@hadoopMan
2015-11-22T15:16:21.000000Z
字数 5144
阅读 1192
mapreduce单词统计案例编程
初探mapreduce
1,环境搭建
1.1 准备软件
apache-maven-3.0.5-bin.tar.gz
eclipse-jee-kepler-SR1-linux-gtk-x86_64.tar.gz
1.2 安装apache-maven-3.0.5
1.21首先将apache-maven-3.0.5-bin.tar.gz解压到/opt/compileHadoop/目录下。
$tar -zxvf apache-maven-3.0.5-bin.tar.gz ./
1.22配置环境变量。
使用sudo vi /etc/profile命令打开文件,在末尾添加内容如下:
$vi /etc/profile添加export MAVEN_HOME=/usr/local/apache-maven-3.0.5export PATH=$PATH:$MAVEN_HOME/bin
1.23验证mvn是否安装成功

1.3 安装eclipse
使用cd /opt/tools/ 进入eclipse 的安装目录,然后使用如下命令,将文件解压到当前目录内:
$tar –zxf eclipse-jee-kepler-SR1-linux-gtk-x86_64.tar.gz ./
使用cd eclipse命令进入软件主目录,可以查看软件的文件:

1.4 使用eclipse创建mvn工程。
1.41 首先使用./eclipse命令打开eclipse程序。

1.42 安装mvn到eclipse。
在eclipse界面下打开window,出现如下窗口:
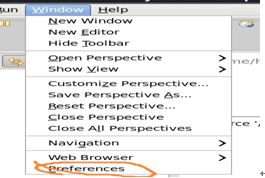
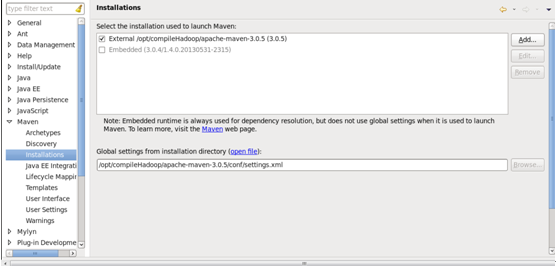
点击preference,弹出如下窗口,添加apache-maven-3.0.5安装目录,完成后如下:点击preference,弹出如下窗口,添加apache-maven-3.0.5安装目录,完成后如下:
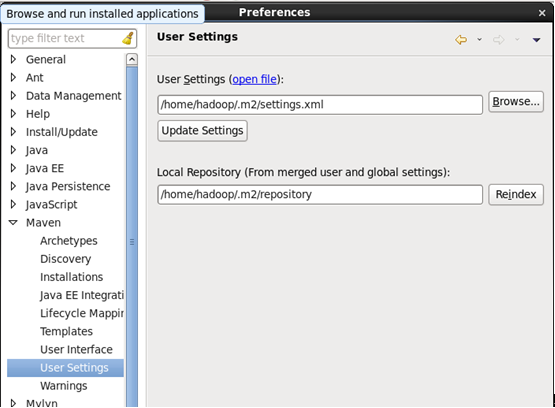
打开user setting配置窗口如下:
首先我们来创建/home/hadoop/.m2目录:
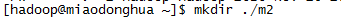
创建成功后:

拷贝setting.xml到/home/hadoop/.m2目录下:
$cp /opt/compileHadoop/apache-maven-3.0.5/conf/settings.xml ~/.m2/
1.42创建mvn工程.

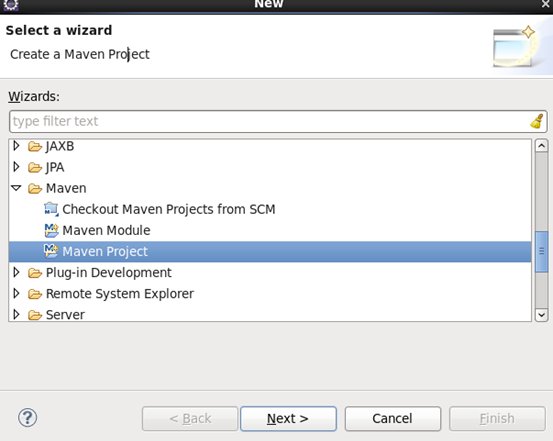
选中maven project点击next,进入下图,再点击next:

选择如下内容后点击next
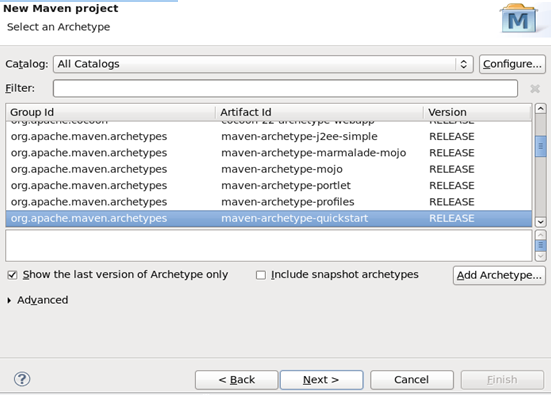
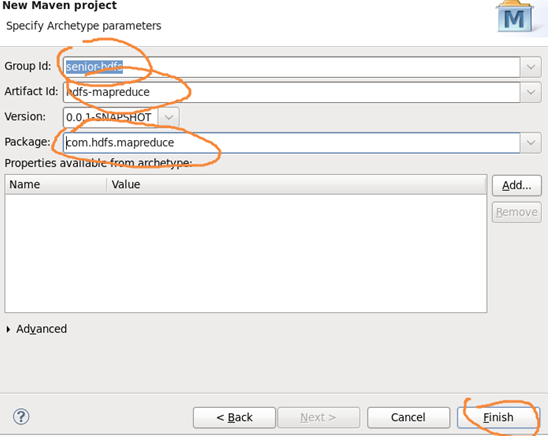
填写工程组及工程名,点击finish.
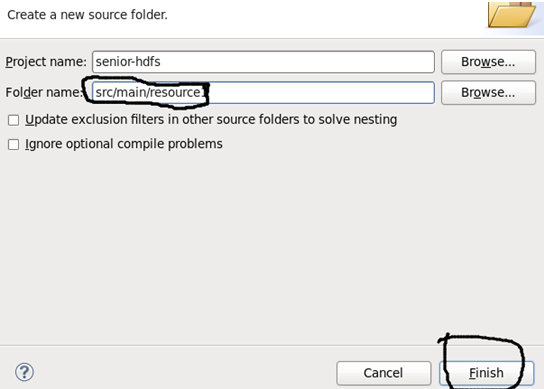
添加一个存储配置文件目录,名字如下,点击finish。
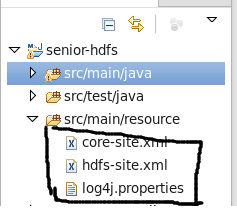
拷贝core-site.xml、hdf-site.xml及log4j.properties到
/opt/tools/workspace/senior-hdfs/src/main/resource目录下,命令如下:
$cp /opt/modules/hadoop-2.5.0/etc/hadoop/core-site.xml /opt/tools/workspace/senior-hdfs/src/main/resource$cp /opt/modules/hadoop-2.5.0/etc/hadoop/hdfs-site.xml /opt/tools/workspace/senior-hdfs/src/main/resource$cp /opt/modules/hadoop-2.5.0/etc/hadoop/log4j.properties /opt/tools/workspace/senior-hdfs/src/main/resource
执行以上命令后,点击刷新目录,该目录下多出三个文件。
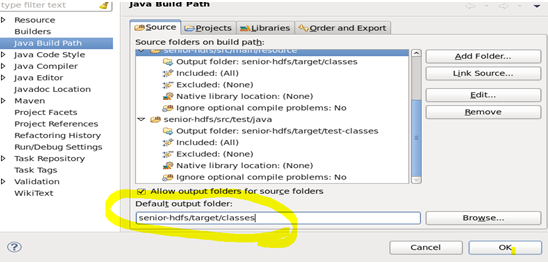
添加输出目录:
修改prom.xml内容为:
<properties><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding><hadoop.version>2.5.0</hadoop.version></properties><dependencies><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-client</artifactId><version>${hadoop.version}</version></dependency><dependency><groupId>junit</groupId><artifactId>junit</artifactId><version>4.10</version><scope>test</scope></dependency></dependencies>
到此处,一个完整的mvn工程算是建立完成。
2,基于【八股文】格式编写wordcount程序
程序内容如下:
package com.hadoop.hdfs.mapreduce;import java.io.IOException;import org.apache.hadoop.fs.Path;import org.apache.hadoop.io.IntWritable;import org.apache.hadoop.io.LongWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Job;import org.apache.hadoop.mapreduce.Mapper;import org.apache.hadoop.mapreduce.Reducer;import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;public class WordCoundMapreduce {//mappublic static class WordCoundMaper extends Mapper<LongWritable, Text, Text, IntWritable>{private Text mapOutputKey=new Text();private final static IntWritable mapOutputValue=new IntWritable(1);@Overrideprotected void map(LongWritable key, Text value, Context context)throws IOException, InterruptedException {String lineValue=value.toString();//按行读取的数据转化为字符串String[] strs = lineValue.split(" ");//按空格分割for(String str:strs){mapOutputKey.set(str);//Sting to TEXT文本类型context.write(mapOutputKey, mapOutputValue);//写到上下文中,专递给reduce}}}//reduced `13public static class WordCoundReducer extends Reducer<Text, IntWritable,Text ,IntWritable >{private IntWritable outputValue=new IntWritable();@Overrideprotected void reduce(Text key, Iterable<IntWritable> values,Context context)throws IOException, InterruptedException {int sum=0;//暂存key的总数值for(IntWritable value:values){sum+=value.get();//计算同一个key的元素数量}outputValue.set(sum);//int转化为IntWritablecontext.write(key, outputValue);//通过写到上下文中来写道hdfs中}}//driverpublic int run(String[] args)throws Exception{Configuration conf=new Configuration();//Job job = Job.getInstance(conf, this.getClass().getCanonicalName());job.setJarByClass(this.getClass());//设置输入路径Path inPath=new Path(args[0]);FileInputFormat.addInputPath(job, inPath);job.setMapperClass(WordCoundMaper.class);//设置map类job.setMapOutputKeyClass(Text.class);//设置输出key类型job.setMapOutputValueClass(IntWritable.class);//设置输出value类型job.setReducerClass(WordCoundReducer.class);//设置reduce类job.setOutputKeyClass(Text.class);//设置输出key类型job.setOutputValueClass(IntWritable.class);//设置输出value类型//设置输出路径Path outPath=new Path(args[1]);FileOutputFormat.setOutputPath(job, outPath);boolean isSuccess=job.waitForCompletion(true);//等待作业完成return isSuccess ? 0 : 1;}public static void main(String[] args) throws Exception{args =new String[]{"hdfs://miaodonghua.host:8020/user/hadoop/input/",//"hdfs://miaodonghua.host:8020/user/hadoop/output3"};int status = new WordCoundMapreduce().run(args);System.exit(status);}}
在当前用了目录下创建imput目录,并将/opt/datas/wc.input上传:
$bin/hdfs dfs -mkdir input/$bin/hdfs dfs -put /opt/datas/wc.input input/
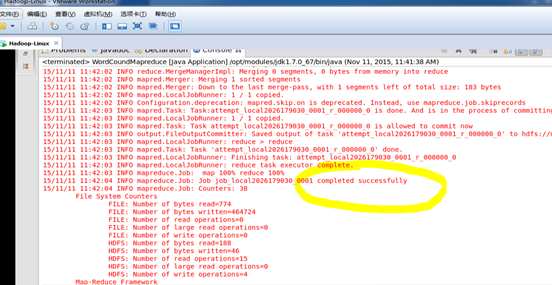
在eclipse工作空间内运行程序。
3 将八股文形式的wordcount导出为jar包,以便在yarn上运行。
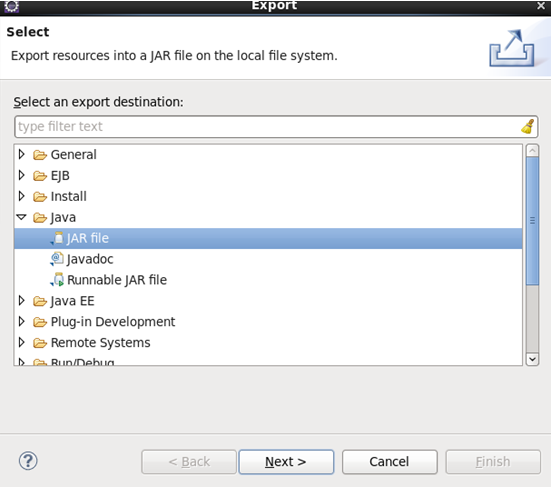
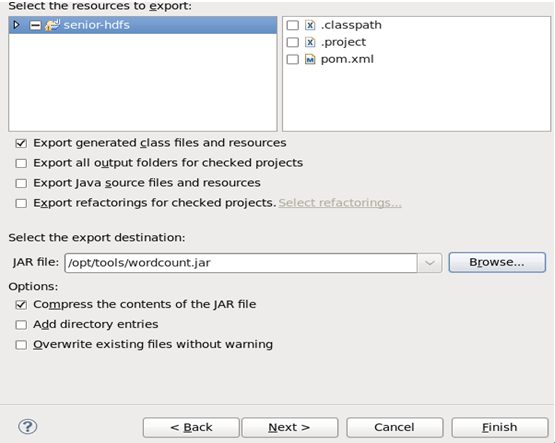
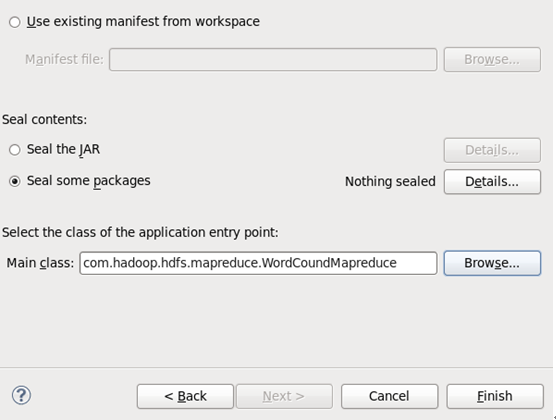
导出成功后,可在/opt/tools/目录下查看:

4,运行生成的wordcount.jar,命令如下:
$bin/yarn jar /opt/tools/wordcount.jar com.hadoop.dfs.mapreduce.wordcountmapreduce /usr/hadoop/input /usr/hadoop/output
可以在webaap,查看到生成目录:
Mapreduce进行词频统计的时候主要分为两部分,即map和reduce.
(1) hdfs文件由inputSplit分割成不同的块,然后交由RecordReader按行形成对(这里key指的是行偏移,value指的是正行的内容)。
(2) map读取RecordReader形成的,经过处理生成,通过上下文context传递reduce。(这里key指的是单词,value指的是单词的数量.map生成的已经根据key进行了排序。)
(3)Reduce读取map生成的,然后将相同key的整合成使用context上下文写入到hdfs文件中.这里的key与value是用制表符分割。
注:map的数量由InputSplit决定,一个InputSplit对应一个map。而InputSplit的数量由文件的大小及数量决定。文件大小小于系统的block大小,则一个文件就对应一个InputSplit。如果文件大于了block块,则将文件按block分割一个分割块对应一个InputSplit。
完整的程序流程如下:

