@liyuj
2018-10-14T15:05:38.000000Z
字数 9863
阅读 2672
Ignite&Spark集成技术方案
在前面的文章中,分别介绍了Ignite和Spark这两种技术,从功能上对两者进行了全面深入的对比,经过分析,还是可以得出这样一个结论:两者差别很大,定位不同,因此会有不同的适用领域。
但是,这两种技术也是可以互补的,鉴于Ignite原生提供了对Spark的支持,因此本文主要探讨如何将Ignite和Spark进行集成。
1.将Ignite与Spark整合
整合这两种技术会为Spark应用带来若干明显的好处:
- 通过避免大量的数据移动,获得真正可扩展的内存级性能;
- 提高RDD、DataFrame和SQL的性能;
- 在Spark作业之间更方便地共享状态和数据。
下图中显示了如何整合这两种技术,并且标注了显著的优势:
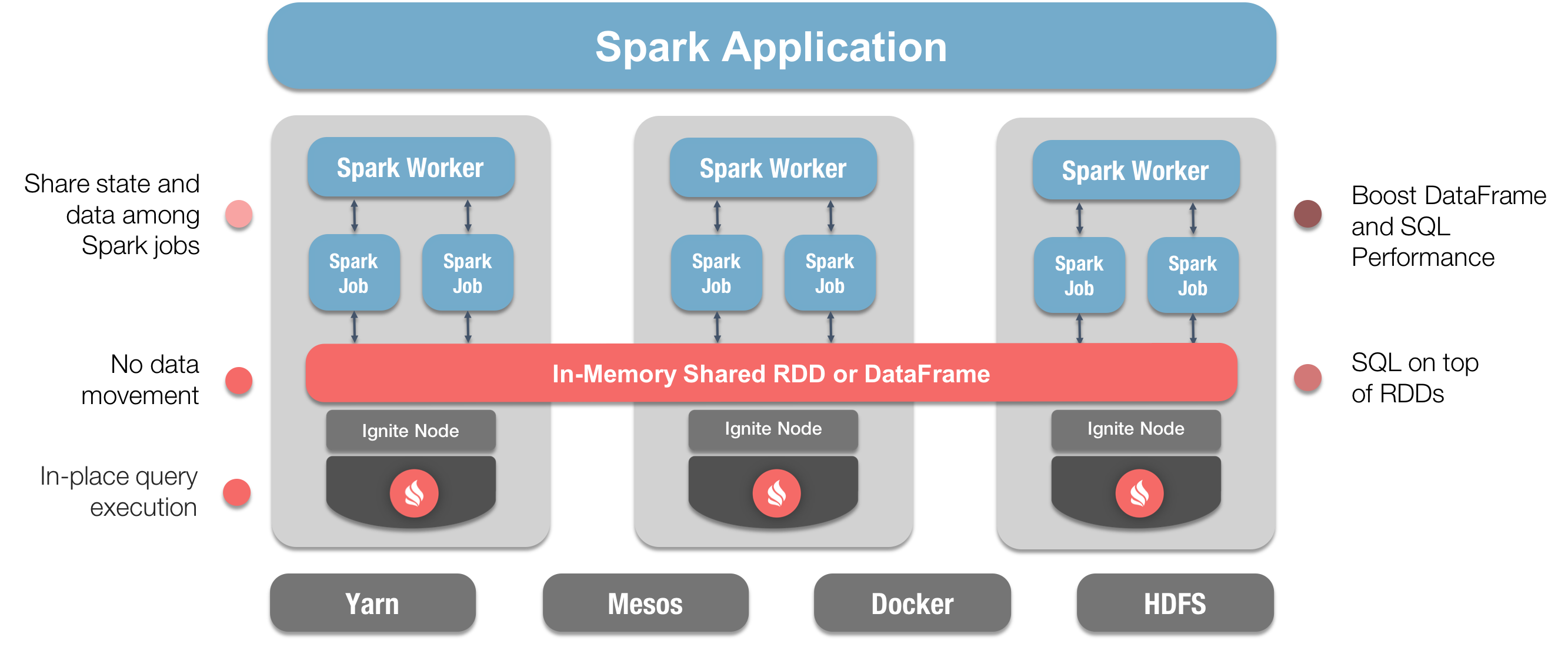
通过该图,可以从整体架构的角度,看到Ignite在整个Spark应用中的位置和作用。
Ignite对Spark的支持主要体现为两个方面,一个是Ignite RDD,一个是Ignite DataFrame。本文会首先聚焦于Ignite RDD,之后聚焦于Ignite DataFrame。
2.Ignite RDD
Ignite提供了一个SparkRDD的实现,叫做IgniteRDD,这个实现可以在内存中跨Spark作业共享任何数据和状态,IgniteRDD为Ignite中相同的内存数据提供了一个共享的、可变的视图,它可以跨多个不同的Spark作业、工作节点或者应用,相反,原生的SparkRDD无法在Spark作业或者应用之间进行共享。
IgniteRDD作为Ignite分布式缓存的视图,既可以在Spark作业执行进程中部署,也可以在Spark工作节点中部署,也可以在它自己的集群中部署。因此,根据预配置的部署模型,状态共享既可以只存在于一个Spark应用的生命周期的内部(嵌入式模式),或者也可以存在于Spark应用的外部(独立模式)。
Ignite还可以帮助Spark应用提高SQL的性能,虽然SparkSQL支持丰富的SQL语法,但是它没有实现索引。从结果上来说,即使在普通的较小的数据集上,Spark查询也可能花费几分钟的时间,因为需要进行全表扫描。如果使用Ignite,Spark用户可以配置主索引和二级索引,这样可以带来上千倍的性能提升。
2.1.IgniteRDD示例
下面通过一些代码以及创建若干应用的方式,演示如何使用IgniteRDD以及看到它的好处。
代码共包括两个简单的Scala应用和两个Java应用。这是为了说明可以使用多种语言来访问Ignite RDD,这在使用不同编程语言和框架的团队中可能存在这样的场景。此外,会从两个不同的环境运行应用:从终端运行Scala应用以及通过IDE运行Java应用。另外还会在Java应用中运行一些SQL查询。
对于Scala应用,一个应用会用于往IgniteRDD中写入数据,而另一个应用会执行部分过滤然后返回结果集。使用Maven将代码构建为一个jar文件后在终端窗口中执行这个程序,下面是详细的代码:
object RDDWriter extends App {val conf = new SparkConf().setAppName("RDDWriter")val sc = new SparkContext(conf)val ic = new IgniteContext(sc, "/path_to_ignite_home/examples/config/spark/example-shared-rdd.xml")val sharedRDD: IgniteRDD[Int, Int] = ic.fromCache("sharedRDD")sharedRDD.savePairs(sc.parallelize(1 to 1000, 10).map(i => (i, i)))ic.close(true)sc.stop()}object RDDReader extends App {val conf = new SparkConf().setAppName("RDDReader")val sc = new SparkContext(conf)val ic = new IgniteContext(sc, "/path_to_ignite_home/examples/config/spark/example-shared-rdd.xml")val sharedRDD: IgniteRDD[Int, Int] = ic.fromCache("sharedRDD")val greaterThanFiveHundred = sharedRDD.filter(_._2 > 500)println("The count is " + greaterThanFiveHundred.count())ic.close(true)sc.stop()}
在这个Scala的RDDWriter中,首先创建了包含应用名的SparkConf,之后基于这个配置创建了SparkContext,最后,根据这个SparkContext创建一个IgniteContext。创建IgniteContext有很多种方法,本例中会使用一个叫做example-shared-rdd.xml的XML文件,该文件会结合Ignite发行版然后根据需求进行了预配置。显然,需要根据自己的环境修改路径(Ignite主目录),之后指定IgniteRDD持有的整数值元组,最后,将从1到1000的整数值存入IgniteRDD,数值的存储使用了10个parallel操作。
在这个Scala的RDDReader中,初始化和配置与Scala RDDWriter相同,也会使用同一个xml配置文件,应用会执行部分过滤,然后关注存储了多少大于500的值,答案最后会输出出来。
关于IgniteContext和IgniteRDD的更多信息,可以看Ignite的文档。
要构建jar文件,可以使用下面的maven命令:
mvn clean install
接下来,看下Java代码,先写一个Java应用往IgniteRDD中写入多个记录,然后另一个应用会执行部分过滤然后返回结果集,下面是RDDWriter的代码细节:
public class RDDWriter {public static void main(String args[]) {SparkConf sparkConf = new SparkConf().setAppName("RDDWriter").setMaster("local").set("spark.executor.instances", "2");JavaSparkContext sparkContext = new JavaSparkContext(sparkConf);Logger.getRootLogger().setLevel(Level.OFF);Logger.getLogger("org.apache.ignite").setLevel(Level.OFF);JavaIgniteContext<Integer, Integer> igniteContext = new JavaIgniteContext<Integer, Integer>(sparkContext, "/path_to_ignite_home/examples/config/spark/example-shared-rdd.xml", true);JavaIgniteRDD<Integer, Integer> sharedRDD = igniteContext.<Integer, Integer>fromCache("sharedRDD");List<Integer> data = new ArrayList<>(20);for (int i = 1001; i <= 1020; i++) {data.add(i);}JavaRDD<Integer> javaRDD = sparkContext.<Integer>parallelize(data);sharedRDD.savePairs(javaRDD.<Integer, Integer>mapToPair(new PairFunction<Integer, Integer, Integer>() {public Tuple2<Integer, Integer> call(Integer val) throws Exception {return new Tuple2<Integer, Integer>(val, val);}}));igniteContext.close(true);sparkContext.close();}}
在这个Java的RDDWriter中,首先创建了包含应用名和执行器数量的SparkConf,之后基于这个配置创建了SparkContext,最后,根据这个SparkContext创建一个IgniteContext。创建IgniteContext有很多种方法,本例中会使用一个叫做example-shared-rdd.xml的XML文件,该文件会结合Ignite发行版然后根据需求进行了预配置。显然,需要根据自己的环境修改路径(Ignite主目录),最后,往IgniteRDD中添加了额外的20个值。
在这个Java的RDDReader中,初始化和配置与Java RDDWriter相同,也会使用同一个xml配置文件,应用会执行部分过滤,然后关注存储了多少大于500的值,答案最后会输出出来,下面是Java RDDReader的代码:
public class RDDReader {public static void main(String args[]) {SparkConf sparkConf = new SparkConf().setAppName("RDDReader").setMaster("local").set("spark.executor.instances", "2");JavaSparkContext sparkContext = new JavaSparkContext(sparkConf);Logger.getRootLogger().setLevel(Level.OFF);Logger.getLogger("org.apache.ignite").setLevel(Level.OFF);JavaIgniteContext<Integer, Integer> igniteContext = new JavaIgniteContext<Integer, Integer>(sparkContext, "/path_to_ignite_home/examples/config/spark/example-shared-rdd.xml", true);JavaIgniteRDD<Integer, Integer> sharedRDD = igniteContext.<Integer, Integer>fromCache("sharedRDD");JavaPairRDD<Integer, Integer> greaterThanFiveHundred =sharedRDD.filter(new Function<Tuple2<Integer, Integer>, Boolean>() {public Boolean call(Tuple2<Integer, Integer> tuple) throws Exception {return tuple._2() > 500;}});System.out.println("The count is " + greaterThanFiveHundred.count());System.out.println(">>> Executing SQL query over Ignite Shared RDD...");Dataset df = sharedRDD.sql("select _val from Integer where _val > 10 and _val < 100 limit 10");df.show();igniteContext.close(true);sparkContext.close();}}
到这里就可以对代码进行测试了。
2.2.运行应用
在第一个终端窗口中,启动Spark的主节点,如下:
$SPARK_HOME/sbin/start-master.sh
在第二个终端窗口中,启动Spark工作节点,如下:
$SPARK_HOME/bin/spark-class org.apache.spark.deploy.worker.Worker spark://ip:port
根据自己的环境,修改IP地址和端口号(ip:port)。
在第三个终端窗口中,启动一个Ignite节点,如下:
$IGNITE_HOME/bin/ignite.sh examples/config/spark/example-shared-rdd.xml
这里使用了之前讨论过的example-shared-rdd.xml文件。
在第四个终端窗口中,可以运行Scala版的RDDWriter应用,如下:
$SPARK_HOME/bin/spark-submit --class "com.gridgain.RDDWriter" --master spark://ip:port "/path_to_jar_file/ignite-spark-scala-1.0.jar"
根据自己的环境修改IP地址和端口(ip:port),以及jar文件的路径(/path_to_jar_file)。
会产生如下的输出:
The count is 500
这是期望的输出。
接下来,杀掉Spark的主节点和工作节点,而Ignite节点仍然在运行中并且IgniteRDD对于其它应用仍然可用,下面会使用IDE通过Java应用接入IgniteRDD。
运行Java版RDDWriter会扩展之前存储于IgniteRDD中的记录列表,通过运行Java版RDDReader可以进行测试,它会产生如下的输出:
The count is 520
这也是期望的输出。
最后,SQL查询会在IgniteRDD中执行一个SELECT语句,返回范围在10到100之间的最初10个值,输出如下:
+----+|_VAL|+----+| 11|| 12|| 13|| 14|| 15|| 16|| 17|| 18|| 19|| 20|+----+
结果正确。
3.IgniteDataframes
Spark的DataFrame API为描述数据引入了模式的概念,Spark通过表格的形式进行模式的管理和数据的组织。
DataFrame是一个组织为命名列形式的分布式数据集,从概念上讲,DataFrame等同于关系数据库中的表,并允许Spark使用Catalyst查询优化器来生成高效的查询执行计划。而RDD只是跨集群节点分区化的元素集合。
Ignite扩展了DataFrames,简化了开发,改进了将Ignite作为Spark的内存存储时的数据访问时间,好处包括:
- 通过Ignite读写DataFrames时,可以在Spark作业之间共享数据和状态;
- 通过优化Spark的查询执行计划加快SparkSQL查询,这些主要是通过IgniteSQL引擎的高级索引以及避免了Ignite和Spark之间的网络数据移动实现的。
3.1.IgniteDataframes示例
下面通过一些代码以及搭建几个小程序的方式,了解Ignite DataFrames如何使用。
一共会写两个Java的小应用,然后在IDE中运行,还会在这些Java应用中执行一些SQL查询。
一个Java应用会从JSON文件中读取一些数据,然后创建一个存储于Ignite的DataFrame,这个JSON文件Ignite的发行版中已经提供,另一个Java应用会从Ignite的DataFrame中读取数据然后使用SQL进行查询。
下面是写应用的代码:
public class DFWriter {private static final String CONFIG = "config/example-ignite.xml";public static void main(String args[]) {Ignite ignite = Ignition.start(CONFIG);SparkSession spark = SparkSession.builder().appName("DFWriter").master("local").config("spark.executor.instances", "2").getOrCreate();Logger.getRootLogger().setLevel(Level.OFF);Logger.getLogger("org.apache.ignite").setLevel(Level.OFF);Dataset<Row> peopleDF = spark.read().json(resolveIgnitePath("resources/people.json").getAbsolutePath());System.out.println("JSON file contents:");peopleDF.show();System.out.println("Writing DataFrame to Ignite.");peopleDF.write().format(IgniteDataFrameSettings.FORMAT_IGNITE()).option(IgniteDataFrameSettings.OPTION_CONFIG_FILE(), CONFIG).option(IgniteDataFrameSettings.OPTION_TABLE(), "people").option(IgniteDataFrameSettings.OPTION_CREATE_TABLE_PRIMARY_KEY_FIELDS(), "id").option(IgniteDataFrameSettings.OPTION_CREATE_TABLE_PARAMETERS(), "template=replicated").save();System.out.println("Done!");Ignition.stop(false);}}
在DFWriter中,首先创建了SparkSession,它包含了应用名,之后会使用spark.read().json()读取JSON文件并且输出文件内容,下一步是将数据写入Ignite存储。下面是DFReader的代码:
public class DFReader {private static final String CONFIG = "config/example-ignite.xml";public static void main(String args[]) {Ignite ignite = Ignition.start(CONFIG);SparkSession spark = SparkSession.builder().appName("DFReader").master("local").config("spark.executor.instances", "2").getOrCreate();Logger.getRootLogger().setLevel(Level.OFF);Logger.getLogger("org.apache.ignite").setLevel(Level.OFF);System.out.println("Reading data from Ignite table.");Dataset<Row> peopleDF = spark.read().format(IgniteDataFrameSettings.FORMAT_IGNITE()).option(IgniteDataFrameSettings.OPTION_CONFIG_FILE(), CONFIG).option(IgniteDataFrameSettings.OPTION_TABLE(), "people").load();peopleDF.createOrReplaceTempView("people");Dataset<Row> sqlDF = spark.sql("SELECT * FROM people WHERE id > 0 AND id < 6");sqlDF.show();System.out.println("Done!");Ignition.stop(false);}}
在DFReader中,初始化和配置与DFWriter相同,这个应用会执行一些过滤,需求是查找所有的id > 0 以及 < 6的人,然后输出结果。
在IDE中,通过下面的代码可以启动一个Ignite节点:
public class ExampleNodeStartup {public static void main(String[] args) throws IgniteException {Ignition.start("config/example-ignite.xml");}}
到此,就可以对代码进行测试了。
3.2.运行应用
首先在IDE中启动一个Ignite节点,然后运行DFWriter应用,输出如下:
JSON file contents:+-------------------+---+------------------+| department| id| name|+-------------------+---+------------------+|Executive Committee| 1| Ivan Ivanov||Executive Committee| 2| Petr Petrov|| Production| 3| John Doe|| Production| 4| Ann Smith|| Accounting| 5| Sergey Smirnov|| Accounting| 6|Alexandra Sergeeva|| IT| 7| Adam West|| Head Office| 8| Beverley Chase|| Head Office| 9| Igor Rozhkov|| IT| 10|Anastasia Borisova|+-------------------+---+------------------+Writing DataFrame to Ignite.Done!
如果将上面的结果与JSON文件的内容进行对比,会显示两者是一致的,这也是期望的结果。
下一步会运行DFReader,输出如下:
Reading data from Ignite table.+-------------------+--------------+---+| DEPARTMENT| NAME| ID|+-------------------+--------------+---+|Executive Committee| Ivan Ivanov| 1||Executive Committee| Petr Petrov| 2|| Production| John Doe| 3|| Production| Ann Smith| 4|| Accounting|Sergey Smirnov| 5|+-------------------+--------------+---+Done!
这也是期望的输出。
4.总结
通过本文,会发现Ignite与Spark的集成是如何的简单。看到了如何从多个环境中使用多个编程语言轻松地访问IgniteRDD。可以对IgniteRDD进行数据的读写,并且即使Spark已经关闭状态也通过Ignite得以保持。也看到了通过Ignite进行DataFrame的读写,因此可以发现,Ignite为Spark应用带来了很大的灵活性和好处。
那么什么时候需要在Spark应用中引入Ignite呢?或者说适用场景是什么呢?主要是这么几个方面,如果觉得Spark中的SQL等运行速度较慢,那么Ignite通过自己的方式提供了对Spark应用进行进一步加速的解决方案,这方面可选的解决方案并不多,推荐开发者考虑,另外就是数据和状态的共享,当然这方面的解决方案有很多,并不是一定要用Ignite实现。
如果想要这些示例的源代码,可以从这里下载。
