@fanxy
2020-03-29T08:22:02.000000Z
字数 9253
阅读 7292
第四讲 概率统计与资产收益率
樊潇彦 复旦大学经济学院 金融数据
0. 准备工作
下载数据:price.Rdata
setwd("D:\\...\\Ch04") # 设定工作目录,注意为/或\\rm(list=ls()) # 清内存install.packages(c("MASS","Himsc","fBasics","mice","sm","mnormt"))## 调用library(tidyverse)library(ggplot2)library(MASS)library(Himsc)library(fBasics)library(mice)library(sm)library(mnormt)
1. 概率统计基本概念
1.1 概率空间和概率
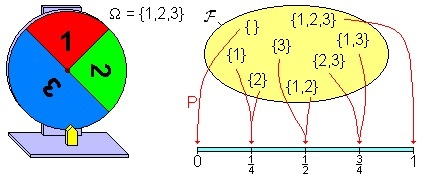
Source:Wiki term "Probability measure".
若函数 满足:
- 非负性 ;
- 规一性 ;
- 可列可加性,即如果 且
则称 为可测空间 上的一个概率测度(probability measure),简称概率。
1.2 随机变量
- 定义:
如果定义在样本空间上的实值函数 对任意 有:
则称 为 上的随机变量。 - 分类:
- 离散型随机变量:如二项分布(伯努利分布,
binom)、泊松分布pois等 - 连续型随机变量:如均匀分布
unif、正态分布(高斯分布,norm)、指数分布exp,以及、、(t、F、chisq)分布等。
- 离散型随机变量:如二项分布(伯努利分布,
- 累积分布函数 :
是概率空间 上的随机变量,若对于 存在:
则称 为累积分布函数(cumulative distribution function,cdf)。 - 概率密度函数 :对连续随机变量 ,如果除有限个点外存在:
称 为概率密度函数(probability density function,pdf)。 - 频率函数或分布律:对于离散随机变量 ,称 为频率函数(frequency function)或分布律。

1.3 样本统计量
是随机变量 的 个独立抽取的样本,常用的样本统计量(sample statistics)定义如下:
- 样本均值(sample mean):
- 样本方差/标准差(sample variance / standard deviation):
- 样本偏度(sample skewness):
- 样本峰度(sample kurtosis):
此外,假定 是随机变量 的 个独立抽取的样本,定义:
- 协方差(covariance):
- 相关系数(correlation coefficient):
注意:
- 如果 是一个正态分布的随机变量,则 和 的分布渐近为均值为零、方差分别为 和 的正态分布。
- 定义 为超额峰度(excess kurtosis)。与正态分布相比, 的分布呈现出 尖峰(leptokurtic)厚尾(fat-tailed) 的特征,也就是存在更多的极端值。
- 统计量是样本的函数,样本不同统计量也不同,因此 统计量本身也是一个随机变量 ;
- 统计量的分布称为 抽样分布(sample distribution),它与随机变量 所服从的 总体分布(population distribution) 是两个不同的概念。比如根据中心极限定理,不论 服从哪种分布,在一定条件下,样本均值 都将渐近服从正态分布 。
1.4 统计推断
- 定义:根据样本判断关于总体分布 的假设是否正确。
- 分类:
- 参数检验:给定总体分布的类型,检验对分布参数的假定是否正确
- 分布检验:检验对总体分布类型的假定是否正确
- 参数检验:给定总体分布的类型,检验对分布参数的假定是否正确
2. R语言实现
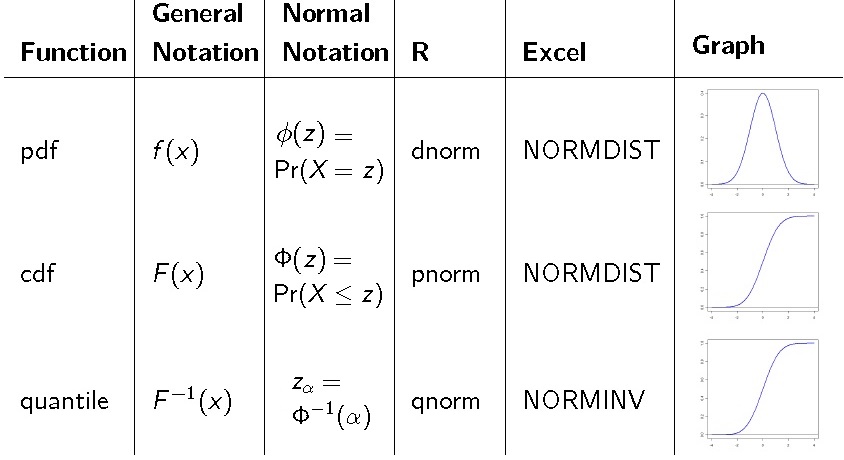
2.1 概率函数
四种前缀(以正态分布 为例):
- d: 概率密度函数或频率函数
dnorm(x,mu,sigma) - p: 累积分布函数
pnorm(x,mu,sigma) - q: 给定概率 ,求累积分布的右侧分位点
qnorm(1-alpha/2,mu,sigma) - r: 生成随机数
rnorm(N,mu,sigma)
课堂讨论:借用下图说明R命令的含义

dnorm(2,0,1)pnorm(2,0,1)qnorm(1-0.05/2,0,1)rnorm(5,0,1)
x <- seq(from = -5, to = 5, by = 0.01) # 横轴向量y <- dnorm(x) # 正态分布的概率密度函数plot(x=x,y=y, type="l",col="seagreen",lwd=2,xlab="x",ylab="density\ny = dnorm(x)")grid(col="darkgrey",lwd=2)title(main="概率分布(PDF)")y <- pnorm(x) # 正态分布的累积分布函数plot(x=x,y=y,type="l",col="seagreen",lwd=2, xlab="x = qnorm(y)",ylab="probability\ny = pnorm(x)") ; grid(col="darkgrey",lwd=2)title(main="累积分布(CDF)")set.seed(1)x <- rnorm(100, sd=3) # 模拟生成单变量y <- rnorm(100, mean=1) + xmn = apply(cbind(x,y), 2, mean) # 计算x和y的均值covmat= cov(cbind(x,y)) # 计算x和y的协方差simdata=rmnorm(300,mean=mn,varcov=covmat) # mnormt包中函数,模拟生成双变量ggplot(as.data.frame(simdata), aes(x=x, y=y)) +geom_point() +geom_smooth(method="lm") + theme_bw()
2.2 统计描述

library(MASS)data(Insurance) # 调用保险数据str(Insurance) # 查看数据结构attach(Insurance) # 绑定数据
- 单变量统计描述
# 1)连续变量mean(Holders) # 基本统计量,有缺失值时用 mean(Holders, na.rm = TRUE)median(Holders)sd(Holders)var(Holders)quantile(Holders) # 四分位值quantile(Holders,seq(0,1,0.1)) # 十分位值library(Hmisc)describe(data.frame(District, Group, Age)) # 简单数据描述describe(data.frame(Holders, Claims))library(fBasics)basicStats(data.frame(Holders, Claims)) # 更多统计量# 2)离散变量table(Age) # 离散变量频率表
- 双变量统计描述
# 1)两个连续变量cor(data.frame(Holders, Claims),use="pairwise",method="pearson") # 相关系数cov(data.frame(Holders, Claims),use="pairwise",method="pearson") # 协方差矩阵# 2)一个连续变量和一个离散变量by(data.frame(Holders,Claims),Age,summary) # 按离散变量分组,对连续变量做统计描述# 3)两个离散变量table(District,Age) # 两个离散变量频率表detach(Insurance) # 解除绑定
2.3 统计推断
- 参数检验
- 正态分布
- 均值检验( 未知)
t.text():单变量 ,双变量 - 方差检验( 未知):
var.text():单变量 ,双变量
- 均值检验( 未知)
- 总体分布未知,单变量或双变量均值检验:
wilcox.test()
- 正态分布
- 分布检验:单变量 ,双变量
- Jarque-Bera 检验
normalTest() - Pearson 检验
chisq.test() - Kolmogorov-Smirnov检验
ks.test()
- Jarque-Bera 检验
3. 应用
3.1 收益率基本概念
3.1.1 资产收益率
- 期简单净收益率(simple return)
- 期简单毛收益率(gross return)或复合收益率(compound return)
- 连续复合收益率(continuous compounding return) 或对数收益率(log-return)
注意:
- 当净收益率很小时,近似等于对数收益率。
# 比较净收益率和对数收益率R <- seq(-0.2,0.2,len=100)data=data.frame(R, r=log(1+R))ggplot(data,aes(R,r)) +geom_line() +geom_abline(slope=1, intercept=0, color="red") +labs(title ="对数收益率(r)和简单净收益率(R)", x = "R", y = "r= log(1+R)") +theme_bw()
- 由于简单净收益率的下限为-1,因此一般不能假定 服从正态分布,而对数收益率的取值为整个实数域,因此一般假定 ,相应的 服从对数正态分布,均值和方差分别为:
4.年化复合收益率
其他相关定义:
- 资产组合收益率(为资产权重):
- 含红利支付 :
- 超额收益率(参照资产标记为0):
## 价格为不同数据类型,计算收益率# 1) 向量P <- c(265.50, 264.27, 266.49, 253.81, 269.20, 277.69, 301.22, 280.98, 312.64,364.03, 393.62, 398.79)P[-length(P)] # P(1), P(2) ... P(T-1)P[-1] # P(2), P(3) ... P(T)R <- P[-1] / P[-length(P)] - 1 # R(t) = P(t+1)/P(t) -1R <- diff(P) / P[-length(P)] # [P(t+1) - P(t)]/P(t)r <- diff(log(P)) # r(t) = log(P(t+t)) - log(P(t))# 2) zoo 对象library(zoo)z <- zooreg(P, as.yearmon("2013-01"), freq = 12)R.z <- diff(z) / lag(z,-1) # 指定 lag=-1r.z <- diff(log(z))# 3) xts 对象library(xts)x <- as.xts(z)R.x <- diff(x) / lag(x) # 默认 lag=1r.x <- diff(log(x))# 4) timeSeries 对象library(timeSeries)r.ts= returns(P)# 比较上述计算结果,注意xts和timeSeries的第一期为NAcomp= data.frame(r, r.z, r.x[-1], r.ts[-1]) # 四种结果列为数据框round(comp,3) # 保留3位小数
3.1.2 债券收益率
记债券价格为 、利息为、面值(par value)为。
- 票面利率
- 当期收益率
- 到期收益率 (yield to maturity, YTM)
3.1.3 汇率升(贴)水率
# 计算股票、债券、汇率的收益率library(quantmod)loadSymbols("AAPL") # 苹果股票loadSymbols("^TNX") # 10年期美国国债收益率loadSymbols("DEXUSEU",src="FRED") # 汇率,1欧元等于E美元# 如果无法直接下载,可通过 load("price.Rdata") 调用数据chartSeries(AAPL,theme="white",TA=NULL) # 股价,TA=NULL则不包括成交量AAPL.rtn=diff(log(AAPL$AAPL.Adjusted)) # 经调整的股价对数收益率chartSeries(AAPL.rtn,theme="white")chartSeries(TNX,theme="white")TNX.rtn=diff(TNX$TNX.Adjusted) # 债券收益率(%)的变化率chartSeries(TNX.rtn,theme="white")chartSeries(DEXUSEU,theme="white")USEU.rtn=diff(log(DEXUSEU$DEXUSEU)) # 汇率变化率chartSeries(USEU.rtn,theme="white")
3.2 资产收益率的特征事实
根据 Fan and Yao(2015) 资产收益率具有以下典型特征:
- 平稳性(stationarity): 有稳定的均值和有限的方差
- 厚尾性(heavy tails):峰度 ,与正态分布相比呈现出尖峰厚尾的特征,说明出现爆涨和爆跌的概率大于正态分布。
- 非对称性(asymmetry): 的分布呈现负偏(negatively skewed)特征,说明市场下跌比上涨的程度大。
- 波动集聚性(volatility clustering):指市场会连续大幅上涨(或下跌)。
- 加总高斯性(aggregational Gaussianity):当时间跨度上升时,相应的收益率会趋向正态分布,如年收益率与月收益率和日收益率相比,更接近于正态分布。
- 长期记忆性(long-memory properties):即各期收益率之间存在相关性。
- 杠杆效应(leverage effect):当收益率为负(即股价下跌)时,企业杠杆率上升、风险上升,股票波动性也随之上升,这种收益率和波动性变化率之间的负相关关系被称为杠杆效应。
# 以苹果的对数收益率为例x=as.data.frame(AAPL.rtn)[,1]# 或者用 Tsay(2013)中3M公司数据url="https://faculty.chicagobooth.edu/ruey.tsay/teaching/introTS/ch1data.zip"download.file(url, "ch1data.zip") # 下载存为同名文件x=read.table(unz("ch1data.zip","d-mmm-0111.txt"),header=T) # 读入数据x=x[,2] # 去掉日期# 1) 作图hist(x,nclass=30) # 直方图d1=density(x,na.rm=T) # 密度plot(d1$x,d1$y,xlab='rtn',ylab='density',type='l') # 密度线rangex=range(x,na.rm=T) # 取值范围seqx=seq(rangex[1],rangex[2],.001) # x轴间隔0.001y1=dnorm(seqx,mean(x,na.rm=T),stdev(x,na.rm=T)) # 正态分布lines(seqx,y1,lty=2) # 添加正态分布线# 2) 检验library(fBasics)basicStats(x)mean(x,na.rm=TRUE); var(x,na.rm=TRUE); stdev(x,na.rm=TRUE);t.test(x) # 均值检验 H0: x=0normalTest(x,method='jb',na.rm=T) # 正态分布检验,JB-tests3=skewness(x,na.rm =T)T=length(x)t3=s3/sqrt(6/T)pp=2*(1-pnorm(t3)) # 偏度检验(Skewness test)s4=kurtosis(x,na.rm =T)t4=s4/sqrt(24/T)pp=2*(1-pnorm(t4)) # 峰度检验(Kurtosis test)
参考文献
- 范剑青、姚琦伟著:The Elements of Financial Econometrics(计量金融精要),科学出版社,2015
- 黄文、王正林编著:《数据挖掘:R语言实战》,电子工业出版社,2014
- R.I. Kabacoff著:《R语言实战(第2版)》,王小宁、刘撷芯、黄俊文译,人民邮电出版社,2016
- R.S. Tsay著:《金融数据分析导论:基于R语言》,李洪成等译,机械工业出版社,2013
- Yollin, G.: R Programming for Quantitative Finance, Lecture Notes
