@hadoopMan
2017-03-04T14:25:53.000000Z
字数 2332
阅读 1516
RDD的操作
spark
想学习spark,hadoop,kafka等大数据框架,请加群459898801,满了之后请加2群224209501。后续文章会陆续公开
1,RDD创建
1,方式一直接读取hdfs上文件
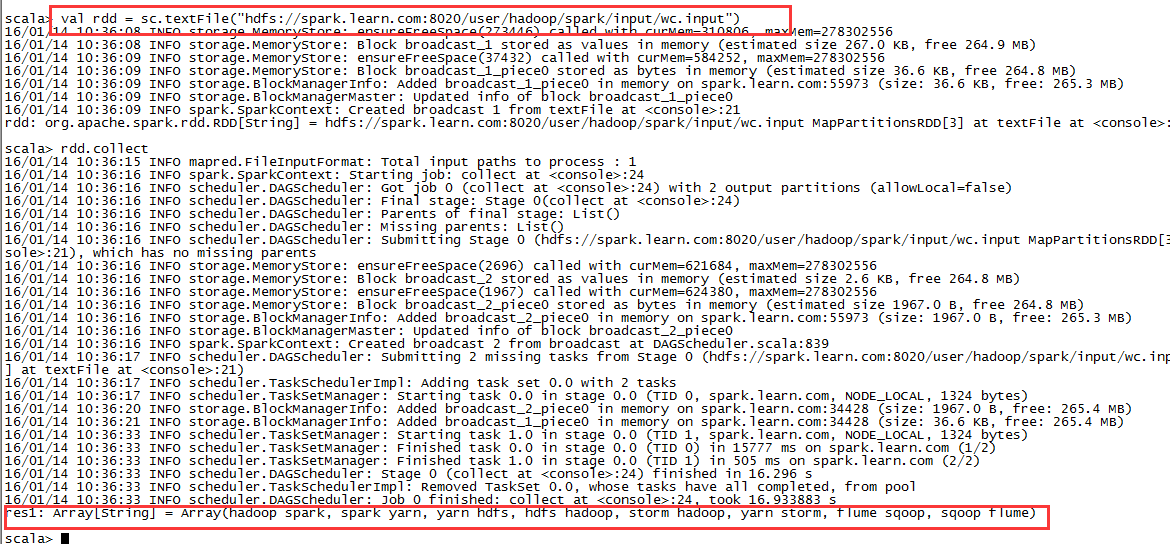
1,读取hdfs上文件生成RDD
val rdd = sc.textFile("hdfs://spark.learn.com:8020/user/hadoop/spark/input/wc.input")
2,对RDD进行处理
val kvRdd = rdd.flatMap(line => line.split(" ")).map(word => (word,1)).reduceByKey((a,b) => (a + b))kvRdd.collect

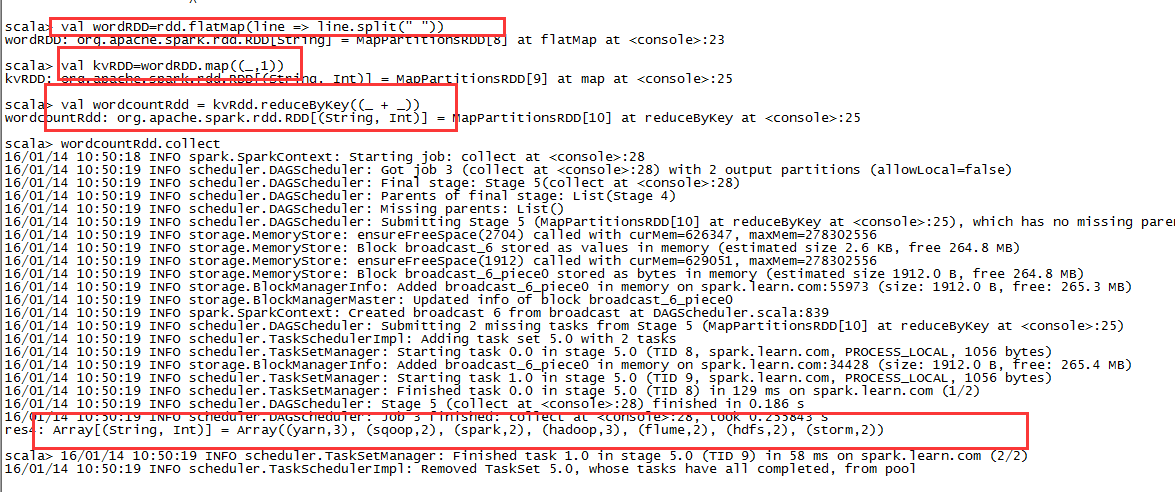
3,对key进行排序
val wordRdd = rdd.flatMap(line => line.split(" "))val kvRdd = wordRdd.map((_,1))val wordcountRdd = kvRdd.reduceByKey((_ + _))wordcountRdd.collect
wordcountRdd.map(x => (x._2,x._1)).sortByKey(false).map(x => (x._2,x._1)).take(3)
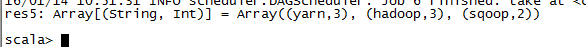
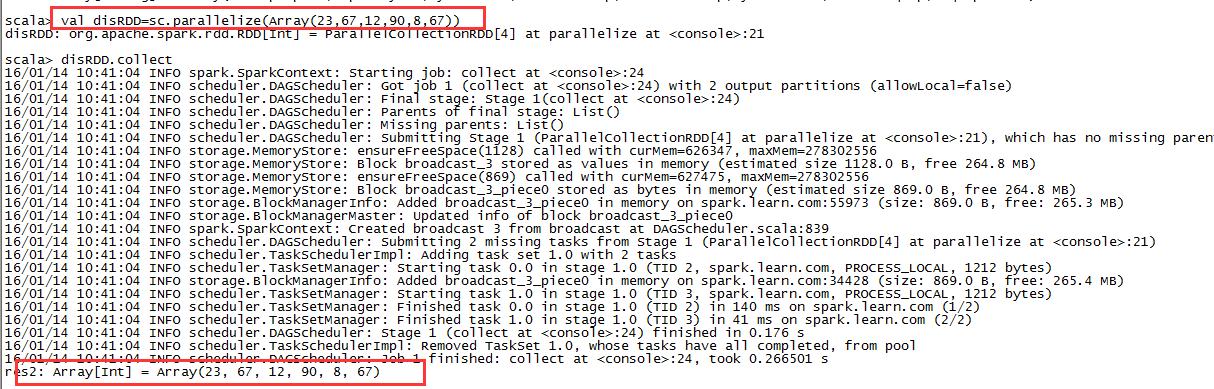
2,方式二并行化数组:
1,并行数组生成RDD
val disRDD=sc.parallelize(Array(23,67,12,90,8,67))
take,top,first,rdd.takeOrdered
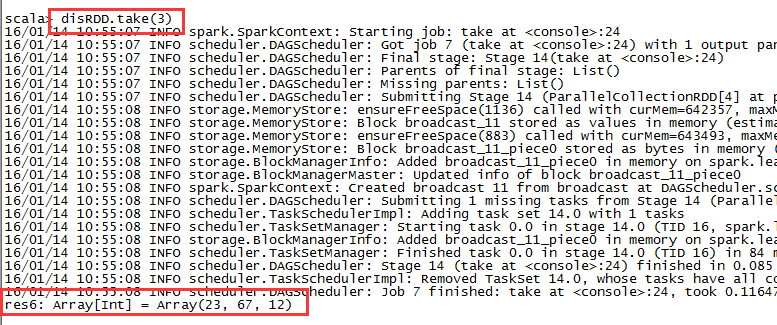
2,take
disRDD.take(3)
3,first
disRDD.first

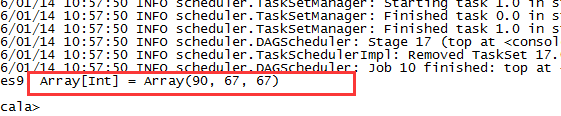
4,top:
disRDD.top(3)
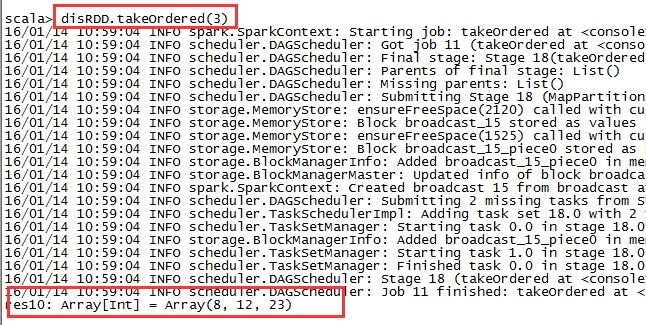
5,takeOrdered:
disRDD.takeOrdered(3)
3,分组并取前几个较大值
先分组,然后对于每组中的数据进行排序(降序),取前KEY值
1,方法一:
1,数据内容
数据集aa 78bb 98aa 80cc 98aa 69cc 87bb 97cc 86aa 97bb 78bb 34cc 85bb 92cc 72bb 32bb 23
2,读取文件生成RDD并处理
scala> val rdd = sc.textFile("/user/hadoop/spark/input/spark.input")scala> rdd.map(line => line.split(" ")).collectArray[String] : Array(aa, 78)scala> rdd.map(line => line.split(" ")).map(x => (x(0),x(1))).collect(String, String) :(aa,78)scala> rdd.map(line => line.split(" ")).map(x => (x(0),x(1).toInt)).collect(String, Int) : (aa,78)scala> rdd.map(line => line.split(" ")).map(x => (x(0),x(1).toInt)).groupByKey.collect(String, Iterable[Int]) : (aa,CompactBuffer(78, 80, 69, 97))rdd.map(line => line.split(" ")).map(x => (x(0),x(1).toInt)).groupByKey.map(x => (x._1,x._2.toList)).collect(String, List[Int]) : (aa,List(78, 80, 69, 97))rdd.map(line => line.split(" ")).map(x => (x(0),x(1).toInt)).groupByKey.map(x => (x._1,x._2.toList.sorted)).collect(String, List[Int]): (aa,List(69, 78, 80, 97))rdd.map(line => line.split(" ")).map(x => (x(0),x(1).toInt)).groupByKey.map(x => (x._1,x._2.toList.sorted.reverse)).collect(String, List[Int]): (aa,List(97, 80, 78, 69))rdd.map(line => line.split(" ")).map(x => (x(0),x(1).toInt)).groupByKey.map(x => (x._1,x._2.toList.sorted.reverse.take(3))).collectres26: Array[(String, List[Int])] = Array((aa,List(97, 80, 78)), (bb,List(98, 97, 92)), (cc,List(98, 87, 86)))
3,结果:

2,方法二:
1,读取文件生成RDD并处理
rdd.map(line => line.split(" ")).map(x => (x(0),x(1).toInt)).groupByKey.map(x => {val xx = x._1val yy = x._2val yx = yy.toList.sorted.takeRight(3).reverse(xx, yx)}).collect
2,结果

4,实现二次排序
rdd.map(line => line.split(" ")).map(x => (x(0),x(1).toInt)).groupByKey.map(x => {val xx = x._1val yy = x._2val yx = yy.toList.sorted.takeRight(3).reverse(xx, yx)}).sortByKey(true).collect

