@hadoopMan
2018-01-04T02:45:54.000000Z
字数 4152
阅读 1958
SparkSql 中外连接查询中的谓词下推规则
sparksql
基本概念
SparkSql
SparkSql是架构在spark计算框架之上的分布式Sql引擎,使用DataFrame和DataSet承载结构化和半结构化数据来实现数据复杂查询处理,提供的DSL可以直接使用scala语言完成sql查询,同时也使用thrift server提供服务化的Sql查询功能。SparkSql提供了Data Source API,用户通过这套API可以自己开发一套Connector,直接查询各类数据源,包括NoSql、RDBMS、搜索引擎以及HDFS等分布式FS上的文件等。和SparkSql类似的系统,从Sql和计算框架分离角度看应该就是Hive;从面相的业务类型看有PrestoDB、Impala等(都可以在一定程度上应对即系查询)。
谓词下推
所谓谓词(predicate),英文定义是这样的:A predicate is a function that returns bool (or something that can be implicitly converted to bool),也就是返回值是true或者false的函数,使用过scala或者spark的同学都知道有个filter方法,这个高阶函数传入的参数就是一个返回true或者false的函数。如果是在sql语言中,没有方法,只有表达式,where后边的表达式起的作用正是过滤的作用,而这部分语句被sql层解析处理后,在数据库内部正是以谓词的形式呈现的。
那么谓词为什么要下推呢?说白了,这个问题就是要回答到底谁来完成过滤数据的操作。那么谁都可以来完成数据过滤呢?我们大致可以把SparkSql中的查询处理流程做如下的划分:
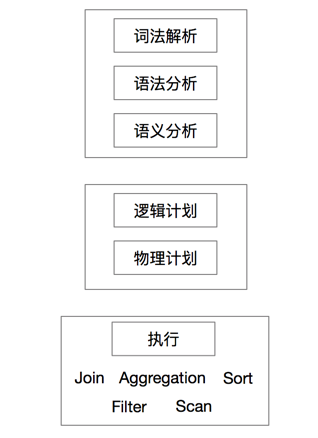
SparkSql首先会对输入的sql语句进行一系列的分析,包括词法解析(可以理解为搜索引擎中的分词这个过程)、语法分析以及语义分析(例如判断database或者table是否存在、group by必须和聚合函数结合等规则);之后是执行计划的生成,包括逻辑计划和物理计划,其中在逻辑计划阶段会有很多的优化,而物理计划则是RDD的DAG图的生成;这两步完成之后则是具体的执行了(也就是各种重量级的计算逻辑),这就会有各种物理操作符(RDD的Transformation)的乱入,和本文讨论的问题相关的则是Filter和Scan两个操作符。其中Scan操作符直接面向底层数据源,完成数据源的扫描读取;Filter操作符完成扫描后数据的过滤。
我们知道,可以通过封装SparkSql的Data Source API完成各类数据源的查询,那么如果底层数据源无法高效完成数据的过滤,就会执行直接的全局扫描,把每条相关的数据都交给SparkSql的Filter操作符完成过滤,虽然SparkSql使用的Code Generation技术极大的提高了数据过滤的效率,但是这个过程无法避免大量数据的磁盘读取,甚至在某些情况下会涉及网络IO(例如数据非本地化时);如果底层数据源在进行扫描时能非常快速的完成数据的过滤,那么就会把过滤交给底层数据源来完成,这就是SparkSql中的谓词下推(至于哪些数据源能高效完成数据的过滤以及SparkSql是又如何完成高效数据过滤的则不是本文讨论的重点)。
外连接查询和连接条件
外连接查询(outter join),分为左外连接查询、右外连接查询以及全外连接查询,全外连接使用的场景不多,所以本文重点讨论的是左连接查询和右连接查询。
连接条件,则是指当这个条件满足时两表的两行数据才能”join“在一起被返回,例如有如下查询:
SELECT LT.value, RT.valueFROM lefttable LT LEFT JOIN righttable RTON LT.id = RT.id AND LT.id > 1WHERE RT.id > 2
其中的“LT.id=RT.id AND LT.id>1” 这部分条件被称为“join中条件”,直接用来判断被join的两表的两行记录能否被join在一起,如果不满足这个条件,两表的这两行记录并非全部被踢出局,而是根据连接查询类型的不同有不同的处理,所以这并非一个单表的过滤过程或者两个表的的“联合过滤”过程;而where后的“RT.id>2”这部分被称为“join后条件”,就是一个单表过滤过程。而上边提到的谓词下推能否在两类条件中使用,在SparkSql中则有特定的规则,以左外连接查询为例,规则如下:
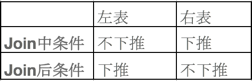
接下来对这个表格中的规则进行详细的分析。
下推规则分析
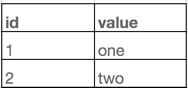
假设我们有两张表,表结构很简单,数据也都只有两条,但是足以讲清楚我们的下推规则,两表如下:
lefttable:

rigthtable:
左表join后条件下推
查询语句如下:
SELECT LT.id, LT.value, RT.valueFROM lefttable LTLEFT JOIN righttable RTON LT.id = RT.idWHERE LT.id > 1
来分析一下LT.id>1下推到左表进行数据过滤的结果,经过LT.id>1过滤后,左表变为:

此时再和右表进行左连接,左表id为2的行,在右表中能找到id为2的行,则连接结果如下:

可见,条件下推过滤了左表整整50%的数据,相当牛叉,虽然只有两条。究其原因,是因为在SparkSql中,把以上的查询解析成了如下的子查询:
SELECT LT.id, LT.value, RT.valueFROM (SELECT id, valueFROM lefttable LTWHERE LT.id > 1) TTLEFT JOIN righttable RTON TT.id = RT.id
这是一个非相关子查询,即完全可以先完成子查询,再完成父查询,子查询在查询过程中和外部查询没有关联关系。
左表join中条件不下推
查询语句如下:
SELECT LT.id, LT.value, RT.valueFROM lefttable LT LEFT JOIN righttable RTON LT.id = RT.id AND LT.id > 1
谓词下推是为了提高查询效率,如果不下推也可以得到正确的查询结果,所以来看看不下推的情况下计算出的正确结果,join过程如下:
第一步:左表id为1的行在右表中能找到相等的id,但是左表的id为1,是不满足第二个join条件(LT.id>1)的,所以左表这一条相当于没有和右表join上,所以左表的值value保留,而右表的value为null(你没满足join中条件没join上还把你的值保留,给我搞个空值?没办法,就是这么任性)。
第二步:左表id为2的行在右表中能找到,而且左表id为2的行的id大于1,两个join条件都满足,所以算是和右表join上了,所以左表和右表的value都保留。最终的查询结果如下:
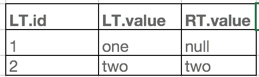
那么如果把"LT.id>1“这个条件下推到做表,会得到什么结果呢?
首先左表经过"LT.id>1“过滤后,如下:

此时再和右表连接,左表id为2的行在右表中能找到,且满足”LT.id = RT.id AND LT.id > 1“这个join中条件,所以两表的value都被保留。左表中已经没有数据了,查询结束,查询结果如下:

这个查询结果和不下推的正确结果不一致,显然是个错误的结果,所以左表join中条件是不能下推进行数据过滤的。
右表join中条件下推
查询语句如下:
SELECT LT.id, LT.value, RT.valueFROM lefttable LT LEFT JOIN righttable RTON LT.id = RT.idAND RT.id > 1
现在把RT.id>1这个右表join中条件下推,来过滤右表,过滤后如下:

然后左表再和右表进行左连接,流程如下:
第一步:左表id为1的行在右表中没有,此时左表值保留,右表为null
第二步:左表id位2的行在右表中有,并且RT.id大于1,两个join条件都满足,则左表和右表的值都保留。查询结果如下:

那么如果不下推(为了得到正确结果),来看看结果,流程如下:
第一步:左表id为1的行在右表中有,但是不满足第二个join条件,所以这行算是没join上,所以左表数据保留,右表为null
第二步:左表id为2的行在右表中有,也满足第二个join条件,所以左右表的数据都保留。
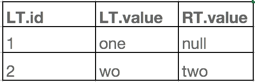
可见,右表join中条件下推不下推,结果一样,所以,干吗不下推?可以过滤掉一半的数据呢。Sparksql中的等价处理语句是:
SELECT LT.id, LT.value, RT.valueFROM LT LEFT JOIN (SELECT id, valueFROM righttable RTWHERE RT.id > 1) TTON LT.id = TT.id
右表join后条件不下推
这个应该是最违反常规理解的查询了,查询语句如下:
SELECT LT.id, LT.valueFROM lefttable LEFT JOIN righttable RTON LT.id = RT.idWHERE RT.id > 1
首先来看,join后条件不下推的情况,流程如下:
第一步:左表id为1的行在右表中可以找到,但是此时仅仅满足join条件,在使用where条件判断这条连接后数据时,发现右表的id不满足RT.id>1的条件,所以这条join结果不保留(注意,这里是不保留,全都不保留,左表右表都不保留,要跟上边的没join上,右表的值为null的情况区别开,这也是关键所在)
第二步:左表id为2的行和右表id为2的行join上了,同时也满足RT.id>1的where条件。

很明显,这是一条符合语义的正确的查询结果。
好了,接下来看看右表join后条件下推的情况:
第一步:使用RT.id>1过滤右表,过滤后右表只剩一行id为2的行
第二步:左表id为1的行在过滤后的右表中没有,此时左表值保留,右表值为null
第三步:左表id为2的行在右表中有,此时左表值保留,右表值也保留。
结果如下:
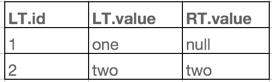
很明显这其实是一个错误的结果。
总结
至此,左联接查询的四条规则分析完了,可以看出,在SparkSql中对于外连接查询时的过滤条件,并不能在所有情况下都用来进行数据源的过滤,如果使用得当会极大的提升查询性能,如果使用不当,则会产生错误的查询结果,而这种错误结果又不易发觉,所以使用时要格外小心。
