@hadoopMan
2017-03-04T14:26:32.000000Z
字数 2331
阅读 1534
flume+kafka+spark+streaming
spark
想学习spark,hadoop,kafka等大数据框架,请加群459898801,满了之后请加2群224209501。后续文章会陆续公开
1,flume+kafka
在flume的source数据源接收到数据后 通过memoryChannel 到达sink,我们需要写一个kafkaSink 来将sink从channel接收的数据作为kafka的生产者 将数据 发送给消费者。
1,flume agent编写
#agent sectionproducer.sources = sproducer.channels = cproducer.sinks = r#source section#producer.sources.s.type = seqproducer.sources.s.type = netcatproducer.sources.s.bind = miaodonghua.hostproducer.sources.s.port = 5555producer.sources.s.channels = c# Each sink's type must be definedproducer.sinks.r.type = org.apache.flume.sink.kafka.KafkaSinkproducer.sinks.r.topic = mytopicproducer.sinks.r.brokerList = miaodonghua.host:9092producer.sinks.r.requiredAcks = 1producer.sinks.r.batchSize = 20#Specify the channel the sink should useproducer.sinks.r.channel = c# Each channel's type is defined.producer.channels.c.type = memoryproducer.channels.c.capacity = 1000
2,启动flume
bin/flume-ng agent \--conf conf \--name producer \--conf-file conf/kafka_flume.conf \-Dflume.root.logger=INFO,console
3,启动zookeeper
bin/zkServer.sh start
4,启动 kafka
bin/kafka-server-start.sh config/server.properties
5,运行kafka customers
bin/kafka-console-consumer.sh --zookeeper miaodonghua.host:2181 --topic mytopic --from-beginning
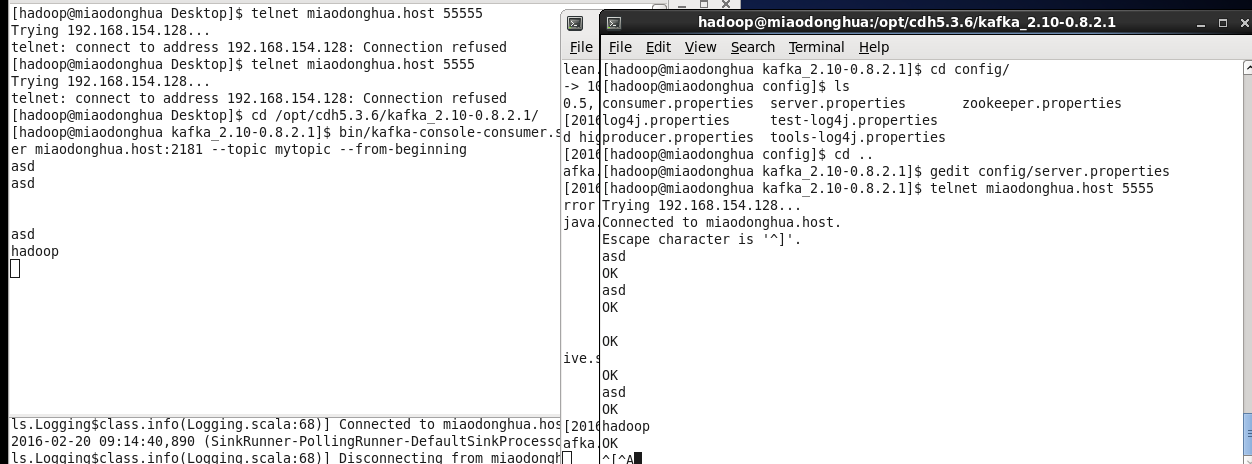
6,测试
网flume监听端口发数据
telnet miaodonghua.host 5555
2,kafka+flume+spark streaming
在flume的source数据源接收到数据后 通过memory 到达sink,我们需要写一个kafkaSink 来将sink从channel接收的数据作为kafka的生产者 将数据 发送给spark streaming。
1,编写spark streaming的wordcount
import org.apache.spark._import org.apache.spark.streaming._import org.apache.spark.streaming.kafka._val ssc = new StreamingContext(sc, Seconds(5))val topicMap = Map("mytopic" -> 1)val lines = KafkaUtils.createStream(ssc, "miaodonghua.host:2181", "testWordCountGroup", topicMap).map(_._2)val words = lines.flatMap(_.split(" "))val counts = words.map((_, 1L)).reduceByKey(_ + _)counts.print()ssc.start()ssc.awaitTermination()
2,启动spark
bin/spark-shell \--jars /opt/cdh5.3.6/spark-1.3.0-bin-2.5.0-cdh5.3.6/externaljars/spark-streaming-kafka_2.10-1.3.0.jar,\/opt/cdh5.3.6/spark-1.3.0-bin-2.5.0-cdh5.3.6/externaljars/kafka_2.10-0.8.2.1.jar,\/opt/cdh5.3.6/spark-1.3.0-bin-2.5.0-cdh5.3.6/externaljars/kafka-clients-0.8.2.1.jar,\/opt/cdh5.3.6/spark-1.3.0-bin-2.5.0-cdh5.3.6/externaljars/metrics-core-2.2.0.jar,\/opt/cdh5.3.6/spark-1.3.0-bin-2.5.0-cdh5.3.6/externaljars/zkclient-0.3.jar \--master local[2]
3,运行wordcount
:load /opt/cdh5.3.6/spark-1.3.0-bin-2.5.0-cdh5.3.6/kafkaWordCount.scala
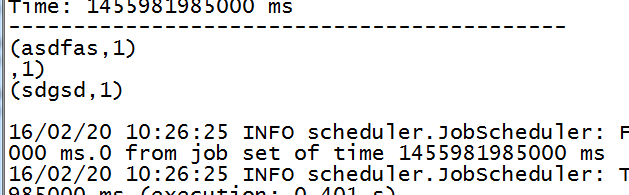
4,测试
输入:

统计成功
 e
e
注:
目前出现这个格式bug
