@hadoopMan
2017-03-04T14:26:14.000000Z
字数 3025
阅读 1161
flume与Streaming集成
spark
想学习spark,hadoop,kafka等大数据框架,请加群459898801,满了之后请加2群224209501。后续文章会陆续公开
1,spark streaming简介
1,Streaming:是一种数据传输技术,它把客户机收到的数据变成一个稳定连续的流,源源不断地送出,使用户听到的声音或看到的图像十分平稳,而且用户在整个文件传送完成之前就可以开始在屏幕上浏览文件。
2,Streaming Compute
- Apache Storm
- Spark Streaming
- Apache Samza
3,上述三种实时计算系统都是开源的分布式系统,具有低延迟、可扩展和容错性诸多优点,它们的共同特色在于:允许你在允许数据流代码时,将任务分配到一系列具有容错能力的计算机上并行运行。此外,她们都提供了简单的API来简化底层实现的复杂度。
三个区别可参考:Storm、Spark Streaming、Samza 三个流式处理架构的区别
2,读取hdfs上文件
$ bin/hdfs dfs -mkdir -p streaming/inputhdfs$ bin/hdfs dfs -put wc.txt streaming/inputhdfs
bin/hdfs dfs -put /opt/datas/wc.input /user/hadoop/streaming/inputhdfs/1
读取程序
import org.apache.spark._import org.apache.spark.streaming._val ssc = new StreamingContext(sc, Seconds(5))val lines = ssc.textFileStream("/user/hadoop/streaming/inputhdfs")val words = lines.flatMap(_.split("\t"))val wordCounts = words.map((_,1)).reduceByKey(_ + _)wordCounts.printssc.start()ssc.awaitTermination()
:load /opt/modules/spark-1.3.0-bin-2.5.0/wordcount.scala
3,与flume集成
1,编译2.5.0-cdh5.3.6
./make-distribution.sh --tgz -Pyarn -Phadoop-2.4 -Dhadoop.version=2.5.0-cdh5.3.6 -Phive -Phive-thriftserver -Phive-0.13.1

2,修改mvn镜像源
编译之前先配置镜像及域名服务器,来提高下载速度,进而提高编译速度,用nodepad++打开/opt/compileHadoop/apache-maven-3.0.5/conf/setting.xml。(nodepad已经通过sftp链接到了机器)
<mirror><id>nexus-spring</id><mirrorOf>cdh.repo</mirrorOf><name>spring</name><url>http://repo.spring.io/repo/</url></mirror><mirror><id>nexus-spring2</id><mirrorOf>cdh.releases.repo</mirrorOf><name>spring2</name><url>http://repo.spring.io/repo/</url></mirror>
3,配置域名解析服务器
sudo vi /etc/resolv.conf添加内容:nameserver 8.8.8.8nameserver 8.8.4.4
4,测试集群
1,FlumeEventCount.scala
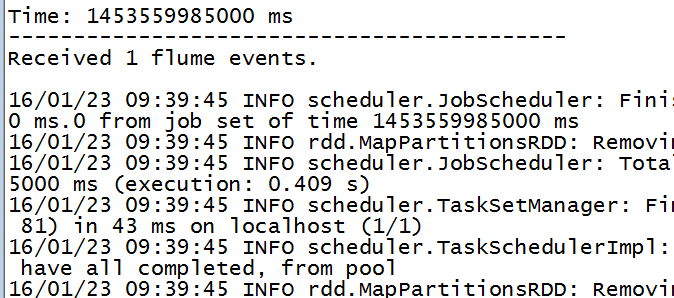
import org.apache.spark._import org.apache.spark.streaming._import org.apache.spark.streaming.flume._val ssc = new StreamingContext(sc, Seconds(5))// Create a flume streamval stream = FlumeUtils.createStream(ssc, "miaodonghua.host", 9999)stream.count().map(cnt => "Received " + cnt + " flume events." ).print()ssc.start()ssc.awaitTermination()
2,编写flume-spark-push.conf
# The configuration file needs to define the sources,# the channels and the sinks.## define agenta2.sources = r2a2.channels = c2a2.sinks = k2## define sourcesa2.sources.r2.type = execa2.sources.r2.command = tail -f /opt/datas/spark-flume/wctotal.loga2.sources.r2.shell = /bin/bash -c## define channelsa2.channels.c2.type = memorya2.channels.c2.capacity = 1000a2.channels.c2.transactionCapacity = 100## define sinksa2.sinks.k2.type = avroa2.sinks.k2.hostname = miaodonghua.hosta2.sinks.k2.port = 9999### bind the sources and sink to the channela2.sources.r2.channels = c2a2.sinks.k2.channel = c2
3,启动spark-shell
bin/spark-shell \--jars /opt/cdh5.3.6/spark-1.3.0-bin-2.5.0-cdh5.3.6/externaljars/spark-streaming-flume_2.10-1.3.0.jar,/opt/cdh5.3.6/spark-1.3.0-bin-2.5.0-cdh5.3.6/externaljars/flume-ng-sdk-1.5.0-cdh5.3.6.jar,/opt/cdh5.3.6/spark-1.3.0-bin-2.5.0-cdh5.3.6/externaljars/flume-avro-source-1.5.0-cdh5.3.6.jar \--master local[2]
4,执行脚本
:load /opt/cdh5.3.6/spark-1.3.0-bin-2.5.0-cdh5.3.6/FlumeEventCount.scala
5,flume指令的运行
bin/flume-ng agent --conf conf --name a2 --conf-file conf/flume-spark-push.conf -Dflume.root.logger=DEBUG,console
6,往wctotal.log追加一条信息
echo hadoop spark shell >>wctotal.log