@fanxy
2021-09-15T04:17:44.000000Z
字数 11702
阅读 13966
第一讲 R 语言入门与金融数据获取
樊潇彦 复旦大学经济学院 金融数据
下载文件:
1. 数据和笔记样本 Ch01.rar,解压缩到工作目录下,存在文件夹 Ch01 中;
2. 里面有数据文件 inc.csv 和笔记样本 Note1.rmd。
设置中文显示:
1. Tools --> Global Options --> Code --> Saving,在 Change 菜单中选择 UTF-8 --> Apply
2. 双击打开 Note1.rmd,如果乱码用记事本等软件打开,全选后考回 Note1.rmd,再选 File --> Save with Encoding
1. R语言入门
1.1 准备工作
setwd("D:\\...\\Ch01") # 设定工作目录# 用 getwd() 可查看当前工作目录rm(list=ls()) # 清内存# "Ctrl"+"L" 清除命令窗口install.packages(c("zoo","xts","timeSeries","quantmod","tseries","Ecdat")) # 安装包install.packages(TTP)library(zoo)library(xts)library(timeSeries)library(quantmod)library(tseries)
1.2 数据类型与结构
1.2.1 五种基本数据类型
- 数值型(numeric)
x = c(1, 2, 3, 4) # 构造数值型向量xx # 显示class(x) # 显示数据类型
- 整数型(integer)
x1 = as.integer(x) # 转换为整数型向量x1class(x1)
- 逻辑型(logical)
is.logical(x) # 判断向量x是否为逻辑型数据x==2 # 判断向量x中元素是否等于2x2=!(x<2) # 判断向量x中元素是否大于等于2,存为逻辑型向量x2which(x<2) # 显示向量x中小于2的元素所在的位置
- 字符型(character)
y = c("I", "love", "R") # 构造元素依次为字符串“I”,“love”,“R”的向量yy # 输出y的值class(y) # 显示向量y的数据类型length(y) # 显示向量y的维度,即元素个数nchar(y) # 显示向量y中每个元素的字符个数y=="R" # 判断向量y中为“R”的元素
- 因子型(factor)
sex = factor(c(1,1,0,0,1), levels=c(0,1), labels=c("male","female")) # 因子型数据sex,加变量标签sex # 输出sex的值class(sex) # 显示sex的数据类型num1 = factor(c("b","a","d","c"), ordered= TRUE) # 字符型因子变量不设levels和labels,按字母排序编号as.numeric(num1) # 显示编号
1.2.2 五种基本数据结构
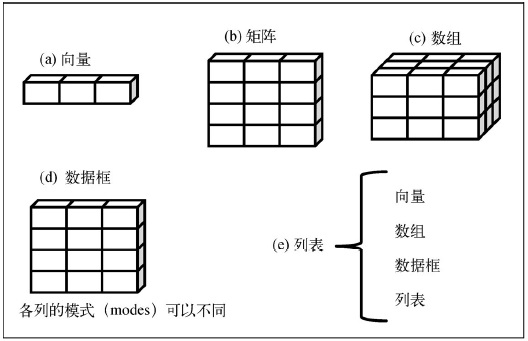
- 向量(vector)
a <- c(1, 2, 5, 3, 6, -2, 4)b <- c("one", "two", "three")c <- c(TRUE, TRUE, TRUE, FALSE, TRUE, FALSE)a[3]a[c(1, 3, 5)]a[2:6]
- 矩阵(matrix)
y <- matrix(1:20, nrow=5, ncol=4)ycells <- c(1,26,24,68)rnames <- c("R1", "R2")cnames <- c("C1", "C2")mymatrix <- matrix(cells, nrow=2, ncol=2, byrow=TRUE,dimnames=list(rnames, cnames))mymatrixmymatrix <- matrix(cells, nrow=2, ncol=2, byrow=FALSE,dimnames=list(rnames, cnames))mymatrixy[2,]y[,2]y[1,4]y[1, c(2,4)]
- 数组(array)
dim1 <- c("A1", "A2")dim2 <- c("B1", "B2", "B3")dim3 <- c("C1", "C2", "C3", "C4")z <- array(1:24, c(2,3,4), dimnames=list(dim1, dim2, dim3))z
- 数据框(data frame)
patientID <- c(1, 2, 3, 4)age <- c(25, 34, 28, 52)diabetes <- c("Type1", "Type2", "Type1", "Type1")status <- c("Poor", "Improved", "Excellent", "Poor")patientdata <- data.frame(patientID, age, diabetes, status)patientdatapatientdata[1:2]patientdata[c("diabetes","status")]patientdata$age# 将diabetes和status由字符型变为因子型和有序因子型diabetes <- factor(diabetes)status <- factor(status, order=TRUE)patientdata <- data.frame(patientID, age, diabetes, status)str(patientdata)summary(patientdata)
- 列表(list)
g <- "My First List"h <- c(25, 26, 18, 39)j <- matrix(1:10, nrow=5)k <- c("one", "two", "three")mylist <- list(title=g, ages=h, j, k)mylist
1.2.3 日期类变量
金融数据中的时间变量有三种常用类型:Date、POSIXct和POSIXt。
Sysdate <- Sys.Date() # 系统当前日期class(Sysdate) # 日期型变量SysdateSystime <- Sys.time() # 系统当前时间class(Systime) # "POSIXct"和"POSIXt"是两种精准到秒的时间变量Systimep <- as.POSIXlt(Systime) # 提取日期中的各个组成部分信息class(p); mode(p)pp$year+1900 # p$year 自1900年以来的年份p$mon+1 # p$mon 表示0-11月p$mday # p$mday 该月的第几天p$yday+1 # p$yday 该年的第几天,0-365天,元旦当天是第0天p$wday # p$wday 对应周几,0-6,周日为0,其他时间和我们日常习惯一致# 用字符和数字生成日期对象t <- as.Date("2014/4/17",tz="CST") # tz为时区,CST为北京时间class(t)tt <- ISOdate(2014,4,17)class(t) # ISOdate()函数得到的是一个POSIXct对象t <- ISOdatetime(2014,4,17,15,28,48) # 继续加入小时、分钟、秒数信息
2. 时间序列程序包
下表列出了一些常用的获取和处理金融数据的程序包,其中TTP是一个技术分析包,感兴趣的同学可以自己查阅,本节将逐一介绍zoo, xts, timeSeries, quantmod, tseries等包的主要命令。
| 功能 | 软件包 |
|---|---|
| 时间序列数据处理 | zoo:以时间为Index |
| xts:zoo包的扩展 | |
| timeSeries:时间为名为Date的指标 | |
| 金融数据处理 | quantmod:数据获取与作图 |
| tseries:数据获取与分析 | |
| TTR:技术分析 |
2.1 用zoo、xts、timeSeries设置时序数据对象
intc=read.table(file="intc.csv",header=TRUE,sep=",") # 读入数据head(intc,3); tail(intc,3)class(intc)library(zoo)intc.z=zoo(x=intc[,"Adj.Close"],order.by=as.Date(intc[,"Date"])) # 转换成zoo类型class(intc.z)head(intc.z);tail(intc.z)class(coredata(intc.z))class(index(intc.z))plot(intc.z,main="Intel Stock Price 1980-03 to 2016-02",ylab="$")library(xts)intc.x <- xts(x=intc[,"Adj.Close"],order.by=as.Date(intc[,"Date"])) # 转换成xts类型colnames(intc.x)="Adj.Close"head(intc.x); tail(intc.x)class(intc.x)library(timeSeries)intc.ts=timeSeries(intc) # 转成timeSeries格式intc.ts=intc.ts[,c("Date","Adj.Close")]head(intc.ts); tail(intc.ts)class(intc.ts)data(Tbrate,package="Ecdat")class(Tbrate) # 时间序列ts,多变量时序mtswindow(Tbrate,start=start(Tbrate),end=c(1950,4))tsp(Tbrate)plot(Tbrate)ts.plot(Tbrate,col=2:4)legend(x="topleft",legend=c("t-bill rate","log GDP","inflation"),lty=1,col=2:4,bty="n")Tbrate.z=zoo(Tbrate,frequency =4) # 将ts转换为zoo
2.2 用quantmod和tseries提取金融数据
quantmod是由Jeffrey Ryan编写的应用最为广泛的金融软件包,主要命令有两个:- getSymbols:从多种来源获取数据,包括 Yahoo、Google、FRED、Oanda,以及本地 .csv 和 .RData 文件和 MySQL、SQLite 数据库等。
- chartSeries:数据绘图
library(quantmod)args(getSymbols) # 查看命令选项getSymbols("^GSPC") # S&P500,默认 scr="yahoo"tail(GSPC,4) # 查看最后4个数据class(GSPC) # 数据类型class(index(GSPC)) # 日期类型dim(GSPC) # 数据行列数colnames(GSPC) # 指标名称tail(Cl(GSPC),4)args(chartSeries)## chartSeries(x, type = c("auto", "candlesticks", "matchsticks",## "bars", "line"), subset = NULL, show.grid = TRUE, name = NULL,## time.scale = NULL, log.scale = FALSE, TA = "addVo()", TAsep = ";",## line.type = "l", bar.type = "ohlc", theme = chartTheme("black"),## layout = NA, major.ticks = "auto", minor.ticks = TRUE, yrange = NULL,## plot = TRUE, up.col, dn.col, color.vol = TRUE, multi.col = FALSE, ...)chartSeries(GSPC,subset="2018::2020",theme="white") # 背景为白色,但上涨为绿色、下跌为红色whiteTheme <- chartTheme("white") # 在此基础上自定义作图模版names(whiteTheme)whiteTheme$bg.col <- "white"whiteTheme$dn.col <- "lightgreen" # 下降为淡绿色whiteTheme$up.col <- "pink" # 上涨为粉色whiteTheme$border <- "lightgray"x <- chartSeries(GSPC,subset="last 3 months",theme=whiteTheme,TA=NULL)class(x)# 选取不同时段作图chartSeries(GSPC["2020"],theme=whiteTheme,name="S&P 500")chartSeries(GSPC["2019/2020"],theme=whiteTheme,name="S&P 500")chartSeries(GSPC["2019-08::2020-03"],theme=whiteTheme,name="S&P 500")chartSeries(GSPC["20161109::"],theme=whiteTheme,name="S&P 500")
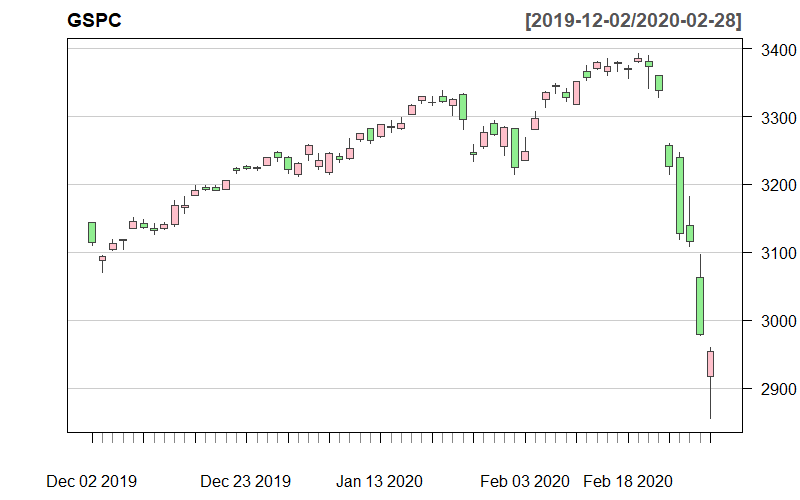
- 计算经拆股、除权调整后的价格。
getSymbols("INTC")head(INTC)chartSeries(INTC,theme=whiteTheme,name="INTC.adj",minor.ticks=FALSE)getSymbols("INTC",index.class="POSIXct",from="2000-01-01") # 提取英特尔数据head(INTC) # 显示前6条chartSeries(INTC,theme=whiteTheme,name="INTC",minor.ticks=FALSE) # 数据作图adj_INTC=adjustOHLC(INTC,adjust = c("split", "dividend"), # 进行拆股、除权的数据调整symbol.name=deparse(substitute(x)))head(adj_INTC) # 显示调整后数据chartSeries(adj_INTC,theme=whiteTheme,name="INTC.adj", # 调整后数据作图minor.ticks=FALSE)
- 提取多支股票数据
symbols = c("INTC", "GOOGL","T") # 三只股票代码的字符向量getSymbols(symbols,from="2010-01-01") # 提取数据prices <- Cl(get(symbols[1]))for(i in 2:length(symbols))prices <- merge(prices,Cl(get(symbols[i]))) # 合并colnames(prices) <- symbolshead(prices)
- 从 FED 获取3个月美国国债收益率
getSymbols('DTB3',src='FRED') # 有时无法连接,可用以下命令直接从网上下载DTB3=read.table("https://research.stlouisfed.org/fred2/series/DTB3/downloaddata/DTB3.csv",sep = ",", header=TRUE, stringsAsFactors =FALSE)str(DTB3) # 查看数据类型DTB3=xts(as.numeric(DTB3$VALUE), order.by =as.Date(DTB3$DATE)) # 变为时间序列xts类型chartSeries(DTB3,theme="white",minor.ticks=FALSE) # 作图
tseries包由 Adrian Trapletti 和 Kurt Hornik 开发,汇集了很多时序数据分析函数和计算金融工具。主要命令有:- get.hist.quote: 从 Yahoo 或 Oanda 下载数据;
- jarque.bera.test:正态分布的 Jarque-Bera 检验;
- adf.test:单位根的 ADF 检验;
- po.test:协整的 Phillips-Ouliaris 检验。
library(tseries)args(get.hist.quote)# function (instrument = "^gdax", start, end, quote = c("Open",# "High", "Low", "Close"), provider = c("yahoo", "oanda"),# method = NULL, origin = "1899-12-30", compression = "d",# retclass = c("zoo", "its", "ts"), quiet = FALSE, drop = FALSE)BA <- get.hist.quote(instrument="BA",start="2009-01-01",quote="A")SPY <- get.hist.quote(instrument="SPY",start="2009-01-01",quote="A")BA.ret <- diff(log(BA))SPY.ret <- diff(log(SPY))class(SPY)class(time(SPY))tail(SPY,3)# Color specification rgb(0,0,100,50,maxColorValue=255) makes dense over-plotted areas darkerplot(x=SPY.ret, y=BA.ret, pch=20, asp=1, xlab="Market Return", ylab="Boeing Return", main="Boeing Return versus Market Return", col=rgb(0,0,100,50,maxColorValue=255))
附录:用Wind中R接口提取数据
1 安装启动WindR
先从 http://www.dajiangzhang.com/document 下载安装个人版"Wind资讯开放应用接口"(免费)或机构版"Wind资讯金融终端"(需要用帐号、密码登录),再按照页面左侧"接口安装说明"操作,安装WindR接口。
library(WindR)w.start() #启动WindR接口
2 提取历史交易报价 w.wsd
- 提取银行间交易债券09付息国债(090007.IB)的净价序列数据,时间从2012-1-1到最新。
#设置起始时间和截止时间,通过wsd接口提取序列数据begintime<-'20120101'; endtime<-Sys.Date()wsd090007.IB<-w.wsd('090007.IB','close',begintime,endtime,'Priceadj=CP;tradingcalendar=NIB')#其中,'Priceadj','CP'表示债券净价,’U’表示不对股票除权,'tradingcalendar','NIB'为银行间市场交易日历。
- 提取000001.SZ的开高低收数据,起始时间前推100天(日期宏),截止时间最新,前复权数据。
#设置起始时间和截止时间,通过wsd接口提取序列数据begintime<-'20120101'; endtime<- Sys.Date()wsd000001.SZ<-w.wsd('000001.SZ','open,high,low,close','-100d',endtime,'Priceadj=F')#其中,-100d是日期宏函数,表示前推100天。
3 提取分钟序列数据 w.wsi
- 提取中金所IF股指期货当月连续合约的3分钟数据,截止时间最新(Sys.time()),起始时间前推100天(Sys.Date()-100);
#设置起始时间和截止时间,通过wsi接口提取序列数据fields='open,high,low,close'begintime= Sys.Date()-100endtime= Sys.time()# Sys.time()是R内置的日期函数,表示当前时刻。wsiIF00.CFE= w.wsi('IF00.CFE',fields,begintime,endtime,'BarSize=3')
4 提取盘口买卖盘数据 w.wst
- 提取平安银行(000001.SZ)当天的买卖盘数据;
#设置起始时间和截止时间,通过wsi接口提取序列数据begintime=format(Sys.time(),'%Y%m%d 09:30:00');endtime =Sys.time()fields='last,bid1,ask1';#last最新价,amt成交额,volume成交量#bid1 买1价,bsize1 买1量#ask1 卖1价, asize1 卖1量wst000001.SZ <- w.wst('000001.SZ',fields,begintime,endtime)
5 提取截面数据 w.wss
- 提取浦发银行(600000.SH)、万科A(000002.SZ)、宝安A(000009.SZ)、南玻A(000012.SZ)、长城开发(000021.SZ)2012年11月30号的基本特征字段,包括公司名称、公司英文名称、IPO日期、流通股、净流入资金、流入量,相应的字段为
comp_name,comp_name_eng,ipo_date,float_a_shares,mf_amt,mf_vol。
codes='600000.SH,000002.SZ,000009.SZ,000012.SZ,000021.SZ'fields='comp_name,comp_name_eng,ipo_date,float_a_shares,mf_amt,mf_vol'wss_inform<- w.wss(codes,fields,'tradedate=20121130')#其中,’tradedate’表示交易日期。
- 提取财务数据,如海正药业(600276.SH)、恒瑞医药(600276.SH)、双鹭药业(002038.SZ)、天士力(600535.SH)2012年年报中的营业收入、营业利润、净利润数据,数据来源为合并报表。
wss_report=w.wss('600267.SH,600276.SH,002038.SZ,600535.SH','oper_rev,opprofit,net_profit_is','rptDate=20121231;rptType=1')# 营业收入、营业利润、净利润对应的字段为oper_rev、opprofit、net_profit_is,报告期为2012年12月31日(rptDate=20121231),财务报表为合并报表(rptType=1)。
6 提取实时行情数据 w.wsq
- 提取世纪星源(000005.SZ)、深振业(000006.SZ)、零七股份(000007.SZ)、宝利来(000008.SZ)股票的当日实时指标数据;
w_data=w.wsq('000005.SZ,000006.SZ,000007.SZ,000008.SZ','rt_time,rt_last,rt_bid1,rt_ask1,rt_vwap')#其中,rt_time,rt_last,rt_bid1,rt_ask1,rt_vwap分别为时间、现价、买入价、卖出价、成交均价字段。
7 提取债券估值数据 w.wsd
- 提取银行间国债09年07附息券(090007.IB)的全价、应计利息、估价修正久期,数据来源为中证指数公司,对应的字段为dirty_csi、accruedinterest_csi、modidura_csi。日期为2013年4月6日至5月6日。
wdata=w.wsd('090007.IB','dirty_csi,accruedinterest_csi,modidura_csi','2013-04-06','2013-05-06')# 注意,目前支持中债公司、中证指数公司、清算所的债券估价,中债公司需要取得授权,清算所的债券估值数据较少。
8 提取数据集 w.wset
目前可以读取板块成分、指数成分股及权重、停牌股票、分红送转等股票数据。目前融资融券数据在个人版中已不能查询。
#取全部 A 股股票代码、名称信息data<-w.wset("SectorConstituent","date=20160227;sector=全部A股")$Datadata=data[,-2]#取沪深 300 指数中股票代码和权重data<-w.wset("IndexConstituent","date=20160101;windcode=000300.SH;field=wind_code,i_weight")#取停牌信息data=w.wset("TradeSuspend","startdate=20160101;enddate=20130608;field=wind_code,sec_name,suspend_type,suspend_reason")#取 ST 股票等风险警示股票信息data<-w.wset("SectorConstituent","date=20160101;sector=风险警示股票;field=wind_code,sec_name")
9 提取资管报表数据 w.wpf
- 某用户终端中资管中选择了名为“130325”的组合,现在将该组合的统计数据读出来,选择的报表为“组合结算数据”,报表字段为:Portfolio_Name(组合名称)、Portfolio_ID(组合ID)、Total_Asset(总资产)
data=w.wpf('130325','PMS.PortfolioDaily','startdate=20130503;enddate=20130603;reportcurrency=CNY;owner=;field=Portfolio_Name,Portfolio_ID,Total_Asset')
10 提取交易日期 w.tdays、w.tdaysoffset、w.tdayscount
- 提取上海期货交易所2013年5月3日至6月3日的交易日期
data=w.tdays('2013-05-03','2013-06-03','TradingCalendar=SHFE;')# 其中,'TradingCalendar=SHFE;'是上海期货交易所代码,默认是上海证券交易所。
- 提取上海股票交易所2013年6月3日前推4个交易日的日期。
data=w.tdaysoffset(-4,'2013-06-03')
- 统计上海证券交易所交易日期
data=w.tdayscount('2013-05-03','2013-06-03')
11 读取股票日K线价格并绘制价格图
- 读取恒瑞医药(600276.SH)历史收盘价,时间是从2013年1月2日至2013年4月2日,并绘制各种股票价格图。
require(quantmod)# 读取一只股票并作图data=w.wsd('600276.SH','open,high,low,close,volume','2013-01-02','2013-04-02')$Datats <- xts(data[,-1],data[,1])chartSeries(ts,TA=c(addVo(),addBBands(),addMACD()),up.col="red",dn.col="#00ffff",name=StockList)# 读取多只股票StockList=c('600276.SH','000001.SZ')for (i in StockList) assign(i, w.wsd(i,'open,high,low,close,volume','2013-01-02','2013-04-02')$Data)
参考资料
- R.I. Kabacoff著:《R语言实战(第2版)》,王小宁、刘撷芯、黄俊文译,人民邮电出版社,2016
- Yollin, G. 2015: R Programming for Quantitative Finance, Lecture Notes,
- 大奖章网站:《WindR数据及交易接口》
