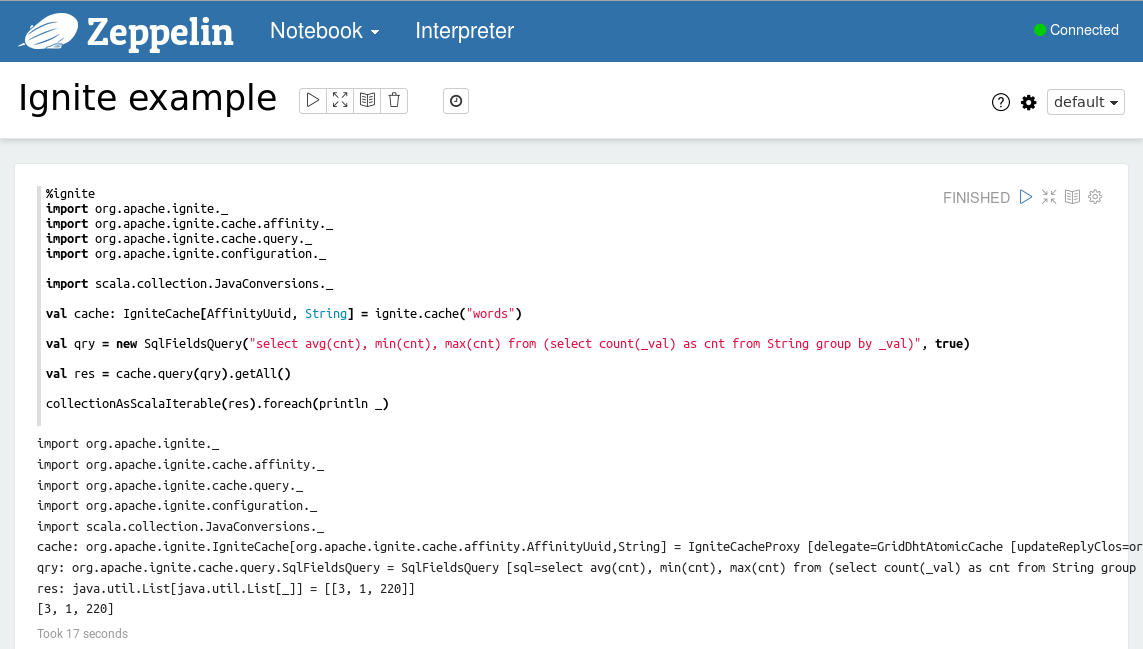
注意Ignite集群的Ignite版本以及Zeppelin的版本必须匹配。
