@liyuj
2017-10-03T08:33:18.000000Z
字数 3541
阅读 5071
Apache-Ignite-2.2.0-中文开发手册
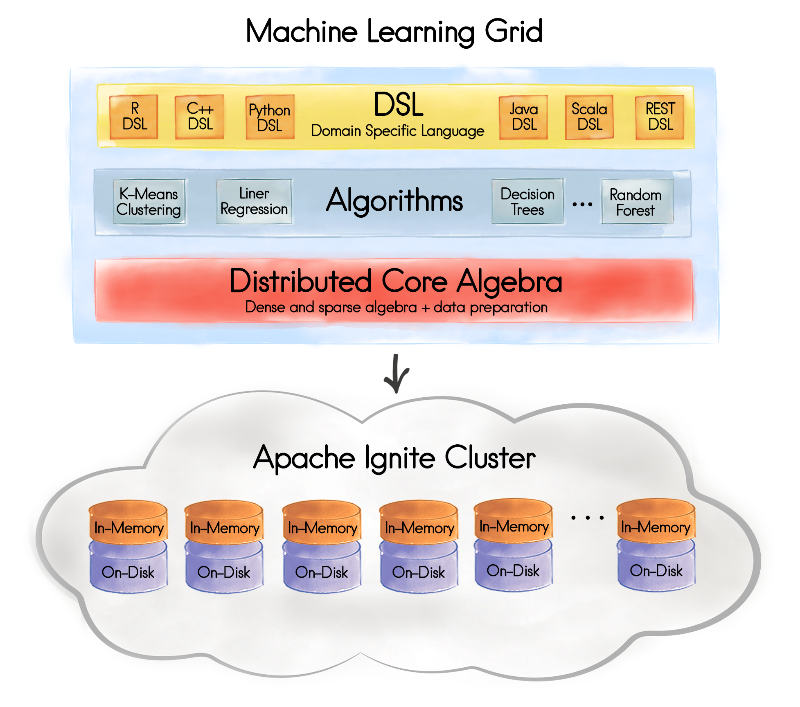
15.机器学习网格
15.1.机器学习网格
15.1.1.摘要
Ignite的2.0版本带来了自己的名为机器学习网格(MLGrid)的分布式机器学习库的第一版。
构建机器学习网格的理由非常简单,许多用户将Ignite作为各种数据集的核心高性能存储和处理系统,当他们想处理机器学习或者深度学习时(比如模型的训练和推理),需要通过ETL工具将数据转移到其他的系统中,比如Apache Mahout或者Apache Spark。
这导致了两个严重缺陷:
- 他引入了一个代价高昂的ETL步骤,这个步骤让人困惑,并且使ML/DL只能在过时的数据集上执行;
- 第二,它削弱了Ignite核心的协同分布式处理,导致整体处理速度变慢。
机器学习网格是解决这两个问题的第一步,Ignite的机器学习网格可以使用户在数据网格上存储的数据集上直接进行ML/DL的训练和推理,并且提供经过专门优化的ML/DL算法,在Ignite的协同分布式处理之后,可以在最新的数据上获得非常高的性能。
机器学习网格的路线图是在Ignite的协同分布式处理之上实现核心的代数开始的。初始版发布于Ignite的2.0版,未来的版本会为Python、R和Scala引入自定义DSL,经过优化的机器学习算法也会增多,比如线性和逻辑回归、决策树/随机森林、SVM、朴素贝叶斯、以及对经过Ignite优化的神经网络的支持还有TensorFlow的集成。
当前,Ignite机器学习网格测试版支持在高度优化和可扩展的Ignite平台基础上构建一个分布式的机器学习库,实现了本地和分布式化的向量和矩阵代数操作以及广泛使用的算法的分布式版本。
15.1.2.入门
MLGrid入门的最快方式是构建和运行它的示例代码,学习它的输出和代码,机器学习的的示例代码位于Ignite发行版的examples目录中,这里是它的GitHub链接。
下面是相关的步骤:
- 一定要使用JDK8及以后的版本;
- 下载Ignite的2.0及以后的版本;
- 在比如IntelliJ IDEA或者Eclipse这样的IDE中打开
examples工程; - 在配置工程时激活
mlprofile; - 在IDE中打开
src\main\ml文件夹然后运行MLGrid示例;
该示例不需要特别的配置,所有的MLGrid示例在没有人为干预的情况下,都支持启动、运行、停止,然后在控制台中输出有意义的信息。另外,还支持一个跟踪器API示例,它会启动一个Web浏览器然后提供一些HTML输出。
15.1.3.从源代码构建
Ignite MLGrid最新版的jar包已经上传到Maven仓库,如果需要获取该jar包然后部署到特定的环境中,那么要么从Maven仓库中进行下载,或者从源代码进行构建,要从源代码进行构建的话,按照如下步骤进行操作:
- 下载Ignite最新的发行版的源代码;
- 清空Maven的本地仓库(这个是避免旧版本的可能影响);
- 确保使用JDK8及以后的版本;
- 从工程的根目录构建并安装Ignite;
mvn clean install -DskipTests -Dmaven.javadoc.skip=true -P java8
- 从工程根目录构建并安装MLGrid;
mvn install -Pml -DskipTests -U -pl modules/ml -am
- 在本地仓库的
{user_dir}/.m2/repository/org/apache/ignite/ignite-ml/{ignite-version}/ignite-ml-{ignite-version}.jar中找到机器学习的jar包; - 如果要从源代码构建MLGrid的示例,执行如下的命令:
cd examplesmvn clean package -DskipTests -Pml
如果必要,可以参考项目根目录的DEVNOTES.txt文件以及ignite-ml模块的README文件,以了解更多的信息。
15.2.K-Means集群
Ignite的机器学习网格提供了两个版本的K-Means集群算法实现,KMeansLocalClusterer只能在本地数据上进行集群处理,而KMeansDistributedClusterer则可以在分布式数据集上进行处理。
下面从KMeansLocalClusterer开始,它是以距离度量、用于随机操作的种子以及最大迭代次数作为参数的:
KMeansLocalClusterer clusterer = new KMeansLocalClusterer(new EuclideanDistance(), 1, 1L);
下面为集群创建一个输入:
double[] v1 = new double[] {1959, 325100};double[] v2 = new double[] {1960, 373200};DenseLocalOnHeapMatrix points = new DenseLocalOnHeapMatrix(new double[][] {v1, v2});
然后将这些points传递给cluster:
KMeansModel mdl = clusterer.cluster(points, 1)
然后获得包含集群信息的模型,比如,下面的代码获取了集群的centers:
mdl.centers()
另外,还有一种方法可以预测一个特定的点所属的集群:
Integer clusterInx = mdl.predict(new DenseLocalOnHeapVector(new double[] {20.0, 30.0}))
KMeansDistributedClusterer以同样的方式工作,但是它需要启动Ignite并且接收SparseLocalOnHeapMatrix作为参数。
目前,KMeansLocalClusterer需要一个DenseLocalOnHeap矩阵作为作为一个输入参数,但是任何本地的矩阵都可以,未来当引入一个单独的本地矩阵接口时,该方法就可以接收它的任意实现,分布式的矩阵和集群也是同样的道理。
15.3.OLS(普通最小二乘)多元线性回归
OLS(普通最小二乘)多元线性回归是广泛使用的基本机器学习算法之一,Ignite支持它的分布式版本,本文档会描述它的原理和实现。
多元线性回归参数(b, u)可以描述为下面方程的解:
y = X*b + u
u的最小平方和。这里X是一个(n,m)矩阵,b是一个叫做regression parameters的k-向量,而u是一个叫做residuals的k-向量。在几何中,上面方程的解在(m+1)维向量空间中是线性分布的,矩阵X可以被视为模型训练的输入。
下面会介绍这个算法的使用:
首先,创建一个OLSMultipleLinearRegression类的实例:
OLSMultipleLinearRegression regression = new OLSMultipleLinearRegression();
下一步,准备一些数据:
y = new double[] {11.0, 12.0, 13.0, 14.0, 15.0, 16.0};x = new double[6][];x[0] = new double[] {0, 0, 0, 0, 0};x[1] = new double[] {2.0, 0, 0, 0, 0};x[2] = new double[] {0, 3.0, 0, 0, 0};x[3] = new double[] {0, 0, 4.0, 0, 0};x[4] = new double[] {0, 0, 0, 5.0, 0};x[5] = new double[] {0, 0, 0, 0, 6.0};
然后将其加载进已经创建的回归对象中:
DenseLocalOnHeapMatrix xm = new DenseLocalOnHeapMatrix(m).regression.newSampleData(new DenseLocalOnHeapVector(y), m);
OLSMultipleLinearRegression默认通过在左边添加一个额外的列来增加输入矩阵,该列填充为1,这样对于模型来说可以确保超线不会跨越原点(中心),这个行为可以通过如下方式禁用:
regression.setNoIntercept(true);
下一步就可以预测回归参数:
double[] betaHat = regression.estimateRegressionParameters();
还有残差:
double[] residuals = regression.estimateResiduals();
