@hadoopMan
2017-03-13T02:22:01.000000Z
字数 7070
阅读 1158
hadoopHA安装部署测试
hadoop
本文主要完成以下内容:
1) HDFS HA(高可用性)原理(把握四大要点),最好自己作图
2) 依据官方文档及课程讲解配置HDFS HA启动并测试
3) YARN ResouceManager HA和ResouceManager Restart 功能及配置部署与测试。
1,背景
- Hadoop2.0之前,在HDFS集群中NameNode存在单点故障(SPOF)。对于只有一个NameNode的集群,若NameNode机器出现故障。则整个集群将无法使用,直到NameNode重启。
- NameNode主要在以下两个方面影响HDFS集群
(1),NameNode机器发生意外,如宕机,集群将无法使用,直到管理员重启。
(2),NameNode机器需要升级:包括软件升级和硬件升级,此时集群也将无法使用 - HDFS HA功能通过配置Active/Standby
两个NameNode实现在集群中对NameNode的热备份来解决上述问题。如果出现故障,如机器崩溃或者机器需要升级维护,这时可通过此种方式将NameNode很快的切换到另外一台机器。
1.1 HDFS HA要点
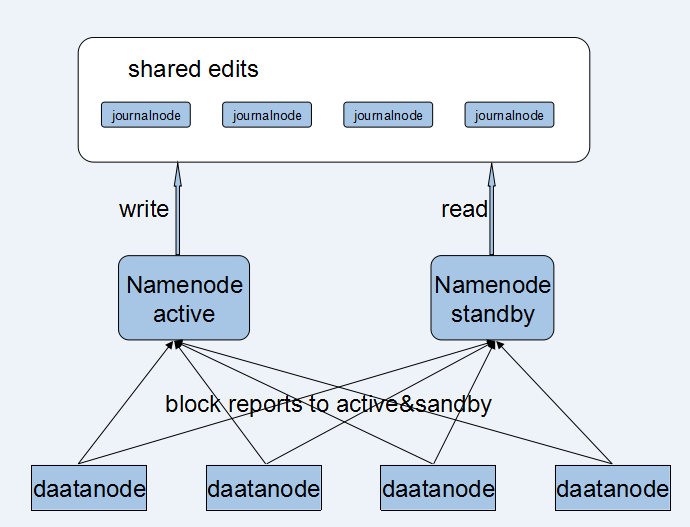
(1).保证两NameNode内存中存储文件系统的元数据要同步。
文件系统元数据变化edits文件安全性的保证也是重点。
方案:如何保证edits安全性
1,好的文件系统。比如好的硬盘
2,分布式存储日志信息。-QJM
2n+1节点管理日志 journalNode只要有n+1写成功就算成功。奇数。
3,使用ZK进行数据存储。
(2).实时接收datanode发送的心跳及块报告。
*dataNode注册
*datanode块报告
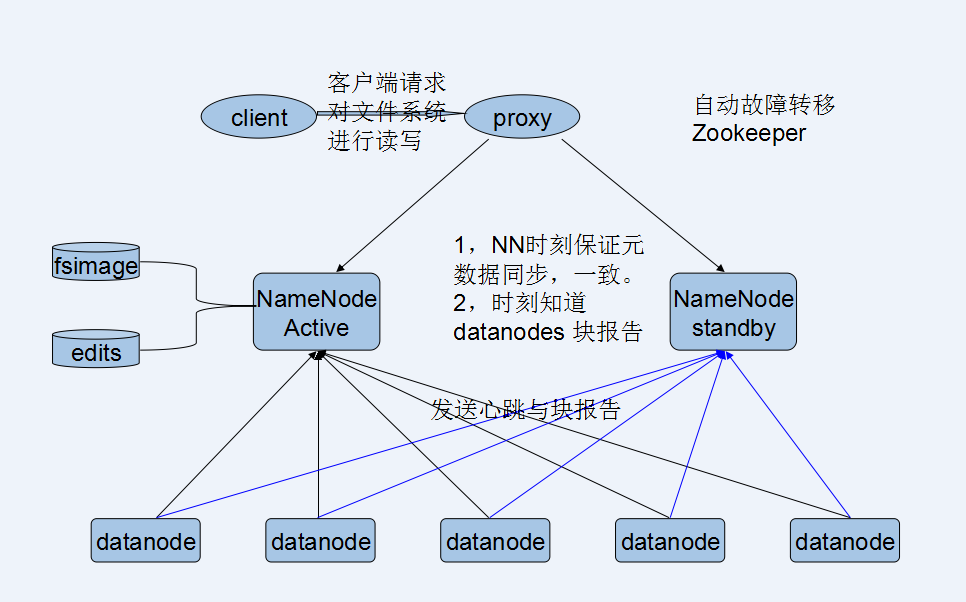
(3).Client 通过代理来访问NN.
代理(Proxy)决定访问那个处于活跃状态的NameNode。
(4).使用隔离机制保障时刻只有一个NameNode处于活跃状态。
1.2,HDFS HA设计结构图
根据四大要点HDFS HA的设计结构图:
2,QJM HA 配置
2.1 基本配置
2.1.1,NameNode HA基本配置(core-site.xml,hdfs-site.xml.)
1,ActiveNameNode与StandbyNameNode地址配置(hdfs-site.xml)
<property><name>dfs.nameservices</name><value>mycluster</value><!--集群的名字 --></property><property><name>dfs.ha.namenodes.mycluster</name><value>nn0,nn1</value><!--//两个namenode的名字 --></property><property><name>dfs.namenode.rpc-address.mycluster.nn0</name><value>miaodonghua.host:8020</value><!-- //nn0所在主机 --></property><property><name>dfs.namenode.rpc-address.mycluster.nn1</name><value>miaodonghua.host1:8020</value><!-- //nn1所在主机 --></property>
2,NameNode和DataNode本地存储路径配置(hdfs-site.xml)
<property><name>fs.defaultFS</name><value>hdfs://mycluster</value></property><property><name>hadoop.tmp.dir</name><value>/opt/app/hadoop-2.5.0/data/tmp</value></property>
3,HDFS NameSpace访问配置(hdfs-site.xml)
<property><name>dfs.namenode.http-address.mycluster.nn0</name><value>miaodonghua.host:50070</value></property><property><name>dfs.namenode.http-address.mycluster.nn1</name><value>miaodonghua1.host:50070</value></property>
4,隔离fencing配置(配置两节点之间的相互SSH无密匙登录)(hdfs-site.xml)
<property><name>dfs.ha.fencing.methods</name><value>sshfence</value></property><property><name>dfs.ha.fencing.ssh.private-key-files</name><value>/home/hadoop/.ssh/id_rsa</value></property>
2.1.2,QJM配置(hdfs-site.xml)
1,QJM管理编辑日志
<property><name>dfs.namenode.shared.edits.dir</name><value>qjournal://miaodonghua.host:8485;miaodonghua2.host:8485;miaodonghua2.host:8485/mycluster</value></property>
2,编辑日志存储目录
<property><name>dfs.journalnode.edits.dir</name><value>/opt/app/hadoop-2.5.0/data/dfs/jn</value></property>
2.1.3,客户端代理配置
<property><name>dfs.client.failover.proxy.provider.mycluster</name><value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value></property>
2.1.3,QJM HA的启动
(1).在各个JournalNode节点上,输入一下命令启动JournalNode:
$sbin/hadoop-daemon.sh start journalnode
(2).在[nn1]上,对其进行格式化,并启动:
$bin/hdfs namenode -format$sbin/hadoop-daemon.sh start namenode
(3).在[nn2]上,同步nn1的元数据信息:
$bin/hdfs namenode -bootstrapStandby
(4).启动[nn2]:
$sbin/hadoop-daemon.sh start namenode
(5).将[nn1]切换为Active
$bin/hdfs haadmin -transtionToActive nn0
(6).在[nn1]上,启动所有datanode
$sbin/hadoop-daemon.sh start datanode
执行上述指令完毕后,三台机器hadoop服务开启情况如下:



web浏览页面可以看到两个namenode的状态如下:


(7).创建目录,上传文件
$bin/hdfs dfs -mkdir -p /usr/hadoop/input/$bin/hdfs dfs -put /opt/datas/wc.input/ /usr/hadoopinput/
执行成功后:
![1.png-28.6kB][8]
2.2,手动故障转移(无需配置)
1,执行一下命令,
$kill -9 pid(active namenode)$bin/hdfs haadmin -transtionToActive nn1 --forceactive
2,命令执行成功后:
 ,
,
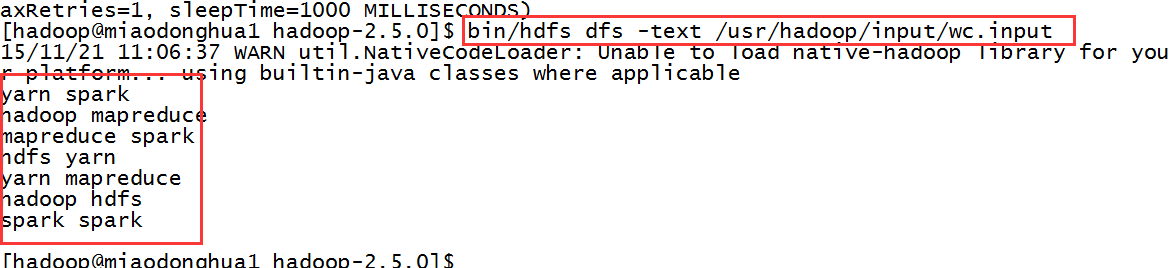
3,读取wc.input的内容:
$bin/hdfs dfs -text /usr/hadoop/input/wc.input
2.3 NN HA自动故障转移
自动故障转移设计结构图:
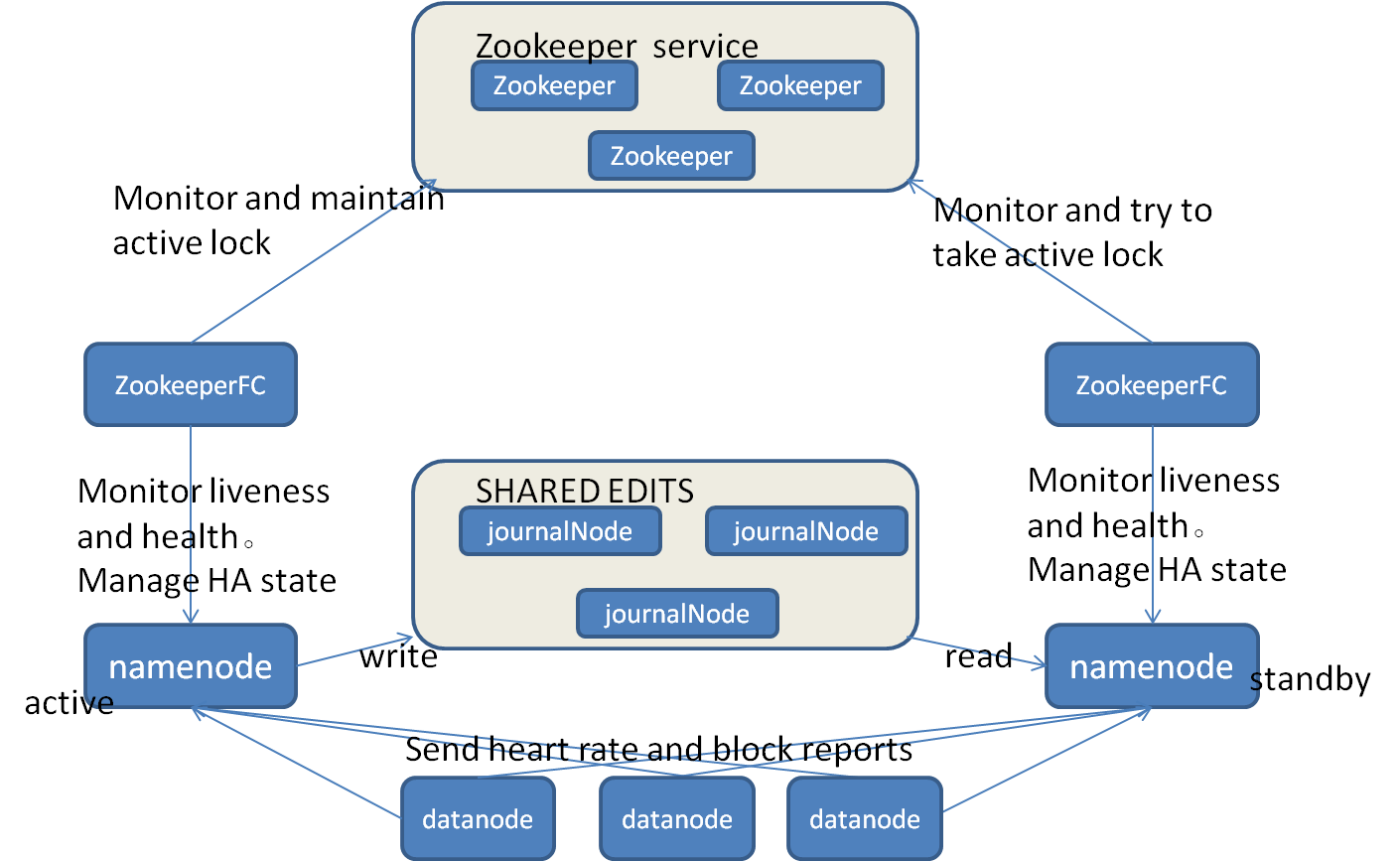
1. 启动zookeeper
(1).关闭所有HDFS服务,命令:
$sbin/stop-dfs.sh
(2).启动Zookeeper集群,命令:
$bin/zkServer.sh start
(3).初始化HA在Zookeeper中状态,命令:
$bin/hdfs zkfc -formatZK


(4).启动HDFS服务,命令:
$sbin/start-dfs.sh
(5).在各个NameNode节点上启动DFSZK Failover Controller,先在哪台机器上启动,哪个NameNode就是ActiveNameNode。命令:
$sbin/hadoop-daemon.sh start zkfc
2. 验证
(1).将ActiveNameNode进程kill,命令:
$kill -9 pid
(2).将Active机器断开网络,命令:
$sudo service network stop
3,yarn resourcemanager HA
- ResourceManager (RM) is responsible for tracking the resources in a cluster, and scheduling applications (e.g., MapReduce jobs).
- Prior to Hadoop 2.4, the ResourceManager is the single point of failure in a YARN cluster.
- The High Availability feature adds redundancy in the form of an Active/Standby ResourceManager pair to remove this otherwise single point of failure.
1. RM HA的结构示意图:
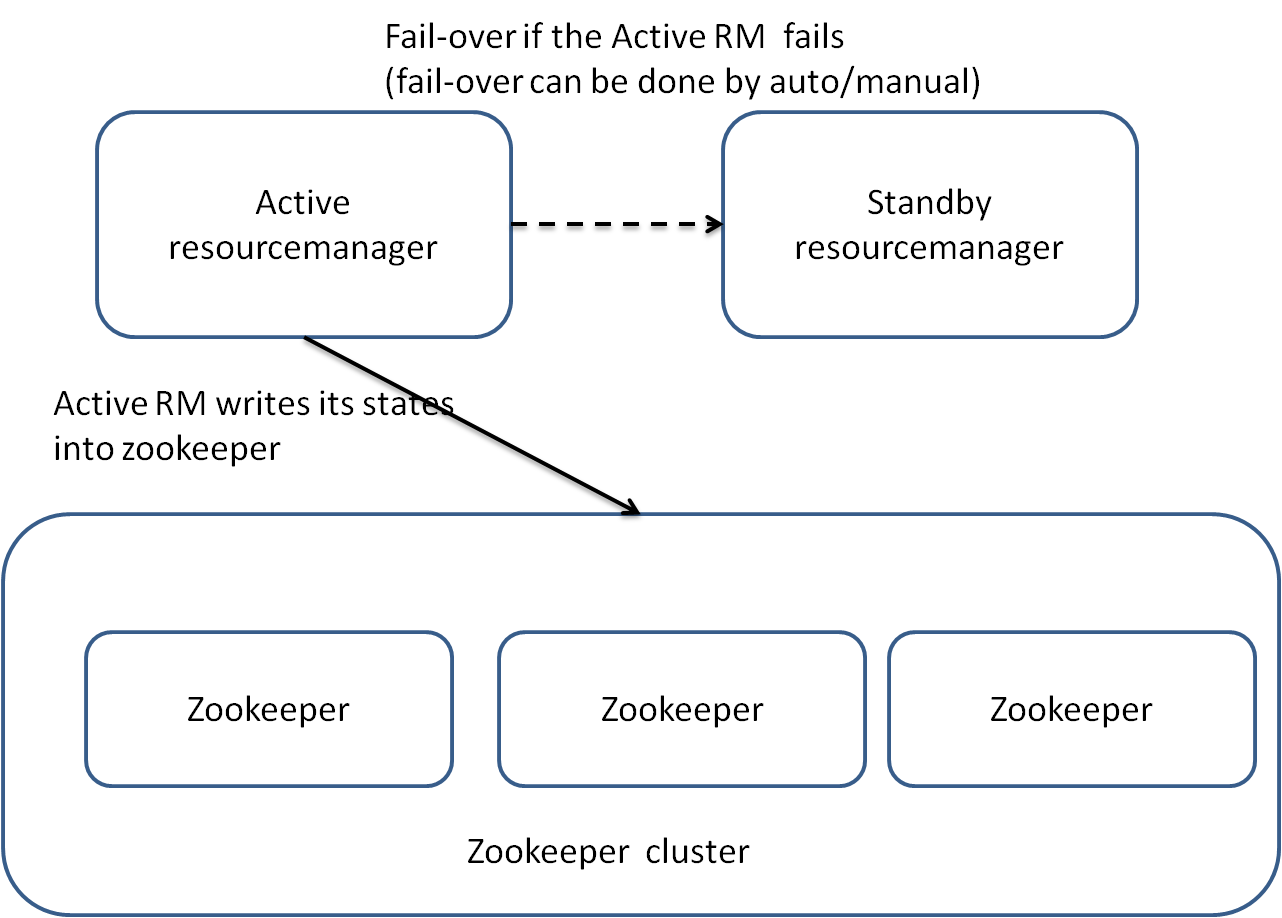
RM HA与NN HA有诸多相似之处:
(1).Active/standby架构,同一时间只有一个RM处于活跃状态。
(2).依赖zookeeper实现。手动切换使用yarn rmadmin命令,而自动切换使用ZKFailoverCrontroller。但是不同的是,zkfc只作为RM中一个线程而非独立的守护进程来启动。
(3).当存在多个RM时,客户端使用的yarn-site.xml需要指定列表。客户端,ApplicationMasters,NodeManagers会以轮训的方式寻找活动状态的RM,也就是Active RM。如果Active RM停止工作了,AMs和NMs就会一直循环查找直至找到一个新的Active RM。这种重试的思路被抽象为属性:org.apache.hadoop.yarn.client.ConfiguredRMFailoverProxyProvider。你可以重写该逻辑,通过使用org.apache.hadoop.yarn.client.RMFailoverProxyProvider并且设置这个属性yarn.client.failover-proxy-provider的值为类名。
(4).新的RM可以恢复之前RM的状态。当启动RM Rstart,重启RM就加载之前活动RM的状态信息并继续之前的操作,这样应用程序定期检查点操作,就可以避免工作内容丢失。在Active/standby的RM中,活动RM的状态数据需要active和standby都能访问,使用共享文件系统方法(FileSystemRMStateStore)或者zookeeper方法(ZKRMStateStore)。后者在同一时间只允许一个RM有写入权限。
2,配置(Configurations)
大部分故障转移功能都可以用下面属性进行配置。具体配制方法可以查看yarn-default.xml。
![configurations.png-45kB][15]
本系统配置实例:
<property><name>yarn.resourcemanager.ha.enabled</name><value>true</value></property><property><name>yarn.resourcemanager.cluster-id</name><value>cluster1</value></property><property><name>yarn.resourcemanager.ha.rm-ids</name><value>rm1,rm2</value></property><property><name>yarn.resourcemanager.hostname.rm1</name><value>niaodonghua1.host</value></property><property><name>yarn.resourcemanager.hostname.rm2</name><value>miaod0nghua2.host</value></property><property><name>yarn.resourcemanager.zk-address</name><value>miaodonghua.host:2181,miaodonghua1.host:2181,miaodonghua2.host:2181</value></property><property><name>yarn.resourcemanager.recovery.enabled</name><value>true</value></property><property><name>yarn.resourcemanager.store.class</name><value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value></property>
3, Admin commands
(1).yarn rmadmin has a few HA-specific command options to check the health/state of an RM, and transition to Active/Standby. Commands for HA take service id of RM set by yarn.resourcemanager.ha.rm-ids as argument.
$yarn rmadmin -getServiceState rm1 active$yarn rmadmin -getServiceState rm2 standby
(2).如果自动故障转移没有启用,你就可以使用下面的命令来切换RM运行的状态。
$ yarn rmadmin -transitionToStandby rm1
4,ResourceManger Restart
- Resourcemanager是资源管理和调度运行在yarn上应用程序的中央机构,因此在一个yarn集群中Resourcemanager可能是单点故障,即只有一个Resourcemanager,这样在该节点出现故障时,就需要尽快重启Resourcemanager,以尽快可能减少损失。
- Resourcemanager重启可以划分为两个阶段。第一阶段,增强的Resourcemanager(RM)将应用程序的状态和它认证信息保存到一个插入式的状态存储中。RM重启时将从状态存储中重新加载这些信息,然后重新开始之前正在运行的应用程序,用户不需要重新提交应用程序。第二阶段中,之前正在运行的应用程序将不会在RM重启后被杀死,所以应用程序不会因为RM中断而丢失工作。
- RM在客户端提交应用时,将应用程序的元数据(如ApplicationSubmissionContext)保存到插入式的状态存储其中,RM还保存应用程序的最终状态,如完成状态(失败,被杀死,执行成功),以及应用完成时的诊断。除此之外,RM还将在安全的环境中保存认证信息如安全秘钥令牌等。RM任何时候关闭后,只要要求的信息(比如应用程序的元数据和运行在安全环境中的认证信息等)在状态存储中可用,在RM重启时,就可以从状态存储中获取应用程序的元数据然后重新提交应用。如果在RM关闭之前应用程序已经完成,不论是成是败、被杀死还是执行成功,在RM重启后都不会再重新提交。
- NodeManagers和客户端在RM关闭期间将保持对RM的轮训,只到RM重启。当启动后,RM将通过心跳机制向正在与其会话的NodeManager和ApplicationMasters发送同步指令。目前NodeManager
和ApplicationMaster处理该指令的方式为:NodeMAnager将杀死他管理的所有容器然后向RM重新注册,对于RM来说,这些重新注册的NodeManager和新加入的nodemanager相似。ApplicationMasters在接受到RM的同步指令后,将会关闭。在RM重启后,从状态存储器中加载应用元数据和认证信息并放入内存之后,RM将为每个还未完成的应用创建新的尝试。正如之前所描述的,此种方式下之前正在运行的应用程序的工作将会丢失,因为他们已经被RM在重启后使用同步指令杀死了。
