@liyuj
2017-12-05T16:27:53.000000Z
字数 14744
阅读 6526
Apache-Ignite-2.3.0-中文开发手册
11.生产准备
11.1.生产准备
本章涵盖了在准备将系统迁移到生产环境时的主要考虑因素。
11.2.容量规划
11.2.1.摘要
对系统容量进行编制和规划是设计的一个必要组成部分。理解需要的缓存大小有助于决定需要多少物理内存、多少JVM、多少CPU和服务器。本章节会讨论有助于规划和确定一个部署的最小硬件需求的各种技术。
11.2.2.规划内存使用量
- 计算主数据大小:每个条目的大小(字节)乘以条目的总数量
- 如果需要备份,乘以备份的数量
- 索引也需要内存,基本的用例是增加一个30%的量
- 每个缓存大约增加20MB(如果显式地指定
IgniteSystemProperties.IGNITE_ATOMIC_CACHE_DELETE_HISTORY_SIZE为比默认值小的值,这个值可以减小)。 - 每个节点增加大约200-300MB,为内部存储以及为了JVM和GC高效运行预留的合理的量。
GridGain通常会为每个条目增加200个字节。
内存容量规划示例
以如下的场景举例:
- 2,000,000个对象
- 每个对象1,024个字节(1KB)
- 1个备份
- 4个节点
总对象数量 x 对象大小 x 2(每个对象一主一备)
2,000,000 x 1,024 x 2 = 4,096,000,000 字节
考虑到索引:
4,096,000,000 + (4,096,000,000 x 30%) = 5,078 MB
平台大约需要的额外内存:
300 MB x 4 = 1,200 MB
总大小:
5,078 + 1,200 = 6,278 MB
因此,预期的总内存消耗将超过 ~6GB
11.2.3.规划计算使用量
如果在没有代码的情况下规划计算通常来说很难进行估计,理解应用中要执行的每个操作要花费的成本是非常重要的,然后再乘以各种情况下预期要执行的操作的数量。为此一个非常好的起点就是Ignite的基准测试,它详细描述了标准操作的执行结果,以及提供这种性能所必要的粗略的容量需求。
在32核4.large的AWS实例上,性能测试结果如下:
PUT/GET: 26k/s
PUT (事务): 68k/s
PUT (事务 - 悲观): 20k/s
PUT (事务 - 乐观): 44k/s
SQL查询: 72k/s
这里提供更多的信息。
11.2.4.容量规划FAQ
- DB中有300GB的数据,Ignite中会不会也是这样的?
不是,磁盘上的数据大小不能直接1:1地映射到内存中,粗略估计的话,如果不计算索引和其他的负载,和磁盘比大概是2.5/3的关系,如果要得到精确值,可以通过将记录导入Ignite来得出对象大小的平均值,然后乘以期望的对象数量。
11.3.性能提示
11.3.1.摘要
Ignite内存数据网格的性能和吞吐量很大程度上依赖于使用的功能以及配置,在几乎所有的场景中都可以通过简单地调整缓存的配置来优化缓存的性能。
11.3.2.禁用内部事件通知
Ignite有丰富的事件系统来向用户通知各种各样的事件,包括缓存的修改,退出,压缩,拓扑的变化以及很多其他的。因为每秒钟可能产生上千的事件,他会对系统产生额外的负载,这会导致显著地性能下降。因此,强烈建议只有应用逻辑必要时才启用这些事件。默认的话,事件通知是禁用的:
XML:
<bean class="org.apache.ignite.configuration.IgniteConfiguration">...<!-- Enable only some events and leave other ones disabled. --><property name="includeEventTypes"><list><util:constant static-field="org.apache.ignite.events.EventType.EVT_TASK_STARTED"/><util:constant static-field="org.apache.ignite.events.EventType.EVT_TASK_FINISHED"/><util:constant static-field="org.apache.ignite.events.EventType.EVT_TASK_FAILED"/></list></property>...</bean>
11.3.3.关闭备份
如果使用了分区缓存,而且数据丢失并不是关键(比如,当有一个备份缓存存储时),可以考虑禁用分区缓存的备份。当备份启用时,缓存引擎会为每个条目维护一个远程拷贝,这需要网络交换和而且是耗时的。要禁用备份,可以使用如下的配置:
XML:
<bean class="org.apache.ignite.configuration.IgniteConfiguration">...<property name="cacheConfiguration"><bean class="org.apache.ignite.configuration.CacheConfiguration">...<!-- Set cache mode. --><property name="cacheMode" value="PARTITIONED"/><!-- Set number of backups to 0--><property name="backups" value="0"/>...</bean></property></bean>
可能的数据丢失
如果没有启用分区缓存的备份,会丢失缓存在故障节点的所有数据,这对于缓存临时数据或者数据可以通过某种方式重建可能是可以接受的。禁用备份之前一定要确保对于应用来说丢失数据不是关键的。
11.3.4.固化内存调优
固化内存调优以及原生持久化,请参考相关的10.3.内存配置以及下面的11.4.固化内存调优章节。
11.3.5.调整缓存数据再平衡
当有一个新节点加入网络时,已有的节点会放弃一些键的或主或备的所有权给新的节点以使整个集群中的数据一直保持均衡,这可能需要额外的资源以及影响缓存的性能。要处理这个可能的问题,可以考虑调整如下的参数:
- 配置适应网络状况的再平衡批量大小。默认是512KB,这意味着默认的平衡消息是512KB。然而,您可能需要将此值设置为基于网络性能的更高或更低的值;
- 配置再平衡暂停减低CPU负载。如果数据集非常大,这会导致很多的消息需要发送,CPU或者网络都会过度消耗,这会连续地降低应用的性能。这时应该启用数据再平衡暂停来帮助调整再平衡消息之间的等待时间量以确保再平衡过程没有任何的负面性能影响。注意再平衡的过程中应用会持续地正确工作;
- 配置再平衡线程池大小。与之前的观点相反,有时希望利用更多的CPU核心来加快再平衡的速度,这个可以通过增加再平衡线程池内的线程数量来实现(默认池内只有两个线程)。
下面是一个在缓存配置中设置上述所有参数的例子:
XML:
<bean class="org.apache.ignite.configuration.IgniteConfiguration">...<property name="cacheConfiguration"><bean class="org.apache.ignite.configuration.CacheConfiguration"><!-- Set rebalance batch size to 1 MB. --><property name="rebalanceBatchSize" value="#{1024 * 1024}"/><!-- Explicitly disable rebalance throttling. --><property name="rebalanceThrottle" value="0"/><!-- Set 4 threads for rebalancing. --><property name="rebalanceThreadPoolSize" value="4"/>...</bean</property></bean>
11.3.6.配置线程池
Ignite使用了一组线程池,它们的大小默认由max(8, CPU总核数)确定,这个默认值适用于大多数场景,从而减少了上下文切换以及更高效地利用CPU缓存。但是,如果因为I/O阻塞或者其他的原因,只要希望也可以增加特定线程池的大小,下面是一个如何配置线程池的例子:
XML:
<bean class="org.apache.ignite.configuration.IgniteConfiguration">...<!-- Configure internal thread pool. --><property name="publicThreadPoolSize" value="64"/><!-- Configure system thread pool. --><property name="systemThreadPoolSize" value="32"/>...</bean>
11.3.7.使用并置的计算
Ignite可以在内存内执行MapReduce计算。然而,通常很多计算都会使用缓存在远程节点上的一些数据,大多数情况下从远程节点加载那些数据是很昂贵的而将计算发送到数据所在的节点就要便宜得多。最简单的实现方式就是使用IgniteCompute.affinityRun()方法或者@CacheAffinityMapped注解,也有其他的方式, 包括Affinity.mapKeysToNodes()方法。关于并置计算主题在3.11.关系并置章节有详细的描述,还有相关的代码样例。
11.3.8.使用数据流处理器
如果需要往缓存中加载大量的数据,可以使用IgniteDataStreamer来实现,数据流处理器在将数据发送到远程节点之前会将数据正确地形成批次然后会正确地控制发生在每个节点的并发操作的数量来避免颠簸。通常他会比一堆单线程的操作有十倍的性能提升。可以在3.13.数据加载章节看到更详细的描述和样例。
11.3.9.批量处理消息
如果能发送10个比较大的作业代替100个小些的作业,那么应该选择发送大些的作业,这会降低网络上传输作业的数量以及显著地提升性能。类似的,对于缓存的条目应该想办法使用API方法,他会使用键和值的集合,而不是一个一个地传递。
11.3.10.调整垃圾收集
请参考11.5.调整垃圾收集章节的内容。
11.3.11.不要在读时进行值复制
JCache标准要求缓存供应商支持基于值存储的语义,这意味着当从缓存中读取一个值时,无法得到真实存储的对象的引用,而是这个对象的一个副本。Ignite默认遵守这个方式,但是可以通过CacheConfiguration.copyOnRead这个配置属性覆盖这个行为。
<bean class="org.apache.ignite.configuration.CacheConfiguration"><!--Force cache to return the instance that is stored in cacheinstead of creating a copy.--><property name="copyOnRead" value="false"/></bean>
如果使用jul-to-slf4j桥,确保日志的正确配置
Ignite使用java.util.logging.Logger (JUL),如果使用了jul-to-slf4j桥,那么需要特别注意为Ignite配置的JUL日志级别,如果因为某种原因将org.apache配置为DDEBUG级别,最终的日志级别可能是INFO,这意味着Ignite会花费十倍的负载来生成日志消息,它们在之后跨桥时会被丢弃,JUL的默认日志级别为INFO。在org.apache.ignite.logger.java.JavaLogger#isDebugEnabled中打上断点,当JUL系统的日志级别配置为DEBUG时,就会暴露这一点。
11.4.固化内存调优
本章节中包括了固化内存和原生持久化的性能建议和调优参数,在10.3.内存配置中已经包括了一般的配置参数。
11.4.1.一般调优
为了正确地进行固化内存的调优,本章节中包含了一般性的建议,而不管将Ignite用于纯内存模式还是开启了持久化。
调整交换参数
当内存的使用达到阈值时,操作系统就会开始进行从内存到磁盘的页面交换,交换会显著影响Ignite节点进程的性能,这个问题可以通过调整操作系统参数来避免。如果使用的是UNIX,最佳选项是或者降低vm.swappiness的值到10,或者如果开启了原生持久化,也可以将其配置为0。
sysctl –w vm.swappiness=0
共享内存
操作系统和其他的应用为了满足功能需要也需要一块内存,再加上Ignite节点本身也需要一部分Java堆空间用于应用的查询和任务的处理,因此,如果Ignite运行于纯内存模式(无持久化),那么就不能将内存的90%都分配给固化内存。
如果开启了Ignite的原生持久化,那么操作系统为了页面缓存还需要额外的内存空间来优化到磁盘的数据同步。在这个场景中,Ignite节点的整个内存占用(固化内存+Java堆)就不能超过内存总量的70%。
比如,下面的配置显示了如何为满足固化内存的需求分配4GB的内存空间:
XML:
<bean class="org.apache.ignite.configuration.IgniteConfiguration"><property name="memoryConfiguration"><bean class="org.apache.ignite.configuration.MemoryConfiguration"><!-- Set the size of default memory region to 4GB. --><property name="defaultMemoryPolicySize" value="#{4L * 1024 * 1024 * 1024}"/></bean></property><!-- The rest of the parameters --></bean>
Java:
IgniteConfiguration cfg = new IgniteConfiguration();// Changing total RAM size to be used by Ignite Node.MemoryConfiguration memCfg = new MemoryConfiguration();// Setting the size of the default memory region to 4GB to achieve this.memCfg.setDefaultMemoryPolicySize(4L * 1024 * 1024 * 1024);cfg.setMemoryConfiguration(memCfg);// Starting the node.Ignition.start(cfg);
11.4.2.与原生持久化有关的调优
本章节包含了开启Ignite原生持久化之后的建议。
页面大小
Ignite的页面大小(MemoryConfiguration.pageSize)不要小于存储设备(SSD、闪存等)的页面大小以及操作系统缓存页面的大小。
操作系统的缓存页面大小很容易就可以通过系统工具和参数获取到。
存储设备比如SSD的页面大小可以在设备的说明上找到,如果厂商未提供这些信息,可以运行SSD的基准测试来算出这个数值,如果还是难以拿到这个数值,可以使用4KB作为Ignite的页面大小。很多厂商为了适应4KB的随机写工作负载不得不调整驱动,因为很多标准基准测试都是默认使用4KB,来自英特尔的白皮书也确认4KB足够了。
选定最优值之后,可以将其用于集群的配置:
XML:
<bean class="org.apache.ignite.configuration.IgniteConfiguration">...<property name="memoryConfiguration"><bean class="org.apache.ignite.configuration.MemoryConfiguration"><!-- Setting the page size to 4 KB --><property name="pageSize" value="#{4 * 1024}"/></bean></property>...</bean>
Java:
IgniteConfiguration cfg = new IgniteConfiguration();// Changing total RAM size to be used by Ignite Node.MemoryConfiguration memCfg = new MemoryConfiguration();// Setting the page size to 4 KB.memCfg.setPageSize(4096);cfg.setMemoryConfiguration(memCfg);// Starting the node.Ignition.start(cfg);
为WAL使用单独的磁盘设备
考虑为Ignite原生持久化的分区和索引文件以及WAL使用单独的磁盘设备。Ignite会主动地写入分区/索引文件以及WAL,因此,如果为每个使用单独的物理磁盘,可以将写入吞吐量增加一倍,下面的示例会显示如何实践:
XML:
<bean class="org.apache.ignite.configuration.IgniteConfiguration">...<!-- Enabling Ignite Native Persistence. --><property name="persistentStoreConfiguration"><bean class="org.apache.ignite.configuration.PersistentStoreConfiguration"><!--Sets a path to the root directory where data and indexes areto be persisted. It's assumed the directory is on a separated SSD.--><property name="persistentStorePath" value="/etc/ignite/persistence"/><!--Sets a path to the directory where WAL is stored.It's assumed the directory is on a separated HDD.--><property name="walStorePath" value="/wal"/><!--Sets a path to the directory where WAL archive is stored.The directory is on the same HDD as the WAL.--><property name="walArchivePath" value="/wal/archive"/></bean></property>...</bean>
Java:
IgniteConfiguration cfg = new IgniteConfiguration();// Configuring Ignite Native Persistence.PersistentStoreConfiguration storeCfg = new PersistentStoreConfiguration();// Sets a path to the root directory where data and indexes are to be persisted.// It's assumed the directory is on a separated SSD.storeCfg.setPersistentStorePath("/etc/ignite/persistence");// Sets a path to the directory where WAL is stored.// It's assumed the directory is on a separated HDD.storeCfg.setWalStorePath("/wal");// Sets a path to the directory where WAL archive is stored.// The directory is on the same HDD as the WAL.storeCfg.setWalArchivePath("/wal/archive");// Applying the persistence configuration.cfg.setPersistentStoreConfiguration(storeCfg);// Starting the node.Ignition.start(cfg);
页面写入优化
Ignite会定期地启动检查点进程,以在内存和磁盘间同步脏页面。这个进程在后台进行,对应用没有影响。
但是,如果由检查点进程调度的一个脏页面,在写入磁盘前被更新,它之前的状态会被复制进一个特定的区域,叫做检查点缓冲区。如果这个缓冲区溢出,那么Ignite会停止所有的更新,直到检查点处理结束。因此,写入性能可能降为0,如下图所示:
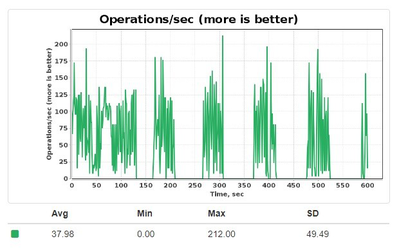
当检查点处理正在进行中时,如果脏页面数达到阈值,同样的情况也会发生,这会使Ignite强制安排一个新的检查点执行,并停止所有的更新操作直到第一个检查点执行完成。
当磁盘较慢或者更新过于频繁时,这两种情况都会发生,要减少或者防止这样的性能下降,可以考虑启用页面写入优化算法。这个算法会在检查点缓冲区填充过快或者脏页面占比过高时,将更新操作的性能降低到磁盘的速度。
下面的示例显示了如何开启页面写入优化:
XML:
<bean class="org.apache.ignite.configuration.IgniteConfiguration">...<!-- Enabling Ignite Native Persistence. --><property name="dataStorageConfiguration"><bean class="org.apache.ignite.configuration.DataStorageConfiguration"><!-- Enable write throttling. --><property name="writeThrottlingEnabled" value="true"/></bean></property>...</bean>
Java:
IgniteConfiguration cfg = new IgniteConfiguration();// Configuring Ignite Native Persistence.DataStorageConfiguration storeCfg = new DataStorageConfiguration();// Enabling the writes throttling.storeCfg.setWriteThrottlingEnabled(true);// Starting the node.Ignition.start(cfg);
检查点缓冲区大小
前述章节中描述的检查点缓冲区大小,是检查点处理的触发器之一。
缓冲区大小预定义为256MB,它并没有为写密集型应用进行优化,因为在大小接近标称值时,页面写入优化算法会降低写入的性能,因此在正在进行检查点处理时,可以考虑增加DataRegionConfiguration.checkpointPageBufferSize,并且开启写入优化来阻止性能的下
降:
XML:
<bean class="org.apache.ignite.configuration.IgniteConfiguration">...<!-- Enabling Ignite Native Persistence. --><property name="dataStorageConfiguration"><bean class="org.apache.ignite.configuration.DataStorageConfiguration"><!-- Enable write throttling. --><property name="writeThrottlingEnabled" value="true"/><property name="defaultDataRegionConfiguration"><bean class="org.apache.ignite.configuration.DataRegionConfiguration"><!-- Enabling persistence. --><property name="persistenceEnabled" value="true"/><!-- Increasing the buffer size to 1 GB. --><property name="checkpointPageBufferSize"value="#{1024L * 1024 * 1024}"/></bean></property></bean></property>...</bean>
Java:
IgniteConfiguration cfg = new IgniteConfiguration();// Configuring Ignite Native Persistence.DataStorageConfiguration storeCfg = new DataStorageConfiguration();// Enabling the writes throttling.storeCfg.setWriteThrottlingEnabled(true);// Increasing the buffer size to 1 GB.storeCfg.getDefaultDataRegionConfiguration().setCheckpointPageBufferSize(1024L * 1024 * 1024);// Starting the node.Ignition.start(cfg);
在上例中,默认内存区的检查点缓冲区大小配置为1GB。
检查点处理何时触发?
当脏页面数超过总页数*2/3或者达到DataRegionConfiguration.checkpointPageBufferSize时,检查点处理就会被触发。但是如果使用了页面写入优化,DataRegionConfiguration.checkpointPageBufferSize就会失效,因为算法的原因,不会达到这个值。
购买产品级的SSD
限于SSD的操作特性,在经历几个小时的高强度写入负载之后,Ignite原生持久化的性能可能会下降,因此需要考虑购买快速的产品级SSD来保证长时间高水平的性能。
SSD预留空间
由于SSD预留空间的原因,50%使用率的磁盘的随机写性能要好于90%使用率的磁盘,因此需要考虑购买高预留空间比率的SSD,然后还要确保厂商能提供工具来进行相关的调整。
11.5.GC调优
11.5.1.GC调优
下面是对应用的一套JVM配置,它会产生大量的临时对象,因此会因为垃圾收集活动而触发长时间的暂停。
集群中的JVM需要不断地进行监控和调优,GC的调优非常依赖于应用以及Ignite的使用模式。
对于JDK1.8来说,建议使用G1垃圾收集器,在下面的示例中,一台开启了G1的64核CPU的机器,配置10G的堆空间:
-server-Xms10g-Xmx10g-XX:+AlwaysPreTouch-XX:+UseG1GC-XX:+ScavengeBeforeFullGC-XX:+DisableExplicitGC
如果要使用G1垃圾收集器,因为经过了不断地改进,建议使用最新版本的Oracle JDK8或者OpenJDK8。
如果G1无法满足应用场景或者使用的是JDK7,那么可以参照下面的基于CMS的配置,对于开始JVM调优是比较合适的(64核CPU的机器的10GB堆举例):
-server-Xms10g-Xmx10g-XX:+AlwaysPreTouch-XX:+UseParNewGC-XX:+UseConcMarkSweepGC-XX:+CMSClassUnloadingEnabled-XX:+CMSPermGenSweepingEnabled-XX:+ScavengeBeforeFullGC-XX:+CMSScavengeBeforeRemark-XX:+DisableExplicitGC
请注意,这些设置可能不总是理想的,所以一定确保在生产部署之前严格测试。
11.5.2.Linux对GC的侵袭
在Linux环境下,因为I/O或者内存饥饿或者其他特定内核的设定的原因,可能发生一个应用面临长时间的GC暂停的情况。本章节会给出一些指导,关于如何修改内核设定来避免因为Linux内核导致的长时间GC暂停。
下面给出的所有的Shell脚本命令都在RedHat7上做了测试,这些可能和实际的Linux发行版不同。
在应用任何基于内核的设定之前,还要确保检查系统统计数据、日志,使其对于实际场景的一个问题确实有效。
最后,在生产环境中针对Linux内核级做出改变,与IT部门商议也是明智的。
I/O问题
如果GC日志显示:“low user time, low system time, long GC pause”,那么一个原因就是GC线程因为内核等待I/O而卡住了,发生的原因基本是日志提交或者因为日志滚动的gzip导致改变的文件系统刷新。
作为一个解决方案,可以增加页面刷新到磁盘的频率,从默认的30秒到5秒。
sysctl –w vm.dirty_writeback_centisecs=500sysctl –w vm.dirty_expire_centisecs=500
内存问题
如果GC日志显示“low user time, high system time, long GC pause”,那么最可能的是内存的压力触发了空闲内存的交换和扫描。
- 检查并且降低‘swappiness’的设定来保护堆和匿名内存
sysctl –w vm.swappiness=10
- 启动时给JVM增加–XX:+AlwaysPreTouch参数
- 关闭NUMA zone-reclaim优化
sysctl –w vm.zone_reclaim_mode=0
- 如果使用RedHat发行版,关闭transparent_hugepage
echo never > /sys/kernel/mm/redhat_transparent_hugepage/enabledecho never > /sys/kernel/mm/redhat_transparent_hugepage/defrag
页面缓存
当应用与底层文件系统有大量的交互时,会导致内存大量使用页面缓存的情况,如果kswapd进程无法跟上页面缓存使用的页面回收,在后台应用就会面临当需要新页面时的直接回收导致的高延迟,这种情况不仅影响应用的性能,也可能导致长时间的GC暂停。
要避免内存页面直接回收导致的长时间GC暂停,在Linux的最新内核版本中,可以通过/proc/sys/vm/extra_free_kbytes设置在wmark_min和wmark_low之间增加额外的字节来避免前述的延迟。
sysctl -w vm.extra_free_kbytes=1240000
要获得有关本章节讨论的话题的更多信息,可以参考这个幻灯片。
11.5.3.调试内存使用问题和GC暂停
当需要调试和解决与内存使用或者长时间GC暂停有关的问题时,本章节包括了一些可能有助于解决这些问题的信息。
内存溢出时获得堆现场
当JVM抛出OutOfMemoryException并且JVM进程应该重启时,需要给JVM配置增加如下的属性:
-XX:+HeapDumpOnOutOfMemoryError-XX:HeapDumpPath=/path/to/heapdump-XX:OnOutOfMemoryError=“kill -9 %p” JROCKIT-XXexitOnOutOfMemory
详细的垃圾收集统计
为了捕获有关垃圾收集的详细信息以及它的性能,可以给JVM配置增加如下的参数:
-XX:+PrintGCDetails-XX:+PrintGCTimeStamps-XX:+PrintGCDateStamps-XX:+UseGCLogFileRotation-XX:NumberOfGCLogFiles=10-XX:GCLogFileSize=100M-Xloggc:/path/to/gc/logs/log.txt
对于G1,建议设置如下的属性,他提供了很多符合人体工程学的、明确地保持-XX:+PrintGCDetails的详细信息:
-XX:+PrintAdaptiveSizePolicy
确保修改相应的路径和文件名,并且确保对于每个调用使用一个不同的文件名来避免从多个进程覆盖日志文件。
FlightRecorder设置
当需要调试性能或者内存问题,可以依靠Java的Flight Recorder工具,他可以持续地收集底层的详细的运行时信息,来启用事后的事故分析,要开启Flight Recorder,可以使用如下的设定:
-XX:+UnlockCommercialFeatures-XX:+FlightRecorder-XX:+UnlockDiagnosticVMOptions-XX:+DebugNonSafepoints
要开始记录衣蛾特定的Java进程,可以使用下面的命令作为一个示例:
jcmd <PID> JFR.start name=<recordcing_name> duration=60s filename=/var/recording/recording.jfr settings=profile
关于Java的Flight Recorder的完整信息,可以查看Oracle的官方文档。
11.5.4.文件描述符
系统级文件描述符限制
对于大规模的服务端应用,当运行大量的线程访问网格时,可能最终在客户端和服务端节点上打开大量的文件,因此建议增加默认值到默认的最大值。
错误的文件描述符设置会影响应用的稳定性和性能,为此,需要设置系统级文件描述符限制和进程级文件描述符限制,以root用户分别按照如下步骤操作:
- 修改/etc/sysctl.conf文件的如下行:
fs.file-max = 300000
- 执行如下命令使改变生效:
cat /proc/sys/fs/file-max
验证这个设置可以用:
sysctl fs.file-max
进程级文件描述符限制
默认情况下,Linux操作系统有一个相对较少的文件描述符和最大用户进程(1024)设置。重要的是,使用一个用户账户,它有他自己的最大打开文件描述符(打开文件数)和最大的用户进程配置为一个合适的值。
对于打开文件描述符,一个合理的最大值是32768。
使用如下命令来设置打开文件描述符的最大值和用户进程的最大值。
ulimit -n 32768 -u 32768
或者,也可以相应地修改如下文件:
/etc/security/limits.conf- soft nofile 32768- hard nofile 32768/etc/security/limits.d/90-nproc.conf- soft nproc 32768
可以参照增加打开文件数限制了解更多细节。
